September 15, 2004
Voice writing
Yesterday afternoon I took the train up to New York, to participate in a panel that Caroline Henton organized at SpeechTEK entitled "Everything You Always Wanted to Know about Voice but were Afraid to Ask". I really enjoyed the other panelists' talks. Marc Moens talked about how to furnish synthetic voices with personality, attitude and emphasis; Sandy Disner talked about "voice stress analysis" and similar things; Judith Markowitz talked about speech-based biometrics; and Chad Theriot talked about the use of automatic speech recognition in real-time transcription, with a demonstration by Jennifer Smith, the President-Elect of the National Verbatim Reporters Association.
The whole experience made me sorry that I didn't plan to spend more time at the SpeechTEK meeting, which I haven't attended in many years. I'll post about the other talks I heard, sooner or later -- the only good thing about dropping in to an interesting meeting for a couple of hours is that there are only a few things to describe -- but I'll start by explaining what I learned from Chad and Jennifer, which complements what I wrote a few days ago about the technology of real-time transcription.
 An alternative to the special chording keyboards that I wrote about earlier is "voice writing", a method originally developed by Horace Webb more than 60 years ago. The basic equipment is traditionally a two-track recorder, a microphone for picking up the proceedings that are being transcribed, and a special "stenomask" which the transcriptionist can use to
"repeat everything that occurs during testimony" without being heard by others. These days, people use a laptop computer as the multi-track recorder, and they also often use automatic speech recognition software to create a draft of the transcript. The software analyzes the transcriptionist's shadowing of the proceedings, not the original signal -- this allows the (much) higher recognition rates that are possible when the program is adapted to the speaker, and the speaker is adapted to the program. The ASR software used is one of the standard systems, typically either IBM's ViaVoice or Dragon's Naturally Speaking.
An alternative to the special chording keyboards that I wrote about earlier is "voice writing", a method originally developed by Horace Webb more than 60 years ago. The basic equipment is traditionally a two-track recorder, a microphone for picking up the proceedings that are being transcribed, and a special "stenomask" which the transcriptionist can use to
"repeat everything that occurs during testimony" without being heard by others. These days, people use a laptop computer as the multi-track recorder, and they also often use automatic speech recognition software to create a draft of the transcript. The software analyzes the transcriptionist's shadowing of the proceedings, not the original signal -- this allows the (much) higher recognition rates that are possible when the program is adapted to the speaker, and the speaker is adapted to the program. The ASR software used is one of the standard systems, typically either IBM's ViaVoice or Dragon's Naturally Speaking.
Chad's company, Audioscribe, sells software and system packages for this application. Jennifer used this method to transcribe the panel presentations and discussions, with the results appearing in real time on a computer projection screen, in the format shown in the (promotional) screenshot below. The quality was very good, definitely in the range of the "95% correct or better" that is claimed -- which means several mistakes per average screenful, to be corrected in a proofreading stage later on.
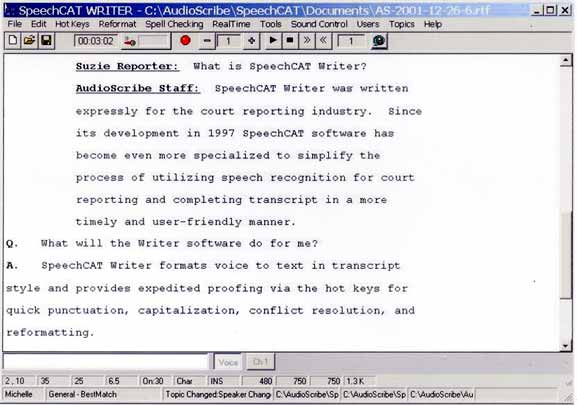 The approach has some problems, both for the human users and for the ASR systems. The human users need to learn to shadow others' speech accurately at high rates for long periods of time, while also entering the other sorts of information that a transcript requires. The ASR systems need to learn to deal with sotto voce or even whispered speech.
The approach has some problems, both for the human users and for the ASR systems. The human users need to learn to shadow others' speech accurately at high rates for long periods of time, while also entering the other sorts of information that a transcript requires. The ASR systems need to learn to deal with sotto voce or even whispered speech.
But the most difficult challenge for both is dealing with fast speech. ASR systems are not supposed to work past about 160 words per minute; but transcriptionists find that they need to keep up with people who are often talking in the range of 180-350 wpm. The speech recognition engines can "learn" to work at rate up to about 250 wpm, according to Chad and Jennifer, but above that rate, they break down in a serious way, even though the human "voice writers" can shadow accurately at up to 350 wpm. In order to deal with this problem, the transcriptionists create special "fast speech vocabulary" -- pseudowords for common words or word sequences spoken rapidly -- which the recognition engines can learn to map to the right transcription. This is apparently one of the more difficult aspects of learning to use this technique.
I was very interested to learn about voice writing, not least because the practice offers the possibility of getting a very large amount of interesting material for speech research. As I understand it, there are about 10,000 trained "voice writers", and about 2,500 who use the computer technology, each doing several hours of transcription per work day. (I gather that there are about 100,000 users of stenograph machines). While some of the recorded and transcribed material is confidential or otherwise limited in distribution, much of it is not, and so there are millions of hours of speech every year for which digital audio, digital audio of the "shadow" track", and a digital form of the (corrected) transcript are being created, and might in principle be used for speech research.
Jim Baker has recently speculated in interesting ways about what speech recognition research could do with millions of hours of speech. Anyone with a bit of imagination can also think of many ways that access to very large transcribed speech corpora could be used as an empirical foundation for scientific or lexicographic investigations of speech and language. The Linguistic Data Consortium and other organizations have found ways to get thousands of hours of transcribed audio that can be used as a shared basis for research in speech science and engineering. There are millions of hours of transcribed audio out there, but there are both practical and legal impediments to getting research access. My conversation with Chad and Jennifer suggests a route to a solution, since the members of the voice writing community have an active interest in fostering the development of better ASR technology.
Posted by Mark Liberman at September 15, 2004 09:33 AM