February 27, 2006
Pornometry and the Slut-o-meter
 Jean Véronis has recently carried out two short studies in pornometry (one and two). The data comes from counting web hits with and without Google's SafeSearch (or similar porn filters) turned on. The ratio for different words varies quite a bit, which forms the basis of the Slut-o-meter created by Joël Franusic and Adam Smith. This is a frivolous little web app that evaluates "promiscuity" based on a formula that they give as
Jean Véronis has recently carried out two short studies in pornometry (one and two). The data comes from counting web hits with and without Google's SafeSearch (or similar porn filters) turned on. The ratio for different words varies quite a bit, which forms the basis of the Slut-o-meter created by Joël Franusic and Adam Smith. This is a frivolous little web app that evaluates "promiscuity" based on a formula that they give as
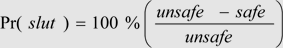
Jean was tickled to find that his last name rates a spectacular 61.94% on the Slut-o-meter. In contrast, for example, "Pullum" rates only 6.82%, "Liberman" an even stodgier 4.61%, "Zwicky" is a positively demure 4.35%, and "Thomason" is the lowest I've had time to try, at 1.16% -- though the authors of the Slut-o-meter observe that negative values are sometimes encountered:
If you're wondering why some subjects have a negative promiscuity, well, you're not alone. In general, this happens when the number of safe results is greater than the number of unsafe results (or if there are no unsafe results whatsoever). We're not quite sure why this is the case, but we believe that Google is not telling us the truth.
Google finds 628,000 hits for {"language log"} without SafeSearch, and 620,000 with it, for a rating of 1.27%, while {"language hat"} is slightly racier at (418000-395000)/418000 = 5.5%.
Jean's investigations are more serious, using these counts as a (narrow but meaningful) window on the continuing war between black-hack SEOs and search engines. The high number for "Veronis" requires some special explanation, but it's broadly in tune with a trend that Jean observes for Google (and other American-based search engines) to filter a larger percentage of non-English (well, anyway French) pages. Jean's explanation:
Posted by Mark Liberman at February 27, 2006 06:56 PMIt seems to me that the explanation for these differences is twofold. Firstly, the search engines undoubtedly go too far: since they are unable to work with the level of delicacy required (it’s difficult, I admit!), they have a tendency to overfilter, perhaps using criteria that go beyond simple lexis (as is clearly the case for the European Constitution with Google). This is a general trend, particularly with Google: under pressure from the web-surfing public, filters were put in place very quickly, and apparently, the only way to make a filter work without a particularly discriminating linguistic technology behind it is to bring out the biggest ladle you can find and skim off a lot more than just the cream. I have mentioned this type of problem before when discussing splogs (here and here).
The other part of the explanation comes from the fact that, in terms of linguistic competences, the different search engines vary considerably. I’ve already had cause to mention that Google doesn’t seem to be very good at handling languages other than English (for instance here). The results above would seem to confirm this. Conversely, we can see how Exalead, which is a French search engine, is better with French than with English. Yahoo! is more or less stable from one language to the other.