April 05, 2008
Trent Reznor Prize, RNR division
The Trent Reznor Prize for Tricky Embedding (Right-Node Raising division) goes to Andrew Ilachinsky, author of "Exploring self-organized emergence in an agent-based synthetic warfare lab", Kybernetes, 32(1/2): 38-76, 2003:
4.84 Universal grammar of combat. Finally, what lies at the heart of an artificial-life approach to simulating combat, is the hope of discovering a fundamental relationship between the set of higher-level emergent processes (penetration, flanking maneuvers, containment, etc.) and the set of low-level primitive actions (movement, communication, firing at an enemy, etc.).
Wolfram (1994) has conjectured that the macro-level emergent behavior of all cellular automata rules falls into one of only four universality classes, despite the huge number of possible local rules. While EINSTein's rules are obviously more complicated than those of their elementary cellular automata brethren, it is nonetheless tempting to speculate about whether there exists — and, if so, what the properties are, of — a universal grammar of combat. (emphasis added)
Mailbag: comparative communication efficiency
In yesterday's post on "Comparing communication efficiency across languages", I compared the sizes of the English and Chinese sides of parallel (i.e. translated) text corpora, and observed that English seems to require 20-40% more bits to express the same information, even after the application of compression techniques that ought to eliminate most of the superficial and local reasons for such a difference. Bob Moore sent an interesting comment:
I can think of at least couple of reasons that might explain how there can appear to be a difference between the communication efficiency of two languages. One suggests that it might only be apparent; the other explains why it might be real.
Bob's first suggestion, about how to explain the difference away:
First, I would not trust gzip to yield an accurate measure of the information content of a given text. You probably recall that Peter Brown et al. showed in their 1992 CL paper on the entropy of English that a simple tri-gram language model yields more than twice the compression of standard text compression algorithms, 1.75 bits per character vs. more than 4 bits per character. Furthermore, If memory serves, the Shannon game of guessing the next character yields a number of around 1 bit per character for English, if there is a human brain in the loop. Playing the Shannon game with the two sides of a bilingual corpus might produce a more accurate comparison than gzip.
I agree that gzip doesn't distill all the redundancy out of text, though it's a lot better than compress, which is the algorithm that produced the estimate of "more than 4 bits per character" -- the output of compress is about 85% larger on standard test corpora than the output of gzip, which in turn is about 20% larger than szip, and about 43% larger than SBC on standard test corpora. But we're looking at a comparison of information content between two sources, and that should be somewhat better estimated by standard compression techniques (even older ones like gzip), especially with respect to local factors.
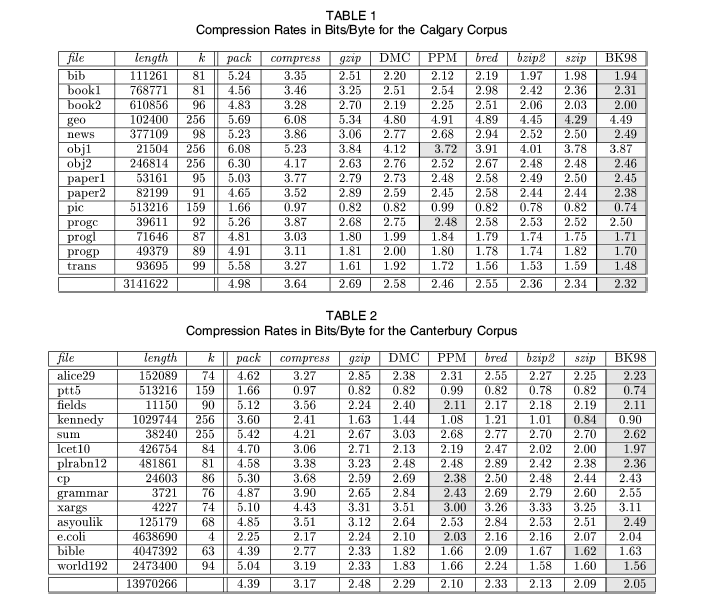
Take a look at these tables from Balkenhol and Kurz, "Universal Data Compression Based on the Burrows-Wheeler Transformation", IEEE Transactions on Computers, 49(10), 2000), comparing compression rates for different algorithms across the text files in two standard test corpora. The antique compress algorithm yields file sizes more than twice those of BK98, and gzip gives sizes about 15-20% greater -- but the bits-per-character values for different subcorpora are highly correlated across algorithms (e.g. r=0.96 between gzip and BK98 across the various files in the Calgary corpus):
While we're on the subject, let me recommend to you the classical references that Bob cites. The trigram model reference is Peter Brown, Vincent Della Pietra, Robert Mercer, Stephen Della Pietra, and Jennifer Lai, "An estimate of an upper bound for the entropy of English", Computational Linguistics, 18(1): 31-40, 1992. And while their model is "simple" compared to some other things one might think of, there's actually quite a bit to it. It models English in four stochastic steps:
1. It generates a hidden string of tokens using a token trigram model.
2. It generates a spelling for each token.
3. It generates a case for each spelling.
4. It generates a spacing string to separate cased spellings from one another.
A genuinely "simple" trigram model, in which case, spelling and spacing were simply handled by multiplying the number of tokens, would not have done as well.
In their paper's famous conclusion, Brown et al. take care to note all the things that they are leaving out:
From a loftier perspective, we cannot help but notice that linguistically the trigram concept, which is the workhorse of our language model, seems almost moronic. It captures local tactic constraints by sheer force of numbers, but the more well-protected bastions of semantic, pragmatic, and discourse constraint and even morphological and global syntactic constraint remain unscathed, in fact unnoticed. Surely the extensive
work on these topics in recent years can be harnessed to predict English better than we have yet predicted it.We see this paper as a gauntlet thrown down before the computational linguistics community. The Brown Corpus is a widely available, standard corpus and the subject of much linguistic research. By predicting the corpus character by character, we obviate the need for a common agreement on a vocabulary. Given a model, the computations required to determine the cross-entropy are within reach for even a modest research budget. We hope by proposing this standard task to unleash a fury of competitive energy that will gradually corral the wild and unruly thing that we know the English language to be.
The history of efforts to estimate the entropy of English by asking human to guess the next character in a text begins with another one of Bob's references: Claude Shannon, "Prediction and entropy of printed English", Bell System Technical Journal ,30:50-64, 1951. Shannon came up with a range of 0.6 to 1.3 bits per character.
A quarter century later, Cover and King ("A convergent gambling estimate of the entropy of English", IEEE Transactions on Information Theory", 24(4):413-421, 1978) used a slightly different technique to sharpen the estimate to 1.25-1.35 bits per character.
Unfortunately, the Shannon/Cover-King results are not strictly comparable to the Brown et al. results, nor to the other algorithmic compression-rate results. The experiments test on different texts, deal with various formatting issues in different ways, estimate entropy by different methods -- and especially, they have radically different standards for how to amortize the entropy of the "dictionary" and other prior knowledge involved. The techniques based on human guessing don't add any cost for transmitting knowledge of English (as opposed to Chinese or French or whatever); the same is basically true of the Brown et al. study, as I recall, since they simply base their estimate on the cross-entropy of the test text given the model, without any provision for transmitting the model. In contrast, the other algorithmic compression techniques start out equally ready to compress text from any source, and must build up and encode their expectations incrementally in the compressed output.
Anyhow, I think that modern compression techniques should be able to remove most of the obvious and simple reasons for differences in document size among translations in different languages, like different spacing or spelling conventions. If there are residual differences among languages, this either relates to redundancies that are not being modeled -- along the lines sketched in Brown et al.'s conclusion -- or it reflects a different sort of difference between languages and cultures, which Bob Moore picks up in his second point:
Second, why should we expect two languages to use the same number of bits to convey the same thoughts? I believe that when we speak or write we always simplify the complexity of what is actually in our heads, and different languages might implicitly do this more than others. Applying Shannon's source/channel model, suppose that when we have a thought T that we want to convey with an utterance U, we act as if our hearer has a prior P(T) over the possible thoughts we may be conveying and estimates a probability P(U|T) that we will have used U to express T. As you well know, according to Shannon, the hearer should find the T that maximizes P(U|T)*P(T) in order to decide what we meant. But the amount of effort that the speaker puts into U will determine the probability that the hearer will get the message T correctly. If the speaker thinks the prior on T is high, then he may choose a shorter U that has a less peaked probability of only coming from T. If I say to my wife "I got it," I can get by with this short cryptic message, if I think there is a very high probability that she will know what "it" is, but I am taking a risk.
