March 24, 2006
The aperiodic song of the communications engineer
A recent paper giving an information-theoretic analysis of humpback whale song has been getting a lot of press (e.g. here, here, here). Let's leave the dissection of the MSM coverage as an exercise for the reader, and go directly to the paper's abstract (slightly abbreviated):
The structure of humpback whale (Megaptera novaeangliae) songs was examined using information theory techniques. The song is an ordered sequence of individual sound elements separated by gaps of silence. Song samples were converted into sequences of discrete symbols by both human and automated classifiers. This paper analyzes the song structure in these symbol sequences using information entropy estimators and autocorrelation estimators. [...] The results provide quantitative evidence consistent with the hierarchical structure proposed for these songs by Payne and McVay [Science 173, 587–597 (1971)]. Specifically, this analysis demonstrates that: (1) There is a strong structural constraint, or syntax, in the generation of the songs, and (2) the structural constraints exhibit periodicities with periods of 6–8 and 180–400 units. [...]
[Ryuji Suzuki, John R. Buck and Peter L. Tyack, "Information entropy of humpback whale song", The Journal of the Acoustical Society of America, Vol. 119, No. 3, pp. 1849–1866, March 2006.]
Here's the paper's description of what humpback whale songs are like:
Most humpback whales have an annual migratory pattern, breeding in subtropical latitudes during winter, and migrating to high latitude waters to feed in the summer. The vocalizations produced by humpback whales during these feeding and breeding seasons differ greatly. The feeding calls involve a few simple sound patterns produced in simple sequences (D'Vincent et al., 1985), whereas whales produce complex songs during the breeding season. The term song is used in animals, such as songbirds and whales, to describe an acoustic signal that involves a wide variety of sounds repeated in a specific sequence.
Humpback songs consist of a sequence of discrete sound elements, called units, that are separated by silence. Each song contains a complicated series of more than 12 different units. These units cover a wide frequency range (30–3000 Hz), and consist of both modulated tones and pulse trains. Payne and McVay (1971) proposed a hierarchical structure for humpback song. A song is a sequence of themes, where a theme consists of a phrase, or very similar phrases, repeated several times. A phrase is a sequence of several units. The song is repeated many times with considerable accuracy to make a song session. The reported range of song duration is from 7 to 30 min (Payne and McVay, 1971) or from 6 to 35 min (Winn and Winn, 1978). Winn and Winn (1978) also reported the maximum duration of observed song sessions to be 22 h. Throughout this paper, we use song length to indicate the number of units in a song, and song duration to indicate the number of minutes the song lasts.
This is a serious and interesting paper, deserving fuller discussion. But as a first step, I figured that turn about is fair play. Imagining myself a cetacean researcher investigating the structure of naked ape (Homo sapiens) vocal displays, I applied one of Suzuki et al.'s techniques to their own paper.
Specifically, I applied their "discrete sequence correlation" analysis to their Discussion section. The basic idea here is to line up a sequence against itself at various lags, like so:
. . . 1 2 3 1 2 3 4 1 2 3 1 2 3 4 1 . .
. . . 1 2 3 1 2 3 4 1 2 3 1 2 3 4 1. . .
____________________________________
lag = 1, number of equal elements = 0 of 14
. . . 1 2 3 1 2 3 4 1 2 3 1 2 3 4 1 . .
. . . 1 2 3 1 2 3 4 1 2 3 1 2 3 4 1. . .
____________________________________
lag = 2, number of equal elements = 0 of 13
. . . 1 2 3 1 2 3 4 1 2 3 1 2 3 4 1 . .
. . . 1 2 3 1 2 3 4 1 2 3 1 2 3 4 1. . .
____________________________________
lag = 3, number of equal elements = 6 of 12
and so on. (I'll spare you the formula, which is their equation (27)). At lags corresponding to the periodicities of the sequence -- if any -- similar units will line up, and the "correlation" (here just the length-normalized count of equal elements) will be higher. At other lags, the corresponding units will be out of phase, so to speak, and the "correlation" will be lower.
