April 12, 2006
The shape of a spoken phrase
 This is a fragment of a work in progress. Jiahong Yuan, Chris Cieri and I have been exploring the ways that speech rate is affected by who you are, what you're talking about, who you're talking to, what language you're speaking, what setting you're in, how you feel about it all, and so forth.
This is a fragment of a work in progress. Jiahong Yuan, Chris Cieri and I have been exploring the ways that speech rate is affected by who you are, what you're talking about, who you're talking to, what language you're speaking, what setting you're in, how you feel about it all, and so forth.
One of the many relevant factors is phrase length: other things equal, shorter phrases tend to be slower. This is mainly because spoken phrases, like musical phrases, unfold in a characteristic way, with a small initial accelerando and a larger final ritard. Short phrases start the final slow-down before they have a chance to speed up; longer phrases have increasingly large proportions of more rapidly-spoken words. As part of an effort to document and model this effect -- so as to be able to normalize it away, among other things -- I did a simple analysis of a small published corpus of English conversational telephone speech. The results are very pretty.
The collection that I used is commonly known as Switchboard. It was recorded at Texas Instruments in 1990-1, originally for use in a speaker-identification study, and has been distributed by the LDC since 1992. The transcripts and time-stamps were corrected at Mississippi State a few years later, and the version that I used can be downloaded here. There are 2,438 conversations, or 4,876 conversational sides.
The transcripts are available in two forms. One set of files divides each conversational side into segments convenient for human transcription or reading. Another set of files assigns a start-time and end-time to every individual word. A (fragment of a) conventional transcript of one of these conversations might look like this:
A: Um yeah I'd like to talk about how you dress for work and and um what do you normally what type of outfit do you normally have to wear?
B: Well I work in uh corporate control, so we have to dress kind of nice, so I usually wear skirts and sweaters in the winter time, slacks I guess [noise] and in the summer just dresses.
But the performed phrasing of conversational speech is not notated in a conventional transcript. One easy-to-see symptom of performed phrasing is the introduction of silent pauses, as shown in the word-by-word time-stamped version of A's turn:
sw2001A-ms98-a-0002 1.724625 2.273625 [silence]
sw2001A-ms98-a-0002 2.273625 2.927625 um
sw2001A-ms98-a-0002 2.927625 3.221500 [silence]
sw2001A-ms98-a-0002 3.221500 3.661750 yeah
sw2001A-ms98-a-0002 3.661750 3.957625 i'd
sw2001A-ms98-a-0002 3.957625 4.107625 like
sw2001A-ms98-a-0002 4.107625 4.267625 to
sw2001A-ms98-a-0002 4.267625 4.527625 talk
sw2001A-ms98-a-0002 4.527625 4.941625 about
sw2001A-ms98-a-0002 4.941625 5.126125 [silence]
sw2001A-ms98-a-0002 5.126125 5.307625 how
sw2001A-ms98-a-0002 5.307625 5.437625 you
sw2001A-ms98-a-0002 5.437625 5.735375 dress
sw2001A-ms98-a-0002 5.735375 5.901125 [silence]
sw2001A-ms98-a-0002 5.901125 6.077625 for
sw2001A-ms98-a-0002 6.077625 6.477625 work
sw2001A-ms98-a-0002 6.477625 6.817625 and
sw2001A-ms98-a-0002 6.817625 7.217625 and
sw2001A-ms98-a-0002 7.217625 7.523125 um
sw2001A-ms98-a-0002 7.523125 7.677500 [silence]
sw2001A-ms98-a-0002 7.677500 7.777625 what
