December 27, 2004
UIMA
James Fallows has an article in yesterday's NYT business section under the headline "At I.B.M., That Google Thing Is So Yesterday". He's talking about UIMA, which I've heard pronounced as "weema", and which stands for Unstructured Information Management.
If you're interested in more, there's a whole issue recent issue of IBM Systems Journal, 43(3), entitled Unstructured Information Management:
Unstructured information represents the vast majority of the data collected and accessible to enterprises. This data may be in various formats and may lack the organization of traditional sources such as database records. Exploiting this information requires systems for managing and extracting knowledge from large collections of unstructured data and applications for discovering patterns and relationships. This issue presents eight papers on the tools, methods, and architectures which are evolving for managing unstructured information in areas such as life science and market research.
Here's an IBM diagram that lays out what this is all supposed to do:
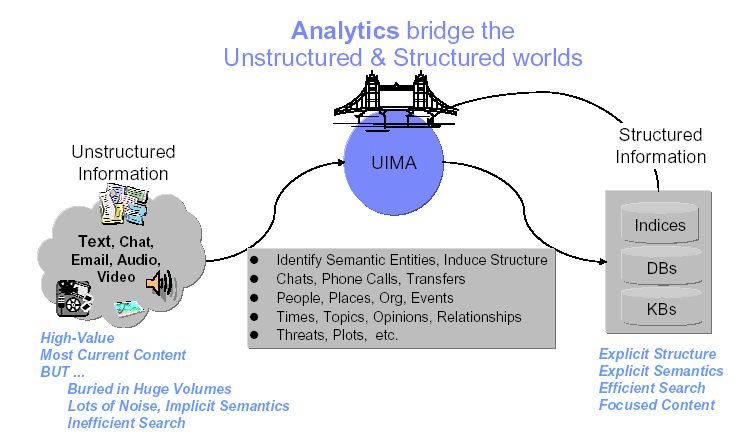
On 12/16/2004, IBM posted to alphaWorks its Unstructured Information Management SDK ("Software Development Kit"), from whose User's Guide the previous picture came:
Unstructured information management (UIM) applications are software systems that analyze unstructured information (text, audio, video, images, etc.) to discover, organize, and deliver relevant knowledge to the user. In analyzing unstructured information, UIM applications make use of a variety of analysis technologies, including statistical and rule-based Natural Language Processing (NLP), Information Retrieval (IR), machine learning, and ontologies. IBM's UIMA is an architectural and software framework that supports creation, discovery, composition, and deployment of a broad range of analysis capabilities and the linking of them to structured information services, such as databases or search engines. The UIMA framework provides a run-time environment in which developers can plug in and run their UIMA component implementations, along with other independently-developed components, and with which they can build and deploy UIM applications.
More specifically
UIMA is an architecture in which basic building blocks called Analysis Engines (AEs) are composed in order to analyze a document. At the heart of AEs are the analysis algorithms that do all the work to analyze documents and record analysis results (for example, detecting person names). These algorithms are packaged within components that are called Annotators. AEs are the stackable containers for annotators and other analysis engines.
Unfortunately, the downloadable stuff is just a development framework -- no interesting Analysis Engines or Annotators are supplied. IBM's framework would be more likely to be widely adopted, instead of various emerging (partial) alternatives, if at least a basic set of analysis methods (and procedures for training new ones) were provided.
Another IBM banner recently raised is Autonomic Computing, featured in another recent issue of the IBM technical journal:
The development of autonomic computing will make systems capable of self-configuring, self-healing, self-optimizing, and self-protecting, analogous to the abilities of living organisms with autonomic nervous systems. In this issue, an overview, 15 papers, and the Technical Forum present concepts, directions, and current work in the evolving research on autonomic computing for such areas as systems architecture, server infrastructure, systems management, security, service, applications, and the effect on users. This issue is an initial contribution to the creation of a body of literature on autonomic computing.
Posted by Mark Liberman at December 27, 2004 02:48 PM