March 31, 2005
Google, champing at the bit
Nathan Vaillette reports in e-mail on 3/31/05, re my posting "Chomping
at the font", that...
- google.de asks
Meinten Sie: "camping at the bit"
- google.fr suggests
Essayez avec cette orthographe : "chomping at the bit"
- google.es opines
Quizas quiso decir "champaign at the bit"
- google.it theorizes
Forse cercavi: "champion at the bit"
However, google.com is willing to believe that's what you mean.
"Champaign"? As in Champaign-Urbana? I was hoping for champagne, at least from google.fr. Meanwhile, in Italy, it seems, we are the champions.
[And now (4/1/05) the report from Finland: Pekka Karjalainen e-mails to say that (unsurprisingly, to me, anyway) neither google.fi nor google.se offered anything at all for the odd "chomping at the font", but when he tried google.de, he got "chomping at the front". German Google seems willing to give most anything a try.]
zwicky at-sign csli period stanford period edu
Absolutely is totally not definitely
I'm a big fan of dictionaries, but sometimes they let you down badly. Here's an example: a systematic difference between absolutely and definitely that is missed by all the English dictionaries I've checked.
According to the American Heritage Dictionary, absolutely means "Definitely and and completely; unquestionably". The AHD doesn't give definitely a separate entry, but (the relevant sense of) definite is given as as "Indisputable; certain". Merriam-Webster's unabridged (3rd edition) says that definitely means "distinctly, unmistakably, positively" while absolutely means "independently, unconditionally, entirely, positively". The OED gives "Without doubt or condition" as the basic (relevant) sense of absolutely, and "In a definite manner; determinately, precisely" as the meaning of definitely. Encarta defines absolutely as "totally", and definitely as "certainly; finally and unchangeably; exactly; clearly; absolutely".
I don't see any way predict from these entries that writers on the web are 198 times more likely to "absolutely adore" something than to "definitely adore" it, while they are 97 times more likely to "definitely prefer" something than to "absolutely prefer" it. Details by Google (in all the tables in this post, the words heading the colums precede the words or word sequences labelling the rows: thus the first entry in the second row gives 289,000 as the count returned for the query {"absolutely adore|adores|adored"}):
| absolutely | definitely | absolutely/definitely ratio | |
| overall | 34.9M | 29.3M | |
| adore|adores|adored | 289K | 1.46K | 198/1 |
| love|loves|loved | 905K | 51K | 18/1 |
| like|likes|liked | 16.2K | 158K | 1/10 |
| prefer|prefers|preferred | 644 | 62.6K | 1/97 |
The fact that love and like grade in between adore and prefer suggests that these are not random lexical associations, but rather reflect some sytematic difference in the emotional or attitudinal loading of the terms. This idea is confirmed if we look at similar counts and ratios for verbs expressing negative attitudes. Netizens are 179 times more likely to "absolutely abhor" something than to "definitely abhor" it, while they are 3 times more likely to "definitely dislike" something than to "absolutely dislike" it:
| absolutely | definitely | absolutely/definitely ratio | |
| overall | 34.9M | 29.3M | |
| abhor|abhors|abhorred | 7.15K | 40 | 179/1 |
| loathe|loathes|loathed | 14.7K | 91 | 162/1 |
| despise|despises|despised | 21.3K | 242 | 88/1 |
| hate|hates|hated | 185K | 5.04K | 38/1 |
| detest|detests|detested | 14K | 370 | 38/1 |
| can't stand | 4.38K | 305 | 14/1 |
don't like |
2.08K | 6.25k | 1/3 |
| dislike|dislikes|disliked | 603 | 1.7K | 1/3 |
There's a similar effect for verbs where the emotion is associated with a proposition under consideration or a contemplated outcome:
| absolutely | definitely | absolutely/definitely ratio | |
| overall | 34.9M | 29.3M | |
| insist|insists|insisted | 45.5K | 1.36K | 33/1 |
| believe|believes|believed | 40.8K | 38.4K | 1/1 |
| suspect|suspects|suspected | 200 | 968 | 1/5 |
| think|thinks|thought | 16.4K | 215K | 1/13 |
| feel|feels|felt that | 12K | 234K | 1/20 |
| suggest|suggests|suggested | 1.25K | 29.1K | 1/23 |
The interaction with modals is complex, because of the different meanings of the modals and the presence or absence of negation, but I think you can see some related effects emerging from the great variation of ratios in this small sample of relevant comparisons:
| absolutely | definitely | absolutely/definitely ratio | |
| overall | 34.9M | 29.3M | |
| must be | 37.7K | 4.34K | 9/1 |
| must not | 7.15K | 654 | 11/1 |
| must be/not ratio | 5/1 |
7/1 |
|
| might be | 61 | 806 | 1/13 |
| might not | 64 | 149 | 1/2 |
| might be/not ratio | 1/1 |
5/1 |
|
| should be | 6.29K | 30.6K | 1/5 |
| should not | 8.44K | 22.6K | 1/3 |
| should be/not ratio | 1/1.3 |
1.4/1 |
|
| could be | 869 | 14.1K | 1/16 |
| could not | 21.4K | 6.89K | 3/1 |
| could be/not ratio | 1/25 |
2/1 |
|
| may be | 113 | 1.15K | 1/10 |
| may not | 38.7K | 447 | 87/1 |
| may be/not ratio | 1/342 |
3/1 |
This all has something to do with what absolutely and definitely mean, and how their meaning interacts with the meanings of other words. But this dimension of meaning seems to be completely (though perhaps not absolutely or definitely?) missing from the dictionary definitions.
[Update: John Lawler emailed a proposal for a solution:
It's long been a standard example in GSish semantics that absolute(ly) subcategorizes to modify only polar attributes, adjectives (for example) that stand at one end or another of a local semantic cline. Thus the asterisk distribution in absolutely frozen/freezing/*cold/*cool/*lukewarm/*hot/boiling/steaming/burning.
The killer example is absolutely mad; mad has two senses, one synonymous with angry, and one synonymous with insane. So He's mad is ambiguous. But He's absolutely mad isn't, since only the insane sense of mad is polar, and is selected by absolute(ly).
This fact about absolute(ly) pretty much distinguishes the data in first 3 tables; definitely outranks absolutely with non-polar predicates, and absolutely greatly outranks definitely with polar predicates (or with believe, which seems to be a predicate that swings different ways in the reality-based and faith-based communities).
As for the modals, I haven't done an extensive analysis, but by eyeball, I'd guess Square/L modals and negative Diamond/M modals would be treated as polar and would prefer absolute(ly). And that Diamond/M modals and negative Square/L modals would prefer definitely.
When John says "GSish" he's abbreviating "generative semantics-ish", I think. To make a long story short, what that means in this case is that he's expressing an aspect of semantics (what things mean) in an essentially syntactic way (in terms of constraints on local structures). In particular, he's saying that absolutely "subcategorizes for" polar adjectives, in the same way that try "subcategorizes for" an infinitive in phrases like "try to go". I'm not sure whether there is a story here about definitely, or whether it's hypothesized to be just operating at baseline rates in the polar cases.
I'm not entirely satisfied by this sort of account -- it seems a bit like saying that extract of poppy makes you sleepy because it has a dormative principle, or that a child who gets a rash in the winter has hibernal eczema. Still, even that much would be better than what the dictionaries now give us for this sort of phenomenon, which is nothing. John was not surprised that dictionaries don't discuss this stuff (as he put it: "Well, yes. Duh. Wudja expect?"). Actually, I'd expect the dictionaries to provide a description (i.e. "absolutely modifies polar adjectives", or something of the kind), and linguists to provide an explanation. ]
March 30, 2005
Pick a site, any adjunct site
Another one for the WTF grammar file: a San Diego lawyer, who had at least once faced Johnnie Cochran in court, was interviewed for a local news spot on Cochran's death yesterday. The lawyer (whose name I unfortunately didn't catch) said that Cochran cared about people, and added:
I think that was clear from the day that I certainly met him.
I know that I've seen or heard examples like this before, where an adverb shows up in a spot where it doesn't seem to belong. In this case, I'm fairly sure the lawyer did not intend certainly to modify met; he meant it to modify was clear in some way.
My suspicion is that the lawyer added the certainly as an afterthought because he wanted to be more definitive about his claim than what was otherwise suggested by his introductory hedge (I think). But note that if the adverb had been placed in the "right" spot, it would have still sounded strange (to me, at least) simply due to the semantic incompatibility with the (now more proximate) hedge:
I think that was certainly clear from the day that I met him.
I do wish I had a sound clip to share, because I think the lawyer's intonation is relevant here. To my (relatively untrained) ear, the I before certainly met was higher-pitched (and lengthened), in such a way that it indicated to me that the lawyer was contrasting his experience of meeting Cochran with the possibly different experiences that others may have had. If this is right, then it's possible that he may have intended for certainly to modify a separate, unexpressed be clear as in the following paraphrase:
I think that was clear; it was certainly clear to me from the day that I met him.
Meaning (roughly): "I think it was clear to everyone that Cochran cared about people, but if not everyone, it was certainly clear to me." Since the second be clear was not expressed, though, certainly was tossed up in the air and just happened to land in (what I consider to be) a WTF site.
[ Comments? ]
Google as the MVWE ("Mountain View Word Exchange")
To what extent can someone own a word or phrase? Can the owner of a name control what others are allowed to respond if asked about it? And what do you think about lexicographic options and futures, or phrasal arbitrage?
On 3/27/2005, Doreen Carvajal has an interesting article in the IHT, reprinted in the NYT, exploring the proliferation of lawsuits against Google's keyword advertising. Her article focuses on certain questions in trademark law and related intellectual property issues. The owner of a trademark or service mark Foo® can get the courts to stop you from operating as Foo, at least in a sufficently similar business. But can they stop you from suggesting to third parties interested in Foo® that they should consider an alternative product or service like Bar®? So far, the answer is: in France they can, but in the U.S., England and Germany they can't.
The crucial issue is whether Google should be able to sell, to anyone interested in paying for it, the right to pop up one of those little right-column ads when an internet pilgrim asks about (say) Hennessy or Vuitton. The advertiser might want to offer genuine Louis Vuitton brand goods, or pirated knock-offs, or testimony from top fashionistas that another brand is *much* more elegant and desirable, really... or a rant about pretentious overpriced junk. Google doesn't care, as long as the advertiser pays the bill. LVMH Moët Hennessy Louis Vuitton and other companies have sued Google in France and won their cases, and Google has not only paid the (small) damage awards but also removed keyword advertising for (some?) trademarks from its French site.
I think there's something bigger and more interesting going on here. A couple of days ago, my colleague Michael Kearns suggested, only half in jest, that Google's most important innovation has not been improved search, but rather the invention of a new kind of market -- a market for words. Look at Google's introduction to AdWords, and especially consider the meaning of "maximum cost-per-click" (CPC), and you'll see that he has a point. In effect, this is a market where advertisers bid against one another for words. Removing trademarks from this market would decrease the total value of the goods traded (and would hurt Google's revenues), but it wouldn't change the basic nature of the situation.
And how long will it be before the usual array of derived instruments for hedging and speculation appears? Someone could make their living by guessing what unheralded keyword will go platinum next year, or what hot little morpheme will be all but worthless in six months.
Seriously, I think there's a clash here between two ideas about property and trade. Marketplaces like AdWords (or the similar systems at other sites) are trading in a certain kind of lexical property, namely the right to show an ad to search engine customers who ask about a certain word or phrase. Anyone at all can get into this market, for a tiny entrance fee, although the bidding can make some words very expensive. A company like LVMH Moët Hennessy Louis Vuitton wants to maintain control of the words that it owns, using the power of the state to keep its words out of this unruly lexicographic marketplace. It's probably not an accident that the country that gives the greatest monopoly power to the owners of words is France, where the feudal tradition of state-awarded monopolies in various areas of manufacture and commerce seems to have survived as a cultural value, though under a variety of different ideological labels.
Although the specific issues here are completely different from those involved in the recent French response to Google's digital library initiative, I get a Cathedral vs. Bazaar feeling from much of the recent news from Paris. I'm not talking directly about the property-rights aspect of open-source software here, but about the ideas of social organization: as Eric Raymond put it in the blurb for the First Monday publication of his essay, there are "analogies with other self-correcting systems of selfish agents". Whether your sympathies, or your legal theories, are on the side of Google or on the side of the trademark holders, there's the independent question of your attitude towards market-like mechanisms. Some people like them; I get the impression that the French, on the whole, don't.
March 29, 2005
5 billion lost articles, 6 interesting posts
Jean Véronis at Technologies du Language has continued to develop the new field of Googlology, or perhaps more precisely Googlometry. In chronological order, supplying links to English versions where they are available, and to French versions otherwise:
Google: 5 billion "the" have disappeared overnight,
Google: Blogues ou bogues dans les News?
Google: A snapshot of the update,
Quel est le Data Center qui me répond?
For non-googlometricians who can read French, Jean offers an Easter basket of word frequency analysis of gospel texts, and on the secular side, a lexicometric analysis of the speeches of Jacques Chirac, following the work of Damon Mayaffre.
Jean presents a graph that
...montre un changement rhétorique majeur dans les discours présidentiels au cours de la Vème République : "le discours des trois premiers présidents, de Gaulle, Pompidou, Giscard, dans les années 1960-70 est nominal et conceptuel, tandis que le discours des trois suivants (Mitterrand1, Mitterrand2 et Chirac) à partir des années 1980 est verbal et énonciatif". Le discours se vide de sa substance...
...shows a major rhetorical change in the presidential discourse over the course of the 5th Republic: "the discouse of the three first presidents, de Gaulle, Pompidou, Giscard, in the the years 1960-70 is nominal and conceptual, while the discourse of the three following [presidents] (Mitterand 1, Mitterand 2 and Chirac), starting in the 1980s, is verbal and expressive." The discourse is emptied of substance...

(The quoted passage is from Mayaffre's book.)
I'm not sure that Jean's view (that the discourse has been emptied of substance) is required by the data. A Chirac partisan (I suppose there must be some of them) might argue that his text is more active, more muscular and so on. This might even be in some sense true, if the difference in noun/verb balance is mainly due to expressing propositions less often in nominalized form. In any case, the change that Mayaffre has found seems to be not only statistically significant but also meaningful; the question is, what does it mean?
Another graph, easier to interpret, tracks the development of the word insécurité in Chirac's texts:

In both graphs, as I understand it, the y-axis represents what the French call "écarts réduits" ("reduced deviations"), which seem to be what we would call "z scores" in English. In other words, zero is the mean value (of the textual frequency of verbs or nouns or the word insécurité or whatever), while positive or negative values are frequencies greater or less than the mean, expressed in terms of standard deviations (mean squared difference from the mean in the overall distribution). The numbers seem too large to be z scores (15 standard deviations above or below the mean would be a gargantuan effect), and z scores don't make sense as a metric on untransformed frequencies, so I'll check this further.
[Update: Jean explains that there is a "well-established tradition in French literary computing (which goes back to Muller in the 1960s)" to use "écarts réduits" as follows:
For word w in section S of corpus C, where
r is the observed count of w in S,
p is the proportion of S with respect to C, and q = 1-p,
t is the count predicted for w in S on the basis of w's frequency in C as a whole;
then the "écart réduit" e of w in S is
e = (r - t) / sqrt (t * q)
In other words, if w occurs 100 times in a certain segment S of the corpus C,
and we would expect it to occur 200 times based on the overall corpus frequency of w, and S is 1/100th of C, then
e = (100-200)/sqrt(200*.99) = -7.1
Jean observes that Brunet's
hyperbase
program (available for the curiously exact sum of 144,83 € from the Institut National de la Langue Française) calculates this value. (I'd give you the hyperlink to INALF -- it's http://www.inalf.fr, as Google will tell you -- but its site was hacked some time ago by someone named Garzt3 and replaced with an ominous-looking flash animation, which has neither been fixed nor taken down.)
]
[More about Damon Mayaffre's work can be found here and here. Some other graphs of political lexicometry, or what Mayaffre calls "L'Herméneutique numérique" ("digital hermeneutics") -- the French right uses the various inflected forms of avoir ("have") much more often than the left does:

and the French right also uses past tenses (the passé composé and the imperfect) more often, while the left uses the future tense somewhat more:
 ]
]
March 28, 2005
Chomping at the font
I grant all this, but still maintain that both expressions had an eggcorn moment in their history, though they have now become "nearly mainstream", as we say on the eggcorn database. One of the lessons here is that dictionaries, even very good ones, don't -- in fact, can't -- tell you everything you need to know.
In both cases, the words (champ/chomp, fount/font) have a history as alternatives, but then differentiated in their uses. Relatively recently, though, one (chomp, font) has been overtaking the other (this is the possibly-eggcorn phase); in both cases, the more familiar, and more frequent, item has been replacing the less familiar/frequent (but phonologically similar) one, to the point where for many people the replacements are the ONLY available forms.
Even very good dictionaries are not particularly good at telling you relative frequencies of usages at different periods -- actually, such information is very hard to come by -- so there's only so much you can conclude from their entries.
For champ/chomp the history is easy to work out: chomp continued to be available as a verb meaning 'munch on, bite', while champ became confined to the idiom champ at the bit 'be restive' and perhaps a few other related idioms, like champing to [get home] 'anxious to [get home]'. Until very recently, idiom dictionaries listed only champ at the bit (if they had the idiom at all): see the BBI Combinatory Dictionary of English (1986, corrected 1993); NTC's American Idioms Dictionary (2nd ed., 1994); the Makkai et al. Dictionary of American Idioms (3rd ed., 1995); and the Oxford Dictionary of Idioms (1999), which lists chafe as a variant of champ. Some general dictionaries -- the British Chambers Dictionary (1998) and the American Heritage Dictionary (4th ed., 2000) -- continue to distinguish the specialized champ in champ at the bit from the munching sense, for which chomp is listed as a variant.
Now, here's a situation that's just ripe for reshaping. The now very rare verb champ occurs in only one or two idioms, where its meaning contribution is unclear. The phonologically similar verb chomp, however, is available, and makes some sense. (Replacing champ by chomp actually revives the original metaphor in the at the bit expression, though most current speakers won't appreciate that.) So chomp spreads rapidly, and quickly becomes just the way you say this.
This change is now recognized in some reference works. The Oxford American Writer's Thesaurus (2004), in particular, has a usage note on chomp, champ (p. 140), which recognizes the chomp at the bit wording as an American variant but claims that it's slightly less common in contemporary print sources than the champ variant. Pretty much the same discussion appears in Garner's Modern American Usage (2003), also from Oxford University Press.
Dictionaries are, for good reason, slow to recognize changes. My guess is that Garner and the Oxford American Writer's Thesaurus are just a bit behind the times.
On to fount/font. My story here is that these two nouns, both traceable back to Latin fons 'spring, fountain', also specialized, in different directions, with fount tending to be reserved for poetic and metaphorical uses (essentially, a "fancy" shortening of fountain in the extended senses 'source, hoard') and font largely reserved for baptismal fonts and similar pools of water. Dictionaries of quotations support this story: Bartlett's Familiar Quotations (14th ed., 1968) has three cites for fount 'fountain, source' and one for font 'pool' (from Tennyson's The Princess); the Oxford Dictionary of Quotations (3rd. ed., 1979) has one cite for fount 'fountain, source' and two for font (the Tennyson, plus one for a baptismal font); and the Chambers Dictionary of Quotations (1996) has one metaphorical fount (of pride) and the Tennyson "Nor winks the gold fin in the porphyry font".
Still, the cites in the larger dictionaries indicate that over the years there have been occasional metaphorical uses of font, which now seem to be overtaking fount at a great rate (from AHD4: "She was a font of wisdom and good sense"). This should not be entirely surprising, since fount is so strikingly "poetic" in tone, while font has concrete uses, with reference to baptismal fonts and, most important, to type fonts. The font of type font has a different history from the occurrences of font I've been talking about, but since the advent of computer typesetting and word processors, pretty much everybody has become (only too) familiar with the word. It's familiar and frequent, and even though it doesn't make perfect sense in expressions like font of wisdom, it has those other virtues; after all, fount doesn't make a lot of sense, either. (To make all of this even more complex, apparently British usage favored type fount until fairly recently, when the American usage with font swamped it. This suggests that metaphorical uses of font originated mostly in the U.S.) It's also possible that baptismal font, with its associations to beginnings, contributed to the spread of metaphorical font.
In any case, we've now reached the state where lots of speakers, especially Americans and especially younger ones, use only font for the metaphorical senses and find fount bizarre (and fountain perhaps a bit too literal). Every once in a while, one of these speakers will report with surprise their discovery that their font might be an eggcorn (as Philip Hofmeister did in e-mail to me the week before last). And it probably was, once.
zwicky at-sign csli period stanford period edu
Noblesse Oblige
Found yesterday in our referrer logs, a link to Language Log from a blog at scoopy.net. Despite (or because of?) the URL's status as a "naked celebrity site", the anonymous scoopy.net blogger has created a marvelously succinct example of pure structuralist social analysis:
The partnership you've been waiting for: France and Microsoft, thus allowing an important consolidation of hatred which might otherwise be too diffuse. Next in line to align: North Korea and Affleck.
My interest in this is purely scientific, of course. Language Log does not promote hatred of any countries, companies or actors, and takes no particular notice of naked celebrities. But as Claude Levi-Strauss wrote in Structural Anthropology (1958):
Structural linguistics will certainly play the same renovating role with respect to the social sciences that nuclear physics, for example, has played for the physical sciences. In what does this revolution consist, as we try to assess its broadest implications? N. Troubetzkoy, the illustrious founder of structural linguistics, himself furnished the answer to this question. In one programmatic statement, he reduced the structural method to four basic operations. First, structural linguistics shifts from the study of conscious linguistic phenomena to study of their unconscious infrastructure; second, it does not treat terms as independent entities, taking instead as its basis of analysis the relations between terms; third, it introduces the concept of system -- "Modern phonemics does not merely proclaim that phonemes are always part of a system; it shows concrete phonemic systems and elucidates their structure" -- finally, structural linguistics aims at discovering general laws, either by induction "or . . . by logical deduction, which would give them an absolute character."
I'm sure that our astute readers don't need me to explain to them how the scoopy.net blogger has compressed this four-part program into a two brief sentences and a hyperlink.
But in fact, as a phonetician, I've never been easy about that guy Nicholai Trubetzkoy, who wrote in his (posthumous) Grundzüge der Phonologie (1939) that "Phonetics is to phonology as numismatics is to economics". In other words, speech sounds are merely the arbitrary (though, alas, necessary) tokens whereby linguistic exchange is carried out. The only thing that matters, on this view, is the system that these tokens implement: if you put someone else's face on the coins, or replace them with paper chits or digital messages, nothing important changes in the economic system. This is Trubetzkoy's version of the structuralist credo that language is a system of relationships, where only the relationships really matter, not the items related.
There's an important insight there, but also an important blind spot. At least, that's the opinion of those of us who spend our time studying the physical properties, psychological effect, and social distribution of speech sounds and gestures.
Most of the (considerable) prestige of mid-20th-century linguistics, which derived from the success of the comparative method and the historical reconstruction of Indo-European and other language families, and also from the expert analysis of hundreds of diverse languages newly encountered around the world, seems to have devolved temporarily on this powerful, flawed structuralist insight. It's amazing, from today's perspective, to read the beginning of chapter II of Levi-Strauss' Structural Anthropology, a few sentences before the description of the four-part method that I just quoted:
LINGUISTICS OCCUPIES a special place among the social sciences, to whose ranks it unquestionably belongs. It is not merely a social science like the others, but, rather, the one in which by far the greatest progress has been made. It is probably the only one which can truly claim to be a science and which has achieved both the formulation of an empirical method and an understanding of the nature of the data submitted to its analysis. This privileged position carries with it several obligations. The linguist will often find scientists from related but different disciplines drawing inspiration from his example and trying to follow his lead. Noblesse oblige. A linguistic journal like Word cannot confine itself to the illustration of strictly linguistic theories and points of view. It must also welcome psychologists, sociologists, and anthropologists eager to learn from modern linguistics the road which leads to the empirical knowledge of social phenomena. As Marcel Mauss wrote - already forty years ago: "Sociology would certainly have progressed much further if it had everywhere followed the lead of the linguists. . . ." The close methodological which exists between the two disciplines imposes a special obligation of collaboration upon them.
Noblesse oblige indeed. If you're in the biz, ask yourself: when was the last time you heard an anthropologist or sociologist talking like that about linguistics?
Against that background, Roland Barthes' description of "a euphoric dream of being scientific" may be easier to understand.
Anyhow, I think that the "system of relations" concept was not as central to the successes of lingustics as Levi-Strauss (following Roman Jacobson) thought. The apparent failure of this concept to get very far in the social sciences may be partly due to the fact that social patterns and structures are different from linguistic ones, but in any case it takes more than a handful of abstract structuralist insights to make a success of an empirical analysis of any kind, linguistic or social.
They may be midgets
Yes, indeed, as Geoff Pullum reports,
there really was an NPR interview this Easter morning in which James
Cochrane, author of Between You and
I: A Little Book of Bad English, really did claim that the modal
verb form might was being
replaced by may and "has
practically disappeared from the language". Geoff supposes that
Cochrane (a "mendacious pontificating old windbag" and "an utter
fraud", as Geoff characterizes him) gets away with peddling this
twaddle because of the abysmal level of public awareness about
language; people like him are "convinced you'll believe absolutely
anything, so they have little motive to stick to even a vague semblance
of truth."
