December 14, 2003
Unicode
In a recent post, Mark Liberman referred to Unicode as a way of reproducing Arabic characters. Unicode is probably unfamiliar to a lot of people, so I thought I'd talk about it a little bit.
Like everything else, written characters are represented on computers by patterns of bits, ones and zeroes. These patterns of bits have a more conventional interpretation as numbers, so we generally talk about the representation of text as if characters were represented by numbers. What bit pattern (or number) represents what character is perfectly arbitrary. In the old days, when computer terminals had character encodings built in, it was a matter of what electrical signals would cause a certain character to appear on the screen. Nowadays it is a matter of what bit pattern causes a certain picture to be drawn. A mapping from bit patterns or numbers to characters is a character encoding. For example, in the American Standard Code for Information Interchange (ASCII) code the letter a is represented by the number 97, or really, the bit pattern 01100001.
ASCII is by far the most commonly used character encoding because it suffices for normal English text and English has long been the dominant (natural) language used on computers. As other languages came into use on computers, other sets of characters, with different encodings, came into existence. Indeed, there is usually more than one encoding for a particular writing system. All in all, there are hundreds of different character encodings.
This proliferation of character encodings causes a lot of problems. If you receive a document from someone else, your software may not be able to display it, print it, or edit it. You may not even be able to tell what language or writing system it is in. And if you need to use multiple writing systems in the same document, matters become much worse. Life would be much simpler if there was a single, universal encoding that covered all of the characters in all of the writing systems in use.
Unicode is a character encoding standard developed by the Unicode Consortium to fulfill this need. The current version of the Unicode standard contains almost all of the writing systems currently in use, plus a few extinct systems, such as Linear B. More writing systems will be added in the future. A list of the current character ranges can be found here. In some cases Unicode lumps together historically related writing systems (for example, what it calls the Canadian Aboriginal Syllabics is not a single writing system), so to find out if your favorite writing system is included, and where the characters are, you may have to spend some time exploring the standard.
Here is a screenshot of the Yudit Unicode editor displaying a sampling of writing sytems. This text is all encoded in Unicode.
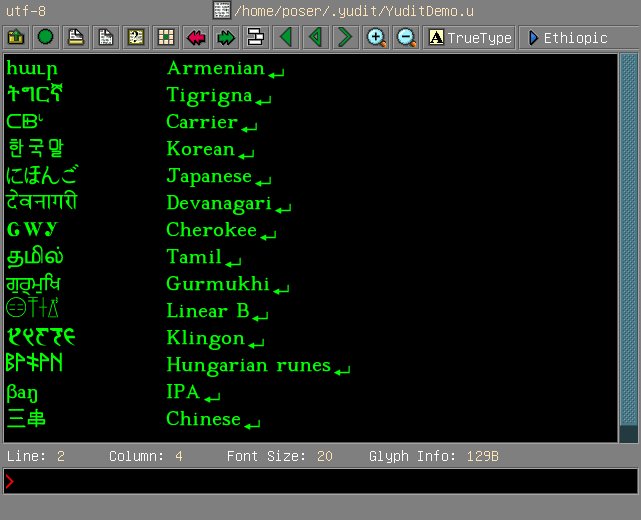
Unicode originally intended to use two bytes, that is, 16 bits, to represent each character. That would be sufficient for 65,536 characters. Although this may seem like a lot, it isn't really quite enough, so full Unicode makes use of 32 bits, that is, four eight-bit bytes. That's enough for 4,294,967,296 characters, which should hold us for a while. In fact, the Unicode Consortium has agreed that for the foreseeable future only the first 21 bits of the available 32 will actually be used. Text encoded in this version of Unicode is said to be in UTF-32.
One problem with UTF-32 is that every character requires four bytes, that is, four times as much space as the ASCII characters and other single-byte encodings. In order to save space, a compressed form known as UTF-8 is usually used to store and exchange text. UTF-8 uses from one to four bytes to represent a character. It is cleverly arranged so that ASCII characters take up only one byte. Since the first 128 Unicode characters are the ASCII characters, in the same order, a UTF-8 file containing nothing but ASCII characters is identical to an ASCII file. Other characters take up more space, depending on how large the UTF-32 code is. Here are the encodings of some of the characters shown above. The 0x indicates that these are hexadecimal (base 16) values.
| UTF-32 | UTF-8 | Name |
| 0x00041 | 0x41 | Latin capital letter a |
| 0x00570 | 0xD5 0xB0 | Armenian small letter ho |
| 0x00BA4 | 0xE0 0xAE 0xA4 | Tamil letter ta |
| 0x04E09 | 0xE4 0xB8 0x89 | Chinese digit 3 |
| 0x10024 | 0xF0 0x90 0x80 0xA4 | Linear B qe |
One source of resistance to using UTF-8 in some countries is that it seems to privilege English and other languages that can be written using only the ASCII characters. English only takes one byte per character in UTF-8, while most of the languages of India, for instance, require three bytes per character. By the standards of today's computer processors, storage devices and transmission systems, text files are so small that it really doesn't matter, so I don't think that this is a practical concern. It's more a matter of pride and politics.