My conjecture is that the acceptable trade-off between linguistic effort and risk of being misunderstood is socially determined over time by each language community and embodied in the language itself. If the probability of being misunderstood varies smoothly with linguistic effort (i.e., bits) without any sharp discontinuities, then there is no reason to suppose that different linguistic communities would end up at exactly the same place on this curve.
Tru dat.
And before we get into cultural differences in tolerance for optional ambiguity and risk, note that simple differences in morphology and syntax are likely to have a significant effect here. Definiteness and plurality are somewhat redundant, but by no means entirely so; and they are sometimes relevant, but by no means always so. Therefore, if a language insists on marking definiteness and plurality on every noun, it forces more entropy into the channel. Similarly, requiring explicit as opposed to null pronouns will increase the explicit information content.
In my earlier post, I tried to estimate how much effect such differences between Chinese and English could have, and I came up short of the observed differences in compressed text size. Maybe my back-of-the-imaginary-envelope estimates were inadequate; or maybe gzip isn't good enough to eliminate some of the effects of differences in superficial orthographic conventions. But I have to admit that there might also be a difference in some sort of cultural set-point for communicative specificity.
[Note to self: try some better text compression progams (like SBC) on parallel-text archives, and see if the differences hold up.]
April 04, 2008
Yet another "yeah no" note
Following up on "Yeah no" and "'Yeah no' mailbag" (4/3/2008), Russell Lee-Goldman writes:
I was actually about to send a long email to you about yeah-no, but decided just to put it on my blog.
That's "Yeah-no and no-yeah again", Noncompositional (3/4/2008).
But one highlight that might interest you is that I found a token of "yeah no" while trolling through archived NPR transcripts on lexis-nexis: it's Geoff Nunberg in Talk of the Nation, April 2nd 2004. The lead-up to the "yeah no" starts at around 10m:30s into his segment of the show.
See Russell's blog post for a transcript and discussion. If I were breaking into the conversation at this point, I might observe that
Yeah, no, well, in fact "yeah no" is pretty much the thematic idiom of NPR.
That is, if I were the sort of person who makes such facile generalizations, which I'm not.
But here are a couple of random examples anyhow. On Science Friday, 4/30/2005, a caller asks whether math is "part of the structure of our mind and reality". Ira Flatow says "Hang on. I've got to get a reaction from Keith Devlin, if he dares to react to that." And Keith Devlin responds:
Yeah. No, and in fact, that's what my book "The Math Instinct" is all about.
On Talk of the Nation, 10/7/2003, Scott Simon asks Ivo Daalder and Todd Lindberg for reactions to Condoleeza's Rice's appointment as head of the Iraq Stabilization Group, and after each has had a turn, Daalder continues with
Yeah. No, no. I mean, I think that's right, we didn't quite know what was going on, but we had some experience.
Russell's note continues:
I also have to mostly agree with you wrt to this: "The null hypothesis, I think, would be that yeah, yes, no, oh, etc. each has its own function, and speakers emit instances of such words randomly as functionally appropriate." In all the cases of "yeah-no" (and "no-yeah") that I've looked at (mostly switchboard and fisher transcripts, also some multi-party meeting recordings) you can identify a function that each of the yeas and nos has, and they correspond almost exactly to functions that they have -individually-. It just might be that certain situations "call for" combinations of these uses, and so you get more yeah-nos than you might expect. But it's not really much different, I think, from other combinations like "oh no" and "so yeah" - it's just that the canonical meanings of "yeah" and "no" are antonymic, so we might wish to attribute the whole collocation with some special meaning before checking all the
facts.I'm working on this stuff for one of my qual papers - look forward to all the answers being laid out therein. (he said sarcastically).
Russell added in a follow-up email:
I just noticed your reporting of Justin Levitt's observation: "I'll just end by noting that I hear "I mean" following "yeah, no" a whole lot. Maybe this indicates people are aware of the ambiguity? I certainly say "yeah, no, I mean I liked it, but...""
This is really great, because it corroborates Schegloff's analysis of this particular use of "no" (to introduce corrections of misunderstandings, to put it grossly) - which he says is often followed by some indication of a correction, such as "I mean."
That's Emanuel "Manny" Schegloff, who has written extensively on conversational corrections over the past 30 years. In fact, this is almost the 30th anniversary of Emanuel Schegloff, Gail Jefferson and Harvey Sacks, "The Preference for Self-Correction in the Organization of Repair in Conversation", Language 53(2): 361-392, 1977.
I also need to point out that there's a band named "yeah NO", founded in 1996.
[Update -- Ian Preston writes:
I hope you don't mind uninvited responses from strangers to your very interesting blog, but, given that you point this out, I thought you might be interested to know there was a band called "Yeah Yeah Noh" working out of Leicester between 1984 and 1986, sufficiently well thought of to have had a compilation album issued twenty years later. (I know this since the guitar player is my cousin). I have no idea of the linguistic origins of their name.
]
Textbook ambiguities
Many -- indeed, most -- linguistic expressions have more than one meaning. An apparently trivial observation, but one that leads to all sorts of puzzles in linguistic analysis and theorizing. The central question is how meanings are associated with linguistic forms, and the answer cannot be that speakers have just memorized all these linkages (though they can have memorized some of them). Instead, we need to look for some kind of compositional account, in which meanings of smaller expressions and meanings associated with syntactic constructions work together to predict meanings of larger expressions. One crucial thing such an account has to manage is predicting, both accurately and completely, the range of ambiguities in complex expressions.
There's a huge literature on the subject, including textbook discussions of various ways in which ambiguities can arise. As it happens, my recent mail has brought me in-the-wild examples of ambiguous sentences of just the sort in textbooks.
From a NYT Magazine piece "Students of Virginity" by Randall Patterson (3/30/08, p. 41):
And the head on a piece on the Denver Post website (2/15/08) by T. J. Wihera:
Textbook discussions of ambiguity usually start with really simple cases, in which the ambiguity can be traced back to a word that represents two or more distinct lexical items --
or two or more senses of a lexical item --
These are "lexical ambiguities" (sometimes called, misleadingly, "semantic ambiguities"). Things then move on to ambiguities in which syntax is crucially involved. In some examples of "syntactic ambiguity", differences in constituent structure distinguish the different readings; these are sometimes called "phrase structure ambiguities". The ones that are easiest to find usually involve lexical ambiguities as well as structural differences:
[how good] [beer tastes] (with degree how)
(not to mention the celebrated We saw her duck). But you can unearth cases where the ambiguity is purely structural. The classic example is
[old men] [and women] 'women and old men' (a "narrow" reading)
made famous in Charles Hockett's A Course in Modern Linguistics (1958:153). This is what we have in (1), the quote about the Anscombe Society. Elizabeth Daingerfield Zwicky, who pointed me to the quote, commented:
Elizabeth read "homosexual sex and marriage" at first as having the narrow reading, as did I, but the writer intended the distributed reading. The narrow reading is favored by the fact that lots of people don't use "homosexual marriage" for this referent: "homosexual marriage" gets 610,000 raw Google webhits; "gay marriage" gets a bit more, 758,000; but "same-sex marriage" (which is the term I use) gets a whopping 5,450,000. In general, the favoring of one reading of Adj Npl and Npl or the other depends on the adjective and the nouns involved and turns crucially on context, real-world knowledge, and expectations. "Young children and linguists" will probably get the narrow reading, even out of context (why would we treat young children and young linguists together as a set?), but the classic "old men and women" seems to get the distributed reading almost all the time, to judge from the Google webhits (old men and old women obviously constitute a natural class for many purposes, but putting women and old men into a class would require considerable support from the context).
It turns out that ambiguous Adj Npl and Npl appears in Brians's Common Errors, but in a surprising place, the middle of his entry on Dangling and Misplaced Modifiers. The general principle is formulated first:
Then, between a discussion of more-or-less classic danglers in which the modifier is separated from the expression it is said to modify and those in which there is no expression at all in the sentence for the modifier to be associated with (and then a discussion of the placement of adverbs like only and even) comes:
I'd guess that Brians wanted to discuss this modifier ambiguity, but had no error category to put it in other than Dangling and Misplaced Modifiers, though that's a stretch.