I think this credits Cochrane (and others of his kind) with more
knowledge about his audience than he actually possesses and with more
calculation in his pontificating than he's probably capable of. I
think he's earnest enought, but he's also ignorant, lazy, and
self-important — ignorant of the facts about English, too lazy to do
his homework (it's not like no one has ever thought about these
phenomena before), and so self-important that he takes himself to be
the measure of all things linguistic and just relies on his gut
feelings about the state of the language. As a result, what he
says is wildly hyperbolic — he hugely overestimates the scope and
significance of the innovations he reports on (and probably their
recency as well) — and misses essentially everything of interest about
the might/may
phenomenon.
But enough about Cochrane. Let's talk facts.
A good place to start is the old reliable Merriam-Webster's Dictionary of English Usage (1989). Section 2 of the may entry concerns may vs. might, citing references back to 1966 for "the puzzling use of may where might would be expected", notably "in describing hypothetical conditions, and in a context normally calling for the past tense."
The first MWDEU case is
epistemic may (the may of possibility, not the "root" may of permission) in the apodosis
of a counterfactual conditional: If
he'd have released the ball a second earlier..., he may have had a
touchdown (note the innovative 'd = would
in the protasis, as well as the innovative may in the apodosis). Here a
past modal form -- would, could, should, might -- is usually called
for. The may is
innovative, but not particularly troublesome, since in the hypothetical
context neither root may nor
present epistemic may (the may of I may vomit and It may rain tonight) makes sense.
(The Cambridge Grammar of the
English Language notes another context in which past modal forms
are usually called for -- in backshifted reports, as when the utterance
It may rain before we get home
is reported as I thought it might
rain before we got home -- and in which may has been encroaching on the
territory of might: I thought it may rain before we got home.
CGEL (p. 203) observes,
"Conservative usage manuals tend to disapprove of [this] usage, but it
is becoming increasingly common, and should probably be recognised as a
variant within Standard English.")
The second MWDEU case is in reports of possibility in the past, as in Born in Buffalo, N.Y., he may have gone to Princeton... but he made his reputation as a railroader. Here there is the potential for the may to be taken as a present epistemic ('It may (well) be the case that he went to Princeton') rather than a past epistemic ('It might have been the case that he went to Princeton (but he didn't)'). This is described as "confusing" by MWDEU.
There are still other cases where may might give the reader or listener pause. For instance, with negation in its syntactic scope, may could be either root may or a present epistemic: I may not eat the peanuts 'I am not allowed to eat the peanuts, I must not eat the peanuts' OR 'I might (well) not eat the peanuts'.
I've been aware of the "confusing" cases at least since 1958-61, when I worked on a newspaper and did a fair amount of copy editing. The innovative uses of may sometimes result in ambiguities that can be troublesome (at least to readers and hearers who aren't so accustomed to the innovative uses), and I dutifully clarified things then (by replacing may with might, or sometimes with must), and since then I have often advised my students to do the same. But I have to admit that lots of people seem to have no difficulty in working out, in context, the intentions of the writer or speaker, so maybe my clarificatory work was just fussiness. People cope with potential ambiguity all the time, after all.
Back to MWDEU, which admits to puzzlement: "No one has a satisfying explanation for why these substitutions [of may for "expected" might] occur, and we are as stumped as anyone else." I think they're giving up too easily. To start with, present epistemic may and might are in widespread alternation: I may/might vomit, It may/might rain tonight, etc. The semantic or pragmatic difference is subtle (by the way, there's plenty of literature on it), so that it's always open for people to see the difference as primarily stylistic and to opt for what they see as the informal variant, may -- sometimes preferring it in situations where both variants are possible, and then extending it (variably) to situations (like hypotheticals and backshifted reports) where particular constructions used to call for might only.
MWDEU entertains the germ of this proposal when it cites a brief footnote in the Quirk et al. Comprehensive Grammar of the English Language (1985), to the effect that the spread of may might be related to "some speakers' not perceiving any [semantic] difference between" You may be right and You might be right.
In any case, the result is a situation where even innovators still have use for might, especially as a strongly tentative epistemic, even though might has lost some ground to may. (And of course there are still all us old folks using might like crazy and keeping the Google numbers up.)
This message has been brought to you by They Might Be Giants, the writers of the advice song "No":
No is always no.
If they say no it means a thousand times no.
No plus no equals no.
All no's lead to no no no...
(Not that we're so disapproving here at Language Log Central. We're really very nice people. Unless you spell badly.)
zwicky at-sign csli period stanford period edu
March 27, 2005
Underwear sociolinguistics
My posting on "Tighty-whities: the semantics" elicited some thought-provoking e-mail about the use of this expression and of other pieces of underwear vocabulary. A lot of what's going on, but not all of it, turns on attitudes towards the underwear itself -- the perceived social "meanings" of the underwear (briefs vs. boxers, Y-fronts vs. bikini briefs, white vs. colored, cotton vs. more exotic fabrics) -- rather than on attitudes towards particular linguistic expressions.
1. In my first posting on this subject ("Tidy-whiteys")
I noted the disdain that some people have for white Y-front briefs, a
disdain that seems to be based on the judgment that such underwear is
conservative, unadventurous, uptight. Now Lal Zimman has written
(on 21 March 2005) to say that the negative judgments are likely to be
on both the clothing and the expression tighty-whities (or however you want
to spell it), and to offer another route to these judgments:
This is briefs vs. boxers, with the canonical briefs being white and cotton and fly-front. In the social world Zimman is describing, boxers communicate adulthood.
Competing with this social meaning is what I'll call the "hotness effect": briefs (of any sort) are hotter than boxers, because briefs display your equipment (in remarkable detail, if the briefs are tight enough and thin enough), and men are, well, vain about these things. The package is especially important to gay men, and it turns out that material designed for gay men portrays a world of briefs, not boxers.
Consider the Undergear catalogue, which (with its big brother the International Male catalogue) is transparently aimed at a gay male audience. The Spring 2005 issue of the catalogue offers not a single pair of boxer shorts. There are briefs of many varieties: bikini briefs, boxer briefs, thongs, jockstrap briefs (essentially jockstraps with seats). But no boxers; the occasional item labeled "boxer" is actually a boxer brief. Now, in the real world, some gay men do wear boxers. ( I can vouch for this, though I haven't done a systematic study.) From what I see at my (not gay-oriented) health club, plenty of straight men wear briefs too (probably because of the hotness effect, or just for the feeling of support that a pouch provides), but gay guys are in general much more committed to briefs over boxers than straight guys are. The Undergear catalogue provides a kind of distilled version of this commitment: in Gayworld, everybody wears briefs.
In the Undergear Gayworld, guys wear mostly colored briefs (though white is available as well), mostly in extraordinary fabrics (though cotton is available as well). There's the shimmery nylon/spandex Flawless Mesh Collection: "Super sheer, sexy mesh is virtually undetectable beneath clothing. Soft, smooth stretch fabric conforms to body. Available in a variety of brilliant colors... Nude, Black, White [more like Silver, I'd say], Purple, Turquoise, Red." (p. 22) On the facing page there's the nylon/spandex Seamless Mesh Collection, essentially fishnet made into tank tops and boxer briefs. All this underwear is meant to display the body, ostentatiously.
What almost no one in the Undergear Gayworld sports is a fly front. Only one item in the entire catalogue (boxer briefs on p. 15, available in White, Heather, Orange, and Black) has a "functional fly", as the catalogue puts it. The word "functional" is actually informative here, since some briefs in the catalogue have front seams that a careless observer might take to be a fly.
On to the presentation of male bodies in gay porn. Although I haven't studied the matter systematically, my impression is that the underwear that these guys rush to take off one another in Porn Gayworld is even more restricted than what's available in Undergear Gayworld. We see almost nothing but bikini briefs of fairly conservative cut, white, and cotton. Segment 2 of Stone Fox (featuring Eddie Stone), for instance, has the arrangement repeated in porn flick after porn flick: two guys in (for a while) these white cotton bikini briefs, one from Calvin Klein, one from 2xist. Tighty-whities in all respects save the missing fly front. I'd expect that some men do in fact call them tighty-whities, in an entirely positive way. [Added 28 March 2005: This speculation has now been confirmed by a gay friend, Jack Carroll, who reports that his usage of the expression, and that of at least one friend of his, is positive, even celebratory. Fly fronts, present or absent, seem to be irrelevant.]
What makes this specific sort of underwear so dominant in gay porn? My guess is that it's an amalgam of two attitudes: the hotness effect of briefs, already noted, combined with the high masculinity associated with white cotton briefs in particular (high masculinity because these briefs are associated, in the minds of gay men if not in the real world, with straight men). Actors in gay porn are supposed to project high masculinity, and the underwear is part of this display.
What I haven't figured out yet is why fly fronts get such a bad rap in Gayworld. Maybe a missing fly front is just a missing fly front.
2. Notice that the expression tighty-whitey or tighty-whities can be used metonymically, to refer to the sort of man who habitually wears tighty-whities. Negative attitudes towards the underwear carry over to the man who wears it. Chris Brew wrote me (on 21 March 2005) to note a possible parallel in British English:
Anyway, that's the only really culturally salient instance of British clothing metonymy that I can muster, apart from the routine 'suit' and 'stuffed-shirt', which seem to work in the US as well.
For non-British readers: British anorak, referring to a person rather than a parka, can be glossed roughly as 'nerd', or in more detail (in the words of the anorakspotters site): "any dull or immature individual, or someone who follows a hobby which appears boring to the majority of people who find other pursuits more attractive once they have passed the legal age for sex and alcohol." Anoraks are usually male, and (to tie two threads together) we can surmise that they wear white cotton Y-fronts.
zwicky at-sign csli period stanford period edu
The disappearing modal: for those who'll believe anything
Happy Easter from Language Log to all our readers. And a quick Q&A reality check for those who could not believe their ears as they listened to NPR's "Weekend Edition Sunday" program this morning.
Q: Was there (perhaps I dreamed it) an interview with a retired
Penguin Books editor called James Cochrane about a book called something like Between You and I ?
A: Yes, there was. You can
listen
to it here. Cochrane was talking about his book
Between
You and I: A Little Book of Bad English.
Q: Did he really say (possibly my ears hadn't quite woken up)
that the modal verb form might was being eliminated in favor of
may and "has practically disappeared from the language"?
A:
Yes, he really did say that.
Q: Presumably the word is almost gone from the World Wide Web,
then. How many residual web pages are there on which this disappearing verb still appears?
A: According to Google's rough estimate,
about 140,000,000. (Perhaps a few of those use the noun might meaning ‘power’ but not the modal verb, but the noun
isn't very common, so most of those will be uses of the modal.)
Cochrane is alluding to a small change that has been creeping
into some varieties of English for some time: may is being
used in certain contexts where the preterite form of other verbs
would occur:
there is a well-established minority dialect that has "They feared they
may get lost" for "They feared they might get lost" and so on.
The topic is treated in pages 202-203 of
The Cambridge Grammar.
But those dialects still have might in numerous other
contexts (like "I might be able to, if we're lucky").
The word might isn't dying out.
Q: Oh. Still there on a hundred and forty million web pages?
That is quite a lot for a word that has "practically disappeared".
Is James Cochran, then, nothing but a mendacious
pontificating old windbag?
A: Yes, it would appear that he is an utter fraud.
Q: Why do people say these completely indefensible things
about language that can be checked up on so easily?
A: Possibly because they know
that with hardly anyone ever taking even one college course in linguistics, public
awareness of the facts about language and languages ranges from
the minimal to the derisory.
But for the most part it is a mystery why linguistic subject matter is treated so differently from other material in which science has been interested; it baffles all of us here at Language Log Plaza. Imagine if an amateur wrote a book on ecology (How Now Brown Cow: A Little Book of Threatened Animals) and said that mice have "practically become extinct" in America. Would the interviewer listen credulously and politely as the nutball pothered on, not even alluding to any evidence for the absurd claim?
Yet people can get away with saying just about anything about language. Only a week or two ago NPR had somebody on who declared that the Irish language has no word for sex, and he too was listened to politely and not challenged. Keep your hand on your wallet when people tell you things about language; they're convinced you'll believe absolutely anything, so they have little motive to stick to even a vague semblance of truth.
Tomorrow was yesterday
Actually that's "Demain, c'etait hier" -- the headline under which Jacques Attali in L'Express on 3/14 tore into Jean-Noel Jeanneney and (implicitly) Jacques Chirac. The subhead:
Si la France avait suivi son plan de numérisation des livres, sa culture serait la plus présente sur la Toile.
If France had followed its plan for digitization of books, its culture would have the biggest web presence.
This is transparently a partisan attack, since Attali is a prominent "socialist" intellectual -- meaning, confusingly, that he's a leading advocate of neo-liberal capitalism, i.e. free-market economics. At least I think that's how he lines up. This is Language Log, and we're used to systematic irregularity (or should that be irregular systematicity?), but French politics is another thing entirely.
Anyhow, for Attali to attack Chirac is as expected as for Paul Krugman to attack Bush, but even if it's predictable, his op-ed piece is a fine specimen of its genre:
La colère que suscite, dans un petit milieu parisien, la décision de Google de numériser des millions de livres et de les rendre gratuitement accessibles serait seulement ridicule si elle n'était pas le reflet du consternant provincialisme de ce qui est nommé à tort nos «élites» et l'un des signes annonciateurs de la marginalisation de la France dans la formidable accélération de la mondialisation en cours.
The anger that is evoked, in a small Parisian milieu, by Google's decision to digitize millions of books and make them freely accessible would be ridiculous if it were not the reflection of the distressing provincialism of what are wrongly called our "elites", and one of the leading indicators of the marginalization of France in the extraordinary acceleration of globalization now underway.
(Skipping a bit about the history of Google...)
Quand Google a proposé à des bibliothèques non anglophones, et en particulier françaises, de se joindre au projet, certains ont crié au scandale: voilà que l'Amérique s'arrogeait le droit de hiérarchiser la littérature et la science, privilégiant nécessairement les écrivains anglo-saxons. Reproche absurde.
When Google proposed to the non-anglophone libraries, and especially the French ones, to join the project [of Google Library], some people cried scandal: there goes America arrogating to itself the right to organize literature and science into a hierarchy, necessarily privileging anglo-saxon writers. An absurd charge.
D'abord, parce que rien n'empêchait les Européens, notamment les Français, d'en faire autant. C'est en effet en France, en 1988, c'est-à-dire avant même l'apparition du nom d'Internet, qu'est née l'idée de numériser les livres et de les mettre gratuitement à disposition du public sur ordinateur. Et si, au lieu de construire, avec la Bibliothèque nationale de France, un bâtiment de plus de 1 milliard d'euros, on avait suivi le plan initial et consacré les 300 millions d'euros prévus à la numérisation des livres, la France serait aujourd'hui le pays à la culture la plus présente sur la Toile.
First, because there was nothing stopping the Europeans, and especially the French, from doing the same. In fact it was in France, in 1988, even before the appearance of the name "Internet", that the idea of digitizing books and putting them freely at the disposition of the public was born. And if, instead of constructing the French National Library, a building costing more than a billion euros, they had followed the initial plan and spent the 300 million euros planned for digitization of books, France would today be the country and the culture with the biggest web presence.
Actually, the word internet was coined in 1974, as documented by the OED:
1974 V. G. CERF et al. Request for Comments (Network Working Group) (Electronic text) No. 675. 1 (title) Specification of internet transmission control program.
and was used in the trade press at least since 1981, but perhaps Attali is confusing internet with world wide web, which was coined in 1990:
1990 T. BERNERS-LEE & R. CAILLIAU (title of electronic document) WorldWideWeb: proposal for a HyperText project.
Also, my memory of the French plan is that it called for the digitized books to be available only on the site of that billion-euro library, via purpose-built "computer-assisted reading environments" provided by a French computer company. But never mind that, let's go on with Attali's op-ed:
Ensuite, parce que c'est ne rien comprendre à Internet que de croire que Google pourrait ou voudrait hiérarchiser les cultures. D'ores et déjà, les moteurs de recherche en espagnol et en chinois connaissent une croissance supérieure aux moteurs anglophones. Et si nous avions aujourd'hui l'intelligence de numériser la culture francophone à grande vitesse et de la rendre disponible sur la Toile par tous les moteurs de recherche, y compris Google, nous l'inscririons dans le réseau de tous les savoirs, sans avoir à craindre de disparaître dans une hiérarchie: un réseau n'est pas une hiérarchie.
Next, because it shows a complete lack of understanding of the internet to believe that Google could or would organize cultures into a hierarchy. Already, the search engines in Spanish and in Chinese are growing faster than the anglophone engines are. And if we had today the intelligence to digitize francophone culture at a great speed, and to make it available on the web to all the search engines, Google included, we would inscribe it in the network of all knowledge, without having to fear disappearing in a hierarchy: a network is not a hierarchy.
Enfin, parce que le monde change et que ce qui est arrivé à la musique arrivera à la littérature: la gratuité des idées est inéluctable. Les auteurs y trouveront leur compte. Les bibliothèques s'y inventeront un nouveau rôle. Et les journaux seront là pour aider à distinguer l'essentiel de l'accessoire. Distinguer: décidément, l'un des plus beaux mots de la langue française.
Finally, because the world changes and what has happened to music will happen to literature: the freedom of ideas is unstoppable. Authors will find a new mode of payment. Libraries will invent a new role for themselves. And the newspapers will be there to help distinguish the essential from the secondary. Distinguish: definitely one of the most beautiful words in the French language.
Attali comes across as distinctly more clueful than Jeanneney, though that may be because he's a better debater, and his political opponents have dealt him a strong hand in this particular debate. But I think it's worth pointing out that the big BNF project was especially associated with Attali's patron Francois Mitterand. The usual tag for Attali (as in the blurb for his book Millennium; Winners and Losers in the Coming Order) is "President Mitterand's most trusted advisor", and Mitterand was in power during much of the period in question (from 1981 to 1995, specifically). So if the BNF project missed the mark so badly on something so important, why wait until now to complain about it?
I wonder, myself, whether the 300 million euros of digital library budget might in fact have been spent, over the course of the project's decade and a half. It wouldn't be the first big government software (and hardware) project that spent a comparable amount of money without producing much. And I'm thinking here of American projects, not French ones.
Chinese in Law and Order
Television is confusing. I was watching Law and Order a little earlier. It was the episode in which the police find a little Chinese girl and her baby sister alone in their apartment, their mother missing. The story is about what has happened to her. The Chinese-speaking detective and the little girl converse in Mandarin, and so do the little girl and her aunt. Near the end, when they locate the little girl's teenage sister, she and her aunt speak Mandarin with each other. But when the aunt goes into a shop in Chinatown to consult the owner, they speak Cantonese.
This scenario seems unrealistic to me. That the man in Chinatown should speak Cantonese is what I'd expect. Most Chinese immigrants to the US until recently spoke Cantonese. Recent immigrants include many Mandarin speakers, so it isn't a surprise that the girls and their aunt spoke Mandarin. Indeed, just recently I had what to me was the rather odd experience of encountering a little girl, maybe 8 or 9, in a shop in Chinatown, who spoke neither English nor Cantonese. We spoke Mandarin (she rather better than me - yet another area in which age and academic degrees don't help).
What is odd is that the aunt spoke Cantonese with the man in Chinatown. Of course, many Cantonese-speakers learn Mandarin as a second language, so bilinguals are not rare, but it is quite unlikely that a Cantonese person who also knows Mandarin would speak Mandarin with her nieces. People who are basically Mandarin speakers rarely speak Cantonese; if they do it is usually because they have moved to a Cantonese-speaking area. The only other hypothesis that I can think of is that the adults are first-language Cantonese speakers who have learned Mandarin as a second language and who so strongly identify with Mandarin as the language of modernity that they have spoken Mandarin with their children and nieces. I guess that's possible, but I haven't ever met anyone like that. In my experience, Cantonese speakers always prefer Cantonese. They may make an effort to learn Mandarin because they perceive it as advantageous to know, but they would never use it with their children.
So, I'm wondering whether the Law and Order folks had in mind some interesting scenario that would explain the choice of languages in this episode, or whether they just don't know one kind of Chinese from another, or don't think that anyone will notice.
Bill Clinton has a blog
[Or maybe he doesn't -- several people have written in to suggest that this is a fake. That probably makes more sense than the hypothesis that Bill Clinton would really write as frankly as he seems to in the entries I discuss. And surely the real Bill Clinton has a staffer who could correct his punctuation...]
It's called BILL CLINTON DAILY DIARY, subtitled "In-depth analysis of current events, personal stories and humor". It's been around since last summer, but I never noticed it before now. The few recent entries I've read are interesting and surprisingly frank, especially the March 25 entry on Rafiq Hariri and Lebanon, which comes straight out and says:
I’m certain Bashar Assad ordered the assassination of Rafiq Hariri, but in international affairs you can’t do anything without proof. I’m certain the international investigation will find proof linking Bashar Assad to the murder of my friend Rafiq Hariri.
The reason I’m so confident is the fact that it took the FBI years to find the culprits, who had blown up the plane over Lockerbie, Scotland, but they found them and linked them to the Libyan government. And when the investigation succeeds, there will be hell to pay for Assad.
He explains about Assad's multiple recent mistakes, and ends this way:
Finally, Bashar Assad doesn’t seem to understand how serious this administration is about dealing with rogue states and state sponsors of terrorism. Let me clarify this. Syria is not the objective, it’s a barrier on the road to Iran.
What he means by this is that
Regime change in Iran isn’t easy. [...] Invading Iran is out of the question. Bombing Iran is possible, but won’t have the intended result. The only avenue left is to mortally wound the regime in Iran by cutting off its tentacles.
The first one is Hizballah in Lebanon, the second one is the Syrian regime.
I was going to call this an astonishly frank threat, but really, it's not a threat, it's a promise. I haven't seen any coverage of this in the mainstream media, an omission that would surprise me if my expectations were higher. [...and if the source were non-fraudulent.]
Anyhow, this is Language Log, and so it's about time to get to the linguistic part. "Bill Clinton" writes clearly and well, but he has an odd thing for extra commas. He adds commas (sometimes) before but not after relative clauses (which should have either no commas or two), before but not after (some) appositives and adverbs (where likewise there should be either none or two), and between (some) subjects and verb phrases. We've seen one of the extra relative clause commas already, in a case where the relative clause is apparently "integrated" rather than "supplementary", and therefore should have no preceding comma:
The reason I’m so confident is the fact that it took the FBI years to find the culprits, who had blown up the plane over Lockerbie, Scotland, but they found them and linked them to the Libyan government.
Here are some of the other extra commas in the March 25 entry:
It also clearly says that Bashar Assad, during a meeting threatened to harm Rafiq Hariri and Druze leader Walid Jumblatt if they stood in his way. [or maybe this one needs a second comma after "meeting"?]
Bashar Assad made the mistake of thinking we, Americans didn’t care about Lebanon. [appositive]
Most Americans have neighbors, who descend from families, who came from Lebanon. [two integrated relative clauses]
For instance, one of the most respected journalists in Washington, Helen Thomas has Lebanese ancestry. [appositive]
Even France, whose president Chirac was a friend and business partner of Rafiq Hariri has made it clear this situation has to be dealt with. [supplementary relative clause that should have a second comma]
One, we destroy their nuclear facilities or two we bring down the regime, which wants them. [integrated relative clause, should have no comma]
Iran is a big country, with a lot of money, because of its oil and gas reserves and has a population of about seventy million people, most of them young and of military age. [adverbial prepositional phrase -- here again a second comma would also work, but before-but-not-after seems wrong]
Syria, which is a poor country with only about 15 million inhabitants will be hit hard. [suppplementary relative clause that should have a second comma]
In the entry for March 22, "Bill" recommends Errol Flynn's autobiography My Wicked Wicked Ways. The recommendation is probably more effective for being hedged: "I probably shouldn’t recommend it to you, but I’m not going to lie, it was probably one of the most amusing books I’ve ever read in my life." Thanks to amazon's "search inside the book" feature, it's easy to figure out what's behind "Bill's" ambivalence. On the second page, Flynn explains why he ran away from home at the age of seven:
I played regularly -- or irregularly -- with a little girl next door named Nerida. One day we exhausted the interest in bush rangers, which is the Australian equivalent of cowboys and Indians.
She proposed that we play house, husband and wife. She prepared mud pies. I pretended to eat them. The inevitable happened. We went under the porch of Nerida's house and played more seriously at husband and wife.
"I'll show you mine and you show me yours," I said. She was game.
Nerida's mother nabbed us red-fingered, and she promptly told my mother. I got a hell of a shellacking.
I wondered why I should get whaled so, while Nerida, who was older, got off with a You-mustn't-do-that, darling.
My mother not only lambasted me, but said, "Now you shall tell your father yourself!"
I dreaded having to do this. It was an afternoon terrible with anticipation, till my father came home. Then, whether from fear or stubbornness, I wouldn't open my mouth.
