March 31, 2008
Subjective tense
William Safire's most recent "On Language" column (NYT Magazine 3/30/08, p. 18) looks at the now-famous quote from Geraldine Ferraro, "If Obama was a white man, he would not be in this position." Then comes a parenthetical digression on grammar:
Yes, "subjective tense", in a grammar peeve. Has all our education been for naught?
Mr. Verb was on the case (or, you might say, mood) immediately:
Our most recent expedition into the land of the passive tense was led by Geoff Pullum here, quoting an earlier posting of mine about how tense gets used as an all-purpose label for a grammatical category, pretty much any grammatical category, of verbs (and maybe other parts of speech as well). My guess is that tense is just the first such technical term that people come across in school, so that's the word they use when they want to sound educated and technical. It's a kind of meta-hypercorrection.
Apparently, we haven't noted subjective for subjunctive on Language Log, though some time ago Mark Liberman and I commented on "passive gerund" for "progressive aspect", again from someone who really ought to know better.
While I'm on the subject of subjunctives, let me express amazement, once again, that so many people are so exercised about the use of the ordinary past rather than a special counterfactual form (often called "the subjunctive" or "the past subjunctive") for expressing conditions contrary to fact. The special counterfactual form is incredibly marginal: it's distinct from the ordinary past for only one verb in the language, BE, and then only with 1st and 3rd person singular subjects, so it does hardly any work. And using the ordinary past rather than the special counterfactual form virtually never produces expressions that will be misunderstood in context. Yes, you can construct examples that are potentially ambiguous out of context, but in actual practice there's almost never a problem, as you can see from two facts:
- all conditionals with past tense verb forms in them, for every single verb in the language other than BE, and for BE with 2nd person or plural subjects, are potentially ambiguous out of context, yet in actual practice, there's almost never a problem; and
- the nit-pickers are, in my experience, flawless at determining when a was in a conditional is to be understood counterfactually (and so "should be" replaced by were) -- which means that they understood the speaker's or writer's intentions perfectly.
As a result, appeals to "preserving distinctions" that are "important for communication" and to "avoiding ambiguity" are baseless and indefensible in this case. There's absolutely nothing wrong with using the special counterfactual form — I do so myself — but there's also nothing wrong with using the ordinary past to express counterfactuality. It's a matter of style and personal choice, and no matter which form you use, people will understand what you are trying to say.
But somehow preserving the last vestige of a special counterfactual form has become a crusade for some people. There are surely better causes.
Ask Language Log: Comparing the vocabularies of different languages
Michael Honeycutt writes:
I emailed Steven Pinker with a question and he told me that I should contact you.
I am a college freshman who plans to study Modern Languages and I am fascinated with linguistics. The question that I had for Dr. Pinker was in regards to the active vocabularies of the major modern languages. This may be a novice question and I apologize ahead of time. I am curious if there are any studies on the subject of the percentage of a language's active vocabulary used on a daily basis. I have been looking into this for a couple of weeks in my spare time and the information I am finding is rarely in agreement.
For example, according to Oxford University Press, in the English language a vocabulary of 7000 lemmas would provide nearly 90% understanding of the English language in current use. Of these 7000 lemmas, what percentage will the average speaker or reader experience on a daily or weekly basis? Are there any particular languages or language families that have a significantly higher or lower percentage of words encountered on a day to day basis? Are there any studies on whether, for example, speakers of Latin used more or less vocabulary in their daily lives than speakers of a modern Romance language?
Those are interesting questions. The answers are also interesting -- at least I think so -- but they aren't simple. Let me try to explain why.
The executive summary: Depending on what you count and how you count them, you can get a lot of different vocabulary-size numbers from the same text. And then once you decide on a counting scheme, there's an enormous amount of variation across speakers, writers, and styles. And in comparing languages, it's hard to decide what counts as comparable counting schemes and comparable ways to sample sources.
First, I'm going to dodge part of your question. It's hard enough to count the words that someone speaks, writes, hears, or reads in a given period of time, and to compare these counts across languages. But when you bring in a concept like "understanding" (much less "90% understanding"), you open up another shelf of cans of worms. How deep does understanding need to go? Do I understand what oak means if I only know that it's a kind of tree? Or do I need to be able to recognize the leaves and bark of some kinds of oaks, or of all kinds of oaks? Does it count as "understanding" if I can sort of figure out what a word probably means from its use in context, even if I didn't know it before? Do I "understand" a proper noun like "Emily Dickinson" or "Arcturus" simply by virtue of recognizing its category, or do I need to know something about its referent (if any)?
And if you pose the question as "the percentage of a language's active vocabulary used on a daily basis", you'll also need to define an even more elusive number, the size of "a language's active vocabulary". What are the boundaries of a "language"? What counts as "active"?
So for now, let's put aside the problem of understanding, and the whole notion of "a language's active vocabulary", and just concentrate on counting how many words people speak, write, hear, or read in their daily lives. This problem is hard enough to start with.
Consider the counting problem with respect to the text of your question. Your note uses the strings language, languages, language's. The word-count tool in MS Word will (sensibly enough) count each of these as one "word". But how many different vocabulary items -- word types -- are they? Are these three items, just as written? Or should we count the noun language plus the plural marker -s and the possessive 's? Or should we just count one item language, which happens to occur in three forms?
Your question also includes the strings am, are, be, is, was -- are these five distinct vocabulary items, or five forms of the one verb be? How about the strings weeks, weekly, day, daily? Is weekly the same vocabulary item as an adjective ("on a weekly basis") and an adverb ("published weekly")? If we analyze weekly as week + -ly and significantly as significant + -ly, are those (sometimes or always) the same -ly?
What about the noun use (in "daily use") and the participle used ("used on a daily basis"). Are those different words, or different forms of the same word? Is the participle used the same item, as a whole or in parts, as the preterite used?
Should we unpack 90% as "ninety percent" (two words) or "ninety per cent" (three words)? And is percentage a completely different vocabulary item, or is it percent (or per + cent) + -age?
Depending on the answers to these five easy questions about 17 character strings, we might count as many as 18 vocabulary items or as few as 10. And as we scan more text, this spread will grow, without any obvious bounds.
You imply a certain answer to such questions by using the term lemma, meaning "dictionary entry". But this doesn't entirely settle the matter, even for the simple questions we've been asking so far. For example, the Oxford English Dictionary has two entries for "use", one for the noun and another for the verb; while the American Heritage Dictionary has just one entry, with subentries for the noun and verb forms.
Answers to various kinds of questions about word analysis will have different quantitative impacts on word counts in different languages. For example, like most languages, English has plenty of compounds (newspaper, restroom), idioms (red herring, blue moon), and collocations (high probability vs. good chance) whose meaning and use are not (entirely) compositional. It's not obvious where to stop counting. But our decisions about such combinations will have an even bigger impact on Chinese, where most "words" are compounds, idioms, or collocations, made out of a relatively small inventory of mostly-monosyllabic morphemes (e.g. 天花板 tian hua ban "ceiling" = "sky flower board"), and where the writing system doesn't put in spaces, even ambiguously, to mark the boundaries of vocabulary items.
However we choose to count, we're going to get a lot individual variation. I gave some examples in "Vicky Pollard's revenge" (1/2/2007), where I compared the rate of vocabulary display of in 900 words from four different English-language sources:
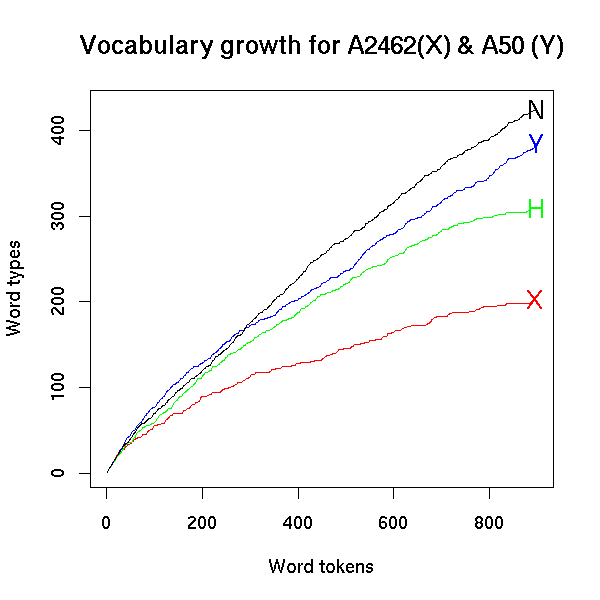
The x axis tracks the increase in "word tokens", i.e. roughly what MS Word's wordcount tool would count. The y axis shows the corresponding number of "word types", which is a proxy for the number of distinct vocabulary items. Here, it's just what we get by removing case distinctions, splitting at hyphens and apostrophes, and comparing letter strings. If we used some dictionary's notion of "lemma", all the curves would be lower, but they'd still be different, and in the same general way.
Sources X and Y are conversational transcripts; sources H and N are written texts. You can see that after 900 words, Y has displayed roughly twice as many vocabulary items as X, and that the gap between them is growing. There's a similar relationship between the written texts H and N. Given these individual differences, comparing random individual speakers or writers isn't going to be a very reliable way to characterize differences between languages. We need to look at the distribution of such type-token curves across a sampled population of speakers or writers, like this for English conversational transcripts (taken from the same Vicky Pollard post, with the endpoints of the curves for speakers X and Y superimposed):
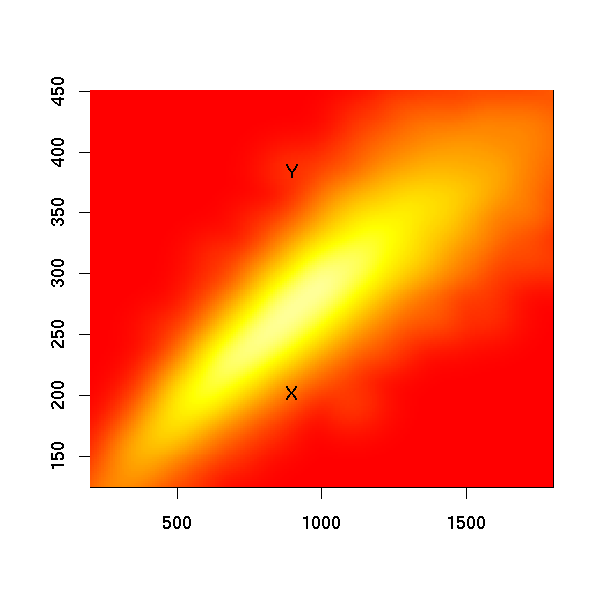
But if we had comparable sampled distributions for Spanish or German or Arabic, we could compare the average or the quantiles or something, and answer your question, right?
Sort of. Here are similar type-token plots for 50 million words of newswire text in Arabic, Spanish, and English:
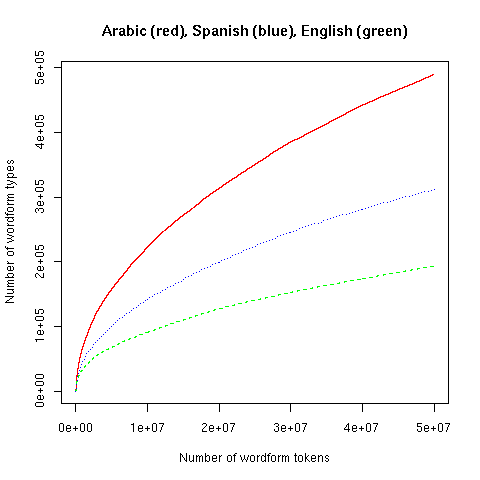
Does this indicate that Spanish has a much richer vocabulary than English, and that Arabic is lexically even richer yet? No, it mainly tells us that Spanish has more morphological inflection than English, and Arabic still more inflection yet.
These curves also reflect some arbitrary orthographic conventions. Thus Arabic writes many word sequences "solid" that Spanish and English would separate by spaces. In particular, prepositions and determiners are grouped with following words (thus this might be aphrase ofenglish inthearabic style). Just splitting (obvious) prepositions and articles moves the Arabic curve a noticeable amount downward:
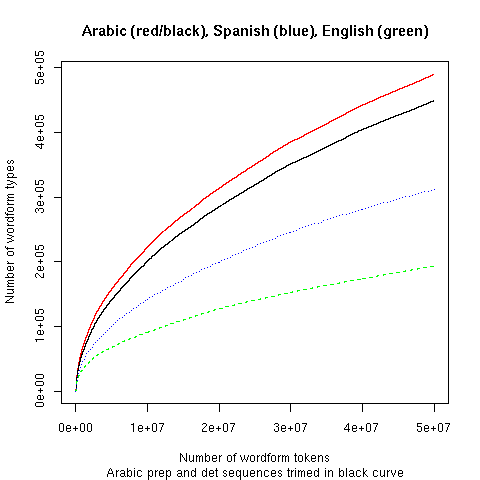
Arabic text has some other orthographic characteristics that raise its type-token curve by at least as much, such as variation in the treatment of hamza. And in large corpora in any language, the rate of typographical errors and variant spellings becomes a very significant contributor to the type-token curve.
But if we harmonized orthographic characteristics, corrected and regularized spelling, and also unpacked inflections and regular derivations, would these three curves come together? I think so, though I haven't tried it in this particular case.
But remember that different sources of speech transcriptions or written text within a given language may display vocabulary at very different rates. To characterize differences between languages, we'd have to compare distributions based on many sources in each language. However, there may be no non-circular way to choose our sources that doesn't conflate linguistic differences with socio-cultural differences.
Let's consider two extreme socio-cultural situations in which the same language is spoken:
(1) High rate of literacy, and a large proportion of "knowledge workers". Many publications aimed at various educational levels.
(2) Low rates of literacy; most of population is subsistence farmers or manual laborers. Publications aim only at intellectuals and technocrats (because they're the only literate people with money).
Given the connections between educational level and vocabulary that we see in American and European contexts, we'd expect a random sample of speakers from situation (1) to have significantly higher rates of vocabulary display than a comparable sample of speakers from situation (2). That's because speakers from (1) tend to have more years of schooling than speakers from (2).
On the other hand, we'd expect a random sample of published texts from situation (1) to have a significantly lower rate of vocabulary display than a comparable sample of texts from situation (2). That's because all the available texts in situation (2) are elite broadsheets rather than proletarian tabloids.
We could go on in this way for a whole semester, or a whole career. But please don't let me discourage you! Whatever the answers to your questions turn out to be, the search will bring up all sorts of interesting stuff. I've only scratched the surface.
If you're interested in taking this further, here are a few inadequate suggestions:
- My lecture notes on morphology from Linguistics 001.
- The Natural Language Toolkit, and the associated book. You might start with Chapter 3, Words.
- My lecture notes (from Cognitive Science 502) on "Statistical estimation for Large Numbers of Rare Events".
- Harald Baayen's book, Word Frequency Distributions.
Motivated punctuational prescriptivism
Further to my remarks about colon rage, Stephen Jones has pointed out a very reasonable structural factor that might influence the use of post-colon capitalization, regardless of the putative dialect split (between a British no-caps policy and an American pro-caps policy): capitalization is strongly motivated, he suggests, when there is more than one sentence following the colon and dependent on what is before it. Jones offers these well-chosen examples to illustrate:
- In order to protect your computer, you should do the following: run a trustworthy anti-virus system such as AVG and keep it updated.
- Computers have become easier to use in various ways since the beginning of the decade: They no longer need periodic reboots almost daily. You can run multiple programs at the same time and never run out of system resources, since that bug disappeared with Win ME. The infrastructure of the telecommunications system is much more robust than before, and dropped connections are a rarity. And finally there has been a consolidation of software vendors, which means that software now is better tested and has more resources behind it.
He comments: "In the first example what comes after the colon remains part of the previous sentence. The punctuation hierarchy of period, colon, semi-colon remains in place. In the second what comes after the colon consists of several sentences, and thus the punctuation hierarchy is broken."
I think this is exactly right. Of course, as Jones notes, one could re-punctuate the second example with semicolons for all periods except the last. But that would create a rather long and cumbersome sentence:
Computers have become easier to use in various ways since the beginning of the decade: they no longer need periodic reboots almost daily; you can run multiple programs at the same time and never run out of system resources, since that bug disappeared with Win ME; the infrastructure of the telecommunications system is much more robust than before, and dropped connections are a rarity; and finally there has been a consolidation of software vendors, which means that software now is better tested and has more resources behind it.
And it would not solve the problem in a case where one or more of the independent clauses involved independently contained a semicolon; in fact the result would be Pretty clearly ungrammatical. This can be illustrated by modifying Jones's second example to introduce independently motivated semicolons inside some of the four post-colon sentences, and then the result of semicolonization is an unpleasant structural chaos:
*Computers have become easier to use in various ways since the beginning of the decade: they no longer need periodic reboots almost daily; you can run multiple programs at the same time and never run out of system resources; that bug disappeared with Win ME; the infrastructure of the telecommunications system is much more robust than before; dropped connections are a rarity; and finally there has been a consolidation of software vendors; software now is better tested and has more resources behind it.
Try to count the separate points made after the colon now, and it is quite unclear whether it should be counted as four, five, six, or seven.
So the point is that clear signalling of structure is best achieved by capitalizing the first letter of each of the four sentences that follow the colon and are dependent on it. The four sentences are items in a list: a list of four ways in which computers have become easier to use, and it is best for them all to be capitalized rather than make the first one an exception.
Jones reminds us that there can be such a thing as an intelligently supported prescriptive recommendation about syntax and punctuation. He offers a motivated critical analysis of how the resources of the written language can best be deployed to signal structure and thus meaning. This is the sort of discussion of language that (as my Language Log colleague Geoff Nunberg has often pointed out) used to be a feature of the discussion of language for general intellectual audiences in the 17th and 18th centuries, but had all but died out by the 20th, to be replaced by shallow ranting and dialect hostility.
I would have to agree (and let me make this observation before you do!) that Language Log has occasionally carried some shallow counter-ranting against the shallow rants of the prescriptivists with whom it has disagreed. This is undeniable (especially by me). Why do we do that? Why do we follow the spirit of the times instead of standing firm against it and offering calm reason?
In my case, some of my over-the-top excoriations of ignorant and intolerant prescriptivism have had purely humorous intent. But there have perhaps been other cases in which I had decided that sometimes fire needs to be fought with fire.
The obvious objection to fighting fire with fire is that professional firefighters who are called to a house or apartment or car on fire do not do this. Flamethrowers and napalm are not standardly stowed on the fire engines; the techniques used, besides rescue equipment, are such things as high-power hoses and flame-retardant chemical foams.
However, in major forest fires, creation of firebreaks by controlled burning of specific areas is sometimes risked. I think that I (like some others at Language Log Plaza) may have felt that the 20th-century outbreak of under-informed fury and resentment that has replaced educated critical judgment about grammatical matters is more like a forest fire than a car fire.
Language Log writers do also, on many occasions, provide some calm analysis of relevant facts. That is our analog of water from hydrants and controlled spraying of chemical foam.
Ultimately, I think linguists would in general favor a return to cautious, revisable, and evidence-based criticism of prose structure. It is wildly wrong to think (as so many in the vulgar prescriptivist tradition seem to think) that descriptive linguists favor anarchy in usage and abandonment of grammatical standards. Theoretical syntax stands or falls on the distinction between what is grammatically well formed and what is not (as I have argued in detail in a recent academic paper). Without that distinction, we have no subject matter that really distinguishes us from mammalian ethologists. If everything is grammatical, it is the same as if nothing is.
I work in a department with a distinguished history of research on the earlier stages of English, where scribal error is a common source of evidence concerning the grammar and pronunciation of long-dead dialects of the Middle English or Old English periods. If everything is grammatical, then scribal error does not exist and cannot exist. What could have been seen as an interesting scribal error in a manuscript would have to be described instead as merely a piece of behavior by a hairless bipedal primate that made a sequence of marks of such-and-such shape being made in ink 900 years ago, apparently for communicative purposes.
Linguists almost always take some sequences of marks (or words, or speech sounds) to be "grammatical", i.e., clearly in conformity with a tacitly known system of principles that also defines unboundedly many other sequences of marks as being in conformity. And they take other sequences to be clearly "ungrammatical" (not in conformity). Still other sequences are of uncertain status, and provide material for debates about what exactly the principles are, and how the particular case should be judged.
The system of principles for punctuation (see The Cambridge Grammar of the English Language, Chapter 20, primarily written by Geoffrey Nunberg, Ted Briscoe, and Rodney Huddleston) is much more fixed and conventionally agreed than most aspects of spoken language, but even with punctuation there are subtleties and divergences, and debate between excellent writers, editors, and publishers concerning what the correct set of principles should actually be said to be.
Stephen Jones shows above that one of the factors that is and should be relevant to whether the first letter after the colon should be capitalized is whether the text following a colon consists of a list of two or more sentences semantically dependent on the material before the colon. He doesn't call anyone appalling or dismiss anyone as uncouth. He gives reasons for a prescriptive proposal. Good ones.
March 30, 2008
Closure
In my last posting on open vs. closed, I looked at the question of why signs on shops and the like oppose these two words, and not opened vs. closed, or open vs. close (both of which would be morphologically parallel in a way that open vs. closed is not). I assumed, but did not say explicitly, that what we want for the signs is two ADJECTIVES with appropriate meanings, and then explained that opened wouldn't do because it was pre-empted by open, and noted
And people wrote to dispute, or at least query, my claim about close. I will now try to fend off these criticisms.
Since my claim was made in the context of selecting adjectives to put on signs, I didn't go on to stipulate that what we wanted was an adjective of current English, in general use, with the appropriate meaning, and usable on its own, solo, on a sign -- that is, something people reading the signs would understand easily. To exclude the adjective close that's a homograph of the verb close, but is not in current general use in an appropriate meaning, I added a stipulation about pronunciation. Unfortunately, that wasn't enough stipulation, and a fair number of readers read the "absence" claim above out of context.
Now, into some messiness. I'll need to distinguish various lexemes spelled CLOSE by pronunciation (/klos/ vs. /kloz/), part of speech (adjective A, verb V, or noun N), and meaning. The historical story includes the following actors:
2: an A /klos/ 'closed, shut' (not at all its modern meaning), in the OED from ca. 1325;
3: a N /klos/ 'an enclosed place' (still in use, especially in British English), in the OED from 1297;
4: a N /kloz/ 'act of closing, conclusion', a N derived from the V /kloz/ (still in use), in the OED from 1399.
Item #2 has a very complex semantic history, with a variety of meanings branching off in various directions over the centuries: 'confined, narrow' (close streets), 'concealed, hidden' (close secrecy), 'private, secluded' (a close parlour), 'stifling' (close weather), [of vowels] 'pronounced with partial closing of the lips', 'stingy' (close with his money), and more; not all of these are still in use, and many of them are used only in very restricted contexts. As for the original #2, the OED's most recent cites are from 1867 (Trollope: a close carriage 'a closed carriage') and 1873 (close hatches 'closed hatches'). These have attributive (rather than predicative) uses, as do the cites for #2 going way back. But what we need for signs is a predicative adjective, and in any case the attributive uses are no longer available to modern speakers.
What we DO have in current English, in general use, and usable both predicatively and attributively, is the A /klos/ in the meaning 'near' and related senses. This is a distant descendant of #2, and it pretty much holds the field these days: ordinary dictionaries (not ones organized on historical principles, like the OED) treat it as the primary sense for the A /klos/, with other senses treated as specialized uses.
One survivor (pointed out to me by grixit on 3/28) appears in the noun close stool / close-stool (the OED's preference) / closestool, which the OED defines decorously as "a chamber utensil enclosed in a stool or box". The OED's most recent cite is from 1869, and I had thought that the noun was now archaic -- the hospitals and care facilities I've dealt with all use commode for the object in question -- but I see from some googling that it's still in use. But the A in it is pronounced /klos/, it's not usable predicatively, and it's not even clear that it has the meaning 'closed'; close-stool is an opaque idiom, not relevant to the original question about signs.
Possibly more relevant is the noun close season (pointed out to me by Cameron Majidi on 3/28). This item was new to me, but it's in the OED, in the two senses Majidi noted in his mail to me:
2. Brit. In professional sport: the period of the year when a particular sport is not played. [cites from 1890 to 2004]
The OED gives /klos/ and /kloz/ as alternative pronunciations for both British and American English. This gets us (oh dear) closer, in both pronunciation and meaning, to what we're looking for. But in both senses, close season is a fixed expression, and I assume that the A in it can't be used predicatively: *The season is close [with either pronunciation]. So there are As /klos/ and /kloz/ hanging around in the corners of modern English, but they aren't available for use on signs.
One more nomination in my mailbox: from Andrew Clegg on 3/29: close /kloz/ circuit and close /kloz/ minded, to which I can add close /kloz/ caption(ed). (From Google searches, Clegg finds the first to be primarily U.K. usage and the second to be more widespread; I believe that the third is primarily North American usage, if only because closed-caption(ed) itself is, according to the OED, originally and chiefly North American.) In each of these cases, close is a variant of standard closed in a fixed expression. As Clegg notes, the variation surely began in speech, where as Mark Liberman said a little while ago:
(and there's a huge literature on English "final t/d-deletion" in general). These spoken variants are eventually recognized in spelling (though dictionaries are slow to record the "reduced" variants), and some speakers seem to have reanalyzed some of the expressions -- so that for some people, ice tea is now understood as having the N ice as its first element. I don't know if some speakers have come to see the close /kloz/ of close circuit etc. as a new adjective. But even if they do, it appears only in certain fixed expressions and then only attributively. So, once again, it's not available for use on signs. (Well, not at the moment, so far as I can tell; who knows what might happen in the decades or centuries to come. After all, the A /klos/ 'closed' ended up with the primary sense 'near' in about 700 years.)
Let this bring this topic to a (sigh) close for now.
Well, maybe not the *first*, actually
Today's Dilbert explores the hidden weakness of the Turing Test.