Enough of purely structural ambiguities, and on to ambiguities that appear to be neither lexical nor structural, like (2), I love my dog more than you (which came to me from Victor Steinbok on 2/26/08; Steinbok had earlier sent me a similar example, I will miss you more than anyone else). The ambiguity here has to do with whether you, the object of than, is understood as parallel to I, the subject of love, or as parallel to my dog, the direct object of love: 'I love my dog more than you love my dog' vs. 'I love my dog more than I love you'. In this case, the second reading is more plausible than the first, and that turns out to be the intended reading; the piece begins:
In general, the reduced comparative
'X Vs Y more than X Vs Z'.
Back in the old days, (2) would have been classified as a "transformational ambiguity": an expression with one assignment of words to lexical items and one constituent structure is analyzed as deriving from two different "remote structures" via the application of syntactic "transformations", operations that alter structures in systematic ways. In the case of (2), the remote structures would be essentially those of the glosses above for (2), and a transformation deletes material in the subordinate than-clauses that duplicates material in the main clause, leaving Z as the (elliptical) remnant. The semantics of the two readings comes from the remote structures.
There are non-transformational alternatives. For instance, we could see the problem of analyzing (2) as the problem of finding antecedents for elliptical elements in (2), that is, as a problem of assigning interpretations to anaphoric (in particular, zero-anaphoric) material. A similar treatment could be offered for the ambiguity in Verb Phrase Ellipsis examples like
'No one has organized the party'
she refers to Mary
Other textbook cases of "transformational ambiguity" share with (2) a central involvement of syntactic functions. For instance, from John Lyons's Introduction to Theoretical Linguistics (1974), the examples (from various original sources):
God understood as the direct object of the verb love
the shooting of the hunters
the hunters understood as the direct object of the verb shoot
Flying planes can be dangerous.
planes understood as the direct object of the verb fly
These have fairly straightforward non-transformational analyses, in which different constructions pair somewhat similar syntactic forms with different semantics. Such an analysis is also possible for (2): there would be two comparative ellipsis constructions, one with the remnant NP understood as a subject, the other with the remnant understood as a direct object. [There is even a prescriptivist tradition, going back to Lowth in 1762, according to MWDEU, which calls for different pronoun cases in the two constructions: Kim likes Terry more than I (nominative) vs. Kim likes Terry more than me (accusative). But accusative case in both constructions has a long history -- this is usually described as involving a preposition than rather than a conjunction -- and many current speakers and writers simply cannot use a nominative in the first construction; for them, than is just like before and after with NP, as in Kim left before/after me/*I 'Kim left before/after I did'.]
An infuriating Cupertino
Audrey Devine-Eller writes in with the latest entry for the Cupertino files. This spellchecker-induced gem is from the Student Personnel Services page on South Brunswick (NJ) High School's website:
In early August, all rising sophomore, junior and senior students will receive an unofficial copy of their transcripts. You should carefully review these for all infuriation: demographic data, courses taken, final grades earned, credits earned, participation in activities. If there are any errors, please follow directions for making corrections.
A likely suspect here is the misspelling "infurmation" getting miscorrected to "infuriation" rather than "information". But since the "edit distance" to "infurmation" from the two possible words is the same (a one-letter substitution in each case), I'm not sure why a spellchecker would rank "infuriation" more highly on its list of suggestions, especially considering "information" → "infurmation" involves a vowel-to-vowel substitution rather than a vowel-to-consonant substitution.
Whatever the source, it's pretty easy to find further infuriating cases online:
Conference themes centred around the issues of human resource development, democracy and infuriation literacy, quality, knowledge management and future roles for the information specialist. (link)
INLEX/3000 libraries with Sirsi Web2, Version 1.2 should refer to Sirsi Web2 Release Notes for INLEX/3000 Systems (Version 1.2) page B-8 for detailed configuration infuriation. (link)
For more infuriation about the Girl Scout Fall Product Sale call the Kay County Girl Scout Headquarters at 405-762-9616. (link)
Use "REGULAR" when the infuriation should be broadcast during a regular news time. (link)
GIS is considered to be a strategic infuriation technology that is consistent with the evolving corporate information technology infrastructure. (link)
After the students were done with this recall task, they were asked two questions about adaptation that required them to "go beyond the infuriation given" in the actual passage and transfer or apply the information to a different situation. (link)
We are truly living in an Age of Information Infuriation.
[Update: James Dreier writes: "My (Word) spellcheck does give 'information' as the first correction for 'infurmation', but as the first correction for 'inforiation' it gives 'infuriation'. So maybe that's the explanation." Indeed, that does seem plausible.]
Comparing communication efficiency across languages
In response to last week's post on comparative vocabulary size ("Ask Language Log: Comparing the vocabularies of different languages", 3/31/2008), a number of readers sent observations about a related but different topic, namely the comparative efficiency of communication. At least as measured by crude metrics such as bit counts, there are differences among languages that are not easy to explain.
Alex Baumans described a bilingual magazine's problems in equalizing space and word-count allocations between Dutch and French:
I read your discussion about the proportion of words of a language that is actually in use. A very thought provoking piece. My view is that any attempt to compare languages will fail, if the word formation rules of the languages differ too much.
I work as a journalist for a HVAC magazine in Belgium. As Belgium is bilingual, out publication exists in parallel Dutch and French versions. For obvious reasons, articles are supposed to be about as long in both languages. However, this provides endless problems, the Dutch text being on average 15-20% shorter, and the word count is way out.
One of the reasons (besides French orthography insisting on writing lots of letters that are not pronounced) is that Dutch, like German, can form compounds on the spot. Usually these are written together. Especially in technical terms, this is useful. A wall hung gas fired boiler is simply gaswandketel, as opposed to chaudière murale à gaz. How many words is that?
Similarly, if you accept these compounds as words, the upper limit to the number of Dutch words, is a lot less clear than, say, in French. Your example of Arabic and Spanish dealt with writing conventions and morphological variation. One can compensate for this in a way in a counting system. It becomes much more difficult if there are differences between languages as to what is exactly a word.
Alex's discussion of Dutch compounds underlines a point that I made in the earlier post, namely that spaces are not a very helpful way to define the boundaries of words, especially in comparisons across languages. But what I'd like to follow up on today is his observation about comparisons of word and character counts.
As discussed in a post a few years ago ("One world, how many bytes?", 8/5/2005), based on a variety of large collections of English-Chinese parallel texts, English texts are larger than their Chinese counterparts by a factor of between 1.37 and 2.27 before compression, or 1.19 to 1.41 after compression.
My impression is that there are several different factors at work here -- but they don't seem to me to account fully for the differences in length, especially in comparing compressed texts.
Consider a crude estimate of differences in character-encoding efficiency in uncompressed texts. Whether GB or Big-5, I believe that fewer than 5,000 characters are actually used in these Chinese texts, representing less than 10% of the 65536 that could be encoded in 16-bit characters. In the English texts, most of the 95 printable ascii characters will be used, representing something like 35% of the 256 possibilities afforded by 8-bit characters.
However, this difference should be eliminated by standard compression techniques, which will also take advantage of the entropy-reduction implicit in the non-uniform frequency of the characters as used.
English text puts spaces between words, and as a result, 15-20% of the characters in English text are white-space characters. Chinese doesn't bother with spaces, which should give it an advantage in concision. But again, compression techniques should eliminate most of this advantage, given that the spaces in English text are mostly redundant.
Chinese lacks the equivalent of the English articles a and the. These are common words, but (even with their separating spaces) they only amount to about 5% of English text, so not very much of the difference can be blamed on them. The impact of plural marking and verbal inflection must also be quite small, no more than a couple of percent in uncompressed text -- and Chinese loses some of this ground because of obligatory classifiers.
So I remain puzzled about why English texts, even after state-of-the-art compression, are 20%-40% longer than their Chinese equivalents.
A topic for another time: how do typical speech rates differ between languages? Do these interact with per-syllable measures of information content so as to equalize the average rate of information transmission?
April 03, 2008
"Yeah no" mailbag
I've gotten a number of interesting messages about this morning's "Yeah no" post, and I also found the time to transcribe and discuss one typically complex example that turned up among the 5,000-odd hits in the search I did on LDC Online. Details below...
