March 31, 2008
Ask Language Log: Comparing the vocabularies of different languages
Michael Honeycutt writes:
I emailed Steven Pinker with a question and he told me that I should contact you.
I am a college freshman who plans to study Modern Languages and I am fascinated with linguistics. The question that I had for Dr. Pinker was in regards to the active vocabularies of the major modern languages. This may be a novice question and I apologize ahead of time. I am curious if there are any studies on the subject of the percentage of a language's active vocabulary used on a daily basis. I have been looking into this for a couple of weeks in my spare time and the information I am finding is rarely in agreement.
For example, according to Oxford University Press, in the English language a vocabulary of 7000 lemmas would provide nearly 90% understanding of the English language in current use. Of these 7000 lemmas, what percentage will the average speaker or reader experience on a daily or weekly basis? Are there any particular languages or language families that have a significantly higher or lower percentage of words encountered on a day to day basis? Are there any studies on whether, for example, speakers of Latin used more or less vocabulary in their daily lives than speakers of a modern Romance language?
Those are interesting questions. The answers are also interesting -- at least I think so -- but they aren't simple. Let me try to explain why.
The executive summary: Depending on what you count and how you count them, you can get a lot of different vocabulary-size numbers from the same text. And then once you decide on a counting scheme, there's an enormous amount of variation across speakers, writers, and styles. And in comparing languages, it's hard to decide what counts as comparable counting schemes and comparable ways to sample sources.
First, I'm going to dodge part of your question. It's hard enough to count the words that someone speaks, writes, hears, or reads in a given period of time, and to compare these counts across languages. But when you bring in a concept like "understanding" (much less "90% understanding"), you open up another shelf of cans of worms. How deep does understanding need to go? Do I understand what oak means if I only know that it's a kind of tree? Or do I need to be able to recognize the leaves and bark of some kinds of oaks, or of all kinds of oaks? Does it count as "understanding" if I can sort of figure out what a word probably means from its use in context, even if I didn't know it before? Do I "understand" a proper noun like "Emily Dickinson" or "Arcturus" simply by virtue of recognizing its category, or do I need to know something about its referent (if any)?
And if you pose the question as "the percentage of a language's active vocabulary used on a daily basis", you'll also need to define an even more elusive number, the size of "a language's active vocabulary". What are the boundaries of a "language"? What counts as "active"?
So for now, let's put aside the problem of understanding, and the whole notion of "a language's active vocabulary", and just concentrate on counting how many words people speak, write, hear, or read in their daily lives. This problem is hard enough to start with.
Consider the counting problem with respect to the text of your question. Your note uses the strings language, languages, language's. The word-count tool in MS Word will (sensibly enough) count each of these as one "word". But how many different vocabulary items -- word types -- are they? Are these three items, just as written? Or should we count the noun language plus the plural marker -s and the possessive 's? Or should we just count one item language, which happens to occur in three forms?
Your question also includes the strings am, are, be, is, was -- are these five distinct vocabulary items, or five forms of the one verb be? How about the strings weeks, weekly, day, daily? Is weekly the same vocabulary item as an adjective ("on a weekly basis") and an adverb ("published weekly")? If we analyze weekly as week + -ly and significantly as significant + -ly, are those (sometimes or always) the same -ly?
What about the noun use (in "daily use") and the participle used ("used on a daily basis"). Are those different words, or different forms of the same word? Is the participle used the same item, as a whole or in parts, as the preterite used?
Should we unpack 90% as "ninety percent" (two words) or "ninety per cent" (three words)? And is percentage a completely different vocabulary item, or is it percent (or per + cent) + -age?
Depending on the answers to these five easy questions about 17 character strings, we might count as many as 18 vocabulary items or as few as 10. And as we scan more text, this spread will grow, without any obvious bounds.
You imply a certain answer to such questions by using the term lemma, meaning "dictionary entry". But this doesn't entirely settle the matter, even for the simple questions we've been asking so far. For example, the Oxford English Dictionary has two entries for "use", one for the noun and another for the verb; while the American Heritage Dictionary has just one entry, with subentries for the noun and verb forms.
