October 27, 2006
Envy, navy, whatever
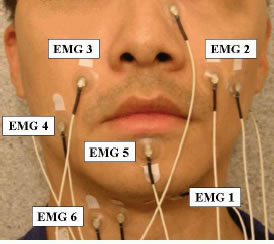 Consider the lead of a recent story by Celeste Biever, "It's the next best thing to a Babel fish", New Scientist, 10/26/2006 :
Consider the lead of a recent story by Celeste Biever, "It's the next best thing to a Babel fish", New Scientist, 10/26/2006 :
Imagine mouthing a phrase in English, only for the words to come out in Spanish. That is the promise of a device that will make anyone appear bilingual, by translating unvoiced words into synthetic speech in another language.
The device uses electrodes attached to the face and neck to detect and interpret the unique patterns of electrical signals sent to facial muscles and the tongue as the person mouths words. The effect is like the real-life equivalent of watching a television show that has been dubbed into a foreign language, says speech researcher Tanja Schultz of Carnegie Mellon University in Pittsburgh, Pennsylvania.
Existing translation systems based on automatic speech-recognition software require the user to speak the phrase out loud. This makes conversation difficult, as the speaker must speak and then push a button to play the translation. The new system allows for a more natural exchange. "The ultimate goal is to be in a position where you can just have a conversation," says CMU speech researcher Alan Black.
You might not guess from this -- or from the rest of the article -- that (a) the cited research does not make any contribution to automatic translation, but rather simply attempts to accomplish practical speech recognition in a single language from surface EMG signals rather than from a microphone; (b) the (monolingual) recognition error rates from EMG signals are now at least an order of magnitude worse than from microphone input, yielding from 20-40% word errors even on simple tasks with very limited vocabularies (16 to 108 words); (c) there are significant additional problems, including signal instability from variable electrode placement, which would cause performance in real applications to be much worse, and for which no solution is now known.
Several other news sources have picked up this story: (BBC news) "'Tower of Babel' translator made"; (BBC Newsround) "Instant translator on its way"; (inthenews.co.uk) "Device promises ability 'to speak in tongues'"; AHN: "Language Translator Being Developed by U.S. Scientists". (Discovery Channetl) "Scientists one step closer to Star Trek's 'universal translator'". As is often the case, the BBC will probably be the vector by which this particular piece of misinformation infects the world's news media. (See this link for an earlier example.) Especially interesting are the staged (or stock) photographs, with no visible wires, which the BBC chose to use to illustrate its stories (compare the picture above, which comes from one of the CMU researchers' papers):
 |
 |
Now the quoted people from CMU -- Tanja Schultz and Alan Black -- are first-rate speech researchers. I was at CMU 10 days ago, giving a talk in the statistics department, and I spent a fascinating hour learning about some of Alan Black's current work in speech synthesis. (I should really be telling you about that. Why have I let myself be tempting into cutting another head off of the science-journalism hydra? This is the occupational disease of blogging, I guess.) And Tanja and Alan really are involved in a team that has been doing great work on the (very hard) problem of speech-to-speech translation.
But these news stories -- like most science reporting in the popular press -- are basically fiction. This is not as bad as the cow-dialect story, in that there is actually some science and engineering behind it, not just a PR stunt. However, these stories give readers a sense of where the research team would like to get to, but no sense whatever of where the technology is right now, what contributions the recent research makes, and what the remaining problems and prospects are. It doesn't surprise me that the BBC uses the occasion as an inspiration for free-form fantasizing, but it's disappointing that New Scientist couldn't do better.
For those of you who care what the facts of the case are, here's a summary of two recent papers by the CMU group, along with links to the papers themselves.
The first one is Szu-Chen Jou, Tanja Schultz, Matthias Walliczek, Florian Kraft, and Alex Waibel, "Towards Continuous Speech Recognition Using Surface Electromyography", International Conference of Spoken Language Processing (ICSLP-2006), Pittsburgh, PA, September 2006.
This paper points out the first big challenge here:
EMG signals vary a lot across speakers, and even across recording sessions of the very same speaker. As a result, the performances across speakers and sessions may be unstable.