Steve at Language Hat pointed out, in the nicest possible way, that he scooped me back on 6/13/2004 ("Yeah no"). His post cites an article in The Age, which quotes Kate Burridge:
Professor Burridge says the phrase falls into three main categories, each determined by context. The literal agrees before adding another point, the abstract defuses a comment and the textual lets the speaker go back to an earlier point.
The next time a footballer answers "yeah no", be aware that there is more to the reply than just an "um-ah" prefix. In this sporting context, Professor Burridge says "yeah no" is often used in its abstract context; as a way to defuse a compliment by a bashful footballer.
"You've got to downplay the compliment but you can't reject it because that seems ungracious. It's a complicated little thing."
There's lots of interesting stuff in the comments on his post, as usual.
Coreen Eaven Moore sent me a copy of Burridge et al. 2002, and I'll look at that and at Moore 2007 to try to figure out what the similarities and differences between the Australian and American usage in this area are.
Peggy Renwick writes:
I wonder if 'yeah no' helps indicate enthusiasm or emphasis on the part of the speaker.
Bryan Van de Ven writes:
I've recently noticed myself using "yeah no" quite often. I'm not actually sure where I picked it up (I'm 34 and male FWIW). However I seem to most commonly use it in situations like:
A: Do you want to go to XYZ?
B: Yeah, no I hate that place.By which I evidently meant "Certainly not" or "Definitely no". As I said, I have no idea where I got this from!
Carl Carlson writes:
This is certainly a phrase that I (a 24 yr old male) use a good bit, and for me, it seems to be a clipped version of "Yeah, I know."
Tam writes:
I think when I use this, the "no" is there to indicate that the "yeah" might have been unexpected.
Q: Do you like sushi?
A: yeah no it's really good
But this is based on mostly useless introspection. Still, it's how I read some of your examples.
Jesse Bangs writes:
Reading your post this morning on LL reminded me of a similar Romanian construction using the word "ba". "Ba" usually means "no", especially in contexts of contradiction:
Gabi este frumos. Ba, este urât. ("Gabi is pretty. No, he's ugly.")
However, the word is often paired with "da" ("yes") where no contradiction is implied, merely to strengthen the affirmation:
Vrei îngheţată? Ba da! ("Do you want ice cream? Yes!" )
This is just one example, but it makes me wonder whether there isn't a cross-linguistic tendency for negatives to become intensives.
But PF commented on Language Hat's site:
Да нет, on the other hand, means extra no. Odd.
And Bryn LaFollette writes in with some scholarly analysis, complete with quotations from the classics:
I found your post this morning on "Yeah no" in English pretty interesting, and I wanted to share some of my thoughts on its usage. This construction is definitely a very natural part of my own ideolect, and from what I've observed it's a well ensconced usage of the broader urban California dialect area (e.g. I've noticed its use throughout LA, San Francisco, Santa Cruz, and Sacramento, to name a few places).
Anyhow, my personal impressions as a speaker of a "Yeah no"-dialect is that it seems to serve at least two discourse functions: the first is that of answering in agreement to a negative question, and the second is that of answering in agreement to a question (positive or negative) but with a contrastive substitution.
Some examples of these, respectively:
A:"You're not going to Black Rock this year?"
B:"Yeah, no, I just can't afford it."
A:"Did you like the movie?"
B:"Yeah, no, it was great!"
The former usage caught my attention at one point because it reminded me of using "si" in French as an answer to a question (as opposed to "oui" or "non"), although in that case it's sort of the opposite, answering in disagreement to negative question with its positive. My intuition is also that the former situation is the only one in which "No, yeah ..." is really possible, though counterexamples may just not be occurring to me at the moment, and I'm not sure but "yeah" in this case may be more of an interjection. As for the latter use, I think it's probably the most prevalent, and I could see how the meaning could be confused with some sort of blanket replacement of "Yeah" or "No" by someone not familiar with the usage, although they're all pretty clearly contrastive to me. Further, I don't think "Yeah no" in my thinking of it is a fixed phrase, but rather the sequencial usage of "Yeah" and then "No" (which introduces the modified statement).
There's a great example of discourse play using this construction in the film "Knocked Up" in which one character is looking for another's approval about their new haircut. This isn't exactly accurate, but the exchange goes something like this:
Jay: So, do you think my haircut looks ok?
Jonah: Yeah, no, it's great.
Jay: You really think so?
Jonah: Yeah, no, it totally looks horrible.
Jay: What? You think it looks horrible?
Jonah: No. Yeah. Yeah, no, it's great. I really think it looks aweful.
Jay: You're messing with me!
Jonah: Yeah, no, it sucks.
There are other more conventional examples in the film of 'Yeah, no', like the following:
Ben: "Last night was great, what I remember of it."
Alison: "Right, yeah. Yeah, no, it was fun. We had a great time."
Overall, I find this a pretty natural construction and although Mr. Hutson sees it as a replacement of normal usage of "Yeah" or "No" (which gives me the impression he's fishing for a validation of a "Downfall-of-English" ambiguity claim), I would disagree and say that it has a specific and distinct function in discourse.
I'm afraid this copy of the script (probably not the final one) has no "yeah, no" instances in it at all, so it remains for future scholars to determine who had the idea to introduce this idiom into the dialogue.
Here's a more-or-less random "yeah no" passage from one of the conversations in the LDC collection, which may help to illustrate some of the points in the emails above, but also makes another one.
The two participants in this highly interlaced conversation sprinkle their speech liberally with uptake markers of various sorts -- 6 yeah, 4 no, 2 mm-hm, 1 exactly, 1 "I totally agree" in about 150 words, about 10% of their total word count. And they sometimes produce them in spurts: "yeah yeah no I totally agree", "yeah no no I-", "mm-hm yeah no I-". It's often difficult to decide whether two such markers in sequence are independent contributions or parts of a single communicative gesture.
These spurts do seem to be more emphatic or enthusiastic than individual uptake markers are.
It's also true that when I listened carefully to one sequence transcribed as "yeah yeah no I totally agree" (the second clip listed below), I had a hard time deciding whether it was really "yeah yeah no" or "yeah yeah ((I)) know". The point is, in this particular context, it's not only hard to tell what was said, but in fact either choice would be pragmatically appropriate. I don't believe that "yeah I know" is overall an adequate source for instances of "yeah no", but it's easy to see how someone who is a not a core "yeah no" speaker might come to that conclusion.
A: so uh-
B: yeah I think it's kind of- it's kind of sad in a way, ev- even though I see what you # mean
A: mm-hm
B: but # it's kind of sad in a way when something like that brings you back to-
even though I think it's a good thing, you # know what I mean?
A: yeah yeah no I totally ...
B: yes
A: ... agree and-
B: that sometimes I think it takes something to get-
you know, to kind of wake you up and I don't know ((it's been the same way-))
A: # yeah. no no I-
B: ... same in our family
kind of wake you up and spend time together and, # you know- ((and so))
A: mm-hm. # yeah, no I- it's-
it's definitely kind of like a contradiction, because I mean-
it's not that before that-
you know we weren't tight ...
B: exactly
A: and that we didn't # see each other, it's was just kind of like [breath]
not as intense, and now it's # like "oh!"
B: probably more haphazard than
A: yeah
B: ... in the ...
The null hypothesis, I think, would be that yeah, yes, no, oh, etc. each has its own function, and speakers emit instances of such words randomly as functionally appropriate, sometimes more than one in a row. This is probably false, if only because the various different orders of pairs are typically very different in frequency: "yeah yeah" and "no no" are about equally common, but "yeah no" is about five times commoner than "no yeah".
So then the challenge becomes to describe and explain the stochatic grammar of these little spurts of uptake markers. Can we provide a plausible account based only transition probabilities among the basic words, and a compositional pragmatics with each contributing its invariant mite? Or do we need lexicalized sequences, or the equivalent? A bit more data: "yeah I" is about 5 times commoner than "no I"; "oh yeah" is about seven times commoner than "oh no"; "yeah yeah" and "no no", equally common, are both about sixteen times commoner than "yeah no". No problems so far -- but there are a lot of pairs to consider.
A few more emails...
Mae Sander writes:
I was sure that your post this morning was the first time I heard of the "yeah/no" thing. At noon I attended a very pedantic academic lecture on the University of Michigan campus. In answer to the first question, the speaker (a postdoc with a very recent PhD from Berkeley) started her answer "yeah, no."