[John Lawler writes:
Certainly not the first, funny as it is.
Don't forget Barry and Julia, whose antics have been linked on the Chomskybot FAQ for some time.
]
[Pekka Karjalainen recommends Mark Rosenfelder's Crib Notes for the Turing Test.]
Fourniret mailbag
A few days ago, I wrote about Michel Fourniret, the "Ogre of Ardennes", an accused serial killer known for what John Lichfield in the Independent called "complex, verbose but inaccurate French, with unnecessary subjunctive verbs and sub-clauses" ("Il fallut que j'accusasse: the morphology of serial murder", 3/27/2008).
Searching the web, I was able to find only one specific example of Fourniret's linguistic style, the phrase "Il fallut bien que je l'enterrasse" ("it was indeed needful that I should bury her"). The article in Le Monde remarked on the imperfect subjunctive, but called his language "suranné et ampoulé" ("outdated and turgid"), not inaccurate. So I wondered whether Fourniret is really given to hypercorrections and other mistakes in attempting to use a register above his station, or whether he's just obnoxiously pretentious and fussy.
This brought in quite a bit of mail. As usual, I stuck the first few on the end of the post as updates. But a few days have gone by, so here's some more commentary on the same topic.
At the end of the earlier post, Alex Price suggested that the imperfect subjunctive "sounds funny" to modern French speakers because the ending -asse "recalls the -asse ending of many informal, often pejorative nouns". Coby Lubliner sent in a joke that
Your post about Michel Fourniret and his language habits reminded me of the film Panique (1947), in which Monsieur Hire, played by Michel Simon, raises the police inspector's suspicions by saying "sans que je le susse..." to which the flic responds, mockingly, "sans que vous le sussiez" (which sounds like "suciez"). I don't remember if the 1989 remake (Monsieur Hire) has this exchange.
Having to translate a joke is even more of a thankless task than having to provide a monolingual explanation for one. But here goes anyhow:
"sans que je le susse" = "without me knowing it", literally "without that I knew it", "susse" being the 1st-person singular imperfect subjunctive of savoir "know";
"sans que je le suce" = "without me sucking it", "suce" being the 1st-person singular (indicative or subjunctive) of sucer "suck";
"sans que vous le sussiez" = "without you knowing it", "sussiez" being the 2nd-person plural (or formal) imperfect subjunctive of savoir;
"sans que vous le suciez" = "without you sucking it", literally "without that you sucked it", "suciez" being the 2nd-person plural (or formal) imperfect indicative of sucer "suck".
Some readers speculated that Mr. Lichfield might have thought that the term imparfait ("imperfect") in "l'imparfait du subjonctif" was referring to correctness rather than aspect -- or tense, or whatever morphological category French imperfects really belong to these days. (A discussion of the relevant areas of current usage is here.)
But Andrew Brown wrote:
You might want to write to [John Lichfield] directly. I've known him for twenty years, and he is one of the best, most lucid and scrupulous journalists I've worked with -- in this context a survival from when the Independent was a high-minded broadsheet. I wouldn't believe much that I read in that paper today without corroboration, but Lichfield doesn't write stuff without evidence and he does speak very good French and knows the country well.
So I'll send him a note, inviting comment, if I can find an email address.
Meanwhile, Fabio Montermini sent in a pointer to some new evidence, as well as a discussion of French journalists' reaction:
If you didn't see it yet, today's Le Figaro quotes larger extracts from the letter M.F. wrote to his judges, and the journalist also provides a sort of explication de texte: ["La cour tente de briser le silence de Fourniret", 3/28/2008]. The article also provides a reproduction of Fourniret's handwritten text, so you can read a bit more of his letter. I won't make an explication de texte myself. I am not a native speaker of French, but according to my competence I don't find any inaccuracy in Fourniret's prose. Among the characteristics the journalist points out, there is the fact that M.F. uses "well known proverbs" ("proverbes rebattus") and a sometimes familiar vocabulary: "cinoche" (argot for "cinéma"), "putain", "péter". In the reproduction of the handwritten part, there are in fact a lot of fixed expressions which are almost clichés, especially from the legal language: "ratissages au peigne fin", "tous azimuths", "affaires non élucidées", etc.
French journalists' comments seem to me also very interesting. In general, the French adore high prose and beautiful style (sometimes they claim it is a reflection of the "génie" of the French language). But look at the expressions used to qualify M.F.'s prose in the article from Le Figaro: "qui tourne vite à la logorrhée", "formulation alambiquée", "style, que l'auteur veut soigné, voire ampoulé". This last phrase is significant: the journalist judges that in any case M.F.'s style cannot be genuinely "soigné", such a mean person cannot actually put "génie" in his style. It seems to me a good example of an ideological reading of language.
[Daniel Ezra Johnson sent a really bad joke:
The imperfect subjunctive isn't so uncommon, you'll see it in any bar in Canada:
BIÈRE EN FÛT
I've already explained one questionable joke in this post, so you folks are on your own with this one. Well, OK, I'll observe that in Canadian French, en fût means "on tap" -- in France, I think it would mean "in tree trunk" or something of the sort -- and I'll give you a link to the verb conjugator at wordreference.com, set up for etre. ]
Hoping to be haunted by legitimacy
According to Perry Bacon Jr. and Anne E. Kornblut, "Clinton Vows To Stay in Race To Convention", Washington Post, 3/30/2008:
"We cannot go forward until Florida and Michigan are taken care of, otherwise the eventual nominee will not have the legitimacy that I think will haunt us," said the senator from New York.
I hate to go all Kilpatrick on this, but wouldn't it be a lack of legitimacy, or perhaps a failure to achieve legitimacy, that would haunt them? As quoted, the sentence seems to me to indicate that Senator Clinton hopes to be haunted by legitimacy, and for that reason plans to stay in the race until the nominating convention in August.
For comparison, here are a few other sentences exhibiting the pattern "... will not have the X that will Y <someone>", as found on the web. In all cases, it's the X that will do the Y-ing, not the failure to have the X.
The upside is they will not have the sort of firepower that will cause the US military a lot of problems ...
The absinthe you get in the US will not have the wormwood in it that will get you "high".
... you will not always have the answers to situations that will confront you in your career/life
... people will not have had the insurance that will allow them to recover.
Josh Marshall calls this interview "pretty astonishing" ("Clinton: All The Way to Denver", TPM, 3/30/2008), although it's the politics rather than the syntax that surprises him. However, he does note an interesting point of usage:
The key quote from the interview is this one: "I know there are some people who want to shut this down and I think they are wrong. I have no intention of stopping until we finish what we started and until we see what happens in the next 10 contests and until we resolve Florida and Michigan. And if we don't resolve it, we'll resolve it at the convention -- that's what credentials committees are for."
So she's promising to remain in the race at least until June 3rd when the final contests are held in Montana and South Dakota and until Florida and Michigan are 'resolved'. Now, that can have no other meaning than resolved on terms the Clinton campaign finds acceptable. It can't mean anything else since, of course, at least officially, for the Democratic National Committee, it is resolved. The penalty was the resolution.
As we've often noted in defense of others, speaking extemporaneously in public is a hard thing to do, and occasional awkwardnesses, infelicities and downright flubs are to be expected. On the other hand, Senator Clinton's quotes in this case were apparently from remarks prepared in advance, on a topic central to her campaign. According to the WaPo article,
The Clinton campaign requested the interview Saturday to talk about how she could win and to emphasize her focus on Michigan and Florida.
So let me note that if linguistic awkardness were part of the journalistic meta-narrative about Hillary Clinton, and someone were keeping score the way Slate's Jacob Weisberg has been toting up Bushisms, this interview would certainly go into the file of Hillarities.
In fact, I've always had the impression that Senator Clinton is a skillful and well controlled speaker. Could this series of rather awkward statements be a sign of an unusual level of stress?
[Andre Mayer wondered:
Or did she say:
"We cannot go forward until Florida and Michigan are taken care of, otherwise the eventual nominee will not have the legitimacy -- that I think will haunt us," said the senator from New York."
I wondered about that myself, and looked for a video or audio clip of the interview to check, but couldn't find any. That construal would still be pretty awkward for a prepared statement, though, unless the Post's reporters mangled the quote more thoroughly than just by ignoring a clause boundary.]
Occupational eponymy
Gerry Mulhern of the Queen's University Belfast wrote a letter to Times Higher Education (2/28/08) after he looked at the list of the vice-chancellors of the Russell Group of the top (and hence most prosperous) UK research universities. He had noticed that there were two named Grant, and several other money-related names like Sterling (the honorific adjective used for the British pound), Thrift (the virtue of good budgeting), and Brink (the cash transport trucking company). He said it reminded him of the name of a director of human resources he once knew (back when Human Resources was still called Labor Relations, I expect), named Strike. The vice-chancellor of the University of Portsmouth later sent in letter (3/13/08) saying simply that he had "never had the guts to study onomastics." His surname, the signature revealed, is Craven. There is a childish joy to these odd coincidences that have given us people apparently named for their jobs (or people who obediently selected the jobs their names foretold). Eric Bakovic nearly choked up his oatmeal last December when he noticed an item about a food company executive with a name suggestive of hurling. I noticed with delight and amazement today that the name of the public relations man cited on this Arts and Humanities Research Council page is Spinner. Honestly. I swear this is not one of my little deadpan jokes. Spinner really is working as a spinner.
By the way, let me not forget to note that the current US Secretary for Education is named Spellings.
Names suited to the occupations of their owners in this way are sometimes known as aptonyms. There is a huge list of them at this site (thanks to Andrew Leventis for this). Some (like New Scientist magazine) refer to the phenomenon under the heading "nominative determinism". The New Scientist got into the business of supplying aptonyms in its Feedback column after noticing an article about incontinence in a urology journal with a truly astounding by-line that I really don't think I want to reveal to you.
Oh, all right. It was Splatt and Weedon. You have John Cowan to blame for me mentioning this (thanks, John; don't send any more).
March 29, 2008
More WTF coordinate questions
Today's find in the world of WTF coordinate questions is
We've been here before, though with a slightly less complicated example:
[A couple more examples from real life: from Paul Kay on 9/13/06, a television commercial for the over-the-counter sleeping medicine Lunesta, noted 9/11/06: Do you wake up in the night and can't go back to sleep? And from Elizabeth Daingerfield Zwicky on 2/14/08, a notice at Kepler's book store in Menlo Park CA: Do you like to knit but are looking for a meaningful project?]
Here's the problem: leaving out many important details, examples like (2) and (3) appear to have something like the structure
Instead, as I observed back in 2005, things like (2) and (3) seem to be simply the yes-no question counterparts to declaratives like
(3') Someone here has been raped and speaks English.
In a later posting I returned briefly to these WTF coordinate questions and alluded briefly to three alternative analyses for them, all of which treat them as involving a coordination of some constituent with an ELLIPTICAL subpart, rather than as being "reductions" of coordinations of full clauses. (I owe these ideas to Language Log and ADS-L readers who wrote me about my first posting and to colleagues at Stanford who commented on a presentation I gave in August 2005.) All would treat simpler coordinations like saw Kim and Sandy as [saw Kim] and [Ø Sandy] (or, better, [ saw Kim] [and [Ø Sandy]], but I'll put aside the question of where conjunctions fit into these structures), but via different formal mechanisms:
Idea 2: the Ø is an instance of "functional control", as in Kim wants Ø to leave.
Idea 3: the Ø is part of an Initially Reduced Question, as in (1) vs. (3) (cf: Ø Sandy gone yet?).
There are knotty technical questions here. I bring these three ideas up only to demonstrate that there are alternatives to the reduction idea. A little more on this below. But first, a note that standard assumptions about constituency might also be called into question. The usual assumption about (3') is that it has a coordinate VP:
A final remark on "deletion", "omission", "reduction" and similar turns of phrase. These terms, which strongly suggest an analysis in which one construction is secondary and is in some way derived from another, primary, construction via various formal operations, can be deeply misleading. (The terms are useful, maybe necessary, but in the end they're just terms, not claims to truth or any kind of analysis.) Even when the historical sequence seems clear, my current position is that once the variants are out there, they are just variants; they will share elements of their structures, true, but they'll have their own details and uses and lexical idiosyncrasies and the like. Each should be described on its own. We should take seriously the idea that "reduced coordinations" are not just full coordinations with some pieces left out, but might be constructions in their own right.
Modesty, hod-carrying, everything but relevance
Interesting to see my friends Mark Liberman and Stephen Jones arguing about whether James Kilpatrick's recent article makes good points. I was already planning to comment on my own reaction to the article: I was astounded by its sheer rambling emptiness; it was far worse than I was expecting.
Kilpatrick had a very clear mandate: he had been asked Why do we study grammar? by a first-year high school student in Oregon named Kathryn. Her question does need an answer. Kilpatrick was apparently intending to provide one. But instead he just sort of staggers about for six hundred words and then falls over and stops. Neither Mark nor Stephen has given you a proper sense of how bad the article is.
Kilpatrick's first point is that using proper grammar is like not driving into downtown Portland wearing a polka-dot bikini. (I swear I am not making this up.) The girl who wore the itsy-bitsy teeny-weeny yellow polka dot bikini in the song (it was a hit back in 1960; Kilpatrick was apparently 40 by then, and should not have even been listening to such songs) was embarrassed at having to come out of the water. Grammar is modesty, Kathryn. Cover your midriff.
He then moves to some condescending comments about the working-class speech of an imagined "hod carrier" who "don't speak no good English" but "pays the rent and, you know, it's like he treats his wife real good". He concedes that the hod carrier might do a good job of work, but... I don't know. I cannot see what that paragraph is supposed to be driving at. It goes nowhere as far as the topic of motivating grammatical study is concerned.
Next he says that the point of grammar is "to avoid being misunderstood", and drifts from there into what seems a glaringly irrelevant remark about vocabulary size ("a hundred thousand words for everyday use and half a million more for special occasions"), and tries to make it relevant by declaring that "we can put these riches to work" with grammar. Otherwise will be unable to write precise laws, persuasive sermons, or clear doll's house assembly instructions. (By the way, everything I've assembled recently has instructions that are entirely pictorial. So much for grammar.) This is the misguided view that Mark convincingly calls "transparent nonsense". It's about getting a message across effectively, and not about studying grammar.
Struggling to get back to his theme, Kilpatrick declares (getting somewhat desperate) that one reason for studying grammar is that "it is surely more fun than algebra." Apparently "once you've done one quadratic equation, you've done them all" (!). But drift sets in again, leading him to remark that "there are few ironclad 'rules' of English composition" — which apparently means there isn't much to study, undercutting his whole point.
His remaining statements are these: First, that he is not a snob, he is merely practical (this is about himself rather than grammatical study).
Second, that English grammar "has its awkward patches" but nonetheless "is a language of remarkably good order" (I do not see what these impressionistic value judgments have to do with his topic).
Third, that "irregular verbs have a pattern of irregularity" and this is exemplified by comparing Kathryn has and Kathryn had (they provide "a perfect, or at least a past perfect example", he says, bafflingly).
And fourth, in a concluding explosion of anglophone triumphalism, that "English is the greatest language ever devised for communicating thought" — the remark that Mark commented on originally, which has nothing to do with why we might or should study grammar.
And there, having hit the 600-word point without having made a single sensible remark about why we study grammar, he simply stops.
Steve says the article "is actually rather good", and even Mark says "Kilpatrick writes beautifully"; but I demur. I think Kilpatrick's little piece may be the worst piece of writing about language that I've ever seen. And the question it starts with — why we study grammar — remains to be addressed. I may have to tackle the question myself one day, because James Kilpatrick clearly has nothing to say about it.
Mongers
We have a real cheesemonger near where we live in Edinburgh: a small shop entirely devoted to cheese, with great wheels of the stuff in the window and a huge array of cheesy comestibles on offer and a genuine cheese expert in a white coat in charge and long lines of prosperous Stockbridge residents waiting outside to get in and receive their cheese advice.
We also have a genuine fishmonger a little further down into Stockbridge village, with huge ugly monkfish looking vacantly out into the street amid fantastic piles of ice, mussels, oysters, prawns, lobsters, herring, and more other slimy denizens of the deep than I could name. And it had been my intention for a while to write a witty Language Log post about the strange fact that in contemporary English (ignoring all the obsolete formations the OED includes) the combining form -monger can only be used to form words in which the first part is one of three basic household needs (cheese, fish, and iron) or one of a longer list of unsavory and frightening abstract entities (fear, gossip, hate, rumor, scandal, war, etc.). Nothing much more. (The word whoremonger, denoting the sort of person Eliot Spitzer would contact before a trip out of town, isn't really in use any more; pimp and madam have replaced it.) The form -monger isn't productively usable any more for deriving new words: you simply can't refer to a timber store as a *woodmonger, or use *meatmonger for a butcher.
But then The Onion just stole the idea for this theme out of my head and published today a highly witty news brief about a war- and fear-mongering conference. Probably better than what I could have done. Damn The Onion. Damn them.
Now what will I do? It's Saturday morning and you're all browsing Language Log to see if I'll have some little funny piece of nonsense for you, and I don't! Maybe Mark Liberman will come up with some more graphs showing that women's brains are (thank goodness) not wired all that differently from men's, or Heidi Harley will spot something really important while watching The Simpsons, or Melvyn Quince will surface with some more of whatever the hell it is that he does... We can but hope.
The values of "correct grammar"
In response to yesterday's post "James Kilpatrick, linguistic socialist", Stephen Jones writes:
I hate to have to come to Kilpatrick's defense again but his article is actually rather good. He makes two excellent points; that 'correct grammar' allows communication between people who speak different dialects, and that there must be some kind of agreed set of grammatical rules if we are to be able to interpret written laws and regulations.
Many people believe that stipulation of shared linguistic norms is essential to communication, or at least improves the efficiency and accuracy of communication. But on examination, this idea is transparent nonsense. Let me illustrate.
I'm one of the judges in the 2008 Tournament of Books at The Morning News, and The Brief Wondrous Life of Oscar Wao, by Junot Díaz, has made it to the final round. Chapter One ("GhettoNerd at the End of the World, 1974-1987") starts like this:
Our hero was not one of those Dominican cats everybody's always going on about -- he wasn't no home-run hitter or a fly bachatero, not a playboy with a million hots on his jock.
This sentence contains an instance of negative concord, a non-standard grammatical feature that isn't part of my dialect of English. But this doesn't cause me any trouble -- it wouldn't have been any easier for me to understand the sentence if Díaz had chosen to write "wasn't a home-run hitter" instead of "wasn't no home-run hitter".
The same sentence also includes several non-standard words or phrases. Cats is an antique piece of hipster slang; fly is slightly more recent; bachatero I didn't know, but it seems to mean a singer of bachatas, a kind of Dominican popular music; hots on his jock I can more or less guess. I wouldn't use any of these, and didn't even know some of them, but Díaz got his idea across, and the non-standard lexical choices are part of what he communicates.
Oscar Wao is a terrific book, but of course I could have chosen Huckleberry Finn, an even better book that's even denser with "incorrect grammar" and non-standard word usage:
You don't know about me without you have read a book by the name of The Adventures of Tom Sawyer; but that ain't no matter.
Here's a final example, of a very different kind. Seth Roberts is visiting Penn to give a talk, and on Thursday I had him over for dinner with 15 or 20 students in Ware College House, where I'm faculty master. After dinner we traded favorite-books recommendations for a while, and I suggested Gibbon's Decline and Fall. As a result, I took it off the shelf and read myself to sleep with Chapter XXVI (365-395 A.D.), "Manners of the Pastoral Nations", which reminded me of how much I like Gibbon.
But it also reminded me of the changes in English style and usage since 1776. Consider the following sentence, discussing the Roman world's reaction to the great earthquake and tidal wave "in the second year of the reign of Valentinian and Valens":
They recollected the preceding earthquakes, which had subverted the cities of Palestine and Bithynia; they considered these alarming strokes as the prelude only of still more dreadful calamities, and their fearful vanity was disposed to confound the symptoms of a declining empire and a sinking world.
No one writes like Gibbon now. This may be our loss, but it's also our reality. Along with the rhetorical differences, there are some changes in grammar and usage. We no longer use subvert in the OED's sense 1, "to overthrow, raze to the ground (a town or city, a structure, edifice)". We no longer put only after the word it limits ("the prelude only of still more dreadful calamities"), except in fixed phrases like "by appointment only".
But these differences don't get between Gibbon and me to any significant extent. I wouldn't enjoy him more, or understand him better, if someone modernized his language.
Obviously, reader and writer must share linguistic norms to some extent. I can't read the Kalevala, much as I might like to, because I don't know enough Finnish. But it's just plain silly to insist that writing must conform to James Kilpatrick's grammatical stipulations in order for Anglophone readers to be able to understand it properly.
What about Stephen's second point, that "there must be some kind of agreed set of grammatical rules if we are to be able to interpret written laws and regulations"? The trick here, as discussed in the post that Stephen is responding to, is what "agreed" means. Kilpatrick believes, or at least asserts, that the route to linguistic clarity is grammatical stipulation by self-appointed experts. I think this is naive and empirically false. Linguistic norms are examples of what Hayek called "spontaneous order", arguing against the "highly influential schools of thought which have wholly succumbed to the belief that all rules or laws must have been invented or explicitly agreed upon by somebody".
Stephen continues:
Also his point that we have 'many different vocabularies' and that the most important thing is to consider the target audience ('Know thy reader') is excellent advice.
I agree.
As I said before, Kilpatrick's problem is that he picked up his theory at a garage sale run by dysfunctional schizophrenics. What he actually recommends in practice is usually spot on.
I disagree with both points. Kilpatrick picked up his theory from the proud and dominant intellectual tradition of rationalist constructivism. It may be dysfunctional, especially as applied to language, but it ain't no garage sale.
And Kilpatrick writes beautifully, but his practical recommendations are a capricious and unpredictable mixture of sensible advice and idiosyncratic peeves.
March 28, 2008
Open and closed
In an earlier posting, I asked when closing begins and when stopping starts. There was, of course, mail on the topic. I'll comment on three responses, in three separate postings, beginning with the morphological asymmetry between the opposites open and closed. Fernando Colina asked on 19 March:
Well, a language is a system of practices, not a designed system, so some things are as they are just because of the way they developed over time; there are plenty of anomalies and irregularities in every language. On the other hand, a language is a SYSTEM of practices, including many regularities. It turns out that almost everything about open and closed is a matter of regularities; the special facts are the presence of an adjective open in the language and the absence of an adjective close (pronounced /kloz/; there is an adjective close /klos/, the opposite of far, as in "Don't Stand So Close to Me", but it's not relevant here).
I'll start with closed, which is, morphologically, the past participle (PSP) form of the verb CLOSE (also the past tense form, but it's the past participle that we're interested in here). In fact, there are two possibly relevant verbs CLOSE here:
transitive CLOSE, denoting a causing (by some agent, usually but not always human) of this change of state (I closed the gate at dusk); such verbs are sometimes called "causative-inchoative" verbs, or more often just "causative" verbs.
This pairing of homophonous verbs -- inchoative intransitive and causative transitive -- is very general in English, extending even to new formations (Palo Alto will rapidly Manhattanize 'become like Manhattan', They are rapidly Manhattanizing Palo Alto 'causing it to become like Manhattan').
Now, the PSP of a state-change verb can be used as an adjective that denotes the property of being in that state, without any implication of change. In particular, closed can be used as a "pure stative" adjective: The window is closed at the moment doesn't require that the window was ever open (it might have been built in a closed state), and The flower is closed doesn't require that the flower was ever open (it might not yet have opened, and maybe never will), and someone with a closed mind might never have had an open one (and might never have one).
Since there's no adjective close /kloz/ in English, the stative adjective closed gets to fill its slot in the pattern, serving as the opposite of the (morphologically simple) adjective open.
In addition, the PSP of a transitive verb (whether causative or not) is also used in the passive construction, as in The gate was closed by the guard at dusk. This use denotes an event, not a state.
Put those last two things together, and you get the possibility of ambiguity, between a pure state reading for a PSP and a passive reading for it: The gate was closed at dusk 'The gate was in a closed state at dusk' (stative adjective) or 'Someone closed the gate at dusk' (passive). The stative adjective use is historically older, with the passive use developed from it, but the two uses have coexisted for centuries. The ambiguity is long-standing and widespread.
A further complexity is that the PSP of a transitive verb (whether causative or not) can also be used as an adjective with the semantics of the passive. The point is subtle, but it's fairly easy to see for non-causatives (and it will become important in a little while, so I can't just disregard it). Consider The point is disputed. This could be understood as a passive, but its most natural interpretation is as asserting that the point has the property of having been (or being) disputed by some people (a sense that allows an affixal negative in un-: The point is undisputed 'No one disputes the point'). For causatives, this sort of interpretation is usually a special case of the pure stative reading, so that it's hard to appreciate that it's there.
On to open. We start with the adjective lexeme OPEN, which is a pure stative; The window is open doesn't require that it was ever closed (it might have been built that way), and The restaurant is open doesn't require that it was ever closed (it could be one of those restaurants that are always open). The adjective can serve as the base for deriving two verb lexemes, the inchoative OPEN 'become open' and the causative OPEN 'cause to become open'. The story of the PSP opened then goes much as for the PSP closed, but with an important difference. The PSP opened has a passive use, as in The gate was opened by the guard at dawn. But the stative adjective use is hard to get: The gate is opened at the moment is decidedly odd. Why?
Because English already has a way to express this meaning (and a way that's shorter and less complex than the PSP opened): the adjective open. The PSP opened in this use is PRE-EMPTED (or, if you will, PREEMPTED) by the simple adjective open. (Pre-emption is a perennial topic in morphology and lexical semantics. A textbook example: English has no causative DIE alongside inchoative DIE because it's pre-empted by causative KILL; in a sense, KILL got there first, so there's no point in creating causative DIE.)
But... in special circumstances, the PSP opened could be used as an adjective -- with the semantics of the passive, as for disputed above. In particular, The envelope is opened could be used if the envelope was not merely open (rather than closed or sealed), but gave evidences of having been opened, say by slitting with a letter opener. This is a case where open might not be specific enough, so it doesn't automatically pre-empt opened.
We end up with an opposition between the stative adjectives open and closed (the former a simple adjective, the latter a PSP). We don't use opened for the first because of pre-emption, and we don't use close /kloz/ for the second because there is no such adjective in English.
Bureaucrats
It's tax season here in America and that usually leads to lots of mumbling under the breath about those "damn bureaucrats in Washington" who make up those unreadable tax forms. Several words in the English language rise to the level of making us mad and bureaucrat seems to be one of them. When our tax filing gets challenged, we blame those nasty bureaucrats at IRS. When we're bogged down with pages of needless forms to fill out, it's the fault of those anonymous servants of the government who are the problem. When a statute is incomprehensible, it's the bureaucrat's fault, even though we might better place the blame on the legislators who wrote it in the first place.
I rise today to defend those bureaucrats. Please stop hissing and booing. Let me explain why.
I suppose I rise to defend bureaucrats because I lived in Washington DC for almost half of my life, surrounded by lots of friends and neighbors who toiled somewhere in the bowels of the federal government. Most of them were really nice folks, just like the rest of us. Sure, they made errors sometimes (just like the rest of us) and occasionally they followed those arcane regulations to the point of seeming unreasonable. But hey, that was their job. They had to. The poor souls at the Social Security Administration (SSA), Medicaid, or Health and Human Services send out notices on which they aren't even allowed to even sign their own names. These are the anonymous sloggers who dutifully work at the job they were hired to do, often without the proper tools to it well. But they do the best they can anyway.
And, as I finally get around to the subject of language (after all, this is Language Log), I have to agree that bureaucrats often write perfectly dreadful prose. But rather than grousing about this or going into another of those language rants that we are so famous for at Language Log Plaza, consider this novel idea: why not try to help with this problem?
Over the years I've worked with a number of bureaucracies, trying to help them make their documents understandable to the general public. One of my favorite cases was one brought by the National Senior Citizens Law Center (NSCLC) against the U.S. Department of Health and Human Services (HHS) over two decades ago. NSCLC charged that the notices being sent out by SSA to Medicare recipients were unclear, unhelpful, and not even readable. The case focused on one notice that was intended to inform all SSA recipients that they also might be entitled to an additional SSA benefit, Supplementary Security Income (SSI). The case wended its way through the court system and finally ended up at the U.S. Supreme Court, which ruled for the plaintiff. Legal resolutions don't often guarantee immediate action, however, and it took quite a while for SSA to get around to sending out this notice to all Social Security recipients. That notice was so badly written and incomprehensible that NSCLC threatened HHS with still another lawsuit.
It was at that point that NSCLC asked me to rewrite the offending notice so that it could be understood by recipients. They liked my revision (which was actually a totally new attempt) and they submitted it to SSA, where the director liked enough to agree to send it out, thereby fending off still another round in federal court.
The really interesting thing, however, is that the Director of SSA, recognizing a serious internal problem in her bureau, then invited me to come to the SSA home office in Baltimore to train her notice writers to produce clear and informative notices like the one I produced about SSI. I agreed, and over the following two years (1984-1986) I trained about a hundred SSA bureaucrats in six, six-week sessions (each containing 15 or more notice writers working in their main and regional offices). I can't give you the details of this training program here (if you're interested, you can read about it in my 1998 book, Bureaucratic Language in Government and Business but I can say that these bureaucrats greatly benefited from my assigned fieldwork (linguists do this a lot), finding old people to test their revisions on. When their subjects understood what they wrote, the notice writers knew they were on to something. These bureaucrats also learned about topic analysis and topic sequencing and they even became rather competent in recognizing and using speech acts in their prose. In addition they were given some rudimentary principles of semantics, pragmatics, syntax, and usage--all based on the documents they were preparing to send out to the public.
These bureaucrats were good people and good bureaucrats. But they had been caught up in the contagious rigidity of the bureaucratic prose fostered by the system. Like most of us who learn to use the language of our fields (doctors and policemen come to mind), they had no background in writing clear and effective prose and, of course, no knowledge of linguistics. But even the small dose they got in this training program seems to have brought about an important change in that bureaucracy.
I was concerned, however, about whether this training would endure. I found my answer a few years later, when I retired and started to receive Social Security benefits myself. The notices I began to get were clear and informative. Something must have worked. One nice thing about bureacracies is that it's hard to change things once they get established. This experience shows, I hope, that it's more useful to try to help with a problem than simply to throw stones at it. What these bureaucrats needed was adequate information about how they could use language effectively to do their daily jobs.
So that's why "bureaucrat" isn't such a bad word for me.
James Kilpatrick, linguistic socialist
Wikipedia describes James J. Kilpatrick as "a conservative columnist". There's good evidence for this. His syndicated column was called "A conservative view"; he was, according to Wikipedia, "a fervent segregationist" during the civil rights movement; for many years he was the conservative side of the Point-Cointerpoint segment on 60 Minutes.
And yet, in his second career as "grammarian" -- by which he means "arbiter of English usage" -- Mr. Kilpatrick promotes the linguistic equivalent of a planned economy. Linguistic rules are to be invented by experts like him, on the basis of rational considerations of optimal communication, and imposed on the rest of us. For our own good, of course.
His most recent column ("Why do we study grammar?", 3/23/2008) offers a small but telling indication of this:
In speech or in writing, English is the greatest language ever devised for communicating thought.
Linguistic chauvinism aside, let's focus on the word "devised". Compare Hayek, Law, Legislation and Liberty, Volumes 1: Rules and Order, p. 10-11:
[Constructivist rationalism] produced a renewed propensity to ascribe the origin of all institutions of culture to invention or design. Morals, religion and law, language and writing, money and the market, were thought of as having been deliberately constructed by somebody, or at least as owing whatever prefection they possessed to such design. ...
Yet ... [m]any of the institutions of society which are indisensible conditions for the successful pursuit of our conscious aims are in fact the result of customs, habits or practices which have been neither invented nor are observed with any such purpose in view. ...
Man ... is successful not because he knows why he ought to observe the rules which he does observe, or is even capable of stating all these rules in words, but because his thinking and acting are governed by rules which have by a process of selection been evolved in the society in which he lives, and which are thus the product of the experience of generations.
In contrast, most academic linguists that I know are political liberals, who would not agree with Hayek about many issues in economic and social policy. There's an apparent paradox here, perhaps related to the curious connection between less government regulation of the economy and more government regulation of morals.
(For more detailed discussion, see "Authoritarian rationalism is not conservatism", 12/11/2007; "The non-existence of Kilpatrick's Rule", 12/14/2007.)
[Andre Mayer writes:
"Grammarian" is of course James J. Kilpatrick's third career. He was a newspaper editor for many years before becoming a columnist, which may explain his prescriptive views. (I think he once endorsed Eugene McCarthy for President, which -- like his views on language -- is actually compatible with a certain kind of conservatism.)
Well, at least he co-authored a book with McCarthy, "A Political Bestiary" (sample entry here). And a piece that Kilpatrick wrote for the National Review in 1968, "An Impolitic Politician", was republished in 2005 on the occasion of McCarthy's death. From this article, I gather that Kilpatrick admired McCarthy's style, and liked him as a person. It's less clear, at least from this evidence, that he endorsed any of McCarthy's political views. An affectionate obituary ("Remembering Gene McCarthy") from The Conservative Voice supports the same conclusion.]
Furth
The University of Glasgow's Faculty of Arts promulgated in 2002 a policy (see it here) that apparently relates to transfer of credit from foreign universities. But what it says, even in the main header to the page (and I thank Judith Blair for bringing this to my attention), is that it concerns "Grades received furth of Glasgow". What the hell is furth?
The answer is that it is yet another English preposition that I had never previously encountered in my entire life.
So I am still not done with learning the prepositions of my native language, for heaven's sake, despite being (i) a current resident of Scotland (and in fact Scottish born); (ii) a native and lifelong speaker of English; (iii) well acquainted after long experience with English in the UK, the USA, and Australia; (iv) a voracious reader since the age of three; (v) a Professor of General Linguistics in the very distinguished Linguistics & English Language department at the University of Edinburgh; (vi) first author of the chapter on prepositions in The Cambridge Grammar of the English Language, and most important of all, (vii) a Senior Contributing Editor for Language Log.
Both Mark Liberman and I were surprised to come upon any English preposition that we didn't know (neither of us had run into outwith until quite recently). But another one? This is more than just interesting. This is positively embarassing. Where have these regional prepositions being lurking during all the earlier part of my life?
What furth of Glasgow means "away from or outside of Glasgow": the policy involves grades assigned by students spending time away, typically at foreign universities during a year abroad. So furth takes an of-phrase, in the way that out usually does, and outside optionally does.
Middle English expert Meg Laing points out to me that furth has the same etymology as the intransitive preposition forth. (Yes, I know, the dictionaries all call it an adverb. All published dictionaries are wrong about where to draw the line between prepositions and adverbs. See Chapter 7 of The Cambridge Grammar of the English Language.)
Though far from moribund in contemporary Standard English, forth is not common, and occurs largely in fixed phrases. More than a third of the 589 occurrences in the Wall Street Journal corpus (199 occurrences) involve the fixed phrase back and forth. Another 81 are in instances of the idiomatic and so forth, synonymous with "and so on". The others occur as complement of verb lexemes (as usual I will indicate lexemes by citing plain forms in bold italics), and they have a very uneven frequency distribution: there are 103 occurrences of set forth, 63 of put forth, and 36 of bring forth, and the others occur at much lower rates.
We find hold forth (an idiom meaning "offer opinions"), come forth, and call forth about a dozen times each, and then a large number of other verb lexemes occurring with forth rather more rarely than that, between one and eight times each. (For the record, the other verb lexemes with forth as complement are blare, blossom, body (which was a new one to me, but it occurs twice), break, bubble, burst, conjure, drive, go, gush, hiss, hold, issue, jerk, offer, pour, sally (a verb that now only occurs with forth, and yes, the comic strip Sally Forth is named after this idiom), send, set, spring, stand, step, summon, throw, thrust, thrust, tumble, and venture.)
What is relevant in the present context is that there is not a single occurrence of forth of NP meaning "away from NP". That is the development, apparently now limited to Scotland, that led to furth of Glasgow. It was once paralleled in other dialects: the Oxford English Dictionary cites examples from 1500, such as Whan your mayster is forth of towne ("when your master is out of town") where forth is spelled with an o but takes the of phrase. But it describes forth of as "Now only poet. or rhetorical, and only in lit. sense expressive of motion from within a place." The only sign of furth is as an early alternate spelling, and never with of. (Note, though, that as Jim Smith points out to me, all modern English dialects have preserved the comparative and superlative forms further and furthest.)
So that was my latest preposition-learning episode. I wonder when I will next encounter an English preposition that I have never seen before.
[Update: The mail server at Language Log Plaza is fighting a losing battle against the tide of incoming mail offering variations on the phrase "furth of the Firth of Forth". If people would like to stop mailing these in now, that would be nice. Thank you.]
March 27, 2008
Il fallut que j'accusasse: the morphology of serial murder
According to John Lichfield ("Ogre of Ardennes' stands trial for girls' murders", The Independent, 3/26/2008), Michel Fourniret, who "is accused of seven murders of girls and young women and seven sexual assaults in a 16-year reign of terror in France and Belgium between 1987 and 2003",
is a man who likes to play mind games with investigators and appear more cultured than he really is. He is a keen chess player, who talks, and writes, in complex, verbose but inaccurate French, with unnecessary subjunctive verbs and sub-clauses.
Lichfield is not the first to accuse Fourniret of linguistic peculiarities. In fact, this seems to have become part of the standard journalistic narrative. However, I haven't been able to find other evidence that the accused killer's usage is "inaccurate" as opposed to old-fashioned and excessively formal. Thus we learn from "Michel Fourniret : 'l'Ogre des Ardennes'", Le Monde, 3/11/208 that
En prison, il a beau écouter Mozart, relire André Dhôtel, citer Rilke et parler en utilisant subjonctif et plus-que-parfait, il a beau mettre un point d'honneur à corriger méticuleusement ses procès-verbaux, son sadisme au petit pied fait de lui le coupable idéal d'une kyrielle d'autres meurtres non élucidés.
Although in prison he listened to Mozart, re-read André Dhôtel, cited Rilke and spoke using the subjunctive and the pluperfect; although he made it a point of honor to meticulously edit his statements; his small-time sadism made him the ideal suspect for a litany of other unsolved murders.
And back on 7/4/2004, Le Monde ran an article by Ariane Chemin under the headline "Michel Fourniret, récits criminels à l'imparfait du subjonctif" ("Michel Fourniret, crime stories in the imperfect subjunctive"), which amplifies the generalization a bit, and gives an actual example:
Michel Fourniret (…) adore en effet les mots. Ou plus exactement la langue française. Il l’écrit sans aucune faute d’orthographe. Il utilise un français, suranné et ampoulé, plein de circonvolutions, de subjonctifs et de plus-que-parfaits.
Indeed Michel Fourniret (...) loves words. Or more exactly, the French language. He writes it without any spelling mistakes. He uses a French that is outdated and turgid, full of circumlocutions, of subjunctives and pluperfects.
Le moins que l’on puisse écrire, c'est que le Français a une haute opinion de lui-même. Il a des lettres, ce monsieur. Et il aime les faire valoir, tout particulièrement aux yeux des enquêteurs belges. Il trousse le récit de ses viols et de ses étranglements dans des imparfaits du subjonctif: « Il fallut bien que je l’enterrasse. »
The least that one can say is that this Frenchman has a high opinion of himself. He's well educated, this fellow. And he loves to emphasize it, especially in front of the Belgian investigators. He frames the tale of his rapes and his stranglings in imperfect subjunctives: "It was indeed needful that I should bury her."
Chemin presents a picture of someone who flaunts fussy and outdated forms like the simple past (the preterite, or passé historique, e.g. fallut) and the imperfect subjunctive (e.g. enterrasse), but I don't see any support for Lichtfield's claim that Fourniret's French is "inaccurate". (If you have some more extensive quotations from Fourniret, especially if you can also provide an explication de texte, please let me know.)
I'm not sure how this case fits with the French Ministry of Education's recent initiative to reduce urban violence by more instruction in grammar and vocabulary. I'll just observe that enterrasse actually is an imperfect subjunctive, suggesting that French journalists, unlike their English-language counterparts, are still in control of the traditional terminology of morphology.
[Tip of the chapeau to Jeremy Hawker.]
[David Creber wrote with a plausible suggestion:
The idea that Fourniret's French might be 'bad' could be a mistake in translation; someone presuming that 'imparfait' meant 'inaccurate' and not a past continuous aspect.
Similarly, Tim Leonard suggested that
the simplest explanation for Lichtfield's claim that Fourniret's French is "inaccurate" is that he thought "imperfect" meant "not quite correct."
This would certainly be consistent with the command of grammatical terminology among anglophone journalists (and other intellectuals) in general.]
[Alex Price writes:
Fourniret’s French might not be “inaccurate,” but his use of imperfect subjunctive forms is, at the very least, inappropriate, and I think, to give Lichfield the benefit of the doubt, that is what he might have been getting at. (The problem is that “inappropriate French” is too vague. People might interpret it to mean crude language.) The use of the imperfect subjunctive is so inappropriate today, in almost any context other than a comic one, that its use amounts to an error in register: the form may be accurate, but its usage inaccurate. As for French journalists correctly identifying the grammatical form, that’s not surprising. French children still receive plenty of training in grammar, despite the concerns of various politicians. More to the point, the imperfect of the subjunctive is notorious and the subject of many jokes, mostly because it sounds funny. For example, the ending –asse, which you get with –er verbs recalls the –asse ending of many informal, often pejorative nouns: vinasse (bad wine), tignasse (bad hair), paperasse (bureaucratic forms, red tape), connasse (stupid woman), and so on.
]
[More here.]
March 26, 2008
Using the IPA
Since we were recently on the subject of Entering Exotic Characters, I thought it would be good to mention again the International Phonetic Alphabet. A clickable IPA chart that will play examples of the sounds for you is located here at the web site of the University of Victoria. John Wells at University College London has a page on The International Phonetic Alphabet in Unicode. Of course, to get it to show up properly, you'll want a font that contains the IPA. Two fonts designed particularly for their IPA characters are Charis SIL and Doulos SIL
You can enter IPA using any of the methods for entering non-ASCII characters in general but a clickable IPA chart may be particularly useful. You can use this IPA keyboard over the net or install CharEntry on your own system. The Yudit editor has an ASCII-IPA keyboard definition that makes typing in IPA straightforward. For example, you type t for "t", T for θ, s for "s", S for "ʃ", n for "n", N for "ŋ", i for "i", but I for "ɪ".
The fractal theory of Canada
Ed Kupfer writes:
Your "X as the Y of Z" post reminded me of the semi-famous "Fractal Theory of Canada", posted to the Usenet group alt.religion.kibology by "Inflatable Space Bunny" many years ago.
Here's a reprint, to save you from having to follow the link:
Background.
Given a community A and an adjacent community C, such that A is prosperous and populous, and C is less populous and prosperous, and nonreciprocal interest of C in the internal affairs of A, often C will need ego compensation by occaisional noisy and noisome display of its superiority over A. In this case C is said to be the canada of A, C = canada(A).
For example, it has been previously established that
canada(California) = Oregon
canada(New York) = New Hampshire
canada(Australia) = New Zealand
canada(England) = ScotlandThe Fractal Theory of Canada.
For all A there exists C such that
C = canada(A)
For example,
canada(USA) = Canada
canada(Canada) = Quebec
canada(Quebec) = Celine DionIt would appear that the hierarchy would bottom out an individual. However an individual is actually a community of tissues, tissues of cells, cells of molecules, and so forth down into the quantuum froth.
canada(brain) = pineal gland
canada(intestines) = colon
...
canada(electron) = neutrinoand so on. There is no bottom.
"My God! It's full of Canadas!"
An early Language Log post discussed the fractal deconstruction of yankeehood ("It's Yankees all the way down", 9/12/2003), without however daring to take the process to the subatomic (or even anatomical) level.
Is autism the symptom of an "extreme white brain"?
In several previous posts, I've discussed Simon Baron-Cohen's theory of autism as a symptom of an "extreme male brain" (e.g. "Stereotypes and facts", 9/24/2006), and also Mary Bucholtz's hypothesis that nerdity is defined by "hyperwhite" behavior (e.g. "Language and identity", 7/29/2007). I'm ashamed to say that it never seriously occurred to me to cross-pollinate these two theories, until (for serendipitous reasons) I recently read YW Wang et al. "The Scale of Ethnocultural Empathy: Development, validation, and reliability", Journal of Counseling Psychology, 50(2): 221-234, 2003.
Like Baron-Cohen and others over the years, Wang et al. find that females test higher on various scales of measured empathy -- in this case, on scales defined by patterns of answers on a newly-devised test instrument:
| Effect size (d) | |||||
| Empathic Feeling and Expression | 3.89 | 0.87 | 4.47 | 0.78 | |
| Empathic Awareness | 4.30 | 1.04 | 4.72 | 0.92 | |
This is consistent with Baron-Cohen's theory that "empathizing" vs. "systematizing" is influenced by fetal testosterone levels (more on this in future posts). But fetal testosterone levels seem unlikely to be responsible for another result reported by Wang et al.:
| Effect size (d) | |||||
| Empathic Feeling and Expression | 4.12 | 0.86 | 4.73 | 0.68 | |
| Empathic Awareness | 4.43 | 0.99 | 5.05 | 0.82 | |
Thus, in their sample at least, the difference between males and females in two empathy-related measures was smaller than the difference between whites and non-whites.
We don't know how general or stable this result is, because the sample was neither representative nor balanced:
After accounting for missing and invalid data (n = 16), we used a data set that included 323 undergraduate students who were enrolled in three Midwestern universities or colleges for the analysis. The sample included more women (66%, n = 213) than men (25%, n = 81), with 29 respondents not indicating their gender. Most of the participants were between the ages of 18 and 22 (97%, M = 19.73 years); most were single and had never been married (97%). [...] A majority of students in the sample described themselves as Caucasian (83%). African Americans constituted 6% of the sample, 5% were Asian American or Pacific Islander, 3% were biracial, 2% were Hispanic or Latino/Latina, and 1% were Native American.
On the other hand, the samples used in sex-differences research are often quite small, and are not in general demographically balanced. We wouldn't trust pollsters who claimed to characterize gender differences in the American electorate based on a sample of, say, 20 UCLA medical students. (Though if they use fMRI scans rather than questionnaires, they can apparently get past the editors at the New York Times.)
Let me note in passing that the magnitude of measured group differences in features like "empathy" may depend on whether the testing situation draws subjects' attention to their self-presentation. Rather than measuring how empathetic people are, some techniques seem to measure how empathetic they want others to think think they are. Thus according to the literature review in Nancy Eisenberg and Randy Lennon, "Sex Differences in Empathy and Related Capacities", Psychological Bulletin 94(1): 100-131, 1983:
In general, sex differences in empathy were a function of the methods used to assess empathy. There was a large sex difference favoring women when the measure of empathy was self-report scales; moderate differences (favoring females) were found for reflexive crying and self-report measures in laboratory situations; and no sex differences were evident when the measure of empathy was either physiological or unobtrusive observations of nonverbal reactions to another's emotional state.
A more recent survey (Richard A. Fabes and Nancy Eisenberg, "Meta-Analyses of Age and Sex Differences in Children's and Adlescents' Prosocial Behavior", 1998) came to a similar conclusion:
Sex differences were greatest when demand characteristics were high (i.e., it was clear what was being assessed) and individuals had conscious control over their responses (i.e., self-report indices were used); gender differences were virtually nonexistent when demand characteristics were subtle and study participants were unlikely to exercise much conscious control over their responding (i.e., physiological indices). Thus, when gender-related stereotypes are activated and people can easily control their responses, they may try to project a socially desirable image to others or to themselves.
To avoid misunderstanding, let me be explicit: Despite the humorous question in the title, I'm not suggesting that there are innate racial differences in empathy, nor that autism is caused by excessively caucasian genetics. Rather, I'm suggesting we should be cautious about attributing stereotypical male-female differences too quickly to the (developmental or immediate) effects of sex hormones.
[For a serious exploration of the effects of sex, race and class on rates of autism (or at least autism diagnosis), see Tanya Karapurkar Bhasin and Diana Schendel, "Sociodemographic Risk Factors for Autism in a US Metropolitan Area", Journal of Autism and Developmental Disorders, 37(4): 667-677 2007.]
March 25, 2008
X as the Y of Z, again
In response to our recent MT funfest, Peter McBurney wrote:
Your post reminded me of a funny experience from my management consulting days. In the early 1990s, we submitted a proposal to the Government of Uruguay to advise on reform of their telecommunications market. Our proposal included the sentence, "Uruguay has been called the Switzerland of South America".
Our proposal was unsuccessful, but shortly afterwards we were invited to make a similar proposal to the Greek Government. With a word processor, we were able to make a few edits to the text and submit it anew. Only after submission did we notice that we'd somehow written, "Greece has been called the Switzerland of South America".
To avoid these little cut-and-paste or search-and-replace embarrassments, it certainly be would be more convenient if we could just say "X is the Y of its superordinate category", in instances of the phrasal template "X is the Y of Z" (previously discussed here).
In any case, a quick web search reveals that Uruguay is far from alone in being identified as "the Switzerland of South America":
[Bariloche, Argentine] features forests, spectacular glaciers, and mountains surrounding gorgeous lakes, earning its nickname, "the Switzerland of South America."
Puerto Montt is the capital of Chile's exquisite lake district, the "Switzerland of South America."
[Ecuador] is truly the land of eternal springtime, and the "Switzerland of South America."
Ushuaia is often referred to as "Argentine Switzerland" or the "Switzerland of South America"
Lebanon was once called "The Switzerland of the Middle East" and Chile the "Switzerland of South America."
[Puerto Varas, Chile] is known as the "Switzerland of South America," ...
And Isaiah Bowman, South America: A Geography Reader, 1915, puts forward a case where the relation is symmetric, at least in the sense that X is the Y of Y's superordinate category at the same time that Y is the X of X's superordinate category:
For this reason Bolivia is sometimes called the "Switzerland of South America", but it would be more nearly correct to call Switzerland the Bolivia of Europe ...
Web search reveals that Guinea, Uganda, Swaziland, Ethiopia, Zimbabwe, Malawi, Burundi, Lesotho, Rwanda, and Zaire are among the places called "the Switzerland of Africa".
A search for {"the Switzerland of"} turns up 34,400 hits, many of them not at all geographical. For example, {"The Switzerland of * software"} alone yields 4,900 hits.
And we would be remiss in failing to note that Liechtenstein is sometimes called "the Switzerland of Switzerland".
Of course, it's not only Switzerland that places the role of Y in geographical snowclones of the form X is the Y of Z. It's well know, for example, that Belgium is the New Jersey of Europe -- except that web search shows that France, Holland, Albania, Wales, England, and Russia are all competitors for this title.
There are 101,000 hits for {"the Athens of"}: Lexington (KY) was once known as "the Athens of the West", and Nashville (TN) has often been called "the Athens of the South"; while "the Athens of the North" is Edinburgh (Scotland) , unless it's Munich, Vilnius (Lithuania), or Belfast (Northern Ireland); and "the Athens of the East" might be Alexandria (Egypt), Antioch (Syria), or Madurai (India), among others. "The Athens of America" is what some (Bostonians?) call Boston. The "Athens of Africa" might be Fez, Dakar, Freetown, Timbuktu, or Cyrene.
Bringing the strands together, we find that Zurich and Basel compete for the title of "the Athens of Switzerland", but no page indexed by Google has yet speculated as the identity of "the Switzerland of Athens". (However, "the Switzerland of Greece" is variously identified as Evritania, Karpenissi, or Arcadia.)
And we can also learn on the web that PsyBlog is "the Language Log of psychology, maybe", while Savage Minds "bids fair to be the Language Log of anthropology".
[Update -- Geoff Nunberg writes:
A Roman friend of mine used to refer to Rome as the Switzerland of Africa.
]
[Faith Jones writes:
Vilnius is the Athens of the north? Must be the goyish Vilnius. Vilne, Jewish Vilnius, was the Jerusalem of Lithuania. In Yiddish you can refer to "Yerushalayim de-Lite" (ירושלים דליטע) without further explanation. It only refers to pre-1941 Vilne, however.
Point taken. But I didn't make it up -- just search {Vilnius "Athens of the North"}.]
[Andrew Wilkinson adds another dimension:
All this (semi-confusing but puzzle-outable) talk on Language Log about Canadas of regions being one of a variety of other regions, or possibly also being Canada themselves, unless reminded me of the most outrageous Trivial Pursuit question I ever had to answer (bear in mind that I was a kid and didn't even know what two of the proper nouns referred to):
"What German city do Italians call the Monaco of Bavaria?"
My stock Trivial Pursuit answer of "Arnold Schwarzenegger" didn't fly; apparently it is actually Munich. But to this day it remains my personal favorite of obtuse, spurious trivia, and it seems to me that it adds a fourth, more confusing and surreal dimension to the three-part snowclone in your previous examples.
By the way, the Athens of the U.S. is of course well known to be Ann Arbor, Michigan -- don't know how anyone could think otherwise.
]
[Bob Ladd explains:
I can't resist responding to two things in this post.
First, the standard put-down response to anyone who refers to Edinburgh as "the Athens of the North" is that it is really more like "the Reykjavik of the South" (Google suggests that the line originated in a Tom Stoppard play). I think this must say something interesting about the semantics (or pragmatics) of the "X is the Y of Z" construction, but Geoff Pullum has taken away my semanticist's license so I won't pursue that thought.
I'm on surer ground demystifying the "Monaco of Bavaria" business. There is nothing "confusing and surreal" about this at all, and it's not, as Andrew Wilkinson suggests, "obtuse, spurious trivia", just a true but boring fact about constructing unambiguous referring expressions. Here's the story: the city known to the Germans as Muenchen has had its name adapted in some other languages, like "Munich" in English and French and "Monaco" in Italian. (Italian also adapts several other German city names, including Stuttgart as Stoccarda and Leipzig as Lipsia). So this means that Italians have occasion to refer to two different cities called (in Italian) Monaco, one a bit west of Genoa (or Genova) and one rather farther north of Venice (or Venezia). Just as Americans talk about Portland Maine and Portland Oregon, and Germans have to distinguish Frankfurt am Main from Frankfurt an der Oder, Italians distinguish the two places called Monaco, when it's not clear from the context, by specifying that one of them is in Bavaria. The guy who made up the Trivial Pursuit question was either uninformed or else just having some fun with the way he phrased the question.
]
March 24, 2008
The (probable) truth about Austria and Ireland
In a couple of earlier posts, I expressed puzzlement about what patterns in parallel or comparable text corpora could have persuaded Google's statistical MT algorithms to translate "Austria" as "Ireland", and so on. Several readers, and Melvyn Quince, had a bit of irreverent but irrelevant fun with the resulting silliness, of course. Anyhow, Bob Moore from Microsoft Research has sent in a very plausible explanation. Like many such theories, it's completely obvious in retrospect.
Although I obviously do not have access to the inner workings of Google's system, I am quite certain of this, because we have observed exactly the same thing happen at Microsoft in some of our research systems that are built along similar lines to Google's.
The problem comes about because these correspondences occur in the training data. As you know a statistical MT system such as Google's is trained on a parallel corpus in a pair of languages. But much of the parallel data one might find is not simply translated, but is "localized". Lengths are changed from feet to meters, prices are changed from dollars to Euros, and contact information is changed to be appropriate for the target audience. This means addresses are changed! The website of a multinational corporation might have a contact address in French version that has "Paris, France" in a place exactly parallel to where the UK version has "London, England". If these are fed as parallel text into Google's training algorithm, it will learn that one possible translation of "Paris" is "London" and one possible translation of "France" is "England". What translation is picked depends on frequency, but also on contextual factors, which is probably why the way "Austria" is translated depends on how many exclamation marks it is followed by.
I think that there are some other things going on as well -- the correspondences between "Indiana" and "Indianapolis", and "Austria" and "Australia", are very likely caused by a too-permissive model of probable transliteration relations. And the contextual effect of the number of exclamation points remains mysterious.
But the idea of structural correspondences between different local contact addresses is something that should have occurred to me. I'm too used to thinking about translations of legal codes and news stories and such-like things as sources of parallel text.
[Update 3/25/2008: Most (maybe all?) of these oddities have now been fixed. Quick work!]
Colon rage
Says geography professor Ron Johnston of the University of Bristol, in a letter to Times Higher Education (March 6, 2008, p. 29):
I note that in his work on the use of colons ("Colonic information", 28 February) James Hartley has adopted the appalling American practice of following a colon by a capital letter. I note that you have not followed him in your leader in the same issue, and trust that you will continue to use English English.
Some people really do have the threshold on their appallingness meter set to the wrong value, don't they? If we are going to use up the word "appalling" on a tiny variation in orthographic conventions, what kind of adjective will be left to describe the taste of fermented soy beans in methylated spirits, or the sound of a cat being electrocuted during a child's violin lesson?
The alleged datum to which Johnston is so super-sensitive is that in British printed prose the first letter after a colon within a sentence is not capitalized. But naturally, this is never true if what follows the colon is a direct quotation, a proper name, a capital-letter abbreviation, or any other case where initial capitalization is normal as in (British) examples like this:
BBC One today: The Passion (http://www.bbc.co.uk)
Explanation of the main types of committees: Select, Joint and General. (http://www.parliament.uk/about/how.cfm)
So it's not, surely, the mere sight of a capital letter following a colon that sets him off. What's more, the contrast with American usage is by no means fully general. Professor Johnston is wrong if he thinks there is always a capital letter after a colon in U.S. sources; consider a recent example of New York Times usage:
But he is making his foray even as he embraces what much of the world sees as the most hated remnant of the Bush presidency: the war in Iraq. (http://www.nytimes.com/2008/03/23/us/politics/23mccain.html)
The Cambridge Grammar of the English Language says nothing about a British/American contrast, but only that "the colon is sometimes followed by a capital letter", and that "It seems best in such cases to take the colon as marking the boundary of a sentence" (see p. 1736).
I have done only a small amount of investigation, and don't intend to spend a great deal of time on this rather trivial topic, but I am not sure there is a robust dialect contrast here (though there may be). It certainly seems to be mostly or entirely with full independent clauses following colons that we get capitalization, as in these cases:
March security updates: Download now to help protect your computer (http://www.microsoft.com)
But it's like this: If you keep eating the same fried chicken every night, you get tired of it. (http://www.nytimes.com/2008/03/23/nyregion/nyregionspecial2/23Rnewark.html)
Both the examples cited by The Cambridge Grammar are of this sort, with independent clauses after the colon.
But anyway, whether or not this is the correct linguistic generalization about the sporadic occurrence of capitalization after colons, let's face it (and I'll follow the American capitalization convention at the risk of driving Professor Johnston over the edge): A man who thinks this is the kind of thing that should be described as "appalling" is a man who should consider whether it's time to switch to decaffeinated.
Why Austria is Ireland
There has been a lot of activity here today in the great research center at One Language Log Plaza. People are running up and down the corridors showing each other new examples of Google's purportedly eccentric translation behavior. The Google translation algorithms perform strange substitutions involving European country names and language names. Among these are replacements of Ireland for Austria, and also sometimes Canada for Austria. I am rather surprised that none of the excited people falling over themselves in the corridors have noticed the obvious generalization.
The Google translation engine is of course a brute-force statistical scheme based on massive amounts of compared bilingual text, and it is quite insensitive to actual meaning. Notice that in one case the algorithm produced a text asserting that the Parliament of Canada meets in Vienna and in another the output text said that Vienna is in Ireland, but only if there were three question marks after the word Austria in the input. The translation algorithms clearly know nothing of politics, geography, or sober punctuation.
In my opinion, what is being statistically detected by the pseudo-translation algorithms is the blindingly obvious relation that holds between the relevant pairs. Think about it: In what respect is it that Ireland is to the UK (for British English speakers) as Austria is to Germany (for Germans), and also as Canada is to the USA (for American English speakers)?
The relevant relation is the one that country A bears to country B when (a) the two are adjacent, (b) A is somewhat looked down on by B, and (b) A uses the same language as B, but in what is regarded (by the citizens of B) as a recognizably different and inferior, or risible form.
I would therefore predict Google translation errors involving other such pairs: A = Belgium, B = France; A = Belgium, B = Holland; and A = New Zealand, B = Australia.
Certain language-name substitutions have also been noted; among them is Spanish for German, produced in a German-to-English translation performed on English text. Notice that Google thought it was reading a German text (about Austria) and translating it for English speakers, though the alleged German was really English. Now, in what way is Spanish for English speakers like German for German speakers?
It should be obvious. The relation is the one holds between a language L and a nationality N when L is the language people of nationality N are most likely to hear spoken around them when they are away on a foreign vacation.
These questions are simple enough if you just think logically.
Austria == Ireland?
In response to yesterday's post about odd transnational substitutions in Google's translations ("Made in USA == Made in Austria|France|Italy|... ?"), Martin Marks writes:
I'm afraid I don't have an answer for your crazy Google mistranslation question, but I do have some even crazier data for you to deal with. On a whim, I "translated" your entry from German to English in its entirety. Most of the entry remains unchanged, with a few weird exceptions. ("German-to-English" is unchanged, for example, but "German-to-French" becomes "English-to-French".) However, one sentence really jumped out at me. You wrote "Of course Austria is not a German word...", but Google translated that as "Of course Ireland is not a Spanish word..."
Madness! Madness! I don't know if I can deal with this.
Of course, the translation program's main fault in this case is not to recognize that it's being asked to translate from German to English a sentence that's already in English to start with:
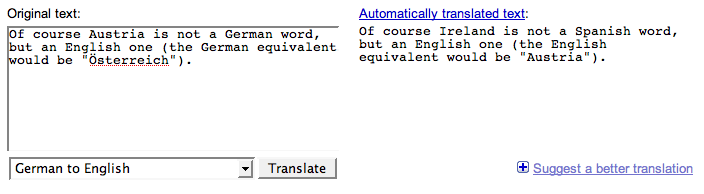
That said, we're certainly well beyond the simplistic notion that certain place-names are being translated into and out of a sort of interlingual <here>. Given the previously-documented translations between "Austria" and "Australia", I suspected some sort of string-matching in comparable text as the culprit, but I don't think this can help explain "Austria" and "Ireland".
Pekka Karjalainen found another way to get from Austria to Ireland:
But J.J. Emerson learned by translating the (English) wikipedia entry on Austria from German to English that "The high mountainous alps in the west of Ireland flatten somewhat into low lands and plains in the east of the country", and "The parliament of Canada is located in Vienna, the nation's largest city and capital."German to English translation can also give this strange result. It appears to only result in Ireland when I have three !'s.
Vienna is in Austria!!! ==> Vienna is in Ireland!
I couldn't find any similar phrase that changes so when going from English to another language. This also is the only time I've gotten a result with Ireland yet.
I was just doing a thorough examination of the Google Translation phenomenon when I discovered among other things that Ireland has alps and that the Parliament of Canada meets in Vienna. It looks like I was scooped only by minutes!
I obtained this by feeding the Wikipedia Entry for Austria through the Google translate engine (link).
I've attached a PDF of the whole page in case Google fixes it soon and some choice pngs that are amusing.
I don't understand it either, but it is fun.
]
[Ron Lee supplies the following:
I think I found another punctuation effect: it seems that "!?!?" often (but not always) evokes a...sense of wonder ("and why?") on the part Google's Machine Translation program (besides Austria sometimes translating to Australia & Indiana to Indianapolis):
1. Is Australia in Austria? ==> Is Australia in Australia?
2. Is Austria in Australia? ==> Is Austria in Australia?
3. Is Austria in Australia!?!? ==> Is Austria in Australia and why?
4. Is Australia in Austria!?!? ==> Is Australia in Australia!?
5. Australia is in Austria!?!? ==> Australia is in Austria and why?
6. Is India in Indiana? ==> Is India in Indianapolis?
7. Is India in Indiana!?!? ==> Is India in Indiana and why?
8. Is India bigger than Indiana!?!? ==> Is India bigger than Indiana and why?
9. Is India not smaller than Indiana!?!? ==> India is not smaller than Indiana and why?
10. Isn't Indiana smaller than India!?!? ==> Is not Indiana smaller than India!?
11. Isn't Indiana bigger than India!?!? ==> Indianapolis Is not bigger than India!?
]
[Update 3/25/2008: Most (maybe all?) of these oddities have now been fixed. Quick work!]
Outwith
Many people think that while new nouns are made up all the time, and new verbs and adjectives are occasionally coined, the prepositions form a small set that is fixed and unvarying over centuries of time and across the English-speaking world. It doesn't seem that way to me. I still remember with pleasure the day I discovered a new one in Australian English, one that other dialects do not have. I might tell the story here some time. (I already told it in a talk on Australia's ABC Radio National, in a program called Lingua Franca, in 1998. Note that the preposition involved in that case was an intransitive one, like away, not taking a noun phrase complement. That means the traditional view would treat it — wrongly, I claim — as an adverb. Someone wrote to Lingua Franca about that point, so I explained the details in a later talk, transcript here.) Anyway, it was not long after my move to Scotland last year that I encountered a preposition that I did not recollect ever having seen or heard before, either in my early decades of living in Britain, or my many years after that living in California, or my long visits to Australia: the preposition outwith. Mark Liberman discussed it in this post in 2006 (which I had forgotten about until Lindsay Marshall reminded me; thanks, Lindsay). It means, as Mark said, "outside of" (exactly what without meant a century or two ago, before its shift to the meaning "not having"). And Mark noted that it is recorded as largely limited to Scotland. But the new part of the story is that it is not entirely thus limited: the other day I saw it used in an English newspaper, which could mean that it is spreading rather than becoming extinct. We shall see.
The prepositions of English are not by any means a small, fixed set. There are hundreds of them, and they vary a bit across dialects (though of course nowhere near as much as nouns). They are even, occasionally, borrowed into English from other languages. If you sit and think for a while you will probably be able to think of a few. I may post on this after a while. Or maybe not. Maybe I will decide it falls outwith my purview.
March 23, 2008
Think of the Children
Geoff's discussion of the ridiculous amount of attention paid to the "fleeting expletive" problem in the United States reminds me of a concern that some Carrier people have with dictionaries, namely that they should not contain naughty words for fear that the children will learn them, as if their little minds will somehow be warped by learning the words that describe the central activity of human beings.
Carrier people who do not speak Carrier generally know a few common expressions such as Hadih "hello" and musi "thank you", a few basic words that they learn in language classes, such as lhi "dog" and duni "moose", and a few culturally salient terms, such as balhats "potlatch" and 'uza "noble in the clan system", but are unable to form a sentence because they know no verbs, which is crippling in a language in which just about everything is underlyingly a verb and in which verbs have hundreds of thousands of forms.
I've discovered, though, that if you get to know someone well enough, he or she almost always turns out to know one form of one verb: nyoosket, which is the first person singular subject with second person singular object optative affirmative of "to fuck". The optative has many uses, somewhat like the subjunctive in Romance and Germanic languages: it is, for example, the appropriate form to use in the "lest" construction, e.g. ...nyoosket whuch'a "lest I fuck thee", but on its own this form is best translated "I'm going to fuck you" or "would that I fuck you".
It turns out, then, that keeping naughty words out of the dictionary is ineffective: the non-speakers did not learn nyoosket from a dictionary. What is particularly ironic is that the single most important thing that those who are not native speakers of the language lack is the ability to conjugate and parse verbs, and that the one verb form that they are likely to know is assiduously avoided in language classes in spite of the fact that it is, from a pedagogical point of view, the ideal verb. Its stem is invariant and easy to pronounce, it requires no thematic prefixes (that is, the only prefixes that it includes are grammatical things like the subject and object and aspect markers), and it has a simple, straightforward meaning. If I had my way, the kids would be going around reciting: nyusket (I fuck thee), nyutesket (I am going to fuck thee), nyoosket (would that I fuck thee), nyuzusket (I fucked thee), lhoduket (let's the two of us fuck each other), etc.
A little more on obscenicons
In today's mail: a wonderful billboard that uses Chinese characters and Spanish punctuation marks as obscenicons, and some speculation about why = and + aren't good obscenicons. This is a follow-up to two earlier postings.
The billboard advertises Chino Latino, a Minneapolis restaurant (at Lake and Hennepin, which might not be clear from the photo) that offers "street food from the hot zones", so the mixture of characters from Chinese and Spanish has some motivation. The source of this photo, correspondent SYZ, suggests that the Chinese is gibberish (but see below), and notes that the sentiment is "a reference to the unspeakable awfulness of the weather in my lovely hometown of Minneapolis, where it snowed on Friday."