sw2001A-ms98-a-0002 7.777625 7.867625 do
sw2001A-ms98-a-0002 7.867625 7.967625 you
sw2001A-ms98-a-0002 7.967625 8.624625 normally
sw2001A-ms98-a-0002 8.624625 8.797625 what
sw2001A-ms98-a-0002 8.797625 9.067625 type
sw2001A-ms98-a-0002 9.067625 9.307625 of
sw2001A-ms98-a-0002 9.307625 9.707625 outfit
sw2001A-ms98-a-0002 9.707625 9.777625 do
sw2001A-ms98-a-0002 9.777625 9.847625 you
sw2001A-ms98-a-0002 9.847625 10.237625 normally
sw2001A-ms98-a-0002 10.237625 10.397625 have
sw2001A-ms98-a-0002 10.397625 10.547625 to
sw2001A-ms98-a-0002 10.547625 10.961250 wear
sw2001A-ms98-a-0002 10.961250 11.561375 [silence]
Similarly, t he word-by-word version of B's turn is:
sw2001B-ms98-a-0003 10.166375 10.764125 [silence]
sw2001B-ms98-a-0003 10.764125 11.189250 well
sw2001B-ms98-a-0003 11.189250 11.302250 i
sw2001B-ms98-a-0003 11.302250 11.496375 work
sw2001B-ms98-a-0003 11.496375 11.676375 in
sw2001B-ms98-a-0003 11.676375 11.846375 uh
sw2001B-ms98-a-0003 11.846375 12.326375 corporate
sw2001B-ms98-a-0003 12.326375 12.866375 control
sw2001B-ms98-a-0003 12.866375 13.096375 so
sw2001B-ms98-a-0003 13.096375 13.186375 we
sw2001B-ms98-a-0003 13.186375 13.346375 have
sw2001B-ms98-a-0003 13.346375 13.456375 to
sw2001B-ms98-a-0003 13.456375 13.706375 dress
sw2001B-ms98-a-0003 13.706375 13.946375 kind
sw2001B-ms98-a-0003 13.946375 14.006375 of
sw2001B-ms98-a-0003 14.006375 14.518000 nice
sw2001B-ms98-a-0003 14.518000 15.104500 [silence]
sw2001B-ms98-a-0003 15.104500 15.316375 so
sw2001B-ms98-a-0003 15.316375 15.386375 i
sw2001B-ms98-a-0003 15.386375 15.656375 usually
sw2001B-ms98-a-0003 15.656375 15.946375 wear
sw2001B-ms98-a-0003 15.946375 16.366375 skirts
sw2001B-ms98-a-0003 16.366375 16.861875 and
sw2001B-ms98-a-0003 16.861875 17.614875 sweaters
sw2001B-ms98-a-0003 17.614875 18.066875 [silence]
sw2001B-ms98-a-0003 18.066875 18.216375 in
sw2001B-ms98-a-0003 18.216375 18.286375 the
sw2001B-ms98-a-0003 18.286375 18.578375 winter
sw2001B-ms98-a-0003 18.578375 19.105750 time
sw2001B-ms98-a-0003 19.105750 19.401500 [silence]
sw2001B-ms98-a-0003 19.401500 19.936375 slacks
sw2001B-ms98-a-0003 19.936375 20.009500 i
sw2001B-ms98-a-0003 20.009500 20.405625 guess
sw2001B-ms98-a-0003 20.405625 21.125000 [noise]
sw2001B-ms98-a-0003 21.125000 21.236375 and
sw2001B-ms98-a-0003 21.236375 21.346375 in
sw2001B-ms98-a-0003 21.346375 21.406375 the
sw2001B-ms98-a-0003 21.406375 21.766375 summer
sw2001B-ms98-a-0003 21.766375 21.986375 just
sw2001B-ms98-a-0003 21.986375 22.468125 dresses
sw2001B-ms98-a-0003 22.468125 22.813500 [silence]
Silent pauses are not the only symptom of conversational phrasing, but they're a relatively straightforward and intersubjectively stable indicator. If we defined the conversational phrases to be the stretches between silent pauses, in the quoted exchange we get
| A: | um yeah i'd like to talk about how you dress for work and and um what do you normally what type of outfit do you normally have to wear |
| B: | well i work in uh corporate control so we have to dress kind of nice so i usually wear skirts and sweaters in the winter time slacks i guess and in the summer just dresses |
By this definition, the Switchboard corpus contains 519,598 "performed phrases".
I categorized each "phrase", in this sense, according to the number of "words" in it. (I called every transcribed token a word, including ums and uhs and partial words and so on, but not including things transcribed as "[noise]".) Printed out as one phrase per line, with the duration of each word following it, the result looks like this.