The Recency Effect in action!
Rich Gerber writes:
It's not a "Yeah no" thing, but your Language Log post this morning reminded me of the time my mechanic once said to me in conversation:
"You know, you never know, you know."
Unfortunately now I actually don't know what exactly he was referencing at the timewhich maybe just goes to prove his point.
That had to be ten years ago and I still can't help but chuckle when I think of it. He obviously didn't even have any idea of having said it just that way.
I, on the other hand, know the exact source and context of this little gem (previously cited here). This also has nothing to do with "yeah no", but as long as we've drifted off topic into found epistemic poetry...
It's like I mean
I just didn't know.You know everyone tells you
you don't know,
you don't know,
you don't know.
And the thing is, you don't know.
So you don't even know that you don't know,
you know what I mean?It's like-
I don't know.
To listen:
[Update -- Lynne Murphy writes:
My South African English books are at the office (and I'm not) so I can't give you all the details, but putting contradictory yes-no things at the beginning of sentences has long been happening in South African English, where the Afrikaans ja-nee is used or calqued.
The phrase that's most often commented upon is 'ja well no fine'. It's not the same as the yeah-no thing you've been talking about, but kinda interesting anyhow. Grant Barrett has it in his double-tongued dictionary.
Also here: "The common informal phrase ja well no fine (yes well no fine) has been adopted in solid written form as an affectionate expression of ridicule (jawellnofine) for broad SAfrE usage, and has served to name a South African television programme."
]
[Justin Levitt writes:
I'm a grad student in political science and frequent reader of Language Log. I just wanted to add my observations. I've heard the expression used in two different ways:
1. As a sarcastic way of saying "no", generally toward questions where even the speaker knows the answer is "no". i.e.:
"Will you let me drive your new BMW?"
"Yeah, no"
Sometimes the "yeah" is drawn out slightly nasally, so it becomes more like "yeeeeeah, no".2. As a hedge implying complexity to the answer: it answers a statement implying either a yes or no answer but where your answer is neither simply yes or no, but one of the following:
A. More intense:
"Do you like pizza?"
"Yeah, no, I love it!"
or
"You don't like sushi, right?"
"Yeah, no, I hate it."
B. Added information (true example from two nights ago):
"President Bush is such a moron!"
"Yeah, no, but he believes that what he's doing is right"
or
"Did you like the pizza place we went last night?"
"Yeah, no, it was good, but I think I like the one we went last week better."C. Shift the topic to something related but different to avoid a direct answer:
"You like that movie we went to Saturday?"
"Yeah, no, I like romantic comedies."
or
"Do you drink?"
"Yeah, no, I'm not a big fan of getting drunk."I'll just end by noting that I hear "I mean" following "yeah, no" a whole lot. Maybe this indicates people are aware of the ambiguity? I certainly say "yeah, no, I mean I liked it, but..." pretty often :)
I hope that Justin finds a way to apply to political science his interest in linguistic analysis...]
[Kaushik Janardhanan writes:
One version of the "Yeah-No" syndrome is very prevalent in India. I think it has its roots ion the vernacular and has moved on to English. But reading your interesting series on this, it looks like it could have been imported as well.
This version conveys the meaning of "Yes. Wasn't it so?" as in
X: "I watched the match last night"
Y: "Me too. Classy batting by Sehwag"
X: "Yeah no"Another related usage; to convey an expression of comprehension - "Yes. Isn't it so?" to mean "Yes. So it is!". Something akin to 'mea culpa'. But this happens more (always?) with "Yes-No" rather than "Yeah-No".
X: "Why did you tell him about it?"
Y: "Well, because.."
X: "But, don't you know that he will tell everyone now about it?"
Y: "Yes, no!"
]
[More here.]
Saying it wrong on porpoise
Grant Barrett is now doing a weekly language column for the Malaysia Star, and this week he talks about saying things the wrong way on purpose — intentional errors like the Internets and coinkydink. The column got picked up by Jason Kottke's blog, where commenters are chiming in with their own examples.
Just in case anyone thought this was a new phenomenon (hello again, Recency Illusion), an article on "Intentional Mispronunciations" appeared in the journal American Speech way back in 1932. If you don't have access to JSTOR and you're not a member of the American Dialect Society, you'll have to make do with this recent summary by Larry Horn on the ADS mailing list:
Margaret Reed (1932), "Intentional Mispronunciations". American Speech 7: 192-99.
This covers what Reed took to be a fad among the "light-hearted youth" of Central Westerners (she's writing from Nebraska) to circulate...well, intentional mispronunciations. (She's following up on a paper by Louise Pound from 10 years earlier in Dialect Notes.) Her categories include everything from adding or subtracting syllables and restressing (antique as "an-tee-cue", "champeen", "the-'ater"), tensing lax vowels ("genu-wine"), borrowing of "vulgar" pronunciations ("agin", "extry", "who'd-a thunk it", "varmint"), "Al Smith" English [a.k.a. Brooklynese, not a moniker Reed herself applies] ("boid", "noives", "toity-toid street", "winegar woiks"), the "extremely annoying" affectation of children's speech ("sojer", "sword" [with /w/, as we've been discussing recently], "Injun", "ax" for 'ask' [!-- she does add 'also archaic' for this], "itty bitty"), Yiddishisms ("epple", "darlink", "dun't esk"), various other dialect borrowings ("enyhoo", "pitcher" [for 'picture'], "divil"), blends and folk etymological forms ("bumbershoot", "brass-ear", "animule", "absotively"), misdivisions ("a tall", "a norange", but not "a whole nother"), spelling pronunciations ("k-nife", "g-nat", "X-mas"), and so on. She ends with the wistful hope that while "human nature" may be responsible for perpetuating this fad (or these fads--unclear how many causal factors are involved), "surely, in its fullest and most extreme form, the phenomenon is now passing its peak".
And of course we could take things back a century before that, to the 1830s, when a fad in comical misspellings eventually led to the popularization of O.K. (as definitively proven by Allen Walker Read in a series of American Speech articles in 1963-64).
Yeah no
Matt Hutson writes:
There's a phenomenon that has interested me for a while, and I noticed a extreme example last weekend. When people mean "yes" they sometimes say "no, yeah" or "yeah, no" and when they mean "no" they say "yeah, no" or "no, yeah" or even "no, yeah, no."
On Saturday I was sitting next to someone at a lunch, and I counted four consecutive times when she said "yeah no" in place of "yeah." For example: "Did you like Columbia?" "Yeah no I loved it." (In fact, once I started looking for it, I never heard her say a simple "yeah.") The "no" was almost imperceptible each time, as the meaning was clear, and adding it is a common practice in speech.
Do you have any insight into the practice? Patterns in gender or age or situation or setup?
Well, there's Vicky Pollard's catch phrase "yeah but no but yeah but ...". Unfortunately, I don't know how to evaluate British class caricatures.
So for this morning's Breakfast Experiment™, I'll take a look at the use of "yeah no" in the LDC-Online (mostly American) English conversational speech transcripts, previously described here. (I'll leave the sequences "no yeah" and "no yeah no", which are significantly less frequent, for another morning.)
The sex and age part is easy, so let's do that first. There were 3,038 conversational sides where the speaker was a male between 20 and 39 years old, and the sequence "yeah no" occurred 711 times in that part of the corpus. Filling in the rest of the table, we get:
sides |
sides |
|||
| YNG (20-39) | ||||
| MID (40-59) | ||||
| OLD (60-69) | ||||
From this we can calculate the number of times "yeah no" occurs per conversational side, on average:
| Male | Female | male/female ratio | |
| YNG | |||
| MID | |||
| OLD |
Or in graphical form:
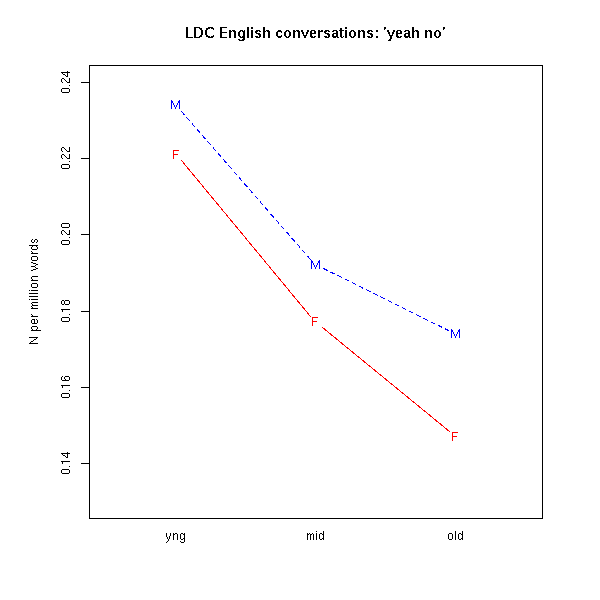
Since the conversational sides average about 900 words, this corresponds to frequencies of around 160 to 260 per million words, which makes "yeah no" roughly as common in conversation as words like seem, happy, look, rather.