[Added 3/26/08: The billboard has found its way to the delightful website Hanzi Smatter, "dedicated to the misuse of Chinese characters in Western culture", where it's noted that the billboard has repetitions of a sequence of characters meaning 'new imitated Song typeface'. We last mentioned Hanzi Smatter on Language Log here.]
Meanwhile, Patrick Masterson writes to suggest that the problem with + and = as obscenicons is that they're not squiggly enough. Good point. He goes on to propose that
which would imply that the cartoonists' obscenicons preceded the punctuational ones. As I said before, I know nothing about the history of these conventions, but it's also possible that punctuational obscenicons came first (or that the conventions evolved together), and that they were chosen because of their other uses (! ? *) or because they were sufficiently large and squiggly to be prominent.
Y is X plus something
Another abstract for a paper that grew in part from material on Language Log. This time it's for a conference to honor Jerry Sadock, May 2-3 at the University of Chicago.
Again and again, it turns out that items X and Y that are widely taken to be synonymous (differing at most stylistically) are in fact subtly different in their semantics or pragmatics (as Bolinger maintained some years ago). In many (though not all) such cases, X is general and Y specific, in the sense that Y is semantically/pragmatically "X plus something". A few cases:
1. Diffcult is hard plus a nuance or connotation or implicature that "the need for skill or ingenuity is required" (AHD4).
2. Jerry Sadock (on Language Log) has argued that nearly n (where n is a numerical expression) is almost n plus the connotation "that n exceeds (hence is better than) what was expected or hoped for".
3. Subordinating once S1, S2 (Once you finish editing this article, you should start on a new one) is after S1, S2 (indicating temporal sequence) plus a presupposition or implicature that the event denoted by S2 is somehow contingent on the event denoted by S1 (from Jason Grafmiller.)
4. The sentence-initial contrastive connective however is but ('against expectation') plus the connotation that it's specifically PROPOSITIONS that are in contrast (from Zwicky & Kenter).
5. The determiner lot (a lot of money/dollars) is the much/many of extent (much money, many dollars) plus a connotation that the extent is significant in the context (from Grano & Zwicky).
6. Motional out of + Object (walk out of the door) is out + Object (walk out the door) plus a connotation of special significance for the thing denoted by the Object in the context.
7. The restrictive relativizer which is the subordinator that plus components of anaphoricity and non-personal reference.
Most of these cases figure prominently in the advice literature on English grammar, style, and usage, where the usual recommendation is to consistently choose one of the putatively synonymous variants over the other, on some criterion or another (omit needless words, avoid potential ambiguity, avoid overused words, avoid ponderous words, avoid colloquial or conversational items, etc.). The ubiquity of Bolingerian differentiation in these cases, and especially of general/specific differentiations, suggests that the forced-choice strategy of many usage advisers is misguided, since it amounts to depriving the users of the language of valuable expressive resources.
Article-article article abstract
Below is a conference abstract for a paper that grew, in part, out of material I was preparing for Language Log. The paper was scheduled to be given at the American Dialect Society meetings in January, but because of sickness I wasn't able to give it then. I then started expanding the abstract into a posting for Language Log, but of course it's been ballooning. So here's the abstract as a promissory note.
Article-article article:
Faithfulness meets Well-Formedness (again)
Case 1. Some proper names in English begin with an article: The Simpsons. Proper names can be used as prenominal modifiers -- Macbeth performance -- but then these nominals need a determiner to serve as full NPs: a/the/this Macbeth performance. What happens when we put these two things together: a The Simpsons show (preserving both articles) or a Simpsons show (suppressing one article to fit the syntactic patterns of English)?
Case 2. Some quantity modifiers in English begin with the article a: a lot. Quantity modifiers can modify comparatives -- much bigger -- and the combinations can modify nouns -- much bigger dog -- but the resulting nominals need a determiner to serve as full NPs: a/the/this much bigger dog. What happens when we put these two things together: an a lot bigger dog (preserving both articles), or a lot bigger dog (suppressing one article)?
In both cases, Faithfulness (Faith: preserve the form of the proper name or quantity modifier) conflicts with Well-Formedness (WF: make things fit the syntax of the language). When Faith meets WF, there are several possible outcomes: stalemate (neither resolution acceptable), resolution in favor of one or the other alternative, variation (both resolutions acceptable).
For article + article, pretty much everything goes, but it's not chaotic. In general, WF usually wins, but all possibilities are attested; the two cases are not entirely parallel; and the choices depend a lot on the particular items involved and the contexts they're in.
I relate these two conflicts between Faith and WF to a large number of other cases, involving the conventions of punctuation, capitalization, and spelling; the treatment of taboo vocabulary; "semantic" vs. "grammatical" determination in agreement; assignment of nouns to Count vs. Mass; and much more.
1/29/06: Dubious quotation marks
4/9/07: Ducky identity
8/1/07: Cousin of eggcorn
8/12/07: e e cummings and his iPod: Faith vs. WF again
9/21/07: Punctuational hypercorrection
Made in USA == Made in Austria|France|Italy|... ?
Antonio Cangiano has noticed an odd thing about Google's statistical translation software. As he puts it,
Google Translate sometimes changes the country mentioned within the source language to the main country of the translation language.
I've checked the examples that he cites, and they work exactly as he says.
For example, Austria can be rendered as "USA":
Or as "France", if the target language is French:
Of course Austria is not a German word, but an English one (the German equivalent would be "Österreich"). But something similar can happen in translating from English:
The phenomenon is a subtle one. Thus in the German-to-English example, the source language is really English, not German. And similarly, in the German-to-French and English-to-Italian examples, the whole phrase is being "translated" from English (or English-pretending-to-be-German) into English-pretending-to-French or English-pretending-to-be-Italian", just substituting "Italy" or "France" for "USA" or "Austria".
I can usually figure out the reasons for amusing translation errors, but I remain a bit puzzled about this one.
Statistical machine translation, of the kind that Google uses, traditionally combines two sorts of information:
- statistical relationships between words or phrases in the source language and words or phrases in the target language;
- statistical word-sequence patterns in the target language.
One of the strengths of Google's MT systems is the size of the samples from which they build their models. Perhaps these samples are large enough for their German-to-English and German-to-French systems to have cross-language information for a significant number of non-German words -- like "Austria". But I don't see why this information would map "Austria" onto "USA" or "France" respectively. And this will not help with the "USA" to "Italy" problem.
Then again, perhaps these amusing errors are a symptom of a different kind of statistical modeling, based on looking for source-target mappings in bodies of untranslated but somehow "comparable" text. For example, we look for an English string E, occuring in contexts AEB, and an Italian string I, occurring in contexts CID, such that A_B and C_D are sufficiently "similar" for us to conclude that E and I may be translations. But I don't see why comparable texts would contain patterns that would create these errors.
If you think you know -- or especially if you really know -- what's happened here, please let me know.
[A reader writes:
It looks like the translator is looking at "Made in USA" with a meaning of "Made in [here]" as opposed to "Made in [specific place]", so it just naturally swaps the country names. Just my guess, though.
That's the obvious route to the mistake. What I don't understand is what statistical patterns in parallel or comparable text would lead a modern MT algorithm to take that path. ]
[Pekka Karjalainen writes:
The posting on Language Log about the translation of country names prompted me to test the feature. I found that the punctuation following the phrase sometimes affects the translation. I couldn't find any consistency in how it happens with different language pairs, but I found that this worked the same way for me every time:
Made in Austria!! => Made in USA!
Made in Austria! => Made in Austria!Here => represents using the translator to go from German to English. With German to French, you can try having a trailing comma right after the same phrase and then some other punctuation mark (or nothing at all).
This probably calls for more thorough testing (which many Language Log readers might volunteer to do). For starters, I hope you can in fact repeat my results.
(I used the Google translator at this address, just to make sure: http://translate.google.com/translate_t.)
]
[Empty Pockets writes:
Following up on Pekka's comment, I got the following (mystifying) results:
I live in Austria! ==> I live in Australia!
I live in Austria!! ==> I live in Canada!
I live in Austria!!! ==> I live in Canada!
I live in Austria!!!! ==> I live in Australia!!In each example the translation is German ==> English.
Wow. ]
March 22, 2008
Entering Exotic Characters
Yesterday for the umpteenth time I was asked for assistance in getting exotic characters into a blog post, so I thought I'd post a little information about this.
If you've got already got the text that you want in Unicode, the problem with getting it into a blog post is probably that your blog software, like the Movable Type package that runs Language Log, gags on non-ASCII characters. To overcome this limitation, you need to replace your Unicode text with HTML numeric character references. For example, instead of directly entering the Unicode for "lower case e with acute accent" é, you enter é. This consists of the Unicode codepoint in hexadecimal 00E9, with the prefix &#x and the suffix ;. It is also possible to give the codepoint in decimal, should you be inclined to the vulgar idiom, in which case you omit the x: é.
If you know or can find out what the codepoints are and you only have a few characters to enter, you can do this manually, but it is easier to use a converter. Assuming that you are connected to the net, you can use Richard Ishida's Uniview converter. Just enter your text in the "characters" window and press "convert", then cut and paste the resulting HTML from the window to the right into your post.

I myself usually use my command-line program uni2ascii. It is installed locally and so doesn't require web access. It is faster and does many more types of conversion, though for most people that doesn't matter.
Of course, you may need to get the Unicode in in the first place. The easy case is where the language is one in which you are accustomed to writing and you have your keyboard mapped for it or some other sort of input system. These exist for many writing systems, but not all, and if the writing system is one that you don't use regularly, it may be too much trouble to track one down and install it, or using it may be difficult. If you don't have a convenient method of entering the writing system you want to use, you may find a solution in Yudit. Yudit is a Unicode editor available free for all major platforms. It doesn't have all the bells and whistles of other text editors and word processors, but it is very good at rendering Unicode and has a simple system for defining your own keyboard mappings and switching among them. It comes with nearly 200 keyboard mappings created by the author or contributed by users.
Here I am entering Carrier syllabics.
If nothing else works, you can always go to the source, namely the website of the Unicode Consortium: http://www.unicode.org. The various files containing the details of the current version of the standard always reside in the directory http://www.unicode.org/Public/UNIDATA/. Of particular interest are NamesList.txt, which pairs character names with codepoints:
00E8 LATIN SMALL LETTER E WITH GRAVE : 0065 0300 00E9 LATIN SMALL LETTER E WITH ACUTE : 0065 0301 00EA LATIN SMALL LETTER E WITH CIRCUMFLEX : 0065 0302UnicodeData.txt which contains additional detail in a terser format intended to be read by machines:
00E8;LATIN SMALL LETTER E WITH GRAVE;Ll;0;L;0065 0300;;;;N;LATIN SMALL LETTER E GRAVE;;00C8;;00C8 00E9;LATIN SMALL LETTER E WITH ACUTE;Ll;0;L;0065 0301;;;;N;LATIN SMALL LETTER E ACUTE;;00C9;;00C9 00EA;LATIN SMALL LETTER E WITH CIRCUMFLEX;Ll;0;L;0065 0302;;;;N;LATIN SMALL LETTER E CIRCUMFLEX;;00CA;;00CAand Unihan.txt, which contains information about Chinese characters. (Since this file is very large, a compressed version is also available for download: Unihan.zip.) These are plain text files which you can search in any text editor or word processor. I have enough reason to look at the information in UnicodeData.txt that I wrote a little browser for it. John Wells has information about the International Phonetic Alphabet in Unicode.
Many people find it easier to use a character map, which shows you a selected block of characters and lets you select characters to insert into a text and provides information about them. The one I use is Gucharmap.
UnicodeChecker for Mac OS X and BabelMap and Unibook for Microsoft Windows are similar. All MS Windows systems come with Character Map, which shows the characters in a particular font.
Some word processors provide a similar facility. In OpenOffice.org Writer, if you click on Insert->Special Character, you will get a chart showing the characters in the currently selected font. Here it shows a portion of the SIL Doulos font, which has good coverage of the International Phonetic Alphabet.
If you need to enter characters frequently, looking for them in a general purpose character map quickly becomes tedious, so special purpose tools are useful. I often use CharEntry, which provides a number of clickable charts, such as this one of the consonants in the International Phonetic Alphabet:
The other thing that I find particularly useful is that you can define custom character charts by creating a file listing the codepoints that you want and the glosses to display as tooltips when the pointer is over the character. Here's the control panel with an Armenian alphabet chart.
The definition begins like this:
Armenian|10|clearlyu|12 \u0561:\u0531|ayb \u0562:\u0532|ben \u0563:\u0533|gim \u0564:\u0534|daFor each letter you enter a line containing the codepoint of the letter (in this case two, lower- and upper-case, separated by a colon), followed by a pipe symbol and the gloss for that letter.
Two good sources for additional resources are the Unicode Consortium's Resources page and Alan Wood's Unicode Resources page, especially the section devoted to fonts.
An annual appeal
Forwarded from the American Dialect Society mailing list yesterday, a message from Grant Barrett:
If you have used its list archives, job postings, or other services over the last year, I would like to encourage you to contribute. I believe it's important that we recognize those good parts of the Internet and it is our personal duty to keep them alive.
If you work for an institution, please consider making a contribution of a size proportional to your organization's use of or appreciation for Linguist List.
Linguist List provides a (moderated) discussion forum, job listings, book announcements and reviews, calls for papers and conference programs, links to resources of many kinds on language and linguistics, and the Ask a Linguist service. It also hosts over a hundred linguistics-related lists, and it archives many of them (including ADS-L). All for free. It's the sort of operation that actually requires a staff (students who receive fellowships), which means that it needs real money.
If you're unfamiliar with Linguist List, check out the site. There's a lot there.
When you contribute to the fund, you can have your contribution credited to an academic institution, in the Grad School Challenge. The winning institution gets glory and some academic booty.
Unlike Grant, I have some connection to Linguist List: I'm an Advisor to the list, and this year I'm one of the featured Linguists of the Day (this year called Ringmasters -- there's a circus theme), along with William Labov, Peter Trudgill, Language Log's own Barbara Partee, Steven Pinker, Katarzyna Dziubalska-Kolaczyk, and Lenore Grenoble. (Geoff Pullum was one of the featured linguists last year.) We each wrote up the story of how we got into linguistics, and these are being posted at intervals during the fund drive. (And now you can nominate a Linguist of the Day for 2009.)
Something wiki this way comes
Geoff Pullum has now written a spirited defense of Wikipedia. I applaud. But on one point I have to issue a warning, having recently read Nicholson Baker's "The Charms of Wikipedia" (a review of John Broughton's Wikipedia: The Missing Manual, yet another splendid volume in the O'Reilly series of computer books) in The New York Review of Books (3/20/08, pp. 6-10). What's at issue is Wikipedia as a boundless resource (unlike conventional print encyclopedias) -- this in face of an enormous number of entry deletions (Baker says about 1,500 a day), some of them removing clearly nuisance items, but some of them performed by "deletionist" editors bent on purging the site of entries they view as insufficiently important.
I admit to having a personal interest in the question. At least once, my own entry has been proposed for deletion as nonnotable (it's been preserved, but at the "stub" level), and so have the Eggcorn and Snowclone entries. For the Eggcorn entry, a small campaign was mounted to demonstrate to the Wikipedia gate-keepers that the eggcorn idea had been cited a number of times in reputable newspapers and magazines. The experience left a bad taste in my mouth.
Baker was obsessed with Wikipedia for some time -- contributing content, editing, righting error, and rescuing threatened entries. He reports (p. 10):
Randall Munroe's xkcd strip (seen here on Language Log a number of times) was deleted and then restored. Here's an xkcd riff on Wikipedia -- entitled "Wikipedian Protester" and captioned "SEMI-PROTECT THE CONSTITUTION":

It's still there. (And see Nicholas Carr's blog entry from 2006 on deletionisn -- "Wikipedia is not a junkyard", it's an encyclopedia -- and inclusionism -- "Wikipedia is not paper", it's a wiki.)
Baker concludes:
[Addendum: I should have realized that a site of this sort already exists: wikidumper, a Wikipedia rejects site started in November 2006. Hat tip to Marnee Klein.]
Language Log presence on Wikipedia: an entry for Language Log itself; non-stub entries for John McWhorter and Geoff Pullum; stub entries for Heidi Harley, Dan Jurafsky, Paul Kay, Mark Liberman, Geoff Nunberg, Barbara Partee, Sally Thomason (with a link to a page of her artwork), Ben Zimmer, and me; so far as I can tell, no entries for the rest (Lila Gleitman and Roger Shuy should certainly be in there).
March 21, 2008
The top and bottom of it
Speaking of the recently discovered incident at the State Department, where someone illicitly accessed Barack Obama's passport file, Secretary of State Dr Condoleeza Rice has apologized, and in addition has stated that she will "stay on top of it and get to the bottom of it."
Now, I am well aware of the tradition of eschewing prescriptivism here at Language Log, where I am privileged to be a Senior Visiting Fellow. But would it be too judgmental of me to point out that Dr Rice cannot get to the bottom of it if she stays on top of it?
I do not seek to question or restrict her powers; this is a matter of antonymy rather than autonomy. Indeed, one might say it is a matter of geometry. There is a fundamental logical problem about staying on the top and getting to the bottom: the bottom is exactly where the top isn't, largely because the middle separates the two.
Take the familiar salutation "Bottoms up!" among drinking companions, for example. When the bottom is up, the top is down. That is just the way it is; that is what bottoms are. And the down position of the top when the bottom is in its up position is precisely what permits the progress of the beer out of the top and down the gullet. "Tops up!" would not have the same effect: the drinkers would just sit there hoisting their glasses and putting them down again. No drinking would be done.
I hope my metaphor is clear. And I hope Dr Rice grasps my point. You may call my insistence on traditional semantics here old-fashioned if you wish, but personally, I have to say that one would hate to think that one was being governed by people who did not know which way was up.
Reading the ampersand comics!
Where did the dog Satchel learn to swear by naming curseword characters (a.k.a. obscenicons)? In today's Get Fuzzy, Satchel explains:

1. Unclaricons. First, from Gavin MacDonald
The first point here is that the use of these punctuation marks as obscenicons is a CONVENTION, however natural it might seem to many people. In other places and at other times, the characters might have no function beyond their conventional uses as punctuation marks (whatever these are in those contexts), or they might have a quite different subsidiary function, as is apparently the case on Japanese television these days.
It's an interesting question when and in what context these conventions for the use of punctuation marks (as obscenicons in writing in English, as "unclaricons" on Japanese television) arose. The history of the non-punctuational obscenicons in comics is also interesting. I know nothing about these topics and probably won't take up researching them -- my plate is already overfull -- but the history of cultural practices is almost always worth investigating.
[A side matter: the choice of punctuation marks that have been pressed into service as obscenicons. Little punctuation marks (the period, comma, apostrophe, single quote, double quote, hyphen, etc.) are presumably unsuitable because they're too puny to convey strong emotion, and delimiters (parens ( ), (square) brackets [ ], (curly) braces { }, angle brackets < >, slash /, backslash \, pipe |) are presumably unsuitable because their delimiting function is so prominent and they otherwise lack meaning. On the other hand, the exclamation point ! and question mark ? are especially SUITABLE because of the meanings they can convey. Plus the asterisk *, because it's used in taboo avoidance and to call attention to material. That leaves @ # $ % & + =. I have at the moment no obscenicon uses of =, but + does occur, as in this rendition (in a discussion of swearing by comic book characters) of "Fuck this shit":
Addendum 3/22/08: Several people have written to point out that $#!+ is surely a recoding of SHIT using punctuation marks to stand for visually similar letters. So + is probably marginal at best as an obscenicon.]
In any case, ! ? * @ # $ % & seem to be the characters most commonly used in the U.S. (I suppose £ and € get some play outside the U.S.) At the moment I have no idea about why = is out of the game.]
MacDonald's note brings up another topic I know almost nothing about, namely the taxonomy of unclarities and incomprehensibilities in language. Ordinary English has the words gobbledygook (variously spelled) and gibberish, each with several (partially overlapping) meanings -- see the Wikipedia entries here and here -- but no word specifically for material that is unclear or incomprehensible on
phonetic grounds (because of mumbling, softness of speech, speed of speech, drunkenness, food in the mouth, etc.), and we have no conventions for representing such material in writing, that is, no unclaricons.
2. Misplaced obscenicon. Then, from Robert Hay, a note about the website firejoemorgan.com, "dedicated to picking apart and ridiculing bad sports journalism", which reported last year on a bizarrely misplaced obscenicon:
I assume they meant to write: "What the #$!&@*?" But they didn't. They wrote "#$!&@* the heck?"
Or, presumably: "Fuck the heck?"
Hay adds that
Delicious.
Wiki rage in Sussex
Tara Brabazon, professor of media studies at the University of Brighton, has written a column about her reactions to the Kindle wireless electronic reading device in the online edition of Times Higher Education. In general she seems to like it, but she does make this remark:
Kindle includes wireless access to Wikipedia. I do not need wireless access to Wikipedia. I would prefer to stir-fry my own small intestines than to have continual access to a site where the entry for Klingon is longer than the entry for Latin.
Now, I don't want to seem insensible to the genre of humorous hyperbole (I believe I might even have used it myself in the past); but let me just enter a mild demurral concerning the use of gross byte count of Wikipedia articles as a means of assessing the encyclopedia's values. [It has been pointed out to me (hat tip: Aaron Davies) that this practice is a recognized sport among whiners; it is called wikigroaning, and it is discussed very entertainingly in this blog post.]
In a literal sense, Professor Brabazon is not wrong on the claim about differential length. I did make some crude efforts to double-check the factual point by hand. There are many problems with measuring the length of Wikipedia entries (because of charts, images, special characters, cultural trivia lists, links, see-also lists, notes, references, etc.), but each time I tried counted non-blank character sequences in the two main articles down to various roughly comparable stopping places, the results did mostly come out with slightly higher word counts for the Klingon language article than for the Latin language article. [Note: this automatic checking site, however, seems to disagree as of March 23rd, 2008.]
The differences are small: gross word counts for the entire articles, including all the Klingon cultural trivia, yield only a 10% difference. Choosing other end points sometimes makes the difference smaller. And of course, the difference starts to go massively the other way when all the related articles on Latin literature and culture are considered. But as things stand, it can truly be said that slightly more has been written on the Klingon language than the Latin language in Wikipedia. (One reason is that Klingon has a separate script that needs some discussion, whereas Latin is written using essentially the same alphabet that English still uses after all these years.)
I just wouldn't want anyone to be tempted to take Professor Brabazon seriously and really look down on Wikipedia just because, at this point in its evolution, the Klingon hobbyists seem to have posted slightly more than the classicists. One point to be made is that excessive length in one article has no implications at all regarding quality of a different article. If Encyclopedia Britannica spends too many pages on a minor topic, you pay for it in actual paper and ink and leather bindings, and there is less space for everything else in the encyclopedia for which you paid your hundreds of dollars. But Encyclopedia Britannica is beginning to look a little bit like the typewriter to a lot of younger people today. Professor Brabazon seems not be quite on board with this new medium in which storage space is essentially free and article lengths are unlimited by media considerations. Long articles on junk topics you don't care about no longer cost you space that could have been devoted to topics you do care about.
More substantively, as the first commenter on the column notes, for scientists Wikipedia is in general remarkably useful, and of astonishingly high factual accuracy. If there has been trouble with destructive battling over biased text, it seems to have been not in science but instead mainly in politics, recent history, and controversial current events.
In fact let me point out right now a factually incorrect statement obviously entered with malice, in a place where you need technical skills in linguistics to spot it. In the article on renegade AIDS researcher Peter Duesberg, when accessed on March 21, a pronunciation was given after Professor Duesberg's surname, in IPA phonetic script. Only the pronunciation shown was not the one for Duesberg; it was the pronunciation of but the one for douche bag. (See why everyone should learn at least the IPA?) That's the sort of minor sabotage you do get on Wikipedia (one can imagine the prank might have been the work of a gay activist who's taken a phonetics class). But even there, the rest of the article seems accurate. [And — underlining the reliability and resilience of Wikipedia rather than its weakness — the insertion was deleted almost immediately. The day after this post went up, that malicious phonetic transcription was gone.]
Stephen Colbert did base a lot of funny material on the idea of a world in which everyone could rewrite the encyclopedia to make it say whatever they wanted it to say (recall the sketch in which he repeatedly altered his own entry). But his entry looks normal and accurate now. Whenever I look up articles on random topics in fields where I have some technical knowledge, in general I am amazed at the quality of Wikipedia. It is constantly revised and improved, and is astonishingly up to date (for example, try looking up the entry for a famous person who died yesterday, and you will probably find that the death has been covered). Adding yet more to the Klingon language entry won't alter its quality, any more than adding to the Latin language entry would reduce Professor Brabazon's rather snobbish hostility to it.
Update, March 22: A case could be made that I am vastly too generous to Professor Brabazon. In fact the case has been made. Jake Troughton writes:
I agree with pretty much everything you said regarding Wikipedia, but I do think it's worth noting that the articles related to the Latin language aren't just "on Latin literature and culture", but on aspects of the language itself. There are separate articles, for instance, on Latin grammar, Latin declension, and Latin conjugation, History of Latin, Latin spelling and pronunciation, and more, which (as near as I can tell) don't have counterparts for Klingon. Thus, I don't think you're quite right when you say, "But as things stand, it can truly be said that slightly more has been written on the Klingon language than the Latin language in Wikipedia." Klingon may have the longer main page, but that's very nearly the extent of Wikipedia's information on the topic, whereas in the case of Latin, there are subpages that go into some detail.
My point, of course, is purely factual. I do not think Wikipedia is made better by an increase of it's Latin-information-to-Klingon-information ratio. If anything, I'd say that it's contributions on the Klingon language are sorely lacking; if you think about, a constructed language that was designed to sound as alien as possible, and that was built to reflect the culture and values of a fictional race of space-faring warriors, yet that some actual Earth-bound human beings apparently still manage to (and choose to) hold mundane conversations in, is a pretty fascinating topic
Eli Bishop has made very similar points. He notes that "Comparing the lengths of Wikipedia articles is even trickier than you suggested. Whenever an article threatens to become unmanageably long, it is almost always broken up into smaller articles, and the main article becomes merely a summary. ... So any measure of just the main article's length is meaningless; certainly it's far from the case that "at this point in [Wikipedia's] evolution, the Klingon hobbyists seem to have posted slightly more than the classicists." It's quite clear that he is right, which makes Professor Brabazon's wiki rage much sillier. As always, I am too generous. It is an oft-noted fault of mine.
March 20, 2008
Spiral thingy lightning bolt!
In the cartoon Get Fuzzy, the dog Satchel has taken to swearing by "saying the cartoon-style swear squiggles" (as the human character Rob puts it).
While we've looked a lot at "taboo avoidance characters", used to mask individual letters in taboo words, we've touched much less often on "cursing characters" (as Ben Zimmer referred to them here; a bit later he referred to them as "obscenicons"), those "cartoon-style swear squiggles" used individually or in clusters -- What the #$*! Do We Know!? -- as visual substitutes for taboo words as wholes. (But see here, here, and here.) Now Satchel has taken things one step further, by using the names of cursing characters in speech (as in a Foxtrot strip Mark Liberman riffed on a few years ago).
Four strips so far, 3/17 through 3/20, beginning with Satchel stubbing his toe on a brick strategically placed in his way by the cat Bucky:




In general, uses of cursing characters can't be uniquely interpreted as particular taboo words, and that's true here, though "ampersand" of "ampersand straight" is surely "damned", damned straight 'absolutely right' being an American idiom of fixed form. ("Dollar sign-A" would be equally interpretable as "fuckin'-A", fuckin'-A being yet another American idiom for 'absolutely right', also of fixed form.) The fact that specific taboo words aren't usually recoverable from cursing characters makes these characters more decorous than the coding of taboo words via avoidance characters; #$*! or "dollar sign" could represent a number of curses, from the mild (hell) to the strong (fuck) -- which ones are available depends on the context -- but f**k leaves almost nothing to the imagination.
Spiral thingy lightning bolt!
Mailbag: non-art as Art-art, and God as singularly plural
Laura Britt Greig sent in an art-historical example of contrastive focus reduplication, from Martha Rosler "Video: Shedding the Utopian Moment", in George Robertson and Jon Bird, eds., The Block Reader in Visual Culture, 1996 (emphasis added):
Cage's mid-1950s version, like Minor White's in photography, was marked by Eastern-derived mysticism; in Cage's case the anti-rational, anti-causative Zen Buddhism, which relied on sudden epiphany to provide instantaneous transcendence; transport from the stubbornly mundane to the sublime. Such an experience could be prepared for through the creation of a sensory ground, to be met with a meditative receptiveness, but could not be translated into symbolic discourse. Cagean tactics relied on avant-garde shock, in always operating counter to received procedures or outside the bounds of a normative closure. Like playing the string of the piano rather than the keys, or concentrating on the tuning before a concert or making a TV set into a musical instrument. As Kaprow complained, this idea was so powerful that soon 'non-art was more Art than Art-art'. Meaning that this supposedly challenging counter-artistic practice, this 'anti-aesthetic', this non-institutionalisable form of 'perceptual consciousness', was quickly and oppressively institutionalised, gobbled up by the ravenous institutions of official art (Art).
Note that expressive capitalization also plays a key role in this case.
 And Paul Farrington-Douglas sent in a striking example of singular they referring to the deity, in a Fox40 News story from 3/17/2008 ("Citrus Heights Man Claims He Saw Virgin Mary in Palm Tree Branch: He Says It's A Message From God").
And Paul Farrington-Douglas sent in a striking example of singular they referring to the deity, in a Fox40 News story from 3/17/2008 ("Citrus Heights Man Claims He Saw Virgin Mary in Palm Tree Branch: He Says It's A Message From God").
Here's the set-up:
"I was going like this and I looked at it and said, Holy... it got me," said Manny Duenas who believes he found the image of the Virgin Mary in a palm tree branch.
"This is her hair, and I see her forehead. I see her neck, her chin is right here."
He was doing yard work last week when he came across it.
Duenas says if you look closely, you can see the Virgin Mary cradling baby Jesus in her arms.
It was just seconds away from becoming yard waste when the homeowner says something stopped him and he noticed what he believes is the image of the Virgin Mary.
"When I'm doing my work I'm just cutting it up putting it in here. But for some reason when I got to the second branch. I don't know if it was looking at me or what. But when I saw it I had the goose bumps. I said, let me share that with the family. I'm getting the goose bumps now." he laughed.
"He was all just like, girls, get out here. Come look at this. I was like, wow. I was speechless. I didn't know what to say," said Manny's daughter Marissa.
And here's the punch line:
Duenas is convinced this is the real deal and not just a coincidence, especially since Easter is coming up.
"God is out there and maybe these are one of the messages that they send," said Manny.
I'm like, wow, too.
Manny's sudden epiphany seems to have transported him beyond the realm of mundane number co-reference in symbolic discourse ("God ... they"; "these ... one of the messages"), while miraculously leaving subject-verb agreement intact ("God is ...", "these are ... ").
I recommend that you watch the video, especially for the paralinguistic aspects of Marissa's testimony. And just for the record, what Mr. Duenas actually said (as opposed to the transcript provided on the web site) is:
God is out there and uh you know maybe these are just one of the- the messages that- that they send, you know?
March 19, 2008
When does stopping start?
Sign on a Stanford campus cafe near my office:
CLOSED
Starting Monday, March 17th
We will Re-open
Monday, March 31th [sic],
8:00 a.m.
I think this one's clear, though I had to think for a moment. But suppose it had said
CLOSE
Monday, March 17th
We will Re-open
Monday, March 31st,
8:00 a.m.
Is that version clear?
The first, actually posted, version says that Olives will be closed on the 17th and for some period thereafter, though for a moment I entertained the possibility that the period of closure would begin at the end of the business day on the 17th (rather than the beginning of the day); this chooses the purely stative (or "false passive") interpretation of "will be closed" ('will be in a closed state'), rather than the true passive interpretation ('someone will close it'), though my moment of indecision was triggered by the possibility that "will be closed" involves the passive of the causative verb close.
For me, an end-of-day closure is the most natural interpretation of the second version, which has the inchoative ('coming into being') verb close. If it's advertised that some store is going out of business and will close on March 17th, the interpretation is that the store will be open on the 17th, but will close at the end of that business day and will not re-open.
(A contribution of context and background knowledge: actually, Olives closed at the end of its business day on Friday the 14th. But it's NEVER open on weekends. So Monday was the first day it was closed when it might have been expected to be open.)
Now, a much clearer version would have been something like
BE CLOSED
Monday, March 17th
Through Friday, March 28th
We will Re-open
Monday, March 31st,
8:00 a.m.
(which is understood with pure-stative "will be closed").
The question of when stopping starts comes up in other contexts. Some years ago I called the circulation department of the Columbus (OH) Dispatch, to stop delivery of the paper while Jacques and I were in California, and, wary of the verb stop, I explained my wishes by saying
which I thought should have been clear enough to a speaker of English. But no. The woman immediately asked me
I explained that I wanted to get a paper on the 15th, but not on the 16th or thereafter. But she merely repeated her question exactly as before. We went back and forth a few more times, concluding with my saying that surely she understood what I wanted, and that she should describe that on the internal forms in whatever way the system required. She was incredibly reluctant to do that; she tried to insist that I actually utter the words
which I wasn't willing to do, because that sentence seemed unclear to me, as a speaker of ordinary English (rather than the English of the forms she was working with), as to when on the 16th delivery of the paper would be ordered stopped. It's the beginning-of-day vs. end-of-day thing.
She started threatening to refuse to take my stop order when I started threatening to speak to her supervisor. We parted inamicably, but the last paper did come on the 15th.
March 18, 2008
Tackling the fleeting expletive
According to (for example) eFluxMedia, the US Supreme Court has said that in September it will hear arguments in the case of the so-called fleeting expletives. This weighty legal subject relates to the dispute between the Federal Communications Commission, which held in 2006 that isolated utterances of the word fuck as an interjection (as heard a couple of time during the Billboard Music Awards show) were "indecent" (who knew?), and a Federal appeals court in New York which ruled 2-1 that this might be unconstitutional. It is good to know that the nine Supreme Court justices will be giving their full attention to this interjection-dropping matter, which is clearly one of the most serious issues facing America. What the fuck would we do without them.
Don't call me doctor or I'll call the police
I never did like being addressed as "Dr." by my students. I figured this feeling must be a result of my working class origins. To me seemed a bit pompous and looked too much like the American Psychological Association's publications that endlessly cite everyone with a PhD as Dr. so and so. So in the early years of my academic career I encouraged my grad students to call me by my first name. This worked fairly well until I got older. But even from the beginning my foreign students just couldn't force themselves to call me Roger.
The title game gets complicated when I testify as an expert witness at a trial. Opposing lawyers call me "Professor" because that gives the impression of an absent-minded, irrelevant dreamer who has nothing useful to tell the jury. The lawyers on my side of the case tend to call me "Doctor," I suppose because that gives the impression of a scientist who knows what he's talking about. "Mister" would suit me just fine, but it doesn't carry the weight of an expert and first names are too infomal for the courtroom setting.
But my problem is nothing compared with that of Ian Thomas Baldwin, who holds a PhD from Cornell, and now serves as researcher at the Max Planck Institute for Chemical Ecology in Jena. The Washington Post reports that he's been accused of "title abuse" by the German police under a little-known Nazi-era law that specifies that only people who hold PhDs or medical degrees from German universities are permitted to be called "Dr." He faces a sentence of one year in prison for calling himself "Dr. Baldwin."
And we think WE have problems.
UPDATE: Mae Sander writes to tell us that persons with a PhD from an accredited US institution can now use Dr. in Germany without jeopardy. As I understand this, however, PhDs from Japan, Canada, and other countries are still banned from calling themselves Doctor. And David Reitter correctly points out that the prosecutors in Dr. Baldwin's case are probably going to drop the charges against him, which I should have indicated in my post. At any rate, I did not intend to give the impression that all German academics support this obviously archaic law. We have lots of archaic laws on our books in the US too, although they often relate to such matters as prohibiting the driving of cattle through city streets or failure to use a spittoon in public.
Taken out of context
Thomas Sowell, the African-American conservative commentator, thinks "Barack Obama has been leading as much of a double life as Eliot Spitzer." Obama has belonged for twenty years to a Chicago church where Jeremiah Wright used to preach. Wright has reportedly stated "that 'God Bless America' should be replaced by 'God damn America'," and has preached sermons containing "wild and even obscene denunciations of American society, including blanket racist attacks on whites." And, says Sowell in The National Review*:
Now that the facts have come out in a number of places, and can no longer be suppressed, many in the media are trying to spin these facts out of existence.
Spin number one is that Jeremiah Wright's words were "taken out of context." Like most people who use this escape hatch, those who say this do not explain what the words mean when taken in context.
In just what context does "God damn America" mean something different?
I know little about Jeremiah Wright or his teachings (I saw him for the first time tonight on BBC TV news for perhaps twenty seconds). But I do know that like Sowell, I have often been annoyed by bald protestations about words, phrases, and sentences having been taken out of context.
*Hat tip: Paul Postal.
Linguists agree that context can have a radical effect on the conveyed meaning of an utterance. But they can provide illustrations and argumentation. I have heard a lot of people who have made incredibly damning statements but think that if they just mouth the talismanic phrase "it was taken out of context", and nothing more, it gives them a sort of get-out-of-disgrace-free card.
In some cases, a context can indeed reverse the conveyed meaning, and render anodyne an apparently damning assertion (for example, suppose the context were that the speaker was performing the opening monologue on Saturday Night Live). But you have to cite the context and do some analysis.
For the most part, "damn America" cannot mean "bless America". And if anyone wants to suggest that nonetheless in a certain context (the very one in which the original utterance occurred) it can, then they do have to answer Sowell's question. He may have written it as a mere rhetorical question, designed never to receive an answer; but it would be perfectly reasonable to ask it in all seriousness, and expect an answer that could be examined in the light of linguistic and philosophical work on pragmatics.
By the way, the above should not be interpreted to mean that I think it is right or proper to try and make political trouble for Obama solely on the grounds that he belongs to Wright's former church. In some of the institutions I have belonged to — clubs, societies, associations, groups, teams, parties, rock bands, committees, companies, universities — I have come in contact with, and worked with, some really disgusting people. Unprincipled bullies, flagrant racists, evil crooks, immoral cheats, eccentric nutballs, corrupt officials, hostile misogynists, fundamentalist crazies, thoughtless twits, callous bigots, ruthless authoritarians, cruel bastards... Don't judge me by them.
Judge me by my actions and my statements — my serious statements, on those occasions when I am not kidding around, telling tall tales for entertainment, or engaging in hyperbolic rants or other humorous conceits to delight Language Log readers.
There are occasions when the context really does change everything. But when pressed I can tell you exactly why and how, and present clear evidence and pragmatic or literary analysis. I don't just say, "Oh, my remarks were taken out of context", as if those magic words would fix it all without further elucidation. Nor can such words fix it for Jeremiah Wright.
Barack Obama is in a different position, though, and Sowell's effort at attacking him through his connection to Wright does not look reasonable to me. Obama didn't say these things. He may at most have sat through plenty of them. Perhaps in a black church in Chicago you have little choice about that: crowd-pleasing overstated rants are a familiar feature of African-American churches, and once the minister starts getting hoarse and the sweat is flying and the congregation is responding, he may get totally carried away.
Obama has now given a speech saying that he firmly disagreed with the controversial political views. It scarcely matters much to me whether he utters such words of disavowal or not. Obama should be judged by what he says for himself on occasions when he understands that he is on the record and will not be taken to be either joking or exaggerating for rhetorical effect.
You can retain my respect without abandoning all association with your church at any episode of rhetorical excess on the part of the minister.
If I left every institution where someone in a prominent position said things I thought were indefensible, I would hardly be a member of anything. Maybe not even Language Log.
More functional neuroanatomy of science journalism
 Some people believe that far-reaching political conspiracies are preventing scientists from discovering and revealing the truth. Ashley Herzog, a journalism major and staff writer at the The (Ohio University) Post, puts this theme front-and-center in her 3/13/2008 article headlined "The Other Side: Despite feminist denial, sexes are wired differently":
Some people believe that far-reaching political conspiracies are preventing scientists from discovering and revealing the truth. Ashley Herzog, a journalism major and staff writer at the The (Ohio University) Post, puts this theme front-and-center in her 3/13/2008 article headlined "The Other Side: Despite feminist denial, sexes are wired differently":
How long before feminists try to censor this? Last week, Science Daily reported on a study from Northwestern University that proved “that girls have superior language abilities than boys ... and gender differences in language appear biological.” Through MRI scans, the researchers discovered that girls’ brains work harder and use more areas during language tasks than boys’ — leading them to conclude that “boys’ and girls’ brains are different.”
This is bad news for feminists, who insist that men and women are really the same (besides the obvious physical distinctions), and that any differences are the products of socialization, “gender roles” and discrimination—and any scientist who suggests otherwise will be punished. We’ll probably never know how great a role biology plays in gender differences, because feminists try to prevent anyone from researching it.
Let me me observe in passing that Ms. Herzog also exhibits the peculiar "brain differences must be innate" idea that I discussed last week in "The functional neuroanatomy of science journalism", 3/12/2008. What got her revved up was a Northwestern University press release reprinted at Science Daily as "Boys' And Girls' Brains Are Different: Gender Differences In Language Appear Biological", 3/5/2008, which starts like this:
Although researchers have long agreed that girls have superior language abilities than boys, until now no one has clearly provided a biological basis that may account for their differences.
For the first time -- and in unambiguous findings -- researchers from Northwestern University and the University of Haifa show both that areas of the brain associated with language work harder in girls than in boys during language tasks, and that boys and girls rely on different parts of the brain when performing these tasks.
"Our findings -- which suggest that language processing is more sensory in boys and more abstract in girls -- could have major implications for teaching children and even provide support for advocates of single sex classrooms," said Douglas D. Burman, research associate in Northwestern's Roxelyn and Richard Pepper Department of Communication Sciences and Disorders.
Braving the feminist hordes, Nikhil Swaminathan at Scientific American also picked up on this press release ("Girl Talk: Are Women Really Better at Language?", 2/5/2008), as did Constance Holden at Science ("He Heard, She Heard", 2/7/2008).
It's true that this story has not yet made as big a splash in the popular press as its authors clearly hoped. On the other hand, neuroscientists are by no means being prevented from researching the biology of sex differences. It's hard to think of any topic that has been getting more study recently, at least among questions without direct pharmacological or clinical applications. And the results often get widespread press coverage, as regular readers of this weblog know. Nor do I know of any cases where scientists have been "punished" for research suggesting that aspects of gender differences are biologically determined -- indeed some well-respected scientists, like Doreen Kimura and Simon Baron-Cohen, have based successful careers on research that argues exactly this.
But in the interests of protecting truth from politics, let's take a look at the paper under discussion in this case. It's Douglas D. Burman, Tali Bitan and James R. Booth, "Sex differences in neural processing of language among children", Neuropsychologia, available online 4 January 2008.
In order to help Ms. Herzog to defeat any antiscientific individuals, feminist or otherwise, who might want to prevent access to this research, I've made a .pdf available here without subscription hindrance. But in fact, after reading the paper, I'm at a loss to see why even the most ardent feminazi in Rush Limbaugh's anxiety closet would want to suppress it.
It's an fMRI study involving 31 girls and 31 boys, ranging from 9 to 15 years in age.
Two language judgment tasks were used. Orthographic judgment (“spelling”) tasks required a subject to judge whether two words presented sequentially shared all letters after the first consonant or consonant cluster. ... In the phonology judgment (“rhyming”) tasks, the subject had to determine whether two sequential words rhymed. ... A visual and an auditory version of each task were presented. ...
In addition, a perceptual control task (24 trials) was used for examining the effect of nonlinguistic sensory processing in each modality. In the visual modality, two visual stimuli were presented sequentially, each consisting of three rearranged letters that bore no resemblance to alphabetic stimuli; in the auditory modality, two triplets of pure tones were presented. The subject indicated whether the second triplet matched the first.
The first thing to observe is that there was no significant sex difference in accuracy on these tasks:
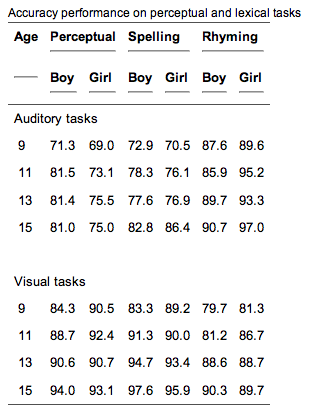
As the authors put it,
Performance on the language tasks performed in the scanner was analyzed with an ANOVA using factors of sex (male, female), age (9, 11, 13, 15 years), and task/modality combinations (auditory rhyming, auditory spelling, visual rhyming, visual spelling). The ANOVA for performance accuracy showed a main effect of age (F[3,155] = 11.264, p < 0.001) and task (F[3,155] = 28.726, p < 0.001). No significant effects on accuracy were observed for sex or its interaction with age or task.
There was a significant difference in reaction time, on the perceptual control tasks as well as the spelling and rhyming tasks: the girls were generally faster, by about 100-200 msec. This was a fairly large effect -- but not one that is consistently found in such studies, as in this table of results from G. Andreou and A. Karapetsas, "Accuracy and Speed of Processing Verbal Stimuli Among Subjects with Low and High Ability in Mathematics", Educational Psychology, 22(5), 2002, where the difference goes in the other direction:
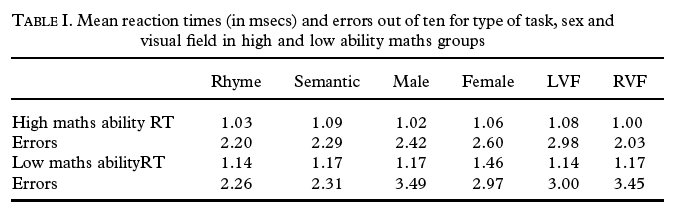
In the Burman et al. study, the fMRI patterns were broadly similar between the sexes, with two particular areas showing greater bilateral activation for the girls in the auditory tasks, and one area showing greater (left-hemisphere) activation for the girls in the visual tasks:
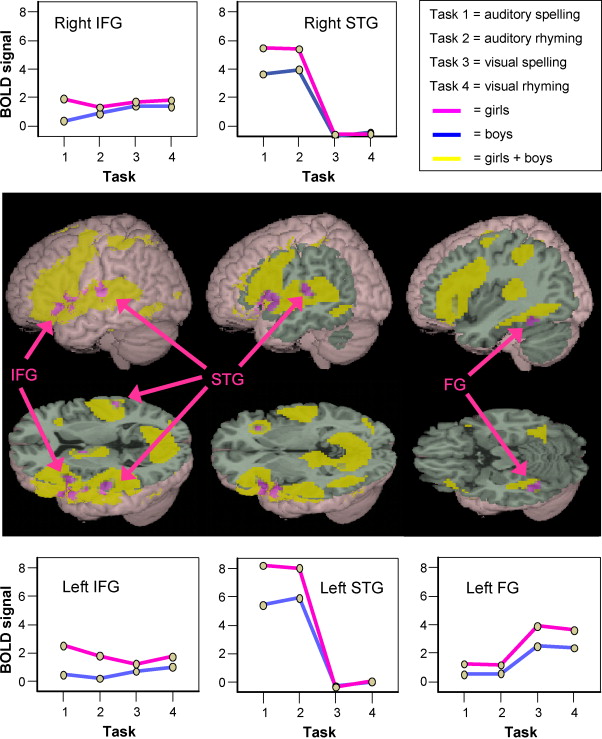
(Unfortunately, there are no standard deviations or other measures of variability from which we could calculate effect sizes.) The authors' description:
Activation across both language judgment tasks and sensory modalities was elicited across all age groups irrespective of sex (yellow in brain images), but girls (pink) showed significantly greater activation than boys (blue) in bilateral regions of IFG and STG as well as left FG. Task, modality, age, and sex were entered into an ANCOVA model with accuracy as a covariate. Graph data were derived from ROI analysis of five regions showing significant sex effects (p < 0.005 with a Bonferroni correction); the BOLD signal represents the estimated partial means derived from the mean activity of each region-of-interest after removing variance attributable to age and accuracy.
Note by the way that
Sex differences were also evident from activation in the perceptual control tasks. Girls showed greater activation than boys in the left occipital and fusiform gyri for visual stimuli, whereas they showed greater activation than boys bilaterally in the superior temporal gyrus for auditory stimuli.
As the authors point out, it's not clear what these differences mean.
Increased brain activation may reflect either greater task difficulty or improved processing and performance. Evidence suggests that increased fusiform and inferior frontal activation by girls is beneficial for performance. [...] Apparently the increased hemodynamic response observed among girls reflects processes relevant to skilled language performance beyond what was required to accurately perform the tasks used here.
In other words, rather than exhibiting (in this experiment) "superior language abilities", the girls' brains appear to be working harder to achieve the same average results (at least in terms of task accuracy -- they did show faster average reaction times).
Of course, increased brain activation might also reflect greater attention to the task, "beyond what was required to accurately perform [it]". Is there any indication that attention might have been an issue in this experiment? Maybe; the authors explain that results from some subjects were excluded
due to excessive movement (>4 mm within a run), poor signal-noise-ratio in primary visual cortex or primary auditory cortex in the complex perceptual condition (more than 2 standard deviations below the mean), or near-chance accuracy on a task (<60%). Functional MRI data from 43 subjects in the auditory rhyming task (19 boys and 24 girls), 42 subjects in the auditory spelling task (17 boys and 25 girls), 54 subjects in the visual rhyming task (26 boys and 28 girls), and 48 subjects in the visual spelling task (25 boys and 23 girls) were used in our analyses.
In other words, out of 31x4 = 124 possible subject-by-task datasets for each sex, 37 of the boys' sessions were excluded, vs. 24 of the girls' sessions. This would be consistent with lower levels of motivation and attention from the boys, resulting in more fidgeting in the magnet, more "near-chance accuracy", etc. -- and perhaps a somewhat lower level of motivation and attention even among those whose data was not thrown out.
For completeness, I should mention that there's a general sex difference in cerebral blood flow, discussed here a couple of years ago ("The vast arctic tundra of the male brain", 9/6/2006), whose nature and interpretation is apparently unclear, and whose relationship to the differences found in this study is certainly not clear to me.
The most interesting part of the Burman et al. study was what happened when they looked for correlations between individual differences in task performance and individual differences in localized fMRI activity. What they found was that these correlations were different, overall, between the boys and the girls. Here's their discussion:
Among boys, brain areas required for accurate performance of a language task depended on the modality of the presented words; accurate responses to visually presented words utilized visual association cortex and posterior parietal regions, whereas accurate response to auditory word forms utilized areas involved in auditory and phonological processing. In boys, correlations with accurate spelling and rhyming judgments were not seen. By contrast, accuracy for rhyming and spelling judgments among girls were each correlated with activation in the left inferior frontal gyrus and the left middle temporal/fusiform gyrus, regardless of stimulus modality. These same areas were also correlated with accuracy during auditory word tasks, perhaps reflecting automatic access of spoken words to the linguistic system (Cobianchi & Giaquinto, 1997; Pulvermuller & Shtyrov, 2006). Among girls, no correlation with accuracy was observed across visual tasks, indicating that accurate performance on visual word tasks involving different linguistic judgments was not limited by visual processes.
[...]
The sensory association areas correlated with accuracy in boys have been implicated in auditory and visuospatial processing, respectively (LaBar, Gitelman, Parrish, & Mesulam, 1999; [Poeppel et al., 2004] and [Simos et al., 2000]). Correlation of performance accuracy with activation in these sensory association areas may reflect the quality of sensory processing before the word is accessed by the language network. If boys do not convert sensory information to language as well as girls, the quality of sensory processing in sensory association areas may act as a bottleneck that limits the accurate representations of words, thereby limiting performance accuracy. Sex differences for the perceptual controls (as well as words) suggests that boys are indeed less effective in sensory processing. If improvement in sensory processing during maturation eliminates the bottleneck in boys, then accurate performance should no longer be limited by (and correlated with) activity in the sensory association cortex, allowing accurate performance to reflect activity in the language network. This may indeed be the case. In a mixed-sex group of adults, accuracy of spelling and rhyming judgments are correlated with activation in linguistic regions of the fusiform and superior temporal gyri, respectively (Booth et al., 2003), suggesting that adult males and females depend on the same specialized language areas. If so, sex differences in linguistic activation during childhood may reflect developmental differences in maturation rate ([Blanton et al., 2004] and [Cohn, 1991]).
This might all be true. But all that Burman et al. tell us is that there was a statistically-significant group difference. Before drawing any very strong conclusions from this research -- for example, that it means something for classroom practice -- I'd like to know more about how big these sex differences in correlations between accuracy and local activation really are, and how the within-group differences compare to the between-group differences.
And I'd like to be more confident that the whole thing is not the result of differences in attention /motivation in the setting of this experiment. For example, if (some of) the boys were not paying attention on some of the trials, then there could be quite a strong correlation between their overall performance and their average level of activation in sensory cortex, and too much noise to see a correlation with activation in cross-modal language areas.
Let's go back to Ms. Herzog's article (she's the Ohio journalism major), which goes on to decry the treatment of Larry Summers, and puts Dr. Louann Brizendine forward as a brave anti-feminist hero:
Predictably, scholars who aren’t intimidated by feminists are ridiculed and ostracized. Last year, Louann Brizendine, a neuropsychiatrist at the University of California San Francisco, published her book The Female Brain, which is based on more than a thousand studies from the fields of genetics, neuroscience and endocrinology. After decades of research, Brizendine concluded that male and female brains are both structurally and hormonally different. As she wrote, “there is no unisex brain…girls arrive already wired as girls, and boys arrive already wired as boys.”
Feminist book reviewers and columnists — who don’t have degrees in neuroscience, just a faith-based belief that socialization accounts for all gender differences — savagely attacked Brizendine and the book, calling it “garbage” and “scary.” Displaying feminists’ typical open-mindedness to scientific facts, one reviewer claimed that “I found my self slamming the book down and walking out of the room in an aggressive and angry mood.”
With this level of censorship, it’s no wonder that scientists are expected to hide research that suggests men and women are innately different. We can rest assured that a book like The Female Brain will never be assigned reading in a college classroom. Meanwhile, sociology and women’s studies textbooks are filled with laughably false assertions about gender. Legitimate scholarship is being sacrificed on the altar of political correctness.
My own impression is that most reviewers were very kind to Dr. Brizendine, and the less they knew about neuroscience, the kinder they were. (Some reviews are discussed in posts linked here.) Rebecca Young and Evan Balaban, whose degrees are in either in neuroscience or in closely related areas, reviewed Brizendine's book in Nature, under the headline "Psychoneuroindoctrinology". It's true that they were not so kind. But rather than slamming the book down and walking out angry, they said that the book "fails to meet even the most basic standards of scientific accuracy and balance", "is riddled with scientific errors", and "is misleading about the processes of brain development, the neuroendocrine system, and the nature of sex differences in general".
It may well be true that "women's studies textbooks are filled with laughably false assertions about gender" -- I've never read any of these textbooks -- but the only example that Ms. Herzog gives is an undocumented anecdote from a work of a rather different kind:
In their book Professing Feminism, women’s studies professors Daphne Patai and Noretta Koertge described a confrontation with a fellow feminist. The feminist was angry over suggestions that women should breast-feed babies, because — in her words — “research shows that men can lactate, too.”
The problem with The Female Brain, at least in the parts of it I've checked, is not that it contravenes feminist orthodoxy. On the contrary, it promotes a set of gender stereotypes that I associate with at least some feminist authors (for instance, that men are competitive while women are cooperative). And just like Ms. Herzog's stereotype of "women's studies textbooks", it was full of strong general statements, often quantitative in nature, that are either unsupported or false -- sometimes, to use Ms. Herzog's term, laughably so. At least one of these false claims -- that men use only a third as many words per day as women -- was withdrawn in later editions, but many others remain, such as the claim that men on average think of sex every 52 seconds, which appears to be wrong by more than 20,000 percent. (For further details, see the posts linked here.)
I'm glad to see a budding journalist who is committed with such passionate intensity to the political independence of science. We scientists are going to need all the support we can get in standing up to political influence as well as cultural orthodoxies of various kinds. But let me appeal to Ms. Herzog, and to journalists at all career stages, to start reading the original sources, not just the press releases, and to apply to arguments from all sources the same informed skepticism that you've learned to apply to politicians that you dislike.
The Lord which was and is
On Palm Sunday evening Barbara and I were in the early 17th-century Greyfriars Church in Edinburgh to hear the Mozart arrangement of Handel's Messiah performed by the Edinburgh Bach Society Choir accompanied by the Sinfonia orchestra. A spectacular performance (with linguist Bob Ladd among the tenors, incidentally). We arrived early (not early enough; the place was packed half an hour before tune-up). We looked around at the fine old church. And syntax, of course, is everywhere: at the altar end behind the choir I noticed these words, carved into the dark woodwork and gilded centuries ago, flanking the cross:
| HOLY, HOLY, HOLY, LORD GOD ALMIGHTY | ✞ | WHICH WAS AND IS AND IS TO COME |
And it seemed to me to provide a very nice illustration of a little-understood fact: the English language has no future tense. Not a trace of one.
Quite clearly, the inscription intends to assert the existence of the Almighty in the past, the present, and the future. If there were a future tense of be, those who chose the wording would have used it. But they couldn't, because there isn't.
Instead of a future tense, English makes use of slew of verbs (auxiliary and non-auxiliary, modal and non-modal) such as be, come, go; may, shall, and will, various adjectives such as about, bound, and certain, and various idiomatic combinations involving infinitival complements. Reference to a variety of future times of different degrees of proximity can thus be achieved, often with some kind of modality (necessity or possibility) mixed in. Among the idioms used in Standard English are all of these:
is to be is to come is to come to be is going to be is going to come is going to come to be is about to be is about to come is about to come to be is bound to be is bound to come is bound to come to be is certain to be is certain to come is certain to come to be may be may come may come to be will be will come will come to be shall be shall come shall come to be
The fact that there is a stubborn tendency in English grammar books to misrepresent will be as the future tense of be doesn't make it right. Traditional grammar is wrong about a whole big ugly bunch of other things too. The arguments that will does not form a tense are briefly summarized in The Cambridge Grammar of the English Language, chapter 3, section 10.1, pp. 208-212, and set out in more detail in an article by Rodney Huddleston ("The case against a future tense in English", Studies in Language 19:399-446, 1995). The arguments include the fact that will expresses volition as well as future temporal location, and that it shows its own tense contrast between present and preterite. In fact every single one of the above constructions can be put into the preterite (simple past) tense as well as the present tense:
was to be was to come was to come to be was going to be was going to come was going to come to be was about to be was about to come was about to come to be was bound to be was bound to come was bound to come to be was certain to be was certain to come was certain to come to be might be might come might come to be would be would come would come to be should be should come should come to be
What happens to the meaning is that the reference point is shifted back into the past, and reference is made to a point subsequent to that, but not necessarily subsequent to now. For example, the past-time-reference counterpart of They say it will be completed by Friday is They said it would be completed by Friday. The latter involves reference to a completion time that is not necessarily in the future relative to now (it could be that they promised completion for last Friday), but it is further on toward the future than the past time reference point to which the past tense of said points.
The claim I'm making is not that reference to future time cannot be made in English; of course it can. And the claim is not that will cannot be thus used: probably over 80 percent of its occurrences involve some kind of future time reference. My claim — Huddleston's claim — is simply that the varied ways we have of referring to future time in English are not part of the tense system; they involve a significant-sized array of idioms and periphrastic work-arounds — and the modal verb will has no particularly privileged place in that array.
If you would like to be convinced that will simply cannot be convincingly analyzed as a future tense marker, consider the examples below. What they show is that will has a wide range of meanings, ranging over volition, inclination, habituation, tendency, inference, and prediction. That is, will X can mean is firmly determined to do X, is inclined toward doing X, has a regular habit of doing X, has tended toward X in the past, can be inferred to be doing X right now, is predicted to do X, and various other shades of meaning.
| Step this way, if you will, sir. | Means "if you wish to", not "if you are definitely going to". |
| Won't you join us? | Means "Don't you wish to join us?" — it's used to issue an invitation, not to request confirmation of a prediction. |
| That will be Mike. | Uttered when the doorbell rings, this means I expect that it is Mike ringing the bell right now (not that it isn't yet but it is going to be). |
| My parents won't know that I'm here yet, so I should call them. | Means that they don't know I'm here, not that a time is coming along in the future at which they will cease to know. |
| Ted and Alice cannot resolve their disputes; they will sometimes fight for hours until they're utterly exhausted. | Means they have a habit of engaging such fights, in the past in particular. (Notice, Ted abd Alice might go into family counseling tomorrow, and the fighting might never happen again. That wouldn't make the statement false.) |
| The reason Warren Buffett has made so much money in his life is that he will not invest in fly-by-night operations. | Means that he has a firm policy of not investing in fly-by-night operations, exemplified by his past practice. The sentence does not suggest that future refusals to invest in fly-by-night operations can explain past financial success! |
| Metallic potassium will explode on contact with water. | Means potassium already does explode on contact with water, and has habitually done so in past experiments — not that it is going to at some future time. |
| I've warned him time and time again, but he won't listen; I'm finished with him. | Means he doesn't listen, as a matter of habitual practice through all the past times I've warned him. (Notice, I'm finished with him: I'm not issuing any more warnings, so my claim is not about what the future is going to be like.) |
| If he was on that plane, he will have spent last night in an airport hotel in Cleveland. | Means that in the world of the assumption that he caught the plane, he has already had his night in Cleveland. The reference is to a possible world that may or may not be the one we're in, but if we are in it, then the night at the airport hotel is already in our past. |
| The folks back home will be missing me right now. | Means that they are missing me right now. It's not claiming that they'll spend Wednesday March 19th missing me on Tuesday March 18th. That's not even coherent. It would involve time travel. |
March 17, 2008
Cavorting and frolicking
In a cartoon I've been saving for several months, Zippy asks the difficult question: cavort or frolic?
What, in fact, is the difference in meaning, if any, between the two verbs? And how do we decide such questions in general?
Eventually, I'll get to this, but in this posting I'll note a sexual sense for both verbs, a sense not yet recognized in the OED (though it's in NOAD2, and probably in other recent dictionaries), and then, we'll be led, once again, to Eliot Spitzer.
The cartoon:

Now to the Spitzer connection. [Sidebar: the NYT Week in Review managed to have an entire survey of the week (always at the top of page 2) devoted to men behaving, or accused of behaving, badly in sexual matters: Eliot Spitzer (New York), Kwame Kilpatrick (Detroit), Reza Zarei (Tehran), Sharpe James (Newark), and Mike Allen (Ohio).] First, it's clear that both cavort and frolic have developed sexual senses. NOAD2:
under frolic: play and move about cheerfully, excitedly, or energetically ... play about with someone in a flirtatious or sexual way
and googling pulls up a fair number of examples from the media (so that I haven't bothered to check how many dictionaries other than NOAD2 have this sense; the OED doesn't yet have it, but it's obviously current). Among these are headlines with sexual frolic:
Call girl who frolicked with Ralph Fiennes lined up for Reality TV ... [from thelondonpaper.com]
and with sexual cavort:
including the appalling
[For those of you who are blessedly out of these things, "Dr. Laura" (Schlessinger) issues, as therapeutic pronouncements, sternly moralizing judgments about human relations. There's a lot that could be said about Dr. Laura's opinions and about the writer's choice to refer to Mrs. Spizer as Silda and to use the blunt whores, but I'm after other things in this posting.]
You can see how the sexual sense of cavort/frolic developed. Our current English vocabulary for talking (especially in print) about incidental sexual relations is unsatisfactory. There are very direct descriptions, using taboo vocabulary or only slightly deflected alternatives:
Then there are remarkably indirect, technical, or euphemistic (or just slangy) alternatives:
Kim had intercourse with Sandy.
Kim did Sandy.
Kim did it with Sandy.
Kim had sex with Sandy.
Kim made love to Sandy.
Kim slept with Sandy.
(and many others).
And of course there are ways of talking about (at least somewhat) more enduring connections, though most of them are unclear about the sexual side of things:
Kim is Sandy's partner/Xfriend.
Kim is Sandy's main squeeze.
and many others -- but all describing a more continuing relationship than the ones we've been trying to allude to.
The question is: how do you report occasional sex in the media? This is where cavort and frolic come in. They convey both activity and pleasure (unlike, for example, sleep with) and, in combination with with + NP they are infrequent enough that context can probably guide you away from more innocent senses, so that
can be taken to convey sexual activity and pleasure. Then, as so often happens, conveyed meaning gets upgraded to conventional meaning, and cavort and frolic develop subsenses with specifically sexual content.
Final note: dictionaries often fail to flag the prepositions selected by (particular senses of) intransitive verbs. Just so with the sexual senses of cavort/frolic, which select with. Examples like
Kim cavorted/frolicked in Sandy's company.
are fine, but don't have the sexual sense. It takes with to do the trick. This fact isn't explicitly noted by NOAD2, though with appears in its examples.
To come: distinguishing cavort and frolic.
Simpsons linguistics jokes redux redux redux
This year's installment of the Simpsons lingstravaganza at Heideas is up, here. Enjoy!
March 16, 2008
Zippy's kid lit
For those of you who are thinking of starting a new career in writing for children, here's a cautionary tale from Little Zippy, plus an example of his style (in stark contrast to the "See Spot run!" approach of Fun With Dick And Jane -- the books, not the 1977 or 2005 movies).

