February 12, 2006
Top Arafat climate scientists
Hoping to find some more George Deutsch audio, I searched Podzinger for {Deutsch NASA}, and got results that set me to wondering. First, let me tell you what happened. Then I'll explain what's so striking about it.
The third item on Podzinger's first page of results was the podcast of WNUR's This is Hell for 2/4/2006, where Podzinger found the following at about 53:20 into the mp3. Podzinger's transcript is in blue, and what I heard in the original audio is in red:
last sunday there's an article in the times about the the nasa's top arafat climate scientists
last sunday uh there's an article in the times uh uh about a uh uh the nasa's top uh climate scientist
began in the thirty years and -- respected throughout the community in effect of the community
the guy that's been there thirty years uh and and is respected throughout the community uh the scientific community
You'll recall that Podzinger uses BBN automatic speech recognition (ASR) to turn podcasts into text, and then indexes the results in a roughly Googlish way. Actually, the text retrieval is probably more like the old Altavista algorithms, since there doesn't seem to be any equivalent of page rank here, but never mind... The TiH commentator has an extraordinary density of uhs for a radio personality, but Podzinger's ASR software manages to ignore the first five of them. That's 5 uhs in 15 words, by the way -- George Deutsch, agressive rises and all, is a hell of a lot more fluent than this guy.
And Podzinger's recognition of the word "NASA" is right on the money, demonstrating again that ASR-based audio indexing has gotten to the point of being really useful. Sometimes. Because then, on that sixth uh, the ASR system does something really weird. It renders "NASA's top uh climate scientist" as "nasa's top arafat climate scientists".
Now the "fundamental equation of speech recognition" says that
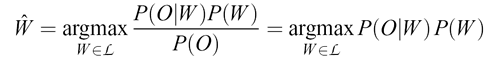
In other words, in deciding which string of Words corresponds to some Observed sound, we should pick the words that maximize (our estimate of) the conditional probability of O given W, multipliplied by the probability of W, divided by the probability of O. And since the probability of the sound -- P(O) -- is the same for all hypotheses about word strings, we can ignore it for the purpose of this decision.
We're left with a product of two terms. One term comes from an "acoustic model" that defines, for an arbitrary word string W, a probability distribution over possible stretches of sound. The other term comes from a "language model" that defines, independent of any considerations of sound at all, a probability distribution over possible word strings. In order to make it practical to create these models and to compute with them, we use pretty crude approximations. As you can see, the current state of the art nevertheless often works quite well.
(I believe that Fred Jelinek is the one who started calling this the "fundamental equation of speech recognition"; for further explanation, see Daniel Jurafsky and James Martin, "Speech and Language Processing", chap. 9, p. 47 of cited .pdf; the equation, of course, is basically just "Bayes' rule" applied to P(W|O), and Bayes' rule is either a trivial consequence of the definition of conditional probability, or one of the most profound and controversial equations in the history of mathematics, take your pick.)
When the method goes wrong, its mistakes sometimes turn out to be sensible when we look into them closely. For example, in my earlier post on Podzinger, I noted a case where the system rendered "when you said Jesus is" as "when music scene it is". Well, in the first place, these two sequences are phonetically a lot closer than you might think at first:
| w | ɛ | n |
j | u | s | ɛ | d | ʤ | i | z | ɪ | s | ɪ | z |
| w | ɛ | nm | j | u | z | ɪ | k | s | i | n | ɪ | ɾ | ɪ | z |
So it's plausible for an acoustic model to be pretty happy with the second one as a substitute for the first. And as for the language model, using counts from a corpus of 4,444,962,381 words of news text, a bigram language model estimates the sequence "when you said Jesus is" as only about 2.2 times more probable than "when music scene it is" -- as such things go, this is a dead heat.
(Using counts from MSN search, the bigrams model rates "when you said Jesus is" as 2,112 times more probable than "when music scene is". I guess this tells us that Jesus is about a thousand time more prominent on the web than in the news; and Podzinger's language model is probably based mostly on news text.)
All this doesn't predict the error, but it tells us that the error was a sensible one given the kind of model being used.
Now consider the mistake that rendered "NASA's top uh climate scientist" as "nasa's top arafat climate scientists".
It's musch harder to explain or excuse this one. We have to assume that the acoustic model was happy to regard this cough-like uh as a probable rendition of "Arafat" -- this is not the behavior of a healthy and effective stochastic model of the sound of the English language. And we also have to assume that the n-grams involved in "nasa's top arafat climate scientists" were estimated to be probable enough to yield a good language-model score for this string.
Now, I can't imagine that anyone faced with a cloze test based on a text like
NASA's top ___ climate scientist
would think to answer "Arafat" as a candidate to fill in the blank. And counts from MSN support this impression, yielding estimates like
P(Arafat | top) = 1.7*10^-6
P(climate | Arafat) = 1.3*10^-6
where by comparison, for example,
P(scene | music) = 5.2*10^-3
P(climate | top) = 6.7*10^-5
P(scientist | climate) = 2.7*10^-3
P(scientists | climate) = 3.9*10^-3
Of course, bigram statistics are a crude measure of what is or isn't plausible English; and people are capable of producing and perceiving very implausible word sequences. But in terms of its own simple-minded models, it's hard to understand why Podzinger mapped uh to Arafat in this context. (Unless maybe its language-modeling materials were unnaturally enriched in strings like "top Arafat aide" and "post-Arafat climate"?) I'm sorry to say that ASR error analysis is not infrequently like this -- I wish there were a clear path to a class of models that would make more lifelike, or at least more coherent, mistakes.
Posted by Mark Liberman at February 12, 2006 08:10 AM