It's clear that the rate of "yeah no" use decreases with age. I'm guessing that if we looked at teenagers, we'd see even higher "yeah no" rates, though I don't have any direct evidence.
It looks like men tend to use "yeah no" more than women -- but in these conversations, the men produce about 5-6% more words than the women do (as explained here), so the young men are using "yeah no" at about the same rate as the young women, if we count in words rather than in conversations. The "yeah no" gender gap among seniors seems to be real, however.
How about the context and meaning or function? This is harder to study within the time constraints of a Breakfast Experiment™. But the example that Matt quotes seems to be typical:
A: Did you like Columbia?
B: Yeah no I loved it.
Here both yeah and no are independently appropriate -- "yeah I loved it" because the basic answer to the question is positive, and "no I loved it" because love is being contrastively substituted for like.
An example from the conversational corpus where both yeah and no are independently appropriate, so that the combination is arguably just compositional:
A: yeah so what do you buy what are you looking for you look for an automatic you know you look for something with all the
B: yes i can't drive a standard
A: you can't drive a standard
B: no i can't drive a standard
A: yeah no i used to when i was when i was uh younger
B: uh-huh
A: you know but i've it's been long gone out of my system now i could just put it in home and let it go there and take me there and that's it i don't like any of that
Here it seems to me that in A's "yeah no", the yeah acknowledges B's contribution (and perhaps indicates sympathy or agreement with it), while the no answers the (unasked) question "how about you, can you drive a standard?".
Sometimes the functions of the yeah and no are more obscure, as in this passage from a different conversation, where A and B are engaged in some meta-conversation about why they signed up for the study:
B: it seems i know people in a
like my sister does r- related research and that's why she forwarded it to me and i was like okay i'll support the cause you know i uh
A: yeah no i think it's great and my my sister in the in her psych program is always like
talking about all these studies that she's doing you know for all her friends who are doing like more
like she's had like
forty seven thousand m._r._i.'s because she has a lot of studies that are doing like
But in all the cases that I looked at, the yeah and the no seem be independently appropriate in the context of use, even if the sequence seems surprising when viewed in merely semantic terms.
In cases like the last one, "yeah no" covers all the interactional bases -- it acknowledges the interlocutor and (ambiguously) suggests agreement, while simultaneously (and ambiguously) indicating novelty in the form of divergence from (perhaps shared) presuppositions or expectations.
Maybe this protean little phrase is so useful that some people become addicted to it, and for them it becomes lexicalized as a unitary discourse marker simply indicating that an opinion follows, or something of the sort. However, I didn't look to see whether there's a different pattern of usage among people who are especially fond of this sequence, as Matt suggests there might be.
[I should say that my search turns up some cases where the no is part of another construction, as in the common phase "yeah no kidding".
And sometimes, because the search process that I'm using scans each side of the conversation separately, it's combining an isolated back-channel yeah, across the interlocutor's next phrase, with no at the beginning of the next phrase.
As a result, the overall frequency in these transcripts of the phrase-initial interjection sequence "yeah no" is somewhat lower than the estimates given above.]
[A quick search on Google Scholar turns up K. Burridge and M. Florey, "''Yeah-no He's a Good Kid': A Discourse Analysis of Yeah-no in Australian English", Australian Journal of Linguistics, 22(2): 124-171, 2002. Here's the abstract:
Yeah-no in Australian English is a relatively new marker which serves a number of functions, including discourse cohesion, the pragmatic functions of hedging and face-saving, and assent and dissent. Drawing on a corpus of approximately 30 hours of both informal conversation and interviews, we analyse the interaction between intonation and turntaking, and the use of yeah-no by topic, conversational genre, and age and gender of speaker. The results indicate that the peak of yeah-no production occurs among speakers aged 35-49 years, and gender differences are not apparent in this preliminary analysis.
Unfortunately, Penn's library doesn't subscribe to this journal, and Routledge (a subsidiary of Taylor & Francis) wants $35.90 plus tax for a peek at the article, which is outside my breakfast budget. This is another good example why organizations like the Australian Linguistic Society should sponsor open-access journals, or at least insist on rational access prices -- and why authors should deposit copies of their articles in open-access archives.
Anthony Eagle sent along a link to another study: Erin Moore, "Yeah-No: A Discourse Marker in Australian English" Honours thesis, Department of Linguistics and Applied Linguistics, The University of Melbourne, 2007.
Anthony writes that "Use of 'yeah no' as a discourse marker is one feature I think of as characteristic of Australian English (I believe on the basis of introspection that I certainly use it)."
I wonder, though, whether rates of use among Australians are really higher than they are among Americans. And if the age-grading indicates a change over time, as opposed to an interaction with life stages, it's interesting that the development in Australia and the U.S. might have been roughly synchronized. If so, by what mechanisms?]
[Update: more here.]
April 02, 2008
"Ampersand asterisk star lightning bolt, you percent sign spiral thingy ministers!"
That would be the comic strip version, anyhow, of the scene evoked by the headline of Augustine Anthony's Reuters story, "Musharraf swears in Pakistan cabinet full of foes", 3/31/2008.
[Hat tip to Andy Hollandbeck]
Comprehensibility and standardness
Step 1: A language maven M contrasts two (roughly) equivalent variants X and Y, labeling them standard and non-standard respectively (or, more starkly, "correct" and "incorrect") and proscribing Y. This is the labeling phase.
Step 2: M attempts to justify the differential labeling (and the accompanying proscription) by claiming that X has intrinsic virtues -- it preserves a distinction that's important for communication, it avoids ambiguity, it's "logical", it's briefer, it's clearer, whatever -- that Y lacks; Y is intrinsically inferior. This is the justification phase.
Step 3: A linguist L objects to the justification phase -- sometimes also to the labeling phase, but the central question here is the validity of the justifications. L argues that the justifications offered in favor of X over Y are ill-founded. In particular, L argues that in practice Y does not impede communication or introduce pernicious ambiguity. This is a rejection of the justifications, not of the labeling. (In some cases L wants to dispute the labeling as well, but L rejects the justifications for dispreferring Y in any case.)
Step 4: L will make a similar argument in case after case, concluding that the standard variety is as it as a consequence of social, cultural, and historical forces, not because of some intrinsic superiority as a vehicle of communication. Having examined case after case, L will note that each non-standard variant has its own intrinsic values -- it makes a distinction that's important in communication, it avoids ambiguity, it's more regular or is simpler in some other way, it's briefer, it's clearer, whatever -- so that the justifications are really beside the point. (But this last step is important because it leads to the humane conclusion that users of the language are all concerned, tacitly of course, with communicative values; people who use non-standard variants are not just sloppy, lazy, cognitively impaired simpletons who have, moreover, perversely rejected the excellences of the standard.)
Step 5: Others now claim that L is maintaining (absurdly) that if people can understand something, it's therefore standard; call this "comprehensibility implies standardness". This conclusion does not follow from what L says; anyone who draws this conclusion deserves to fail Logic 101.
I believe that no linguist has ever said that comprehensibility implies standardness, and also that no linguist has ever said that if a speaker of a language says something on some occasion it's therefore standard (in lay terms, "correct" or "grammatical"), an even more absurd claim that Geoff Pullum rants about occasionally (most recently, in passing, here). Certainly I have never said either of these things.