I sent a copy of this one to children's author Lois Lowry (she's the mother of a friend of mine), who replied on 3/6/08, "And not only the narrative cohesion...but the overarching metaphor sucked, too."
What about the writing style? See:

Billy and Eddie are stuck in Dick-and-Jane-Land, where simple vocabulary, banal content, and short sentences rule. Short, awkward sentences; "Watch me ride around" is imaginable, but I find "See my fast car go" unnatural (though grammatical). Zippy, on the other hand, has something to say -- granted, something bizarre, but then that's Zippy -- and has moved past monosyllables (I especially liked the juicy "sauerkraut") and simple imperative sentences. His two sentences even cohere -- sauerkraut and Oscar Mayer wieners link them -- but the metaphor of religious conversion has probably been overused (though maybe not in kid lit), and I'm not sure that the Fifth Dimension reference works ("Up, Up and Away"? "Aquarius/Let the Sunshine In"? "Go Where You Wanna Go"?). Then there's the phallic subtext: too racy for the kiddies?
Rings and circles
A few days ago Mark Liberman pointed out that the OED lacks an entry for the 'crime ring' sense of ring, though he found cites for it back to 1904 (all American), notably for drug ring and prostitution ring, and though the OED does have subentries for related specific (and older) senses of ring (economic rings, in particular price-fixing rings; political rings, like Tammany; and espionage rings). All these uses for associations of people are negative in tone.
The noun circle referring to associations of people is based on the same metaphor -- but this time the connotation is neutral or positive. (The OED's cites go back to 1646, and come from both British and American sources.)
American criminal ring is in the news thanks to Eliot Spitzer's connection to what has been referred to as a "prostitution ring" (sometimes "high-class prostitution ring"); the term in the trade for this form of prostitution is the more demure and much less dramatic "escort agency" or "escort service". There are prostitution rings, drug rings, smuggling rings, racketeering rings, bootlegging rings, blackmail rings, extortion rings, kidnapping rings, robbery rings, murder rings, abortion rings, and so on, including generic crime rings. On screen you can find the 1938 Crime Ring and the 1941 Ellery Queen and the Murder Ring, and probably others.
On the positive side, there's the webring (or web ring). In the words of the Wikipedia, this is "a collection of websites from around the Internet joined together in a circular structure"; OED draft addition February 2004 for web ring, "a number of web sites with related content, offering links to one another in such a way that a person may view each of them in turn rather than repeatedly going back to a single referring site". But that's not an association of people; ring used for collections of people, and with no reference to location in a circle, is heavily negative in tone.
Compare circle. The relevant OED subentry is:
with cites beginning with Sir Thomas Browne in 1646, including references to "a polite circle", "the circle of one's acquaintance", "a wide circle of friends and admirers", "their domestic circle" (the obligatory Jane Austen citation), belonging to "the first circles" (Austen again), "one's immediate circle", "the circles in which he moved", and "political, social, and literary circles". These are all neutral or positive in tone.
The difference in connotation between ring and circle shows up in the Google webhits for combinations of these nouns with preceding crime/criminal (negative) and social (neutral or positive).
| ring |
circle |
|
| crime |
163,000 |
2,120 |
| criminal |
12,400 |
1,190 |
| social |
2,500 |
2,260,000 |
The difference in connotation here looks roughly similar to the difference between gang (negative) and band (neutral or positive): gang of thieves, band of brothers, etc.
News flash: semantics not in linguistics
This morning, NPR's Weekend Edition aired a conversation between Ari Shapiro and Nina Totenberg, "Supreme Court to Hear Second Amendment Case", which included this Q&A:
| Ari Shapiro: | So is this as much a linguistic question as a legal one? |
| Nina Totenberg: | Well, it's partly a linguistic question, and partly a question of what the founding fathers [pause] meant. |
I guess it's possible that Ms. Totenberg meant that it's a historical question rather than a question of the interpretation of an English sentence, either in general or in its original 18th-century context. Or perhaps she believes that linguistics is only about words and phrases, and not about how people use them. But I suspect that she was just brushing the word "linguistic" aside so as to get to what she actually wanted to say.
Some earlier LL posts on related issues:
"Some linguists weigh in on D.C. v. Heller", 1/16/2008
"The right to keep and bear adjuncts", 12/17/2007
"Scalia on the meaning of meaning", 10/29/2005
"Is marriage identical or similar to itself?", 11/2/2005
"A result that no sensible person could have intended", 12/8/2005
"Once is cool, twice is queer", 11/27/2004
[Jonathan Weinberg writes:
I think you had it right (speaking as a constitutional-law teacher) with "it's possible that Ms. Totenberg meant that it's a historical question rather than a question of the interpretation of an English sentence, either in general or in its original 18th-century context." I think Totenberg understood "linguistic question" to refer to the question of what the sentence, and the words in it, mean in the abstract -- and she was answering that one crucial question here is the historical one of what the framers *in fact meant*, even if they may have chosen a way of expressing themselves that accords badly with other things we know about 18th-century English usage. In that analysis, the language they chose is probative of their intent, but not dispositive; we would also want to look, say, at other contemporary understandings about what the drafters had in mind. I'm oversimplifying the question of intent here, and the precise roles of "text" and "intent" (along with other considerations) in constitutional analysis are highly contested, but that there's a difference between the two approaches is something I'd expect to be to at the forefront of Totenberg's thinking.
Well, she went on to discuss two ways of interpreting the language of the amendment:
Did they mean 'a well-regulated militia', so you have to have a gun, and you can either have it at home, or the state can have depots in strategic places to keep the guns; or does it mean, 'look, everybody had a gun at the time of the founding of the republic, and the king tried to take them away at some point, and we need to guarantee an individual right to own a gun,' ...
... etc. As far as the history goes, I don't recall that attempted gun control was one of the complaints lodged against King George (though maybe I've forgetten that episode). Otherwise, her exegesis seems pretty linguistic to me. ]
The terrifying power of language
Arnold reminded us here of how the Piranha Brothers learned to blackmail with conditionals. But my all-time second favorite enucleation of the terrifying power of language comes only later in the same sketch. (Number one, also Monty Python of course, centers on the deadly German joke Wenn ist das Nunstück git und Slotermeyer? Ja! ... Beiherhund das Oder die Flipperwaldt gersput. Number three, beloved by all geeks, linguists, and thus, a fortiori, linguist geeks, is Adams' Babel Fish, "which by effectively removing all barriers to communication between different races and cultures, has caused more and bloodier wars than anything else in the history of creation." But I digress.)
For in the years after the Pirhanas' discovery of blackmail by conditionals, and while Dinsdale perfected new extremes of physical violence, Doug Piranha took a tack that was at once more fearsome, and yet more pragmatic:
| Vercotti | [...] one night Dinsdale walked in with a couple of big lads, one of whom was carrying a tactical nuclear missile. They said I'd bought one of their fruit machines and would I pay for it. |
| Interviewer | How much did they want? |
| Vercotti | Three quarters of a million pounds. Then they went out. |
| Interviewer | Why didn't you call the police? |
| Vercotti | Well I had noticed that the lad with the thermo-nuclear device was the Chief Constable for the area. Anyway a week later they came back, said that the cheque had bounced and that I had to see Doug. |
| Interviewer | Doug? |
| Vercotti | Doug (takes a drink) I was terrified of him. Everyone was terrified of Doug. I've seen grown men pull their own heads off rather than see Doug. Even Dinsdale was frightened of Doug. |
| Interviewer | What did he do? |
| Vercotti | He used sarcasm. He knew all the tricks, dramatic irony, metaphor, bathos, puns, parody, litotes and satire. |
| Presenter | (voice over) By a combination of violence and sarcasm, the Piranha brothers by February 1966 controlled London and the South East. In February, though, Dinsdale made a big mistake. |
So, the brothers' early failed attempt at intimidation "they selected another victim and threatened not to beat him up if he didn't pay them", as discussed by Arnold, prefigured the terrible acts of litotes that followed.
The original scene (enough material for an entire pragmatics course) follows, in two parts. The snippet above is at 2'50s in the second clip.
A tryst too far?
What characteristic is shared by sex outside of marriage, boxing matches, and meetings involving third-world leaders? As of a quarter-century ago, these were apparently the three types of events that writers for the New York Times called "trysts".
How do I know this? I looked it up, and you can too.
Why did I look it up? Like Geoff Pullum ("Tryst", 3/14/2008), I was puzzled that the OED's entry for the word tryst fails to mention the modern sense of "romantic assignation", and I wondered when and how this sense developed. The first place that I looked was the NYT's archive from 1981, and here are the first couple of dozen examples:
In ''The Tryst,'' a married man cannot stay away from his young mistress ...
... Roberto Duran's tryst with Sugar Ray Leonard ...
... Miss Levine turns their moon-haunted tryst into a dialectic of love and justice ...
Odette, the swan queen, is the realization of his swan obsession, and his final tryst with her takes place in a forest.
"You use me like an animal. Come here," says Juli, rather memorably, after one tryst.
... a completely fictional account of a ''tryst'' she and Charles allegedly had late one night on the royal train ...
That is a 10-round tryst with Ken Norton scheduled for Madison Square Garden May 11.
Anny, the family's unhappy daughter, has a midafternoon tryst with the hired man.
Julie was a 23-year-old secretary, Bob was a 44-year-old real estate agent. They had only just met and their tryst was not going according to plan.
Professor Honan speculates that he may have been ''halfrelieved'' by the unconsummated tryst.
... sneaking off to the nearby beach for his 9 o'clock tryst with his beloved Muriel McComber ...
Tarzan and Jane appear ready to enjoy their first tryst when C.J. interrupts their plans.
... he captures the romantic mood of an afternoon tryst in ''On the Lily Pond.''
Ned and Matty embark upon a sexual tryst that might be powerfully erotic were Mr. Kasdan not so concerned with his characters' posing.
... a puling practical nurse (Freda Scott), who watches the bartender fall apart after their brief tryst;
A tryst with Lira sends Bobby escaping the jealous husband by dashing home in nothing but Lira's angora sweater ...
... the senator suddenly shows up with a newly acquired lady friend. Object: tryst. Result: blackmail.
The Sudanese are deeply concerned about Colonel Mengistu's recent tryst with Colonel Qaddafi.
In her rhythmic, A-plus-B-equals-C fashion, the playwright shows us each nocturnal tryst ...
As the movie takes pains to point out, the tryst is a distinctly minor event for them both.
The first and only sexual tryst between Bart and Zack is the only real sex scene in the movie ...
..When Zach's wife goes away for the weekend on a business trip, Zach turns up at the writer's apartment for a prolonged tryst.
Maria has been jilted and so has Paolo, and they are ready to embark upon a long and acrobatic tryst ...
... he arranges a yearly European tryst with another lady ...
... Jeanne has a casual tryst with a stranger ...
... he sees his father in an apparent tryst at a local museum ...
... the clergyman had been surprised in a tryst with another man's wife ...
Searching the (London) Times adds an example of corporate dalliance:
It is a charming, painlessly hip modern animation brought to us by the Pixar tryst with Disney that produced Toy Story, Toy Story 2 and A Bug’s Life.
And a political example worth quoting at length:
I have never thought of John Hutton as a passionate man but yesterday he came to the Commons glowing. Yes, glowing, as he told us of his new amour. He had kept it a secret because, for Labour, this has been a love that dared not speak its name. But now that has changed. The Energy Secretary’s statement was long and detailed but it amounted to this: I (heart) Nuclear.
John spoke, with the deep yearning that befits a Mills and Boon hero, of an idyllic tryst that had taken place only the day before in deepest Suffolk. His new love may have an unconventional name (Sizewell B was popular for only a brief period in the 1980s) but he doesn’t care about such things. “Sizewell B is a phenomenal success story,” he told us dreamily. She was “probably the most successful PWR reactor in the world”.
Like the meeting of Colonels Mengistu and Qaddafi, these are clearly a figurative extension of (what has become) tryst's core "meeting for sex outside of marriage" meaning, which the OED has missed although it dominates usage at the London Times just as it does at the New York Times:
Just like Clinton’s (“I did not have sexual relations with that woman”) after his tryst with Monica.
... that tryst turns Jarry’s second demonstration of theft as performance art into a battle of wits between lovers...
While Viagra patients must take the drug at least an hour before a “tryst”, user-friendly Cialis is taken just once.
A dab of aftershave deals with most post-tryst suspicion ...
... Jettel incurs more jealousy by encouraging another tryst with a local farmer ...
... he did manage to slip in a quick tryst with one of his backing vocalists ...
... what will no doubt become an infamous celluloid sex tryst ...
... the broody supermodel is currently embroiled in a tryst with Guy Laliberte ...
... Pamela Anderson and Liz Hurley (after that unfortunate tryst on Oscar night) are deemed trashy ...
For the reference of those without a subscription, here are the senses in the OED's entry:
1. A mutual appointment, agreement, engagement, covenant. Now rare or Obs. exc. as in 2.
2. spec. An appointment or engagement to meet at a specified time and place. Chiefly in phrases, as to make, set tryst; to hold, keep tryst; to break, crack tryst; to bide tryst, to wait at the appointed place for the person with whom the appointment is made. Also fig.
Only Sc. till 19th c.
3. An appointed meeting or assembly: = RENDEZVOUS 5.
b. An appointed journey. Obs. rare.
4. An appointed place of meeting: = RENDEZVOUS 2.
5. An appointed time
6. An appointed gathering for buying and selling; a market or fair, esp. for cattle. Sc. and north. Eng.
It's easy to find 19th-century examples where tryst simply means "meeting", as in Elizabeth Barrett Browning's 1850 sonnet Mountaineer and Poet:
The simple goatherd between Alp and sky,
Seeing his shadow, in that awful tryst,
Dilated to a giant's on the mist,
Esteems not his own stature larger by
The apparent image, but more patiently
Strikes his staff down beneath his clenching fist,
While the snow-mountains lift their amethyst
And sapphire crowns of splendour, far and nigh,
Into the air around him. Learn from hence
Meek morals, all ye poets that pursue
Your way still onward up to eminence!
Ye are not great because creation drew
Large revelations round your earliest sense,
Nor bright because God's glory shines for you.
I presume that at some point in the past 100 years or so, the sexual-assignation association became a reliable connotation and then a part of the core meaning of this word, to the point where people like Geoff Pullum and me take it for granted. I leave it up to the word scouts at the OED to determine when and how this happened.
But I can't resist observing that the legions defending the English language have not come forward to defend the traditional sexlessness of tryst.
Geoff tried to defend the purity of romantic motive in the assignation sense, but a citation from 1695 in the OED's entry for succubus suggests that this connotation has never been as pure as he would like:
1691 R. KIRK Secret Commw. i. (1815) 13 For the Inconvenience of their Succubi, who tryst with Men, it is abhominable.
And a quick search of Google's news archive for {"Christine Keeler" tryst} suggests that the word tryst was used in the 1960s roughly as it is has been recently in the Spitzer scandal.
[Update 3/17/2008 -- Ray Girvan writes:
A skim (admittedly unsystematic) of the Times Digital Archive of the 1960s finds a few examples of its non-romantic usage:
Dec 02, 1966
Times editorial re Harold Wilson's historic meeting with Ian Smith
"...Mr Smith, leader of a rebel regime, is flying to the tryst under the aegis of the governor..."Jun 16, 1962
Editorial leader
"If Uganda is to keep tryst with the date set for its independence..."Sep 25, 1963
Editorial re indepedence of Kenya
"pressure to keep tryst with December 12 is overwhelming"A number of 20th century examples from the Times, if not explicitly romantic, carry an implication of deep fatefulness and destined encounter close enough to be quasi-sexual: for instance, "India's tryst with destiny" on its independence; the pollarding of a blackthorn to make a walking stick - "Not Just a Stick: A Friend for Life"- described as "a secret tryst"; and Sherlock Holmes' "tryst with Moriarty" at the Reichenbach Falls.
But note that four of these examples involve third-world countries! ]
Tibetanized Roman Letters
While reading about the on-going uprising in Tibet against the Chinese occupation, I came across a number of nice examples of Roman letters styled to resemble Tibetan writing. Here is one:

Update: Several readers have noticed that the "Tibetanized" letters are really "Devanagarized". That is true, but I think that the intention is to make the letters look Tibetan. The visual impression of Devanagari and Tibetan is similar, especially to the eye of people who don't actually know one or the other. If you have fonts for both, here's a comparison. This is the Tibetan word chos "dharma" in Tibetan letters: ཆོས. This is how it looks written in Devanagari: चोस्.
I suspect that the reason is a matter of font availability. Fonts containing Devanagarized roman letters are readily available; one such is Samarkan, which Partha Talukdar suggests is the font used in this example. To my knowledge,Tibetanized Roman letters are not so readily available.
March 15, 2008
Big news from the Arctic Circle
The inimitable Mr. Verb reports on a recent potential breakthrough in historical linguistics: The Na-Dene languages, most of which are/were spoken in northwestern North America, and the Yeniseic languages of Siberia have been demonstrated to be related. Work by Ed Vajda (Western Washington University) on the endangered Siberian language Ket, and work by Jeff Leer, Michael Krauss, and James Kari (University of Alaska, Fairbanks) on Na-Dene languages, including the recently-extinct Eyak, showed enough parallels to satisfy some heavy-hitting historical linguists of their common descent -- and, as Mr. Verb notes, they're a tough bunch to satisfy. According to a Linguist List report by Johanna Nichols, Edward Vajda and James Kari,
The distance from the Yeniseian range to the most distant Athabaskan languages is the greatest overland distance covered by any known language spread not using wheeled transport or sails. Archaeologist Prof. Ben Potter of UAF reviewed the postglacial prehistory of Beringia and speculated that the Na-Dene speakers may descend from some of the earliest colonizers of the Americas, who eventually created the successful and long-lived Northern Archaic tool tradition that dominated interior and northern Alaska almost until historical times.This is definitely big news; I don't know when the last time any proposed connections between major language families was demonstrated, but certainly none have ever been convincingly demonstrated between North American and Asian languages. See some of the original evidence here.
Doing things with conditionals
If X then Y conditionals are remarkably versatile. Just sticking to the ones with present-tense antecedents and future consequents, the neutral use, out of context, is simply to say that X has Y as a consequence, and so to express a prediction that X will lead to Y:
If you put sodium in water, it will react violently.
But making a prediction can be used to convey all sorts of other meanings indirectly. For example, it can serve as a suggestion, a piece of advice --
All of these have conjunctive imperative alternatives. The last two types, however, express consequences that the hearer can be expected to view negatively, and these have alternative imperatives in DISJUNCTIVE form:
Vote for me, or I'll have your house burned down.

There's a lot more that could be said about these conditionals and their coordinate-imperative alternatives, but it's wonderful how much of the system is packaged into the last two panels of the strip.
And now for some Monty Python's Flying Circus, also wrestling with how to issue threats. It comes up in a sketch about the notorious Piranha brothers, Doug and Dinsdale (p. 186 in the first volume of All the Words):
To summarize: in order to extort money from victims, the Piranhas attempted to issue threats. Paring the intended threats down to if ... then form, we get, for the three Operations:
(O2) If you don't pay us, we won't beat you up.
(O3) If you don't pay us, we will beat you up.
(Hat tip to Barbara Partee.)
OK OK vs. really OK
Last year, we featured the illustration of "Contrastive Focus Reduplication in Zits" (6/11/2007): "I am up. I'm not not up-up." Yesterday's strip offers another example of the phenomenon.

Other relevant citations:
"Reduplication reduplication", 6/11/2007.
"Contrastive focus reduplication in the courtroom", 6/11/2007.
[Jonathan Weinberg writes:
Stuff you've figured out already, but which took me longer: If CR means, a la Ghomeshi et al., "a more sharply delimited, more specialized, range . . . the prototypical instance of the reduplicated lexical expression," then often that can be conveyed pretty well by appending "really" to the expression. It wouldn't work to say "Like-them-like-them? Or really like them?" The two mean more or less the same thing. So why not in the Zits strip? Because of ambiguity as to what the prototypical meaning of "OK" is. If the prototypical meaning of "OK" were fine/successful/no problem, then the usage in the strip wouldn't work. The usage in the strip makes sense -- and is funny -- on the understanding that the prototypical meaning of "OK" is adequate-but-not-great, while the meaning of "really OK" is something better.
Exactly.
Charlie Clingen writes:
Somehow reminds me of the joke (?) about computer software product development:
Done: It ran for the first time.
Done-done: Draft documentation available, but, uh, a few features haven't been completed yet.
Done-done-done: dropped on System Test a week before scheduled release date.
]
Posted by Mark Liberman at 06:55 AM
March 14, 2008
Twisting in the rings
Cathy Prasad asks:
What exactly is a prostitution "ring"? Is it like a lion pride or a bird flock? Or does it have something to do with a circle?
Inquiring minds want to know .. ;)
It wouldn't have occurred to me that this usage would seem odd, but on reflection, the modern metaphor would be based on the spatial arrangement of a network rather than a circle.
In the AHD, sense 9 for ring is
An exclusive group of people acting privately or illegally to advance their own interests: a drug ring.
However, just like Cathy, the OED misses this sense. The entry for ring has
10.a. A circle or circular group of persons.
where ring is interpreted literally as a spatial arrangement; and a group of more specific senses, namely
11. a. A combination of interested persons to monopolize and control a particular trade or market for their private advantage. spec. a combination of dealers, contractors, or the like, who cooperate in buying or selling at agreed price-levels, in order to increase their profits. Also attrib. orig. chiefly U.S.
b. An organization which endeavours to control politics or local affairs in its own interest.
c. An organization or network of people engaged in espionage.
The OED does have some relevant example sentences, for example under prostitution:
1975 Times 21 June 2/3 Runaway boys..were procured for a male prostitution ring by offers of food and shelter.
and under under mule:
1989 T. CLANCY Clear & Present Danger xiv. 300 Met a new girl, but she was kidnapped and murdered by a local drug ring—seems she was a mule for them before they met.
But the relevant sense is missed in the ring entry itself. Nevertheless, at least in the U.S., the "crime ring" usage is more than a century old:
"Folsom Drug Ring", AP [in Los Angeles Times], May 23, 1904:
"The summary dismissal and quiet departure of four guards from Folsom prison recently marked the abrupt ending of a drug ring which had been engaged in an extensive business of smuggling opium and morphine through the dead lines to the convicts," says the Chronicle.
"Officials Exonerated", Los Angeles Times, Apr 28, 1931:
The leader of the local radical political element was asserted to have charged in election speeches that a bootleg and prostitution ring was operating about the City Hall and that he had information which would force Orbison and Melcher to resign as soon as it was made public.
[Laura Britt Greig writes:
I think rings, as opposed to networks, imply a closed system. Outsiders are unwelcome.
]
Tryst
I'm not subject to word rage. I'm not a lexical purity nut, really I'm not; but I notice that the New York Times uses the word tryst, three times in one article, for the special times that disgraced ex-New York State Governor Eliot Spitzer set aside for his commercial encounters with young prostitutes in Washington, Florida, and Texas. Could we not reserve tryst for something a little more romantic? A secret arrangement between two lovers to meet for the mutual joy of private time alone together? Surely a necessary condition on trysts should be that both lovers are there for romantic reasons. Renting a hot babe with great hair for sexual services at a thousand bucks an hour (Spitzer goes for the expensive stuff, and has spent an estimated $80,000 on renting young women's bodies over the past year or so) is not trysting. For the call girl it's simply a client appointment. And for the client it is time booked and billed for, like time with a lawyer. The client can charge it to his American Express. Maybe even to his campaign funds (they're now looking into whether Spitzer did that). I don't think it's too puristic to suggest that in the typical tryst the parties have met before, are highly attracted to each other, have become romantically intimate already, and are yearning to see each other again. On the way to a tryst, two hearts should be going pitter-patter with romantic desire and excitement. And at a tryst no thousand bucks changes hands. Am I too far out of line with lexicographical normality here?
Of course, not calling them trysts would mean not being able to call the zealous FBI investigators trystbusters, as James Wimberley points out to me. But we can do without one bad pun, can't we?
[Update: I would like to thank a large number of the roughly 1.1 billion people of India for pointing out to me rather solemnly that my little flippancies above should not be allowed to obscure the fact that an earlier and more neutral sense of tryst, before it picked up the specialized sense of romantic assignation that I think it has now, meant simply "rendezvous", and in that sense it was used in the phrase "a tryst with destiny" in Jawaharlal Nehru's 1947 tryst with destiny speech, one of the most momentous speeches in the history of India, and a landmark of great political oratory.
So, now that my Indian correspondents have insisted that we get all serious lexicographically speaking, Webster says that a tryst is either (1) "an agreement (as between lovers) to meet" or (2) "an appointed meeting or meeting place". The Middle English origin lies in the 14th century word triste, used mainly for an appointed station for hunters (in fact the 27 bus in Edinburgh runs between Silverknowes and a place called Hunter's Tryst in the south). It is probably related to the word trust (the relationship between trysting and trusting being, of course, that normally you set up trysts with people of whom you can trust to be there). The specialization toward meaning (1) that I stress in the opening paragraph above seems to be a more modern development in the use of the word. The OED entry for the word seems, however, to have virtually no sign of the modern development. The OED entry is seriously in need of an update.
Not many people realize that the same is true for most of the entries in the OED. People who cite the OED as support are not just appealing to a settled authority of the last few years; they are often appealing to settled authority of the 19th century. The massive job of doing a true update of that magnificent reference work is really only in its earliest stages, and the total amount of effort needed will be huge. Language Log's own Ben Zimmer, God bless him and keep him, is one of the lexicographers engaged on the task. Our good friend and frequent correspondent Jesse Sheidlower is another.]
Cognitive therapy for word rage
Paul Quirk wrote:
Perhaps just because I have the dispositions of a prescriptivist, the fairly recent hijacking of "around" to mean "about" or "concerning" drives me nuts. This seems to be an academic politics or social activist sort of thing; I don't notice it among business people (although I don't have much contact) or even straight academics. Academics who set up conferences or workshops use it once every minute. The young left-wing political theorists in my department use it.
A bit of correspondence verified that Paul is not upset about the use of around to as a preposition meaning "at approximately", as in "around 3:00", though the OED suggests that this is an Americanism originating in the late 19th century. Rather, he's bothered by cases like these, where around means something like "in connection with the topic of" (emphasis added):
Laura Sinagra, "In Ethical Culture's Venerable Halls, Music Camp in Riot Grrl Tradition", NYT 2005:
At an "image and identity" workshop, a women's studies instructor, Ingrid Dahl, and a drummer and counselor from Portland, Winner Bell, led a discussion around new vocabulary words like "dichotomy," "institutionalization" and "oppression" (setting aside, for the time being, "percussion").
Brown University press release, "Sheldon Whitehouse to Deliver Speech on Global Climate Change", 1/22/2008:
The event is free and open to the public. The speech will serve as a kick-off for the University's involvement in Focus the Nation, a national event organized around the issue of global warming and involving a coalition of more than 1,000 colleges, universities and high schools around the country.
Paul explains:
I think this is an unfortunate development, losing distinct meanings of these words.
I don't have anything interesting to say about it, other than this griping, and don't know if it holds any interest for LL.
Well, we're always interested in documenting new examples of the human urge to express shared annoyance with perceived misuse of language (see e.g. "The social psychology of linguistic naming and shaming", 2/27/2007; "The ecology of peevology", 7/26/2007; "The liturgy of lost causes", 2/18/2008).
And Paul gives one of the commoner justifications for such annoyance, namely that "distinct meanings of these words" are being lost. With respect, though, I suggest that this is probably more of a rationalization than a reason. That is, the annoyance comes first and the reasoning comes second.
In any case, the usage in question seems to be a rather limited extension of the already extensive metaphorical transfer from spatial relations to topical ones. The preposition about made a more complete version of this move during the development of middle English (if not before) -- the OED has
7. a. Abstract connexion: Touching, concerning; in the matter of, in reference or regard to. The regular preposition employed to define the subject-matter of verbal activity, as in to speak, think, ask, dream, hear, know about; to be sorry, pleased, perplexed about; to give orders, instructions, information about; to form plans, have doubts, feel sure about.
1230 Ancren Riwle 344 Hu hire stont abuten vleschliche tentaciuns, {ygh}if heo ham haue{edh}. c1449 PECOCK Repr. I. xix. (Skeat, Specim. 51) Defautis doon aboute ymagis & pilgrimagis ben myche li{ygh}ter & esier to be amendid. 1590 SHAKES. Two Gent. III. i. 2 We haue some secrets to confer about. 1596 —— Merch. V. I. iii. 109 In the Ryalto you haue rated me About my monies and my vsances. 1599 —— (Title) Much Adoe about Nothing. 1611 BIBLE Lev. vi. 5 All that about which hee hath sworne falsly. 1777 HUME Ess. & Treat. I. 193 Shall we be indifferent about what happens? 1854 KINGSLEY Alexandria ii. 50 It is better to know one thing than to know about ten thousand things. 1855 MACAULAY Hist. Eng. IV. 13 Twenty governments, divided by quarrels about precedence, quarrels about territory, quarrels about trade, quarrels about religion.
But we should note that around is not yet available for most of these uses. I bet that not even the young left-wing political theorists in Paul's department are young enough or left enough to speak, think, ask, dream, hear, or know around (things), nor to be sorry, pleased, or perplexed around (things). No edgy young lyricist, as far as I know, is likely to update Sam Cooke's "Don't know much about history" to "Don't know much around history".
Still, it's hard to keep a good metaphor down. For around, Robert Kelly made the connection of ideas to connection in space explicit in a 1975 poem ("The Loom"):
480 ... the table
481 set,
482 Third Surface
483 between the surfaces of our minds
484 where the whole
485 mystery of talk
486 bounds & needs
487 the bounce. The shared
488 preoccupation. I'm no friend
489 of heart-to-hearts; for heart
490 to speak to heart you need
491 a table. A body. A body
492 of work. A trade. A box
493 of swiftian tools.494 The Third
495 is magic---
496 it unlocks the heart.
497 Heart to heart is dumb squish.
498 We need
499 the artifice of order, something
500 to talk around,
501 an obstacle. A stump.
The OED gives a number of equally explicit, if less poetic, examples of transfer from spatial organization to topical organization, for example:
1999 E. NIJENHUIS & O. VAN DER HART in J. Goodwin & R. Attias Splintered Reflections I. iv. 109 Somnambulistic states are..organized around one single fixed idea (monoideism) or around a limited set of related fixed ideas (polyideism).
I hope and trust that Paul is not yet annoyed: it would be hard to talk about ideas if all figurative use of spatial language were forbidden. But at a certain point, such figurative uses start to overlap with one meaning of the preposition about -- whose figurative use in this connection was conventionalized half a millennium ago. From the OED again:
2000 Big Issue 10 Apr. 46/2 With regards to the debate around 'economic migrants' vs 'genuine' asylum seekers..a further aspect of British history should be acknowledged.
As far as I can tell, the extension of around into this conceptual space is still mostly a living metaphor, though perhaps a few lexical frames such as "organized around" and "discussion around" are becoming conventionalized. Here's some evidence.
There are lots of examples of phrases like "organize a conference|workshop around" -- Google finds 241, compared to 1,870 for "organize a conference|workshop about". But no one on the web has yet been moved to ask "What is this conference around?", though 2,770 pages ask "What is this conference about?"
The same is true for the questions "What is this (discussion|article|nonsense|passage|weblog|leaflet|fuss) around?" Amazingly, none of the trillions of web pages out there has thought to organize even one question around this potential meaning of around.
What we find, instead, is a modest number of examples based on the metaphor of organizing or structuring a debate, discussion, conference, workshop, event, etc., around one or more ideas or questions. The verb -- organize or structure or whatever -- may sometimes be implicit, and in these cases we might express a similar idea with about instead of around. Thus "the debate around 'economic migrants' vs 'genuine' asylum seekers" might instead have been "the debate about 'economic migrants' vs 'genuine' asylum seekers".
However, this is not the same as "hijacking 'around' to mean 'about' or 'concerning'". And I don't see that this usage -- granting for purposes of discussion that it has recently become more common -- has created any significant ambiguity, or caused any loss of distinct word meanings.
I'm also not convinced that this usage is an "academic politics or social activist sort of thing".
Thus in a letter to the Financial Times dated Feb. 14, 2008, Mr. Loughlin Hickey, the "Global Head of Tax" for KPMG -- certainly not an academic, and probably not a left-wing activist -- wrote:
Discussion around the Organisation for Economic Co-operation and Development's international report on tax planning last month included frequent expressions of concern on the apparent disengagement of policymakers in many jurisdictions from the practical effects of their decisions.
And on the political right, we can cite Mark Hemingway, "Meet the New Frosts, Same as the Old Frosts", NRO Online, 10/16/2007:
While the debate around the Frost family at least initially centered around their relative wealth, the issue really at hand is one of bad behavior.
Though I don't have any comparative counts, I can say that it's trivial to find dozens of similar examples on various business-oriented and politically-conservative sites. Why might Paul think that the use of around with concepts like discussion or debate is "an academic politics or social activist sort of thing"? Without speculating as to his particular psychodynamics, I can cite a reaction that I've frequently observed in myself, and even more frequently seen in others. The process is nicely illustrated in this recent xkcd cartoon:

Overall, I don't mean to invalidate Paul's belief that people he dislikes are doing something bad to the language that he loves. Rather, I invite him to engage these feelings in a sort of cognitive therapy.
What is really happening to the English language in these cases? Who is really doing it? As a result of looking into these questions carefully, he may find himself less nuts as well as better informed.
[Update -- Ewan Dunbar writes:
Regarding 'around' as 'about' - I wonder if Prof. Quirk would have the same reaction to 'surrounding'? My first impression is that this is restricted to things having to do with incongruence in some sense ("History of the Debate Surrounding the 2004 Presidential Election", "15 Anomalies Surrounding Death of Nick Berg," "Myths and misunderstandings surrounding SOAP") though some of the uses Google turns up ("The Culture Surrounding Google", "A Timeline Surrounding September 11th") don't quite fit. At any rate, I am never surprised by this "surround" and don't get a strong sense of any vivid imagery when I hear it, at least not under the first usage. It's not clear what that means, but it seems to be "conventionalized" in some vague sense. The question test, at least for "debate" and "controversy," fails: the only example of do-support I can find with "controversy/debate surrounding" is "... so did the controversy surrounding it." It also helps me deal with "around" when used in the sense described by Quirk: I don't find it unusual when I can substitute "surrounding", but I do when I can only substitute "about", and I have occasionally heard this latter use.
]
March 13, 2008
Zippy goes nucular
Every so often, Bill Griffith's cartoons play with the pronunciation nucular; check the archives here. Two more:


BBC reads Language Log?
Andrew West mailed me (yeah, I know, I gave strict instructions and threatened a curse, but nobody cares about that), and this is what he said:
I know I'm not meant to email you, and a trillion people have probably already have told you, but someone at the BBC must read Language Log, because the report now reads:
"The adverts juxtaposed pictures of women with quasi-religious text."
Now all you've got to explain is how "quasi-religious" got to "predatory".
Sorry for disturbing you,
Andrew
Well, I put the hex on him anyway — his skin is erupting, his teeth are itching — but that's interesting, isn't it? You don't think they read Language Log at the BBC do you? If they do, it might mess up our plans. We do some regular ridiculing of their science stories here (especially the stories about language and animal communication). They might go and fix them all up or rescind them, and we'll lose a rich and precious vein of humorous literature. Rats.
Zippy snow(clone)
It's been a while since we had a Zippy the Pinhead snowclone strip. Here's one illustrating the Outlaw snowclone ("If X is/are outlawed, only outlaws will have X"). And, as a bonus, a strip on Zippy snow words.


Synchronicity in the funny papers
According to Carl Jung, the fact of "acausal parallelism", in the form of "temporally coincident occurrences of acausal events", provides evidence for the existence and nature of the collective unconscious. That's what I was taught in college, anyhow. That argument never seemed to me to make a particle of sense, but neither did many of the other things I was taught in college.
Anyhow, a couple of days ago, there was an amazing example of synchonicity in the comics. Two nationally-syndicated strips featured (different) bad puns on the same not-especially-common word.
First, there was Frank & Ernest for Tuesday 3/11/2008:

Among the 12 transitive (verbal) senses given for pass in the American Heritage Dictionary, that's "pass the ketchup" in sense 9b. To hand over to someone else: Please pass the bread. vs. sense 5b. To cause or allow to go through a trial, test, or examination successfully: The instructor passed all the candidates.
Then there was Opus for the week starting Sunday 3/9/2008:

