Here in Anaheim at this year's Secret Cabal of the Linguistic Elite, otherwise known as the annual meeting of the Linguistic Society of America, the seers and acolytes are bartering all sorts of fascinating arcana. One that caught my eye was a presentation by Cati Brown, Tony Snodgrass, Michael Covington, Susan Kemper and Ruth Herman, "Measuring propositional idea density through part-of-speech tagging". Their abstract:
We present a computer program, CPIDR (Computerized Propositional Idea Density Rater), that measures idea density automatically through part-of-speech tagging. Idea density, the number of propositions per N words, is a useful measure of discourse complexity and of possible cognitive impairment on the part of the speaker. Propositions correspond roughly to verbs, adjectives, adverbs, prepositional phrases, and conjunctions (Snowdon et al. 1996). By counting these parts of speech and then applying readjustment rules for particular syntactic structures, we closely replicate the proposition counts given by the standard Turner & Greene method.
This is part of the CASPR ("Computer Analysis of Speech for Psychological Research") project. And the part about "idea density" being "a useful measure of ... possible cognitive impairment" seems, believe it or not, to be a bit of an understatement.
The research behind this notion comes out of what is colloquially known as the "nun study", summarized in D. A. Snowdon, S. J. Kemper, J. A. Mortimer, L. H. Greiner, D. R. Wekstein and W. R. Markesbery. Linguistic ability in early life and cognitive function and Alzheimer's disease in late life. JAMA Vol. 275 No. 7, February 21, 1996.
Two measures of linguistic ability in early life, idea density and grammatical complexity, were derived from autobiographies written at a mean age of 22 years. Approximately 58 years later, the women who wrote these autobiographies participated in an assessment of cognitive function, and those who subsequently died were evaluated neuropathologically. [...] Cognitive function was investigated in 93 participants who were aged 75 to 95 years at the time of their assessments, and Alzheimer's disease was investigated in the 14 participants who died at 79 to 96 years of age. [...] Low idea density and low grammatical complexity in autobiographies written in early life were associated with low cognitive test scores in late life. Low idea density in early life had stronger and more consistent associations with poor cognitive function than did low grammatical complexity. Among the 14 sisters who died, neuropathologically confirmed Alzheimer's disease was present in all of those with low idea density in early life and in none of those with high idea density.
I discussed this work at greater length a couple of years ago ("Writing style and dementia", 12/3/2004). I'll reprise here what I wrote about the specific numbers behind the autopsy correlations:
According to the study's summary table, the mean "idea density" in early life autobiographies for nuns whose autopsied brains "met neuropathologic criteria for Alzheimer's disease" was 4.9 (95% confidence interval 4.6-5.3), while for nuns whose brains were free of Alzheimer's symptoms, the mean "idea density" was 6.1 (95% confidence interval 5.6-6.6).
This is major wizardry, which I find striking on several levels.
First, it's amazing that quantification of writing style at age 22 works to predict dementia six decades later, and apparently works so well. The N for the brain-autopsy part of the study is not very large (just 14), but the results are still impressive; and the sample of 93 in whom old-age cognitive function was correlated with early-life writing style is reassuring. It would be nice to see results from a much larger epidemiological study. But the nun-study results themselves suggest that "idea density" in writing samples might be the basis of a screening test for Alzheimer's, whose predictive value would compare favorably to many tests that are in common use to screen for other diseases.
Second, the fact that "idea density" worked better than other metrics that the researchers tried, especially "grammatical complexity", is puzzling and therefore interesting.
And third, the fact that this particular way of measuring "idea density" turned out to work so well is puzzling and therefore interesting.