Mother yelled, "Go on! Tell him what you did, you dirty little brute! Go on! Don't stand there! Tell your father what you were doing!"
My father, who was sympathetic, said, "Now, Marelle, he will tell me in his own time."
"He will not! He will tell you now!"
She flew at me again. I screamed. He stepped in. He was never any match for her, either in words or action, and Mother followed through with a torrent of invective.
This is no place for me, I decided. I'd leave home, get a job.
[...]
Recently my mother wrote a letter descriptive of that incident, remarking, "He ran away from home when he was about seven and we suffered agonies of anxiety for three days and nights. He was found miles away where he went and offered himself for work at a dairy farm. He asked only five shillings a week as wages, saying that would do him, as he 'never intended to marry'."
That tells it.
I never have married. I have been tied up with women in one legal situation after another called marriage, but they somehow break up.
In the same entry, "Bill" confesses that he lied repeatedly to reporters. About his favorite songs, that is:
It’s a strange thing, being a politician. When I was running for office journalists asked me what my favorite song was. I couldn’t tell them the truth. My favorite song is “Be my Baby” by the Ronettes. Obviously I couldn’t say that, because it’s too romantic. So I decided to say it was “Don’t stop thinking about Tomorrow” by Fleetwood Mac.
It was the right thing to do at the time. You’re a politician, you’re telling voters you are going to change politics as they know it, so what better theme song than “Don’t stop thinking about Tomorrow”? It was perfect for the campaign.
I do like Fleetwood Mac. Most baby boomers do. If I’m right their album “Rumors” is still the best selling album in the United States. Their best song though, is, you will agree and you will know I’m being honest with you, their best song is “Tell me Lies”. Am I right or not? I couldn’t use “Tell me Lies” as my theme song during my presidential campaign.
As he explains, those little white lies sometimes have consequences:
I can’t tell you how many times I had to listen to some saxophone player play “Don’t stop thinking about Tomorrow” when I was president. It wasn’t fifty or a hundred times, not just here in the US, but also overseas. I never liked the song, but after all the times I was forced to listen to it, I genuinely dislike the song, but that’s my own fault. I was the one, who told them I liked it. [emphasis added]
There's that extra comma again.
Liberalism is the new communism
Political rhetoric can be very confusing. Americans are used to hearing from right-wing politicians that liberalism is like communism, and the most recent right-winger to put this idea forward was Jacques Chirac, at a European summit meeting in Brussels last Tuesday. But he wasn't talking about the ideas of the Americans for Democratic Action -- he was warning about the dangers of free markets.
According to an article in The Times, the context seems to be the upcoming French referendum on the European Constitution, where the polls say the verdict might be "non". One of the issues is apparently worry about economic effects of competition for jobs, and in particular the consequences of the so-called "Services Directive", which French politicians are therefore vying with one another to oppose. As The Times explains:
This directive would allow anyone employed in a huge range of professions — from architects to plumbers — to operate anywhere in the EU without hindrance. It is such a logical element of a single market that was supposed to have been secured more than a decade ago that it is astonishing that it has not been introduced already. Every authoritative estimate of its economic impact is that it would increase net employment and enhance the rate of growth in Europe. It is, as Americans would put it, a “no-brainer”.
Unfortunately, there appears to be a severe shortage of brainpower at the highest level in France. Even though more jobs will be created than lost, the prospect of any redundancies means the directive has been attacked by the Socialist Party and the trade unions. Not to be outdone, M Chirac has jumped on the bandwagon, seized the wheel, and chose a dinner on Tuesday to condemn liberal market principles as “the new communism of our age”.
In European lingo, as I understand it, liberalism means (roughly) "free market economics", in the classical tradition of David Hume, Adam Smith, David Ricardo, J.S. Mill and so on. It's opposed on the left by socialism/communism, and on the right by Bonapartism and fascism. Chirac's party, the Rassemblement pour la Republique (RPR), is a right-wing party, opposed in principle by the Socialists and other leftists, and apparently in trouble on several fronts.
A Reuters story, presented on the site of the left-wing paper Libération, offers essentially the same perspective as The Times:
On a affirmé de sources diplomatiques britanniques que Jacques Chirac avait stigmatisé mardi soir devant ses pairs européens l'ultralibéralisme, "ce nouveau communisme".
Le Premier ministre irlandais, Bertie Ahern, a rapporté que le président français s'était présenté comme "socialiste" lors des discussions du sommet.
"J'ai souligné fortement que la croissance économique et la cohésion sociale allaient de pair dans le projet européen. C'est ce qui fait la force, l'originalité du projet européen", a expliqué Jacques Chirac.
L'ancien contempteur de la "fracture sociale" a ainsi esquissé l'argumentaire élyséen dans la campagne référendaire.
We have confirmed from British diplomatic sources that on Tuesday evening Jacques Chirac stigmatized ultra-liberalism, in front of his European peers, as "this new communism". [...]
The Irish prime minister, Bertie Ahern, reported that the French president presented himself as a "socialist" at the time of the summit discussions.
"I have forcefully emphasized that economic growth and social cohesion go together in the European project. That is what makes the force, the originality of the European project," explained Jacques Chirac.
The one who was formerly scornful of the "social divide" has thus sketched the Elysee's sales pitch in the referendum campaign.
The business about "bruits du couloir" refers to this press conference, in which Chirac was asked
QUESTION - Monsieur le Président, si le néo-libéralisme est le nouveau communisme, qui est donc Tony BLAIR, qui mène ce néo-libéralisme ?
Question - Mr. President, if neo-liberalism is the new communism, then who is Tony Blair, who leads this neo-liberalism?
and answered with 700 words of ergodic poli-babble, beginning
LE PRESIDENT - Je ne sais pas exactement ce à quoi vous faites allusion, mais je vais quand même vous répondre : je veux simplement vous mettre en garde contre les bruits de couloir, c'est une règle générale.
The President - I don't know exactly what you're alluding to, but I will respond anyhow: I simply want to put you on guard against corridor chit-chat, as a general principle.
The issue of dirigisme ("interventionism", i.e. central planning by the state) is apparently one of the issues on which left and right can agree, at least in France.
Radio France Internationale, quoting Le Figaro, suggests that Chirac's opposition to the Services Directive is, shall we say, subtle:
Jacques Chirac a « critiqué cette directive sans exiger son retrait » : [...] la position française apparaît « si peu lisible qu'elle perd de sa crédibilité ».
Jacques Chirac has "criticized this directive without requiring it to be withdrawn": the French position seems "so unreadable that it loses its credibility".
Please don't think I'm picking on the French, by the way. I happened to notice this little episode because I've been reading the French-language press to keep tabs on the France v. Google story. I have extra time to do this because the American news media have now become "all Terri Schiavo, all the time". It's always refreshing to learn about the pandering of some other country's politicians.
Oh, and one last linguistic note -- the snowclone "X is the new communism" (in English) get 2,280 hits in English, for values of X including (in page-rank order) Islam, Frenchness, capitalism, ultra-liberalism, libertarianism (these last three referring to Chirac's mot), trashy-chic fashion, terror, terrorism, and organized crime.
I'm not quite sure how to generalize Chirac's expression in French: there are 798 pages about {"nouveau communisme"}, but most of them seem to be actually about new or renewed communism. We can find things like
L'argent est le nouveau "Dieu"
Le marron est le nouveau noir.
but the pattern doesn't seem to have the currency that it does in English, and "ce nouveau|nouvelle" doesn't seem to turn up analogous uses.
March 26, 2005
Another dangling modifier
Here's another "stunningly inept" dangling modifier for Geoff Pullum's collection, from a post by amberglow over at metafilter:
Pegged to head the World Bank, is Wolfowitz' lover, Shaha Riza, one of the reasons we invaded Iraq?
Paul Wolfowitz is the one who has been nominated to head the World Bank -- his alleged "lover" already works there.
According to a story in the Daily Mail, Wolfowitz has been linked romantically to Shaha Ali Riza, said to be "the acting manager for External Relations and Outreach for the Middle East and North Africa Region at the World Bank", and formerly "the Gender and Civil Society Coordinator" for the same organization. Riza, said to have been born in Tunis, "grew up in Saudi Arabia and was passionately committed to democratising the Middle East when she allegedly began to date Wolfowitz". Her academic background includes the London School of Economics and Oxford, and she was previously married to a Turkish Cypriot.
To the extent that all this is anybody's business at all, it seems to me like a heart-warming story of improving international understanding. But this is Language Log, and so we do have business with that modifier.
Cargo Cult poetry?
In reference to my recent series of posts on the origins of literary theory in "cargo cult linguistics," John McChesney-Young wrote to draw my attention to a passage in Clive James's review of Camille Paglia's "Break, Blow, Burn":
The penalty for talking about poets in universal terms before, or instead of, talking about their particular achievements is to devalue what they do while fetishizing what they are.
This insidious process is far advanced in America, to the point where it corrupts not just the academics but the creators themselves. John Ashbery would have given us dozens more poems as thrilling as his jeu d'esprit about Daffy Duck if he had never been raised to the combined status of totem pole and wind tunnel, in which configuration he produces one interminable outpouring that deals with everything in general, with nothing in particular, can be cut off at any length from six inches to a mile, and will be printed by editors who feel that the presence in their publication of an isotropic rigmarole signed with Ashbery's name is a guarantee of seriousness precisely because they don't enjoy a line of it. Paglia, commendably, refuses such cargo-cult status even to Shakespeare. [emphasis added]
James is referring to Ashbery's 1975 poem "Daffy Duck in Hollywood" -- but what does he mean by "such cargo-cult status"?
I've always interpreted the cargo cult metaphor as describing a case where unsophisticated people "go through the motions" in imitation of a respected and powerful group with more advanced capabilities, without any understanding of the real functions of the imitated activities or the causal processes behind them. But for James in this passage, it seems that "cargo cult status" means something like "value assigned blindly, without any understanding of the real basis of such value". Is Ashbery (according to James) cluelessly going through the motions of being a poet? Perhaps, but it's readers who are assigning or refusing "cargo cult status". So for James, apparently, Ashbery's audience is cluelessly going through the motions of appreciating his poetry.
Cults aside, James' review is full of little linguistic curiosities. Two examples among many: the anonymous "editors who feel that the presence in their publication of an isotropic rigmarole signed with Ashbery's name is a guarantee of seriousness"; and Paglia described as "a woman who sometimes gives the impression that she finds reticence a big ask".
Isotropic is a term from physics, first used in the late 19th century, meaning "Identical in all directions; invariant with respect to direction." Usually it's properties such as elasticity or conductivity that are at issue, though there is that famous joke about the recovering physicist whose consultant's report to the dairy cooperative began "Consider a perfectly spherical cow, radiating milk isotropically."
According to the OED, Ragman (dating from 1276) was "A game of chance, app. played with a written roll having strings attached to the various items contained in it, one of which the player selected or ‘drew’ at random." The roll used in the game was called a ragman's roll or a ragman roll, and rigmarole was a reduced form of this, sometimes re-analyzed as "rig-my-roll" and similar things. So aleatoric poetry could be described with historical exactitude as a rigmarole.
"Isotropic rigmarole" is a cute collocation, with a texture like chrome and bone. It's never been used before, within the ken of Google anyhow, but it's worth recycling and even turning into a cliché. You could make up other phrases on the same pattern, like "adiabatic gobbledygook", or "ergodic gibberish", but it's hard to create one that goes down as smoothly as "isotropic rigmarole". (Though maybe "adiabatic technobabble" has some promise, in the right context...)
And as for "big ask", when John Kerry used that phrase, it made Eric Bakovic doubt his own native-speaker status. I'm with Eric on this one, but I have to admit that it works better than the obvious alternatives: "a woman who sometimes gives the impression that she finds reticence a lot to ask"; "a woman who sometimes gives the impression that she finds reticence difficult "; etc.
Anyhow, if you're in search of some really Xtreme ritual displacement, you can download the video game version of Daffy Duck in Hollywood...
[Update: Cosma Shalizi sent in a pointer to Espeth Aarseth's Cybertext: Perspectives on Ergodic Literature. adding that "'ergodic gibberish sounds much better to me than 'isotropic rigmarole'". Well, Cosma has the advantage (or perhaps disadvantage) of knowing what the words mean. I suppose that Clive James really meant something like "ergodic", anyhow, since he says that (poor abused) Ashbery's poetry is "one interminable outpouring that ... can be cut off at any length from six inches to a mile". This certainly sounds like the result of "a process in which a sequence or sizable sample is equally representative of the whole", which would make it ergodic. And since there's really only one direction in text, anyhow, it's hard to avoid having text be "identical in all (available) directions", and thus isotropic, even if it's not semantic yardgoods. But what I liked about "isotropic rigmarole" was its prosody, anyhow. And maybe the geographical resonances of "-tropic". I mean, we're talking about poetry here. ]
Pharyngealization and annoyance
Heidi Harley at HeiDeas has a terrific list of linguistic Simpsons jokes, which she proposes as the basis for an introductory course. She also asks a phonetic question:
As I looked at a few Simpsons sites for this post, I noticed that the accepted orthography for Marge's trademark annoyed noise is mmm. This didn't seem adequate to me, and got me thinking about the difference between a regular prolonged bilabial nasal, [mmm] (the noise you make for yummy things), and Marge's annoyed noise. It seemed to me it might be an ATR minimal pair, with [mmm] being [+ATR] and Marge's noise being (aggressively) [-ATR]. Does that make sense to any phonologists out there?
"ATR" stands for Advanced Tongue Root: the root of the tongue, which is the front wall of the pharynx, can be pulled forward to make the pharyngeal cavity wider, or pulled back to make it smaller. The distinction was first named in the case of some distinctions among vowels in certain African languages, where vowels come in a +ATR and a -ATR set. Examples for Akan can be found here, including sound files and x-ray tracings. A similar articulatory gesture is used in English (and many other language) in voiced stops, where advancing the tongue root (and/or lowering the larynx) helps to permit voicing to continue despite the oral closure.
It has been argued that the tongue root can be actively retracted (pulled backwards, narrowing the pharynx) as well as advanced (pulled forward, widening the pharynx). So maybe Retracted Tongue Root (RTR) would be a better term than "aggressively [-ATR]". These changes are sometimes associated with other epiglottal and laryngeal maneuvers, resulting in voice quality differences: thus the enlarged pharynx is sometimes associated with breathy voice (as in Javanese), and the constricted pharynx can be associated with creaky voice. From memory, I'd say that Marge's "annoyed voice" (which I think she uses for more than just "mmm" noises) involves pharyngeal constriction and creaky voice.
Phoneticians of the world, can you advance (or retract) to Heidi's challenge?
For a start, we need a good corpus of annoyed and non-annoyed Marge Simpson vocalizations. Perhaps I need to buy the boxed set of DVDs for the phonetics lab. Meanwhile, I'll assemble any data that readers care to contribute.
Europe's response to Google to be managed by... Microsoft?
The proposed European response to Google's library initiative got a lot of additional publicity after Jacques Chirac met last Wednesday with Jean-Noel Jeanneney, head of the French National Library, and Renaud Donnedieu de Vabres, French minister of culture. Thanks to Google Actualités France, I've been following the story in various French-language news outlets.
Except for the news that Chirac is definitely on board, most of the discussion has followed predictable lines, but I was brought up short by the end of an article by Béatrice Gurrey et Emmanuel de Roux in Le Monde on 3/16/2005:
Dans l'esprit du chef de l'Etat, il s'agit de bâtir un "alter ego" au projet américain, avant d'envisager une éventuelle collaboration avec Google, pour ne pas discuter en situation de faiblesse. Le président serait-il prêt à s'entretenir avec le concurrent de Google, Microsoft, puisqu'il a tant de convergences de vues avec son président, Bill Gates, qu'il a longuement reçu à l'Elysée? "Pourquoi pas?", répondent les conseillers de M. Chirac.
In the mind of the chief of state, it's a question of building an alter ego to the american project, before thinking of an eventual collaboration with Google, so as not to negotiate from a position of weakness. Would the president be ready to make a deal with Google's competitor, Microsoft, since he has so many views in common with its president, Bill Gates, whom he has long welcomed to the Elysée? "Why not?", respond M. Chirac's advisors.
I don't want to encourage any facile Microsoft-bashing here. I often use Microsoft software, generally without complaints, and I have a lot of respect for the research carried out at Microsoft Labs. Still, the idea of Bill Gates being enlisted by Jacques Chirac to defend the world's citizens from the crushing domination of American culture... Well, words fail me, that's all.
With respect to this same idea, La République des Lettres commented, under the headline La Grande Bibliothèque Virtuelle de Jacques Chirac:
Cela semble cependant mal engagé lorsque l'on entend les propos des conseillers du Président de la République -- par ailleurs grand ami de Bill Gates, grand équimentier américain des administrations françaises, reçu plusieurs fois avec tous les honneurs à l'Elysée -- n'excluant pas de s'associer avec Microsoft pour mener à bien ce programme de numérisation contre la domination américaine. LOL (à se rouler par terre de rire), comme on dit sur l'internet.
It seems nevertheless like a bad beginning to hear the suggestion of the advisors of the President of the Republic -- in any case a great friend of Bill Gates, the great american supplier (?) of french administrations, welcomed several times with all the honors of the Elysée Palace -- not excluding an association with Microsoft to accomplish this digitization program against american domination. LOL (rolling on the floor laughing), as they say on the internet.
Um, guys, that would be the acronym ROFL, or else the translation should be whatever the French idiom for "laugh out loud" is -- "rire tout haut"?
Moving right along, Bill will doubtless be happy to learn that Jacques' advisors have concluded that the Euro/MS digital library will cost them more than Google has estimated for its effort:
L'enjeu culturel de ce projet est énorme, mais il est conditionné par la technique, domaine encore plein d'inconnues, qui déterminera lui-même les coûts financiers. "Nous pensons que Google sous-évalue le coût de l'opération, sauf si leur percée technologique est vraiment majeure", estiment les conseillers de M. Chirac, jugeant d'autant plus nécessaire une collaboration européenne sur le plan culturel, technique, financier. "C'est typiquement le genre de projet que le président souhaite porter", soulignent-ils. Ils admettent, sans en préciser le montant ni le calendrier, que l'Etat sera prêt à faire un effort financier pour soutenir ce projet européen.
The cultural stakes of this project are enormous, but it is dependent on the technology, an area still full of unknowns, which will itself determine the financial costs. "We think that Google under-estimates the cost of the operation, unless they have a really major technological breakthrough", M. Chirac's advisors warn, judging it all the more necessary for Europe to cooperate on cultural, technological and financial levels. "It's exactly this type of project that the president wants to carry out", they emphasize. They acknowledge, without being precise about either the quantity or the schedule, that the State will be ready to make a financial contribution to support this European project.
Meanwhile, the Elysée is not getting a uniformly respectful treatment elsewhere in Europe. Scott Lamb at Spiegel Online asks "What Does France Have Against Google?", and comes up with this (fake) search for {french military victories}.
Along with the obvious AFP suit, which is ironically designed to prevent Google's Anglo-Saxon outlook from being tempered by material from the French national news agency, Lamb also lists a set of three small trademark violation judgments in a court in Nanterre, which "found that the practice of letting competitors bid to have their ads appear when keywords containing trademarked words or phrases came up was a violation of trademark law".
Given M. Jeanneney's concern that Google will present the world with "The Scarlet Pimpernel triumphing over Ninety-three... ; valiant British aristocrats triumphant over bloody Jacobins; [and] the guillotine concealing the rights of man and the shining ideas of the Convention...", maybe it would make sense for the Elysée to invest in some Google ads of its own, to direct searchers to right-thinking links for an appropriate set of revolutionary keywords? I don't think that any American or British courts will intervene on behalf of Edmund Burke and the Scarlet Pimpernel.
Seriously, as I wrote a month ago, I wish M. Chirac (and M. Gates?) well in their enterprise, despite some qualms, and I sincerely hope that the clouds on its horizon dissipate rather than thicken.
[Update: the backstory on the relationship between Jacques Chirac and Bill Gates includes this reference in Chirac's recent 1/26/2005 speech at Davos:
For large corporations and private financial organisations, it would be a magnificent undertaking to set up, under their aegis, large international foundations dedicated to the fight against poverty, in the same vein as the Bill and Melinda Gates Foundation. Let us give thought to the promising prospects of co-operation between private and public development stakeholders that such an initiative would bring about.
Chirac and Gates last met in November of 2004, on the occasion of an agreement between Microsoft and Unesco:
Microsoft chairman Bill Gates will sign a co-operation agreement with Unesco today to improve access to computers, the Internet and IT training in developing countries.
The Microsoft co-founder and Koichiro Matsuura, head of the UN Educational, Scientific and Cultural Organisation, will sign the deal at a meeting in Paris, Unesco said in a statement. [...]
After the Unesco meeting, Gates is due to meet Jacques Chirac, the French president’s office said.
Chirac spokesman Jerome Bonnafont said the two men would discuss development issues including the fight against Aids in Africa and the work of the Bill and Melinda Gates Foundation, the billionaire’s philanthropic organisation.
Some other stories on the meeting are here and here. It's probably the recent memory of these stories that led Gurrey and de Roux to ask Chirac's advisors about possible Gates involvement. However, it does seem striking that Chirac went out of his way to mention the Gates foundation at Davos. ]
March 25, 2005
A euphoric dream of being scientific
Kerim Friedman thinks that when I called French post-structuralism "cargo cult linguistics", it was a cheap shot. Actually, being nice about it, he says that I "overstate [my] case", even if the analogy is "cute and apt ... in respect to the crisis engendered by the failure of 60s radicalism". In order to "put linguistics in its rightful place -- genealogically speaking", Kerim offers a helpful quote from Ferdinand de Saussure about the possibility of semiology, defined as "a science which studies the role of signs as part of social life".
Kerim concludes that
Linguistics, for Saussure, was a sub-field of semiotics, and those thinkers who drew from this tradition steadfastly refused to reduce language to a purely psychological phenomenon. Derrida and Bourdieu, for instance, were clearly interested in speech act theory and discourse analysis, even if they didn’t engage in the practices associated with contemporary phonology, morphology, or syntax.
I'll observe in passing that many psychologists would object to the implication that the study of social life is in principle beyond the bounds of their discipline. And while Derrida may have been interested in speech act theory and discourse analysis, I can't imagine that J.L. Austin, H.P. Grice or Barbara Grosz would have gotten much out of an afternoon at the café with Jacques. This is not because Derrida had nothing to say. But there seem to be two very different kinds of intellectual activity here. Those three anglophone thinkers each tried to provide a theory, right or wrong, to engage and elucidate some kinds of facts about human communication. No matter how hard I try to read him sympathetically, I can't convince myself that Derrida is in that game at all. In that connection, it's particularly ironic that American humanists and social scientists have taken to using the term "theory" to describe whatever it is that Derrida and others like him do.
Anyhow, when I first read Kerim's post, I thought he was right. It had all started because I was annoyed by Eric Gibson's suggestion that pomo posturing was "derived from linguistics". The implications of the word "derived" seemed inappropriate to me, and in trying to clarify the relationship I settled on the "cargo cult" idea, which of course I borrowed from Feynman's famous essay on Cargo Cult Science. Now, linguistics has a few conceptual skeletons in its own closet, and so I worried that this might be hypocritical, a rhetorical cheap shot. But I decided to go ahead with it -- if you can't indulge in a little rhetorical flourish once in a while, what's a blog for?
Then Kerim took me to task, in such a nice way, for the "tone" of that entry, and I felt bad about it all over again. However, after thinking about it some more, I've decided that the "cargo cult" phrase finds direct support in the testimony of one of the key historical figures in the intellectual tradition under discussion.
Consider this passage from Philippe Dulac's essay on Roland Barthes, talking about Barthes' role as a founding father of French semiology:
Si donc la sémiologie relève de la linguistique, l’affaire devient relativement simple. Il suffit d’emprunter à la linguistique sa rigueur de méthode et ses concepts les plus opératoires (principalement ces couples fondamentaux que sont : langue/parole, signifiant/signifié, syntagme/paradigme, dénotation/connotation), de prendre pour modèle le système langagier avec ses principes spécifiques d’articulation et de combinaison, pour pouvoir dès lors constituer et analyser en système tout champ social important et traiter en sémiotiques particulières les discours littéraire, cinématographique, musical, voire alimentaire ou vestimentaire. [...] Il n’en est que plus surprenant de voir Barthes, bien loin de le développer et de le dépasser, l’abdiquer superbement, passer rapidement à tout autre chose (ce qui deviendra une coutume chez lui) et en finir avec ce qu’il appellera « un rêve euphorique de la scientificité » – laissant à d’autres les destinées de la sémiologie comme science.
Thus if semiology comes from linguistics, things become relatively simple. It's enough to borrow from linguistics its methodological rigour and its most operative concepts (mainly the fundamental pairs language/speech, signifier/signified, syntagmatic/paradigmatic, denotation/connotation), to take as a model the linguistic system with its specific principles of connection and combination, in order to constitute and systematically analyze every social area, and to treat as particular semiotic systems the discourses of literature, cinema, music, even food and clothing. [...] It's therefore all the more surprising to see Barthes, far from developing and going beyond [these ideas], proudly abdicating them, passing quickly to all sorts of other things (as will become his custom) and giving up entirely on what he called "a euphoric dream of being scientific" -- leaving to others the destinies of semiology as science.