My comments on the special conditional form of English (sometimes called "the subjunctive" or "the past subjunctive") have elicited the usual pile of accusations that I am an anarchic, anything-goes, radical relative-moralist academic who rejects standards in language (well, this is usually framed in somewhat more polite language). What I did was compare the special conditional form (call it form C) with the ordinary past form (call it form T) as an expression of conditions contrary to fact. In this use, form C is labeled by many critics as standard and form T as non-standard. In fact, I think that these labels are no longer accurate, but that wasn't the point of my critique. Instead, I examined the justifications that appear in handbook after handbook for proscribing form T in this use: that it eliminates a distinction that is important in communication and induces ambiguity. Against these claims, I noted that using form T in this way simply doesn't produce difficulties in communication or occasion troublesome ambiguities. You can maintain that form T is non-standard, and we can discuss the evidence for that; you can choose to use form C (as I do in many circumstances); but this talk about the communicative virtues of form C and the communicative deficiencies of form T is just beside the point. (I originally typed "is just bullshit", and maybe I should have stuck with that.)
I did not say that form T used in counterfactual conditionals is standard because people understand it so easily. I said that specific claims about the communicative values of form C are not supported by the facts of actual usage (in particular, the ease with which people understand it), and that communicative values therefore provide no justification for labeling form T in this use as non-standard. If form T is in fact non-standard, that's just a brute fact, having to do with which people use the variant in what contexts and for what purposes.
I have no problem in labeling variants as non-standard, if they in fact are, and I've done it many, many times here on Language Log (an awful lot of the variants I study are non-standard) -- with the result that I get a certain amount of e-mail from people who are shocked by some of this labeling: how, they write, can I say that some variant is non-standard, when it makes so much SENSE? Why should theirselves be non-standard? Why should themself used with singular antecedents (Anyone who shoots themself in the foot shouldn't be trusted with a gun) be non-standard? Why, in fact, should theirself in this use be non-standard (in fact, doubly so)? All I can say to these correspondents is: it just IS. (Though in the case of themself it might not be so for much longer.)
I understand that there are powerful bits of ideology at play here (which lead to the expectation that standard variants have special virtues, and then to the sort of e-mail I just described), but I feel they need to be exposed and resisted. So I find myself "defending" non-standard variants, and informal variants, and primarily spoken variants, and innovative variants, and regional/social variants, but not by claiming that they're standard, formal, written, etc. Instead, I have the much more reasonable goal of noting system (patterning, structure) in, communicative values for, and discourse functions for these "low" variants as well as the "high" ones (and the ones that are neutral with respect to the high/low poles). This is something that linguists have done for a long time. (Not by any means the only thing, but an important thing.)
A final note on form C. Jay Livingston writes to say, wryly:
If I was you, I wouldn't worry too much about it disappearing entirely.
This is an especially interesting example, because there seem to be a fair number of people who have essentially no productive use of form C, though they do have what are essentially relics of form C in a few fixed expressions, like if I were you and would that it were so, which are learned as wholes. In an important sense, the grammatical system of such speakers doesn't include form C, any more than the grammatical system of modern speakers with always and towards (and non-standard anyways) includes an adverbial genitive, though that is the historical source of the final /z/ in these items. That is, for these speakers, form C HAS disappeared entirely.
Ernie Banks gets apostrophized
When the Chicago Cubs unveiled a statue of beloved player Ernie Banks outside Wrigley Field earlier this week, there were murmurs of horror among the enemies of apostrophe abuse. The granite pedestal of the statue was inscribed with Banks' famous catchphrase, "Let's play two" — a shorter version of the saying usually attributed to him: "It's a beautiful day for a ballgame. Let's play two!" (As the Wikipedia page on Banks helpfully explains, this is "expressing his wish to play a doubleheader every day out of his pure love for the game of baseball, especially in his self-described 'friendly confines of Wrigley Field.'") But the carvers of the statue managed to leave out the apostrophe in "Let's". Local columnists and talk radio hosts had a field day with the goof.
This morning, the missing apostrophe took its rightful place on the pedestal. Lou Cella, the sculptor who made the statue, told the Sun-Times that it took about 30 minutes for carvers to etch the added punctuation. Below are before and after photos.

(Hat tip, Alice Faber.)
[Update #1: On the American Dialect Society mailing list, Larry Horn writes: "Mr. Cella and his staff no doubt obtained their apostrophe at cut-rate from a nearby statue promoting Taco's and Burrito's."
And graphic designer Andy Pressman emails: "Comically that's still not an apostrophe — it's a foot mark!"]
[Update #2: Curtis Booth emails:
Andy Pressman, as a graphic designer, should know better. Ernie Banks's inscription was defaced with a 'typewriter apostrophe', a baleful holdover from the typewriter age and the seven-bit ASCII inventors' insensitivity to matters typographical. Pressman's 'foot sign' is what typographers call a 'prime', and it's a glyph that's distinct from the typewriter apostrophe, which should now be retired from any use whatsoever, in my opinion. The carvers of the inscription should have used a 'typographer's apostrophe'. You can see many examples of typewriter apostrophes in this email and on Language Log in general, since fake apostrophes are much more common on the web than real ones. ]
[Update #3: If only the sculptor had used the Microsoft Office contextual spellchecker...]
Pennsylvania blather?
With the Democratic presidential primary in Pennsylvania still three weeks away, political reporters have a lot of column inches to fill and are no doubt looking for creative ways to combat the campaign trail's proverbial fear and loathing. Take Michael Powell's recent article for the New York Times about how Barack Obama is "grounding his lofty rhetoric in the more prosaic language of white-working-class discontent, adjusting it to the less welcoming terrain of Pennsylvania." Powell hauls out an unusual reference to support his essentialized depiction of Pennsylvanians (all of them?) as no-nonsense, salt-of-the-earth types:
Pennsylvania’s culture, as the historian David Hackett Fischer noted in his book “Albion’s Seed,” is rooted in the English midlands, where Scandinavian and English left a muscular and literal imprint. These are people distrustful of rank, and finery, and high-flown words. It should come as no surprise that the word “blather” originated here.
Kudos to Powell for making the attempt to provide background on "Pennsylvania's culture" from an academic source like Albion's Seed: Four British Folkways in America (1989). But he has misread Fischer, at least when it comes to the putative origins of the word blather. And the linguistic evidence presented in Albion's Seed is problematic enough without injecting further misinformation.
Fischer's thesis is that the "folkways" of four British regional groups shaped the cultural development of key settlement regions in American colonial history. One of these regions is the Delaware Valley, colonized by Quakers and others coming chiefly from the North Midlands of England and Wales. One legacy of the North Midlands migration to the Delaware Valley and beyond, Fischer argues, is linguistic, found in American "speech ways." He bases this assertion on surveying dialectal glossaries:
Not only the pronunciation but also the vocabulary of the England's North Midlands became part of American midland speech. In the word lists of Cheshire, Derbyshire, Lancashire and Yorkshire we find the following terms, all of which took root in the Delaware Valley: abide as in "can't abide it," all out for entirely, apple-pie order to mean "very good order," bamboozle for deceive, black and white for writing, blather for empty talk ... and wallop for beat. [Fischer lists 75 vocabulary items in all.] None of these words was invented in America, though many have been mistakenly identified as Americanisms. All were carried from the North Midlands of England to the Delaware Valley, and became the basis of an American regional vocabulary which is still in use today. (Albion's Seed, pp. 472-3)
So Fischer is clear enough that blather did not originate in the Delaware Valley, contrary to the claim of the Times article — it was merely transplanted, along with all the other North Midlands vocabulary he itemizes. But even ignoring this journalistic blunder, I'm a bit suspicious of Fischer's overarching "speech ways" argument here. To be sure, it's easy to verify the presence of blather in the relevant British dialectal sources (e.g., here, here, here, and here). In northern England and Scotland the form for the noun and the verb has historically been blether (though they all go back to Old Norse bladhra), so the regional variation is significant. But how do we get from there to the Delaware Valley and thence to "American midland speech" in general? I find no documented evidence supporting the idea that American blather (or many of the other items on the list) spread from a Delaware Valley locus, and Fischer provides no sources to substantiate this. In the case of blather, two nineteenth-century dictionaries of American English (John Russell Bartlett's 1848 Dictionary of Americanisms and Maximilian Schele De Vere's 1872 Americanisms: The English of the New World) merely label it "Western," with no indication of how it got out West.