{kind=link}
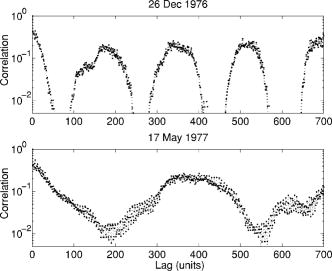
The "periods of 6–8 and 180–400 units" that they found in the whale song show up clearly in their autocorrelation plots. The 6-8 element periods, presumably corresponding to Payne's "phrases", show up in the shorter-time plots:
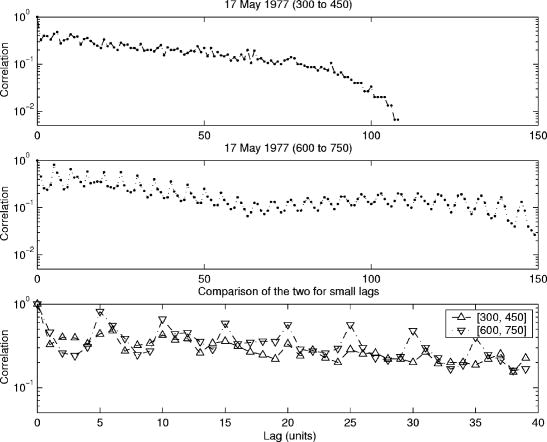
The 180-400 unit periods show up in the plots of longer-time-scale patterns:
The comparable plots for their own discussion section are much less regularly structured:
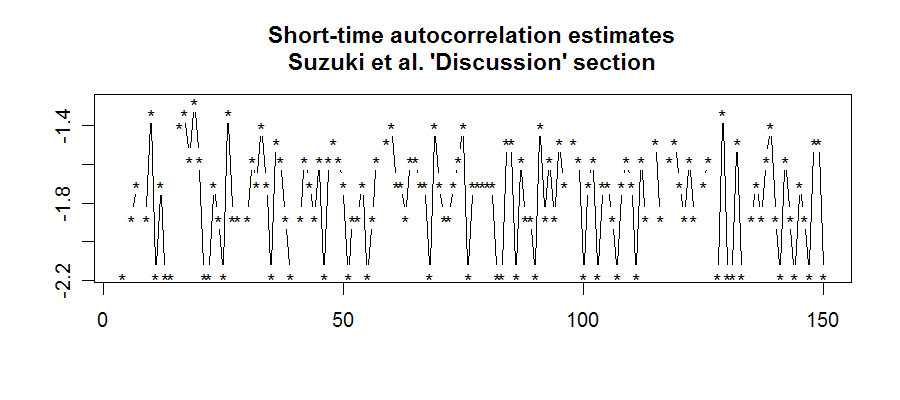
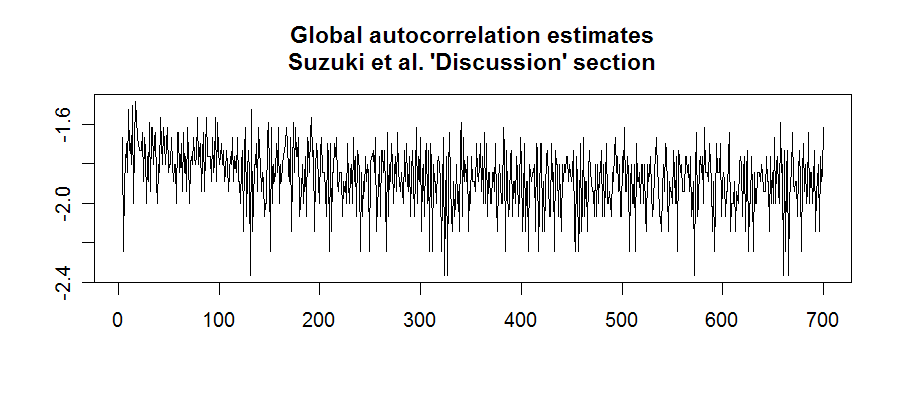
So as cetacean scientists, should we conclude that English is less regularly patterned than Humpback? Well, sort of. My comparison is rather unfair, since Humpback only has a dozen or so different "sound elements", whereas English has hundreds of thousands of qualitatively distinct wordforms. For this reason alone, the structure of English is less likely to show up in this simple sort of serial cross-correlation analysis. It might work a bit better to do the serial cross-correlation on strings of English parts of speech, or perhaps on strings of vectors in a "latent semantic analysis" subspace, or something of the sort. But however we do it, the fact will remain that Humpback song is, well, song. As Suzuki et al. explain:
A song is a sequence of themes, where a theme consists of a phrase, or very similar phrases, repeated several times. A phrase is a sequence of several units. The song is repeated many times with considerable accuracy to make a song session
While we all know people whose discourse gives this impression, the fact is that even the most boring and repetitive among us produces less rigidly patterned rhetoric than this.
