December 13, 2004
Bibster
In response to yesterday's post on typed citation links, Stefano Bertolo emailed to draw my attention to Bibster. It's a Semantic Web project that combines the widely-used BibTex format for bibliographical records with the "napster"-associated idea of peer-to-peer searching.
The project is documented in Haase et al., "Bibster - A Semantics-Based Bibliographic Peer-to-Peer System", whose abstract reads
This paper describes the design and implementation of Bibster, a Peer-to-Peer system for exchanging bibliographic data among researchers. Bibster exploits ontologies in data-storage, query formulation, query-routing and answer presentation: When bibliographic entries are made available for use in Bibster, they are structured and classified according to two different ontologies. This ontological structure is then exploited to help users formulate their queries. Subsequently, the ontologies are used to improve query routing across the Peer-to-Peer network. Finally, the ontologies are used to post-process the returned answers in order to do duplicate detection. The paper describes each of these ontology-based aspects of Bibster. Bibster is a fully implemented open source solution built on top of the JXTA platform.
(Another version of the same paper seems to be available here).
The two ontologies in question are SWRC (the "Semantic Web Research Community Ontology"), which "models the semantic web research community (its researchers, topics, publications, tools, etc. and relations between them)", and the ACM Computing Classification System (often called "the ACM topic hierarchy").
I downloaded the Bibster application, installed, and tried an initial search for papers by Haase, the first author of the Bibster documentation cited above. The search took about three minutes and returned nothing. I'm not sure whether the application actually succeeded in finding any peers to query -- maybe now that the "case study" is done and the paper has been published, the project is inactive? The schedule on the Bibster web site says that it should continue
| 29.03.2004 | Phase I will start SWAP developers will work with the system. The network will consist of about 20 peers. |
| 07.04.2004 | Phase II will start The Bibster partner team will join the case study. Additionally about 30 peers will join the Bibster test team. The Phase II partners will be completely supported by the Bibster team. |
| 09.07.2004 | Phase III will start Bibster will be announced on several mailing lists and will become a public system. |
| 30.09.2004 | The official case study will be stopped. The logging will be cancelled and the collected data will be evaluated. Of course, the Bibster system itself will continue its work. |
but this depends on the user base keeping it going. If Bibster peers are out there, the application running on my machine here doesn't seem to be able to find them.
Additionally, I will say that I don't think that the ACM topic hierarchy is very helpful as a framework for bibliographic search. My hope to check this by trying to use it in searching the computer science literature has been frustrated by my failure to find any Bibster peers to search over. However, I took three topics that I happen to be interested in right now, and tried to see where they would fit into the ACM CCS. In each case, my experience was the same -- the topic of interest to me seemed to fit, more or less uneasily, into several categories at once, leaving me skeptical that choosing such categories would do me much good in searching.
All in all, I was disappointed. There are many interesting ideas in the Bibster documentation, but it's not clear to me that (even if there were lots of peers out there) it would work better as a way to navigate in bibliographical space than Google Scholar, CiteSeer, Scirus or similar centralized search tools, which use the bibliographies of the indexed literature as a proxy for the distributed bibliographical databases that Bibster aims to take advantage of. I did not have a chance to experience the claimed benefit of the ontologies in query routing and duplicate detection, but my experience with trying to use the ACM topic hierarchy in query formulation was not an inspiring one.
So it looks to me like the Semantic Web is a still set of possible solutions looking for a problem -- see here, here, here, here here for prior discussions. And there's an interesting article by Dan Brickley entitled Nodes and Arcs 1989-1999, which puts the Semantic Web in a recent historical perspective, and in particular displays this figure from the original 1989 WWW proposal
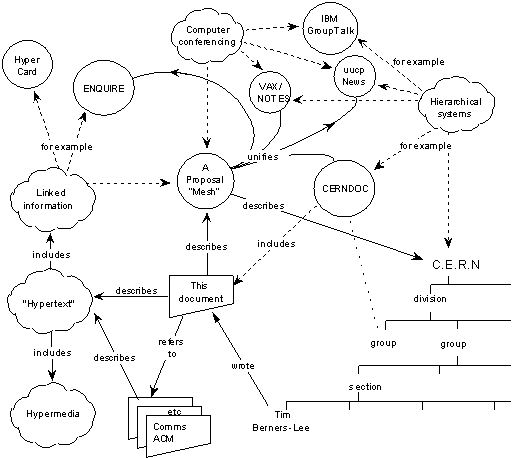
— which reminds us that the web has always been about to be about semantic networks, but somehow it keeps turning out to be about (communication by means of text and pictures embedded in) structures with functions but no intrinsic semantics.
[Update 12/16/2004: Steffen Staab sent these comments by email:
There is an important trivial comment:
in fact the two rendevous servers have been down because of simple administration problems.
As Bibster is no longer a core task, we do not look for it every day....
(and actually the rendevous server is all about JXTA and not about Semantic Web at all)The more interesting comment is about what is the use of ACM topic hierarchy?
Well, it is as bad as such a hierarchy goes.
a. It is too general for the expert.
b. It does not closely mirror new developments
c. It is not possible to unambigously assign bib items.It is also as good as such a hierarchy goes.
a. The less proficient user (not one that does not know the domain) gets an idea how the domain could be structured.
b. The hierarchy allows for easier search through larger parts
(this only becomes relevant for more complex searches; actually this is a point where ontoprise earns money with!)
c. It is better to have a weak agreement than none.And:
a. you can still do keyword search! So, you are still as good as plain information retrieval.
b. you can use the social network structure. Knowing that a particular entry on semantic annotation is relevant for your fellow researcher is an implicit evaluation!
c. you can use Bibster to manage your bib entries!Most importantly:
It really is a complete shift of the paradigm that some central server stores all the resources and raises many more potential than even Bibster already has.Granted, all this needs much more software engineering (e.g. giving feedback about responsiveness of servers, leaving less CPU and memory imprint etc.).
Granted, this also must be able to attract enough attention in order to solve the chicken and egg problem that users go, where other users are (e.g. there were many marketplaces but ebay virtually hooks all auctioneers now).
Hence, I think the arguments you make in your blog don't hit the nail on its head.
The next couple of days are kind of busy for me, but I'll try Bibster again over the weekend and report back when I've had a chance to try it.
There are serious issues here about centrally-controlled vs. peer-to-peer search, the role of ontologies in search and in navigation of search results, etc., which deserve more thought and discussion. ]
Posted by Mark Liberman at December 13, 2004 06:15 PM