Isn't Barthes' phrase "un rêve euphorique de la scientificité" equivalent to saying that the importation of semiotic terminology into French "theory" of the past half-century was exactly "cargo cult linguistics"?
March 24, 2005
Retrodiction confirmed
In an earlier post, I made an educated guess about Chippewa ("Anishinaabe") verbal morphology:
... I suspect on general principles that the system is quasi-regular: in other words, the relationship between the meaning and the combination of stem-forming elements, prefixes and suffixes is often regular and therefore predictable, but can also often be more or less opaque and "idiomatic".
Within a couple of hours, John Lawler sent a link to a 25-year-old paper confirming the guess: Richard Rhodes and John Lawler, "Athematic Metaphors", CLS 17 (1981). It's not very impressive to predict something that turns out to have been documented in a paper published 25 years ago, but I'll take my successes where I can...
As Rhodes and Lawler explain:
...after some time working in Ojibwe, one of us elicited an item mdwesjiged in a text. From our general knowledge of Ojibwe, we knew that the stem of this word has the morphemes madwe- ‘be/make a sound (at a distance)’, -sid- ‘cause to be in a location/state’, and -ige ‘unspecified object’. By the regular rules of Ojibwe semantics, this means, altogether, ‘make a noise at a distance by moving things around’.
However, our native speaker insisted that this word only meant ‘ring the church bells,’ even though he admitted that the form inflected for definite object, mdwesdood, could be used by someone in one room commenting on noise emitting from another, as, for example, when one sits near the kitchen in a restaurant. It was only after some prodding that he allowed that, in fact, mdwesjiged could refer to other situations in which things were being moved around and were making noise, but were out of sight.
Now one might think, as we at first did, that this was simply a reaction to the situation in which this word was being discussed, but subsequent elicitation has shown that one of the “meanings” of mdwesjiged is ‘ring the church bells,’ although people who come from Protestant areas, where church bells are less prevalent, don’t get this reading as strongly. Similarly, enormous numbers of Ojibwe words whose semantics are clear from their structure and which can be used in those meanings have important restrictions on their “meanings” in normal usage.
You could compare this to an English compound like "chair lift". Most people will tell you that it refers to a particular kind of contraption found on ski slopes, which carries people up the hill on chairs suspended from a cable. But according to the regular semantics of English, "chair lift" could be used to refer to many other things, for example to a kind of exercise done while sitting in a chair, or a scheme for storing extra furniture by hanging it on the wall. Similarly, a "spark plug" could be a device to keep live embers from escaping from a chimney -- but it isn't, it's a very specific part of certain types of internal combustion engine. Or consider conscription, which literally means "writing together", but normally refers to being drafted into military service.
Rhodes and Lawler give some other examples:
Form |
Semantics |
Meaning |
| zhisjiged | put things in a certain place | set the table |
| zhising | be laying in a certain way | be written |
| gshkitod | be able | afford |
| aanjpizod | change s.t. tied | change a bandage |
| dbaaknigaazod | be judged | be in court |
| miijgaazod | be given s.t. | be on welfare |
They interpret these as cases where extra meanings arise from a "prototype context" whose properties are carried along as a particularization of a more general, compositional sense. They contrast these with idioms where the compositional meaning is lacking
Form |
Semantics |
Meaning |
| giiwsed | *walk around | hunt |
| mzinhigan | *s.t. to carve/write on/with | paper, book |
| mzinhiged | *carve/write | get credit |
| namhaad | *greet | pray |
| zaaghigan | *s.t. to get out with | lake |
| waawaaskone | *light | flower |
| baashkzang | *burst/break s.t. with heat | shoot s.t. (with a gun) |
and/or where (they feel that) the meaning is not a predictable consequence of any "prototype context":
Form |
Semantics |
Meaning |
| zaaghaad | be stingy with s.t. (animate) | love s.o. |
| waabgookookoo | white owl | wedding cake |
| mnidoons | little spirit | flying insect |
| baasod | be dry | be thirsty |
Whatever the right taxonomy is, it's clear that the Chippewa/Ojibwe system of stem-forming elements, prefixes and suffixes is a rich combination of regularities, subregularities and irregularities -- just like every other such system I've ever learned about.
Spatial gender
Last year, I heard an interesting talk by Len Talmy entitled " How Spoken and Signed Language Structure Space Differently". He started out by talking about cross-linguistic properties of closed-class forms (like prepositions or verbal affixes) that specify spatial structure, and what he said got me thinking about how complicated the interaction of prepositions and their head nouns can be, even in one language. Yesterday I cleaned out my briefcase and found the handout from his talk, on which I'd jotted down some notes about in and on in English, which I've expanded into the rest of this post.
For anyone who knows what the words mean, it's not surprising that you put something in the oven but on the stove.
However, it's somewhat less clear why you put something in the picture but on the screen, why the people who are in your heart are often on your mind, or why a file is in a folder but on the desktop. There's an obvious story about the relationship between preposition choice and the shades of meaning in such expressions, but it's not obvious whether a basic feature of the expression's meaning causes a certain preposition to be used, or alternatively an arbitrary choice of preposition in the expression generates an difference of interpretation. And when we get to the difference between being in town and being on campus, or for that matter the difference between being in time and being on time, we're pretty clearly in the realm of idiomatic phrasal patterns.
We get in a car, but most forms of transport are things we get on: a train, a ship, a plane, a bicycle. Is that because we basically think of trains, ships and planes as platforms that carry us, even though we generally ride inside them, while we view cars as spaces that we inhabit? Or is it because the passenger-carrying parts of trains, ships and planes are generally high up? Does the relatively small size of cars matter? In any case, the choice between in and on is not simply an arbitrary property of words for vehicles -- it depends on the meaning of the words. If you tell someone to get on the jeep, the van or the Buick, you mean for them to climb on the hood or the roof or to do something else that treats the vehicle as a platform. However, if you tell someone to get on the downtown local, or next flight to Tibet, or the Queen Elizabeth, or the 8:17, you just mean for them to get into the vehicle's passenger-carrying space in the usual way.
In this web example of getting on a car, car turns out to mean streetcar:
To get on the car, take hold of the front railing with the hand toward the front of the car, raise the corresponding foot to the step, and you are safe.
There are other examples where the distinction between in and on is predictable according to semantic class, even if assignment of preposition to class seems to be arbitrary. Thus someone appears in a play (in Macbeth, in Tom Stoppard's latest, in a student production), but on a recurrent show (on Letterman, on Saturday Night Live, on 20/20) or a media outlet (on CBS, on cable, on pirate radio, on the stage, on the runway -- but in the movies). Is a production of a play in some sense a container in which people are placed, while a named show or a communications medium is in some sense a surface on which people are displayed? Perhaps so, but I'm not sure whether this conceptual distinction precedes or follows the linguistically-determined choice of preposition.
Sometimes a class of semantically-similar words seems to split between in and on in lexically-arbitrary ways. An item is in the index, the table of contents, or the specifications; but on the agenda, the menu, the docket or the feature list. Is that because an index or a table of contents is a kind of container, while an agenda or a menu is a surface? You might think that this follows somehow from the idea that an index or table of contents is a fixed collection of items, while an agenda or menu involves different items on different occasions. This might have something to do with the origin of the difference. But stories are listed in the table of contents of a weekly magazine, while dishes are listed on the menu of a restaurant that hasn't changed its selections in years.
The combinations of bare singular nouns with in or on are all clearly idioms, and in some cases there's no semantic basis in current usage for the distinction: the fact that I'm in town but on campus is now as arbitrary as the fact that I can't be either in or on village, city or park (unless "park" is the same for an automatic-transmission state, in which case I can be metonymically in it...) In some of these [P N] idioms, though, the choice of preposition makes sense. Trouble is clearly something you're going to be in, rather than on, while you're on message or on target in the same sense that you can be on the rails or on the path to a destination. It's less obvious why you go on vacation but stand in line. It makes sense that something under control is in hand, but it's less obvious why something is on hand when it's in stock.
These patterns of preposition usage are reminiscent of the distribution of grammatical gender, or the related case of noun-classifier systems with multiple categories. These are partly determined by meaning in a simple way (e.g. by the sex of the referent), partly by meaning in a more complicated way (e.g. by extension to semantic categories that aren't connected directly to sex), and partly by arbitrary lexical assignment.
Lera Boroditsky's work (e.g. her paper on Sex, Syntax and Semantics) suggests that a language's quasi-regular patterns of grammatical gender can affect the way that speakers think about the referents of the words involved. It seems reasonable that the similarly quasi-regular patterns of preposition choice -- which notoriously differ from language to language -- might also affect people's associations with the concepts involved.
Postscript: it's interesting to look at what's involved in getting web-corpus support for the claim that cars take in while other modes of transportation take on. Raw Google counts go in the right direction, but not very strongly:
in |
on |
||
the car |
5.93M |
1.58M |
79% in |
a car |
4.18M |
674K |
86% in |
the bus |
306K |
2.77M |
90% on |
a bus |
187K |
677K |
78% on |
the plane |
1.08M |
1.15M |
52% on |
a plane |
668K |
894K |
57% on |
the train |
307K |
1.36M |
82% on |
a train |
172K |
733K |
81% on |
Looking at the minority examples makes it clear that nearly all of them are not relevant, for structural or semantic reasons:
A US armored vehicle in Iraq fired on the car carrying the freed Italian hostage...
...the numerous cameras positioned on the car allow you to share your driving experience with others...
Refuse to pay for it, even if it's on the car- they only paid $15 for it...This page contains quick descriptions of the four types of symmetry in the plane.
Since the heliport control tower is strangely invisible in the "plane" photo...
The line in the plane with i = 0 is the real line.
If we add some context, such as "get in X" vs. "get on X", the numbers are much more nearly categorical:
get in |
get on |
||
the car |
147K |
2.33K |
98% in |
a car |
29.8K |
688 |
98% in |
the bus |
2.19K |
174K |
99% on |
a bus |
494 |
28.9K |
98% on |
the plane |
2.04K |
51.7K |
96% on |
a plane |
588 |
64.7K |
99% on |
the train |
918 |
39.4K |
98% on |
a train |
280 |
14.2K |
98% on |
Again, most of the (now few) contrary examples are not relevant:
If no moisture is present, and dust and dirt cannot get on the car, the car will be removed in the same condition as when stored.
This ensures that no resin will get on the car and gives you a surface to work on
That means the chances of seeing another in the valet parking lot outside Saks Fifth Ave. are about as slim as the dealer discounts you'll get on the car.The officers are sometimes collecting a blue form, which you might get in the plane.
How would Anthrax get in the plane?
One comedian once pointed out that an airport loudspeaker might announce. "Last call for Flight 104. Time for all passengers to get ON the plane" "No thanks", said the comedian, "I'll get IN the plane."
However, especially with airplanes, there are some genuine contrary examples (i.e. with in). Many of these seem to be cases where the plane is a small one -- people seem to treat small aircraft like cars from this prepositional point of view:
(link) Time to get in the plane. You have to get yourself in first, then retrieve your stuff. [about a glider]
(link) Here, you get to fly within the second week of class. You get to get in the plane and get going right away! [about a flight school]
(link) Most people get in the plane and then consider it a victory if they crash into something that doesn't belong to their own team. [about a video game]
(link) As long as you get in the plane (which you will bc it doesn't get scary till youre in the plane) but once youre in the plane you don't have much of a choice! [about skydiving]
(link) Now I can just get in the plane and go fishing anywhere in the Western US, and be there in just a few hours.
Others seem to involve a special perspective on the process:
(link) Are you sure can get in the plane? [about fear of flying]
(link) We thought we would get in the plane first considering the amount of kids we have, but we waited like the rest of the pack.
(link) At the very last moment, one member of the crew came racing out of an automobile to the plane, carrying on all of his spare uniforms and clothing, running as hard as he could to get in the plane.
As usual, it would be very helpful to be able to get a random sample (i.e. not biased by page rank or similar things) of the hits for a given pattern.
[Update: Nicholas Sanders sent in some relevant information about Danish:
If it be assumed (not unreasonably) that på (paa) stands for on and i for in, the matter of why one is på posthuset (on the post office) but i banken(in the bank) is a puzzle, and not only for learners.
Perhaps a clue may be found in that one is also på biblioteket (on the library), på hospitalet (on the hospital), and på arbejde (on work - on the job?), but i skolen (in the school) or i butikken (in the shop).
I suggest a connection with the number of the institutions concerned, at least in the past when a human settlement of a certain size would have had just one each of the på group, but a few of each of the other category - work might have been included in the former because every adult male would have had a defined job, so that his occupation was likened to the official status of the other examples.
If his analysis of the på/i distinction for building-like locations is correct, then Danish has crystallized a locative subregularity that (I believe) is missing in English. What seems to happen in such cases is that a local association spreads, to some greater or lesser degree, along a dimension that is salient in the initial exemplars. The spread of such patterns is limited as they bump up against regions in which other patterns hold, somewhat in the manner of grain boundaries in polycrystals. ]
[Update #2: John Cowan wrote:
New Yorkers (and immigrants like me) "stand on line", as is well known. What seems not to be so well known is the semantic difference between "get in line" (form a line) and "get on line" (enqueue yourself to an existing line). I'm told that this distinction has spread to the Twin Cities as well, supposedly through the medium of New Yorker Catholic teaching nuns.
"Get on line" is under some pressure from its homonym "get online" (connect to the Internet), though.
I've never lived in New York, nor been taught by nuns, but I have the same "get in line"/"get on line" distinction. ]
March 23, 2005
EuGoogle advances
Jacques Chirac is signing up with Jean-Noel Jeanneney's campaign to launch a European competitor to Google Print (previous Language Log discussion here and here). French Minister of Culture Renaud Donnedieu de Vabres
...denied the French initiative was an "anti-Google operation".
"It is about a desire for everyone to be able to put forward their talents, heritage, history and culture," he told French newspaper Le Monde. "There's nothing hostile about it."
The article in The Times quotes M. Jeanneney to the effect that
...the "heavily biased" British and American version of the French Revolution would be all about "valiant British aristocrats triumphing over bloodthirsty Jacobins and the guillotine blotting out the rights of man".
I wonder if he really said this. It's bizarrely disconnected from the reality of the situation. Looking through the first couple of pages of returns from Google for { French revolution} or (limited to French-language pages) { revolution francaise}, I couldn't find a single mention of a British aristocrat, heroic or otherwise...
Anishinaabemowin
The Red Lake Band of Chippewa have been in the news recently, because of the tragic killings at the Red Lake high school. The Native Languages of the Americas site has a page on the Chippewa language, from which you can learn that other anglicized versions of the name include Chippewe, Ojibwa and Ojibway (all of which come from the same Algonquian word meaning "puckered", apparently referring to a characteristic style of moccasin), and that the language is "known to its own speakers as Anishinabe or Anishinaabemowin". According to the same page, "the Ojibwe are one of the most populous and widely distributed Indian groups in North America, with 150 bands throughout the north-central United States and southern Canada", and the language of the Anishinabeg "is among the heartiest of North American languages, with many children being raised to speak it as a native language."
The Ethnologue gives "Ojibwa" the language code oji in ISO 639-2, and applies this code to seven languages listed separately as Chippewa, Central Ojibwa, Eastern Ojibwa, Northwestern Ojibwa, Severn Ojibwa, Western Ojibwa, and Ottawa. An eighth language of the same subgroup of the Algonquian family, Algonquin, is listed separately, apparently for historical rather than linguistic reasons.
The Encyclopedia of North American Indian's article on the Ojibwa Language, written by John Nichols, is also on line. It contains a fair amount of detail, presented in the form of illustrative examples:
A typical Ojibwa sentence contains a multipart verb, the core meaning of which is carried by a verb stem, itself composed of meaningful elements. In front of the stem may come prefixes, one of which can show the person (first, second, or third) of a subject or object; others show grammatical ideas such as tense or location, or modify the core meaning. In the verb ningiiani-maajii-babima'adoon, "I started following and following it (a road) along," the first four prefixes are - nin-, indicating first person; gii-, past tense; ani-, away from the speaker; and maajii-, "start to." The last prefix, ba-, which indicates that the action was extended in time or space ("following and following"), also offers an example of reduplication, a process by which a prefix takes its shape from the stem by copying its first consonant and adding a vowel: the first syllable bi of bima'adoon, "follow it along," when combined with the reduplicated prefix made from it, becomes babi in babima'adoon, "follow and follow it along."
After the stem there are more than a dozen slots for suffixes indexing grammatical ideas such as order (determining whether the verb is a main clause, subordinate clause, or command verb); the person, number, and gender of the subject and object, and their relationship; negation; and verb mode. The verb ningii-wiiganawaabamigosiinaabaniig, "they didn't want to look at us (but they did)," includes a stem—ganawaabam, "look at someone"—and the suffixes -igo, indicating that the subject of the verb is a third person and that the first person referred to by the prefix nin- is the object; -sii, negation; -naa, "us"; ban, unrealized action; and -iig, "they."
Nichols takes a Whorfian line on what this all means:
The meanings of the stem-forming elements and their patterns of combination represent a unique Anishinaabe way of viewing human experience and the natural world.
This way of thinking seems to be a natural result of time spent in analyzing such morphological systems -- it's the flip side of the revelations of polysemy that John McWhorter wrote about here back in the fall of 2003. Nichols is understandably enthusiastic about the Anishinaabe system of stem-forming elements:
Their creative use allows speakers to talk about and name new things as well as known ones. A typical stem has two or three main parts, each selected from distinct sets of hundreds of elements. The first part is an initial, often a root of shape, size, color, spatial relationship, or direction, such as azhe-, "backwards"; babaami-, "going about"; giishk-, "severed"; miskw-, "red"; and, nabag-, "flat." The last part is a final, which often carries meanings close to those of English verbs. A few of these are -aadagaa, "swim"; -aashi, "blown (by the wind)"; -batoo, "run"; and -shin, "lie or fall against something." Thus there is not just one verb stem meaning "run," as in English, but many, each blending a different initial with the final -batoo, "run," as in azhebatoo, "runs backwards"; bimibatoo, "runs along"; babaamibatoo, "runs about"; and bejibatoo, "runs slowly."
Other finals describe the means by which something comes about, among them -aakiz, "by flame"; -bood, "by back-and-forth motion (as in sawing)"; and -zh, "by blade." A look at a few stems meaning "cut" can illustrate how different the Anishinaabe analysis of events can be from that of English. The initial tells about the result of the cutting and the final about the way the cutting was done. For example, if the cutting resulted in something being cleanly cut or severed, the initial is giishk-. Adding the final -zh gives giishkizhan, "cut it (with a knife)"; the final -bood gives giishkiboodoon, "cut it (with a saw)"; the final -aakiz gives giishkaakizan, "cut it (with a flame, as with a welding torch)." If the result is that something is split, the initial daashk- is used: daashkizhan, "cut it (with a knife and have it split)"; daashkaakizan, "cut it (with a flame and have it split)." If many pieces result, the initial is biis-, as in biisizhan, "cut it (to pieces with a knife)."
An optional intervening medial element describes things connected with the verb. It can classify things affected, as in giishkaabikizhan, "cut it ([something of metal or rock] with a knife)," where the medial is -aabik-, "something of metal or rock"; or daashkaakoboodon, "cut it ([something sticklike] with a saw and have it split)," where the medial is aako-, "something sticklike." In the verb giishkinikezh, "cut off someone's arm," the medial is the more specific and nounlike -nike-, "arm."
The most nearly comparable parts of the English lexicon seem to be the combinations of verbs with prepositions ("run along", "run out", "run up", "run in", "run off", "run over", etc., and the creation of various sorts of compounds ("flame-broiled", "arc weld", "sparkplug"). Alternatively you could look at the system of English compound words made of Greek and Latin bits, like {in-|con-|per-} {-form|-spire}. English doesn't incorporate as much stuff into a typical word, but there are some similar patterns on a smaller scale. (I was going to say that you can "flame cut" something, and you can "cut off" something, but you can't "flame cut off" something; but a web search turned up the sentence "To get the old stuf off he is most likely going to flame cut it off". Go figure.)
Although I don't have any specific knowledge of Anishinaabe verbal morphology, I suspect on general principles that the system is quasi-regular: in other words, the relationship between the meaning and the combination of stem-forming elements, prefixes and suffixes is often regular and therefore predictable, but can also often be more or less opaque and "idiomatic". This sort of thing is well known in the derivational morphology of languages like English, but has been less studied in the case of richer derivational systems in languages like Ojibwa or Navaho, where the complexity of the system (and its status as a second language for most analysts) tends to emphasize analytic decomposition over lexicographic nuance.
March 22, 2005
Up with (more) good, down with (more) bad
Yesterday, I heard a fascinating talk on intonational meaning in Japanese. Conclusion: speakers use higher pitches for more intense or emphatic evaluative phrases -- when the evaluation is positive. When the evaluation is negative, speakers use lower pitches for more intense or emphatic evaluation. This was true in conversational speech, but when speakers read lists of phrases, no such effect was found.
The talk was given by Yoshinori Sagisaga, for many years a researcher and research manager at ATR, and now a professor at Waseda University. He described some experiments (done in collaboration with Takumi Yamashita and Yoko Kokenawa) on the sort of simple adverb+adjective phrases that someone might say in response to a "how is it?" question, e.g.
Q. "Aji doo?" (How does it taste?)
A. "Hijooni umai" (It's extremely tasty.)
These phrases involved a number of adverbs, in decreasing scalar intensity:
| hijooni | extremely |
| sootoo | very |
| wariai | quite |
| sokosoko | relatively |
| futsuuni | normally |
| anmari | not so much |
and also a number of adjectives, which come in "positive" and "negative" pairs like clean vs. dirty:
positive |
negative |
+ |
- |
kirei |
kitanai |
clean |
dirty |
umai |
mazui |
delicious |
unsavory |
kawaii |
busaiku |
charming |
ugly |
yasasii |
kibisii |
mild |
strict |
omosiroi |
tumaranai |
interesting |
boring |
When subjects read such phrases in lists, the pitch contours were basically all the same (these examples are chosen to use accentless four-mora adverbs and adjectives, for ease of comparison, and the plot shows the fundamental frequency at the mid-point of each mora):
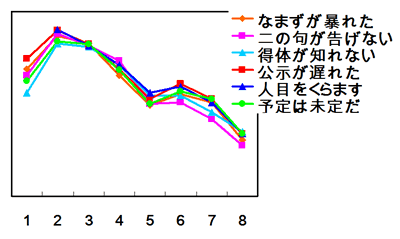
Things were different when people were giving their evaluation of a scene, situation, substance etc. in conversation with an experimenter. In this case, the scalar intensity of the adverb interacted with the emotional direction of the adjective. For positive adjectives (clean, charming, interesting, etc.), more adverbial intensification produced higher pitches (this plot shows pitch values at vowel mid-points for six adverbs):
and this plot shows the (proportional) difference between conversational speech and read speech for the highest pitch of each adverb:
In contrast, for negative adjectives (dirty, ugly, boring, etc.) , more adverbial intensification produced lower pitches (this plot shows the proportional difference between conversation speech and read speech for highest pitch of each available adverb):
This table gives the correlation between adverb F0 and adverb intensity:
| Correlation between adverbial F0 and adverb "intensity": | |
| Read speech | (no significant correlation) |
| Conversational speech, positive adjectives |
+0.85 |
| Conversational speech, negative adjectives |
-0.83 |
Sagisaka also did some perceptual experiments, in which 10 subjects listened to combinations of adverb+adjective at 12 different overall pitch levels, and judged them on a five-point scale from 1 (very bad) to 5 (very good). The average judgements for the positive adjectives showed preference for higher pitch with greater intensification:
max F0 (Hz) |
not at all |
not so much |
normally |
relatively |
quite |
very |
extremely |
185( F# ) |
1.56 |
1.42 |
1.70 |
1.96 |
2.26 |
3.48 |
3.78 |
174 ( F ) |
1.76 |
1.62 |
2.14 |
2.48 |
2.60 |
3.74 |
4.10 |
164 ( E ) |
2.10 |
2.00 |
2.62 |
2.94 |
3.18 |
4.00 |
4.16 |
155 ( D#) |
2.36 |
2.56 |
3.20 |
3.48 |
3.82 |
3.98 |
4.06 |
146 ( D ) |
2.84 |
2.88 |
3.52 |
3.72 |
4.04 |
3.84 |
3.98 |
138 ( C#) |
3.20 |
3.16 |
3.96 |
4.14 |
4.14 |
3.56 |
3.50 |
130 ( C ) |
3.48 |
3.50 |
4.12 |
4.18 |
4.00 |
3.28 |
3.12 |
123 ( B ) |
3.80 |
3.90 |
4.10 |
3.98 |
3.64 |
2.94 |
2.70 |
116 ( A#) |
3.98 |
4.08 |
3.66 |
3.60 |
3.30 |
2.50 |
2.38 |
110 ( A ) |
4.34 |
3.92 |
3.12 |
3.00 |
2.66 |
2.20 |
1.94 |
103 ( G#) |
4.34 |
3.72 |
2.56 |
2.56 |
2.36 |
1.84 |
1.64 |
98 ( G ) |
4.18 |
3.54 |
2.30 |
2.32 |
2.12 |
1.70 |
1.54 |
The judgments for the negative adjectives showed preferences in the opposite direction:
max F0 (Hz) |
not at all |
not so much |
normally |
very |
extremely |
185 ( F# ) |
2.80 |
2.32 |
1.52 |
1.96 |
2.20 |
174 ( F ) |
3.12 |
2.72 |
1.78 |
2.26 |
2.32 |
164 ( E ) |
3.46 |
3.22 |
2.24 |
2.46 |
2.46 |
155 ( D#) |
3.50 |
3.56 |
2.82 |
2.62 |
2.52 |
146 ( D ) |
3.64 |
3.72 |
3.22 |
2.88 |
2.84 |
138 ( C#) |
3.66 |
3.86 |
3.66 |
3.22 |
3.26 |
130 ( C ) |
3.52 |
3.80 |
3.92 |
3.64 |
3.50 |
123 ( B ) |
3.10 |
3.60 |
4.14 |
3.80 |
3.84 |
116 ( A#) |
2.74 |
3.10 |
4.06 |
4.04 |
3.92 |
110 ( A ) |
2.38 |
2.54 |
3.76 |
4.12 |
4.14 |
103 ( G#) |
2.18 |
2.34 |
3.54 |
4.22 |
4.12 |
98 ( G ) |
1.94 |
2.08 |
3.44 |
4.04 |
3.94 |
I suspect that English speakers would show similar effects, at least in some circumstances.