If we don't need the extinct writing systems and other fancy stuff outside of the Basic Multilingual Plane, we could all be equal and use UTF-16. English and some other languages would take twice as much space to represent, but other languages would take the same space that they do in UTF-8 or even take up less space. At least from the point of view of those of us who aren't English imperialists, this might not be a bad idea, if not for the fact that UTF-8 has another big advantage over UTF-16: UTF-8 is independent of endianness.
What is endianness? Well, whenever a number is represented by more than one byte, the question arises as to the order in which the bytes are arranged. If the most significant bits come first, that is, are stored at the lowest memory address or at the first location in the file, the representation is said to be big-endian. If the least significant bits come first, the representation is said to be little-endian.
Consider the following sequence of four bytes. The first row shows the bit pattern.
The second row shows the interpretation of each byte separately as an
unsigned integer.
| bit pattern | 00001101 | 00000110 | 10000000 | 00000011 |
| decimal value | 13 | 6 | 128 | 3 |
Here is how this four byte sequence is interpreted as an unsigned integer
under the two ordering conventions:
| Little-Endian | (13 * 256 * 256 *256) + (6 * 256 *256) + (128 * 256) + 3 | 218,529,795 |
| Big-Endian | (3 * 256 * 256 *256) + (128 * 256 *256) + (6 * 256) + 13 | 58,721,805 |
Most computers these days are little-endian since the Intel and AMD processors that most PCs use are little-endian. Digital Equipment machines from the VAX through the current Alpha series are also little-endian. On the other hand, most RISC-based processors, such as the SUN SPARC and the PowerPC, as well as the IBM 370 and Motorola 68000 series, are big-endian.
By now you've probably forgotten the point of all this. Well, UTF-16 is subject to endianness variation. If I write something in UTF-16 on a little-endian machine and you try to read it on a big-endian machine, it won't work. For example, suppose that I encode the Armenian character հ ho on a little-endian machine. The first byte will have the bit pattern 01110000, conventionally interpreted as 112. The second byte will have the bit pattern 00000101, conventionally interpreted as 5. That's because the UTF-32 code, 0x570 = 1392, is equal to (5 * 256) + 112. Remember, on a little-endian machine, the first byte is the least significant one. On a big-endian machine, this sequence of two bytes will be interpreted as (112 * 256) + 5 = 373 = 0x175, since the first byte, 112, is the most significant on a big-endian machine. Well, 0x175 isn't the same character as 0x570. It's ŵ (w with a circumflex). So, if you use UTF-16 you have to worry about byte order. UTF-8, on the other hand, is invariant under changes in endianness. That is a big enough advantage that most people will probably continue to prefer UTF-8.
The terms big-endian and little-endian were introduced by Danny Cohen in 1980 in Internet Engineering Note 137, a classic memorandum entitled "On Holy Wars and a Plea for Peace", subsequently published in print form in IEEE Computer 14(10).48-57 (1981). He borrowed them from Jonathan Swift, who in Gulliver's Travels (1726) used them to describe the opposing positions of two factions in the nation of Lilliput. The Big-Endians, who broke their boiled eggs at the big end, rebelled against the king, who demanded that his subjects break their eggs at the little end. This is a satire on the conflict between the Roman Catholic church and the Church of England and the associated conflict between France and England. Here is the relevant passage:
It began upon the following occasion.
It is allowed on all hands, that the primitive way of breaking eggs before we eat them, was upon the larger end: but his present Majesty's grandfather, while he was a boy, going to eat an egg, and breaking it according to the ancient practice, happened to cut one of his fingers. Whereupon the Emperor his father published an edict, commanding all his subjects, upon great penalties, to break the smaller end of their eggs.
The people so highly resented this law, that our Histories tell us there have been six rebellions raised on that account, wherein one Emperor lost his life, and another his crown. These civil commotions were constantly formented by the monarchs of Blefuscu, and when they were quelled, the exiles always fled for refuge to that Empire.
It is computed, that eleven thousand persons have, at several times, suffered death, rather than submit to break their eggs at the smaller end. Many hundred large volums have been published upon this controversy: but the books of the Big-Endians have been long forbidden, and the whole party rendered incapable by law of holding employments.
During the course of these troubles, the emperors of Blefuscu did frequently expostulate by their ambassadors, accusing us of making a schism in religion, by offending against a fundamental doctrine of our great prophet Lustrog, in the fifty-fourth chapter of the Brundecral (which is their Alcoran). This, however, is thought to be a mere strain upon the text: for their words are these; That all true believers shall break their eggs at the convenient end: and which is the convenient end, seems, in my humble opinion, to be left to every man's conscience, or at least in the power of the chief magistrate to determine.
Some aspects of Unicode have come in for criticism, and there are some alternative proposals, but at least for now it is by far the most widely adopted universal encoding.
Your web browser can probably handle Unicode, provided that you have the necessary fonts installed. And you may have to explicitly tell your browser that the text is in Unicode - sometimes it can't tell. You can get a free Truetype font called Code2000 that includes just about everything here. Some text editors and word-processors can handle Unicode, but a lot of software, including the software that runs this blog, still can't, not directly and conveniently. That's why I used an image above.
Here's a little more Unicode, inserted the hard way. If your browser doesn't display it properly, you can click on it for an image.
Posted by Bill Poser at December 14, 2003 12:59 AM