March 22, 2008
Entering Exotic Characters
Yesterday for the umpteenth time I was asked for assistance in getting exotic characters into a blog post, so I thought I'd post a little information about this.
If you've got already got the text that you want in Unicode, the problem with getting it into a blog post is probably that your blog software, like the Movable Type package that runs Language Log, gags on non-ASCII characters. To overcome this limitation, you need to replace your Unicode text with HTML numeric character references. For example, instead of directly entering the Unicode for "lower case e with acute accent" é, you enter é. This consists of the Unicode codepoint in hexadecimal 00E9, with the prefix &#x and the suffix ;. It is also possible to give the codepoint in decimal, should you be inclined to the vulgar idiom, in which case you omit the x: é.
If you know or can find out what the codepoints are and you only have a few characters to enter, you can do this manually, but it is easier to use a converter. Assuming that you are connected to the net, you can use Richard Ishida's Uniview converter. Just enter your text in the "characters" window and press "convert", then cut and paste the resulting HTML from the window to the right into your post.

I myself usually use my command-line program uni2ascii. It is installed locally and so doesn't require web access. It is faster and does many more types of conversion, though for most people that doesn't matter.
Of course, you may need to get the Unicode in in the first place. The easy case is where the language is one in which you are accustomed to writing and you have your keyboard mapped for it or some other sort of input system. These exist for many writing systems, but not all, and if the writing system is one that you don't use regularly, it may be too much trouble to track one down and install it, or using it may be difficult. If you don't have a convenient method of entering the writing system you want to use, you may find a solution in Yudit. Yudit is a Unicode editor available free for all major platforms. It doesn't have all the bells and whistles of other text editors and word processors, but it is very good at rendering Unicode and has a simple system for defining your own keyboard mappings and switching among them. It comes with nearly 200 keyboard mappings created by the author or contributed by users.
Here I am entering Carrier syllabics.
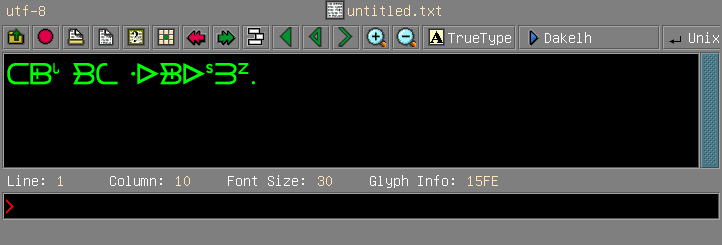
If nothing else works, you can always go to the source, namely the website of the Unicode Consortium: http://www.unicode.org. The various files containing the details of the current version of the standard always reside in the directory http://www.unicode.org/Public/UNIDATA/. Of particular interest are NamesList.txt, which pairs character names with codepoints:
00E8 LATIN SMALL LETTER E WITH GRAVE : 0065 0300 00E9 LATIN SMALL LETTER E WITH ACUTE : 0065 0301 00EA LATIN SMALL LETTER E WITH CIRCUMFLEX : 0065 0302UnicodeData.txt which contains additional detail in a terser format intended to be read by machines:
00E8;LATIN SMALL LETTER E WITH GRAVE;Ll;0;L;0065 0300;;;;N;LATIN SMALL LETTER E GRAVE;;00C8;;00C8 00E9;LATIN SMALL LETTER E WITH ACUTE;Ll;0;L;0065 0301;;;;N;LATIN SMALL LETTER E ACUTE;;00C9;;00C9 00EA;LATIN SMALL LETTER E WITH CIRCUMFLEX;Ll;0;L;0065 0302;;;;N;LATIN SMALL LETTER E CIRCUMFLEX;;00CA;;00CAand Unihan.txt, which contains information about Chinese characters. (Since this file is very large, a compressed version is also available for download: Unihan.zip.) These are plain text files which you can search in any text editor or word processor. I have enough reason to look at the information in UnicodeData.txt that I wrote a little browser for it. John Wells has information about the International Phonetic Alphabet in Unicode.
Many people find it easier to use a character map, which shows you a selected block of characters and lets you select characters to insert into a text and provides information about them. The one I use is Gucharmap.