Answers to various kinds of questions about word analysis will have different quantitative impacts on word counts in different languages. For example, like most languages, English has plenty of compounds (newspaper, restroom), idioms (red herring, blue moon), and collocations (high probability vs. good chance) whose meaning and use are not (entirely) compositional. It's not obvious where to stop counting. But our decisions about such combinations will have an even bigger impact on Chinese, where most "words" are compounds, idioms, or collocations, made out of a relatively small inventory of mostly-monosyllabic morphemes (e.g. 天花板 tian hua ban "ceiling" = "sky flower board"), and where the writing system doesn't put in spaces, even ambiguously, to mark the boundaries of vocabulary items.
However we choose to count, we're going to get a lot individual variation. I gave some examples in "Vicky Pollard's revenge" (1/2/2007), where I compared the rate of vocabulary display of in 900 words from four different English-language sources:
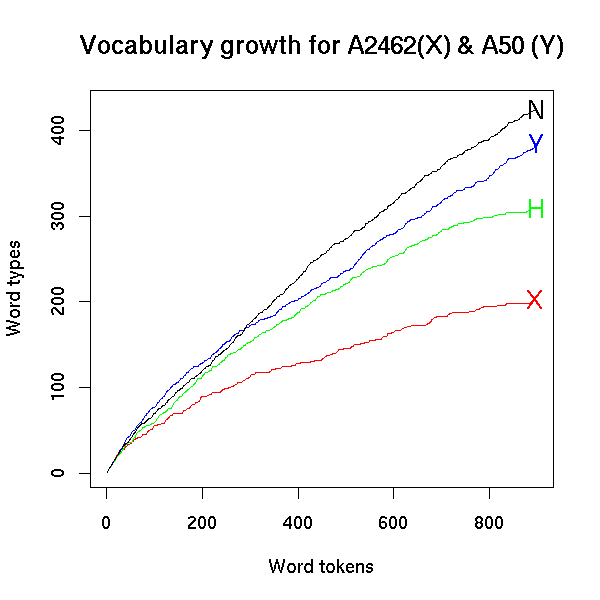
The x axis tracks the increase in "word tokens", i.e. roughly what MS Word's wordcount tool would count. The y axis shows the corresponding number of "word types", which is a proxy for the number of distinct vocabulary items. Here, it's just what we get by removing case distinctions, splitting at hyphens and apostrophes, and comparing letter strings. If we used some dictionary's notion of "lemma", all the curves would be lower, but they'd still be different, and in the same general way.
Sources X and Y are conversational transcripts; sources H and N are written texts. You can see that after 900 words, Y has displayed roughly twice as many vocabulary items as X, and that the gap between them is growing. There's a similar relationship between the written texts H and N. Given these individual differences, comparing random individual speakers or writers isn't going to be a very reliable way to characterize differences between languages. We need to look at the distribution of such type-token curves across a sampled population of speakers or writers, like this for English conversational transcripts (taken from the same Vicky Pollard post, with the endpoints of the curves for speakers X and Y superimposed):
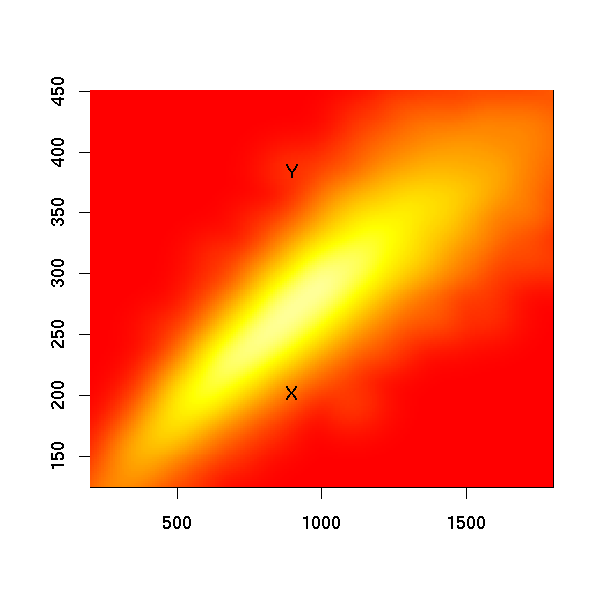
But if we had comparable sampled distributions for Spanish or German or Arabic, we could compare the average or the quantiles or something, and answer your question, right?