Suzuki et al. make the point that the structure of these songs (the 6-8-unit phrases, the 180-400-unit groupings) means that they are not generated by a low-order markov process. On the other hand, such "songs" might be generated by various simple (non-stationary) generalizations of markov processes, such as the hierarchical markov random fields used in image segmentation, or the "hierarchical Dirichlet processes" recently discussed by Teh et al. And models of this kind have an obvious interpretation in terms of neurological pattern generators. (For those to whom this is opaque, consider it a promise to come back and explain -- if only to myself -- when I have a bit of free time...)
I first heard Roger Payne talk about humpback whale song back in the mid 1970s, and I was convinced by his talk that these displays exhibit hierarchical (though probably not recursive) structure. It's nice to see this confirmed by various quantitative means, but the confirmation is not a surprise, in my opinion. The aspect of humpback vocalizations that I found most interesting in Payne's talk, and still find most interesting today, is the social evolution of the song patterns. Here's how Suzuki et al. describe this process:
All whales in a population are singing the same or very similar songs at a given time, although whales within hearing range do not coordinate to sing the same part of the song at the same time. The songs within a population gradually change over time, so that after several singing seasons few elements of the song have been preserved (Payne et al., 1983). Several reviewers believe that the speed and pervasiveness of this change indicates that singing whales must learn each sound unit and the sequence order that make up a full song (Janik and Slater, 1997; Tyack and Sayigh, 1997). Guinee and Payne (1988) suggested that this song evolution presents a difficult learning and memory task. They proposed that humpback whales increase the redundancy of parts of phrases between adjacent themes as a mnemonic aid, and they found that this redundancy was more common in songs with larger numbers of themes where more material would have to be remembered.
This cultural evolution of humpback song has not been quantitatively analyzed or formally modeled, as far as I know: I hope that the authors of this paper (or others) will go on to do so. I've heard that the U.S. Navy has released long-term passive sonar recordings from its SOSUS program; along with recordings from NOAA and other sources, these presumably include thousands of hours of humpback whale song recorded over several decades.
[Here's an audio clip of a fragment of one of these songs.]
[As an example of how a genuine human song would show structure somewhat more like that of a humpback whale song, here's a plot of the discrete sequence autocorrelation of the lyrics to the children's song "Skip to my Lou":
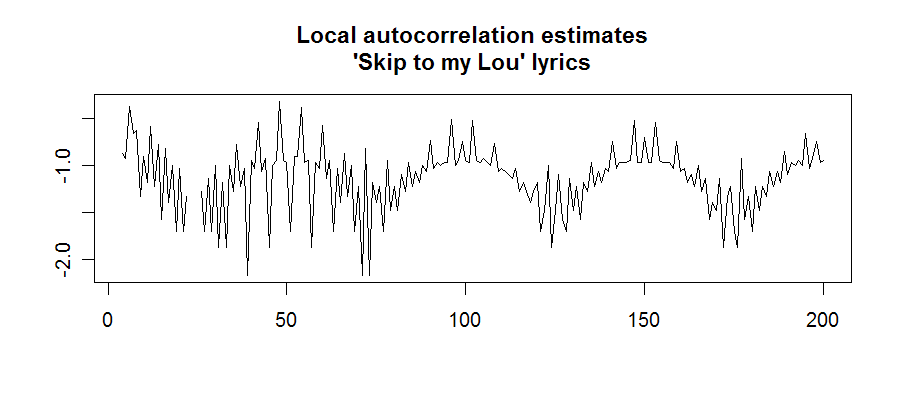
Of course, this is an unusually repetitive song -- for more normal sorts of lyrics, you'd need a more abstract representation to see the periodicity.]
Posted by Mark Liberman at March 24, 2006 06:54 AM