November 11, 2005
Sex doesn't matter
At least it doesn't seem to affect conversational speech rate, and the effect on the relative time of conversational contributions is small (in mixed-sex conversations, men use about 5-6% more talk time than women). That's the result of this morning's Breakfast Experiment, in which I ran a few little perl scripts over the transcripts from a published corpus of conversational speech (Fisher English Training Speech Part 1).
This corpus comprises 5,850 conversations of about 10 minutes each, for a total of 11,700 conversational sides. It forms about a third of the set involved in my two previous Breakfast Experiments, in which I looked at the effects of speaker (and interlocutor) sex and age on the frequency of filled pauses and assenting murmurs. This time I was interested in overall word counts and time spans, which were not provided by the interactive search program that I used before, and so I had to do a bit of programming.
A typical transcript fragment (this one is from conversation 5189) looks like this:
67.53 69.74 B: my best friend is my wife
69.41 80.38 A: is that right well that's just about the same the same way with me [laughter] i can depend on her [laughter]
70.63 71.69 B: (( yes ))
82.37 89.12 A: yeah [lipsmack] well that's why i think i say i have a few special friends 'cause the ones i have are
89.45 93.62 A: special because i can always depend on 'em and and
93.05 93.70 B: (( [noise] ))
94.23 100.98 A: ah they're always there when you need 'em if you need 'em and 'course i never hardly ever need 'em so that makes it nice
101.84 103.32 B: that's how i feel
There's a relational table telling us that in conversation 5189, the A side was speaker 35043 and the B side was speaker 75769, and thre's another table telling us that speaker 35043 was a 66-year-old man with 16 years of education, raised in Oregon, while speaker 75769 was a 42-year-old man with 14 years of education, raised in California.
So for this morning's exercise, I wrote a little script that added up the time and the word count on the A side and the B side of each conversation; looked up the conversational number in the tables that defines which speakers were involved in which conversations, and printed out the results in a long list like this:
00001 A 149 773 208.5 222.446 B 138 876 212.26 247.621 2602 m.a 1790 f.a
00002 A 113 632 159.69 237.46 B 204 1451 382.64 227.525 2152 f.a 9998 m.a
00003 A 161 502 205.9 146.285 B 209 1043 344.35 181.734 5897 f.a 9997 m.a
00004 A 117 627 209.57 179.51 B 165 1001 343.32 174.939 4775 f.a 4612 f.a
00005 A 106 760 221.01 206.33 B 121 483 167.14 173.388 5334 m.a 2066 f.o
where (for example) the fifth line means that the A side of conversation #5 involved 106 segments, 760 words, and 221.01 seconds, for a speech rate of 206.33 words per minute; and was produced by speaker #5334, who was a male native speaker of American English. The B side of the same conversation involved 121 segments, 483 words, 167.14 seconds, for a speech rate of 173.388 wpm; and was produced by speaker #2066, who is a female whose dialect is "other" than American English (in fact the caller table tells us that she is a native speaker of Japanese).
The distribution of speech rates across the 11,700 conversational sides in the corpus looks like this:
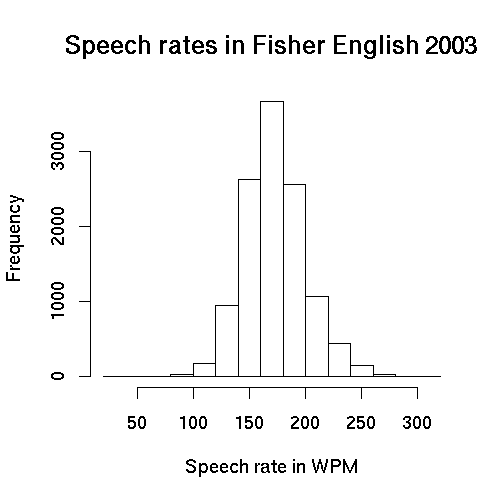
The sample mean of this distribution is 172.7 wpm, and the standard deviation is 27.23.
If we then calculate the overall speech rate of the male native speakers of American English, we get 174.3 wpm; and for female native speakers of American English, we get 172.6. (Note that these were calculated in a different way, based on the total words and the total time for a given category of speakers, instead of averaging the speech rates calculated for the individual speakers in the category.)
The overall speech rate of the men whose dialect was "other" (which was mostly non-native speakers, but also includes some native speakers of variants such as British and Australian) was 162 wpm, while for "other" women it was 160 wpm.
What about the effect of the conversational partner's sex? There wasn't much.
American native-speaker (ANS) women speaking to ANS women produced on average 907 words in 315 sec., at an average rate of about 173 wpm. ANS women speaking to ANS men produced 872 words in 303 sec., at the same average rate (173 wpm).
ANS men speaking to ANS men produced on average 940 words in 324 sec., at an average rate of about 174 wpm. ANS men speaking to ANS women produced an average of 934 words in 320 sec., for an average rate of about 175 wpm.
In mixed-sex conversations, the men on average used about 5.7% more time than the women did, and produced about 7% more words.
There were 1,694 mixed-sex conversations between native speakers of American English in this corpus, and in 931 of them (55%) the male participant took more overall speech time than the female participant. (And of course in the other 45%, the female participant took more overall speech time.)
These results, though basically negative, are not without interest. Given the general (and reasonably well supported) belief that women have greater verbal facility than men, we might have expected to see women's speech rates significantly higher than men's. However, there was essentially no difference. Given the various available stereotypes about sex and talk, we might have expected to see a large difference in average talk time in one direction or another. Of course, it's not clear which way it should go -- maybe women's stereotypical chattiness should make them talkier, or maybe men's stereotypical drive to dominate should make them the winners. Here as often, stereotypes are like horoscopes -- after the fact, they can be seen to have predicted just about any outcome. Anyhow, the effect in this case was a small one, so neither stereotype has much work to do.
[Caveats:
This corpus was created for the purpose of training speech recognition systems, not for linguistic or sociological research. The transcripts are not perfect, and neither is their alignment with the audio time lines -- in both cases, the process was designed to optimize cost-benefit tradeoffs for ASR research.
Also, the demographic variables are by no means guaranteed to be orthogonally varied -- the distribution of geography, age, educational level, conversational topic and sex may contain some relevant partial correlations. (I don't know that they do, but I also don't know that they don't.) Finally, different portions of the transcripts were done by different groups using different methods -- although nominally the same specifications.
For all of these reasons, and some other ones, conclusions based this corpus should be checked for the possible influence of uncontrolled demographic variables, and a random sample of the associated data should be re-transcribed and/or re-aligned in order to estimate the relevant rates of error and/or bias.
In my experience, essentially all sources of empirical evidence, in linguistics and in other subjects, are subject to similar sorts of questions. In this case, the good news is that all the relevant raw information -- the audio, the transcripts, and the demographic tables -- has been published, and so the empirical foundation of any results can be checked in these and other ways.
I should not need to stress that the patterns shown in telephone conversations between pairs of American strangers speaking about assigned topics are not necessarily characteristic of other kinds of conversations or other groups of speakers.
]
Posted by Mark Liberman at November 11, 2005 07:15 AM