March 21, 2005
Axe a stupid question
Safire's "On Language" column in the New York Times Magazine of 3/20/05 (p. 26) has a segment on nucular that strikes me as deeply confused. It also fails entirely to mention Geoff Nunberg's book Going Nucular and the piece that gave the book its title (not to mention the various Language Log postings that have discussed this pronunciation: here, here, here, here, and here). I would have thought that the title of Geoff's book would be a pretty clear hint that the pronunciation nucular was going to be discussed somewhere in the volume.
Instead, Safire asked for Steve Pinker's advice, and Pinker came up with a metathesis account -- Safire dutifully defines "metathesis" and indicates its pronunciation -- that can't be the right story. Here's how Safire starts his analysis:
I'm not sure how to share out the blame here -- to Safire, to Pinker, to Safire for consulting Pinker instead of a linguist who's thought about the phonology at issue. But there are at least four problems with what Safire says, and two of them are serious.
Problem 1, a minor annoyance: "the smallest units of sounds" isn't going to elucidate the notion of "phonemes" to anyone who doesn't already know what phonemes are. It's just baffling.
Problem 2, more serious: "an unfamiliar sequence of phonemes". As Geoff points out in his book, the /liǝr/ at the end of "nuclear" isn't at all unfamiliar to or difficult for speakers of English: comparatives like pricklier are unproblematic and show no inclination towards being reshaped. The problem with nuclear isn't phonological but morphological, and that's why words in -cular /kyǝlǝr/ are relevant; they appear to have some sort of root ending in c /k/, followed by morphological elements ul /yǝl/ and ar /ǝr/, or perhaps an indivisible ular /yǝlǝr/. (Back on 7/3/04, in fact, Alison Murie suggested on ADS-L that nucular might be a reanalysis in which the root is the word nuke, and the word nucleus isn't involved at all. And Geoff entertains a similar idea in his article, noting that this would predict a difference, for some people, between nuclear in things like nuclear family and nucular in things like nucular weapons.)
Problem 3, also serious: getting the metathesis proposal to work. Metathesis of the /l/ and /i/ of /nukliǝr/ would give /nukilǝr/, with primary accent on the first syllable and secondary accent on the second (as in nuclear). To get towards nucular, that second syllable would have to lose its accent (this is not particularly unlikely), yielding /nukIlǝr/ or /nukǝlǝr/. This isn't all the way home, though, because there's still that /y/ to pick up. It looks like Safire is assuming a metathesis and then a reshaping to match other -cular words, which would supply a /y/. But direct reshaping is a more parsimonious account of the phenomenon; the metathesis is unnecessary (as well as insufficient).
Problem 4, another mere annoyance. Safire is being really sloppy when he says that nuclear rhymes with cochlear. It doesn't, because the accented vowel /u/ of nuclear doesn't match the accented vowel /o/ or /a/ (depending on your pronunciation) of cochlear. ( If they "rhyme", then so do noodles and models.) Rhyme involves a matching between accented vowels and everything that follows them. The pair nuclear/cochlear is a kind of almost-rhyme, in which everything that follows the accented vowels matches. Almost, but definitely no cigar.
[An earlier version of this critique appeared on ADS-L on 3/21/05. My thanks to Geoff Nunberg for suggesting the title.] zwicky at-sign csli period stanford period eduCargo cult linguistics
In response to my defense of our field from the charge that certain formerly-fashionable French literary theories were "derived from linguistics", several knowledgeable readers wrote in with references to Saussure and Levi-Strauss, quotations about Foucault from Piaget's Structuralism, and so on. OK, we're busted. I have to confess that there is a connection, although as far as I know, none of the French theorists in question ever actually learned anything much about linguistics, or ever actually engaged in linguistic analysis of the sound, form and meaning of words or sentences.
The transmission of influence seems to have been something like this: the anthropologist Claude Levi-Strauss was influenced by the linguist Roman Jakobson during WW II in New York, and after the war, Levi-Strauss in turn brought some of the ideas and terminology of semiotics and structuralism back to Paris. This contributed to the intellectual compost in which thinkers like Barthes, Foucault and Derrida germinated.
There's an excellent explanation of these influences in The Johns Hopkins Guide to Literary Theory and Criticism, which is available on line to subscribing institutions (and for the most part is remarkably readable, in contrast to the material it describes). Here's a bit of the entry on semiotics:
French semiotics, which developed directly from Russian Formalism and Prague structuralism and arrived in Paris via New York thanks to Roman Jakobson's influence on Claude Lévi-Strauss during World War II, made a critical contribution to the study of literary texts during the mid-1960s. A special issue of Communications, edited by Roland Barthes in 1966 and devoted to the structural analysis of narrative, contains articles by the leading European semioticians who had a profound impact on the future and evolution of literary semiotics. In his introduction, which owes a great deal to Louis Hjelmslev's rethinking and development of Saussure's concepts of sign, system, and process, Barthes ascertains that narrative analysis must be based on deductive procedures and must construct hypothetical models patterned on structural linguistics. He proposes a multilevel model of analysis in which each level is in a hierarchical relationship to the others and narrative elements have both distributional (if relations are situated at the same level) and integrative relationships (if situated at different levels). In turn, levels are defined as operations or systems of symbols and rules. Barthes then delimits three linked levels of description--"functions," "actions," and "narration"--in which a function has meaning only within the field of action of an actant, and action is meaningful only when narrated.
And from the entry on Barthes:
... Barthes was eager to promote his French brand of Structuralism for only a few years before he rejected most of its methodological assumptions. [...] His numerous essays and books, written over 25 years from the 1950s to the 1970s (some published posthumously in the 1980s), have taught a whole generation "how to read" (to quote Ezra Pound) and have accompanied that generation through increasingly rapid changes in theory. Besides, even though he retained a set of favorite concepts, Barthes's own swiftness of mind rendered these concepts mobile and capable of important shifts in meaning...
I think it's fair to call this "cargo cult linguistics". Just as some post-war islanders in the South Pacific engaged in ritual imitations of the airstrip activities of foreign armies, in the belief these actions would bring them cargo, so some post-war philosophers in Paris engaged in ritual imitations of the analytic practices of linguists, in the belief that these actions would bring them insight. The islanders carved wooden radio sets and sat mumbling in imitation control towers; the philosophers invented semiotic terminology and sat disputing in Parisian cafes. And just as the failure of cargo to arrive as expected led to social crises and theological reformations in the South Seas, the failure of stable insight to emerge in Paris led to "rapid changes in theory" and to "mobile" concepts expressed in an increasingly opaque style.
More from the JHU semiotics entry:
It is possible to trace two major tendencies in France that evolve from the intellectual activity of the mid 1960s. The first, founded on the Saussurean-Hjelmslevian legacy, best represented by work done by Greimas, has become known as the "Paris school" of semiotics. [... ]
The second tendency is represented by the large number of works that draw their inspiration from a radical questioning of the structural principles defining semiosis. Julia Kristeva and especially Roland Barthes were instrumental in this respect. Indeed, the latter begins his study S/Z by challenging the very possibility of structural analysis to account for the specificity or individuality of any text. He then shifts the problematics from that of science and ideology to that of writing and rewriting, in short to a semiotics of addressers and addressees, of signs and interpreters. In so doing he also substitutes a semiotics of codes for a semiotics of signs and processes and, without structuring or hierarchizing them, determines five codes under which all the textual signifiers can be grouped: hermeneutic (enigma), semic, symbolic, proairetic (actions), and cultural (references to a science or body of knowledge).
And to take things to yet another level, here's a quote from the entry on Derrida:
... one might say that Derrida uses this theory of the sign--a purely diacritical mark, made up of absence, since in language there are "only differences," according to Saussure--to criticize Husserl and Heidegger, while bringing the phenomenological inquiry to bear on the foundations (or lack of foundation) of structuralist scientism, thus forcing two very different traditions to grind ceaselessly against each other.
This seems to be a form of religious syncretism, in which the symbols and rituals of historically different cults are similarly made to "grind ceaselessly against each other".
In this situation, to assign blame (or if you prefer, credit) to linguistics for French literary theory is rather like saying that the clothing preferences of today's urban youth are "derived from prison". There's a historical connection, but we're talking about social gestures that pick up bits of the surface of things and give them a completely new significance as emblems of group identity.
March 20, 2005
Tighty-whities: the semantics
Now that Mark Liberman has looked at the phonology
of tighty-whitey (and tidy-whitey and tidy-widy), let's take a quick
first glance at the semantics. To simplify things, I'm going to
reduce the profusion of spellings described here
to one spelling, and in the plural (but, like briefs, with reference to an
individual object) : tighty-whities.
What makes this an interesting question is that the expression is so
recent -- so far it's been traced back to 1990, and is surely a bit
older than that, but its absence from the standard dictionaries and
sources of information on word and phrase histories suggests that it's
probably not more than twenty or so years old -- that you might not
have expected it to have drifted very far semantically. It's also
so (apparently) transparent that you might have expected the components
of tightness and whiteness to have maintained themselves over those few
years. But, as it turns out, the gloss 'men's briefs', even
amended to include whiteness and tightness, doesn't really do the trick.
For a long time, there were briefs, and there were boxers, and briefs
were white, made of cotton, had fly-fronts, had no legs, and caught a
man's equipment in a pouch (hence, were "tighter" than boxers).
These are still the prototypical briefs, though for decades they've been
available in colors and in other fabrics (like silk), without
fly-fronts (these are "bikini briefs", though they aren't necessarily
minimal objects), and in generous dimensions (so, not
constricting). There's even the hybrid the "boxer brief", with
both legs and a pouch.
So the question is: which of these objects count as tighty-whities?
I think that the fly-front is
still non-negotiable (so that American tighty-whities correspond to
British Y-fronts): snug white cotton BIKINI briefs for
men are not tighty-whities. But all the other components already
seem to be negotiable, so maybe this one will become flexible too, and
people will start talking about bikini
tighty-whities. It's already possible to find references
to loose tighty-whities, to red tighty-whities and black tighty-whities
(one writer wonders whether the black ones should be called tighty-blackies), and to silk
tighty-whities.
It looks like the current best gloss for tighty-whities is 'fly-front
briefs', perhaps amended by 'usu. snug, white, and cotton'. The
'men's' component comes for free, given the fly-front component:
fly-front briefs are intended for men, though they can of course be
worn by women (for whatever reason). (There are bikini
briefs made for women, though the line, if there is one, between these
and panties is unclear to
me. Sometimes I think that bikini briefs are just panties for
men. Hey, I wear them myself, and have for decades. I'm not
criticizing guys in bikini briefs.)
A further subtlety is the evaluative dimension of tighty-whities.
It's not entirely clear to me whether the judgments here are directly
on fly-front briefs (esp. snug white cotton ones) and the sort of men
who would wear them, or whether there's an evaluative dimension to the
expression tighty-whities
itself. Both things are possible: sometimes judgments cut across
linguistic expressions, other times they're attached to specific
expressions.
I just don't know what this social world is like, in detail. I
know that some American speakers now view tighty-whities as a negative,
dismissive label (perhaps through association with uptight and tight-assed and even the racial tag
whitey), in a way that (I
think) Y-fronts just doesn't
function in British English, even for people who think Y-fronts are,
well, boring. I know that some people didn't used to have those
judgments. I suspect that some of this is fashion in dress and
some of it is fashion in language, and that it's different for
different people, but I have no idea what the details are like.
zwicky at-sign csli period stanford period edu
Raising and lowering those tighty whities
We're talking about vowels here, of course. At least, we will be, once some preliminaries are out of the way.
In his post on tighty/tidy whities, Arnold Zwicky mentioned that tighty and tidy are pronounced almost but not quite the same, due to the flapping and voicing of the intervocalic (i.e. between-vowel) /t/ and /d/. This is worth discussing a bit, at least for those who are interested in English pronunciation.
First issue: flapping and voicing. In nearly all varieties of North American English, /t/, /d/ and /n/ turn into a short tongue-tip tap when they precede a vowel and are not in the onset of a stressed syllable. In the same contextss, /t/ also becomes "voiced", i.e. it loses the feature that distinguishes it from /d/. Here are some examples of such contexts for /t/:
| Flapping/voicing happens: | Flapping/voicing doesn't happen: |
attic |
attack |
at all |
a tall |
sincerity |
fourteen |
As a result, words that are historically distinguished by /t/ vs. /d/ can become essentially homophonous. In my own pronunciation, for example, latter and ladder are homophones, unless I'm trying hard to convey the distinction (which I would do by artificially suppressing the voicing process).
Second issue: vowel length before voiceless vs. voiced consonants. In most dialects of English, the voicing of syllable-final consonants makes a big difference to the duration of the previous vowel, especially in phrase-final stressed syllables. For example, in a fully-stressed syllable at the end of a phrase, the vowel in mad might be half again as long as the vowel in mat. This effect is much smaller in syllables that are medial and/or less stressed.
For some speakers, there can be a sort of residue of this difference in vowel length in cases where the consonant voicing has disappeared, so that the first vowel in bedding may be a little bit longer, on average, than the first vowel in betting. But the effect, where it exists, is typically very small relative to the normal variation in vowel duration for other reasons. In fact, it's hard to find clear evidence for this effect, outside of cases where facultative disambiguation may be involved. In my own speech, I'm pretty sure that betting and bedding are indistinguishable, absent a special effort to convey the difference.
Third issue: vowel quality change in /aj/ before voiceless vs. voiced. In some North American dialects, certain vowels are different in quality when voiceless vs. voiced consonants follow. The vowel most commonly affected is "long i" -- the vowel in five vs. fife, tide vs. tight, bide vs. bite, etc. In the affected dialects, this vowel is raised and fronted in the pre-voiceless cases. For these speakers, the diphthong in fife starts out near the vowel of bud, and ends near the vowel of bade; while the diphthong in five starts near the vowel of hod, and ends nears the vowel of hed. In IPA, this is something like the difference between [fʌef] and [fɑɛv].
(If you want to see what this means in terms of acoustic measurements,here was a discussion of this on phonoloblog last summer (here and here), in which Bob Kennedy and I exchanged plots of our formant trajectories (time functions of resonance frequencies) in fife vs. five.)
This vowel quality distinction is generally not affected by flapping/voicing of /t/. As a result, in my own speech, the same quality difference that appears in write vs. ride also appears in writer vs. rider. As a result, while latter and ladder are homophones for me, writer and rider are definitely not. The original /t/ and /d/ are both neutralized to a voiced tap [ɾ], but the initital-syllable diphthongs are very different.
(This change in "long i" before voiceless consonants is sometimes called "Canadian raising", but a similar change is found in many U.S. dialects as well. Back in 1942, Martin Joos claimed that Ontario speakers divided into two groups, one of which maintained the vowel quality distinction in spite of flapping and voicing, while the other group didn't; however, I've never been able to find any speakers of his second type, who would raise the diphthong in write but not in writer.)
Now we're in a position to discuss what Arnold said about the pronunciation of tighty and tidy:
On the pronunciation front: tighty and tidy get to be (almost) the same in pronunciation in American English via intervocalic flapping, which plays a role in a large number of reinterpretations, and plain spelling errors too. Interestingly, the two words aren't necessarily pronounced exactly the same, even if they both have an intervocalic flap. Full neutralization at the word level turns out to be rarer than people used to think; often there's some cue as to the "real" nature of the neutralized segment. For tighty vs. tidy, this would be in the length of the vowel preceding the flap -- shorter in tighty than in tidy, at least on the average.
For speakers who don't raise "long i" before voiceless stops, and who do retain the vowel length difference in a reliable way, this is accurate. For speakers who have the "long i" raising pronunciation, the two words tighty and tidy are clearly distinguished by vowel quality.
Although this change might seem to help prevent the tighty → tidy substitution by preserving the distinction in pronunciation between the two words, life is more complicated than that. When a non-i-raiser whose speech is otherwise like mine says tighty, what I hear is equivalent to my own pronunciation of tidy. Thus in the cross-dialect situation, this change can actually create a confusion.
Finally, let's note that flapping and voicing apply to the /t/ in whitey too -- which opens up the possibility to misunderstand that word as something other than a diminutive of white. It could be related to wide, or perhaps to Y, or could be interpreted just as a cutesy reduplication of tidy. And Google indeed finds some forms with appropriate spellings:
It's Viewtiful Joe, but with Resident Evil thrown in, and the whole running around in your Tidy Widy's (Y fronts(pants)) when you get an ass full of lead (shot) sounds like the best thing since ?
It is your chance to break into the San Franciscan art scene without any of the hot-headed, tidy-widy high-nosers looking down on you. What more can you ask for?
So IMO I wouldn't say you would need a 1-hit-kill-blade to make everything perfectly tidy-widy, just some dodging skillz.
Is that all perfectly cleary-weary?
March 19, 2005
Saying more with less
The students in my Advanced Introduction to Linguistics course (for grad students in other departments) had a textbook exercise (from Akmajian et al.) on subject omission in informal English -- specifically, about the omission of dummy IT plus following form of BE in declarative sentences:
Too bad (that) she had to leave town so soon.
Amazing that he didn't spot the error.
One student, Tyler Schnoebelen, added a footnote to his answer:
This struck me as a perceptive observation: the Subject Omission and the I think versions are more expressive/subjective, while It is odd that Mary never showed up is more reportive/objective. This is an old observation for I think, but I don't recall having seen it for omission of dummy subject IT (which is usually lumped together with other types of Subject Omission, as in Taught three classes yesterday and See any penguins yesterday?, though I'm coming to think that there are several different constructions here).
I was moved, in fact. to think about a possibly parallel difference in the Article Omission cases, which also came up in the homework exercise:
The problem is, we have to leave now.
Problem is, we have to leave now.
These do seem subtler to me; still, I suspect that more than simple economy of expression is going on in the Article Omission cases.
Indeed, though economy of expression, or brevity, was surely the original motive for people's omitting highly predictable sentence-initial material, in a kind of strategic reshaping of linguistic material, the conventionalization of the results seems to have followed quickly on this bit of creative language use, and rather "specific contributions to the pragmatically conveyed meaning" (quoting Geoff Pullum's words to me about these examples) came to be associated with what started as phonological elision in a weak position.
In other correspondence on this phenomenon, Elizabeth Traugott noted that this case "fits in with various well-known phenomena like absence of 'that' after verbs like 'see'. Generally, less structure seems to be equated with more subjective [my emphasis], except in the domain of discourse markers, where the more one has the more (inter)subjective things get!" That gets things started; then they become conventional, and in fact grammatical.
Meanwhile, Eve Clark noted, "I think it's something of a convention in writing that one uses a lot more ellipsis to convey 'internal feelings, attitudes'. Does this spill over to actual spoken usage?" Good question.
And Bruno Estigarribia, our local expert on Initially Reduced Questions, tells me that "Haegeman finds a lot of subject deletion in root and in embedded clauses (the latter being usually considered not acceptable) in English diary registers. That also suggests a correlation between 'internal discourse' and subject deletion (which reminds me slightly of Bakhtin 1981)." His references:
Haegeman, Liliane. 1997. Register variation, truncation and subject omission in English and in French. English Language and Linguistics 1.233-70.
Haegeman, Liliane & Tabea Ihsane. 1999. Subject ellipsis in embedded clauses in English. English Language and Linguistics 3.117-145.
So, lots of things to think about.
zwicky at-sign csli period stanford period edu
Another bullshit night in suck city
A little while back, Geoff Pullum ranted,
very briefly, about a National Public Radio talk show discussing Harry
Frankfurt's book Bullshit,
observing that
[I regularize the capitalization etc. of the original.]
Another Bull _ _ _ _ Night . . .
I didn't understand the second ellipsis, taking the ellipsis dots to be part of the title. But a Google search showed me my error.
Vendela Vida's review begins by addressing the issue of the title:
Booksellers, book discussion groups, other book reviews, Wisconsin Public Radio [but this was before the FCC's current campaign really got going; maybe they used the word only on their website, though, and not on the air -- isn't this absurd?], and many other sources just used the damn title, without apology.
"Another bullshit night" comes up in several blogs, with reference to disappointing evenings. Google also nets a few occurrences of "Suck City" (with reference to Flint MI and Atlanta GA, at least) that are not references to a band of that name. Both expressions in one package is (so far as my searches last fall showed) restricted to Nick Flynn's book.
The NYT's refusal to use some form of shit in print is just barely understandable, though many other publications didn't share its reluctance. What is so remarkable to me is that it seems to consider suck a taboo word as well, even in contexts with no explicit reference to fellatio. As far as I can tell, it's unique in this.
zwicky at-sign csli period stanford period edu
Orthocorrection
The first example was supplied by Wilson Gray on 3/16/05:
Spoken by a black TV-show guest:
He aks me _whose, uh, who_ car was this.
Note the nonstandard aks. Then the speaker starts the standard possessive whose car, but restarts and downshifts to the nonstandard who car (without the overt marker 's), and then continues with the nonstandard (in subordinate clauses) inverted word order was this.
I then posted a somewhat similar example, from an interviewee on NPR's Morning Edition, 3/8/05 (talking about mercury vapor):
...it will break up into so small a... so small of a bead that...
People with of in this degree construction tend to judge the of-less variant as fancy, bookish, old-fashioned, pretentious, etc. (Please don't write to tell me that the of variant is just incorrect and I'm corrupting the young by even mentioning such things. My students at Stanford mostly view my of-less variant as having a whiff of the 19th century. I stick to it, but I'm clearly riding the wave of the past.) So this guy found himself embarking on the (to him) stylistically inappropriate construction, and fixed things.
So, what do we call this phenomenon? It's clearly not hypercorrection, since the move is AWAY from a more standard variant. Nor is it really what John Baugh has called "hypocorrection", though the move is towards a less standard variant. But in Baugh's hypocorrection, as in classic hypercorrection, the form that actually gets produced overshoots the target in some way -- someone trying to drop into AAVE, say, and coming out with I yo' man, omitting a copula where AAVE speakers just wouldn't. There's no overshoot here; people end up right at the level they're aiming for.
Whimsically, this might be called "Baby Bear correction" ("ursacorrection" for short): not too much towards one end of the scale, not too much towards the other, but instead just right. "Orthocorrection" is a less whimsical possibility, and it keeps up the tradition of using Greek-derived prefixes with the Latin-derived base correct(ion).
zwicky at-sign csli period stanford period edu
Tidy-whiteys
Although the Eggcorn Hoard has been moving from the gleaming towers of
Language Log Plaza to Chris Waigl's elegant new warehouse, those of us
here at the home office haven't lost interest in the phenomenon.
Indeed, eggcorniacs (Chris included) are forever faced with trying to
judge what went on in people's minds during the first productions of
some form-meaning pairing that diverges from the pairing previously
current in the speech community. Making these judgments can be a
tough task.
Case in point: tidy-whitey,
as in this cite from Mark Morford's column "Attention, Liberal
Shoppers!" in the March-April 2005 Gay
and Lesbian Review, p. 4:
(I left in the whole context partly because it amuses me. But also because it's clear that Morford thinks tighty-whitey underwear -- white cotton briefs, usually for men -- is boring, while I've always thought of this label as denoting the kind of men's underwear made famous by Calvin Klein and aggressively purveyed by 2xist and other firms, the sort of thing that made it ok for the bodies of straight guys to be viewed as public objects of desire. So tighty-whiteys (or -whities, if you wish) call up different connotations for Morford and me, apparently. But this is Language Log, and here we're all about language, not the bodies of male models.)
I'm really pretty sure that the expression started life as tighty-whitey, a (modestly) clever rhyme that bundles together the tightness of briefs and the whiteness of their prototypical exemplars, two properties also combined in the prototypical men's t-shirt.
First complication: the expression occurs in both orders, whitey-tighty as well as the reverse. Second complication: tidy instead of tighty. Now, this makes sense: tighty is a novelty, tidy an established word, the two are pronounced (almost -- see below) the same, and tidy has a good meaning in this context, since the briefs in question might or might not be tight (and revealing), but they're certainly supposed to be neat and clean, that is, tidy.