Sort of. Here are similar type-token plots for 50 million words of newswire text in Arabic, Spanish, and English:
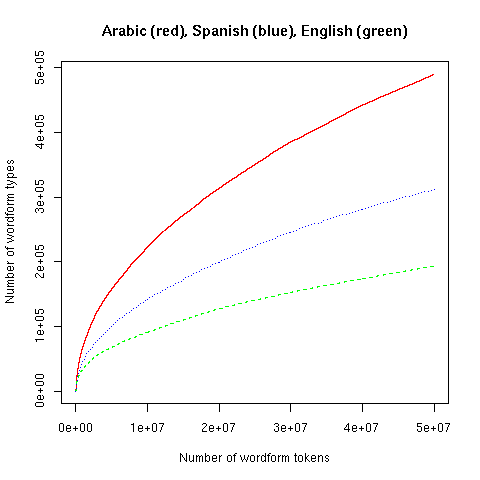
Does this indicate that Spanish has a much richer vocabulary than English, and that Arabic is lexically even richer yet? No, it mainly tells us that Spanish has more morphological inflection than English, and Arabic still more inflection yet.
These curves also reflect some arbitrary orthographic conventions. Thus Arabic writes many word sequences "solid" that Spanish and English would separate by spaces. In particular, prepositions and determiners are grouped with following words (thus this might be aphrase ofenglish inthearabic style). Just splitting (obvious) prepositions and articles moves the Arabic curve a noticeable amount downward:
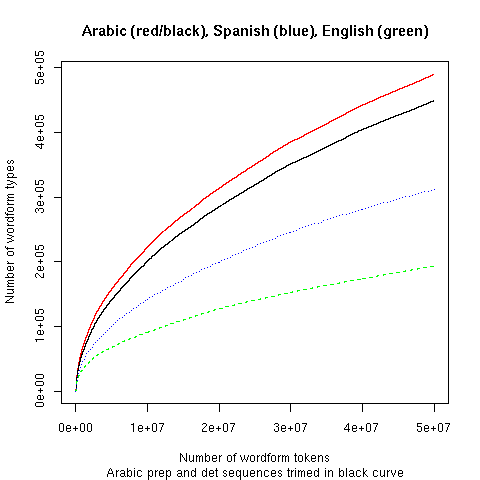
Arabic text has some other orthographic characteristics that raise its type-token curve by at least as much, such as variation in the treatment of hamza. And in large corpora in any language, the rate of typographical errors and variant spellings becomes a very significant contributor to the type-token curve.
But if we harmonized orthographic characteristics, corrected and regularized spelling, and also unpacked inflections and regular derivations, would these three curves come together? I think so, though I haven't tried it in this particular case.
But remember that different sources of speech transcriptions or written text within a given language may display vocabulary at very different rates. To characterize differences between languages, we'd have to compare distributions based on many sources in each language. However, there may be no non-circular way to choose our sources that doesn't conflate linguistic differences with socio-cultural differences.
Let's consider two extreme socio-cultural situations in which the same language is spoken:
(1) High rate of literacy, and a large proportion of "knowledge workers". Many publications aimed at various educational levels.
(2) Low rates of literacy; most of population is subsistence farmers or manual laborers. Publications aim only at intellectuals and technocrats (because they're the only literate people with money).
Given the connections between educational level and vocabulary that we see in American and European contexts, we'd expect a random sample of speakers from situation (1) to have significantly higher rates of vocabulary display than a comparable sample of speakers from situation (2). That's because speakers from (1) tend to have more years of schooling than speakers from (2).
On the other hand, we'd expect a random sample of published texts from situation (1) to have a significantly lower rate of vocabulary display than a comparable sample of texts from situation (2). That's because all the available texts in situation (2) are elite broadsheets rather than proletarian tabloids.
We could go on in this way for a whole semester, or a whole career. But please don't let me discourage you! Whatever the answers to your questions turn out to be, the search will bring up all sorts of interesting stuff. I've only scratched the surface.
If you're interested in taking this further, here are a few inadequate suggestions:
- My lecture notes on morphology from Linguistics 001.
- The Natural Language Toolkit, and the associated book. You might start with Chapter 3, Words.
- My lecture notes (from Cognitive Science 502) on "Statistical estimation for Large Numbers of Rare Events".
- Harald Baayen's book, Word Frequency Distributions.