November 14, 2007
How about the Germans?
Following up on earlier posts about "Nationality, gender, and pitch" (see also here and here), Linda Lanz sent in some personal experience supporting the view that Japanese have different expectations than Americans do about the appropriate degree of gender polarization in fundamental frequency:
I once worked for a Japanese travel agency in the United States, and as part of that job I frequently fielded phone calls from our Japanese clients. I was never aware of any problems, but after working there for some time, the boss informed me that I needed to speak "higher" on the phone. At first I thought he had a problem with my politeness level, since Japanese phone conversation is highly formal (at least for a business), but that wasn't it. He said that while my grammar was fine, I just talked too low, and the callers thought I was angry or unwilling to help them because of it. Apparently they'd had complaints that the woman answering the phone wasn't very friendly. After that, I tried to remember to speak with a higher pitch when I was answering phone calls in Japanese.
And Tilman wrote to propose another stereotype of national difference in this characteristic:
... speaking of anecdotal and subjective evidence, the impression I get is also that on average American and British women tend to speak with a higher pitch than German women, and one of my English Language lecturers in college confirmed that, again from personal experience. (BTW, I am a historian who studied English as his minor). Thus quite a few American actresses sound rather squeaky to German ears, while as far as I gather the voices of the likes of Marlene Dietrich were perceived as more unusually low-pitched in a US context than they were in a German one.
Well, it would take more work to compare actresses, but the idea that Germans in general might be less gender-polarized than Americans, in terms of voice pitch, is easy to test by the same method that I used to test the difference between Japanese and Americans. The same CallHome collection that I used to compare English and Japanese had a German edition as well. Of the 100 German conversations that were published, 30 involved one male and one female. So for this morning's Breakfast Experiment™, I've added those 30 German conversations to the same plot as the 18 Japanese and 27 American conversations that I used before:

Here's the version plotted in Hz instead of in semitones:
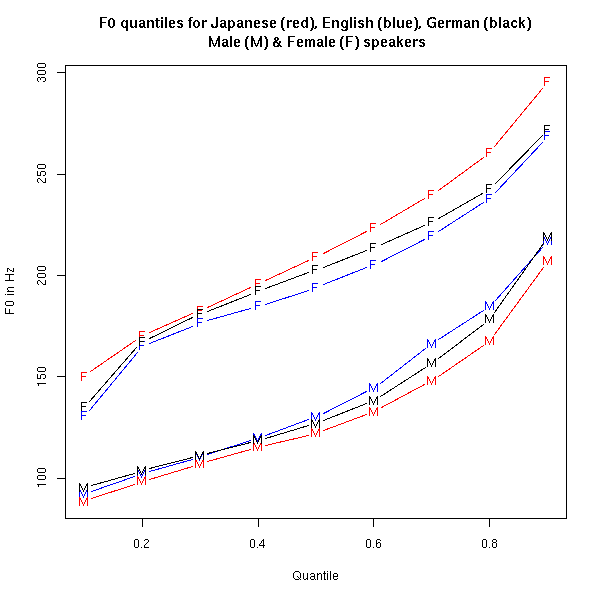
Rather than being less gender-polarized than the Americans, the Germans are actually slightly more gender-polarized. Overall, the German pitch values fall roughly in between the Americans and the Japanese. Another way to see this is to look at a table of the difference (in semitones) between female and male speakers of each language at each percentile:
| .1 | .2 | .3 | .4 | .5 | .6 | .7 | .8 | .9 | |
| Americans | 6.0 | 8.4 | 8.1 | 7.5 | 6.9 | 6.1 | 4.8 | 4.4 | 3.7 |
| Germans | 6.0 | 8.3 | 8.5 | 8.3 | 8.1 | 7.5 | 6.4 | 5.3 | 3.7 |
| Japanese | 9.2 | 9.5 | 9.2 | 9.1 | 9.3 | 9.0 | 8.3 | 7.6 | 6.2 |
(The same caveats about possible non-sampling error apply as in the earlier case, of course.)
I'd also like to clarify where these numbers came from.
When we track F0 values as a function of time, we get a lot of numbers. Here's the opening phrase of Jane Auten's Pride & Prejudice, as read by Chris Goringe, one of the readers whose versions are available from the free LibriVox audiobooks effort:
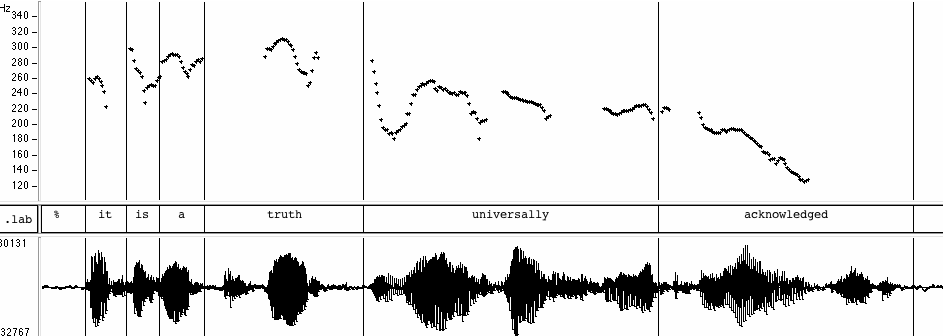
The F0 values in Hz estimated for the first word, "it", look like this:
259.816
256.915
255.231
260.004
262.266
260.464
256.444
250.559
243.562
223.176
If we take Chris Goringe's recording of the first three chapters, and estimate the F0 200 times per second, we wind up with 93,816 values. (In regions where Chris is not talking, or is producing voiceless sounds, no pitch estimate is produced -- as long as the F0 estimate algorithm is doing its job. The algorithm that I used is a good one, and doesn't make too many errors on the material I've used, so I believe the percentile estimates should be fairly accurate and stable.) If we translate the F0 into semitones relative to A 110, and then calculate the 10th, 20th, ..., 90th percentiles of those values, we get the points that are plotted with the blue 1's in the graph below.