The raw Google net hits are in favor of the t-word first and in favor of tighty over tidy as that t-word:
| tighty |
tidy |
|
|
t - w |
5,150 |
190 |
| w - t |
3,070 |
13 |
Things are much the same in the plural, though now there are two plurals for whitey: whities and whiteys, with the first preferred to the second:
| tighty |
tidy |
|
| t - whities |
17,400 |
1,740 |
| t - whiteys |
5,820 |
546 |
| w - t's |
2,850 |
144 |
There are (at least) two ways these arrays could come about. If the expressions have been around for a while, then an original tidy could have been being reanalyzed as tighty by people who thought tightness was more significant than cleanliness, so that tighty eventually overtook tidy. These things happen, and if you don't believe they do, you have another thing coming.
On the other hand, if the expressions are pretty recent, then this array reflects incipient reanalysis of original (and still dominant) tighty as tidy. I don't (yet) know the history (it's not in the OED Online, or on the standard word origin sites), though I'm hoping to extract some of it from colleagues on ADS-L. But I'm pretty sure that the expressions are relatively recent, so scenario #2 is the one to go with.
Of course, once the eminently sensible tidy-whitey is around, people will pick it up from writing like Morford's, and they will believe that this is in fact the "correct" form of the expression. They'll treat tighty-whitey as a misinterpretation, in fact. I'll bet Morford (or his copyeditor, or both) is such a person.
On the pronunciation front: tighty and tidy get to be (almost) the same in pronunciation in American English via intervocalic flapping, which plays a role in a large number of reinterpretations, and plain spelling errors too. Interestingly, the two words aren't necessarily pronounced exactly the same, even if they both have an intervocalic flap. Full neutralization at the word level turns out to be rarer than people used to think; often there's some cue as to the "real" nature of the neutralized segment. For tighty vs. tidy, this would be in the length of the vowel preceding the flap -- shorter in tighty than in tidy, at least on the average. (Morphological relatedness plays some role -- tighty is related to tight -- and so, probably, does the spelling system. These aren't simple matters.)
What's really surprising, though, is that PRONOUNCING such distinctions can be divorced from PERCEIVING them. Many years ago I served as a subject in an experiment run by Patricia Donegan, who told me that I made a made a (significant) distinction between the length of the first vowels in latter vs. ladder and similar pairs, but failed totally to perceive my own distinctions. And I was scarcely alone.
So even if I'm sending out cues that will distinguish tighty and tidy, there's no guarantee that other people will get them. The two words will "sound the same" (even if they don't quite sound the same, they're really very close); and one can be reinterpreted as the other.
[Late-breaking (3/19/05) news from ADS-L: (a) Sam Clements's 14-year-old son volunteers that (some version of) tighty-whitey was in the movie Porky's (1982), though no one has verified this. (b) Alice Faber reports a 1993 newsgroup use that glosses the expression unfavorably, in a reference to "the tighty-whitey (that means that their jockey underwear is too small, not anything racist, BTW) crybabies". (c) Ben Zimmer gets things back to 1990 with a cite for tighty-whities ("think of boxers as opposed to the traditional Fruit-O-The-Loom/Hanes 'tighty-whities' ") and notes that Connie Eble's Slang and Sociability (1991) reports "tighty whities: men's briefs" in use on the UNC-Chapel Hill campus. And on 3/20/05 Tom Ace complains in e-mail that his "preferred variant spelling, tightie-whities, wasn't among those discussed in Language Log" and observes that he often sees the expression "used with a disparaging connotation, as if white briefs were the most uncool underwear choice going. Tightie-whities have become the Rodney Dangerfield of underwear. It wasn't that way when I was a kid." Ah, fickle fashion!
On the spelling front, Ace's comments moved me to check out uses with tightie and (for completeness) tidie and tidey, also with whitie and whity. This increased the tight- count by 7,886 and the tid- count by only 534. There are an amazing number of spellings out there, though, in addition to the ones in the tables above: for tight- + whit-, tightie-whitey(s), tightie-whitie(s), tighty-whity, tightie-whity; for tid- + whit-, tidy-whitie, tidie-whitie(s), tidie-whitey(s), tidy-whity, tidey-whity, tidey-whitie(s), tidey-whitey(s); for whit- + tight-, whitie-tightie(s), whitie-tighty, whity-tightie(s), whity-tighty; for whit- + tid-, whitie-tidy, whitie-tidie(s), whity-tidy, whity-tidie(s), whity-tidey(s). If there are any spellings with wit- instead of whit- or tit- instead of tight-, I don't want to hear about it. The pattern is very clear, anyway: tight- way over tid-, and t - w way over w - t.]
zwicky at-sign csli period stanford period edu
France defies Google
Perhaps inspired by Jean-Noël Jeanneney, Agence France Presse (AFP) is suing Google for copyright infringement. According to Reuters:
The French news service is seeking damages of at least $17.5 million and an order barring Google News from displaying AFP photographs, news headlines or story leads, according to the suit filed on Thursday in the U.S. District Court for the District of Columbia.
According to the same story, Google must be prepared to argue this one out in court:
AFP said that it had informed Google it was not authorized to use AFP's copyrighted material as it did and that it had asked Google to stop.
Google has ignored those requests, AFP's suit alleges.
I suppose that it's for this reason that Google News continues to be called "beta", and also that it doesn't offer any advertising. If Google can win this fight, it would be a rare legal triumph for the concept of "fair use", which I assume would be the basis of their defense. As the U.S. Copyright Office explains, section 107 of the U.S. copyright law "sets out four factors to be considered in determining whether or not a particular use is fair:"
- the purpose and character of the use, including whether such use is of commercial nature or is for nonprofit educational purposes;
- the nature of the copyrighted work;
- amount and substantiality of the portion used in relation to the copyrighted work as a whole; and
- the effect of the use upon the potential market for or value of the copyrighted work.
In this case, the argument for Google would be (1) that Google News has an educational (and experimental) function and does not generate revenue for Google; (2) that the material cited is available to the public on the web in any case; (3) that only minimal amounts are cited, just enough to allow readers to determine whether or not to click through to the source; and (4) that the effect on AFP is positive, since it brings more readers to sites that run their stories (and may run advertising as well).
This doesn't take into account the "Anglo-Saxon perspective" that pained M. Jeanneney so keenly, though congeniality of national perspectives is not one of the factors recommended by section 107 for determining fair use. But I'm not raising Jeanneney's arguments as a joke, since AFP is chartered by the French government, giving it roughly the same status as Xinhua or Voice of America. Well, it may be technically somewhat more independent, but it would be surprising if AFP took a step like this without government consultation.
I'm not a lawyer, and have very little understanding of the current dynamics of copyright law. However, this strikes me as a fortunate case for defenders of fair use, since it pits one of the most popular and innovative U.S. companies against the news agency of the French government, who presumably have less influence in the Federal Court system (and on Capitol Hill) than Disney does. Of course, Google might avoid the fight, for instance by agreeing not to index AFP.
[Update: some news reports quote "Google spokesman Steve Langdon" as saying "We allow publishers to opt out of Google News but most publishers want to be included because they believe it is a benefit to them and to their readers." This is in direct contradiction to AFP's charge that they've asked Google to stop crawling their stuff but that "Google has not stopped despite repeated requests."
This odd discrepancy will presumably be cleared up soon. My own guess is that it's a question of where the material is aggregated from: not from AFP's site, but from the sites of newspapers that subscribe to AFP and reprint its stuff under license.]
[Update #2: Edward Hasbrouck thinks that writers ought to be rooting for AFP. And Dana Blankenhorn says that AFP's site has no robots.txt file.]
Fo did it
 Alexander, King of Jesters, seems to be wrong when he says that "Many jesters and fools spoke a gibberish language called Grammelot that was first described over 500 years ago." Similarly, Gianni Ferrario seems to be wrong when he says that "Grammelot is a form of theater invented by the comic actors of the Commedia dell'Arte of 1400, and is organized in an onomatopoeic mode, that is, it manages to evoke concepts by means of sounds that are not established or conventional words." At least they're wrong to imply that the term Grammelot dates from the 15th or 16th century. (See this earlier post for references and links). In fact, the term was apparently invented by Dario Fo, perhaps in connection with his 1969 play Mistero Buffo.
Alexander, King of Jesters, seems to be wrong when he says that "Many jesters and fools spoke a gibberish language called Grammelot that was first described over 500 years ago." Similarly, Gianni Ferrario seems to be wrong when he says that "Grammelot is a form of theater invented by the comic actors of the Commedia dell'Arte of 1400, and is organized in an onomatopoeic mode, that is, it manages to evoke concepts by means of sounds that are not established or conventional words." At least they're wrong to imply that the term Grammelot dates from the 15th or 16th century. (See this earlier post for references and links). In fact, the term was apparently invented by Dario Fo, perhaps in connection with his 1969 play Mistero Buffo.
 The confusion seems to have arisen because of Fo's references to the 16th-century playwright Angelo Beolco. In Fo's Nobel acceptance speech, he gave credit to "Ruzzante Beolco, my greatest master along with Molière", called him "until Shakespeare, doubtless the greatest playwright of renaissance Europe", and referred to the inspiration of Ruzzante's linguistic inventiveness:
The confusion seems to have arisen because of Fo's references to the 16th-century playwright Angelo Beolco. In Fo's Nobel acceptance speech, he gave credit to "Ruzzante Beolco, my greatest master along with Molière", called him "until Shakespeare, doubtless the greatest playwright of renaissance Europe", and referred to the inspiration of Ruzzante's linguistic inventiveness:
Ruzzante, the true father of the Commedia dell'Arte, also constructed a language of his own, a language of and for the theatre, based on a variety of tongues: the dialects of the Po Valley, expressions in Latin, Spanish, even German, all mixed with onomatopoeic sounds of his own invention. It is from him, from Beolco Ruzzante, that I've learned to free myself from conventional literary writing and to express myself with words that you can chew, with unusual sounds, with various techniques of rhythm and breathing, even with the rambling nonsense-speech of the grammelot.
Stefano Taschini told me by email that his dictionary "suggests that Grammelot might result from the composition of the French words grammaire, mêler, and argot, but its etymology stays uncertain." Stefano checked the "Encyclopedie Larousse, without finding any matches (trying all possible accent combinations). Despite being a french-looking and french-sounding word (I always heard it pronounced as [gram'lo]), apparently it isn't."
My own searches for grammelot in the BNF's Gallica archive and the Dictionnaire de l'Académie Française (both 8th edition and 9th edition) likewise produced nothing. In addition, the word grammelot isn't in large English dictionaries such as the OED and Webster's 3rd International, nor is it in the LION ("Literature Online") database. The ARTFL project's Opera del Vocabolario Italiano search form and the Ricerca page of the Tesoro della Lingua Italiana delle Origini also return "Nothing found matching specified search term(s)" and "Nessun elemento trovato" for various types of searches for grammelot. If such a word had really been in use since the 15th and 16th centuries to describe the language of the Commedia Dell'Arte, or even Ruzzante's language in particular, this absence would be very surprising. It seems much more likely that the term was invented in the 1960s by Dario Fo and Franca Rame to describe their own linguistic experiments.
This leaves the question of whether the language of Ruzzante's plays was simply a representation of the local vernacular, or rather (as Fo says) a theatrical invention. Stefano isn't sure:
As for Ruzzante's language, I really cannot say. My unsubstantiated feeling is that it looks too much like a parody of Po plane dialects to be really one of them, and I'm rather inclined to consider it more an invention à la Fo than a faithful representation of the vernacular spoken in the countryside around Padua. At some point in La Moscheta, Ruzzante dresses up as a foreigner, and speaks in a mocked-up Italian (rather funny, actually). There, the language is obviously invented, but probably reflecting the efforts of his farmers to speak "properly".
Stefano (one of those special people whose email has footnotes) points out that a book and video tape of Fo's Mistero Buffo is available here, and that the texts of two of Ruzzante's plays are on line here.
Continuing on the trail of grammelot, the only return for this term from the MLA bibliography is Erith Jaffe-Berg, "Forays into Grammelot: The Language of Nonsense", Journal of Dramatic Theory and Criticism (JDTC) 2001 Spring; 15 (2): 3-15, which is not available on line. The fact that there are no other references seems to be further evidence that this is a new term, not an old one. However, Ray Girvan sent a reference to a paper by Adrienne Ward ("'Imaginary Imperialism': Goldoni Stages China in 18th Century Italy". Theatre Journal 54.2 (2002) 203-221) which is available through Project Muse, and which uses the term grammelot as if it were a traditional name for (certain kinds of) theatrical double-talk.
Ward's paper is about a scene of "pretend Chinese" ("finti cinesi") in Carlo Goldoni's comic opera L'isola disabitata (1757). In footnote 36, Ward writes:
The deployment of a variety of languages and dialects (existing or imaginary) was relatively common practice on the Italian stage in Goldoni's time, hailing back to a classic bit in the commedia dell'arte tradition. A key feature of the commedia's poetics of improvisation involved virtuoso linguistic performances, in which characters would spew forth exaggerated and comical but authentic-sounding streams of foreign language, sometimes switching deftly between diverse tongues. Grammelot is the term used to describe this early practice of replicating the Other's language, which then became particularly suited to eighteenth-century exotic theatre. In Dario Fo and Popular Performance (Ottawa: Legas, 1998), Antonio Scuderi defines grammelot as ". . . a fake language which consists of nonsensical sounds that imitate the inflection and cadence of real speech," 8. He also notes that "The insertion of a limited number of key words that are identifiable to the audience conveys a sense of semantic value and thus a sense of real speech to the otherwise nonsensical sounds," Dario Fo: Stage, Text and Tradition (Carbondale: Southern Illinois University Press, 2000), 58. The scene of the "finti cinesi" clearly exhibits these traits of grammelot, and shows Goldoni's continued reliance on certain aspects of commedia dell'arte performance. For more on the history of grammelot and its manifestations in twentieth-century theatre, see the aforementioned works by Scuderi, as well as Dario Fo, Tricks of the Trade, trans. Joseph Farrell (New York: Routledge, 1991). [emphasis added]
So either Ward and Scuderi have misread Fo, or this word has someone survived for half a millenium in the theatrical demimonde, without leaving any detectable traces in the literary and linguistic history of Italy, France and England.
[Update 12/10/2006 -- I was wrong to suggest that Antonio Scuderi might have misread Fo. In Scuderi's discussion of the subject, which I had read only in Ward's quotations, he makes it clear that he does not know the origin of the term, and he does not claim either that it is an old word or that it is a new one. Ward's discussion, which I had read in full, certainly implies that the term dates back to the early days of the commedia dell'arte tradition. However, Scuderi's only role here was to provide the definition that she used.]
Just for fun, here's Goldoni's passage of fake Chinese:
| Valdimonte: | Karamenitzkatà. |
| Garamone: (a due) | Macaccorebeccà. |
| Ti menaccà — paraticà, | |
| Baracca papagà. | |
| (verso degli altri mostrano che queste parole siano complimenti chinesi) |
|
| Giacinta: | (Sentite!) (a Carolina e Panico) |
| Carolina: | (Che han detto?) (a Panico) |
| Panico: | (Chi diavolo il sa?) (piano a Carolina) |
| Carolina: | Panciri nascattà. |
| Giacinta: | (a due) Penaci caraccà. |
| Timpana là, timpanaccà. | |
| (corrispondono con simili complimenti) | |
| Panico: | Scarbocci mascabà. |
| Chichirichi caccaraccà, | |
| Quaiotta squaquarà. |
and the "translation" given in Ward's paper:
| Valdimonte and | Timbuktù-cuckoo. |
| Garamone: (together) | Chung-feng-shui-to-you. |
| I bust-a-you-butt—watcha-you-gut, | |
| Tung-hu yu-a-foo. | |
| (they indicate to the others that these words are Chinese compliments) |
|
| Giacinta: | (Listen!) (to Carolina and Panico) |
| Carolina: | (What did they say?) (to Panico) |
| Panico: | (Who the hell knows?) (softly to Carolina) |
| Carolina and | Belly nakka-pu. |
| Giacinta: (together) | Bing-ho sooka-doo. |
| Bong-a-drum-one, Bong-a-drum-two. | |
| (they correspond with similar compliments) | |
| Panico: | Scribble-dibble bally-hoo. |
| Willy-nilly cock-a-doodle-doo, | |
| Ming-ho yu-go poo-poo-poo. |
about which she writes
My English translation of this portion of the scene of the "finti cinesi" can only hope to approximate both the sense and the nonsense of the Italian wordplay. The Italian version makes great use of the occlusive phoneme /k/ and truncated syllables at the end of lines, most likely to imitate the clipped sound of Chinese speech. I have tried to imitate this in an English parody as closely (and creatively) as possible. The repeated use of the syllable "ka" in the Italian contributes to the scatological tone of the exchange, sharply reminiscent of standard commedia dell'arte sketches. Other verbal constructions from which meaning can be extracted include threats ("Ti menaccà—paraticà"), and more overt scurrilous phrasing, such as "Chichirichi caccaraccà, / Quaiotta squaquarà," where "squaquarà" evokes the colloquial expression for diarrhea, "la squaquerella."
[Update 12/7/2006 -- Antonio Scuderi writes:
The other day, in a moment of egoistic self-indulgence, investigating books and articles where my work has been cited, I came across my name on your blog, Language Log, in an installment entitled "Fo Did It" (2005). Apparently without opening a book, the author concludes that the Italian Nobel Playwright, Dario Fo, invented the term grammelot, which refers to an aural performance technique. He quotes a long passage by someone else who quotes me, and then concludes, "So either Ward and Scuderi have misread Fo, or this word has someone (sic) survived for half a millennium in the theatrical demimonde, without leaving detectable traces in the literary and linguistic history of Italy, France and England" (2005:3).
Okay, it's just a blog, no responsible peer reviewing required, etc. But still... If the author had cracked open the two books of mine that are mentioned, he would have found that I cite where the term is listed in a major Italian dictionary (Zingarelli 1995:797), and a survey of attempts to trace the origins of the word. In my essay, "Updating Antiquity," in Dario Fo: Stage, Text and Tradition, I explain that according to John Rudlin (Commedia dell'Arte: An Actor's Handbook, 1994:59-60), Fo most likely learned the technique from Jacques Lecoq, who "definitely" learned it from Jean Dasté, who had used it with the Copias troupe, which had called it grummelot. I explain that the etymology is uncertain and provide several hypotheses. None suggest that Fo invented the term, and in fact, Fo himself makes it clear that it did not originate with him: "termine di origine francese, coniato dai comici dell'Arte e maccheronizzato dai veneti che dicevano 'gramelotto'."
Wrestling with this enigmatic term in a scholarly endeavor was not easy. In any instance, of course, it is disappointing to see the results of such research bandied about in an off-hand irresponsible manner. In the present case, the invention of Fo inventing the term has reached Wikipedia by way of Language Log, so that myth is not just lost in a blog, but, alas, presented in a forum that some will trust.
I'm grateful for the additional information. However, the word grammelot (under whatever spelling) still seems to be a modern invention, contrary to the implication of some prominent contemporary users. Although Fo says that the term is "di origine francese", it is apparently not attested in any French dictionaries or other historical sources that I have been able to find. Specifically, the 8th edition of the Dictionnaire de l'Académie Française has neither grammelot nor grummelot nor grammelotto. Likewise, Gallica tells us that "aucun document ne répond à la requête".
And neither grammelotto nor relevant similar word appears to occur in the Opera del Vocabolario Italiano textual database, which includes more than 20 million words of pre-1375 Italian text.
Pending any evidence of use before 1960 or so, it still seems to me that the word grammelot is a modern invention -- whether the inventor was Fo or Jacques Lecoq or someone else -- which has been introduced into general use by Fo. The fact that the word occurs in an Italian dictionary published in 1995 doesn't address this question one way or another, unless it gives citations from an earlier time.]
March 18, 2005
Franklin Medal to Aravind Joshi
 Aravind
Joshi has been awarded the 2005 Benjamin
Franklin medal in Computer and Cognitive Science. The citation,
quoted below, focuses on his many research contributions and his other honors.
It doesn't mention some of the the most important things about Aravind, though.
There's his 40 years of tireless work to build a culture of interdisciplinary
research on human language, involving linguists, psychologists, philosophers
and mathematicians as well as computer scientists and engineers. There's his
unwavering intellectual tolerance and respect for alternative approaches, combined
with the utmost rigor and the highest standards of evaluation. And at an age
when some people might think about retiring, Aravind has been forging into a
completely new area of research, modeling the language
of biological macromolecules.
Aravind
Joshi has been awarded the 2005 Benjamin
Franklin medal in Computer and Cognitive Science. The citation,
quoted below, focuses on his many research contributions and his other honors.
It doesn't mention some of the the most important things about Aravind, though.
There's his 40 years of tireless work to build a culture of interdisciplinary
research on human language, involving linguists, psychologists, philosophers
and mathematicians as well as computer scientists and engineers. There's his
unwavering intellectual tolerance and respect for alternative approaches, combined
with the utmost rigor and the highest standards of evaluation. And at an age
when some people might think about retiring, Aravind has been forging into a
completely new area of research, modeling the language
of biological macromolecules.
Here's what the Franklin Institute has to say about him:
Citation: The 2005 Benjamin Franklin Medal in Computer and Cognitive Science is awarded to Aravind Joshi for his fundamental contributions to our understanding of how language is represented in the mind, and for developing techniques that enable computers to process efficiently the wide range of human languages. These advances have led to new methods for computer translation.
Aravind Joshi is a world leader in the interdisciplinary research that covers linguistics, cognitive science, and computer science. His theoretical insights regarding the structure of human language, and the resulting tools and techniques he developed, help us understand how we communicate and allow us to interface with technology more naturally.
After receiving his B.E. in electrical and mechanical engineering from Pune University and his D.I.I.Sc. in communication engineering from the Indian Institute of Science, both in his home country of India, Dr. Joshi began a fruitful academic career in the United States. He received his M.S. (1958) and his Ph.D. (1960), both in electrical engineering, from the University of Pennsylvania, where he has been a professor for the last 40 years. Currently Henry Salvatori Professor of Computer and Cognitive Science, Dr. Joshi is also co-founder and co-director of the University's Institute for Research in Cognitive Science.
Dr. Joshi's numerous awards include the David Rumelhart Prize for 2003 from the Cognitive Science Society, a Lifetime Achievement Award from the Association for Computational Linguistics, the Research Excellence Award of the International Joint Conference on Artificial Intelligence, and an honorary doctorate from the University of Paris 7. He was elected to the National Academy of Engineering, and is a fellow of the Institute of Electrical and Electronics Engineers (IEEE), a founding fellow of the American Association of Artificial Intelligence (AAAI), and a member of the Association for Computational Linguistics, the Linguistic Society of America, and the Association for Computing Machinery.
The other 2005 citations can be found here.
Surnames
Linking to a post on Japanese surnames at Butterfly Blue, Steve at Language Hat asks "Did you know (to take one startling fact) that Japan has more different surnames than any other country in the world (about 120,000)?" Backed by Steve's well-deserved authority on the net, I'm afraid that this meme may start to propagate, although it's far from being true.
20-odd years ago, I worked on software to determine the pronunciation of names for text-to-speech applications. We worked from lists of American surnames, derived from phone books and other sources, that comprised several million distinct (orthographic strings representing) surnames, and were far from complete. This is also the kind of number that emerges from the description of NameX, a software product that can be seen as a "thesaurus containing 132 million variants for 2.6 million distinct Surnames," though this is for names "from all over the world with comprehensive coverage of names with European origins".
You can download a list of "Frequently Occurring Names" from the U.S. Census Bureau that includes 88,799 distinct surnames from 6,290,251 records. According to the documentation, this is based on the records of people living in the 5,300 blocks where the "post enumeration sample" was done, along with "additional surrounding ring blocks", amounting to about 1/40 of the overall 1990 census. This was then pruned further: "For purposes of both confidentiality and elimination of data noise we restricted the number of unique names available at this internet site to the minimum number of entries that contain 90 percent of the population in that data file."
The file was sorted in inverse order of frequency, with the names for each frequency count sorted in inverse alphabetical order. The last batch before the file is cut off includes 13,124 names from
ZYSETT 0.000 89.231 75677
to
AALDERINK 0.000 90.483 88799
The count of individuals with each name is not given, but the numbers mean that these 13,123 names comprise 90.483-89.231= 1.252% of the total set of people in the sample, so that we can determine that the sample count for the names in this set must have been 6. This allows us to provide a lower bound on the number of distinct names in rest of the sample as about 99,774 (i.e. assuming that all additional names occur six times each), which would yield 88,799+99,774=188,573. In fact this is surely much too small, since the tail of names will normally include increasing numbers at lower frequency counts (of 5, 4, etc. people per name). In addition, the other 39/40 of the census will add considerably to the tail of infrequent names, not only because of the expected effects of a larger sample, but because of the bias introduced because the existing list sampled whole households from a particular set of compact geographical areas ("blocks").
I don't present this as any sort of estimate of the number of distinct surnames among American households (which I believe to be well over a million), but rather as a demonstration that whatever the true number is, it's much larger than 120,000.