Among the 19 intransitive senses for pass in the AHD, that "hope they pass" is simultaneously used in sense 16. To be approved or adopted: The motion to adjourn passed. and in sense 18. To be voided: Luckily the kidney stone passed before she had to be hospitalized.
According to the word frequency lists from Geoffrey Leech, Paul Rayson and Andrew Wilson, Word Frequencies in Written and Spoken English, the verb pass has a frequency of 136 per million in written English, and 212 per million in spoken English. It's ranked as the 110th commonest (lemmatized) verb and the 1,862nd most common (unlemmatized) word overall.
So what're the odds of two nationally-syndicated comic strips featuring puns on this word on the same time? We could set up a sort of birthday-paradox version of the Drake equation for it, based on the estimated probability that a random day's comic strip will be based on a pun (1 in 100?), the number of nationally-syndicated comic strips (100?), and the conditional probability of choosing a particular word given the choice to base a comic strip on a pun (which we could estimate crudely in terms of relative word frequency, here about 150/1,000,000).
Any way you fill it in, it's an amazing coincidence. But what does it have to do with the collective unconscious? I mean, aside from the image in the last panel of FEMA-procured Elysium (complete with supporting cast from QAT International...)
[Note also that this is not the first time that we've had occasion to take note of comic-strip synchronicity: see "The perils of comic-strip lead time", 2/25/2007.]
[OK, two readers have already sent in sketches of theories about puns as quantum entanglement. I wish I could think of something funny to say about this.]
The innateness hypothesis in 1000 AD
Following my report last Friday of finding the standard innateness argument in a 18th-century text by an amateur philologist, I expected my inbox to be overflowing with passages about language acquisition from Aristotle, Descartes and (in contrast) Locke. I had prepared for the onslaught by performing extensive finger-limbering exercises.
Amazingly, the number of people interested in quoting extensively from the work of ancient philologists out there is considerably smaller than the number of rabid Cupertino effect fans, who cannot be beaten off with sticks. Perhaps understandable. But I did get an interesting email from Lameen Souag, of Jabal al-Lughat. An 11th-century Arabic scholar, Ibn Hazm, considered and dismissed the innateness hypothesis before 1064 A.D. As a kind of bonus, in the same passage, he offhandedly alludes to a version of the observation that Saussure laid such stress on: Linguistic signs are arbitrary.
Lameen writes:If you're looking for earlier discussion of the language instinct idea, you could try Ibn Hazm, d. 1064 - coincidentally, he was also the very unorthodox medieval theologian that the Pope rather misleadingly quoted on Islam's notion of the relationship between God and ethics in his Regensburg address. In his book al-Ihkam fi Usul al-Ahkam (Judgement on the Principles of Rulings), Ibn Hazm briefly considers and rejects the idea, essentially saying that language can't be an instinct because if it were surely we would all speak the same language. I'm afraid the translation below is far from perfect - I'm not too accustomed to reading early medieval Arabic - but the idea is pretty clear:Actually, I don't really want to get a ton of philological email, so if you have additional thoughts on this, you could contribute to the comments section on the crosspost of this post at Heideas. If enough accumulate, I'll update with another post on Language Log.ولم يبق إلا أن يقول قائل إن الكلام فعل الطبيعة قال علي وهذا يبطل ببرهان ضروري وهو أن الطبيعة لا تفعل إلا فعلا واحدا لا أفعالا مختلفة وتأليف الكلام فعل اختياري متصرف في وجوه شتى. وقد لجأ بعضهم إلى نوع من الاختلاط وهو أن قال إن الأماكن أوجبت بالطبع على ساكنيها النطق بكل لغة نطقوا بها قال علي وهذا محال ممتنع لأنه لو كانت اللغات على ما توجبه طبائع الأمكنة لما أمكن وجود كل مكان إلا بلغته التي يوجبها طبعه وهذا يرى بالعيان بطلانه لأن كل مكان في الأغلب قد دخلت فيه لغات شتى على قدر تداخل أهل اللغات ومجاورتهم فبطل ما قالوا. وأيضا فليس في طبع المكان أن يوجب تسمية الماء ماء دون أن يسمى باسم آخر مركب من حروف الهجاءElsewhere in the same chapter, he discusses the common origin of Arabic, Aramaic, and Hebrew."There remains only the case of someone suggesting that speech is a natural action. This is falsified by a necessary proof: that nature would do only a single action, not many actions, and putting together speech is a voluntary action, coming in many different forms. Some might take refuge in a kind of combination [of the arguments], saying that different places naturally impose on their inhabitants the language that they speak. This is entirely impossible, because if languages were imposed by the natures of places, then each place would have to have only the language imposed by its nature; but the falsehood of this is plain to the eye, because almost every place has had many languages enter it due to their speakers' involvement and proximity; so this hypothesis is falsified. Also there is nothing in the nature of a place to require that water be called "water" rather than some other combination of letters."
March 12, 2008
Straighter forward
The student's homework said, in an assignment about the derivational suffix -ize in English, that for some adjective bases the meaning of the derivative is "straighter forward", while other cases are more complex. Naturally, my interest was piqued by the comparative, so I asked her about it.
She reported that she had originally typed "more straightforward", but that the grammar checker in the version of Microsoft Word she was using suggested that that was incorrect and that "straighter forward" was what she wanted. "Straighter forward" looked just wrong to her, but who was she, a mere undergraduate, to argue with the linguists at Microsoft?
My own version of Word doesn't object to "more straightforward", "more straight-forward", or "more straight forward". It's cool with "more straight" rather than "straighter". There are a lot of mysteries in the world of grammar checking.
[Added 3/12: Several correspondents have now reported grammar checkers that suggest "straighter forward" for "more straight forward" but not the other variants, so if my student typed "straight forward" -- which the OED recognizes as a variant, though it's clearly a rarely used one nowadays -- that might have triggered "straighter" as a suggested correction.]
Now, the comparative of a three-syllable adjective like straightforward (also spelled straight-forward and straight forward) would unproblematically be the periphrastic "more straightforward". This is so, um, straightforward that dictionaries normally don't list such comparatives; it would just be a waste of space to include them.
If you press things hard, you could imagine an inflectional comparative "straightforwarder" (with spelling variants), and there are a few relevant webhits for this version:
(Many of these hits seem to be from Middle Eastern and South Asian sites.) This version is at least consistent with the etymology of straightforward, which had straight as a modifier of forward, but phonologically it's about as awkward as "beautifuler" 'more beautiful'.
Nevertheless, there are also a few relevant webhits for "straighter forward" as the comparative:
Here it looks like straight has been interpreted as the head of straightforward, with forward as a postmodifier. Or maybe the straight element was picked to take the inflectional comparative suffix -er because it's more of an adjective than forward. Who knows?
So the non-standard inflected comparatives do occur, but in very small numbers. You wouldn't want your grammar checker to take them seriously as models.
Maybe some grammar checkers are dubious about periphrastic comparatives with monosyllabic adjectives. Mine apparently isn't. And querying any sequence of "more" plus a monosyllable that could be an adjective could get you into a fair amount of trouble. You wouldn't want
turned into
Apostrophies
I'll get around to saying more about Barney Oliver's Modern English Misusage (SETI Press, 2001) -- the title pretty much tells you what kind of book it is -- but right now I'm going to reflect on a surprising misspelling in the book. It comes in the section on possessive nouns and pronouns. The background (p. 14):
and then the fall from grace (p. 15):
Before I take up apostrophies, I'll note some other oddities in this passage:
(2) Oliver's apparent assumption that the conventional written representation of English IS English, which would lead him to refer to the s-possessive as "the apostrophal possessive", as if the PUNCTUATION were its most significant aspect. (In the Gurnhill book, such terminology makes sense, since Gurnhill was contrasting spellings of the s-possessive without -- the older variant -- and with an apostrophe.)
(3) The note that "nothing has been elided" in ours and the like. That's an allusion to the idea that possessive s is a reduction of his: "There is some indication that the elided letters [yes, letters] were originally h and i." (p. 14) But there's not much to recommend this idea; the modern s-possessive goes back to the -(e)s genitive case ending of Old English. And in fact something HAS been elided in ours and the like: ours was oures (two syllables) in earlier English.
Oliver was right in thinking that the main use of the apostrophe is to indicate the location of material that in the course of history has been elided (though in pronunciation, with the spelling adjusted to reflect the change in pronunciation), but it has other uses, as in those "unusual plurals" he referred to, and some historical elisions are no longer indicated in the spelling: we no longer spell the once-innovative disyllabic (rather than trisyllabic) pronunciation for the past tense form of the verb BELIEVE as believ'd, for instance. Trying to rationalize the uses of the apostrophe by reference to history doesn't make much sense. Instead, there's just a list of conventions for the standard spelling of English.
But back to the spelling of the plural of apostrophe. That would be apostrophes. Where does apostrophies come from?
Digression: please don't write to accuse me of hypocrisy because I label a spelling as incorrect while "defending" non-standard syntactic and lexical choices. I hope to post soon on the hypocrisy charge in general -- how can you "defend" non-standard usages while using standard variants yourself? -- but in the case of spelling things are a bit crisper. There are advantages to having, for the most part, a single spelling for a word.
Note: "for the most part". There are differences between British and American spellings -- -our vs. -or, -ise vs. -ize, and so on -- and there are other cases where the choice between alternatives seems to me to be of no consequence: o.k., O.K., OK, etc. In fact, though I advocate a reasonable adherence to standard spellings and deprecate non-standard spellings that would give almost any reader pause, I'm not ENRAGED by non-standard spellings that can't be misunderstood by a well-intentioned reader. Rage is not an appropriate response. Nor is writing off the errant speller as a total idiot.
So, in fact, I'm not at all enraged by apostrophies. It's incorrect, but who could misunderstand it? I bring it up only because it occurs in a book that aims to root out evil in English usage.
I'm a student of, among other things, errors/mistakes in language (of all kinds, and there are many kinds), which involves trying to figure out why people say/write the things they do. In general, errors/mistakes aren't just random appearances in the production of language; there are explanations for why people "get things wrong".
So: where did apostrophies come from in Oliver's text (whether written by him or introduced by an editor)?
First observation: the text has apostrophe as the singular throughout. What's notable is the juxtaposition of apostrophe and apostrophies. As it turns out, you can google up a fair number of instances of apostrophies (most of them in contexts involving computers). In a lot of these cases, it's singular apostrophe vs. plural apostrophies, as on this site with grammar advice:
By Brian Kerrigan
THE PROBLEM: Knowing whether to put the apostrophe before or after the 's whether it is a noun or a pronoun.
... SOME RULES TO HELP YOU WITH APOSTROPHIES:
This page uses apostrophe throughout, but apostrophes only in a quote from the Bedford Handbook. Some other sites have both apostrophes and apostrophies.
And in some cases it's singular apostrophy vs. plural apostrophies, as in this query (reproduced here verbatim) on another advice site:
Ok, this has been bugging me long enough. In the sentence " I drove my car to joes house. " where exactly in the word joes does the apostrophy go? Every time I see a word like that the apostrophy is before the S no matter what context they are using the word. Last I knew, the apostrophy was there to take the place of a letter. So instead of joe is, one would write Joe's. But if I wanted to use my example setence, wouldn't the apostrophy go after the S?
Aha! Now, THAT would make some sense. To see where singular apostrophy might come from, think about how compound words are borrowed from Greek. There are (at least) three classes:
(II) catastrophe, hyperbole, apocope, calliope, ...
(III) homonymy, democracy, apostasy, monarchy, ...
Words in class I end in a consonant sound (with a "silent E" in the spelling), while those in classes II and III end with /i/, spelled as E in (II), as Y in (III). This is remarkably difficult.
Please don't write to tell me that IF YOU ONLY KNEW THE HISTORY, you would be able to spell these words. That's an outrageous idea: learning the history -- what the Greek originals were, which words came to English directly from Greek, which came from Greek via Latin, which came to us through French and when, which ones were re-shaped in the process and in what ways, etc. -- is a much harder task than simply memorizing the spellings. The division of words into classes I-III in current English is just arbitrary, and this arbitrariness is what learners of the spelling system are confronted with. To expect them to refer to the details of hundreds of years of complex linguistic history is ridiculous.
How, then, do you spell final /i/ in Greek-y compounds? The weight of the evidence seems to lean towards Y, so you'd expect apostrophy. For which the plural would be apostrophies, using the default rules for English spelling. There you are.
Then the spelling apostrophies gets transferred into other settings, even when the writer uses apostrophe as the singular. Well, the pronunciation of apostrophies is straightforward, while to pronounce apostrophes correctly, you need to analyze it as containing apostrophe as a part. Maybe some people think apostrophes looks funny. Certainly, I found the past participle apostrophed funny-looking when I first encountered it, in a Chicago Tribune piece (2/24/08) by "Sean ODriscoll", "You might say it's the curse of the apostrophed", about the problems that can beset people with apostrophes (or hyphens, or spaces) in their family names. (You can google up other examples of apostrophed.)
But so far as I can see, neither apostrophies nor apostrophy makes it into any of the standard dictionaries.
In any case, apostrophies is wrong, but it's not crazy, or random. Nevertheless, it's entertaining that a book that rants against error in English can't quite get this spelling right.
Hair care blasphemy and predatory text
 It must have just swept the execs off their feet when the Jemella ad
agency suggested it: a series of advertisements would feature young
and attractive women — hot babes with great hair — in
poses suggesting prayer, with ecstatic expressions on their faces, and text
of a religious-sounding nature, advertising ghd IV hair
styling equipment. Like, we'll have a woman kneeling in prayer
— a hot babe, in her lingerie — and she'll be saying "May my
new curls make her feel choked with jealousy"! Or a woman with a votive
candle praying "Make him dump her tonight and come home with me"!
And we'll have phrases like "A new religion for hair" on the screen;
and "Thy will be done", with the "T" of the first word shaped like a
crucifix! It'll be so great! You can imagine the suits in the boardroom
thrilling to the idea of this confluence of erotic and religious imagery
combining to sell product. And they bought it.
Only Jemella had misjudged it: the Archdeacon
of Liverpool and many others complained to the UK's Advertising Standards
Authority (ASA), and the ads have been deemed "likely to cause serious
offence, particularly to Christians." You've seen the Danish cartoonist versus
Islam; now, just when you thought it was safe to go outside again, it's
hair care product ads versus the ASA and the
Archdeacon of Liverpool!
It must have just swept the execs off their feet when the Jemella ad
agency suggested it: a series of advertisements would feature young
and attractive women — hot babes with great hair — in
poses suggesting prayer, with ecstatic expressions on their faces, and text
of a religious-sounding nature, advertising ghd IV hair
styling equipment. Like, we'll have a woman kneeling in prayer
— a hot babe, in her lingerie — and she'll be saying "May my
new curls make her feel choked with jealousy"! Or a woman with a votive
candle praying "Make him dump her tonight and come home with me"!
And we'll have phrases like "A new religion for hair" on the screen;
and "Thy will be done", with the "T" of the first word shaped like a
crucifix! It'll be so great! You can imagine the suits in the boardroom
thrilling to the idea of this confluence of erotic and religious imagery
combining to sell product. And they bought it.
Only Jemella had misjudged it: the Archdeacon
of Liverpool and many others complained to the UK's Advertising Standards
Authority (ASA), and the ads have been deemed "likely to cause serious
offence, particularly to Christians." You've seen the Danish cartoonist versus
Islam; now, just when you thought it was safe to go outside again, it's
hair care product ads versus the ASA and the
Archdeacon of Liverpool!
Andrew West has pointed out to me that in the BBC News report about this, we read:
The advert juxtaposed the words 'thy will be done' alongside erotic images of women accompanied by predatory text.
But, he asks, what the hell is "predatory text"? We've heard of predatory animals and predatory behavior. But predatory text seems semantically anomalous. Could it be a Cupertinoesque spelling-correction error? From what? Could it be a fanciful metonymic usage? Could it be a malapropism? I don't know what they mean. Andrew notes that it does not come from the original ASA adjudication. At the time of first posting this, I was at a loss for a hypothesis. Yet within minutes...
Yes, within minutes of my first posting the above, a chemist at the Office of Pollution Prevention and Toxics of the US Environmental Protection Agency, whom I will not name because he may have emailed me on government time, sent a suggestion which is extremely plausible. I wonder if you can guess what the word was that the spelling checker incorrected, or the typist mistyped? It is beautiful. Absolutely perfect. Don't underestimate government chemists.
Don't mail me about it. I have enough mail. Just think, and check back. In the fullness of time — in a day or so — I will reveal all, right here on Language Log.
Update: All right, so you will not obey me, you lawless rabble. Many of you have mailed me. And do you know who the first person was who mailed me after I posted the above very clear instruction "Don't mail me about it"? It was Mark Liberman. Yes, the freakin' CEO of the Language Log Inc. That's how close I am to being able to get people to pay attention to my commands: even my colleague at One Language Log Plaza, the chief executive of our multinational language edutainment corporation, won't toe the line.
I suppose I have to tell you what Mark mailed to say. But first, so you don't pester me, I'll tell you the word that the anonymous government environmental toxicological chemist thinks might have been intended: the word he suggested was precatory. It means "expressive of a wish", and it comes from the Latin verb meaning "pray". That is a beautiful, beautiful hypothesis. The letters c and d are adjacent on the keyboard as well as in the alphabet, and precatory, with only 53,400 raw Google hits, is vastly rarer than predatory, which gets roughly 4.9 million (two orders of magnitude more).
Now to Mark. What he mailed to me (against my express instructions, but who the hell listens to me) was the point that women are described as predatory when they seek to attract the male companions of other women, and text that suggested such predatory behavior might be called predatory text, in the context at hand.
And while I was typing this, Norman Macleod mailed me (the flow is unstoppable) to say he thought perhaps it could have been prefatory that was meant (notice that d and f are neighbours on the QWERTY keyboard). Though it's semantically less plausible.
So we have three competing hypotheses on the table. One says it was an incorrection from precatory; another says it was an incorrection from prefatory; and the third says it's a metonymic use of predatory and not an error at all.
So here's what I want you to do: Don't mail me about it. I'm serious. I get too much email. Although I never put my email address in a Language Log post, people look me up (I'm a professor in a public institution of great renown, I can be easily found) and get my address and mail me anyway, all the time. But I've had it with this one: if you email me about this, I will put a curse on you. Your skin will break out in boils; your teeth will itch where you can't reach to scratch them; your car will develop an annoying whiny rattle that will stop whenever a mechanic listens; your bananas will go directly from green to black without passing through yellow; your country music albums will play backwards so that your dog comes back to life... I'm warning you, bad shit will happen all over in your life. Don't test me.
If you want to complain about this new and admittedly harsh policy of mine, feel free to send your whiny, snivelling messages to complaints@languagelog.com, where we have rigged up a program that runs 24 hours a day to send out blandly polite responses and delete the incoming message. Just like what the White House runs.
Look, we don't know whether the (anonymous) BBC website writer meant predatory or precatory or prefatory. We'll never know. I don't even want to know. I have no idea why I started this thread.
It's late in the evening here in the Edinburgh office, OK? I'm going to bed. And if I find in the morning that any of you (unless of course you're the anonymous BBC website writer) have emailed me with your crazy-ass, off-the-wall, seat-of-the-pants, cockamamie, addle-brained theories about this question, I am going to be so mad that the cork and the bubble-truck will tumble from the mountaintop as far as I'm concerned; I'll light up every tuba tent and walleyed river king from 44 to the roller coaster. So don't provoke me. THE END.
The functional neuroanatomy of science journalism
Michael White has an interesting post at Adaptive Complexity on "Bad Science Journalism and the Myth of the Oppressed Underdog":
There is a particular narrative about science that science journalists love to write about, and Americans love to hear. I call it the 'oppressed underdog' narrative, and it would be great except for the fact that it's usually wrong.
The narrative goes like this:
1. The famous, brilliant scientist So-and-so hypothesized that X was true.
2. X, forever after, became dogma among scientists, simply by virtue of the brilliance and fame of Dr. So-and-so.
3. This dogmatic assent continues unchallenged until an intrepid, underdog scientist comes forward with a dramatic new theory, completely overturning X, in spite of sustained, hostile opposition by the dogmatic scientific establishment.
I agree that this is a great story line, and one that is probably used in situations where it's false more often than in situations where it's true. But the implication that it's a commonly-used narrative is, I think, an example of the frequency illusion.
Unfortunately, there's no search engine that indexes news stories by rhetorical pattern, so it's not easy to compare the relative frequency of such patterns. Thus I have no better evidence for the frequency of my own candidate for Most Pernicious Science Narrative of the Decade:
1. Consider the hypothesis that <Stereotypical-Observation-X-About-People>.
2. Brain Researcher Y used fMRI to show that (some experimental proxy for) X is (somewhat) true. Now we know!
3a. Optional bonus #1: Now we know why! It happens (somewhere) in the brain!
3b: Optional bonus #2: This shows that X is hard-wired and biological, not all soft and socially constructed.
There was a great example of this narrative in the New York Times a few days ago: Tara Parker-Pope, "Maternal Instinct Is Wired Into the Brain", 3/7/2008:
A mother's impulse to love and protect her child appears to be hard-wired into her brain, a new imaging study shows.
Tokyo researchers used functional magnetic resonance imaging (M.R.I.) to study the brain patterns of 13 mothers, each of whom had an infant about 16 months old.
First, the scientists videotaped the babies smiling at their mothers during playtime. Then the women left the room, and the infants were videotaped crying and reaching for their mothers to come back. All of the babies were dressed in the same blue shirt for the video shoot.
M.R.I. scans were taken as each mother watched videos of the babies, including her own, with the sound off. When a woman saw images of her own child smiling or upset, her brain patterns were markedly different than when she watched the other children. There was a particularly pronounced change in brain activity when a mother was shown images of her child in distress.
So let's recap this.
1. Mothers react differently to videos of happy 16-month-olds and crying 16-month-olds.
2. Mother react more strongly to videos of their own 16-month-olds in distress than to videos of other infants in distress.
And guess where in their bodies these differences can be found? In their brains! (Among other places, anyhow.)
It's rhetorically interesting that Ms. Parker-Pope takes the existence of brain differences observed by fMRI as evidence that the reactions in question are "hard-wired", i.e. innate. No doubt the ability to recognize one's children and the impulse to empathize with them have a substantial evolved biological substrate. But the fact that the psychological states in question are distinguishable in fMRI scans tells us nothing whatsoever about the balance between Nature and Nurture, in this case or in any other.
This curious mistake is by no means original to Ms. Parker-Pope. Thus I observed a couple of years ago ("David Brooks, Cognitive Neuroscientist", 6/12/2006) that
[David Brooks] writes as if demonstrated group differences in brain activity, being "biological", must therefore be innate and essential characteristics of the groups, and not "socially constructed". But how else would socially constructed cognitive differences manifest themselves? In flows of pure spiritual energy, with no effect on neuronal activity, cerebral blood flow, and functional brain imaging techniques?
I guess that it's the bizarre inference from observation in fMRI scans to innateness that makes this story at all newsworthy. If the existence of maternal love been established simply by asking the mothers how they felt ("On a scale from 1 to 7, where ..., how does this video make you feel?"), no one would have published the study or written about it in the newspaper. And other (essentially equivalent) dependent variables would also probably not have rated any notice: judgments of mothers' facial expressions, or other physiological variables such as those that are used in polygraph examinations.
Of course, it's not just the journalists who say silly things about such studies, at least in the popular press:
"This type of knowledge provides the beginnings of a scientific understanding of human maternal behavior," said Dr. John H. Krystal, editor of Biological Psychiatry, which published the study last month. "This knowledge could be helpful some day in developing treatments for the many problems and diseases that may adversely affect the mother-infant relationship."
In fairness to Dr Krystal and the editorial standards of Biological Psychiatry, I thought that I should take a look at the original paper, to see whether it has any real scientific content beyond the "discovery" that mothers recognize their infants, and find their infants' distress distressing, and exhibit measurable differences in brain activity that correspond to these differences in psychological state.
The paper seems to be Madoka Noriuchi et al., "The Functional Neuroanatomy of Maternal Love: Mother's Response to Infant's Attachment Behaviors", Biological Psychiatry, [available online 7 August 2007].
There is indeed some additional information, beyond the fact that the mothers' brains responded variously to the various videos:
We found that a limited number of the mother's brain areas were specifically involved in recognition of the mother's own infant, namely orbitofrontal cortex (OFC), periaqueductal gray, anterior insula, and dorsal and ventrolateral parts of putamen. Additionally, we found the strong and specific mother's brain response for the mother's own infant's distress. The differential neural activation pattern was found in the dorsal region of OFC, caudate nucleus, right inferior frontal gyrus, dorsomedial prefrontal cortex (PFC), anterior cingulate, posterior cingulate, thalamus, substantia nigra, posterior superior temporal sulcus, and PFC.
These results are not without value, I guess, though they are not very specific, and also not in general very surprising.
The researchers did in fact ask the mothers how they felt:
After the fMRI scan, the mother was asked to rate her feelings while viewing sample video clips. The sample video clips consisted of 10 video clips (the mother's own infant and four other infants in each situation), which were selected from the stimuli that had been presented to the mother while in the fMRI scanner. The mother was asked to rate each of 11 descriptors, i.e., happy, motherly, joyful, warm, love, calm, excited, anxious, irritated, worry, and pity, on a five-point scale (−2 = not at all, 0 = neutral, 2 = extremely) while watching each video clip.
These results were not surprising either:
The intensities of the mothers' feelings while viewing their own infant in each situation decreased as follows: happy, motherly, love, joyful, warm, calm > excited > anxious, irritated, worry, and pity in PS [Play Situation]; motherly, love > happy, joyful, warm, calm, and irritated in SS [Separation Situation].
Nor is it surprising that Ms. Parker-Pope saw no reason to mention this aspect of the study.
[Note that the rhetorical pattern discussed in this post is a specific example of the general mind-fogging effect of brain-talk, as demonstrated by Deena Skolnick Weisberg ("Distracted by the brain", 6/6/2007).
Note also that some research results of this type are taken to establish the truth of things that are obviously true prior to investigation (in this case, that most mothers can recognize their own infants, and react especially strongly to seeing them in distress), but the same rhetorical technique is sometimes used to establish the "truth" of things that are probably false, e.g. that "men are emotional children".]
[James Russell asks:
"We found that a limited number of the mother's brain areas were
specifically involved in recognition of the mother's own infant,
namely orbitofrontal cortex (OFC), periaqueductal gray, anterior
insula, and dorsal and ventrolateral parts of putamen ... dorsal
region of OFC, caudate nucleus, right inferior frontal gyrus,
dorsomedial prefrontal cortex (PFC), anterior cingulate, posterior
cingulate, thalamus, substantia nigra, posterior superior temporal
sulcus, and PFC."But does it involve the crockus?
Inquiring minds like mine want to know.
No, alas, because this is Neuroscience research, which is not nearly as entertaining as Early Childhood Education research.]
March 11, 2008
Repenting in Public
Linguists get their data from many places, as any Language Log reader knows, but the daily news is always a fertile source. We've dealt with science reporting, warning labels, apologies, and simple news stories, to name only a few. But I don't recall seeing much about the speech event of repentance on this site. Goodness knows we've had lots of examples, especially from fallen evangelists and religious leaders who got into considerable ethical trouble.
Today's Washington Post and New York Times accounts of Governor Eliot Spitzer's orchestrated appearance before cameras is an immediate example. The Post called it a "ritual of repentance." We'll see. Spitzer appears to follow a formula that looks like what linguists call a speech event--in this case a repentance speech event, except he doesn't quite get to the repentance part.
Dell Hymes orginally named these language phenomena "communication events," but this designation has been more or less replaced these days by "speech events, " which are structured activities that reflect the way people belong to or are involved in the social life of a specific community. In Spitzer's case, the specific community seems to be public officials who are caught (or appear to be caught) in acts for which, well, repenting is a good thing to do.
So what is the structure of the speech act of repentance? There appear to be six phases:
1. Carefully choose the best place to do it. Pick your own office, if possible, never on the street. Make it appear that you are still in control, no matter what happens later. Have an American flag behind you. Speak from a lectern. Wear a red tie. Control.
2. Have your family, especially your wife, standing next to you. Begin with, "I want to briefly address a private matter." "Briefly" downplays the importance of what you did. "Address" makes it formal and powerful. "Private matter" says it's really nobody's business but your own.
3. Admit wrong-doing in a general way. Don't be specific because the fact has already come out and it doesn't need to be repeated endlessly, especially by you.
4. Frame an apology without specifics. Stress your family. Say you've "disappointed," but not "disgraced" or "acted illegally." Spitzer's went like this:
5. Say that you have learned your lesson and you will never do this again (this part of the repentance speech event seems to be missing from Spitzer's appearance). But you don't want to be premature either (keep Senator Larry Craig in mind).
6. Take no questions. No need to be embarrassed further. You've done your job. You've apologized (well, sort of anyway), so leave it at that.
Constituent order, interview etiquette, and being a monster
Barack Obama's presidential campaign suffered a major embarrassment just before last weekend, and it started right here in Edinburgh, when Gerri Peev of The Scotsman newspaper got an interview with Samantha Power, the 37-year-old Irish-born writer who walked away from a teaching job at Harvard to become an unpaid campaign adviser to Obama. Interviewing her in London, Peev asked about the primary result in Ohio, and Power blurted out:
"We fucked up in Ohio. In Ohio, they are obsessed and Hillary is going to town on it, because she knows Ohio's the only place they can win. She is a monster, too — that is off the record; she is stooping to anything."
What would you have done with that sentence if you were an ambitious Gerri Peev and you had caught it on your recorder, with that afterthought "that is off the record" dropped in the middle there?
What The Scotsman decided to do was to print it, and in fact headline it. The request for off-the-record status was ignored, and the remark was directly attributed (with the quotation tag line "Ms Power said, hastily trying to withdraw her remark").
Michelle Tsai, in a Slate magazine article about verbal practices in going off the record, said:
Power would have been on less-shaky ground had she switched the order of her words and said, "This is off the record — she is a monster, too," instead of, "She is a monster, too — that is off the record."
I think Tsai is right, except that it's constituent structure as well as word order. Here the syntactic structure really matters. There is a key difference between The following is off the record: Hillary is a monster on the one hand and Hillary is a monster; that is off the record on the other. The following somewhat clearer contrast is of the same sort:
- Hillary is a monster — that's what people are saying.
- People are saying that Hillary is a monster.
In the first of these, the utterer could reasonably be claimed to have actually said that Hillary is a monster. The part after the dash comes across as a sort of excuse or citation of support for the remark. In the second, it would not be reasonable to make that claim: what is being said is clearly about people, and about what they are saying. The difference is what's in the main clause (or the more subtle semantic matter of what is foregrounded in the sense of being the most salient proposition conveyed), not simply of what comes first.
Even with a form like "This is off the record — she is a monster", one would be taking an insane gamble. I would have thought everyone knew that requests to go off the record have to be announced and agreed to up front. It was a prominent turning point of the plot in the film All the President's Men. Ask first if you can be guaranteed off-the-record status. If the answer is a firm yes, and you trust the reporter, then spill the beans. But say nothing unquotable until you get the reporter's OK. It should be more like this:
Power: I need this next bit to be off the record. I'm giving it to you for your private information: it will help you to put things in context but it's not for print. I need your promise and your editor's promise that you won't quote me in the story, or elsewhere, OK? Otherwise this interview is over. 'Cause if you use it they will fire my ass quicker than greased lightning. Do you understand that, Gerri?
Peev: Umm... Couldn't I just say, "An adviser told me privately..."?
Power: No! What are those ugly pink things on the sides of your head, ears or what? Listen to me! You promise not to use it, or I don't tell you, OK?
Peev: Oh, all right, spoilsport. Just tell me so I get the general picture. I promise I won't quote it. I'll go to jail rather than tell on you.
Power: OK. So don't tell ANYone I said this, but Hillary is a freakin' monster. She'll stoop to anything. It's like running a campaign against an alligator that won't release its tax returns.
That's what it should have been like. Schoolgirls gossiping in a playground know how to swear people to secrecy. The rules for journalists are basically the same, except that schoolgirls are not quite so nasty and ruthless. I certainly don't approve of what Gerri Peev or The Scotsman did: I think the reporter was a snake and the paper acted like a cheap scandal sheet. (I know, some people are saying it was in the public interest to have this known because we should be made aware that Obama has some advisers who are not yet seasoned enough to survive in the fierce and dangerous ecology of a presidential campaign, let alone a presidential administration; but I'm not buying it. This was gossip.)
But Ms Power has herself to blame. She handed the scoop away; she doomed herself. It was like leaving her car keys in, the engine running, and the door open. You don't do that if you want the car to be there when you come back out of the liquor store.
If Ms Power didn't know the rules about going off the record, but was arrogant enough to be trying to function in a US presidential campaign context, then she's a fool. A monster. And that is off the record, by the way. Don't tell anyone you read it on Language Log.
P.S.: The Scotsman has appended to its article a statement of its off-the-record policy:
WHEN is off the record actually off the record? When the rules are established in advance.
Journalists are always looking for knowledge and want the information they receive to be available for publication.
But occasionally an interviewer will accept an exchange is "off the record" and that the conversation is not attributable. Remarks can be used as background to inform a journalist's article.
If a conversation is to be off the record, that agreement is usually thrashed out before the interview begins. Sometimes, public figures say something and then attempt to retract it by insisting it was "off the record" after the event.
But by then it is too late, particularly if it is in the public interest that the story be published.
In this instance, Samantha Power was promoting her book and it was established in advance that the interview was on the record.
One may not admire them for this (Scottish readers are split down the middle about whether to condemn the paper for privacy intrusion and campaign meddling or praise it as a national treasure for informing us all), but what they say about the usual policy is basically accurate.
And (good news) Samantha Power may not have lost her main job: she reportedly took leave from her Harvard position rather than resigning from it. And she is also a Time magazine columnist . Her life is not over. She will survive.
Onomatolexicography
Jerry Anning writes:
Adam "ApeLad" Koford, of Laugh-Out-Loud Cats fame, recently started a new site called Onomatopedia where people send him sound effects and the like and he draws cartoons using them.
Here's Laugh-Out-Loud Cats #774, which will make no sense without basic knowledge of two quite different cultural traditions (or maybe three):

And here's the Onomatopedia posting for March 3:

This picture, though inspiring, is not consistent with the Jargon File's definition for splork:
[Usenet; common] The sound of coffee (or other beverage) hitting the monitor and/or keyboard after being forced out of the mouth via the nose. It usually follows an unexpectedly funny thing in a Usenet post. Compare snarf.
The word splork also seems to have several prior definitions whose signifier-signified relationships are more arbitrary: a junglefowl from the Olympic Peninsula rainforest; a turn-based strategy war game set in space; a mountain biker from Nashville, TN; the embryonic form of certain Klingon food animals; etc.
There is also a puzzling page giving three "informative speech splork topic lists", about which the less said, the better.
[More lolcats history here, here, here.]
[Update -- Melanie wrote:
I was particularly amused at your Language Log post today. In an early Viz Media translation of the X/1999 manga, "splork" was the sound of a fist going through someone's chest, so it was always been one of my favorite sound effects.
]
March 10, 2008
Pyow, hack, everybody! Monkeys again
For those who read the Daily Telegraph, let me just point out that the new story about the putty-nosed monkeys saying "Pyow hack" seems to be... well, basically just the old story about the putty-nosed monkeys saying "Pyow hack", the one that Language Log has discussed at least three times before. The funniest post (also the first) was certainly David Beaver's And people say we monkey around, on May 18, 2006. I commented, with a sarcasm that I hope actually raised welts on exposed skin, in a post called "Homo journalisticus" on May 19th, after I saw the headline "Monkeys use 'sentences', study suggests". Some days later Mark Liberman later discussed some of the better reporting on the story in his Monkey words on May 28. I cannot see anything new in the Telegraph's story today. Except for the part that doesn't seem to make sense.
The Telegraph story (headlined "Monkeys communicate in sentences" — sic) is based on a paper in Current Biology that I have not yet seen. It says of work by Kate Arnold and Klaus Zuberbühler on the alarm calls of putty-nosed monkeys:
Now in the journal Current Biology the researchers say that these calls function in similar ways as morphemes - the smallest meaningful units in the grammar of a language so for instance, a word such as 'cat' or a prefix such as 'un-'.
This seems to be the same old absurd overstatement as before. Making two distinguishable calls in quick succession is not the same as controlling a word-formation device like the prefix un-. People are so inclined to just look for gross conveyed meaning that they overlook all of the details that make human language interesting to study. The prefix un- attaches to many adjectives to create new adjectives denoting the complement of a property (unhelpful denotes the property possessed by all and only those entities that are not helpful). Some adjectives — color adjectives, for example do not take it. The same prefix (or a prefix of the same form) attaches to some verbs to form new verbs denoting inverses of reversible processes (to untangle something is to reverse the process of tangling it). Many verbs do not take it: *unsneeze is not a verb in English. Nothing remotely like any of this is found in animal communication.
Moreover, the headline said "sentences". Morphemes like un- don't combine to form sentences. They are involved in morphology (word structure). Failing to draw this sort of distinction is like writing on personal finance and investment when you don't know stocks from bonds.
But the unintelligible bit comes when the writer, Roger Highfield, makes some remarks about how the supposedly new results "challenge the notion, commonly held by theorists, of why grammar evolved from simple vocal languages which use a different sound for every different meaning." I'm not quite sure who has ever voiced the view that once every meaning was conveyed by a different sound; but the mysterious bit is what comes next:
Prof Martin Nowak of Harvard University, a pioneer in a field called evolutionary game theory, showed that there is a limit to the range of sounds that can be made and easily distinguished. So for complicated messages it is more efficient to combine basic sounds in different ways to convey different meanings.
"Our research shows that these assumptions may not be correct," Dr Zuberbühler says. "Putty-nosed monkeys have very small vocal repertoires, but nevertheless we observe meaningful combinatorial signalling."
He points out that, unlike humans, most primates are limited in the number of signals they can physically produce because of their lack of tongue control. Thus grammar did not come about because there were too many different sounds to make in different scenarios, but not enough: combining these few calls in different ways meant that they could use them to describe more situations.
I may be missing something, but Nowak and Zuberbühler seem to me to be both saying the same thing: that when you have only a very limited inventory of sounds, you need to string them together to make a larger inventory of conveyed messages. Zuberbühler is not contradicting Nowak's assumptions. He is agreeing. Perhaps some paragraphs got reordered in the writing, or perhaps Nowak is cited as further support for the new view rather than an illustration of the supposed old view. I don't know. But I can't make head or tail of it: I just can't see what Highfield thinks is the relation between Nowak's game theory and the new (old) pyow-hack story. This is not good science writing.
But then it's never time for good science writing when it's animal communication time. It is, like quite a number of other subjects, a topic that turns science journalists' brains to mush.
To Henry Fowler on the occasion of his 150th birthday
Today is the 150th birthday of Henry Watson Fowler, author of the
influential Dictionary of Modern
English Usage. On his Web of Language blog,
Dennis Baron has created an e-card for the occasion:

