December 23, 2005
Multiplying ideologies considered harmful
Tim Groseclose and Jeff Milyo's recently-published paper ( ("A Measure of Media Bias", The Quarterly Journal of Economics, Volume 120, Number 4, November 2005, pp. 1191-1237) has evoked plenty of cheers and jeers around the web. The complaints that I've read so far (e.g. from Brendan Nyhan, Dow Jones, Media Matters) have mainly focused on alleged flaws in the data or oddities in the conclusions. I'm more interested in the structure of their model, as I explained yesterday.
As presented in the published paper, G&M's model predicts that perfectly conservative legislators -- those with ADA ratings of 0% -- are equally likely to cite left-wing and right-wing sources, basing their choices only on ideology-free "valence" qualities such as authoritativeness or accessibility. By contrast, perfectly liberal legislators are predicted to take both ideology and valence into account, preferring to cite left-wing sources as well as higher-quality or more accessible ones. Exactly the same pattern is predicted for media outlets, where the conversative ones should be indifferent to ideology, while the more liberal the media, the more strongly ideological the predicted motivation.
Common sense offers no reason to think that either politicians or journalists should behave like this, and everyday experience suggest that they don't -- the role of ideology in choice of sources, whatever it is, doesn't seem to be qualitatively different in this way across the political spectrum. Certainly Groseclose and Milyo don't offer any evidence to support such a theory.
This curious implication is a consequence of two things: first, G&M represent political opinion in terms of ADA scores, which vary from 0 (most conservative) to 100 (most liberal); and second, they put political opinion into their equations in the form of the multiplicative terms xibj (where xi is "the average adjusted ADA score of the ith member of Congress" and bj "indicates the ideology of the [jth] think tank") and cmbj, where cm is "the estimated adjusted ADA score of the mth media outlet" and bj is again the bias of the jth think tank.
As I pointed out yesterday, the odd idea that conservatives don't care about ideology can be removed by quantifying political opinion as a variable that is symmetrical around zero, say from -1 to 1. (It's possible that G&M actually did this internal to their model-fitting, though I can't find any discussion in their paper to that effect.) However, this leaves us with two other curious consequences of the choice to multiply ideologies.
First, on a quantitatively symmetrical political spectrum it's the centrists -- those with a political position quantified as 0 -- who don't care about ideology, and are just as happy to quote a far-right or far-left source as a centrist source. This also seems wrong to me. Common sense suggests that centrists ought to be just as prone as right-wingers and left-wingers to quote sources whose political positions are similar to their own.
A second odd implication of multiplying ideologies is that as soon as you move off of the political zero, your favorite position -- the one you derive the most utility from citing -- become the most extreme opinion on your side of the fence, i.e. with the same sign. If zero is the center of the political spectrum, and I'm a centrist just a bit to the right of center, then I'll maximize my "utility" by quoting the most rabid right-wing sources I can find. If I happen to drift just a bit to the left of center, then suddenly I'm happiest to quote the wildest left-wing sources. This again seems preposterous as a psycho-political theory.
I'm on record (and even with a bit of evidence) as being skeptical of the view that the relationship between ideology and citational preferences is a simple one. And I'll also emphasize here my skepticism that political opinions are well modeled by a single dimension. But whatever the empirical relationship between political views and citational practices is, it seems unlikely that ideological multiplication captures it accurately.
On the other hand, does any of this matter? It's certainly going to do some odd things to the fitted parameters of G&M's model. For example, if they really treated the conservative position as the zero point of the political spectrum, then I'm pretty sure that their estimated "valence" parameters (which they don't publish) will have encoded quite a bit of ideological information. If we had access to G&M's data -- it would be nice if they posted it somewhere -- we could explore various hypothesis about the consequences of trying models with different forms. Since (as far as I know) the data isn't available, an alternative is to look at what happens in artificial cases. That is, we can generate some artificial data with one model, and look to see what the consequences are of fitting a different sort of model to it.