March 16, 2005
The winter eggcornucopia
The eggcorns mount up alarmingly here at Language Log Plaza. I've started to move items to Chris Waigl's eggcorn database and don't expect to provide further catalogues of examples here. (If you have contributions to make, drop them off at Chris's warehouse.) But here's an inventory of the winter crop (including genuine eggcorns, dubious ones, and examples of related types).
First, an appreciation of eggcorns from my soc.motss friend Michael Siemon, in e-mail on 2/19/05:
... The whole eggcorn thing, since you nudged us a while back, has fascinated me. I used to pass over these, with a small wince or blink of amazement/amusement, but passed on without dwelling on the possible mental processing involved. But now, they seem to be jewels (kitschy jewels, to be sure) cast before the usenet swine who do their best not to notice them. And so I now pause and allow them their voice.
Meanwhile, Rich Baldwin asked me in e-mail on 1/21/05, "Is the birth of an eggcorn an eggcoronation? Or is that taking the joke too far?" Well, I have no shame, as you can tell by the title of this posting. Let the eggcoronations begin!
1. Stuff already in the eggcorn data base. These are items from my winter list that others have already entered into the data base:
deep-seeded [ < deep-seated ]
(run the) gambit [ < gamut ]
(take for) granite [ < granted ]
hare's breath [ < hair's breadth ]
off-times [ < oft-times ]
sorted [ < sordid ]
2. Stuff I just entered. Quite an assortment of things today.
catchnap [ < catnap ]
centrifical (force) [ < centrifugal ]
centripedal (force) [ < centripetal ]
content (with) [ < contend ]
far be it for [ < far be it from ]
girdle (one's loins) [ < gird ]
granola (oil) [ < canola ]
Grumman [ < Grauman ]
languistics [ < linguistics ]
marball [ < marble ]
metal [ < medal ]
(in the) mist (of) [ < midst ]
passed [ < past ]
powerhorse [ < powerhouse ]
pre(-)fix, pre(-)fixe, pre-fixed [ < prix fixe ]
skeletal (staff) [ < skeleton ]
soak (one's wild oats) [ < sow ]
3. Still in the to-do files. Some of these might already be in the database; I haven't checked them all. A number of them present special problems of analysis that need comment. Some are old standards.
black and (red fish) [ < blackened ]
carrot on a (stick) [ < carrot and ]
chomping (at the bit) [ < champing ]
(French) crawlers [ < crullers ]
(make) due [ < do ]
flaunt [ < flout ]
flush (out) [ < flesh ]
font (of knowledge) [ < fount(ain) ]
lazy-fare [ < laissez-faire ]
mano y mano [ < mano a mano ]
(comedy of) manors [ < manners ]
mitigate (against) [ < militate ]
pack [ < pact ]
pain-staking [ < pains-taking ]
(set) perimeters [ < parameters ]
prolongered [ < prolonged ]
(on) queue [ < cue ]
same-oh same-oh [ < same-old same-old ]
verses [ < versus ]
wonderlust [ < wanderlust ]
4. Cases that are even more problematic. Here's a collection of things that might be simple misspellings, blends, classical malapropisms, or whatever.
adapt [ < adept ]
bare (responsibility) [ < bear ]
beg to pardon [ < beg (your) pardon ]
canape [ < canopy ]
coward [ < cowered ]
exult [ < exhort ]
hold (up) [ < holed ]
kick in the bucket [ < kick the bucket ]
perceptively [ < perceptibly ]
picture (of beer) [ < pitcher ]
waiver [ < waver ]
zwicky at-sign csli period stanford period edu
The experience of capricious censorship
I'm frustrated. Three separate attempts to produce a blog entry this morning have been stopped by the weirdest netnannity that I've ever seen.
I'm at the Airlie Center in Warrenton, VA, attending a workshop, on which more later. Airlie is a lovely place, whose web page says that it was "founded in 1960 as an 'island of thought', and has provided a unique environment for the the creative exchange of ideas ever since." This environment features hundreds of acres of lovely countryside, swans in mating duets, and an internet connection, available in the rooms for the usual $9.95 per day, that capriciously blocks about half the web.
I first noticed this when I tried to access the comics archive at http://www.doonesbury.com. What I got instead of Doonesbury was a big dark-blue page, blank except for a light-blue box reading:
This site is blocked by the IT Department. Contact the IT Dept. For help if needed. |
The page title is "SonicWALL -- Web Site Blocked." Gee, I thought, that's funny. Did one of Trudeau's strips insult the swans?
Then I started to compose a post on the origins of the term Grammelot. Stefano Taschini wrote that his Italian dictionary says it "might result from the composition of the French words grammaire, mêler, and argot", but he couldn't find it in any French dictionaries. So I thought I'd check the Gallica website at the Bibliothèque Nationale de France. Oops -- blocked by the IT department again. Now, I've been critical of the BNF, but blocking their site doesn't make it better.
So to soothe myself, I took a quick tour through our blogroll. But http://ablauttime.blogspot.com/ and
http://mixingmemory.blogspot.com/ and apparently every other site at blogspot were blocked. Also blocked were:
http://www.raygirvan.co.uk/apoth/thought.htm
http://piginawig.diaryland.com/
http://www.audhumla.org/
http://blinger.org/
http://www.languagehat.com/
http://keywords.oxus.net/
http://www.painintheenglish.com/
http://www.wordlab.com/
Allowed, on the other hand, were
http://semanticcompositions.typepad.com/ (and apparently all other typepad sites)
http://mattweiner.net/blog/
http://www.livejournal.com/users/q_pheevr/ (and apparently all other livejournal sites)
http://www.margaret-marks.com/Transblawg/
http://www.bisso.com/ujg/
http://www.multilingualblog.com/
This doesn't make any sense at all as an attempt to protect America's conference-goers from nefarious influences.
I can see three alternative explanations. One is that it's pure pharmaceutical-grade incompetence -- someone's pet cat sleeping fitfully on a keyboard connected to SonicWALL's Content Security Management control screen. A second possibility the Airlie IT department is staffed by a manager who is worried about ritual pollution by words and images, and a lackey who has no idea how the web works ("sexually explicit lyrics over at blogspot? check, boss, it's taken care of; and those French postcards won't be a problem again, not at Airlie, no sir."). The third and most probably theory is that the Bastard Operator from Hell has retired to the Virginia countryside and is now running the Airlie IT department. This page might provide some insight -- I don't know, I can't read it, myself, because
This site is blocked by the IT Department. Contact the IT Dept. For help if needed. |
[Seriously, you can look up the rating of URLs according
to
SonicWALL's
Content Filtering
Service database, and you'll find that the BNF, the bartleby.com site,
all blogspot weblogs, Ray Girvan's site, etc. etc. are all classified as
"Category 14 - Arts/Entertainment". Apparently the Airlie IT department
has voted arts and entertainment off their "island of thought". Or could that just be the default configuration for SonicWALL's software? ]
March 15, 2005
The moose who chose to lose whose nose?
Arnold Zwicky remarked in the first version of this post that lose is the only English word with /uz/ spelled <ose>. [The remark is not there now, because he's thoroughly on the ball, and corrected himself just a few hours later, while I was writing this one. We tussle like this all the time at Language Log Plaza. They say that in the corporate world it's dog eat dog. Well, at Language Log it's exactly the reverse.] ’Tisn't true [as he now says in the corrected version]: there is also whose (which he might perhaps have initially missed because it's an inflected form, not a citation form of a lexeme). But the temporary slip only underlines his point about the orthographic minefield of English words ending in /uz/ and /us/ (likewise /eiz/ as in phrase and /eis/ as in base, and so on). If I had talent as a poet I would attempt to write poems about it for the bemusement (one can scarcely say amusement) of children:
If a moose should choose to lose his nose,
His does, I s'pose, would get morose.
A nose does have use for a moose on the loose:
It's his nose he would use when close to a rose,
For roses aren't food a loose moose would choose
(Whose moose would choose a dose of rose?)...
[etc. etc., approx. 165 stanzas]
But first, I have no talent as a poet (my stuff is right down there with
mortgage
company poetry); and second, confusing poems aren't going to help
the little mites with their spelling problems, are they? Best to use old-fashioned methods: if you spell lose as loose or
choose as chose you will be punished.
We are Language Log, and we will brook no ilittera
illitter
illiteracy.
Ke'o and Ngadha
Last summer I learned about a couple of truly odd languages spoken by small groups in Indonesia, Ke'o and Ngadha. They have no prefixes or suffixes at all. All grammar is taken care of by separate words -- no WALK-ED, no FRIEND-SHIP, no RE-SEND. These days I am thinking that this, of all things, may be evidence of an interspecies encounter between two different species of HOMO.
Now, there are plenty of languages that are awfully low on prefixes and suffixes, although typically languages have at least something along these lines according to some linguists' analysis. But Ke'o and Ngadha are particularly odd in that they belong to the Austronesian family, which is not exactly known for being affix-shy. Ke'o and Ngadha's relatives include languages like Tagalog, bristling with prefixes and suffixes, and Malay, which shaves down the chaos somewhat, but still challenges the learner with affixes galore. Even Ke'o and Ngadha's VERY closest relatives, in what is called the Central Malayo-Polynesian group, are usually chock full of, at least, prefixes.
So what worried me about Ke'o and Ngadha was why languages would just dump their affixes. When this happens elsewhere, typically the affixes leave behind some kind of footprint -- in Chinese, for example, many prefixes faded away eons ago -- but often morphed into a change in pitch on the word that remains today. But in Ke'o and Ngadha, nothing of the sort. No tone, no fossilized warts. They're just nude. Their grammars are, in this aspect, simpler than what is typical of their relatives. They are haikus amidst limericks.
In fact, whenever grammars just let it all go in this way, it is because at some point, they were learned more by adults than children. Adults aren't as good at learning languages as kids -- as we all know from language classes -- and so in cases like this, the grammar becomes more streamlined. The demonstration case here is the extreme one of creoles, where a European language full of AMO, AMAS, AMAT-type baubles becomes one where the verb stays the same in all persons, and so on.
But Ke'o and Ngadha are not creoles. They have had nothing to do with plantation slavery or anything similar. I scratched my head over these languages for months.
But then last fall, we all learned about the discovery of skeletons of the "little people" on the Indonesian island of Flores. The skeletons date from 13,000 to 18,000 years ago, and are so unprecedently small in size that they have been classified as a new species of HOMO.
And get this -- Ke'o and Ngadha are spoken on none other than Flores.
This got me thinking: could it possibly be that what made these languages go "creole" was that the "little people" learned them so extensively that the way they spoke them became what children heard most? This, after all, is how creoles come to be. It is also why Swahili, used as a second language more than as a first one for centuries, is significantly more user-friendly than other Bantu languages. It is even why, in some linguists' opinion (including mine) English is the only Indo-European language in Europe without pesky gender of the LE BATEAU/LA LUNE sort.
Of course, I can only venture this as a nervy guess at this point. But the evidence is interesting indeed.
The skeletons were unearthed in western Flores, while Ke'o and Ngadha are spoken somewhat eastward, in the South Central part. But there are two things. First, the language of western Flores is Manggarai, and while it has a little scattering of affixes, even it is "naked" enough that when I read a description of it last summer, long before the "little people" had been reported, I wondered just what was up even with it.
But second, not only the Manggarai but also the Ngadha people have legends about little people who once lived among them until as late as the 1500s. It may well be that "little people" skeletons have yet to be unearthed in the Ngadha area, since Flores is very small.
And in any case, the legends say that the little people spoke in an incomprehensible babble but couldn't repeat back in the Homo sapiens' language. This can't be taken as evidence that the little people did not have language, since the "babbling" impression is a typical judgment of foreigners' language by people unschooled in the esoterica of modern linguistics. And wouldn't you know that two weeks ago we learned that the "little people"'s brain case suggests advanced cognition -- just as does their hunting and tool-making, which, in the analysis of Homo sapiens, is regularly treated as evidence that natural language had arisen.
Then there is one more thing. Many of the languages of Flores are barely documented, and this includes various ones spoken between Manggarai and Ngadha. But documentation is beginning for one of them, Rongga, which sits right between the other two. And it turns out to be one more language with, mysteriously, no prefixes or suffixes.
So -- a preliminary hypothesis is that when a descendant of the ancestral Proto-Austronesian language came to Flores, which archaeology and comparative linguistic reconstruction suggest was between 4000 and 4500 years ago, its speakers encountered "little people" already there, speaking their own language. These would not have been the only people around, as Homo sapiens is thought to have gotten to the Flores region about 50,000 years ago.
But we might suppose that the "little people," perhaps because of their smallness and less "advanced" society, were incorporated into the newcomers' society at some point, possibly by force. Their non-native rendition of the newcomers' language gradually became the model that all children learned. The result -- "schoolboy Proto-Austronesian," kind of like our version of French or Spanish in middle school. Except in this case, this was refashioned into a full, nuanced language. Full, nuanced language does not require affixes.
There are models for this. For example, Afrikaans in South Africa is a variety of Dutch as filtered through Khoi ("Bushman") servants and nursemaids, the result being the second most streamlined Germanic language after English.
We could also take this hypothesis as support that the "little people" indeed had the language capacities that we do, since it would appear that they acquired the newcomers' language just as successfully -- albeit incompletely -- as Homo sapiens does worldwide in similar situations. They managed a version of Proto-Austronesian (for linguists, technically, Proto-Malayo-Polynesian) robust enough that children could acquire it and use it everyday without surrounding adults conclusively dismissing it as utter gibberish.
Obviously, we need a lot more data before I could go further -- genetic analysis of the skeletal material, documentation of more of the languages of Central Flores, and more thorough searching for fossils (i.e. we have no fossils of "little people" after 13,000 years ago as of yet).
But the sheer weirdness of Ke'o, Ngadha and Rongga strikes me as begging for an explanation beyond ordinary tendencies in how languages change over time when nothing interrupts them -- such as, just maybe, being learned by hobbits.
March 14, 2005
Two types of "errors" (again) and it's all "grammar" (again)
Over on the eggcorn database site, I've added a comment on the lose-to-loose entry, which Chris Waigl has annotated with:
This entry has been assigned to the "questionable" category pending further discussion: [it] looks like a simple misspelling to me.
I agreed with Chris (and MWDEU), but the other comments mostly maintain that this can't be a spelling error -- several point out, in support of this claim, that it is very frequent -- and one (from Spindoc) even declares it to be "one of the more common and genuine grammatical errors in the language". I see now that I have once again failed to appreciate that ordinary people just don't distinguish two types of "errors" (Spindoc puts them together in the judgment: "Not a misspelling/typo") and also lump everything that's regulated in language under the heading of "grammar". Let me try to sort this stuff out one more time.
People who study errors in language make a systematic distinction between inadvertent errors -- in the case at hand, slips of the pen or typos -- and another type of mistake, which arises from imperfect command of the conventions at work in the larger community of language users -- in the case at hand, "spelling errors" in the sense of errors involving the conventions of spelling. Writing or typing "teh" for "the" is an inadvertent error, and a very common one. Writing or typing "loose" for the present tense or base form /luz/ of the verb whose past tense is spelled "lost" is, I maintain, almost always something else; people who spell this way, and there are a great many of them, almost always intend that spelling (while those who spell "teh" surely do not intend that spelling).
Now, spelling /luz/ as "loose" is a very likely and natural error to make: "lose" is one of only two English words, and the only verb, with /uz/ spelled "ose" (the spelling of possessive "whose" is equally surprising); the very common verb "choose" has /uz/ spelled "oose"; and anyway there's another very common word "loose" already hanging around. So plenty of people, having learned that /luz/ has a "-se" spelling with an "o" in it (rather than a "u"; "luse" would have been the most likely candidate spelling), opted for the reasonable (though incorrect) "oo" spelling. Unfortunately, the conventional spelling, "lose", is even odder than they realized.
Once you have a lot of people spelling /luz/ as "loose", they can serve as models for other people, so the spelling error will tend to maintain itself and spread. After all, this spelling makes sense; if you can't have "luse", "loose" is the next best thing.
Unless it's done very carefully, instruction might actually make things worse. A kid who learns that there's something odd about the way /luz/ is spelled, and that it has something to do with /lus/, and that lots of people spell it wrong, might simply conclude that the oddity is that these words are homographs, like the present and past tense verb forms spelled "read", and that it's the spelling "lose" that's wrong. That would reinforce "loose" as the spelling for /luz/. Another possible baleful effect of instruction is that the spelling of /lus/ could be cast into doubt; see below.
In passing, I note (once again) that very different kinds of conventions and knowledge are involved in spelling vs. pronunciation, syntax, morphology, vocabulary, and so on (not to mention discourse organization, linguistic politeness, and a variety of other skills of language use). Using "grammar" as a cover term for all this stuff merely sows confusion and misunderstanding.
Some of the comments on lose-to-loose on the eggcorn site suggest that there is confusion in both directions (though I have not seen examples of this), and even that pronunciations are affected (though I have not heard this). Both possibilities are alluded to in a comment from Patricia:
I agree this is not simply a spelling error or typo. "Lose" should not be pronounced in the same way as "Loose" or vice versa, but often is. As an English teacher in the public schools for 25 years, I have marked and remarked, discussed and rediscussed this error in both group settings and one-on-one. My limited successes have been the result of one-on-one, dogged persistence in correcting pronunciation and in insisting on visualizing the difference in the one "o" and the "double o."
I'm inclined to think that Patricia is showing a deep confusion of pronunciation and spelling here, and that her report is really just about more instances of the spelling "loose" for /luz/. But it would be possible for spelling reversal -- "lose" for /lus/ -- to take place, if the spelling of /lus/ (which is not very odd, although you do have to learn to select between "oose" and "uce" for /us/) has been cast into doubt. It's hard to see how you could get the pronunciation of a verb spelled "lose" as /lus/, but I can see how you could end up with a verb with the meaning of "lose" but pronounced /lus/; it would be spelled "loose", of course. This is one thing that could happen from students reading things like "You'll loose your wallet" in the writing of others who are imperfect spellers; after all, "loose" is pronounced /lus/, right? Such a student would have two verbs denoting accidental dispossession -- /luz/, learned from speech, and /lus/, learned from writing. You know, there are people who think that there are two different cities in southern California -- one with a name pronounced like La Hoya and learned from speech, and one with the name La Jolla, pronounced just like it's spelled (in English), learned from writing.
It's worth noting, once again, that very common spelling errors are always the consequence of imperfections in the conventions of spelling. People seek out system in these matters, and resist isolated peculiarities in favor of spellings that play by the general rules.
Somewhere back of the teeth in Glasgow
Another story about language, another case of attributional abduction.
Actually, there are two stories, one by Fiona MacGregor in The Scotsman, and another by Gerard Seenan in the Guardian (based on MacGregor's piece, apparently). Both are about Jim Scobbie's research on sound change in progress in Glasgow. The stories both put forward an interesting research question, and discuss an on-going research project that has turned up new evidence. However, both stories also quote the featured scientist as saying some things that don't quite make sense. In this case, as we've often had occasion to suggest before, it's a good bet to attribute the mistake to the journalists.
The two stories discuss changes in Glaswegian pronunciation that apparently bring it closer to Home Counties standards, and especially the loss of trilled /r/ in some contexts.
Residents of Maryhill, an area of Glasgow perceived to have a "strong" accent, are now dropping the consonant altogether at the end of words with words such as ‘car’ and ‘bar’ are changing in pronunciation to ‘cah’ and ‘bah’.
However, contrary to claims that English television programmes are influencing the way Scots speak, Scobbie believes the dropping of the final R is a natural development.
"To the casual listener it may sound like the R has been dropped completely as it is in England, but when you look at the ultrasound images you can see the tongue starts to shape an R before the sound trails off."
He said if it was a case of merely copying English pronunciation there would be no evidence of the R at all. And he claimed that within Glasgow there were also differences with the dropped R more common in Maryhill than Bearsden.
"There’s a natural tendency in all languages for consonants to become weaker at the end of the word than at the beginning. So you might still get the burred R at the start of word even if people are losing the final R. [from the article in The Scotsman]
So far, so good.
In fact, it's terrific to see questions like these discussed in the popular press. The basic facts are clear and easy for everyone to understand at an elementary level, people are interested in what's happening, and there are some fundamental issues in play. For example, this is the latest in a lengthening series of examples where "loss" of a phoneme has been shown to be the result of weakening a speech gesture to the point where it no longer has its normal acoustic effect, though it still exists in a vestigial form. Phoneticians have traditionally assumed that this sort of thing happens, but as far as I know, the first clear instrumental documentation of this phenomenon was by Louis Goldstein about 20 years ago. The availability of inexpensive, safe ultrasound imaging technology has made it possible to find many additional cases.
You could object a bit to the way the disjunctive choice is set up. Couldn't the influence of r-less mass media be interacting with -- not in opposition to -- the effects of articulatory lenition? And in any case, it's a little odd to frame things as a contrast between the influence of television and "a natural development". If television is part of the world people live in, then their response to television is as natural as their response to anything else, isn't it?
However, the bit that puzzled me came later on:
Scobbie added other changes that had been noticed in pronunciation including a loss of the aspirating H sound. As a consequence, words such as ‘which’ were beginning to be pronounced ‘wich’ north of the border and some young Scots were even being recorded as saying ‘lock’ instead of ‘loch’. [from The Scotsman again]
Now one of the alternative pronunciations of which really does involve "an aspirating H sound", that is, noise generated by turbulent flow of air through the glottis. But the difference between the two pronunciations of loch has nothing to do with "aspirating H" or the larynx, or for that matter anything else connected to the pronunciations of which in any way. The one that MacGregor writes "lock" ends in [k], a voiceless velar stop, whereas the one she writes "loch" ends in [x], a voiceless velar fricative.
I'm sure that Jim Scobbie knows all this at least as well as I do, and probably better, so I'm going to assume without argument that this mistake was introduced by Fiona MacGregor, and then picked up in an even more muddled form by Gerard Seenan in his Guardian story:
Dr Scobbie also noticed a decline in the aspirating "h" sound, with some young Scots committing the cardinal sin of pronouncing loch as lock. [from The Guardian]
Sidestepping the theology here, let's get the articulatory phonetics straight.
From the lips back to the larynx, the IPA names 11 places of articulation:
| bilabial | labiodental | dental | alveolar | postalveolar | retroflex | palatal | velar | uvular | pharyngeal | glottal |
On this drawing of a midsagittal section of a human head, I've indicated with red and blue arrows the approximate location of a velar stop or fricative, and of the glottis where the noise in [h] (and the aspirated [wh] in some pronunciations of which) is created.
As you can see, the velar and glottal positions are both "in the back of the mouth" but otherwise are not very close. Uneducated people often get confused about all those places in back of the teeth, taking a perspective sort of like Saul Steinberg's famous map of the view to the west from 9th Ave.

Looking in from the lips, I guess you can get just as confused about velar vs. glottal articulations as Steinberg's New Yorkers might be about the relative locations of Albuquerque and Los Angeles. Add the fact that loch is spelled with a digraph "ch" to represent the velar fricative written in IPA as [x], and that if you remove the "h" you get "loc", which looks like it should be pronounced the same as "lock", and there you are.
The mistake is not essential to the story -- but think of the fuss if a story in the Guardian referred to "Eastern European countries such as Bulgaria and Belgium".
And whose fault is it that today's intellectuals (including journalists) don't know the difference between spelling and sound, and are ignorant of the elementary geography of the vocal tract? I blame the linguists.
Unwinese
In response to Friday's post about Grammelot, Donal Lynch sent in a pointer to the British comedian Stanley Unwin. This BBC Unwin sampler offers two short passages in Unwinese about language. Here's my quick attempt at an orthographic transcription of the first one.
England joys all concentrate. Corruption of the English, well, English language. So manifest was so many careless. ((They mission it)) a sillibold, like "partic'ly". And ((intrudes ye)) an extra one, like "renovenate" instead of "renovate", as I heard by a zealous cockney who knowed it all. No bother, 'e think it, ((before)) out of the voice box he ho. Oh, no.
Corrections are welcome, since my linguistic and cultural background is inadequate to deal with some of this. For example, what I've transcribed as "intrudes ye" seems to be something like [ɪnˈtru.ʤi] in broad IPA (i.e. it rhymes with "tin fuji").
The practicioners of doubletal, comedic and otherwise, are legion. Their gobbledygook comes in many different forms -- perhaps there is a (folk-) taxonomy of doubletalk somewhere. In any case, doubletalk is often combined with bits of dialect or special spoken registers, perhaps because it's easier to persuade someone they're not quite getting it if the accent and other features index a form of speech that might have unexpected features.
Some more Unwin links: The World of Stanley Unwin; a BBC obit; some Stanley Unwin Transcripts; memorial at Bikwil.
March 13, 2005
Rats off to ya!
 In today's NYT, Dave Itzkoff has an article on Cartoon Network's Adult Swim. If you haven't heard of this late-night collection of idiosyncratic animations, there are two reasons why you might want to check it out. The first reason is demographic:
In today's NYT, Dave Itzkoff has an article on Cartoon Network's Adult Swim. If you haven't heard of this late-night collection of idiosyncratic animations, there are two reasons why you might want to check it out. The first reason is demographic:
When Nielsen begins tracking the block's ratings separately from Cartoon Network's daytime numbers at the end of this month, Turner Broadcasting expects "Adult Swim" to be the top-rated basic cable network among 12-to 34-year-old males.