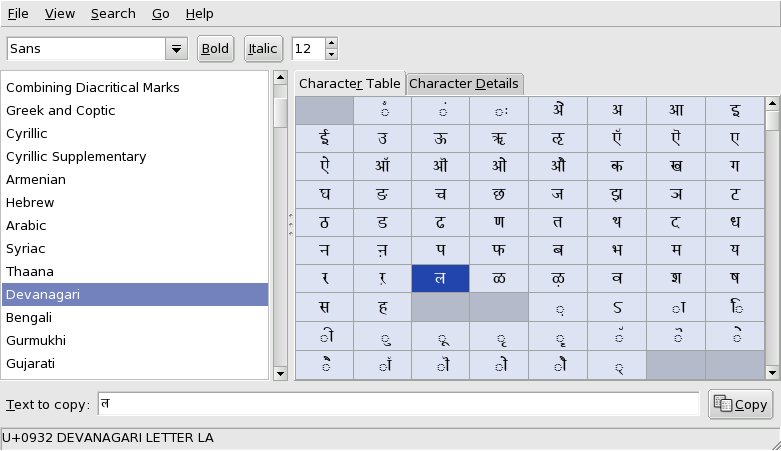
UnicodeChecker for Mac OS X and BabelMap and Unibook for Microsoft Windows are similar. All MS Windows systems come with Character Map, which shows the characters in a particular font.
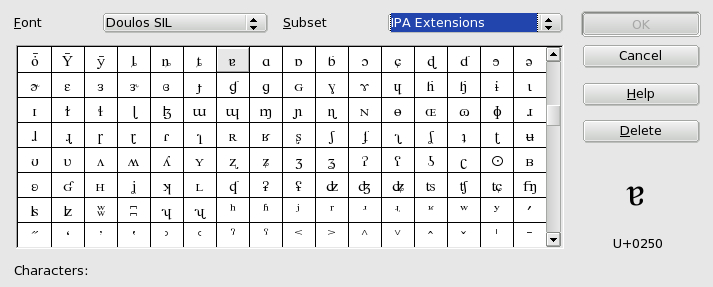
Some word processors provide a similar facility. In OpenOffice.org Writer, if you click on Insert->Special Character, you will get a chart showing the characters in the currently selected font. Here it shows a portion of the SIL Doulos font, which has good coverage of the International Phonetic Alphabet.
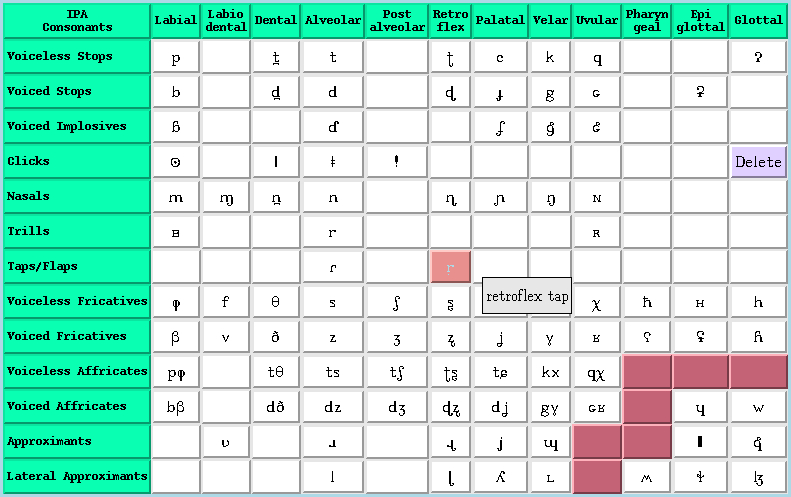
If you need to enter characters frequently, looking for them in a general purpose character map quickly becomes tedious, so special purpose tools are useful. I often use CharEntry, which provides a number of clickable charts, such as this one of the consonants in the International Phonetic Alphabet:
The other thing that I find particularly useful is that you can define custom character charts by creating a file listing the codepoints that you want and the glosses to display as tooltips when the pointer is over the character. Here's the control panel with an Armenian alphabet chart.
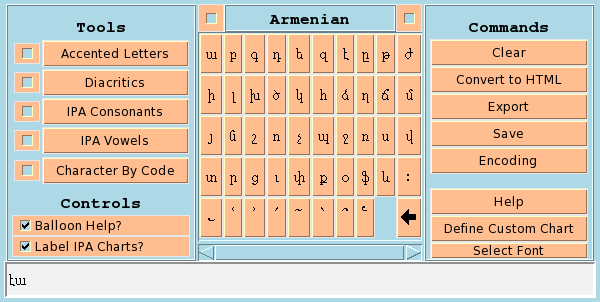
The definition begins like this:
Armenian|10|clearlyu|12 \u0561:\u0531|ayb \u0562:\u0532|ben \u0563:\u0533|gim \u0564:\u0534|daFor each letter you enter a line containing the codepoint of the letter (in this case two, lower- and upper-case, separated by a colon), followed by a pipe symbol and the gloss for that letter.
Two good sources for additional resources are the Unicode Consortium's Resources page and Alan Wood's Unicode Resources page, especially the section devoted to fonts.
Posted by Bill Poser at March 22, 2008 02:56 PM