September 05, 2004
Blame Miles Bartholomew, Ward Stone Ireland and IBM
With respect to the Spanish closed-captioning for the recent Republican convention, Geoff Pullum contemplated the translation of Senator Olympia Snowe as "Senador Nieve de Olympia", and asked "Is it incredibly stupid 16-year-old human translation slaves that they have chained to desks at the captioning service office? Or machine translation software so dumb that even the armed services wouldn't pay for research into how to improve it any more so they had to go sell to the private sector?"
Well, it certainly seems as if some particularly stubborn transfer-based MT system might have been in the loop ("OK, we have an English phrase of the form MODIFIER NOUN, so that means we get a Spanish version in the form TranslationOf(NOUN) de TranslationOf(MODIFIER)"). But I suspect that the rest of the problem was probably not the fault of a human operator, but rather the consequence of a CAT ("Computer Aided Transcription") system.
If so, the (indirectly) guilty individuals were Miles Bartholomew, the "father of the stenograph", who patented the first American shorthand machine in 1879; Ward Stone Ireland, whose "high-speed keyboard [is] still in use today"; and a series of inventors funded from 1950 through the 1980s by the U.S. Defense Department and IBM, who created the technology for CAT.
In this system, the (human) transcriber uses a special keyboard, with a layout like this:
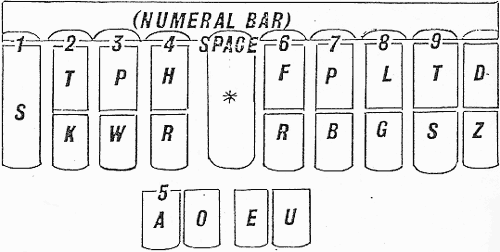
Some of the benefits are explained in this page, such as the fact that the word straight can be typed with one "stroke" (in which multiple keys are depressed), and the word centralization with three "strokes". Some details of how it works are explained here. A key point is that the primary coding scheme is based on pronunciation rather than on spelling. You can get an idea how this works from the stenotype output below, which represents the phrase "You should be able to read these short words":

Here's the basic stenotype "alphabet" -- remember that multiple keys are typically depressed simultaneously, coding a syllable or more at a time:

Note that not all sounds are represented directly on the keyboard, so that (for example) "gleam" is written by simultaneously chording the eleven keys TKPWHRAOEPL (which is what prints out on the tape), interpreted as TKPW = g, HR = l, AOE = long e, and PL = final m. Of course, (the toothpaste brand) "Gleem" would be chorded in just the same way, since the system is based on pronunciation.
The tape below shows a realistic example of such transcription, combining pronunciation-based sequences with other sort of keypresses, which according to the page where I got this, may be "unique to each reporter. In addition to the spoken word the reporter writes steno outlines to identify speakers; punctuate; insert parenthetical phrases, 'notes to self,' cues for computer translation. Some reporters invent new steno outlines 'on the fly' as needed".

In the old days, the machine just allowed the transcriptionist to keep up with a speaker in real time, but a human (typically the same transcriptionist) needed to go back later and transcribe the notes to normal text form. These days, the transduction to normal text is normally done by means of a computer program, which uses the same sort of "language model" that a speech recognition system does, in order to make appropriate guesses about how to make the translation. If there's time and/or money, a human editor may check the output, but if you want things cheaply and/or quickly, this may not happen.
I don't know exactly what combination of human and machine transcription and translation technologies was involved in producing the Spanish subtitles at the Republican convention, but if the transduction from "Senator Olympia Snowe" to "Senador Nieve de Olympia" involved a CAT step, then the loss of Senator Snowe's mute e was a small sample of the changes that in principle might have taken place, as this page explains.
Posted by Mark Liberman at September 5, 2004 10:59 PM