The main reason for variability across sessions is that the signals depend on the exact positioning of the electrodes. The CMU researchers didn't tried to solve this problem, but instead avoided it:
To avoid this problem and to keep this research in a more controlled configuration, in this paper we report results of data collected from one male speaker in one recording session, which means the EMG electrode positions were stable and consistent during this whole session.
The goal of the research reported in this paper was to compare the performance in EMG-based speech recognition of different sorts of signal processing. It's worth mentioning that more is required here than just to "simply attach some wires to your neck", as one of the BBC stories puts it:
The six electrode pairs are positioned in order to pick up the signals of corresponding articulatory muscles: the levator angulis oris (EMG2,3), the zygomaticus major (EMG2,3), the platysma (EMG4), the orbicularis oris (EMG5), the anterior belly of the digastric (EMG1), and the tongue (EMG1,6) [3, 6]. Two of these six channels (EMG2,6) are positioned with a classical bipolar configuration, where a 2cm center-to-center inter-electrode spacing is applied. For the other four channels, one of the electrodes is placed directly on the articulatory muscles while the other electrode is used as a reference attaching to either the nose (EMG1) or to both ears (EMG 3,4,5). [...]
Even so, they apparently needed to place eight electrodes to get six usable signals:
...we do not use EMG5 in our final experiments because its signal is unstable, and one redundant electrode channel ... has been removed because it did not provide additional gain on top of the other six.
The recognition task was not a very hard one:
The speaker read 10 turns of a set of 38 phonetically-balanced sentences and 12 sentences from news articles. The 380 phonetically-balanced utterances were used for training and the 120 news article utterances were used for testing. The total duration of the training and test set are 45.9 and 10.6 minutes, respectively. We also recorded ten special silence utterances, each of which is about five seconds long on average. [...]
So the test set was ten repetitions of each of 12 sentences. To make it easier, they limited the decoding vocabulary to the 108 words used in those 12 sentences:
Since the training set is very small, we only trained context-independent acoustic models. Context dependency is beyond the scope of this paper. The trained acoustic model was used together with a trigram BN language model for decoding. Because the problem of large vocabulary continuous speech recognition is still very difficult for the state-of-the-art EMG speech processing, in this study, we restricted the decoding vocabulary to the words appearing in the test set. This approach allows us to better demonstrate the performance differences introduced by different feature extraction methods. To cover all the test sentences, the decoding vocabulary contains 108 words in total. Note that the training vocabulary contains 415 words, 35 of which also exist in the decoding vocabulary.
The baseline system that they adapted to use surface EMG signals as input wa the Janus Recognition Toolkit (JRTk)
The recognizer is HMM-based, and makes use of quintphones with 6000 distributions sharing 2000 codebooks. The baseline performance of this system is 10.2% WER on the official BN test set (Hub4e98 set 1), F0 condition.
That's the published 1998 HUB4 evaluation data set and one of the conditions specified in this evaluation plan. They don't report how well their baseline acoustic recognizer did on the task they posed for the surface-EMG recognizer. Given that the acoustic system that has only a 10.2% Word Error Rate on a task with multiple unknown speakers and unlimited vocabulary, my guess is that in a speaker-trained test on sentences containing 108 words known in advance, its performance should be nearly perfect.
How did the surface-EMG-based recognizer do? It depended on the signal-processing method used, which was the point of the research. Here's the summary graph:
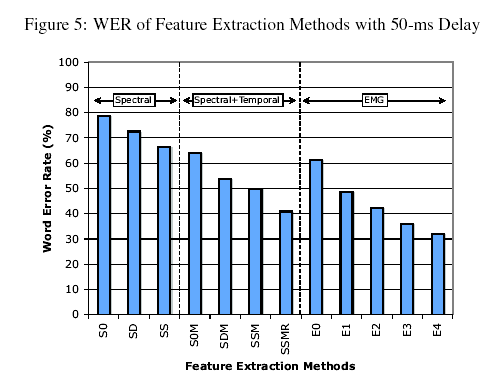
The underlying input in all cases was the set of signals coming from the surface EMG electrodes. The different bars represent the error rates given different kinds of signal processing applied to these signals. The details of the signal-processing alternatives are interesting (read the paper if you like that sort of thing, as I do), but the differences are not relevant here -- the point is that the best method they could find, adapted to the particular electrode placements of this experiment on this speaker, with decoding limited to the exact 108 words in the test set, had a word error rate of a bit over 30%.