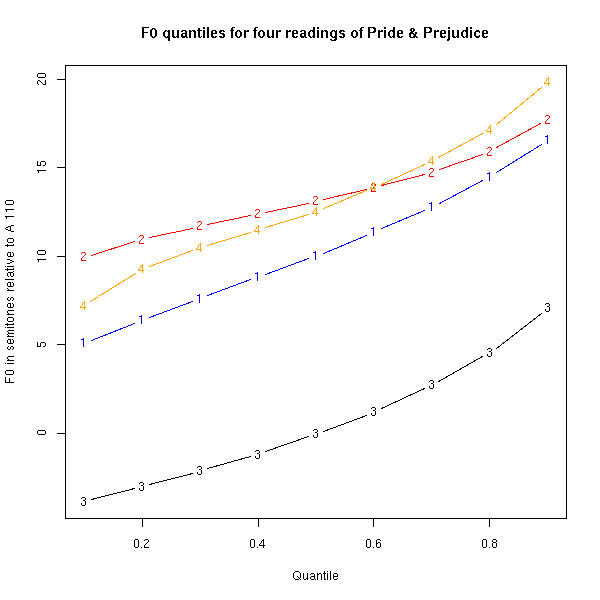
The other plots are (2) Annie Coleman reading the first four chapters of Pride & Prejudice, (3) Micah Sheppard reading the first two chapters of Pride & Prejudice, and (4) Karen Savage reading the first chapter of Pride & Prejudice, all based on the mp3 files available from LibriVox.
Note that the "percentiles" involved are NOT percentiles of people, but percentiles of pitch values. In Hz (= cycles per second), the percentiles look like this:
| 10% | 20% | 30% | 40% | 50% | 60% | 70% | 80% | 90% | |
| Reader #1 | 147.6 | 159.0 | 170.7 | 183.3 | 196.1 | 212.0 | 230.3 | 254.0 | 286.7 |
| Reader #2 | 195.3 | 206.9 | 216.0 | 224.9 | 234.4 | 245.0 | 257.5 | 275.9 | 305.8 |
| Reader #3 | 88.0 | 92.4 | 97.2 | 102.6 | 109.8 | 117.7 | 128.8 | 142.9 | 165.3 |
| Reader #4 | 166.4 | 188.1 | 201.5 | 213.3 | 226.8 | 245.4 | 267.4 | 295.9 | 345.7 |
You shouldn't be surprised to learn that readers 1, 2, and 4 are female, while reader 3 was male. [Update 11/16/2007: Chris Goringe has written to inform me that he is, in fact, male; so much for naive connections between pitch range and sex. There is more sexual dimorphism in pitch range than in height, for example, because of testosterone-induced "voice change" at puberty -- but there is still some overlap in the distributions.] If we pool the estimated F0 values for the three female [rather, higher-pitched] readers, and plot the percentiles for the pooled data, we get a picture like this:
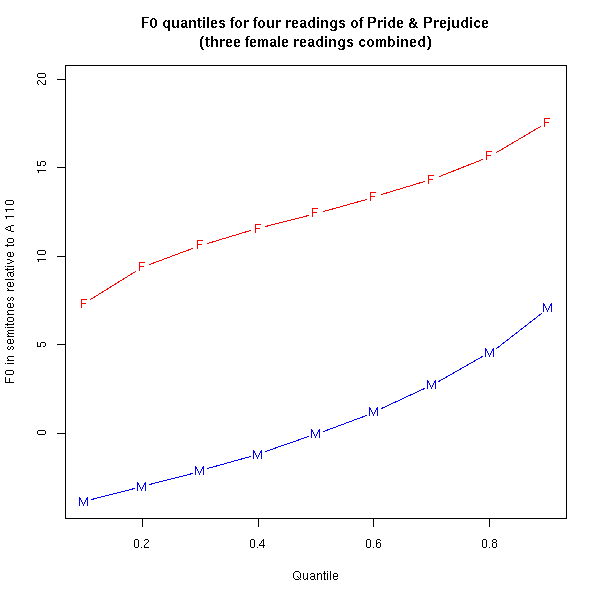
In order to look at gender polarization among Japanese, Americans, and Germans, I pitch-tracked all the conversations (after separating the two channels), pooled all the pitch estimates for each combination of nationality and sex (generally resulting in more than a million numbers per category), and determined the percentiles for each collection of pooled estimates. [I took the identification of speakers by sex from the demographic information given in the database -- I trust that it was more reliable than my identification of the sex of the Pride & Prejudice readers... In both cases, though, the fact that the data is published makes it more likely that errors can be found and corrected, even -- or perhaps especially -- in informal Breakfast Experiments.]
This is not the only way to examine the question quantitatively, and it's surely not the best way, but it gives a simple picture of what's happening, and it's easy to calcuate. For a Breakfast Experiment™, that matters -- and in fact, my second cup of coffee is getting cold, and I have a 9:00 appointment, so bye for now.
Posted by Mark Liberman at November 14, 2007 08:15 AM