November 06, 2003
Discourse: branch or tangle?
Coherent texts seem to have a clear, more-or-less hierarchical structure that crosses sentence boundaries, and may extend over arbitrarily long passages. However, several millennia of attempts to provide an analytic foundation for this kind of discourse structure have been disappointing. At least, discourse has never achieved the kind of widely-accepted informal analytic lingo that we take for granted as a foundation for talking about syntax: "in the sentence It is a vast and intricate bureaucracy, there is a noun phrase a vast and intricate bureaucracy, in which vast and intricate is a conjunction of adjectives modifying the head noun bureaucracy; etc."
Why? Is the apparent structure of coherent text just an incoherent illusion, a rationalization of ephemeral affinities that emerge as a by-product of the process of understanding? Is it too hard to figure things out when there is little or no morphological marking? Have linguists just not paid enough attention?
Recently, several of the many small groups developing various theories of discourse analysis have started creating and publishing corpora of texts annotated with structures consistent with their theories. The RST Discourse Treebank led the way, with the 2002 publication of Rhetorical Structure Theory annotations of 385 Wall Street Journal articles from the Penn Treebank. The corpus has enabled this approach to be widely used in engineering experiments and even some working systems.
Now Florian Wolf and Ted Gibson have put forward an alternative approach. In a paper entitled The descriptive inadequacy of trees for representing discourse coherence, they argue that "trees do not seem adequate to represent discourse structures." They've also provided an annotation guide for an approach that does not assume strictly hierarchical relationships in discourse, and annotations of 135 WSJ texts, which have been submitted for publication to the LDC.
As a non-expert in such things, I find their arguments convincing. Even leaving aside the structure of everyday speech, where we all too often surge enthusiastically "all through sentences six at a time", there are often cases where the commonsense relationships between bits of discourse seem to cross, tangle and join in a way that a strictly hierarchical structure does not allow.
Here's an example taken from the Wolf/Gibson paper (souce wsj_0306; LDC93T3A), divided into discourse segments:
0. Farm prices in October edged up 0.7% from September
1. as raw milk prices continued their rise,
2. the Agriculture Department said.
3. Milk sold to the nation's dairy plants and dealers averaged $14.50 for each hundred pounds,
4. up 50 cents from September and up $1.50 from October 1988,
5. the department said.
Here's their annotation of coherence relations for this segmentation:
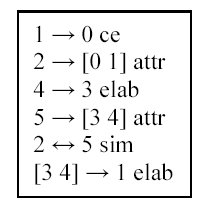
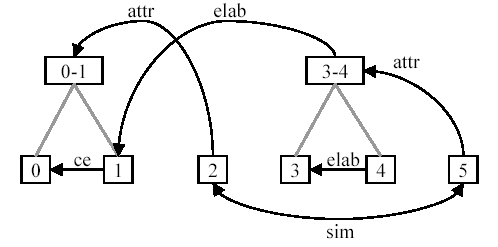 |
(ce=Cause-Effect; attr=Attribution; elab=Elaboration; sim=Similarity.)
Note how the "Elaboration" relation between segments [3 4] and segment 1 crosses the "Attribution" relation between segment 2 and segments [0 1], and also applies only the second segment of the [0 1] group. This seems to me like a plausible picture of what's happening in this (simple) passage -- I wonder if someone who believes in tree-structured theories of discourse relations can offer an argument against cases like this.
Overall, Wolf and Gibson report that in their corpus of 135 texts, 12.5% of the (roughly 16,000) arcs would have to be deleted in order to eliminate crossing dependencies, and 41% of the nodes had in-degree greater than one (i.e. would have multiple "parents" in a tree-structured interpretation).
I think that these things -- both the RST Treebank and the Wolf/Gibson corpus -- are wonderful steps forward. Two alternative approaches to the same (hard) problem offer not just examples and arguments, but also alternative corpora (of overlapping material!), annotation manuals, annotation tools and so on.
The RST authors have applied their ideas to engineering problems of summarization, MT, essay grading and so on, as well as basic linguistic description. Wolf and Gibson are using their analysis as a foundation for psycholinguistic research as well as information extraction and other engineering applications.
What a great time to be in this field!
[Update: a response by Daniel Marcu is discussed here, and a response by Florian Wolf to this response is discussed here.]
Posted by Mark Liberman at November 6, 2003 08:13 PM