January 19, 2008
It's a dog's life -- 0.3 bits at a time
After reading Geoff Pullum's note on "Parsing dog talk", I heaved a sigh and faced my duty to Language Log's Reading the Original Paper and Thinking About the Actual Numbers department.
The original paper is Csaba Molnár, Frédéric Kaplan, Pierre Roy, François Pachet, Péter Pongrácz, Antal Dóka and Ádám Miklósi, "Classification of dog barks: a machine learning approach", Animal Cognition, published online 1/15/2008 (a .pdf is here).
And the actual numbers are pretty simple. The researchers collected 6,646 barks from 14 dogs (4 male, 10 female), in six situations, whose nature is suggested by their one-word descriptions: "Stranger" (N=1802), "Fight" (N=1118), "Walk" (N=1231), "Alone" (N=752), "Ball" (N=1001), "Play" (N=742). If you guessed the situation at random, you'd expect to be right 1/6 = 17% of the time. If you always guessed "Stranger", you'd expect (in a sample from this dataset) to be right 1802/6646 = 27% of the time. Human listeners guessed right 40% of the time. A automated classifier made 43% correct classifications. No one asked the dogs.
We can deduce that Colin Barras wrote "Computer decodes dog communication" (New Scientist, 1/17/2008) from the press release, without reading the original paper, because he serves up this quote:
"The idea sounds totally cool," says Brian Hare at Duke University in Durham, North Carolina, US. "This is animal behaviour research at its best. You see a pattern that no one else knew was there because we can't hear the difference ourselves."
If Brian Hare had read the paper before getting the phone call, and noted the 43% vs. 40% performance, he wouldn't have said such a silly thing; and if Colin Barras had done his duty as a journalist, he would never have embarrassed his source (as well as himself) by printing the quote.
In fact, I wonder whether Hare said any such thing at all, since anybody who's ever had a dog knows that (for example) the "Walk" scenario
The owner was asked to behave as if he/she was preparing to go for a walk with the dog. For example, the owner took the leash of the dog in her/his hand and told the dog „We are leaving now”.
and the "Fight" scenario
For dogs to perform in this situation, the trainer encourages the dog to bark aggressively and to bite the glove on the trainer’s arm. Meanwhile the owner keeps the dog on leash.
are likely to produce rather different-sounding vocalizations, and we probably don't need a machine-learning algorithm to discover this.
[I should note in passing that in the original paper, the authors explicitly decline to interpret the quantitative comparison between the human and automatic classification performance, since the test methodologies were so different: the human subjects made their judgments after listening to a series of barks from the same context, whereas the computer classified just one bark; on the other hand, the computer algorithm was based on extensive feature selection and parameter setting for the same collection of recordings, whereas the humans were given no training at all. As a result, there's no point in trying to decide whether the human 40% is "significantly" lower than the computer's 43%, and to their credit, the authors don't try to do it. Alas, the author of Springer-Verlag's press release was not so restrained.]
OK, time for a bit of fiddling with the numbers. Here's the authors' Table 4, a confusion matrix showing the relationship between the true situation (row labels) and the program's guess (column labels):
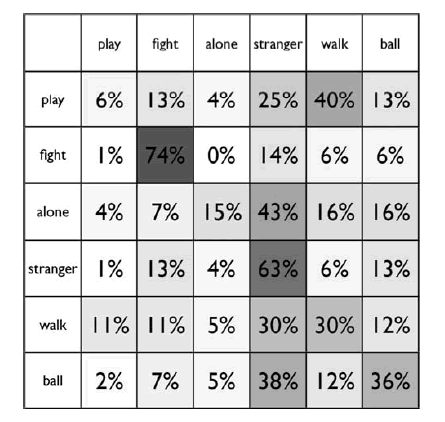
[A small technical note. The approach had three phases: (1) "Generation of a large number of [signal-processing] descriptors adapted to a specific classification problem", using a genetic algorithm with fitness defined by nearest-neighbor classification, to select from a very large number of possible compositions of a large set of signal-processing primitives; (2) "Creation of an optimal subset of descriptors", using a greedy stepwise feature selection method for a Naive Bayes classifier; (3) "Complete evaluation of recognition performance", using a Naive Bayes classifier trained on the descriptors from (2), testing on each of the 10 dogs after training on the other 9. While each of the three phases used a (different) train/test division to avoid over-fitting, the same dataset was used over again in each of the phases. This makes it likely that the final performance is higher than would have been achieved if a test set had been kept aside from the beginning, or if new data were collected.]