The "idea density" concept comes from Kintsch, W. (1972) "Notes on the structure of semantic memory", in E. Tulving and W. Donaldson (eds) Organization of Memory, pp. 247–308. New York: Academic Press, and Kintsch, W. & J. Keenan. Reading rate and retention as a function of the number of propositions in the base structure of sentences. Cognit. Psychol. 5: 257-274 (1973). As the title of the second paper suggests, this work developed out of early work in transformational grammar, initiated by Noam Chomsky's Syntactic Structures, based on some earlier work by Zellig Harris, and carried forward in the early 1970s under the rubric of "generative semantics". Kintsch et al. interpreted these theories in a particular way in deciding how to count the "ideas" or "propositions" expressed by an English sentence. Other interpretations of these or other theories, before and since, would come out with very different "idea density" counts for the same sentences interpreted in the same way.
For example, this metric treats "the cat ate the rat" as one proposition, while "the cat ate today" is two. That's because a verb and its arguments (e.g. subject and object) are treated as a single proposition, while modifiers such as adverbs and adjectives are treated as adding separate propositions. As I understand it, determiners like "the" or "a" are not counted, nor are plurals or auxiliary verbs. Explicit connectives are counted, but implicit ones generally are not: thus "the cat appeared; the rats scattered" is two propositions, but "when the cat appeared, the rats scattered" is three. Some complex nominal constituents are treated as elementary units -- thus in Snowdon et al. 2000, they give this example of calculating idea density:
The following sentence from an autobiography illustrates the method used to compute idea density: "I was born in Eau Claire, Wis., on May 24, 1913 and was baptized in St. James Church." The ideas (propositions) expressed in this sentence were (1) I was born, (2) born in Eau Claire, Wis., (3) born on May 24, 1913, (4) I was baptized, (5) was baptized in church, (6) was baptized in St. James Church, and (7) I was born...and was baptized. There were 18 words or utterances in that sentence. The idea density for that sentence was 3.9 (i.e., 7 ideas divided by 18 words and multiplied by 10, resulting in 3.9 ideas per 10 words).
There have been many different ways of thinking about how represent the meaning of sentences and discourses, and for each representational theory, there could be many different ways of quantifying its count of elementary parts. I don't think that most semanticists these days would be inclined to make the same choices that Kintsch et al. did, 35 years ago -- for example, it seems odd to say that "St. James" adds an extra proposition so that " in St. James Church" contributes two propositions, while "in Eau Claire, Wis." and "on May 24, 1913" each add just one, ignoring the nominal substructure in those cases.
But maybe today's choices would be worse ones, I don't know. It's hard to argue with success. Then again, maybe a different metric would result in even better clinical prediction. This is an excellent example of why "executable articles" are a good idea -- if the nun-study texts, the details of their "idea density" analyses, and the associated clinical data were available, it would be just a few hours work to compare alternative metrics. This is also a good example of why the idea faces some non-trivial obstacles, since such data is (properly) protected by privacy considerations that would have to be respected by any method for offering research access.
Meanwhile, it's exciting that Cati Brown and the rest of the CASPR people have designed and implemented a program that computes the "idea density" metric automatically -- and according to their poster, "agreed with the group of human raters appreciably better than the raters agreed with each other (r = 0.942, or 0.969 if one outlier is excluded, vs. r ≥ 0.82 for human vs. human)". Not only that, but they list among their planned future work to "Package CPIDR as a shareable software package", and to "Factor propositional idea density into its components (verb density, adjective density, etc.) and determine the neuropsychological relevance of each". I've been a bit puzzled about how little follow-up there seems to have been to the nun study, both in neuroscience and in linguistics; maybe the CASPR work will change that.
Posted by Mark Liberman at January 6, 2007 11:10 AM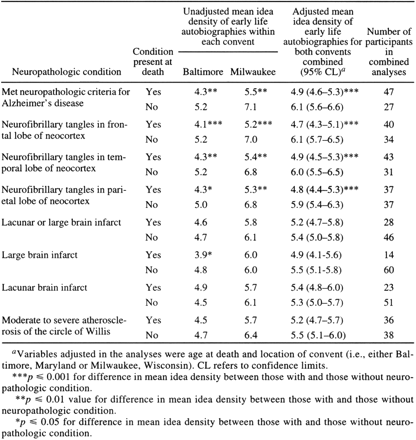{kind=link}