December 14, 2003
Strange scrambling Alphabets
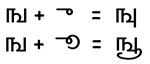 Here's a follow-up to Bill Poser's post
on Unicode. Knowing the appropriate Unicode character codes (in whatever
UTF-? presentation) is only the first step towards being able to enter, display,
edit and print documents in many of the world's languages. To give a fuller
picture of the issues, I'll add a quick set of commented links on the problem
of "rendering", that is, creating a correct visual representation
for the character code sequences representing words, phrases, paragraphs and
so on.
Here's a follow-up to Bill Poser's post
on Unicode. Knowing the appropriate Unicode character codes (in whatever
UTF-? presentation) is only the first step towards being able to enter, display,
edit and print documents in many of the world's languages. To give a fuller
picture of the issues, I'll add a quick set of commented links on the problem
of "rendering", that is, creating a correct visual representation
for the character code sequences representing words, phrases, paragraphs and
so on.
To see why rendering is a problem, look at this page on Examples of Complex Rendering and this one on Challenges in publishing with non-Roman scripts. I'll leave issues of entering and editing multi-lingual text for another time.
As for where the digital world is now on this problem, it's really complicated. Things are a lot better than they were just a couple of years ago, when Unicode was nearly useless because there were hardly any applications that could actually do anything with Unicode text, even for simple cases of "complex" rendering like single diacritics on Roman text, much less Arabic or Hindi. Today, nearly any reasonably up-to-date browser should be able to handle Arabic Unicode mixed with English, as would be required for Appendix II of Burton's First Footsteps. However, there are still lots of holes, inconsistencies and incompatibilities. You can find a relatively recent overview of the problem and (some of) the range of partial solutions here, though that page does not mention Pango or Qt (about which more below), or the progess recently made in the Java world.
The most extensive practical progress on this problem has been made by Microsoft. Internet Explorer and Microsoft Word, on recent Windows XP platforms, appear to offer the easiest context for dealing with the widest range of scripts. Here is the Introduction to a series of pages on Windows Glyph Processing that illustrate Microsoft's approach to rendering.
There are some open-source projects for rendering complex scripts that are very well designed and have great promise for the future. Here are the home pages for SIL's Graphite and Gnome's Pango projects. Unfortunately, the results have not been very thoroughly integrated into other programs and toolkits yet, so (for example) if you want to craft new interactive programs that involve rendering Arabic or Indic scripts using open-source software, it appears that your best bet at present is the (semi-open) Qt toolkit. This toolkit takes a less general approach -- it lacks a programmable rendering engine of the type represented by Graphite and Pango -- and you have to pay to develop with it for Windows platforms, but it offers a set of useful widgets that do the job well for some specific scripts right now.
There's a lot more to say -- some of it hopeful, some of it depressing -- but these links should be enough to get you started in the right direction if you're interested. One well-earned piece of advice: if you have a project that depends on scripts with complex rendering, don't believe what anyone says about their software's capacities until you see it with your own eyes, doing the kind of thing you want to do, in your own operating environment. This is not mainly because people are dishonest, though of course they sometimes are. Rather, it's because people (including me!) are often incompletely informed -- not to say ignorant -- and the situation is very complicated.
[The title of this piece is a quote from Beaumont's Psyche. More of its context can be found here.]
Posted by Mark Liberman at December 14, 2003 09:20 AM