How much information is being conveyed here? One way to quantify this would be in terms of mutual information: how much does hearing the dog's bark reduce our uncertainty about the situation in which the bark was recorded? (And the answer is going to be about the same for the human listeners and for the computer algorithm, since their performance was about the same.)
The maximum possible, in this case, would be log2(6) = 2.58 bits. The actual answer, by my calculation from the counts given in Molnár et al.'s Table 3, is 0.337 bits. In other words, the researchers' automated classifier is getting about a third of a bit of information from each bark. The human listeners were getting about the same.
So this is not quite the situation described in Gary Larson's Far Side cartoon, where Professor Milton invents a device that translates from Dog to English, and goes down a street full of barking dogs, only to discover that they are all saying "Hey hey hey hey hey hey..." But neither is it the situation implied by the headlines (and the associated stories) about this work: "Computer Decodes Dog Communication" (ABC News); "Scientists decode dogspeak" (MSNBC); "Computer Translates Dog Barks" (FOXNews); "Comuter Learns Dogspeak: Programs Can Classify Dog Barks Better Than Humans, Study Shows" (Science Daily); "Computer can help your dog communicate" (Reuters); "Yap-lication unlocks canine moods" (BBC News); " Computer communicates with dogs" (Telegraph), etc. etc.
More important, though, it's not obvious that this is research on communication at all, at least as most people understand the term.
To see why, let's imagine the response to a superficially very different piece of research. We record 6,000 sound clips from the engine compartments of 10 different cars in 6 different situations: "Stopping at a red light"; "Cruising on the interstate"; "Pulling out to pass"; "Idling"; "Accelerating from a standing start"; "Revving the engine while stopped". We calculate a bunch of acoustic features, and use machine-learning algorithms to generate and select feature-combinations that are good at classifying the basic situations, and then we train a classifier that is able to guess correctly, a little less than half the time, which of the six situations the car was in when a recording was made.
Would newspapers all over the world tell us about it, under headlines like "Computer Decodes the Language of Cars" or "Computer can help your car communicate"? I don't think so. (Well, maybe the BBC would...)
I'm not (just) being perverse here. The point is that the dogs in these six situations are probably doing rather different things with their bodies, and are also probably in rather different physiological states (of overall arousal, among other things), and these differences are likely to affect their vocalizations. Compare, for example, lunging at a trainer while being restrained on a leash (the "fight" situation), vs. trotting around happily while preparing to go out (the "walk" situation).
I realize that dogs are social animals, with considerable vocal skills, who make extensive use of vocalizations in their social interactions. And I think that using machine learning techniques to explore animal vocalizations is indeed an excellent idea, and this is a very worthwhile study -- Brian Hare was right to be enthusiastic, even he managed to get quoted saying something that seems rather silly given the facts of the case. But ... well, you fill in the rest.
If you want to follow along at home, the equation for mutual information is here:

And here's a little R script that applies the equation to the dog data.
[Update -- Laurence Sheldon Jr. writes:
We have just one dog, and I have no notion of just how a study involving more than one individual would turn out, but there is no doubt in my mind that we (wife and I) can correctly differentiate among "I'm bored and going out sounds like something to do.", "Squirrel in the bird feeder!", "I gotta go!", "Car! You going somewhere in the car?!", "I think I heard the garage door open and I want to go [greet Pat|greet Larry|get into the car before [Pat|Larry] notice.]!", and "[Pat|Larry] has been gone quite a while, I want to check the garage for them.".
Some of these we think we can identify without seeing the dog ("Squirrel!") or knowing which of four doors she is at.
I think that most dog owners have a similar sort of impression. But are all of these vocalizations just barks, or are some of them (at least half-way) whines or growls? Molnár et al. don't specify whether they excluded such mixed-type sounds or not. I should think that if you allowed them in, you could get more than a third of a bit of information out of each vocalization.]
Posted by Mark Liberman at January 19, 2008 08:36 AM