1 um 0.654
6 yeah 0.440 i'd 0.296 like 0.150 to 0.160 talk 0.260 about 0.414
3 how 0.182 you 0.130 dress 0.298
5 for 0.177 work 0.400 and 0.340 and 0.400 um 0.306
14 what 0.100 do 0.090 you 0.100 normally 0.657 what 0.173 type 0.270 of 0.240 outfit 0.400 do 0.070 you 0.070 normally 0.390 have 0.160 to 0.150 wear 0.414
15 well 0.425 i 0.113 work 0.194 in 0.180 uh 0.170 corporate 0.480 control 0.540 so 0.230 we 0.090 have 0.160 to 0.110 dress 0.250 kind 0.240 of 0.060 nice 0.512
7 so 0.212 i 0.070 usually 0.270 wear 0.290 skirts 0.420 and 0.496 sweaters 0.753
4 in 0.150 the 0.070 winter 0.292 time 0.527
9 slacks 0.535 i 0.073 guess 0.396 and 0.111 in 0.110 the 0.060 summer 0.360 just 0.220 dresses 0.482
Now for each possible phrasal word count, I averaged the duration of the words in each position of all the phrases of that size. (Of course, what I mean is that I wrote a little computer program to do this.)
For example, there were 41,578 phrases of length 3. The words in the first position of these 3-word phrases had an average duration of 0.259877 seconds; in the second position, the average was 0.267758 seconds; in the final position, the average was 0.393747 seconds.
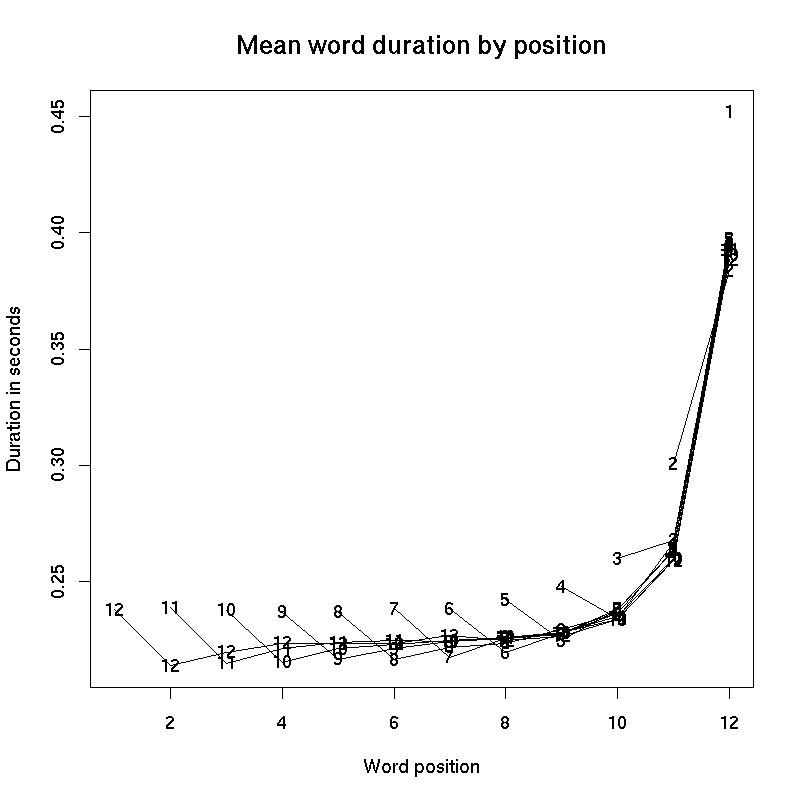
If we plot these position-wise average durations for phrases from length 1 to length 12, lined up so that all the first-position words are in the same place, we get a plot like this:
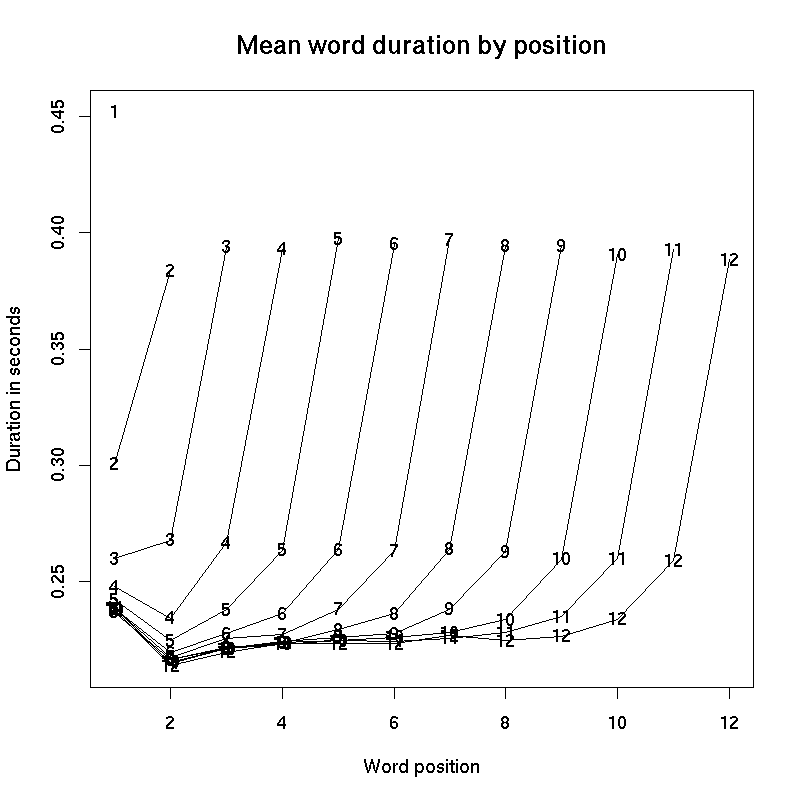
Another option is to line up the phrase lengths so that the final positions correspond. This makes the pattern easier to see, in my opinion, since the phrase-final modulation of timing is larger than the phrase-initial modulation:
There's nothing special about the number 12, in this case -- the longer phrases look just as you would expect. I kept the plot to lengths 12 and below to keep the plot from getting too busy.
