September 20, 2006
Powarrr law
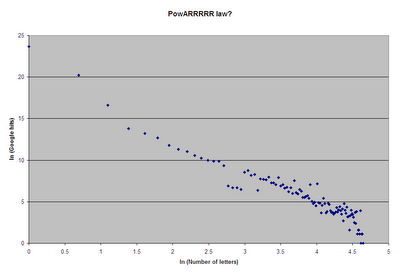
BZ at Mah Rabu takes a mathematical look at the distribution of (the number of) Rs in textual renditions of AR+ on the internets:
Language Log welcomes this addition to a specialized but fascinating literature, where we're pround of our small but pioneering contributions:
"Helpful Google" (11/29/2003)
"The memetic phylogency of 'our new * overlords'" (1/30/2004)
"Conservation of (orthographic) gemination" (3/29/2004)
"The perils of degemination" (3/29/2004)
"Jeniffer afficionados" (3/30/2004)
"Orthographic metathesis?" (4/1/2004)
"The mysteries of ... what's his name?" (4/21/2004)
"Lamkin Perbeck, pretender" (4/22/2004)
"AW+" (4/29/2004)
"AW++" (5/8/2004)
"(Mis)spelling Gandhi" (6/2/2004)
"Conservation of gemination: another example" (6/7/2004)
"Liberal gemination" (6/8/2004)
One comment on the "future directions" part of BZ's post:
One unexplained phenomenon is the dearth of Google hits for 16 to 19 R's, only to return to the regular pattern with 20 and above. This provides new and exciting directions for further research in the field.
What do you want to bet that it tells us something about Google's indexing, search and count-approximation algorithms, rather than something about the behavior of piratical writers out there on the internets?
[Hat tip: Josh Rosenberg]
[Update -- Bill Poser suggests:
The dearth of strings of 16-19 Rs is no doubt due to the fact that this is a neighborhood of 17, well known for its randomness. Obviously there is no information to be gained from a random phenomenon.
]
[And Cosma Shalizi cites Dennis Chao and Patrik D'haeseleer, "The Distribution of Variable-length Phatic Interjectives on the World Wide Web", UNM Computer Science Department Tech Report TR-CS-2001-23.]
Posted by Mark Liberman at September 20, 2006 11:17 AM