In these parts, Fowler is most famous for his suggestions for
regulating the choice between the relativizers that and which, most recently treated on
Language Log by Geoff Pullum, here.
Fowler's Rule, as I've come to refer to it, is a rare instance of a
usage prescription that is motivated entirely on rational grounds -- on
the grounds that "better use might have been made of the material
to hand" than was the case in the language of the time.
Almost all the prescriptions of so-called "prescriptive grammar" began
life as PROSCRIPTIONS: someone deemed a usage to be
socially deficient in some way (non-standard, informal, spoken rather
than written, innovative, restricted to some social group or
geographical region) and proposed that this usage should be banned,
either in general (as just flat "incorrect") or at least in the formal
written standard language. This approach to usage should
therefore be properly called "proscriptive grammar". The
proscriptions are often backed up by appeals to "logic" or general
principles like avoiding ambiguity, unnecessary wordiness, unacceptable
terseness, and the like -- though sometimes the proscriptionists just
declare that some usage is wrong, period. Prescriptions come into
the matter late in the game, as offers of acceptable alternatives to
the proscribed usages.
(One bizarre consequence of this approach to usage is that the Cambridge Grammar of the English Language,
which explicitly aims to describe established formal general standard
written English -- and, in my view, does a damn good job of this -- is
nevetheless rejected by many who think of themselves as
"prescriptivists", because it fails to proscribe these critics'
favorite disapproved usages.)
Fowler's Rule, in particular the part in which Fowler suggests using that as the relativizer for
restrictive relative clauses, isn't like this at all. Both which and that were entirely standard as
restrictive relativizers in Fowler's day, as they still are.
Fowler was suggesting that that
should be used rather than which
as a matter of neatness in patterning, not because of any perceived
social deficiency (non-standardness, informality, conversational tone,
whatever) in which. The
result of following Fowler's Rule consistently (as some style sheets
now demand) is a contraction in the expressive capabilities of the
established formal general standard written language. That's why
here at Language Log Plaza we object to the enforcement of Fowler's
Rule: don't mess with our choices!
But Fowler himself was not rigid about the matter, and though there's a
lot to criticize in Modern English
Usage, we can't hold him responsible for what zealots have made
of his ideas. So let's have a glass of sherry on Fowler's 150th
birthday.
What's the difference?
 An article in today's NYT (Laura Holson, "Text Generation Gap: U R 2 Old (JK)", 3/9/2008) suggests anecdotally that cell-phone text messaging is surging among U.S. teens. My own recent anecdotal experience bears this out -- a 12-year-old of my acquaintance much prefers text messaging to talking on the phone, even when it seems to me that a voice conversation would be quicker and more efficient.
An article in today's NYT (Laura Holson, "Text Generation Gap: U R 2 Old (JK)", 3/9/2008) suggests anecdotally that cell-phone text messaging is surging among U.S. teens. My own recent anecdotal experience bears this out -- a 12-year-old of my acquaintance much prefers text messaging to talking on the phone, even when it seems to me that a voice conversation would be quicker and more efficient.
But just a few years ago, the situation was completely different. Although texting was popular in Europe and Japan, the rate of use in the U.S. was roughly two orders of magnitude lower -- and was mainly confined to online trading addicts getting stock price alerts, sports fanatics getting score updates, etc. See "No text please, we're American", The Economist, 4/3/2003; "Why text messaging is not popular in the US", textually.org, 4/4/2003. I also noted this difference in a few posts three years ago ("Texting", 3/8/2004; "More on meiru", 3/9/2004; "Texting, typing, speaking", 7/1/2004).
The explanations offered for the geographic difference, back then, included Japanese commuting habits and social conventions discouraging phone conversations in public; greater availability of networked computers to Americans; different voice, SMS and internet pricing structures between Europe and the U.S.; the fact that SMS "was originally defined as part of the GSM series of standards", while U.S. cell phone service is more diverse in terms of its underlying technology.
But in general, these things haven't changed (as far as I know). So why are U.S. adolescents suddenly texting up a storm? Is this a cultural change driven by purely cultural factors?
Anyhow, we're still not quite at European levels of texting, at least among adults. So the management of advertising space on parking-meter and lamppost padding in American cities remains a business opportunity for the future ("Padded Lampposts Tested in London to Prevent Cell Phone Texting Injuring", Fox News, 3/7/2008; "Padded lampposts coming to London, for the protection of stupid text messagers", TechDigest).
March 09, 2008
Reading the government's mind
In Geoff Pullum's post, Per Bus Per Journey, he illustrates how organizations that try to communicate with the public find it hard to "see the world through other people's eyes."
It's not difficult to find instances of this all around us when we bother to look. Sometimes the language in question rises even to the level of lawsuits, as in the case of The State of Nevada Business and Transportation Authority v. Preferred Equities Corporation (Case No. 10699) a couple of years ago. The defendant was a Las Vegas condominium that provided free shuttle service to and from that condominium to and from the Venetian and Frontier casinos. Nevada state inspectors investigated this service and charged Preferred Equities with violating the state code by:
This charge was based on the State's interpretation of the following three subsections of the state code:
(d) Transportation is furnished only if the provider's place of business is the point of origin or the point of destination of the customer's trip.
(e) Each trip is between a place of business owned by the provider and one other point.
The lawyer for Preferred Equities was concerned about what his clients must do in order to "effectively limit" the provision of free transportation to their customers (subsection c), whether the "trip" referred to in subsection (e) is different from the "customer's trip" referred to in subsection (d), and what the code meant by "customers."
Subsection (c) gives no indication of how a transportation provider might "effectively limit" service to its customers. Without such an indication, the paragraph is like many faulty contract and code paragraphs: subjective and vague as to its intended meaning. "Limits" doesn't prescribe the actual restraints on providing transportation, nor does it specify any absolute boundary for whatever is to be limited. The Meriam Webster Collegiate Dictionary (MWCD) defines the verb, "limit," as:
2. a. To restrict the bounds or limits of; b. To curtail or reduce in quantity or extent
Synonyms: restrict, circumscribe, confine
"Limit" implies setting a point or line beyond which something cannot or is not permitted to go.
In the code, "limit" suggests only that there is a boundary out there somewhere that should not be exceeded, but it doesn't tell us where it is or how the transportation service might breach it. In other words, the condominium's transportation provider had to imply the limit . . . or guess at it. The expression used in the code is semantically vague and is subject to multiple interpretations.
"Customers" offers similar problems. MWCD and American Heritage define a customer as "one that purchases a commodity or service" and "a person with whom one must deal." And we all know that shops refer to "customers" even when the customer is just looking around and doesn't even make a purchase. Subsection (c) doesn't specify whether those who use the transportation service must be actual purchasers of that service (but also note that the service is free), or whether they were friends of the actual customers and perhaps even potential customers.
"Trip" is equally vague in the code (subsection e). The State's investigators claim to have found riders who violated this subsection by riding from one casino to another rather than first returning to the condominium before starting a different trip to the other casino. There is no indication in the code about whether a trip is defined from the perspective of the rider or from the perspective of the provider. If the code writers had intended to mean a trip made by the provider rather than the traveler, they could have done so clearly, just as they defined trip in section (d) as "the customer's trip." The code could have clarified this by saying, "each trip made by the provider is to be between a place of business owned by the provider and only one other point." But because they identified "trip" previously in subsection (d) as the customer's trip, the reader, absent any other marked clues, is encouraged to understand "trip" in subsection (e) to continue to mean the customer's trip, not the provider's.
Specific to this case, a more explicit wording would have helped ensure that customers would not be picked up at the Venetian and driven to the Frontier, for example. A more explicit wording would also indicate that the provider could not make two stops, one at the Venetian and another at the Frontier, on any "trip" from the condominium, if that's what the code intended.
The problem is unfortunately common. Laws, codes, and statute are not usually written or reviewed by language specialists, who would be able to point out instances where they are unclear, vague, or ambiguous. And it seems likely that this Nevada code failed, as Geoff put it, "to see the world through other people's eyes."
P.S. This case is one of the 18 civil lawsuits I describe in my book, Fighting Over Words (Oxford U Press, 2008).
Double Jeopardy Has Attached
In the criminal law of the United States and many other countries, "double jeopardy" is prohibited. Simply put, this means that you can't be tried more than once for the same offense.
In the US, double jeopardy is unconstitutional due to the following clause of the Fifth Amendment:
nor shall any person be subject for the same offense to be twice put in jeopardy of life or limb
In the common law, the antecedant of the doctrine of double jeopardy applied only to final judgment. A defendant could plead that a new trial was barred by the fact that he was autrefois acquit "previously acquitted" or autrefois convict "previously convicted". However, the prohibition has developed in such a way as to preclude, with certain exceptions, more than one trial for the same offense, even if no verdict was reached in the first trial. As Blackstone (4 W. Blackstone, Commentaries 26) put it:
no man is to be brought into jeopardy of his life more than once for the same offence.
If a final judgment is not required for a prosecution to preclude a later prosecution, the question arises as to the point at which we shall say that the first prosecution should count. This point is known, after Blackstone's formulation above, as the point at which "jeopardy has attached". In cases tried before a jury, jeopardy attaches when the jury is sworn. In cases tried before a judge, jeopardy attaches when the first witness is sworn.
Last night I was watching Law and Order and for the umpteenth time heard the expression "double jeopardy has (not) attached". Whenever I hear this it makes me wince, and I hear it a lot on Law and Order. Real lawyers do not say this, for good reason: it doesn't make any sense. What "attaches" once a certain point is reached in a prosecution is plain "jeopardy"; "double jeopardy" is what would happen if that first prosecution were allowed to be followed by a second prosecution for the same offense.
I mention this in part in the probably vain hope that word will get back to the producers of the show and they will stop it, and in part because I wonder how it happens. My understanding is that such legal shows have advisers to keep them accurate. If so, how is it that this one not only got by but is a persistent error? I also wonder how the error arises in the first place. What does someone who says this, or writes it in a script, think that the phrase means? The best I can come up with is that they think it means: "the trial has now reached the point at which an additional trial would result in a violation of the ban on double jeopardy", but that seems awfully contrived and unlikely.
Update: In asserting that real lawyers do not say "double jeopardy has attached" I relied on individual judgment, including that of a law professor. Reader David Cohen ran a search on Westlaw's Federal court database and found numerous instances of this usage, along with "jeopardy has (not) attached", so it seems that real lawyers, in particular, judges, actually do use this expression. He found no instances of the "double jeopardy" usage in Supreme Court opinions, suggesting that it is regarded as a less correct, less formal, usage. It is still a sloppy and awkward usage, but what is contrived for an ordinary person no doubt is less so for judges. This is a nice example of how people's impressions of usage may not reflect the facts as revealed by search of a corpus.
Reader David Seidman suggests a possible motivation for preferring "double jeopardy has (not) attached", namely that for the average, non-lawyer viewer, the meaning of jeopardy having attached may be obscure, while "double jeopardy" is something more likely to be familiar.
Per bus per journey
There was something linguistically strange about the sign I saw on the number 60 bus between Ayr and Girvan yesterday. It concerned the baby buggy parking area of the bus, and it said there was a limit: "a maximum of two baby buggies allowed per bus per journey". It's not that you can't iterate preposition-phrase modifiers with per; you can, for example when talking about acceleration (an object dropped from a height accelerates at a rate of 32 feet per second per second). I'll tell you what I decided was weird about it. Curiously, it relates to the sea lion story I once told on Language Log, which was really about officialdom, technical vocabulary, and failure to adjust perspective.
Here's what I think is wrong with the wording of the notice. The modifier "per bus per journey" could be a relevant way to talk, but only if bus/journey pairs were under consideration. That might happen in a context where, for example, someone was trying to compute the maximum number of baby buggies that could be transported from place to place in a day given a certain number of passenger boardings or stop-to-stop transits. It's transport economics talk.
No one who needs to know whether they can bring a baby buggy on board is interested in bus/journey pairs, because other journeys than their own are irrelevant to them. For them, "a maximum of two baby buggies allowed per bus" would do fine, because they experience the bus as a small transient universe, not as a resource with a certain daily carrying capacity.
Certainly, a given bus will be able to carry vastly more than 2 baby buggies on it during a day: the theoretical maximum would be 2n baby buggies for n stop-to-stop transits (basically, it would be reached if at every stop two passengers get on with baby buggies and two others get off). But no passenger cares about that. The notice is trying to tell passengers something about the limits of what they can do on their one segment of the bus's daily activities: if there is one other baby buggy on board, or none, they can bring theirs on, but if there are two on board, they can't. Nothing about other journeys or trip segments can be relevant. As Noam Bernstein points out to me, it is hard even to get it to make any sense: he notes that you have to redefine journey to try and get "per bus per journey" to mean that there mustn't be more than two buggies on the bus at any one time. The only way Noam could see is to define it so that a journey "is from one stop to the next, and then passengers who are going more than one stop are taking multiple journeys, which isn't what anyone means by 'journey'." He's exactly right, I think. The modifier "per bus per journey" is semantically not quite right, and syntactically one layer too complex for the situation at hand, when properly viewed — from the passenger's perspective.
A lot of the linguistic trouble that arises when organizations attempt to communicate with the public stems from point of view: an inability on the part of members of the organization to empathize, to view situations from the perspective of someone who is in the situation that a member of the public will typically be in. (Think of those unintelligble sheets of instructions that incorrectly assume you will know how to align the trunnion with the sprocket flange when they haven't told you what these are.) It's not about the grammar; it's about theory of mind. It's about being able to see the world through other people's eyes.
There are plenty of other examples out there, I think. Beverley Rowe points out that in Camden, north London, there are recycling bins labeled "Mixed card and paper". But that's not what we're supposed to put into them, is it? It doesn't mean we have to mix card and paper. The council is thinking about what it will be taking out of those bins. They labeled them from their perspective instead of from the user's. No ability to see through others' eyes, or walk a mile in other people's shoes.
Ask Language Log: sounds and meanings
Barbara Duncan asks:
Do you know of any language where sounds have consistent meanings from word to word? If so, what language? If not, why not?
If by "sounds" you mean phonemes or phonetic features, then there are no languages where sounds have consistent meanings from word to word. This generalization is what Charles Hockett ("The origin of speech", Scientific American, 203: 88-96, 1960) called "duality of patterning":
The meaningful elements in any language -- "words" in everyday parlance, "morphemes" to the linguist -- constitute an enormous stock. Yet they are represented by small arrangements of a relatively very small stock of distinguishable sounds which are in themselves wholly meaningless. This "duality of patterning" is illustrated by the English words "tack,", "cat" and "act." They are totally distinct as to meaning, and yet are composed of just three basic meaningless sounds in different permutations. Few animal communicative systems share this design-feature of language -- none among the the other hominoids, and perhaps none at all.
A hundred years ago, Ferdinand de Saussure referred to the meaninglessness of the atomic elements of linguistic sound with the famous phrase "the arbitrariness of the sign" ("l'arbitraire du signe" in the original French).
Why do all languages exhibit duality of patterning? Why are linguistic signs, in general, arbitrary combinations of elementary discrete sound elements that are themselves meaningless? Basically, this digital encoding is the only way to have a large and expandable vocabulary whose elements are transmitted reliably.
Here's how I explain it in the lecture notes for Linguistics 001:
Experiments on vocabulary sizes at different ages suggest that children must learn an average of more than 10 items per day, day in and day out, over long periods of time.
A sample calculation:
* 40,000 items learned in 10 years
* 10 x 365 = 3,650 days
* 40,000 words / 3,650 days = 10.96 words per dayMost of this learning is without explicit instruction, just from hearing the words used in meaningful contexts. Usually, a word is learned after hearing only a handful of examples. Experiments have shown that young children can learn a word (and retain it for at least a year) from hearing just one casual use.
Let's put aside the question of how to figure out the meaning of a new word, and focus on how to learn its sound.
You only get to hear the word a few times -- maybe only once. You have to cope with many sources of variation in pronunciation: individual, social and geographical, attitudinal and emotional. Any particular performance of a word simultaneously expresses the word, the identity of the speaker, the speaker's attitude and emotional state, the influence of the performance of adjacent words, and the structure of the message containing the word. Yet you have tease these factors apart so as to register the sound of the word in a way that will let you produce it yourself, and understand it as spoken by anyone else, in any style or state of mind or context of use.
In subsequent use, you (and those who listen to you speak) need to distinguish this one word accurately from tens of thousands of others.
(The perceptual error rate for spoken word identification by motivated listeners is less than one percent, where words are chosen at random and spoken by arbitrary and previously-unknown speakers.)
Let's call this the pronunciation learning problem. If every word were an arbitrary pattern of sound, this problem would probably be impossible to solve.
What makes it work? In human spoken languages, the sound of a word is not defined directly (in terms of mouth gestures and noises). Instead, it is mediated by encoding in terms of a phonological system:
- A word's pronunciation is defined as a structured combination of a small set of elements
The available phonological elements and structures are the same for all words (though each word uses only some of them)
- The phonological system is defined in terms of patterns of mouth gestures and noises
This "grounding" of the system is called phonetic interpretation, and it's the same for all wordsHow does the phonological principle help solve the pronunciation learning problem? Basically, by splitting it into two problems, each one easier to solve.
- Phonological representations are digital, i.e. made up of discrete elements in discrete structural relations.
Copying can be exact: members of a speech community can share identical phonological representations.
Within the performance of a given word on a particular occasion, the (small) amount of information relevant to the identity of the word is clearly defined.- Phonetic interpretation is general, i.e. independent of word identity
Every performance of every word by every member of the speech community helps teach phonetic interpretation, because it applies to the phonological system as a whole, rather than to any particular word.
For more on this topic, see Michael Studdert-Kennedy and Louis Goldstein, "The Gestural Origin of Discrete Infinity", in Christiansen & Kirby, eds., Language Evolution, OUP, 2003. And for an amusing and interesting -- but completely unsuccessful -- attempt to design a language with more systematic sound-meaning correspondences, see Joge Luis Borges' essay "El Idioma Analítico de John Wilkins", Otras Inquisiciones (1952).
However, the arbitrariness of the sign is not complete. Every language has a certain amount of phonetic symbolism. There are always onomatopoeic words like whoosh and tick-tock, and this natural sound/meaning connection may bleed through to some extent into fairly large areas of vocabulary, as in English flip/ flap,/flop, clink/clank/clunk, etc. And in some languages, there are specific classes of words, sometimes called "ideophones", where these quasi-natural sound-meaning correspondences are systematized, sometimes to a considerable extent.
I've been interested in this area since I was an undergraduate, when I worked for a while on sign languages, and thought about the imitative aspects of signing. And it came up again in my work in graduate school, in connection with the form and interpretation of pitch patterns in intonational languages, again because a crucial feature of ideophonic systems is that their semantics is mainly iconic rather than symbolic. Here's something that I wrote about this in my dissertation (The intonational system of English, 1975):
An additional complication in the analysis of intonational units arises because of the extremely strong role played by phonetic symbolism in constraining intonational meanings. In no other aspect of language is "l'arbitraire du signe" less manifest than in intonation., and we have every reason to believe that a substantial portion of the content of the intonational lexicon of English is determined by the universal symbolic (better: metaphorical) value of tones and tone-sequences. However, there are also many clear examples of language-specific tunes, and meanings for tunes, so that some degree of arbitrariness or conventionalization must be built into the system.
In the non-intonational lexicon, phonetic symbolism clearly cross-cuts morphology and even phonology, with non-distinctive oppositions (e.g. short/long, for English) and non-morphological sequences (e.g. -ink in wink and blink) often playing a role.
Some psychologically significant intonational oppositions (e.g. terminally falling / terminally rising) should be seen as being of this nature. [...] [In a description based on level tones,] the rising/falling distinction is not a direct characteristic of the phonology or morphology of the intonational system, but rather an overlaid distinction, a complex property of the systematic representation of the tune, like those distinctions which would be required in defining phonetic symbolism in general.
I think that there is excellent evidence that this is true. We have a sense that "rising" gestures in general share some property by opposition to "falling" gestures. Weak and strong beats in music are conceived of as rising and falling respectively (arsis/thesis, levatio/positio, upbeat/downbeat etc.). In dance, rising up on the toes is generally an arsic gesture, while coming down flatfooted in generally thetic. Raising the eyebrows is an other-directed gesture (greetings, expression of skepticism etc.), while lowering the eyebrows is a more self-directed gesture (signaling concentration, etc.). In sign languages, questions, nonterminal pauses etc. are usually signaled with an upward motion of the hands, while more "final" terminations are signaled with a downward motion (superimposed on whatever signs are being employed in the "utterance"). Examples could be multiplied indefinitely; the point is simply that "rising" and "falling" have some general metaphorical value independent of any role that they may play in intonation, and that they roles which can in general be attributed to these concepts in intonation (e.g., other-directed vs self-direction, nonfinal vs. final) are exactly what would be expected on the theory that we have proposed, that they are essentially para-linguistic metaphors.
The fact that the normal metaphorical value of "rising" and "falling" is sometimes violated in the case of particular intonational tunes shows that universal sound symbolism does not completely determine the meaning of intonational words, although is obviously has a strong influence.
If we are to understand this situation, we would do well to examine the properties of conventionalized systems of sound-symbolism in general. Following a usage originally established to cover such phenomena in Bantu languages, and since extended to other cases, we will call these aspects of language ideophonic systems.
Ideophonic systems have five properties that will be of interest to us; the first and last of these they share with more conventional linguistic systems, while the remaining three tend to differentiate them from other aspects of language. [...]
1) Ideophones are words; that it, they are made up of sequences of systematically distinctive elements (= phonemes), in patterns whose structure is determined by a morphology.
2) In general, the meaningful units in an ideophonic system are not directly driven by the morphological analysis of a particular ideophone, but rather by some set of (more or less complex) properties defined on it.
3) The meanings of these units are typically metaphorical rather than referential; that is, they refer to a class of analogous aspects of different cognitive structures, rather than to any particular aspect of any particular such structure.
4) Ideophonic signs are not arbitrary -- the meanings of particular elements of an ideophonic system are strongly influenced by universal considerations. However, in any particular case, these form-meaning correspondences may become a specific, characteristic system, which is usually consistent with the universal basis, but is not entirely predicted by it.
5) Within a given system, "lexicalization" is possible -- that is, specific ideophonic words may take on particular meanings which are not predicted either by the universal basis, or by the particular system they belong to.
The most familiar linguistic examples of ideophones are echoic words, like English clang, clank, etc. Words that are not exclusively echoic may also have an ideophonic component -- for example, it is not completely accidental that "gong" refers to a large metallic disk that gives a loud, resonant tone when struck, while "flute" refers to a high-pitched wind instrument. However, there are cases in which ideophonic systems extend far behond the metaphorical relationship of the sound of a word to a non-linguistic sound.
For example, in Bahnar (Guillemet 1959, cited in Diffloth 1972), the words /blɔːl/ and /bloːl/ are glossed as follows:
/blɔːl/ 1. when a small fish quickly jumps out of the water.
2. when a man who has debts comes to your door or appears at your window./bloːl/ 1. when a big fish quickly jumps out of the water.
2. when an important person comes to your door or appears at your window.
3. when a great effort is made to reach an object which is out of reach.
4. suddenly speaking louder when one cannot be heard well.Several aspects of the above example deserve comment. 1) We are dealing with words, made up of sequences of phonemes, not just free expressive noises; 2) the aspect of the word that is changed to produce a difference in meaning is (in this case) a single feature of a single phoneme, not a substitution of phonemes or sequences of phonemes; 3) the meanings of these words are extremely abstract properties, which pick out classes of situations related in some intuitively reasonable, but highly metaphorical way: the general "meaning" seems hopelessly vague and difficult to pin down, yet the application to a particular usage is vivid, effective and often very exact; 4) the particular phonological opposition which differentiates the two words, /ɔ/ vs. /o/, has a non-arbitrary connection to the meaning difference [...]
This last point deserves some amplification. Suppose we make a partial listing of certain pairs of adjective with intuitively corresponding properties:
large
strong
important
loud
dominantsmall
weak
unimportant
soft
submissiveNow, there is some phonological feature opposition (say tense/lax) which characterizes the difference between Bahnar /ɔ/ and /o/. In the system of ideophones of which the examples /blɔːl/ and /bloːl/ are members, this feature opposition (if it occurs in the proper position) has semantic content. But it is not at all clear that we want to say that tense means "big" while lax means "little", and that the other emanings are metaphorical extensions of these core meanings. Rather, what seems to be happen is that a systematic analogy is made between the phonological opposition "tense/lax" itself and the class of semantic oppositions big/little, important/unimportant etc., so that the actual "meaning" of the choice tense depends entirely on the nature of the situation to which one decides to apply the ideophone in question. Thus it may be true, in an ideophonic system, that the only meaning of a given element lies in the ability to analogize (in a systematic way) from its phonetic or phonological character to a large number of different concepts. In one sense, then, an ideophonic element means itself, given the human ability to make a kind of free-ranging metaphor out of its particular phonological or phonetic properties.
On this view, the non-arbitrary character of dieophonic sound-meaning correspondences, and their referential indeterminacy, the apparent abstractness of their meanings, are closely connected. This connection between the non-arbitrariness of the meaningful element and the essentially metaphorical character of the meaning is clearly exemplified in these examples from Korean (cited in Diffloth 1972):
tɔllɔŋ tɔllɔŋ 1. sound of small bells.
2. swaying movement of something suspended.
3. feeling of being left along when everyone has gone.
4. someone appears flippant.ttɔllɔŋ ttɔllɔŋ 1. sound of narrow bells, bells hit hard.
2. swaying movement of short object, tightly suspended.
3. feeling of being left alone when everyone has gone; shock of solitude comes more suddenly.N.B. Diffloth cites more than twenty Korean exmaples from a "paradigm" created by holding constant the formal property "repeated disyllabic word with medial -l-"; this property seems to represent some meaning like "back and forth movement, socillation, suspension, etc." Apparently there are thousands of possible words in the ideophonic system of Korean, including the possibility of nonce formations.
The meaning of the distinction t/tt, in these examples, is again best considered as the ability of construct a metaphorical connection between the phonological opposition itself and any one of a class of rather different concepts.
Following what I believe is a fairly standard usage, we will call this mode of meaning, in which the signifié is a general metaphorical extension of some intrinsic property of the significant, by the term iconic. [...]
Iconic meaning is also characteristic of non-linguistic expressive noises, gestures, etc. However, an interesting aspect of ideophonic systems is that they are linguistic, made up of phonemic sequences which are often arranged according to fairly restrictive morpheme structure constraints. As a result, they are more prone to conventionalization than paralinguistic systems generally are -- the range of possible metaphors is often restricted, the meanings of the ideophonic elements become less iconic and more arbitrary, and the degree of compositionality of the resulting ideophonic words may decrease, in just the same way that polymorphemic words in general decrease in compositionality across time.
For more on this, from people who know a lot more about than I do, you could take a look at two relatively recent books:
Leanne Hinton, ed., Sound Symbolism, CUP 1994
Erhard Friedrich Karl Voeltz & Christa Kilian-Hatz, eds., Ideophones, John Benjamins, 2001
[John Cowan writes:
Even Wilkins's language doesn't truly have phonemes with consistent meaning. All that can be said is that words for closely related concept differ in the last phoneme, and so on up the tree, but initial 'r' does not mean the same thing as 'r' in the third position: the former has a single (broad) meaning, but the latter's meaning depends on the identity of the first two phonemes.
Put that way, the language isn't so very different from natural languages with single-phoneme morphemes, like the one-letter clitic prepositions in the Slavic languages, or the "changed tone" in Cantonese, which is a set of homophonous bound morphemes (or a single highly polysemous one) that changes the tone of the preceding syllable to mid rising (35). In both cases, these morphemes formerly had more phonemes that have been lost; the 35 toneme was apparently once a whole syllable that happened to have 35 tone.
]
Posted by Mark Liberman at 08:38 AM
March 07, 2008
YouCool
[Victor Mair sent me this more than a week ago. Apologies to all for my delay in getting it ready to post on his behalf.]
The Chinese have been celebrating the 50th anniversary of the birth of Hanyu Pinyin, the official Romanization of the People's Republic of China. Even the foreign media are aware of this important milestone for the PRC's alphabetical writing system, part of what I call the "emerging digraphia" composed of HANZI (characters) and HANYU PINYIN (romanization) in China.
I was delighted to come across a video of my 102-year-old friend, Zhou Youguang, who is hailed as "the father of pinyin," though in the video he begins with a polite disclaimer by styling himself "the son of pinyin." ("Helping China learn to read", Guardian, 2/29/2008.)
Then, on an exciting new blog called Beijing Sounds, I was directed this 30-minute video of Zhou Youguang holding forth (in Mandarin) on the virtues of pinyin ("Don't take away our pinyin", 2/22/2008). The Beijing Sounds blog will surely be attractive to all who are interested in the niceties of Beijing colloquial, particularly its most endearing phonetic aspects. The blog also covers the welcome rebirth of Manchu, Tianjin speech peculiarities, and all manner of other intriguing linguistic and cultural information about China today.
What I want to do here, however, is comment on the name of the video sharing service that brings Zhou Youguang's video to us, which is blatantly a take-off on YouTube. The Pakistanis and Stanford Daily columnist Nat Hilliard (see Arnold Zwicky's post "Doomed by Poor Spelling and Rampant Racism etc.", 2/ 29/2008) may have bid YouTube good riddance, but the Chinese welcome it with open arms.
The name to which I am referring is YouKu 优酷.
What to make of this hybrid appellation? If we read it according to the surface signification of the characters, it means:
YOU1 excellent; ample, well-off; give preferential treatment; ancient term for an actor or actress. (This pinyin syllable should be pronounced to sound something like the first syllable of "yeoman" or South Philadelphia "yo!" but with a high, level tone.)
KU4 cruel, savage, ruthless; extremely, very. (This pinyin syllable sounds like "coo" with a falling tone.)
Of course, there's no way you can make any sense out of the name by relying on the meaning of its two component characters in Chinese. The creators of this ersatz YouTube have christened their video sharing service with two English words written in Chinese characters, "you" and "cool." The first relies on a pinyin-English faux ami and the second on a not-so-near-homophonous sinographic transcription of an English word. Mandarin KU4 = English "cool" has a very high frequency among youth, despite the fact that the character chosen to represent the English sound is not exactly what one would consider the semantically most appropriate choice.
YouKu 优酷 is a good example of what may be called "Sino-English," which I predict will become increasingly evident in the years to come, until Chinese and English experience a kind of blending (a veritable Mischsprache?) which is the theme of an unpublished, futuristic novel called China Babel that I wrote about 15 years ago. It's not so unlikely as one might think: Japanese has well over sixty thousand gairaigo (lexical borrowings, the vast majority from English), and the number continues to grow daily, so that in some contexts, one seems to hear an English word in almost every other Japanese sentence that is uttered.
[Above is a guest post by Victor Mair.]
lytdybr continued
I received some interesting e-mails following up on
my post on the "lytdybr" encoding based on Cyrillic keyboard and QWERTY keyboard key locations.
One reader noted the similarity to "phone numbers written with letters instead
of numbers (like 1-800-MATTRES), where one set of characters is replaced by
another set with a shared mapping". I haven't heard from anyone about
QWERTY-words showing up in other languages. The closest is the interesting
phenomenon that Richard Earley wrote to me about, where new lexical items are
entering English slang thanks to the T9 (and similar iTap) predictive text
technology on cell phones:
Richard Earley:
I wanted to share with you a similar source for linguistic creation among English speakers: the T9 dictionary on a cell phone.Elizabeth Moffatt wrote from New Zealand:
In case you aren't as compulsive a text messager as are the huge majority of today's teenagers, the T9 dictionary speeds up text composition by allowing users to press only one key to enter a character. As each key contains three of four letters, the T9 keeps track of a sequence of keystrokes and then suggests an intended word by matching the possible combinations of those three or four letters to the words in a dictionary.
It's a remarkably efficient system, but it does have a few problems where two words can be produced from one sequence. Some simple examples are 'of'/'me' and 'if'/'he'.
There are also some more amusing ones, mostly caused by the limitations of the T9 dictionary particularly with regards to brand names.
For instance, the name of Vodka brand Smirnoff is rendered as 'poisoned'. This has become a slang term among some young people, normally bringing a laugh of recognition the first time it is brought up. Misspellings can also cause confusion, and I have heard people talk about their 'plans for unoppo', which is what results from forgetting the m in 'tomorrow'. Thanks to the prudes at Nokia and Samsung similar problems arise with swear words. The first suggested word for 'bitch' is 'chubi', which has gained some popularity as a word on its own. There are many other examples that I could give you, but I will finish with the term 'book' meaning 'cool' which is something I used to hear a lot in London.
I find it an amusing parallel that a device that is so often used to communicate without the knowledge of a teacher has also birthed an RIAA parental advisory version of several swear words and probably helped confuse older generations even with no cell phone in sight. Conversely, and quite contrary to the probably first reaction of most 'grammarians' to this, I have to confess that before I started using a T9 dictionary I could never spell tomorrow, and now I have no problems with it. So might text-speak actually improve people's English?
I just read your post about encoding of Russian using the Cyrillic alphabet. I was wondering whether perhaps were talking about this?:I checked it out and realized that its another interesting encoding but a different one. In Volapük you look for letters that LOOK alike in the two languages. Here's an example from the Wikipedia article:
"Volapuk encoding (Russian: кодировка "волапюк", kodirovka "volapyuk") is a slang term for rendering the letters of the Cyrillic alphabet with Latin ones. Unlike Translit (there characters are replaced to sound the same), in volapuk characters can be replaced to look or sound the same."
I've just read Spook Country by William Gibson, which is where I was introduced to the term.
• COBETCKIJ COIO3 ("advanced" Volapük)
• СОВЕТСКИЙ СОЮЗ (Cyrillic)
• SOVETSKIY SOYUZ (transliteration)
• Soviet Union (English)
To which I add
• CJDTNCRBQ CJ.P (QWERTY)
UPDATE There's an inverse of Volapuk known as Faux Cyrillic, described here. Hat tip to Douglas Sundseth.
Bill Poser sent me a nice alphabet-related anecdote that is neither QWERTY-code
nor Volapük.
Years ago I went away for some time and one of the grad students, Jennifer Cole, stayed at my place in Palo Alto. She wasn't there when I returned and had left a note on the door. I assumed that it told me where she had left the key since for reasons I now forget I had not taken a key with me. The note was in Cyrillic letters, so I attempted to read it as Russian, a task in which I was unsuccessful. At first I interpreted this as due to my lousy Russian and despaired that I would have to search for the key or break in. Fortunately, further contemplation revealed that the note was not in Russian: it was in Japanese. I think that her assumption that few burglars would have understood the note was correct.UPDATE:
Bruce Rusk adds:
Your LL post today on T9 cussing (bussing?) reminded me of this video on that very topic.
It's a lovely sendup of benign dictatorial prescriptivism.
Venti
Dave Barry once suggested that the Starbucks coffee-size name venti might mean, for all we know, "weasel snot" ("Latte Lingo: raising a pint at Starbucks", 11/30/2004). In fact, of course, it's the Italian word for "twenty", referring to the spectacularly non-Italian denomination of twenty ounces. Stefano Taschini's reaction:
I believe there must have been a small mistype: technically, a warm liquid that you ingest in quantities exceeding half a liter is "stock" not "coffee".
I'm personally quite fond of American-style coffee infusions, and prefer them to the tiny intense Italian versions. But I've always found Starbuck's coffee-size names silly at best, and venti is the silliest and least attractive one. There's some indirect evidence that the rest of the English-speaking world agrees with me -- despite tens of millions of encounters with this word every day, no one has adopted venti as slang for "large".
Well, hardly anyone. From a weblog titled "Life in a Venti Cup":
Life is too short to think small. So live large. Live with style. Live with adventure. Live venti.
Web search turns up a few comments on various myspace pages:
i am venti and in charge... omg i love u!
I am not tall, I'm venti!
Marina told me about Venti Emily at your store...so you're short, I'm tall, she's venti...now we need a Grande!
And apparently there's a religious podcast out there called "A Very Venti Christmas". But most of the extended uses that I found on the web are part of explicit arguments that venti is not an acceptable word for large, or part of various anti-Starbucks complaints:
"A very venti vent"
"It seems to me if you're going to charge a couple bucks for a cup of coffee the least you can do is give away wifi. That's not very venti of you"
"Venti means big. As in waistline. A Chocolate Brownie Frappucino has almost as many calories as a six-pack of beer".
This morning's Cathy illustrates the point, by pretending that its opposite is true:

But the harvest is remarkably slim. Overall, this might be the least successful large-scale naming effort in history, at least in terms of impact on general usage in relation to amount of exposure.
March 06, 2008
The innateness hypothesis in the late 1700s
Here's something I've been meaning to post since before Christmas. You may recall at the time that a student and I were excited to have found an older use of the word 'eggnog' than was recorded in the OED. Turned out we were far from the first to have noticed it, but it was fun anyway -- and it paid an unexpected dividend. Harvard had kindly mailed me, via inter-library loan, their actual copy of the posthumous 1807 printing of philologist and clergyman Jonathan Boucher's 'Glossary of Obsolete and Provincial Words', with an extensive introduction. Looking at WorldCat, it seems there are only 7 extant copies of this printing in libraries they know about, which makes me even happier that I photocopied the introduction while I had my paws on its old and yellowed pages (very, very carefully, of course).
It's printed in a tiny font, and I haven't read through it thoroughly, but one early passage caught my eye, which I thought I'd share with you. Boucher (kind of) makes the case for language as an instinct -- an innate endowment of the species -- rather than as garden-variety learning:
Common as the case is, it is not easy to describe the process that is gone through in learning to speak; nor is it possible, for instance, to assign a reason, why some children, apparently of equal capacities and with equal opportunities, learn to speak so much later, and with so much more difficulty than others; and why also, in a family of children, all brought up together, and as near as may be in the same manner, one pronounces one certain letter with ease, which another cannot pronounce at all. There are whole nations that cannot pronounce the letter r. One thing is certain, that all mankind do, sooner or later, learn to speak; and, in general, though we hardly know how, wih a degree of ease, not less extraordinary than the certainty of success. [...] This is a most providential dispensation: since, at a period in which our powers are too feeble, and but little disposed to learn other things, they are eminently well calculated, and well disposed also, both to acquire and to retain words. [...] And when we contemplate with what difficulty children, and even grown persons, are taught things which, comparatively speaking, are infinitely less complicated than any language; whilst yet they learn to utter, combine, and understand words of the most diversified forms, almost as naturally and easliy as they learn to perform any of the other most ordinary functions of life, we are lost in astonishment at the goodness of that Almighty Power, who formed us with these admirable capacities.This, except for the appeal to the supernatural at the end, could practically have been lifted straight from an introductory lecture pushing the innateness hypothesis about language acquisition. The note that all non-disabled people eventually learn to speak, at an age when it's hard to explicitly teach them, and the comparison of the complexity of language with that of other material which is learned later in life with much more difficulty, are all key points in any such lecture.
When reading the rest of the Introduction, I bogged down somewhere in the middle, where Boucher is arguing that of all the modern language families, Celtic is most closely related to Hebrew, the proto-language, and that the other Indo-European languages are descended in turn from the Celtic languages. I'm not a historical linguist, nor yet (more importantly) a linguistic historian, so I don't know how widespread such views were in those days when Sir William Jones was just first lecturing on the connections between Sanskrit, Persian, Greek and Latin, but I'm assuming that the historical discussion is partly a reflection of Boucher's times as well as a reflection of his calling.
But I'd be interested to know more about whether similar passages about the remarkableness of language acquisition appeared in other linguistic discussions of the age.
Ph(o)netics and ph(o)nology
Courses on phonetics and phonology usually cover the topic of language-particular phonotactic constraints: conditions on the sound sequences that are allowed to form words in a given language. For example, a phonologist may explain, English has fricatives with the usual spellings f, th, s, sh, and h; but only one of those sounds is allowed to occur before a nasal consonant (m or n) at the beginning of a word in English. The one that is permitted is s. Although none of the following are actual words:
*fmelp, *fnelp, *hmelp, *hnelp, *shmelp, *shnelp, *smelp, *snelp, *thmelp, *thnelp, *vmelp, *vnelp, *zmelp, *znelp
there is a difference: *smelp and *snelp may not exist, but they are at least possible words. There could be someone called Mr Snelp; the name does not (I think) exist, but it is perfectly English-sounding. And the fish called smelt could just as well have been called smelp. Words in English can begin with [sn]; but they cannot begin with, for example, [fn].
Now, having explained this, the phonetics/phonology instructor is sometimes faced with a smart student who says: "You said words don't begin with [fn]. But what about words like [fn]etics and [fn]onology?" At this point, a bad phonetics/phonology instructor, the sort you do not want to study with, will say: "Shut up; when I want your stupid observations I'll ask for them", or something along those lines.
But a good phonetics/phonology instructor, of the sort you might meet at the University of Edinburgh or U C Santa Cruz, will say something rather different.
Interesting things (they will say) can happen in rapid or casual connected speech, including complete loss of vowels in completely unstressed syllables. And thus words like phonetics are sometimes heard with essentially no pronounced vowel at all between the [f] sound (spelled ph) and the [n] sound. Yet the people who use words like phonetics and phonology also use related words like phonetician and phonotactics, and they always have a vowel after the [f] in those words — precisely because in those words the first syllable is not entirely unstressed.
And that illustrates rather nicely the difference between phonetics and phonology. The fact that phonetics has a vowel between the first two consonants is part of the phonology of English. The fact that you will sometimes hear it pronounced without that vowel is a fact about the phonetics of English.
So that was a good question. Well done. Thank you for asking it.
After that someone may ask about the status of words like schmuck and schnapps, borrowed from German and Yiddish. And that may lead to a bit of discussion about the curious possibility of words that are phonologically impossible but occur as loanwords anyway, which may lead to a consideration of whether a notion like "definitely possible in English" can be defined at all... But sometimes you have to re-assert control and return discussion to something a bit closer to the point about phonotactics that you were trying to teach in the first place.
There is a rather nice discussion of the phonotactics of English, and the question of how many syllables there are in the language, in Heidi Harley's book English Words. And if you want a serious scholarly study by a proper phonetician, see Lisa Davidson's paper in Phonetica. The abstract says:
Pretonic schwa elision in fast speech (e.g. potato > [pt]ato, demolish > [dm]olish) has been studied by both phonologists and phoneticians to understand how extralinguistic factors affect surface forms. Yet, both types of studies have major shortcomings. Phonological analyses attributing schwa elision to across-the-board segmental deletion have been based on researchers intuitions. Phonetic accounts proposing that elision is best characterized as gestural overlap have been restricted to very few sequence types. In this study, 28 different [#CəC-] sequences are examined to define appropriate acoustic criteria for elision, to establish whether elision is a deletion process or the endpoint of a continuum of increasing overlap, and to discover whether elision rates vary for individual speakers. Results suggest that the acoustic patterns for elision are consistent with an overlap account. Individual speakers differ as to whether they increase elision only at faster speech rates, or elide regardless of rate. Phonotactic legality per se does not affect elision rates, but speech rate may affect the phonological system by causing a modification of the standard timing relationships among gestures.
Note that figure 8 is incorrect in Lisa's article (I knew you'd notice). The correct figure is in this .TIF file.
Oh, one other thing. Please don't email me about fnord, OK? Don't make me be a bad person and tell you that when I want your stupid observations I'll ask for them.
Also don't mail me about snelp: I knew some damn fool would invent something to be named with one of my possible but nonexistent words so it would then exist, and sure enough, there actually is something called snelps: it's a real-time-strategy game that I didn't know about (thanks, Russell Aminzade, for the info); see this site. Sigh. All I wanted was a few nice little examples of words that were not on Paul Payack's stupid list. I didn't feel like Googling every single one, since there was nothing important about the specific examples chosen, and it was probably going to be ten tedious searches with zero hits except for several thousand misspellings etc. It's not easy being a linguoblogger. Sniff.
Some egg preceded every chicken
I just noticed (I was forced by a joint project to spend some time messing with the vile Microsoft Word) that if you type this:
Every chicken must logically have been preceded by an egg out of which it developed.
Microsoft Word's grammar checker will (if you have foolishly left it switched on) underline the sentence with a wavy green line, and if you run a Spelling and Grammar check to see why, it will recommend that you change this sentence (it's a passive, you see, and all passives are bad juju) to the following:
An egg out of which it developed must logically have preceded every chicken.
It will also recommend changing Every incarcerated prisoner in California is housed by some penal institution, which is true, to the "corrected" version Some penal institution houses every incarcerated prisoner in California, which is false.
Language Log's free online grammar-checking service hereby recommends that you do not follow Word's advice on such matters.
March 05, 2008
A virtual feminist elbowing his way in
A very intelligent further discussion of the Gelernter's mad rant can be found on Peter Seibel's blog A Billion Monkeys Can't Be Wrong. Amid some good discussion of the literary history, he notes a place where Gelernter fails to live out the true meaning of his creed:
Gelernter gives up the game a bit with this sentence: "Who can afford to allow a virtual feminist to elbow her way like a noisy drunk into that inner mental circle where all your faculties (such as they are) are laboring to produce decent prose?" Surely that should be "elbow his way".
Excellent point. The claim that he can be sex-neutral (the standard Strunk/White/Gelernter claim that CGEL discusses as "purportedly sex-neutral he) suggests that allow a virtual feminist to elbow his way into that inner mental circle should be fully grammatical, even if most feminists are women: it is not impossible for men to be feminists, and there is no definite referent here, so the sex of the referent is indeterminate. Yet the masculine-gender pronoun sounds very strange indeed — as it should, given the CGEL view that it can only refer to a male (and thus any engineer worth his salt really does bias discussion toward the view that engineers are always maile). Seibel's discussion of the point deserves to be read in full.
March 04, 2008
For National Grammar Day: Copy editors, we do not hate your guts!
I want to begin my celebration of National Grammar Day (goofy idea though it may be) by disabusing Mr John McIntyre, assistant managing editor for the copy desk at the Baltimore Sun, of his belief that "the linguists at Language Log ... hate copy editors' guts."
No, no, no, good heavens, no! Just about every writer at Language Log has experience with publishing books, and has benefited from the close and expert attention of copy editors in finding errors and inconsistencies, and accepted with gratitude frequent suggestions about removing unintended ambiguities or clumsiness in grammar. Does anyone really think that Rodney Huddleston and I could have completed our 1860-page grammar of English without being much indebted to the expert assistance of a dedicated Cambridge University Press copy editor? No. Copy editors are a blessing, and a necessity. And on the human side, Mr McIntyre in particular looks (in the photo on his blog) friendly and humorous, and I am certain we would like each other if we could just get together and have a drink together and talk grammar. Which perhaps we will. All of us here at Language Log Plaza recognize that John's mock warning of linguistic warfare breaking out in the streets today is written with tongue in cheek. Yes, I know I once wrote (out of sympathy with a man who was wrestling with some silly proposals for puristic alterations to the text of his book) a piece called "More timewasting garbage, another copy-editing moron"; but this is not about hating people's guts.
Copy editors in general are nice people playing a valuable role, but they do waste some of their time doing silly make-work things in the service of house style rules that should be dropped. And they can be wrong on grammatical topics. In the post about which and that cited above, where Mr McIntyre made the guts-hating remark, he is wrong from top to bottom about syntactic facts concerning relative clauses. Let me explain.
Mr McIntyre's thesis about which and that is quadripartite: he holds that
- the word which should be used only to introduce what CGEL calls supplementary relative clauses (the kind with the commas), and
- which should introduce all those supplementary relatives that have non-human head nouns; and
- that should be used only to introduce only those relative clauses of the kind that CGEL calls integrated relative clauses (the kind without the commas), and
- that should introduce all those integrated relatives that have non-human head nouns.
This is a recommendation that Henry Fowler made regarding relative clauses. It has never been uniformly followed by good writers in either Britain or America, and Fowler never thought for one moment that it had. It was a quixotic proposal for change. It had no hope of success. William Strunk did not observe the rule in his writing. (Jan Freeman of the Boston Sunday Globe discovered the astonishing fact is that E. B. White went through The Elements of Style in the middle 1950s and altered Strunk's text to conceal this. And I discovered within two minutes of examining White's own prose that White didn't follow (i) or (iv) either).
Parts of the quadripartite claim, though, are unexceptional: part (ii) and thus also part (iii) are overwhelmingly complied with by everyone: supplementary relatives introduced by that do turn up in prose and in speech every now and then (I catch one every few months, and they pass without remark, being too rare to attract copy editors' notice), but they are fantastically rare. That's fine with me, of course.
It is parts (i) and (iv) that are the bone of contention. American copy editors (including John McIntyre, it seems) waste company time "correcting" prose to make it comply in certain cases. They are completely misguided in doing so, and it makes me sad to see nice people forced to carry out tedious and pointless pseudo-work.
The problem with (i) and (iv) is that they are false claims about English syntax and no one can make them true by reiterating them.
Fronted prepositions Mr McIntyre would never even think of trying to follow his rule when a fronted preposition precedes the introducer of the relative clause. Thus he writes the shibboleths to which newspapers' in-house style guides are prone (where to which newspapers' in-house style guides are prone is an integrated relative clause), and not *the shibboleths to that newspapers' in-house style guides are prone, because the latter is completely ungrammatical. So much for whether (iv) is always followed: it isn't, not even by Mr McIntyre.
Ambiguity The same facts likewise dispose of the suggestion that what's at stake here is preventing ambiguity from arising between relative clauses of integrated and supplementary types. Where the head noun is non-human and there is a fronted preposition, both types of clause have to begin with Preposition + which. It's the commas that eliminate the ambiguity, not the choice of the wh-word that introduces the relative clause.
McIntyre's title But never mind the preposition cases, where the rule is impossible to follow; does McIntyre at least follow the rule when he could? Let's look at the title of the relevant post: "That which we dispute". It is a counterexample to his own claim. The which we dispute there is an integrated relative clause (no commas), and it has been introduced by which, quite properly, so that we don't get a visually annoying that that sequence: if his stuff were edited at Language Log Plaza and I "corrected" his title to That that we dispute, he'd be rightly furious. So much for whether he even follows his own rule when he could: he doesn't, because he's sensible. He chose correctly.
McIntyre's that example Now let's look at his examples. The first is from "Annie Get Your Gun": the phrase the girl that I marry. But it's completely irrelevant. It has a human head noun (girl), so choosing which would be out of the question: nobody writes *the girl which I marry, because the grammar requires that the wh-word should be who. And the girl who(m) I marry is not objected to by copy editors. (Whether they would typically insist on whom is not the point here; the point is that which is impossible.) Incidentally, this example again shows that ambiguity is not the issue: no comma, so who(m) I marry is an integrated relative clause.
McIntyre's which example His example for correct use of which is from "My Fair Lady": A man was made to help support his children,/ Which is the right and proper thing to do. But again it is not relevant, because the line beginning with which is one of those special supplementary relatives that doesn't have a noun antecedent at all: the understood antecedent is the clause to help support his children. That's what is claimed to be the right and proper thing to do. There is no integrated relative clause parallel to this: integrated relatives can never modify clauses the way this one is doing. Mr McIntyre is picking examples that are entirely irrelevant to illustrating the point he claims to want to support.
Non-defining integrated relatives Finally, he picks on the phrase the Homeland Security and Government Affairs Committee that has been investigating the government's response to Katrina, and claims that it is a grammatical mistake because the Homeland Security and Government Affairs Committee in question is unique. He thinks the wording "would suggest that there are multiple Government Affairs Committees and that we are here specifying the one investigating Katrina": because this is not so, he believes, this noun phrase cannot take an integrated relative clause. What he is pushing here is the view that integrated relatives always define or restrict. He is wrong: they don't. There is nothing wrong with sentences like After his wife died, he keenly missed the marital companionship that he had enjoyed for so many years. There are no multiple entities describable as companionships: there is just the wifely company he enjoyed, which is unique. Yet in this case the additional fact that he used to enjoy it can be expressed by an integrated relative clause. Notice also the ubiquitous cellphone chatter that annoys me so much on buses and trains: the constant chatter is unique, but there is nothing wrong with attaching an integrated relative clause.
This, in fact, is why CGEL didn't adopt the terms "restrictive relative clause" or "defining relative clause": it just isn't true that things line up so that integrated relatives always define or restrict, and supplementary relatives never do, and by their restrictiveness or lack of it ye shall know them. There are tendencies for them to be used that way, but one shouldn't take a simplistic view of those tendencies.
Main points So let me summarize a few points and conclude.
Integrated relative clauses beginning with which are fully grammatical and always have been.
Which is actually required in some cases, as Mr McIntyre's own excellent prose clearly shows.
Such uses of which do not contribute ambiguity to properly punctuated prose.
There is no reason for copy editors to alter an understandable sentence in which a competent author has selected which rather than that to begin an integrated relative clause (there seem to be rather subtle meaning differences, and it should surely be up to the writer to decide which shade of meaning to suggest).
It is in any case an insult to intelligent copy editors to imply that their job could be taken over by computer programs running simple substitution routines.
This is not an anti-copy-editor position. I'm saying copy editors are highly trained, intelligent people who couldn't do their job without great sensitivity to nuances of meaning and style. Mechanical which-hunting is not a good idea, and (as I have shown here) the reasoning with which some copy editors support it is unsound. For the most part, writers simply do not need to be policed over their choice of how to begin a relative clause, and that is why British copy editors normally pay no attention to the matter.
Mr McIntyre has many who will back him up in his preferences, of course. The first commenter on his post says, "John, this is one where I'll stand at your side to the death against those Language Loggers." (To the death! Are alternations between word choices in different types of relative clauses worth dying for?) But I have given some simple syntactic facts above that cannot reasonably be contested (the points about fronted prepositions, non-human head nouns, lack of ambiguity, and so on). I think copy editors would do well to work with linguists rather than pretend that it must be war between us. (And yes, of course, I should be careful not to spend too much time on humorous rants against timewasting garbage and copy-editing morons; except that this is Language Log, and I know that if I promised never to rant again you would be deeply disappointed.)
At the very least, let us pledge on this National Grammar Day that even if linguists can never make the copy editing profession believe that changing which to that is a superstitious behavior that should be beneath them, we can make it clear and plain that we do not hate any of the internal or external organs of the fine people who attempt with considerable success to keep up the quality level of printed prose. Copy editors are worthy souls, who should not be judged by the silliest things they do any more than linguists should. And we do not hate their guts.
March 03, 2008
Ornamental etymology
In an op-ed piece in the New York Times yesterday, Adam Freedman (Legal Lingo columnist for the New York Law Journal Magazine) takes on an exchange between Hillary Clinton and Barack Obama over whether Obama should be "rejecting" or (instead) "denouncing" Louis Farrakhan. Freedman observes that the two verbs are not interchangeable and shows how they work differently in the Farrakhan context. I have nothing much to add to this discussion, but my attention was caught by Freedman's making two digressions into etymology:
... in this context, "reject" implies an even more thorough rebuke, which is perhaps why Mr. Obama initially resisted the word. Reject derives from the Latin reicere, "to throw back." To reject something means to refuse to receive, accept or even recognize it. You hurl it back, literally or metaphorically.
I have nothing against etymologies; I find many of them fascinating. I sometimes digress in class to comment on an interesting bit of word history, like the pen- of penult and penultimate being originally the same element (meaning 'almost') as the pen- of peninsula: almost last, almost an island. But I don't think such excursions actually contribute content to the class, beyond possibly making it easier for students to remember the technical terms; what's important in this case is that being next to last -- syllable in a word, word in a phrase or sentence -- is sometimes important in the analysis of linguistic structure, and that it's useful (though not strictly necessary) to have a short technical term with this meaning. (In most cases, it's actually necessary to have a technical term, because there's no ordinary-language counterpart.)
Back to Freedman. He characterizes the meaning of denounce as 'declare a person or thing to be wicked or evil' and the meaning of reject as 'refuse to receive, accept, or recognize'. These definitions, which are very close to the ones in good dictionaries of modern English, are entirely adequate for Freedman's purposes in analyzing the Clinton-Obama exchange. The etymologies contribute nothing; if you're a serious adherent to Omit Needless Words, or if you're just writing to space limitations, the etymologies should be excised. So why are they there?
They're mostly ornamental, I think, though Freedman might believe that they contribute some support to his claims about the meanings of the verbs. But those claims stand on their own as accounts of how these words are used. Anything else is just our old acquaintance the Etymological Fallacy.
Tautology of the day
I just recently bought a new CD case. Here it is:

The manufacturers helpfully describe its key feature on the packaging:

I just had to buy it, when I saw what it could do!
Update: Mike Williams writes in:I've noticed this same packaging label myself. I wondered if anyone else in the blogosphere had also. A quick Google indicates that this company's camera case product packaging also says "holds all digital cameras small enough to fit".http://sharppointythings.blogpeoria.com/2007/11/26/good-to-know-raquel/
Someone at that company has a cute sense of humor!
Texting shiv
I sympathize with these gentlemen -- for my own history as a developer of digital bowdlerization methods, see "I18N invective" (7/25/2007):
[Hat tip: Kerim Friedman]
Someone's word order is wrong on the internet
A couple of weeks ago, xkcd explained the intellectual dynamics of networked discourse:

But according to a comment by Wulak at the Volokh Conspiracy:
It should say:
SOMEONE ON THE INTERNET IS WRONG.
Ted F mock-agreed:
Wulak is correct. The strip steps on its punchline. I am going to write an angry email to the author expressing my dismay.
When the strip first came out, I noticed Randall Monroe's word-order choice, but my reaction was the opposite. I thought that he got it exactly right, though at first I couldn't figure out exactly why.
It's true that if you thought that "on the internet" was meant as a reduced relative clause, then you'd be reluctant to see it extraposed to the end of the sentence. You might describe an inaccurate gas bill as (a), but not as (b):
(a) Someone from the gas company is mistaken.
(b) ?Someone is mistaken from the gas company.
On the other hand, if "on the internet" is a locative adverbial phrase, then it would be normal to put it at the end of the sentence, as in "It's raining in Paris". So both word-orders are perfectly grammatical, and since the comment's crucial point seems to be the wrongness, it would make sense to pick the order where wrong is final. I did an informal poll of acquaintances -- without showing them the cartoon or explaining the context -- and most of them agreed with Wulak in picking "Someone on the internet is wrong".
But that word order misses the poetic resonance with "Something is wrong".
Consider the following table of Google hit counts:
| something is __ | 4,050,000 |
|
| someone is __ | 275,000 |
"Something is wrong" implies that in principle, everything ought to be right. Or at least, right enough. The sense of wrong involved is something like the OED's sense 6: "Not right or satisfactory in state or order; in unsatisfactory or bad condition; amiss".
Consider these two lines from Ted Hughes' poem Women:
3 A hushed animation, sombre and uneasy.
4 Something is wrong and everybody is aware of it.
Substituting "someone is wrong" into that line turns an ordinary example of social discomfort into a curious joke. When people are wrong, it's generally in OED sense 5.b "Not in consonance with facts or truth; incorrect, false, mistaken." A diversity of opinions, even about matters of fact, is normal, and so in that sense, someone is pretty much always wrong. This is normally not something that has to be put right before you can rest easy.
And that's why "Someone is wrong on the internet" is funnier than "Someone on the internet is wrong."
[Jonathan Weinberg writes:
I agree with you entirely, but I want to make more explicit a point I think is already implicit in your post: What's funny about the sentence is the delayed recognition. That is, we read it as "Someone is wrong [huh? so what? people are wrong all the time] on the Internet [oh, on the Internet! well, yeah, I guess that is a different story. If someone is wrong *on the Internet*, it needs to be put right immediately. I can relate to that.]
]
March 02, 2008
Lying feminist ideologues wreck English, says Yale prof
The danger when encountering a misogynist prescriptive grammar rant as extreme as the one just published by David Gelernter in the Weekly Standard (vol. 13 no. 24, 03/03/2008) is that one might get as angry and fired up and beyond reason as he is. That would be a pity. I will try to remain calm (it's not exactly my forte, though I have occasionally tried it). The right reaction for this one is sadness rather than indignation. Gelernter is a distinguished computer scientist at Yale; yet here he makes a complete fool of himself.
His claims are apocalyptic. Although English "used to belong to all its speakers and readers and writers" it has now been taken over by "arrogant ideologues" determined "to defend the borders of the New Feminist state." A major "victory of propaganda over common sense" looms: "We have allowed ideologues to pocket a priceless property and walk away with it." The language is on the brink of being lost, because although the "prime rule of writing is to keep it simple, concrete, concise", today "virtually the whole educational establishment teaches the opposite". This is the mild part. Soon he gets more seriously worked up, calling his opponents "style-smashers" and (I'm not kidding) "language rapists", and claiming that "they were lying and knew it" when they did what they did.
What, then, is the terrible thing that the style-smashers have done? The following is (and I stress this) a complete list of all the facts about English usage he cites:
- Some writers now use either he or she, or singular they, or purportedly sex-neutral she, instead of purportedly sex-neutral he, to refer back to generic or quantified human antecedents that are not specifically marked as masculine.
- Some people recommend the words chairperson, humankind, and firefighter over chairman, mankind, and fireman.
- Some try to avoid using the phrases great man when speaking of a great person, or using brotherhood when making reference to fellow-feeling between human beings.
That's it; we're done. That is the totality of the carnage to which he directs our attention, the sum of all his evidence that we have "allowed ideologues to wreck the English language".
Gelernter insists on the beauty and clarity of "Shakespeare's most perfect phrases", calling them "miraculously simple and terse"; and of course he raves about E. B. White ("our greatest modern source of the purest, freshest, clearest, most bracing English, straight from a magic spring that bubbled for him alone"), and about Strunk and White's The Elements of Style, "justly revered as the best thing of its kind", where it is claimed that purported sex-neutral he ("a student who lost his textbook") "has no pejorative connotations; it is never incorrect." White's claim seems to me quite untrue. Consider how weird this sounds:
Is it your brother or your sister who can hold his breath for four minutes?
Why would it sound so weird if forms of the pronoun he could be sex-neutral? They can't. He is purely masculine in reference. The claim that it can be sex-neutral is not in accord with the facts. Plenty of people have noted and illustrated this. Cathy Kessel points out to me that when William Safire advocated saying Everyone should watch his pronoun agreement, one C. Badendyck wrote a letter to the editor of the New York Times Magazine suggesting this example for consideration:
The average American needs the small routines of getting ready for work. As he shaves or blow-dries his hair or pulls on his panty hose, he is easing himself by small stages into the demands of the day.
(This is quoted in pp. 45-46 of the Handbook of Nonsexist Writing [2nd edition, Harpercollins, 1988] by Casey Miller and Kate Swift, two authors whom Gelernter would hate.) That last his doesn't sound too good, does it? Yet clearly the average American is without any definite gender semantically. The problem is that forms of the masculine pronoun, like garments such as pantyhose, do have definite gender associations. Badendyck is right, Safire is wrong, and Gelernter is wrong.
Gelernter huffs and puffs a lot about the use of he or she, but this is only a prelude to something more serious: a furious condemnation of singular antecedents for they ("a student who lost their textbook"). In his telling of the story, the feminist language terrorists weren't content with imposing he or she on us, a phrase that is merely clumsy; worse was to come when grammar itself "collapsed in a heap after agreement between subject and pronoun was declared to be optional", i.e., they was permitted to have singular antecedents.
But his ignorance of the history of English literature on this point is breathtaking. It is quite clear that he has no idea Shakespeare used they with singular antecedents (I discussed a couple of examples here).
Gelernter also specifically singles out Austen for praise: "The young Jane Austen is praised by her descendants for having written "pure simple English." He obviously is not aware that Jane Austen is famous for her high frequency of use of of singular-anteceded they (Henry Churchyard has a list of examples here).
Gelernter thinks singular they was invented by post-1970 feminist "ideologues", rather than a use of pronouns having a continuous history going back as far as a thousand years. One might think it remarkable that someone this ignorant of the history and structure of English would nonetheless presume to pontificate, without having checked anything. But not if you read Language Log. We have noted many times the tendency to move straight to high dudgeon, skipping right over the stage where you check the reference books to make sure you have something to be in high dudgeon about. To take a random example, when Cullen Murphy accused three word-sense usages of being modern illiteratisms, Mark Liberman showed that in fact all three were the original meanings from long ago. And then a couple of months later Mark found John Powers had made an exactly analogous mistake with three other words. People just don't look in reference books when it comes to language; they seem to think their status as writers combined with their emotion of anger gives them all the standing they need.
No, it is not Gelernter's high indignation-to-expertise ratio that amazes me, but his unbelievable level of anger. The "language rapists" have deliberately destroyed our native tongue and people's ability to write it, he claims: "The well-aimed torpedo of Feminist English has sunk the whole process of teaching students to write... we used to expect every educated citizen to write decently--and that goal is out the window." Education has been ruined: "we graduate class after class of young Americans who will never be able to write down their thoughts effectively". The whole United States has been ruined: "the country is filling up gradually with people who have been reared on ugly, childish writing and will never expect anything else".
I'd like to assume that intellectual content can speak for itself rather than having to be diagnosed ad hominem as a symptom of broader personal character, but I found it hard to read Gelernter without reflecting on the fact that in 1993 he became one of the victims of a deranged terrorist, 'Unabomber' Ted Kaczynski; he was badly injured by a letter bomb and suffered permanent damage to his right hand and eye. I found myself wondering whether his very understandable rage against protesters who favor violence was bubbling up and infecting his attitude toward women, progressivism, political correctness, students, everything.
Some kind of explanation is needed, surely. The entire linguistic and educational system built up by a nation of 300 million people cannot be in danger of being flushed down the toilet because of a commonplace, centuries-old practice of occasionally and optionally using a plural-reference pronoun with a morphosyntactically singular quantified or indefinite-reference antecedent, can it?
[Hat tip: Thanks to Paul Postal for pointing me to the article.]
Scrupulously avoiding sigma
The cover story in today's NYT Magazine is Elizabeth Weil, "Teaching Boys and Girls Separately". Unsurprisingly, it features the ideas of Leonard Sax, a tireless advocate for single-sex education. Weil's story starts like this:
On an unseasonably cold day last November in Foley, Ala., Colby Royster and Michael Peterson, two students in William Bender's fourth-grade public-school class, informed me that the class corn snake could eat a rat faster than the class boa constrictor. Bender teaches 26 fourth graders, all boys. Down the hall and around the corner, Michelle Gay teaches 26 fourth-grade girls. The boys like being on their own, they say, because girls don't appreciate their jokes and think boys are too messy, and are also scared of snakes. The walls of the boys' classroom are painted blue, the light bulbs emit a cool white light and the thermostat is set to 69 degrees. In the girls' room, by contrast, the walls are yellow, the light bulbs emit a warm yellow light and the temperature is kept six degrees warmer, as per the instructions of Leonard Sax, a family physician turned author and advocate who this May will quit his medical practice to devote himself full time to promoting single-sex public education.
Because of efforts by Dr. Sax and others, the traditional boy/girl issues like messiness, snakes, and different taste in jokes are now bolstered by starkly-posed findings from psychophysics and neuroscience. These scientific arguments for sex-segregated education often seem to be careless and misleading at best -- for a sample, see "Are men emotional children?" (6/24/2006), "Leonard Sax on hearing" (8/22/2006), "Girls and boys and classroom noise" (9/9/2006).
I'm not going to repeat the debunking exercise this morning (though Dr. Sax has sent me several newer studies about sex differences in hearing and in vision, which are equally unable to support the conclusions that he wants to draw from them). Instead, I'd like to applaud Elizabeth Weil for including in her article a helpful quote from Jay Giedd about the comparison of sampled distributions:
Scans of boys' and girls' brains over time also show they develop differently. Analyzing data from the largest pediatric neuro-imaging study to date — 829 scans from 387 subjects ages 3 to 27 — researchers from the National Institute of Mental Health found that total cerebral volume peaks at 10.5 years in girls, four years earlier than in boys. Cortical and subcortical gray-matter trajectories peak one to two years earlier in girls as well. This may sound very significant, but researchers claim it means nothing for educators, or at least nothing yet. "Differences in brain size between males and females should not be interpreted as implying any sort of functional advantage or disadvantage," the N.I.M.H. paper concludes. Not one to be deterred, Sax invited Jay Giedd, chief of brain imaging at the Child Psychiatry Branch at N.I.M.H., to give the keynote address at his N.A.S.S.P.E. conference in 2007. Giedd spoke for 90 minutes, but made no comments on schooling at all.
One reason for this, Giedd says, is that when it comes to education, gender is a pretty crude tool for sorting minds. Giedd puts the research on brain differences in perspective by using the analogy of height. "On both the brain imaging and the psychological testing, the biggest differences we see between boys and girls are about one standard deviation. Height differences between boys and girls are two standard deviations." Giedd suggests a thought experiment: Imagine trying to assign a population of students to the boys' and girls' locker rooms based solely on height. As boys tend to be taller than girls, one would assign the tallest 50 percent of the students to the boys' locker room and the shortest 50 percent of the students to the girls' locker room. What would happen? While you'd end up with a better-than-random sort, the results would be abysmal, with unacceptably large percentages of students in the wrong place. Giedd suggests the same is true when educators use gender alone to assign educational experiences for kids. Yes, you'll get more students who favor cooperative learning in the girls' room, and more students who enjoy competitive learning in the boys', but you won't do very well. Says Giedd, "There are just too many exceptions to the rule." [emphasis added]
There's only one problem with Giedd's excellent example: the cited height difference is not really true for kids in most of the age range under discussion, as any parent of a child in the first through tenth grades will recognize. But looking a little more closely may help to underline his point. The NIST Anthrokids database gives height (in centimeters) from a sample of around 100-140 females and males in each of 16 age ranges, measured in 1977:
| Male mean | Male SD | Female mean | Female SD | Difference in cm (male - female) |
Effect size (difference divided by pooled SD) |
|
| 2.0-3.5 | ||||||
| 3.4-4.5 | ||||||
| 4.5-5.5 | ||||||
| 5.5-6.5 | ||||||
| 6.5-7.5 | ||||||
| 7.5-8.5 | ||||||
| 8.5-9.5 | ||||||
| 9.5-10.5 | ||||||
| 10.5-11.5 | ||||||
| 11.5-12.5 | ||||||
| 12.5-13.5 | ||||||
| 13.5-14.5 | ||||||
| 14.5-15.5 | ||||||
| 15.5-16.5 | ||||||
| 16.5-17.5 | ||||||
| 17.5-19.0 |
So among the 17- to 19-year-olds, the males really are two standard deviations taller. But up through age 16.5, at least for kids like those in the NIST sample, assigning locker rooms on the basis of height would be even closer to random than Dr. Giedd suggested.
The term "standard deviation" comes up more often in the New York Times than you might think. But it's rare -- maybe unprecedented -- for one article in the New York Times Magazine to use it three times in a meaningful way, as Weil's piece does. Two of the instances are in the quotation from Dr. Giedd given above. The third one is in a quote from me:
Sax initially built his argument that girls hear better than boys on two papers published in 1959 and 1963 by a psychologist named John Corso. Mark Liberman, a linguistics professor at the University of Pennsylvania, has spent a fair amount of energy examining the original research behind Saxs claims. In Corso's 1959 study, for example, Corso didnt look at children; he looked at adults. And he found only between one-quarter and one-half of a standard deviation in male and female hearing thresholds. What this means, Liberman says, is that if you choose a man and a woman at random, the chances are about 6 in 10 that the woman's hearing will be more sensitive and about 4 in 10 that the man's hearing will be more sensitive.
A surprisingly large fraction of the misapplications of science to public policy arise because most people in our society never learn simple techniques for thinking about differences in sampled distributions, and therefore have to fall back on pop-platonic ideas about properties of group archetypes. See here and here for some discussion of a different case:
The rhetoric of science journalism -- and sometimes the rhetoric of science -- all too easily engages a sort of pop-Platonism that seems to be deeply connected to the way that we think about natural kinds. As a result, small (but statistically reliable) differences in group distributions are seen as essential properties of the groups themselves, and therefore of all the individuals that make them up. Or at least, all the normal or typical individuals. Intellectual and social mischief often ensues.
If we look back at the uses of the term "standard deviation" in the NYT index, we find that most of the examples are presented as a species of arcane financial magic ("Historical volatility bears him out: he says that since 1993 the annualized standard deviation of returns, a customary measure of volatility, has been 22 to 23 percent in emerging markets, versus 13 to 14 percent for the Standard & Poor's 500-stock index.") or oddly-explained scientific jargon ("To physicists, the gold standard for a discovery is what they call a "5-sigma" bump, where sigma is a measure of bumpiness known as a standard deviation.").
In neither case is any understanding of the properties of distributions invoked. And in one telling case, the term "standard deviation" is used as an symbol of incomprehensibility (Anastasia Rubis, "Just your standard deviation", 3/20/2005):
As I skipped around in The Princeton Review, scrupulously avoiding permutations and standard deviation, certain synapses began firing for the first time in a quarter-century, even if the connections were as stiff as morning joints.
This is "a not-so-happy-housewife more than 20 years out of college, [who] had resolved to apply to graduate school for a teaching degree".
It's not a new idea to base legal, educational, or social prescriptions on scientific findings. It's not a bad idea, either, unless such arguments are based on bad science, or on good science badly applied. But I'm afraid that in today's educational policy debates -- and not just about segregation of the sexes -- the density of bad or misrepresented science is high and rising. In self-defense, our society needs to persuade people like Anastasia Rubis that standard deviations should not be so scrupulously avoided.
March 01, 2008
lytdybr
I just discovered a kind of alphabet-to-alphabet encoding/shorthand/slang - I don't know what to call it - that I had never been aware of before. I have a Live Journal account where my "friends" are mainly young Russian linguists, so most of the posts are in Russian, in the Cyrillic alphabet, but user-names, tags, etc., are all in the Roman alphabet. There was one tag that I had often seen in one particular user's posts, "lytdybr", and I had just guessed that it was some private code word of her own (I even invented a romantic etymology for it as an abbreviation starting with "love you".) But then last week I suddenly saw the same tag on a post by another young Russian linguist, and realized that it wasn't just one person's private tag.
So I googled it and discovered what it really is: it's how the Russian word дневник, dnevnik 'diary', comes out if you're typing on a QWERTY keyboard with the keystrokes you would use on a Cyrillic keyboard. There's a Wiktionary entry about it; and I didn't even know such a category of -- of what? I guess I'll call it slang -- existed.
So on my LJ, I asked if there were any other examples, and it generated some interesting discussion. One person told me about usus for гыгы (gygy 'laughter' -- think hee-hee); someone remarked that the "usus" of usus is fun in itself. Another example is ghbdtn, which is привет, privet 'hi' or 'greetings', common in instant messaging, with ICQ, Google Talk, etc. [Update: I had misunderstood; this one occurs is common in instant messaging by accident, but isn't used intentionally. Thanks, "alexkon".]
One common example goes in the other direction: Russians typing in Cyrillic often use З.Ы. for P.S. so as not to have to switch out of the Russian keyboard. And one person told me they even sometimes use Ж-) instead of : -) for the same reason!
Here's one I was informed of that has an extra layer: there is a character named Фрейби Freybi (an Englishman) in a novel by Akunin, Freyby being a QWERTY version of Акунин Akunin.
As for the tag I first noticed, lytdybr, there were several ideas about who had invented it, with the consensus that it had been invented more than once. One of my students commented that lytdybr, even sometimes transliterated back to лытдыбр, has become a word of its own, with a meaning more specific than the original 'diary'.
It is often (but not always, there is a neutral meaning too) used to tag posts in blogs that are nothing more than boring retelling of author's life. For example, something like "Just eaten some apples. Cool." is a typical lytdybr in its negative meaning.
Cool.
Listening to Prozac, hearing effect sizes
As I've observed too often, it's hard for most people to talk or to think about differences in sampled distributions. Imagine, then, how hard it is to deal with models of sampled distributions of differences in sampled distributions. A recent case of this type seems to have reduced the American journalistic establishment to uncharacteristic silence.
The topic is a study by Irving Kirsch et al. that came out in PLoS Medicine on Monday, "Initial Severity and Antidepressant Benefits: A Meta-Analysis of Data Submitted to the Food and Drug Administration".
The British press gave this quite a bit of play: "Anti-depressants 'of little use'", BBC News; "Prozac, used by 40m people, does not work say scientists", The Guardian; "Antidepressant drugs don't work -- official study", The Independent; "Depression drugs don't work, finds data review", The Times; etc.
The relative lack of American coverage was noted by Kevin Drum at Washington Monthly ("Talking back to Prozac", 2/25/2008):
... what really drew my attention was the range of news outlets that reported this news. According to Google News, here they are: the Guardian, the Independent, the London Times, the Telegraph, the BBC, Sky News, the Evening Standard, the Herald, the Financial Times, and the Daily Mail. In fact, it's getting big play from most of these folks, including screaming front page treatment from some.
So what's the deal? Why is this huge news in Britain, where most of the stories are making great hay out of the amount of taxpayer money the NHS is squandering on these drugs, and completely ignored here in the U.S.?
There have since been a few American news reports. One was on Fox News, "Study: Antidepressants May Not Work in All Patients"; another was Steven Reinberg, "Only Severely Depressed Benefit From Antidepressants: Study", WaPo, 2/26/2008; and another was Laura Blue, "Antidepressants hardly help", Time Magazine, 2/26/2008. As far as I can tell, neither the NYT nor the AP have picked up the story at all.
Kevin seems to be on to something: the American media may not have "completely ignored" the study, in the end, but the American coverage has been not only smaller and later but also softer. The Fox headline was especially timid: "Antidepressants May Not Work in All Patients", and the lede was just as cautious:
Researchers from various U.S., U.K. and Canadian universities found that some patients taking antidepressants believe the drugs are working for them, but many times it is only a placebo effect.
The Fox story attributed its information to Sky News, a Murdoch TV outlet in the UK, rather than to the original study. But the Sky News coverage had a very different tone: "Depressed? Why The Pills Won't Help"; "Study Casts Doubt On Antidepressants" (lede: "Antidepressants are no more effective than dummy pills in most patients, researchers have found.")
And the coverage in the Times, also owned by Murdoch was even more baldly negative: "Depression drugs don't work".
I've waited a few days for the American coverage to catch up, without seeing much change. But this being Language Log, not Journalism Log, nor for that matter Psychiatry Log, what drew my professional attention to this case was the variable use of linguistic devices to present -- or misrepresent -- the original paper. Journalists are faced with the need to talk about the comparison of sampled distributions -- or worse, a model of sampled distributions of comparisons of sampled distributions -- while being unable to talk about models and distributions, instead being limited to generic propositions with a few standard quantifiers and modals.
Some writers got tangled up in sentences that mean very little, and certainly don't describe the results of the Kirsch et al. meta-analysis accurately:
some patients taking antidepressants believe the drugs are working for them, but many times it is only a placebo effect
not every antidepressant works for every patient
anti-depressants may not work in all patients
Other produced statements that are clear and contentful, but unfortunately are also false:
Four of the most commonly prescribed antidepressants, including Prozac, work no better than placebo sugar pills to help mild to moderate depression
They found that patients felt better but those on placebos improved as much as those on the drugs.
The new generation anti-depressants had no more effect than a dummy pill for people with mild or moderate depression.
Contrary to one's natural suspicion in such cases, the more baldly negative descriptions are not in this case more accurate. One of the most accurate presentations seems to me to be Laura Blue's story in Time Magazine ("Antidepressants hardly help", 2/26/2008):
There are really two issues at the heart of the controversy. One is the difference between "statistical significance" — a measure of whether the drug's effects are reliable, and that patient improvement is not just due to chance — and "clinical significance," whether those effects actually are big enough to make a difference in the life of a patient. The researchers behind this new paper did find that SSRI drugs have a statistically significant impact for most groups of patients: that is, there was some measurable impact on depression compared to the placebo effect. "But a very tiny effect may not have a meaningful difference in a person's life," says Irving Kirsch, lead author on the paper and a professor of psychology at the University of Hull in England. As it happens, only for the most severely depressed patients did that measurable difference meet a U.K. standard for clinical relevance — and that was mostly because the very depressed did not respond as much to placebos. The drug trials showed SSRI patients improved, on average, by 1.8 points on the Hamilton Depression Rating Scale, a common tool to rate symptoms such as low mood, insomnia, and lack of appetite. The U.K. authorities use a drug-placebo difference of three points to determine clinical significance.
The more troubling question concerns what kind of data is appropriate for analyzing a drug's efficacy. The companies are correct in claiming there is far more data available on SSRI drugs now than there was 10 or 20 years ago. But Kirsch maintains that the results he and colleagues reviewed make up "the only data set we have that is not biased." He points out that currently, researchers are not compelled to produce all results to an independent body once the drugs have been approved; but until they are, they must hand over all data. For that reason, while the PLoS Medicine paper data may not be perfect, it may still be among the best we've got.
Contrast Sarah Boseley, "Prozac, used by 40m people, does not work say scientists", The Guardian, 2./26/2008
Prozac, the bestselling antidepressant taken by 40 million people worldwide, does not work and nor do similar drugs in the same class, according to a major review released today.
The study examined all available data on the drugs, including results from clinical trials that the manufacturers chose not to publish at the time. The trials compared the effect on patients taking the drugs with those given a placebo or sugar pill.
When all the data was pulled together, it appeared that patients had improved - but those on placebo improved just as much as those on the drugs. [emphasis added]
Apparently in an attempt to make the point clear and strong, the Guardian's story crosses the line into plain falsehood, and so do the stories in several other major UK papers. Thus David Rose, "Depression drugs don't work, finds data review", Times, 2/26/2008:
The new generation anti-depressants had no more effect than a dummy pill for people with mild or moderate depression.
This case study in the public rhetoric of statistics is interesting and important enough to merit a closer look, so let's go back to the original article. Its authors used a Freedom of Information Act request to pry loose the results of "all clinical trials submitted to the US Food and Drug Administration (FDA) for the licensing of the four new-generation antidepressants for which full datasets were available" (fluoxetine, venlafaxine, nefazodone, and paroxetine). Significant parts of these datasets had not previously been published.
The final list comprised results from 35 studies, with the relevant numbers listed in their Table 1. Each row is a different study. Columns 3 and 4 are the average initial score on the "HRSD" (the Hamilton Rating Scale for Depression) and the average change in HRSD for patients in that study who got the drug; columns 8 and 9 are the average initial HRSD score and the average change in HRSD for the patients in that study who got the placebo ("sugar pill" or "dummy pill").
If we plot column 4 (average HRSD change in patients who got the drug) against column 9 (average HRSD change in patients who got the placebo), it's obvious to the eye that the drugs are having an effect different from the placebo. (Each red x is one clinical trial, with the average HRSD improvement in the drug group on the x axis, and the average HRSD improvement in the placebo group on the y axis.)
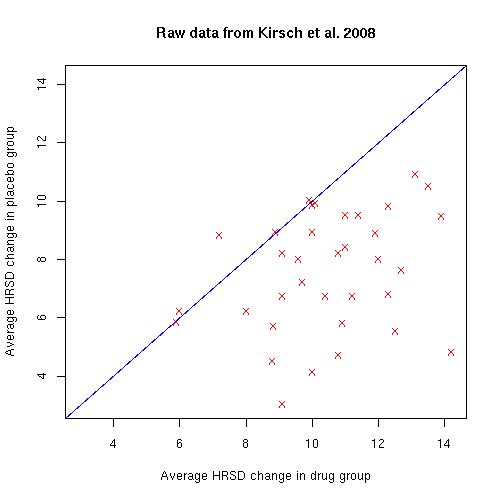
You can see that the placebo (or perhaps just the passage of time) is also having a positive effect on the HRSD values. But nearly all of the red x's are on the lower-right side of the blue line, indicating that in 32 out of 35 trials, the drug beat the placebo. This surely did not happen by chance. It's just not true that "those on placebo improved just as much as those on the drugs". In these studies, the drugs almost always had a greater positive effect than the placebo did.
The question is, how significant is the difference? And we're not talking about "statistical significance" -- we're interested in the "clinical significance" of the drug-minus-placebo effect. The definition of "clinical significance", which Kirsch et al. take from the UK's National Institute for Health and Clinical Excellence (NICE), depends not just on the average difference between drug and placebo groups, but also on the distributions of those effects. Specifically, the average measured outcomes are normalized by (i.e. divided by) the standard deviation of the measured outcomes.
(This is a common way to evaluate the "effect size" of a difference between two distributions -- there's a good explanation here, and an example here that may help to explain why this is a reasonable sort of thing to do.)
For example, in one of the Prozac studies (line 5 of Table 1), there were 297 people in the "drug" group, who began the study with an average HRSD score of 24.3, and ended with an average HRSD score of 15.48, for an average change of 8.82. There were 48 people in the "placebo" group, who began with an average HRSD of 24.3, and ended with an average of 18.61, for an average change of 5.69.
But these are the average results -- of course there was a great deal of individual variation. So it makes sense to divide the average change in HRSD score by the standard deviation of the change in HRSD score, producing what the authors call a "standardized mean difference".
If we do this in the cited case, then the effect size for the drug group is d=1.13, which is quite a large effect. But the effect size for the placebo group is d=0.72, which is also very respectable. And the difference in effect sizes between drug and placebo is d=0.41, which just misses the d=0.50 level that the British National Institute for Health and Clinical Excellence (NICE) has suggested should be the standard threshold for "clinical significance".
If we re-plot all the data using the d values rather than the change values, we get this:
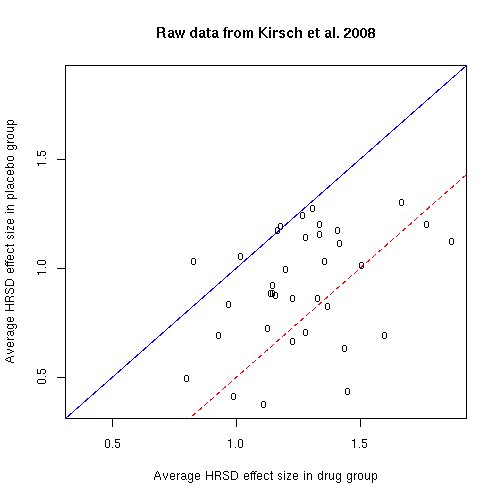
Of course, nearly all of the studies are still on the side of the blue line that indicates that the drug beat the placebo. However, only 10 of the 35 studies are on lower-right-hand side of the dashed red line, marking the NICE d=0.5 threshold for clinical significance.
Kirsch et al. go beyond this, to model the effect size as a function of the average initial HRSD score of patients in the study. I've reproduced their Figure 2, "Mean Standardized Improvement as a Function of Initial Severity and Treatment Group".
There are two points plotted for each trial: a red triangle for the "drug" group and a tan circle for the "placebo" group. The horizontal axis is the average initial HRSD score of the patients in the trial. The vertical axis is the improvement, measured in terms of effect size, i.e. "standardized mean difference (d), which divides change by the standard deviation of the change score SDC". The size of the plotted points represents their weight in the regression analysis (which I believe depends on the width of the error bars for the effect size estimates).
The solid red and dashed blue lines are curves fit to the data points, and the green region is the area where (according to the models) the "comparisons of drug versus placebo reach the NICE clinical significance criterion of d = 0.50".

{kind=link}
But now we're talking about fitting a statistical model to the distribution across studies of effect sizes -- a measure of the difference between the distributions of outcomes in the "drug" and "placebo" groups -- as a function of initial severity. And there's no easy way to use the resources of ordinary non-statistician's English -- reference to groups, plurals, numbers and quantifiers like "most" and "some", negatives, modals like "may" -- to explain what's going on.
Where's Benjamin Lee Whorf when you need him? Seriously, linguistic anthropologists interested in language, thought and reality shouldn't be wasting their time with Eskimo words for snow. They should be investigating the way that different groups in our own culture describe differences in distributions.
[Update 3/15/2008 -- Peter Michael Gerdes writes:
I just wanted to point out that while the recent meta-analysis by Kirsch et. all about antidepressants only directly challenges the size of the effect it it embedded in a larger debate about whether these drugs are effective at all. As Kirsch and others have pointed out in prior papers a large fraction of patients and doctors are able to break the blind in these studies because the drugs have side effects the placebo lacks. In fact one study (which I can't remember the site for) suggested that the efficacy of the drugs was strongly correlated with the extent of side effects which at least shows that unblinding is a plausible explanation and other studies with older antidepressants have suggested that active placebos tend to be more effective than inactive ones.
I don't disagree with what you said in your post. If anything this is another point the media didn't cover very well. However, since you posted on the subject I thought you might want to know about this point. Anyway if you are interested I included some links to journal articles and comments by the involved scientists in my post on the subject, " Ghosts, UFOs, Yeti and Antidepressants?" (scroll down to the bottom for the references) .
Another relevant link is the editorial in Nature, " No More Scavenger Hunts", 3/6/2008. ]