January 10, 2005
Rats
In reference to the rat speech perception story, David Beaver asks several good questions, including:
Are there types of pattern recognizer such that those recognizers can differentiate between certain classes of pattern they are presented with in one order, but not differentiate between those classes of pattern when presented in the reverse order?
This question has a particularly easy answer, which is obvious when you think about it. If we're talking about acoustic patterns in the natural world, then (most) such patterns share local properties that are very different from those of their time-reversed equivalents. As a result of these differences, any system that is used to encoding local acoustic properties of naturally-occurring complex sounds is likely to have trouble with time-reversed sounds. Specifically, many sound onsets have abruptly rising amplitude profiles -- bangs, pops, etc. -- while sound offsets mostly have more gradually falling amplitude profiles. This follows from the response of any resonant system (a room, a struck object, a vocal cavity) to an impulse-like excitation.
As a result, most natural sounds have very different local amplitude-contour statistics, overall or across frequency bands, from their time-reversed counterparts. You can see that in the following time waveform of the start of a bugle call:

and you can easily hear the difference (in the individual notes) between the original and time-reversed versions. Here's a short drum passage and a time-reversed version of the same file, making the same point even more strikingly. Imagine trying to learn to recognize a particular rhythmic pattern in each case...
Rats, like humans, have a lot of experience with natural sounds. Lab rats may have a fair amount of experience with human voices, but I don't think this is necessary. Any critter sensitive to the statistical properties of the signals that impinge on it -- and that means pretty much any critter at all -- will experience normal and time-reversed natural sounds in very different ways.
The fact that the signals used in (the forward vs. backward part of) this experiment were synthetic doesn't matter, since synthetic speech shares the relevant properties with natural speech.
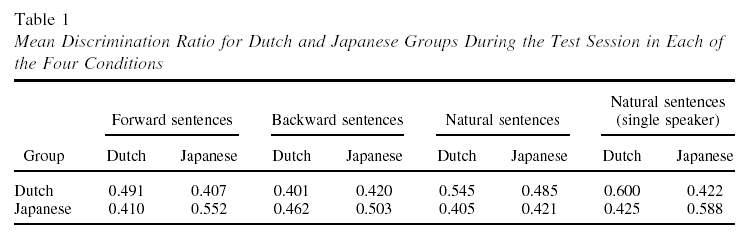
It's easy to imagine that rats find it harder to learn to distinguish patterns in locally-unnatural acoustic stimuli. And the differences in the experiment were pretty small ones. Here are the actual results from the paper:
The definition of discrimination ratio is
The discrimination ratio was calculated by dividing the mean frequency of lever pressing in the first minute (A) of the 2-min interval after each sentence by the mean responses in A plus mean responses in the second minute of this interval (C). This operation gives values between 1 and 0. Values tending to 1 indicate a higher mean response in A than in C; values tending to 0 indicate a higher mean response in C than in A.
So in the forward condition, the rats trained on Dutch had a discrimination ratio of 0.491 for Dutch test sentences, and 0.407 for Japanese test sentences. This was a statistically significant difference, but it's not exactly an impressive level of overall performance. In the backwards condition, the rats trained on Dutch had a discrimination ratio of 0.401 for Dutch test sentences, and 0.420 for Japanese test sentences.
In other words, in all cases the rats are responding very nearly randomly, but in the forwards condition they responded just a bit (about .08) more often (in the first minute vs. the second minute after hearing the sentence) to same-language test material than to the new-language test material. This marginal effect did not hold in the backwards condition, which might be because the rats were better able to encode the natural patterns, or might be because they were distracted by the unnatural patterns (you might call this the "holy sh*t, what was that?" effect).
Both sorts of explanations might have played a role here.
Posted by Mark Liberman at January 10, 2005 08:42 AM