What this shows, obviously, is that speech recognition from surface EMG signals is indeed a research problem.
Here's the second paper: Matthias Walliczek, Florian Kraft, Szu-Chen Jou, Tanja Schultz, and Alex Waibel, "Sub-Word Unit based Non-audible Speech Recognition using Surface Electromyography", (ICSLP-2006), Pittsburgh, PA, September 2006.
This paper looks at a variety of alternative unit choices for EMG-based speech recognition: words, syllables, phonemes.
To do this, the researchers
... selected a vocabulary of 32 English expressions consisting of only 21 syllables: all, alright, also, alter, always, center, early, earning, enter, entertaining, entry, envy, euro, gateways, leaning, li, liter, n, navy, right, rotating, row, sensor, sorted, sorting, so, tree, united, v, watergate, water, ways. Each syllable is part of at least two words so that the vocabulary could be split in two sets each consisting of the same set of syllables.
This time they used two subjects, one female and one male, and recorded five sessions for each speaker. Some limitations were imposed to make the task easier (for the algorithms, not for the speakers):
In each recording session, twenty instances of each vocabulary word and twenty instances of silence were recorded nonaudible. ... The order of the words was randomly permuted and presented to the subjects one at a time. A push-to-talk button which was controlled by the subject was used to mark the beginning and the end of each utterance. Subjects were asked to begin speaking approximately 1 sec after pressing the button and to release the button about 1 sec after finishing the utterance. They were also asked to keep their mouth open before the beginning of speech, because otherwise the muscle movement pattern would be much different whether a phoneme occurs at the beginning or the middle of a word.
The first phase of testing compared the performance of the different unit sizes and features:
First the new feature extraction methods were tested. Therefore, all recordings of each word were split into two equal sets, one for training and the other for testing. This means that each word of the word list was trained on half of the recordings and tested on the other half. After testing sets were swapped for a second iteration. All combinations of the new feature extraction methods were tested, a window size of 54 ms and 27 ms, with and without time domain context feature. We tested the different feature sets on a word recognizer, a recognizer based on syllables as well as phonemes.
The results?
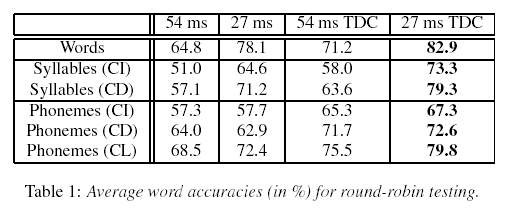
In other words, a speaker-dependent isolated-word recognition system, with a 32-word vocabulary, had a word error rate of about 20% using EMG signals as input. Again, the researchers don't tell us what a state-of-the-art acoustic system would do on this task -- my prediction would be an error rate in the very low single digits, roughly an order of magnitude lower than the error rate of the EMG system. Again, a demonstration that EMG-based recognition is a hard research problem -- much further from solution than an acoustically-based speech recognition, which is not an entirely solved problem either, as far as that goes.
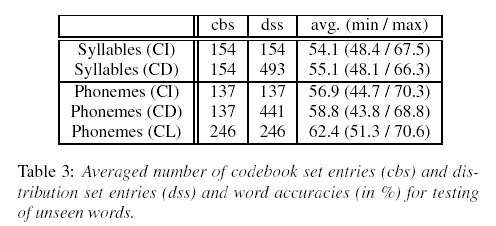
The researchers then went ahead and tried a harder problem -- using the subword units to test words not in the training set:
While in the previous tests seen words were recognized, we test in this section on words that have not been seen in the training (unseen words). Therefore, the vocabulary was split into two disjoint sets, one training and one test set. The words in the test set consist of the same syllables as the words in the training set, so that all phonemes and syllables could be trained. For an acoustic speech recognition system training of phonemes allow the recognition of all combinations of these phonemes and so the recognition of all words consisting of these combinations. This test investigates whether EMG speech recognition performs well for context sizes used in ASR or whether the context is much more important and goes beyond triphones. To do so we tested both a phoneme based system and a syllable based system. While the syllable based system covers a larger context, the phoneme based system can obtain more training data per phoneme.
