May 30, 2006
Rhythms of the blogosphere
Last year ("Language: the anti-beer?" 4/23/2005) I mentioned something that's obvious to anyone who tries blogpulse -- the blogosphere, like the ocean, has rhythms on several different time scales. Comparing, say, "paper" and "movie", we can see an inverse correlation at two of these scales:
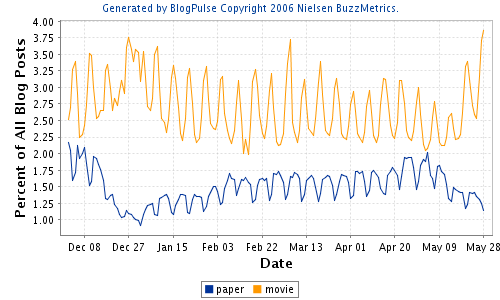
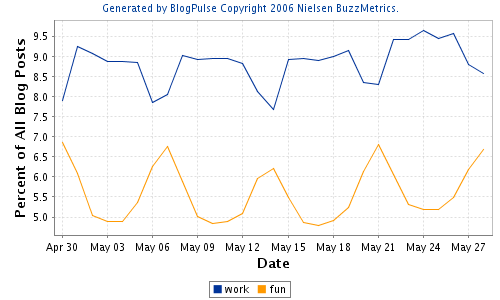
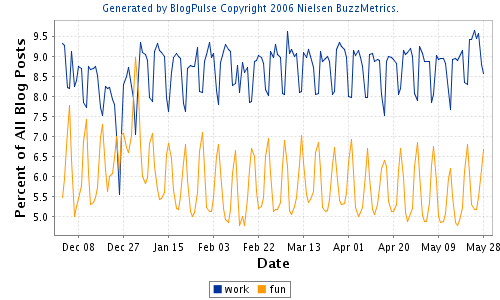
There's a week-vs.-weekend pulse, which we can also see in pairs like "work" vs. "fun":
And in the case of "paper" and "movie" there's also a semester-sized rhythm, with an decrease of school-related concerns relative to leisure during the Christmas break, and an increase at the end of the spring semester -- and then there's the leading edge of the summer holidays.
The same sort of rhythms are apparent in Language Log's visits and page views. Language Log's weekly rhythms traditionally correlate, alas, with "work" as opposed to "fun" -- up during the week, down on the weekends (ignore the fractional-day numbers for today, May 30):
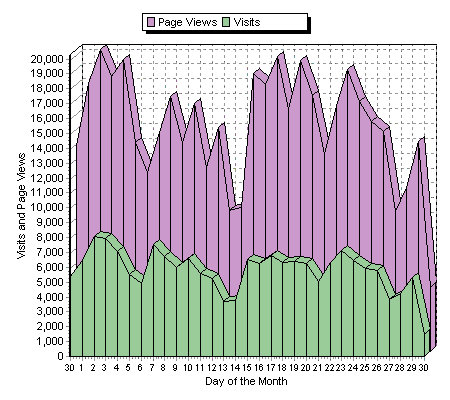
The weekend of May 21 was something of an exception, due to traffic associated with the opening of The Da Vinci Code.
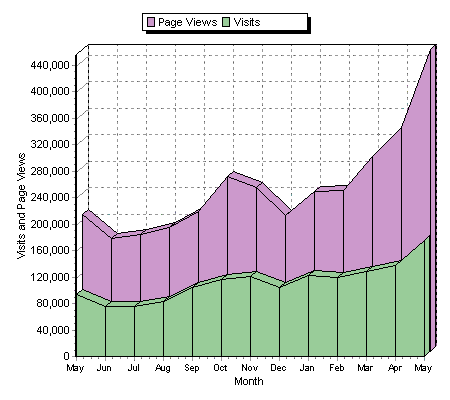
On a larger time scale, we can see the (negative) effect of holidays superimposed on a general positive trend:
Not all words in the blogosphere resonate to the semesterly rhythm: "work" vs. "fun" seems to show the more local effect of grown-up holidays:
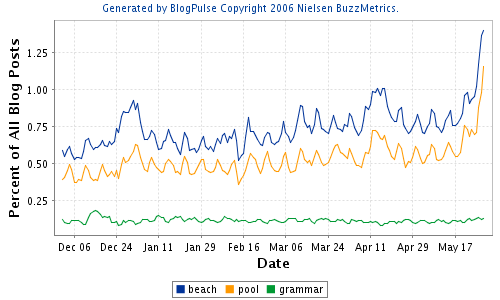
Down in the Language Log marketing department, Arnold Zwicky keeps yelling "come on, enough with the lexicostatistics and grammar already, it's after Memorial Day, we need more movie reviews and travel features!"
Temporarily ignoring this sensible prescription, I'll observe that there's an opportunity here for some interesting lexico-temporal hacking. "Latent Semantic Analysis" and similar techniques find useful relations among words based on the eigenstructure of a term-by-document matrix; does adding the dimension of time contribute anything that is not already implicit in the distribution of words across (atemporal) documents? There are some large weblog and webforum databases where this could be explored.
[Update -- Bob Carpenter emailed a pointer to Krisztian Balog and Maarten de Rijke, " Decomposing Bloggers' Moods", 3rd Annual Workshop on the Weblogging Ecosystem: Aggregation, Analysis and Dynamics (at WWW 2006). This paper applies ARIMA time-series analysis to "20 million mood-annotated blog posts harvested between June 2005 and March 2006". The authors draw four conclusions:
(i) there is a clear overall decline in the usage of mood annotations; (ii) weather phenomena and holidays have a clear impact on the profile of some moods; (iii) looking at the relative counts, we observe that some moods are stationary, while others decline or climb; and (iv) several moods display changes in their cyclical or seasonal component during the period covered by our data.
This seems both plausible and interesting, but it's not what I was suggesting. My idea was that by modeling word-co-occurrence data relative to significant periodicities, such as weekly or seasonal rhythms, you could learn something about the distributional implications of word content beyond what would emerge only from considering a-temporal co-occurrences.]
Posted by Mark Liberman at May 30, 2006 09:38 AM