Fischer's reliance on dialectal data, mostly from sources much later than the colonial era when the migrations took place, has been sharply criticized. Charles Joyner is largely dismissive of this evidence in his review of Albion's Seed for The Journal of American Folklore (Spring 1992, pp. 238-40):
Such early data as he has are mainly anecdotal evidence from nonlinguists, less systematic, less reliable, and less useful for comparative purposes than one would wish. Finally, support for Fischer's thesis rests most heavily upon the least stable area of language, the comparison of word forms. Vocabulary is the area of language most easily borrowed and spread across social, ethnic, and geographical boundaries. Available sources reveal much too little about grammar, the area of language least susceptible to change from contact with other languages or dialects.
Moral of the story: beware of those who would derive telling cultural insights from individual lexical items. Even if it spices up the inexorable grind of the primary season.
[Update: Two readers have suggested that "here" in the sentence "It should come as no surprise that the word “blather” originated here" could actually refer to the English (North) Midlands, mentioned earlier in the paragraph, rather than to Pennsylvania. That seems unlikely to me. The article is all about Pennsylvania, where the correspondent is reporting from, so it would be very odd indeed for the deictic grounding of "here" to shift suddenly to the other side of the Atlantic. If the writer had intended that, I would have expected "there" instead of "here" in this context. (Or who knows, maybe "there" got changed to "here" by an inattentive copy editor.)]
April 01, 2008
Important safety information
If you have strong concerns about English usage, science reporting, language analysis, lexicography, or linguistic atrocities of any kind, you should use Language Log. It is well known for its delayed release. For best results daily use is recommended.
Although laboratory studies have shown the effectiveness of Language Log, it may not be for everyone. Federal regulations require Language Log to disclose possible adverse effects when used by children under twelve (12), by certain adults, or by small animals and birds that are said to evidence minimal language skills.
Possible side effects vary by age and may include nausea, diarrhea, constipation, or headache. If you experience nausea while using Language Log, take food or strong coffee. If diarrhea becomes severe, see your doctor. Constipation is the normal condition of Language Log writers and studies have shown that it can be contagious. If Language Log causes headache, you should complain directly to the writer. Users experiencing symptoms of blindness should not read Language Log.
Tell your doctor right away if your condition worsens or if you have sudden, unusual changes in behavior or recurring dark and depressing thoughts.
If you experience unwanted side effects, Language Log offers a money back guarantee and a free one-year subscription.
Speculative semiotics of Northern European product names
Richard Morrison's 3/12/2008 column for The Times (London) ran under the title "The very Ikea: Denmark takes the floor in an entertaining feud", and began like this:
Not since Shakespeare declared that something was rotten in the state of Denmark have the inhabitants of that fair country been so disgruntled. A Copenhagen University academic has just produced some research that has shaken every Dane to his irreducible Viking core. He analysed all the products in an Ikea catalogue according to name. What he found was startling. It seems that Sweden's all-conquering furniture firm quite shamelessly names its fanciest futons, tables and chairs after Swedish, Finnish or Norwegian places, while reserving Danish place names for doormats, draught-excluders and cheap carpets.
Min gud, as they say in Danish. That has set the kat among the pigeons. The Danish press has accused Ikea of “symbolically portraying Denmark as the doormat of Sweden”. Ikea's response is that the Danes “appear to underestimate the importance of floor-coverings”. I can't work out whether that retort is a genuine attempt to smoothe ruffled feathers, or yet another sly Swedish dig at their neighbours. Either way, it hasn't helped to mollify the seething Danes.
Morrison doesn't tell us who the "Copenhagen University academic" in question was, but other coverage of the Great Danish Doormat Scandal identifies the professor as Klaus Kjøller, specialist in kommunikationsanalyse, massekommunikation, politisk kommunikation, interaktion, kulturanalyse, organisation, ledelse, ideologi, indoktrinering, indholdsanalyse, and sprogfilosofi.
And there was a lot of coverage. The story was apparently broken by Der Spiegel, and it was widely reproduced in UK newspapers: Linsay McIntosh and Allan Hall, "Ikea walking all over us, say angry Danes: Imperialism claim as Swedes give their mats Danish names", The Scotsman, 3/7/2008; "Ikea's cheap lines upset the Danes", 3/7/2008, The Telegraph; Claire Soares, "Ikea and loathing: What's in a product name?", The Independent, 3/7/2008; Roxanne Soroohian, "Is Ikea really trying to wipe the floor with Denmark?", The Sunday Herald, 3/8/2008; Haroon Siddique, "Ikea: closet imperialists?", The Guardian, 3/7/2008; "Skulduggery afoot at Ikea", The Scotsman, 3/7/2008
The story also made the news in Australia (Allan Hall, "Scandalised Danes say they won't be Swedish doormats", The Age (Melbourne), 3/8/2008), and was picked up by USA Today ("Ikea's naming system leads Danes to decry 'Swedish imperialism'", USA Today, 3/7/2008), though the rest of the U.S. mass media seem to have decided that a feud between Denmark and Sweden about the names of rugs was below the threshold of newsworthiness.
Regular readers of Language Log will now be able to predict the rest of this post. But cue the music anyway, and let's step through the familiar dance.
If you check the online version of the story in Business Week, "Danes Offended by IKEA's Product Names", 3/6/2008), you now find this notice:
This story, from content partner Spiegel Online International, has been removed at the request of Spiegel after evidence emerged that it contained inaccurate reporting.
And in place of the story at Spiegel Online ("Is IKEA Giving Danes the Doormat Treatment?", 3/6/2008), we read:
Last week, SPIEGEL ONLINE published an article about IKEA products named after Danish cities. We regret that we must retract the article because of inaccurate reporting. We apologize for the error.
In the article originally published at this address, SPIEGEL falsely reported that Danish researchers Klaus Kjøller and Trøls Mylenberg had conducted a "thorough analysis" of the naming conventions at Swedish furniture maker IKEA. In fact, Kjøller was approached by a journalist from the free daily Nyhedsavisen who had inquired about why apparently inferior IKEA products had been given the names of Danish towns.
Kjøller answered the question, but says he was very surprised by the "extremely exaggerated" article that appeared on the cover of Nyhedsavisen the following day, which would later get picked up by other media in Denmark and abroad, including SPIEGEL ONLINE.
"The story sounds good, but it unfortunately isn't true," Kjøller told SPIEGEL ONLINE on Monday. The author of the article and the editorial staff failed to contact Kjøller prior to the publication of the article.
SPIEGEL ONLINE strives to adhere to the highest standards of reporting and apologizes to its readers for the error, which we deeply regret.
The BBC was the only major British news provider not to reproduce the faked story. "We've changed our ways", said Helen Boaden, the director of BBC News. "You won't be seeing any more parrot telepathy, breast enlargement, or cow dialect stories from us. And if something slips through, we'll issue a prompt and prominent correction. As a graduate student at the University of Pennsylvania, I learned the importance of a reputation for factual accuracy and honest admission of error."
Liberman to move to BBC
In a major personnel shock, it was announced today that Mark Liberman is to leave Language Log to move to the Science News section of the BBC. Negotiations had apparently been under way for some time. Liberman's openly critical attitude toward the science reporting standards of the BBC (the organization that first brought the phenomenon of tricapital amphibia to the attention of the world's biologists) had suggested, to the few who knew of the ongoing discussions, that the BBC would fail in its bid to recruit him. But his critical stories were in fact a cover. Liberman said today, "I have a high regard for the BBC's upper-crust pomposity and tabloid-like credulity. And above all, I have a high regard for the ratio of its salary levels to those of Language Log. When plotted on a logarithmic scale, they absolutely go through the roof."
The salary Dr Liberman has been offered is reputed to exceed that of Natasha Kaplinsky, who was recruited away from the BBC last year by Five News. The BBC's move is widely regarded in the industry as the first step in a contest to fight back against Five. It is not clear whether Liberman will still be free to write anything for Language Log under the terms of his new contract. Language Log lawyers were reviewing his no-compete clause when this article was posted.
Reactions at One Language Log Plaza were muted today; senior staff who had not known about the possibility that Liberman would go were clearly stunned. Some wept openly at the water cooler. Cleanup crews were dispatched. Geoffrey Nunberg, Language Log writer and NPR superstar, who on one occasion dashed a glass of chardonnay in Liberman's face during an argument about prescriptivism, said: "If it could have kept Mark here, I would give anything to be able to take that glass of chardonnay back — and drink it."