As expected, the results on unseen words were considerably worse -- around 40% word error rate on a 16-word vocabulary:
Here's the confusion matrix:
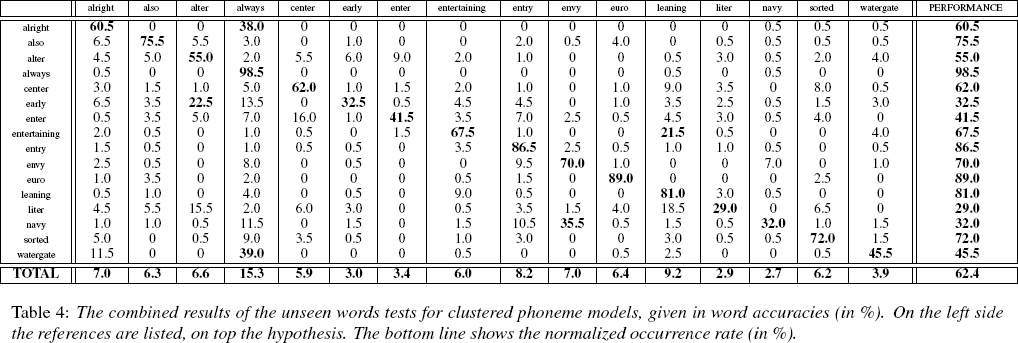
The researchers comment:
From the mapping between phonemes and muscle movements we derived that the muscle movement pattern for vocalizing the words navy and envy are quite similar (except the movement of the tongue, which is only barely detected using our setup). So the word envy is often falsely recognized as the word navy.
In an unlimited-vocabulary system, this effect will be multiplied many-fold -- leaving out the issues of stable electrode placement and acquisition of adequate training data. It's obvious that more research is needed, to say the least, before this system could be the front end to a communicatively effective conversational translation system.
[As I read the papers, the cited experiments don't test the EMG from subvocalizing -- silently mouthing words, much less thinking about silently mouthing words -- but rather the EMG generating while speaking out loud. I believe that EMG from subvocalizing will be more variable and thus harder to recognize. How much of a problem this might turn out to be is unclear.]
[Update -- Julia Hockenmaier writes, in respect to the New Scientist:
My flatmate in Edinburgh had a subscription, so I used to read this over breakfast. I don't recall ever seeing a computer-science/AI related article that didn't seem like complete fiction...
Oh well, I guess I was fooled by the packaging into thinking that this is a publication that takes science (and engineering) reporting seriously.]
[Update #2 -- Blake Stacey writes:
This may be germane to the recent talk around Language Log Plaza about New Scientist magazine, and in particular to Julia Hockenmaier's comment posted in the update. Recently, New Scientist drew a hefty amount of flak from the physics community for their reportage on the "EmDrive", the latest in a long series of machines which promise easy spaceflight at the slight cost of violating fundamental laws of nature. First to criticize the magazine was the science-fiction writer Greg Egan, whose open letter can be found here:
http://golem.ph.utexas.edu/category/2006/09/a_plea_to_save_new_scientist.html
The events which followed may be of interest to those who study how disputes unfold on the Internet. Since the discussion spread erratically around the blogosphere (touching also upon New Scientist's Wikipedia page), it is difficult to get the whole story in one place. I wrote up my perspective on the incident at David Brin's blog:
http://davidbrin.blogspot.com/2006/10/architechs-terrific-and-other-news.html
(Unfortunately, the Blogspot feature for linking directly to comments appears to be broken.)
]
Posted by Mark Liberman at October 27, 2006 06:25 AM