Here's a table of the numbers from the plot.
[count] |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
|
| 1 | 151,995 |
0.452 | |||||||||||
| 2 | 59,260 |
0.300 | 0.384 | ||||||||||
| 3 | 41,578 |
0.260 | 0.268 | 0.394 | |||||||||
| 4 | 35,483 |
0.248 | 0.234 | 0.267 | 0.393 | ||||||||
| 5 | 31,891 |
0.242 | 0.225 | 0.238 | 0.264 | 0.397 | |||||||
| 6 | 28,545 |
0.238 | 0.219 | 0.228 | 0.236 | 0.264 | 0.395 | ||||||
| 7 | 25,388 |
0.238 | 0.217 | 0.225 | 0.227 | 0.238 | 0.263 | 0.397 | |||||
| 8 | 22,386 |
0.237 | 0.217 | 0.222 | 0.224 | 0.229 | 0.236 | 0.264 | 0.394 | ||||
| 9 | 19,306 |
0.237 | 0.217 | 0.221 | 0.224 | 0.226 | 0.228 | 0.238 | 0.263 | 0.394 | |||
| 10 | 16,485 |
0.238 | 0.215 | 0.221 | 0.223 | 0.225 | 0.226 | 0.228 | 0.234 | 0.260 | 0.391 | ||
| 11 | 14,155 |
0.239 | 0.215 | 0.221 | 0.224 | 0.225 | 0.225 | 0.226 | 0.228 | 0.235 | 0.260 | 0.393 | |
| 12 | 12,124 |
0.238 | 0.214 | 0.220 | 0.224 | 0.223 | 0.223 | 0.227 | 0.225 | 0.227 | 0.234 | 0.259 | 0.388 |
There's a lot more to say, but for now I'll just end with this. The duration of any particular spoken word depends on many things -- how many syllables are in it, and what kind of vowels and consonants make them up; how emphatically it's pronounced; the dialect and speaker and style of speech; the process of selecting the next word; and on and on. But in this case, we've averaged across all sorts of values for all of these factors in every position of every phrase length, and so what is left to see is the shape of the spoken phrase itself.
Because very large collections of transcribed speech are now available -- Switchboard is small by modern standards -- it's become easy to let the Law of Large Numbers reveal the latent structure of speech. This is a great time to be a scientist.
Posted by Mark Liberman at April 12, 2006 12:06 AM