January 24, 2005
Questioning reality
I wrote to an acquaintance at Google to ask about the odd estimates of counts in boolean queries ("goolean logic"?), and he explained that the problems are mainly due to faulty extrapolation from a sample (as I had unclearly conjectured in an earlier post) :
[T]here are small variations in the number of results due to the fact that index updates are done at different times in different data centers. But there are much larger variations due to the fact that these are all estimates, and we just haven't tried that hard to make the estimates precise. To figure out the number of results in the query [a OR b], we need to intersect two posting lists. But we don't want to pay the price of intersecting all the way to the end, so we do a prefix and then extrapolate. The extrapolation is done with the help of some parameters that were carefully tuned several years ago, but haven't been reliably updated as the index has grown and the web has changed, so sometimes the results can be off.
This also confirms Geoff Nunberg's understanding that "this is old code that is low on Google's priority list". Geoff points out that Google seems to perform boolean operations correctly for search terms whose frequency is small enough. He suggests that 1,000 (the number of hits that Google will actually show you) is a reasonable bound, and that seems like sensible advice. However, it seems that it may be possible to get accurate counts from queries with larger counts. Sometimes.
I did a bit of experimental observation with respect to the curious matter of the shrinking {X OR X} counts, as a way of uncovering some clues about the extrapolation algorithm and its performance as a function of set size. Now, the count of pages in response to a query {X OR X} should logically always be the same as the count of pages that match the query {X}. But Google's answers have a shortfall that increases systematically with frequency, although the error remains relatively small up to frequencies of 50,000 or even 100,000.
Here are some examples. {Nunberg} returns 49,500 hits, while {Nunberg OR Nunberg} returns 49,400 hits, which at an {X OR X} to {X} ratio of 0.998 is close enough.
{Hammurabi} gets 198,000 hits, but {Hammurabi OR Hammurabi} gets only 158,000, for a ratio of 0.798.
{Thomason} gets 606,000, {Thomason OR Thomason} gets 362,000, so at this point we're down to a ratio of 0.597.
{Berlusconi} get 3,250,000, and with {Berlusconi OR Berlusconi} at 1,810,000, for a ratio of 0.557.
And by the time we get way out there to {see}, at a count of 677,000,000, with {see OR see} at 60,200,000, the ratio of {X OR X} to {X} is a mere 0.090. In other words, the count for {see OR see} is less than 10% of what it should be, if the count for {see} is correct.
Here's a graph of showing the relationship for 60 words that span a range of Google counts from 40 to 677,000,000:
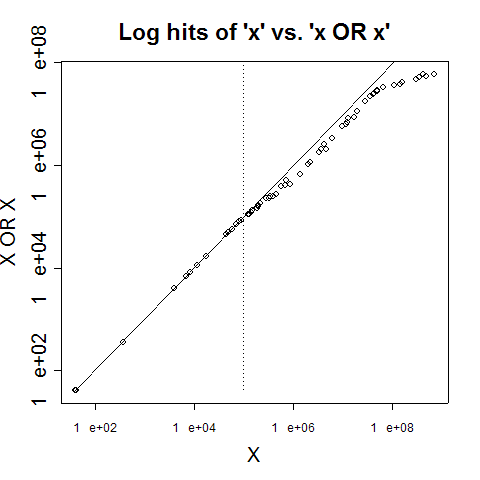
(The solid line is the x=y diagonal, and the dotted line marks x=100,000.)
Exploring a bit above {Nunberg} (which has 49,400 hits and an {X OR X}/{X} ratio of 0.998), there's aspectual at 57,600 hits and a ratio of 0.988; parterres at 67,000 and a ratio of 0.996; fidgets at 77800 and a ratio of 0.976; Wagnerian at 90,400 and a ratio of 0.988; keypresses at 105,000 and a ratio of 0.908; marquises at 136,000 and a ratio of 0.868; carjacking with 172,000 and a ratio of 0.860; and then Hammurabi (198,000 and 0.798) and on up (or down).
Exploring below {Nunberg}, cubbyhole gets 43,800 and a ratio of 1.0; cupfuls gets 27,600 and a ratio of; 1.0; Nixonian gets 24,200 and a ratio of 1.0, Johnsonian gets 14,300 and a ratio of 1.0, maniple gets 11,500 and a ratio of 1.0, embargoing gets 7,690 and a ratio of 1.0, and so on.
This suggests that whatever Google's extrapolation algorithm is, its parameters are tuned to work pretty well up to 50,000 or even 100,000 (where the dotted line is in the plot above). Or perhaps up to that point, it's doing a real intersection of pagerank-sorted lists? Of course, I don't know whether this pattern predicts the behavior of real disjunctions (i.e. those of the form X OR Y, for Y not equal to X). It would be unwise to count on it.
One check would be to look at the equation {X OR Y} = {X -Y} + {X AND Y} + {-X Y}, for {X} and {Y} as counts of {X} and {Y} rise past 50-100K.
(That is, we're comparing the (estimate of) the number of pages containing either X or Y or both, against the sum of (the estimates of) the number of pages with X but not Y, both X and Y, and Y but not X. If the two totals match, that doesn't prove that they're accurate -- but at least they're giving a consistent picture of web reality.)
{Nunberg} 49,500
{Pullum} 53,400
{Nunberg OR Pullum} 101,000
{Nunberg -Pullum} 48,000
{Nunberg AND Pullum} 484
{-Nunberg Pullum} 51,900
Checking: 101,000 against 48,000 + 484 + 51,900 = 100,384. And the {X OR X}/{X} ratios for Nunberg and Pullum are 0.998 and 0.996, respectively.
Close enough for the round-offs obviously involved -- here the extrapolation errors seem to be tolerable.
Now let's try a pairing with some larger numbers.
{Knossos} 357,000
{Minoan} 350,000
{Knossos OR Minoan} 577,000
{Knossos -Minoan} 326,000
{Knossos AND Minoan} 38,300
{-Knossos Minoan} 214,000
Checking: 577,000 against 326,000 + 38,300 + 214,000 = 578,300.
Again, within plausible estimation error bounds. But in this case, {Knossos OR Knossos} gives a count of 416,000, for an {X OR X}/{X} of 1.17 -- not a shortfall, but an overrun!
David Beaver is right: The reality of the situation is constantly in question.
Posted by Mark Liberman at January 24, 2005 06:28 AM