I had a spare hour this afternoon, so I tried a simple example of this. I generated data with a model in which people most like to quote sources whose political stance is closest to their own -- left, right or center -- and then fitted a model of the form that G&M propose. The R script that I wrote to do this, with some comments, is here, if you want to see the details. (I banged this out rather quickly, so please let me know if you see any mistakes.) One consequence of this generation/fitting mismatch seems to be that the "valence" factor for the think tanks (which I assigned randomly) and the noise in the citation counts perturb the "ideology" and "bias" estimates in a way that looks rather non-random. I've illustrated this with two graphs showing the difference between the "true" underlying media bias parameters (with which I generated the data) and the estimated media bias parameters given G&M's model. The first graph shows a run in which nearly all the media biases are overestimated,
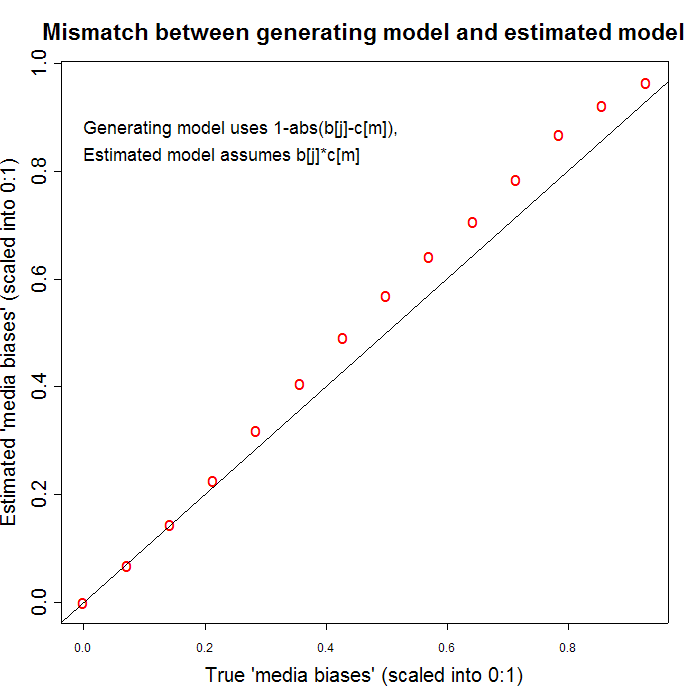
while the other shows a run in which nearly all the media biases are underestimated.
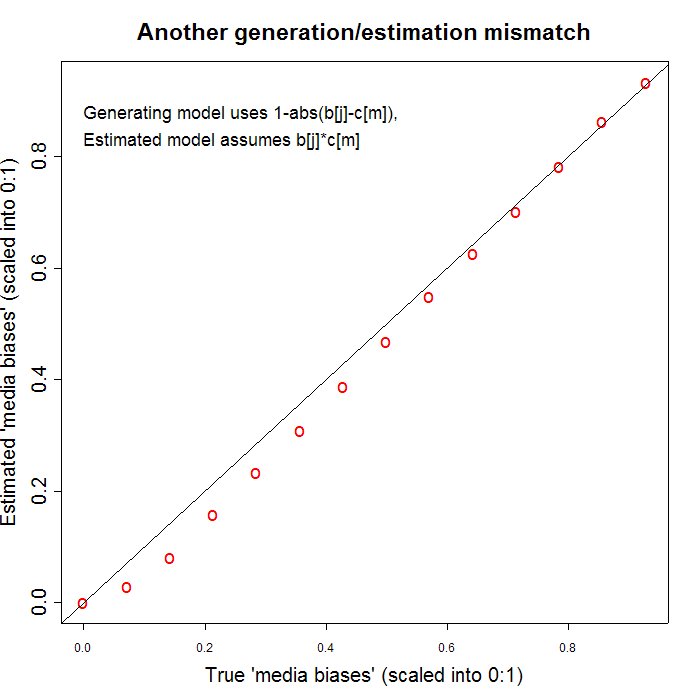
The only difference was different seeds for the random number generator. I used rather small amount of noise in the citation counts -- noisier counts give bigger deviations from the true parameter values, like this one:
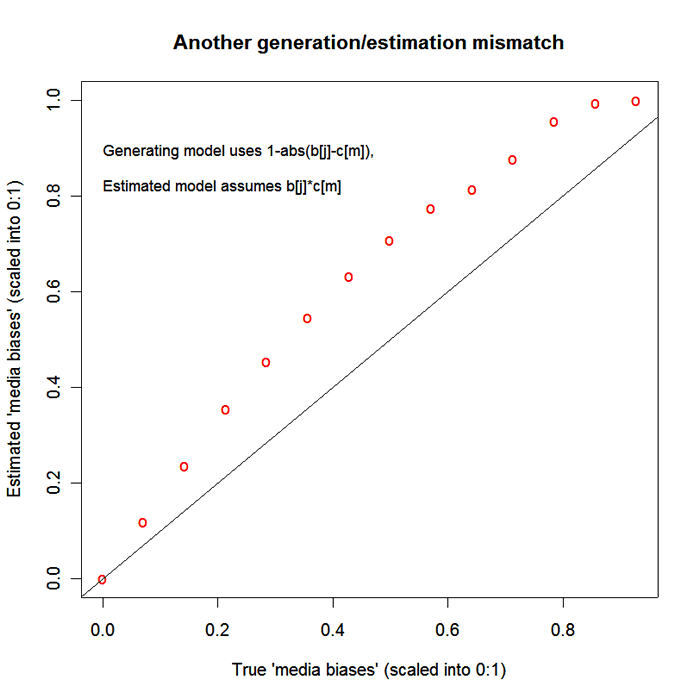
Presumably similar effects could be caused by real-word "valence" variation or by real-world citation noise. Nearly all runs that I tried showed this kind of systematic and gradual bending of the estimates relative to the real settings, rather than the sort of erratic divergences that you might expect to be the consequences of noise. Since R is free software, you can use my script yourself as a basis for checking what I did and for exploring related issues.
