December 11, 2003
Ticks and tocks of glottoclocks
As a footnote to Bill Poser's lucid discussion of the recent Nature article by Gray and Atkinson, Language-tree divergence times support the Anatolian theory of Indo-European origin, I thought I'd put up a few details from earlier work on rates of vocabulary retention.
Note, by the way, that I don't mean any of this as a refutation of Gray and Atkinson's work. Their (very brief) paper and their bibliography make it clear that they are quite familiar with the relevant literature and have in some way taken account of these issues in their modeling. Their basic innovation is the application of a "model-based bayesian framework," which they assert "allowed us to ... estimate divergence times without the assumption of a strict glottoclock." I can understand in principle how this might work, but the problem, as Bill explained, is that from their paper it's not possible to determine in any detail just what they did, and so it's hard to evaluate their conclusions. Like Bill, I look forward to learning more about this work. From their references we can learn a bit more about the class of bayesian models they used (whose equations they do not provide in the published paper), but it's clear that a fuller evaluation of their time estimation methods will have to wait on a fuller publication of their research and/or similar explorations by others.
I should note also that Nature posts on its web site "supplementary info" about papers that it publishes, and in this case it would have been very appropriate to supply a fuller account of the work, since the web site presumably does not suffer from the severe space limitations of the paper journal. Unfortunately in this case the supplementary information is just a table of the "[a]ge constraints used to calibrate the divergence time calculations, based on known historical information". This table makes it clear that the authors worked hard to be careful in establishing dates to provide a sort of scaffolding for their bayesian framework, and provides another indication that this is a serious and interesting work, very different in its flavor from the work of Forster and Toth recently published in PNAS. However, it still doesn't tell us what model they actually fit!
Swadesh (1952) estimated 14% change (86% retention) per millenium in his defined vocabulary. Lees (1953) estimated 20% change (80% retention) per millenium:
Thirteen sets of data, presented in partial justification of these assumptions, serve as a basis for calculating a universal constant to express the average rate of retention k of the basic-root morphemes:
k = 0.8048 ± 0.0176 per millennium,
with a confidence limit of 90%.
Here's some of Lees' data:
| Language |
Years |
Words |
Cognate |
Rate (per KY) |
| English | 1000 |
209 |
160 |
.766 |
| Latin/Spanish | 1800 |
200 |
131 |
.790 |
| Latin/French | 1850 |
200 |
125 |
.776 |
| German | 1100 |
214 |
180 |
.854 |
| Middle Egyptian/Coptic | 2200 |
200 |
106 |
.760 |
| Greek | 2070 |
213 |
147 |
.836 |
| Chinese | 1000 |
210 |
167 |
.795 |
| Swedish | 1050 |
207 |
176 |
.853 |
Here are some estimated per-millenium retention rates for "more retentive" languages, taken from Bergsland & Vogt (1962):
| Language |
100-word list |
200-word list |
| Icelandic (rural) | .990 |
.976 |
| Icelandic (urban) | .980 |
.962 |
| Georgian | .965 |
.899 |
| Armenian | .978 |
.940 |
Here are some less retentive ones, cited in Guy (1994):
| Language |
Source |
Time period |
Retention |
Rate per 1KY |
| East Greenlandic | Bergsland & Vogt | 600 years |
.722 |
.34 |
| Muyuw (Woodlark Island) |
David Lithgow | "one generation" | ~.80 |
~.06 |
I'm not sure how well documented the last data point (suggesting 20% vocabulary replacement in one generation) is, but it certainly seems that a fairly wide range of rates can be observed empirically.
However, note that because the assumed model is stochastic, and the numbers (of words) are small, some variation is to be expected given a constant underlying rate, and in principle any actual replacement rate could be observed. The half life of Oxygen 15 is 2 minutes, but if we start with only two atoms, it's by no means certain that after two minutes, exactly one atom will have decayed and one will be left. That is the most likely single outcome, but there is an equal chance that both or neither will have decayed. Of course, as the number of atoms increases, the likelihood of substantial deviations from 50% total decay after 2 minutes goes down.
What kind of variation of word loss rates over a millenium do we expect, given a "strict glottoclock"? Well, there are 50 20-year "generations" in a millenium, so if a word has probability R of being retained for a millenium, it should be retained with probability R^(1/50) per generation. I ran a trivial little simulation, in which each of 200 words has a fixed chance of being lost in each of 50 generations, and got an empirical distribution of outcomes like this:
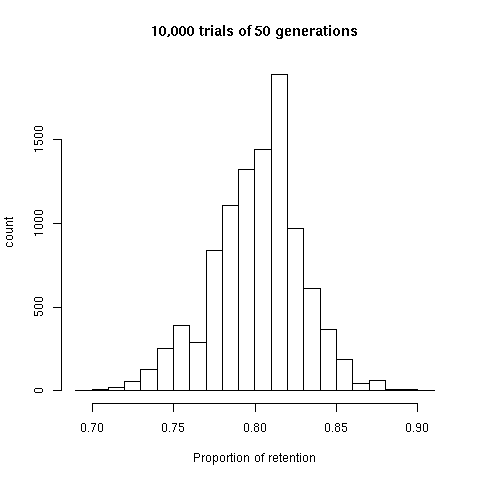
A distribution like this is quite consistent with the values in Lees' sample (as he well understood), but both the more retentive and less retentive examples from e.g. Bergsland and Vogt are rather unlikely to come from such a source. That's the essential basis for the conventional skepticism about the validity of the dates emerging from classical glottochronology: if two languages A & B share 80% of the Swadesh 200 list, then if the underlying rate is .8 retention per millenium, A and B probably separated about 1000 years ago; but if the underlying rate is the .34 retention per millenium documented for East Greenlandic, then A and B most likely separated about 210 years ago; and if the underlying is the .976 retention per millenium documented for rural Icelandic, then the most likely time for the separation of A and B is about 9200 years ago. These look like pretty big uncertainties; and the number of cases for which we have good calibration of historical "glottoclock rates" is not very large; and there are almost certainly significant effects of speech community size, extent of contact, type of social organization and so on, which are not very well varied in our sample of calibration cases.
[Note that large differences in the "glottoclock" rate along different branches of a language family may also cause relative cognation proportions to be incongruent with the true historical descent structure. As Bill Poser pointed out to me, in Bergsland and Vogt's work this led to the lexicostatistical conclusion that the biggest split among Eskimo languages is between East and West Greenlandic, which is not plausible on other grounds.]
Some very smart people have worked on ways to get around these problems or at least to quantify them carefully. One of these whom I know well is Joe Kruskal, who made significant contributions in many areas of applied mathematics, and who was always very scrupulous in his attention to the facts of the various applications areas he worked in, and very careful in the claims that he made for the results he achieved. My own evaluation has been that the past attempts to rescue glottochronology have produced results that are interesting but remain subject to great uncertainties of interpretation, and I don't think that Joe would disagree with that. I'll be very interested to see how far the new ideas of Gray and Atkinson -- or perhaps it's better to say their application of ideas that have been developed in the biological modeling literature -- go towards reducing those uncertainties.
[Note: there is a useful discussion and bibliography on "classical" lexicostatistics and glottochronology on Paul Black's web site here.]
Posted by Mark Liberman at December 11, 2003 09:53 PM