(By the way, the mixture of underlying 'ideology' into estimated 'valence' can be seen clearly in this modeling exercise -- here's a plot illustrating this:
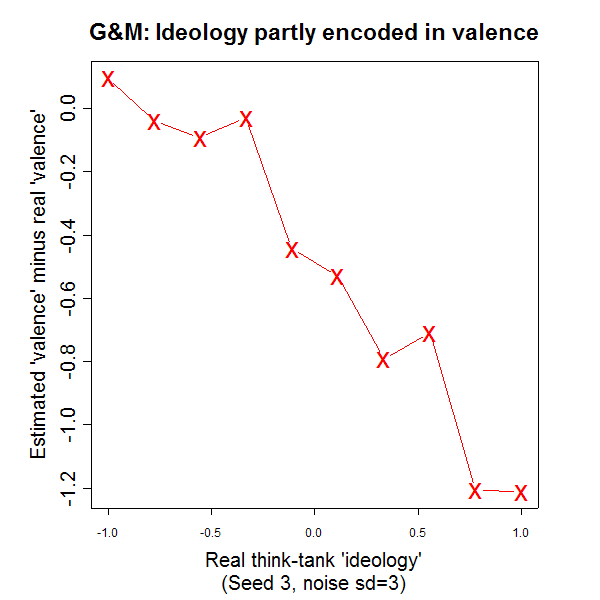
)
I'm not claiming to have shown that G&M's finding of quantitative media bias is an artefact. I do assert, though, that multiplying ideologies to get citation utilities (and through them, citation probabilities) is a choice that makes very implausible psychological claims, for which no evidence is presented. And fitting ideology-multiplying models to data generated by processes with very different properties can definitely create systematic artefacts of a non-obvious sort.
No regular readers of Language Log will suspect me of being a reflexive defender of the mass media. I accept that news reporting is biased in all sorts of ways, along with (in my opinion) more serious flaws of focus and quality. I think that it's a very interesting idea to try to start from congressional voting patterns and congressional citation patterns, in order to infer a political stance for journalism by reference to journalistic citation patterns. I also think that many if not most of the complaints directed against G&M are motivated in part by ideological disagreement -- just as much of the praise for their work is motivated by ideological agreement. It would be nice if there were a less politically fraught body of data on which such modeling exercises could be explored.
Posted by Mark Liberman at December 23, 2005 05:16 PM