The second reason, of course, is linguistic.
Itzkoff mentions in passing that the creators of one Adult Swim cartoon are consciously setting out to create catchphrases that will bond the audience to the show and to one another. Fair enough -- this mechanism, whether conscious or not, has worked for entertainers from Shakespeare to Matt Groening. But there's something new this time: it seems that these catchphrases are meaningless to start with, gaining significance only from their role in the show and its subculture. At least that's how Tim Heidecker and Eric Wareheim talk about a phrase promoted in their new series Tom Goes to the Mayor:
The playful visuals of "Tom Goes to the Mayor" are matched by its idiosyncratic sense of humor, one in which a meaningless catchphrase like "rats off to ya!" (a caption from a T-shirt that Tom fruitlessly tried to market) can form the basis for a secret language shared by fans of the show.
"There's no reason for anyone to be saying that," Mr. Wareheim said. "There's no basis for it at all. But people find little sayings like that, and it just takes over their lives. It becomes special to them because it's theirs."
Well, it worked for Monty Python and Star Trek, not to speak of various advertisers and academics too numerous to mention, even if it's traditional to start with a phrase that means something in its original context. But I'm not sure that this one is going to make the grade. A Google search for {"rats off to ya"} produces only 195 hits. Compared to 27,800 for {"I for one welcome"}, or 4,570 for {" No one expects the Spanish Inquisition"}, this suggests that relatively few lives have been taken over by TGTTM so far (though in fairness the episode only aired 12/19/2004). There seems to be some other evidence of lack of TGTTM life-taking-overness as well.
Perhaps you need something more than catchphrases? Or maybe it works better to start with the traditional sort of catchphrase, which functions as an ordinary piece of language in its original context, before being generalized by cultural resonance? I'm not sure about all that, but I can confidently tell you that we haven't heard the last from the catchphrase industry.
[Update: Tim May points out that { "nobody expects the spanish inquisition"} gets "an even more impressive ~14,600" Google hits.]
[Update #2: and of course the disjunction of both patterns gets more hits yet, not to speak of various generalizations of the pattern, as various other readers have written to explain. Here's a table of some additional results:
]
March 12, 2005
No word for sex
Novelist Frank Delaney was on NPR's Weekend Edition today, babbling to Scott Simon about the Irish and how different their world view is from everyone else. We Irish, he explained, have no word for yes in our language, and no word for no. And, he added, "no word for sex! But we're not going to get into that." Not him, maybe, but Language Log is not afraid to get into sex. I immediately suspected that Delaney was gilding the lily, and that this notion — a language with no word for the absolute best way to have fun that does not involve laughing — would turn out to be utter nonsense. I therefore turned, as I have before, to one of the foremost modern Irish specialists in the world, my colleague at UC Santa Cruz, Jim McCloskey. Could it be true, really, I asked him, that Irish has no word for sex?
He sighed the deep sigh of a man who often has to listen to people talking ignorant nonsense about a dying language that he loves and has studied for forty years. And he remarked that FrankDelaney couldn't have spent much time around people who actually speak the language. And he then listed the first few Irish terms for various kinds of sex and sexual activities that came to his mind:
ag bualadh leathair
ag déanamh pite boid
ag déanamh pís ghlaice
ag ealáin
an cleas a dhéanamh
collaíocht
craiceann a bhualadh
craiceann a dhéanamh
cuid a dhéanamh de
focáil
gnéas
(I dare not tell you what these mean, because of FCC regulations. I've put them in alphabetical order. Some dictionaries fail to list some of them, but all are in use in the native-speaker community. Two of the terms refer to masturbation, but hey, as Woody Allen said, that's sex with someone you love. Notice that three of the terms are single words.)
So what on earth can Frank Delaney be thinking of? Why do people say these things about languages they purport to care about, and do absolutely nothing to check up on whether the things they are saying are even remotely close to the truth? Why is everyone so given to bullshitting about language and thought, even about the language of their own countrymen?
The story about Irish lacking particles meaning "yes" and "no" is true, by the way. But it has nothing to do with the Irish mind or spirit or way of looking at the world or the notion of neither agreeing nor disagreeing. In Irish you repeat the verb of someone's clause to agree with it (as if someone said "Got milk?" and the way you gave an affirmative response was to say "Got"), and you repeat their verb with the negation particle in front to deny it ("Not got"). But the same is true of Chinese. Anyone want to suggest that the Chinese have exactly the same cultural propensities and outlook on life as the Irish? More bullshit about language and thought.
Here's some advice. Whenever you hear someone starting to say something that begins with "The X have no word for Y", or "The X have N different words for Y", never listen to them, and always check your wallet to make sure it's still there.
It's not our fault
Eric Gibson doesn't like "Art Since 1900". It's not the art he dislikes, but the book, authored by Hal Foster, Rosalind Krauss, Yves-Alain Bois and Benjamin Buchloh, and just published (3/15/2005) by Thames & Hudson. And he really, really, really doesn't like this book, to the point where he offers this "suggestion for parents of high-school students":
Find out whether the college that your child hopes to attend plans to assign "Art Since 1900" in its art-history courses. If so, apply elsewhere.
Since Gibson is The Wall Street Journal's Leisure & Arts features editor, this may be bad news for admissions statistics at Princeton, Columbia and Harvard, where the book's authors teach. Or maybe not, I don't know. My own interest in the matter is not institutional but disciplinary. Gibson blames everything on psychoanalysis, Marxism -- and linguistics:
Since the early 1980s, the authors have been at the forefront of "the new art history," an interpretive school whose fullest expression can be found in October magazine, a quarterly they founded in 1976. (The name is meant to evoke revolutionary associations.) It was in October that Hal Foster, Rosalind Krauss, Yve-Alain Bois and Benjamin H. D. Buchloh led the charge against the traditional, aesthetic appreciation of art, supplanting it with psychoanalysis, political ideologies such as Marxism and various forms of French theory, like those derived from linguistics. According to this school of thought, a painting isn't merely an abstract or representational image on canvas but a social "text" to be interpreted and deconstructed. [emphasis added]
I'm not sure which of the "various forms of French theory" particularly offend him, but his review mentions Jacques Derrida and Michel Foucault. To the extent that it's possible to determine what these authors mean, I don't find anything important in their "theories" that can be plausibly said to be "derived from linguistics". I'll continue to put off an evaluation of Derrida's language-related ideas -- including the "everything is a text" meme that so clearly offends Gibson -- but let me say for now that his ideas were "derived from linguistics" roughly in the sense that the views of the Marquis de Sade were derived from Catholicism.
As for Foucault, the article about him in the Stanford Encyclopedia of Philosophy does mention (the famous linguist) Saussure, but describes nothing that I would call a consequential influence. And along with works on prisons, clinics and sex, Foucault did once write a book called "Les mots et les choses" ("words and things"), in which he (very obscurely) discusses (the early linguist) Rasmus Rask along with David Ricardo and the Comte de Buffon. But on that evidence, you might as well say that Foucault's theories are "derived from economics" or "derived from biology".
So why might Gibson blame Foucault & Co. on linguistics? Perhaps it has something to do with the modern continental-philosophy sense of discourse:
1976 T. EAGLETON Crit. & Ideology ii. 54 A dominant ideological formation is constituted by a relatively coherent set of ‘discourses’ of values, representations and beliefs.
I'm sorry to say that I found that quotation in the OED's 1993 additions to the entry for discourse the noun, as a citation for an additional sense attributed to linguistics:
[3.] e. Linguistics. A connected series of utterances by which meaning is communicated, esp. forming a unit for analysis; spoken or written communication regarded as consisting of such utterances. Also transf. in Semiotics.
But the Eagleton quote is not about that sense of discourse at all. The other citations are mostly appropriate ones for the gloss given:
1951 Z. S. HARRIS Methods in Structural Linguistics iii. 28 For the incidence of formal features of this type only long discourses or conversations can serve as samples of the language.
1957 G. L. TRAGER in Encycl. Brit. XIV. 162H/2 The syntax of any language can be arrived at in analogous ways. The phonologically determined parts of a discourse are found, and their constituent phrases separated out.
1983 BROWN & YULE Discourse Analysis ii. 29 We can see little practical use, in the analysis of discourse, for the notion of logical presupposition.
This sense of discourse is relatively straightforward -- it just means "chunks of speech or text bigger than a sentence", such as stories, conversations, arguments and so on. "Discourse analysis" in this sense is just "the analysis of the form, meaning and use of language in pieces bigger than a sentence".
But what Foucault and his followers mean by a discourse is something completely different. I haven't been able to find a good definition -- the Foucaultian culture is not one in which clarity is prized -- but it seems to mean something like "a set of social norms that define who can talk how about what, to whom and when, including provision of words, phrases and larger linguistic forms, as well as restrictions on accessible ideas and assumptions".
Here is a set of somewhat random selections from the first page or so of what Google returns for {Foucault discourse}:
To Foucault, discourse is just one of the rules of society he examines critically. Language too, he argues, transcends and even obviates individual perception rather than allows our independent existence to flourish.
What interested him were the rules and practices that produced meaningful statements and regulated discourse in different historical periods.
Discourse is "a group of statements which provide a language for talking about ...a particular topic at a particular historical moment".
Discourse, Foucault argues, constructs the topic. It defines and produces the objects of our knowledge. It governs the way that a topic can be meaningfully talked about and reasoned about.
In more general terms for F. it is discourse as a medium for power that produces subjects or, as he puts it, "speaking subjects," which, for him, are the only kind there are.
"[I]n every society the production of discourse is at once controlled, selected, organised and redistributed according to a certain number of procedures, whose role is to avert its power and its dangers, to cope with chance events, to evade its ponderous, awesome materiality"
Discourse operates by "rules of exclusion" concerning what is prohibited. Specifically, discourse is controlled in terms of objects (what can be spoken of), ritual (where and how one may speak), and the privileged or exclusive right to speak of certain subjects (who may speak).
This kind of discourse is produced by a "will to knowledge" or "will to power," wherein discourses "discipline" us: "a will to knowledge emerged which . . . sketched out a schema of possible, observable, measurable and classifiable objects; a will to knowledge which imposed upon the knowing subject-in some ways taking precedence over all experience-a certain position, a certain viewpoint, and a certain function . . . " (218). So the will to knowledge or truth or power has a history-"of a range of subjects to be learned, the history of the functions of the knowing subject," etc.
Some of the most important contemporary discourses are "disciplines," by which he particularly means academic disciplines that discipline our thinking. Disciplines are "opposed to . . . the author, because disciplines are defined by groups of objects, methods, . . . the interplay of rules and definitions, of techniques and tools: all these constitute a sort of anonymous system . . . without there being any question of their meaning or their validity being derived from whoever happened to invent them"
You can argue about whether particular pieces of this stuff are meaningful or meaningless, profound or trivial, useful or useless, true or false. You could even argue that this is the kind of thing that linguists ought to have thought about and worked on, in principle, since it purports to establish a general framework for how language can be used in a given place and time. But in sober historical fact, none of this is "derived from linguistics", and linguistics has been less affected by this discourse discourse than any of the other fields in the humanities and social sciences. [Well, except maybe for economics..]
It's ironic, even poignant, to blame the discipline of linguistics for postmodern "theory", since its proponents in the American academy generally appear to despise linguistics. They haven't in general studied linguistics themselves, and they've removed not only requirements but even recommendations for linguistics courses from the curriculum for their undergraduate majors and graduate students alike. Some of the blame for this estrangement belongs to the linguists, no doubt, but regardless of fault, the rise of postmodernism has been a disaster for our field.
So, Mr. Gibson, give us linguists a break. We didn't do it!
March 11, 2005
More WTF coordinations
As I noted in an update to my post on my reaction to an odd coordination that I read, Neal Whitman wrote to tell me about his recent article in Language 80.3 (pp. 403-434) on this topic, entitled "Semantics and Pragmatics of English Verbal Dependent Coordination" (sorry, access to Project Muse required for the link to work). Neal also provided the following additional examples:
It makes it hard for him to get [his stuff done] and [to bed on time].
She wants [an engagement ring] and [her boyfriend to stop dragging his feet].
Don't eat [fast food], or [at restaurants, food-service companies, or caterers].
The last of these examples is perfectly fine for me, underscoring the apprehensiveness I had about saying that only phrases with the same syntactic category can be conjoined: [fast food] is a noun phrase, and [at restaurants ...] is a prepositional phrase. The other two examples are different, though; my knee-jerk, WTF reaction is to give the first a question mark (by which I mean that it's somehow borderline between grammatical and ungrammatical) and the second a star (by which I mean that it's ungrammatical -- except that it improves somewhat if a for is added before the second conjunct).
Mike Pope also wrote to comment:
Would you say that this is a form of zeugma? The small child of a friend of mine once said "The sun makes you hot and sneeze," which seems at least similar in spirit to what you've got here.
As explained here, zeugma is "A construction in which a single word, especially a verb or an adjective, is applied to two or more nouns when its sense is appropriate to only one of them or to both in different ways, as in He took my advice and my wallet."
This [my advice] and [my wallet] (noun phrase and noun phrase) example is fine for me; Mike's [hot] and [sneeze] (adjective and verb) example is not (but it must have been fun to hear a kid say it). If they're both just examples of zeugma, why is that? WTF?
Now consider the following example (from Life of Pi, pg. 37):
I nodded so hard I'm surprised my neck didn't snap and my head fall to the floor.
When I first read this a few months ago, I had an even bigger WTF reaction than for any of the others. But I immediately reasoned through it and now find it almost perfectly grammatical. All that it took was the recognition that the negation expressed by "didn't" in the first conjunct takes scope over both conjuncts ...
NOT [ [my neck snap] and [my head fall to the floor] ]
... and that this means something subtley different from having two negations, each taking scope over one of the conjuncts ...
[ NOT [my neck snap] and [ NOT [my head fall to the floor] ]
as in:
I nodded so hard I'm surprised my neck didn't snap and my head didn't fall to the floor.
Which is ambiguous (as my colleague Andy Kehler pointed out to me) between a reading in which the neck-snapping causes the head-falling and one in which there is no causation (as pragmatically odd as that might be); in other words, causation between the first and second conjuncts is not necessary in this second sentence while it is in the original.
(Andy also reminds me of Arnold Zwicky's post from last August about grammatical and ungrammatical coordinations, sparked in part by a suggestion by Neal Whitman. Some of us here at UCSD are planning to read and discuss Neal's Language paper sometime next quarter; if anything particularly interesting comes out of that -- or if we have any more WTF reactions worth commenting on -- you'll hear about it here on Language Log.)
[ Comments? ]
Simlish as 21st-century Grammelot?
The things I've read about Grammelot, and the bits of it that I've heard, remind me of Simlish, the fake language used in The Sims and its follow-on games. In case you're not a Sims person, here's a bit of Simlish motherese and some Simlish food enjoyment, just to give you the flavor of this "language".
According to the article on Simlish where I found those samples:
... when The Sims was originally designed Will Wright wanted the language the Sims spoke to be unrecognizable but full of emotion. That way, every player could construct their own story without being confined to a Maxis-written script (to say nothing of the mind-numbing repetition). We experimented with fractured Ukrainian (one of the original The Sims designers was a native speaker), and the Tagalog language of The Philippines. Will even suggested that perhaps we base the sound on Navajo, inspired by the code talkers of WWII. None of those languages allowed us the sound we were looking for – so we opted for complete improvisation, originated and performed by some SF Bay Area professional actors whose specialty was improv; Stephen Kearin and Gerri Lawlor.
So now it is five years since Simlish was born, and the tradition is carried on by an additional nine actors performing all the age range voices: baby, toddler, child, teen, adult and elder. The auditions were held January through May 2003 with over 100 actors from SF and LA trying out. We selected a highly talented cast and quickly got them to work recording many full 8 hour days, recording voice to over a hundred animations a day, resulting in thousands of takes a day.
With such a huge amount of voice data - 40,620 samples at the moment our pre- and post-production processes have been streamlined to get the voice into the game so it can be listened to, assessed and either re-recorded (in rare cases) or hacked (constructed out of similar-sounding files) . Currently there are at least six Maxoids dedicated to getting the sound effects and voice in the game.And even though I said Simlish is not a language per se, there are some common words that we directed all the actors to perform. If you listen closely, you’ll hear a word that means baby (nooboo), another for pizza (chumcha), and another phrase said during the Dirty Joke interaction that isn’t exactly defined, but just seemed to fit. That one was invented by Liz Mamorsky, our elder female voice.
Near the bottom of this page, there's a link to a video interview with one of the people who does Simlish "voiceovers" (described as "a behind the scenes look at how Simlish is created"). There are now pop songs in Simlish, and Ravi Purushotma thinks that Simlish is a good way to teach foreign languages. Well, really, it's the textual instructions that give the foreign language practice -- but the characters give you feedback in Simlish if you misunderstand and (say) have your character take a shower when what he really needs is lunch.
Here's a recent interview with Will Wright, the creator of The Sims and its sequels and add-ons.
[Update: A sort of Simlish dictionary is available.]
Bovine excrement on NPR
In connection with Harry Frankfurt's book Bullshit
(discussed briefly on Language Log
here,
here,
and
here),
I forgot to mention a week ago that I heard a National Public Radio talk
show devoted to the book, with Professor Frankfurt on the line to talk
about his book and various other professors and comentators brought in
from time to time; but because of the goddamn
Federal Communications Commission,
no one was at any time during the hour
permitted to mention the name or the topic of the book.
Makes you proud to be an American, don't it?
You can use it, you can speak it all the time,
but you won't ever have to face it being named on the radio...
Gibberish by any other name
David Donnell sent in a link to an item in the Dover-Sherborn Press concerning the "magical sounding gibberish language called Trammeled that originated in Europe centuries ago":
Alexander, King of Jesters, will perform his unusual comedy at Kraft Hall in Dover Church Sunday, March 20, 3 p.m. [...] This offbeat performance includes Renaissance water spitting, the nose flute serenade, jingle bell juggling, twisted sticks of the forest, balancing stunts high above the audience and other unusual routines inspired by the tradition of the fool.
Alexander enjoys surprising his audience with a rapid fire of visual gags. In one routine, he observes them through a darting eyeball in his mouth shortly before he crams three flutes into his mouth. Without missing a beat, he plays a sweet tune in staggered rhythms on all three at once.
During the act, Alexander speaks a magical sounding gibberish language called Trammeled that originated in Europe centuries ago. In those times, nearly every village had its own dialect, sometimes even a completely different language. Trammeled helped traveling jesters and minstrels cut through language barriers that presented themselves every few miles. It serves Alexander today, since he often performs abroad.
David was intrigued:
I don't know what kind of lingo "Trammeled" is, but it sure sounds magical... On one hand it's "gibberish", on the other it's useful "abroad" and helps "cut through language barriers"!
I Googled it quickly, but didn't see any refs to a language by that name.
Me either. But checking for "Alexander, King of Jesters" turned up this study guide from the Alaska Junior Theater, in Fairbanks, which mentions "the jester gibberish language 'Grammelot'". Alexander's Alaska hand-out says that
Many jesters and fools spoke a gibberish language called Grammelot that was first described over 500 years ago. It consisted of funny sounds along with a few real words from different languages. Although Grammelot could not say everything quite as clearly as a real language, it could express general ideas and it engaged people's imaginations. It also turned out to be very practical because:
1. Villages were remote centuries ago. They were separated by dark woods. The terrible roads made it was hard to leave town, and without TV or radio, the peasants of one village may never hear the accent of the people in the next town. As a result, even neighboring villages might not understand each other. Every town spoke a little differently, and so each town had their own dialect. Sometimes they spoke very differently, and had their very own language. Not surprisingly, there were far more languages then than there are today.
2. Free speech was not a right centuries ago In the days before mass media, it was the traveling perform-ers who gave peasants much of their news of the outside world. If anyone said something that angered the king or queen, he or she could easily be thrown in jail. The censors watched performers very closely. The censors were the people hired by the king or queen to make sure that nothing was said that could upset them or the royal court. If the jesters spoke Grammelot, the censors were less likely to give them a hard time, since nobody knew exactly what they were saying.
The "study guide" also provides a glossary for "Alexander's version of Grammelot":
co yo yo - curly or twisted. It is also used in slang to mean 'wow' since jesters prefer things that are twisted and bent.
hodio tonada - an exclamation of surprise like “woah, check it out!”
Waga dee bwa - I am
Waga da bala - He is
Kafuggo! - darn it!
bo-whoo - (low voice) the big one
wuh hoo - the medium one
eee oo - (pronounced in a high voice) the little one
bweesta - fish
galeggwi - up
jiffa - middle
peet - down
Basnop ka dipple yadda yadda - rather than try to fix the problem, just validate my feelings
Kafuggo! Snippa blop! - But I'm just trying to help!
Right.
Well, Grammelot is apparently for real:
Il Grammelot è una forma di teatro inventata dai comici della Commedia dell’Arte del 1400 ed è organizzata in chiave onomatopeica, ossia il riuscire a far arrivare concetti attraverso suoni che non sono parole stabilite, convenzionali.
Questi giullari usano intruglio di dialetti e parole inventate che rendono immediata e molto colorita la recitazione, nella quale predomina anche una gestualità ed una mimica molto accentuate.Dall’insieme di queste componenti viene fuori un tipo di teatro estremamente espressivo, iperbolico, esilarante, viscerale, diretto e quindi comprensibile un po’ dappertutto e ad ogni tipo di pubblico.
Un modo di recitare in cui il linguaggio usato perde di significato letterale, per diventare suono, vibrazione, musicalità che comunica emozioni e suggestioni.
Grammelot is a form of theater invented by the comic actors of the Commedia dell'Arte of 1400, and is organized in an onomatopoeic mode, that is, it manages to evoke concepts by means of sounds that are not established or conventional words. These jokers use a mixture (?) of dialect and invented words that make for a vivid and very colorful performance, in which exaggerated gesture and mimicry are also very prominent.
From the combination of these components there emerges a type of theater that is extremely expressive, hyperbolic, hilarious, visceral, direct and therefore somewhat comprehensible everywhere and to every type of audience.
A way of speaking in which the language that is used loses its literal meaning, in order to become sound, pulsation, musicality that communicates emotions and suggestions. [apologies for my translation -- I read Italian by triangulation from Latin and French...]
There are some quicktime videos with transcripts on the same site.
The word grammelot is not in the OED -- which is a surprise -- nor in the other dictionaries that I checked. Apparently this word has never caught on in the history of the English language. For example, it doesn't occur in the LION database. Perhaps there is some other word that's used instead.
Anyhow, the one remaining mystery is how grammelot got morphed into trammeled over at the Dover-Sherborn Press. A clue is provided by the fact that the very same wording recurs in other announcements for Alexander, King of Jesters:
During the act, Alexander speaks a magical sounding gibberish language called Trammeled that originated in Europe centuries ago. In those times, nearly every village had its own dialect, sometimes even a completely different language. Trammeled helped traveling jesters and minstrels cut through language barriers that presented themselves every few miles. It serves Alexander today, since he often performs abroad. (from the Dover-Sherborn Press)
During the act, Alexander speaks a magical-sounding gibberish language called Grammelot that originated in Europe centuries ago. In those times nearly every village had its own dialect, sometimes even a completely different language. Grammelot helped traveling jesters and minstrels cut through language barriers that presented themselves every few miles. It serves Alexander today since he often performs abroad. (from the Wilbraham Public Library News)
As you can see, these passages are identical except for some differences in punctuation and the Grammelot -> Trammeled substitution. I think we can assume that this was a scribal error in a chain mediated by speech. Perhaps the reporter called in the story, reading Alexander's press materials, to someone who typed it up from the tape. Or perhaps the reporter used an automatic speech-to-text dictation system, which of course did not have grammelot in its lexicon, and then didn't proofread carefully enough. My money is on ASR.
Please notice that I resisted the temptation to make the audio track of a Grammelot monologue into a language identification quiz. (I do have another quiz queued up, contributed some time ago by Stefano Taschini, which I have neglectfully failed to post...)
[Update: several people have written in to point out that Microsoft Word's spelling checker corrects "Grammelot" to "Trammeled", and is therefore the most probable culprit in this case.]
[Update 3/12/2005: Ray Girvan has turned up some more accurate information on the origins of (recent versions of) Grammelot:
The modern popularisation seems to have sprung from Dario Fo's one-man touring show, "Mistero Buffo", Various references imply that while Grammelot existed generically, he has reinvented it in a personal form tailored for modern relevance. The Times review of "Mistero Buffo" (Saturday, Apr 30, 1983) mentions that his three grammelot sketches, though based on mediaeval texts, were performed in separate Italian, French and American grammelots.
Dario Fo biography:
"'grammelot', a language derived from the mixture of modern phonemes and dead dialects from Italy's Po valley area".Fo's own Nobel speech:
"Ruzzante, the true father of the Commedia dell'Arte, also constructed a language of his own, a language of and for the theatre, based on a variety of tongues: the dialects of the Po Valley, expressions in Latin, Spanish, even German, all mixed with onomatopoeic sounds of his own invention. It is from him, from Beolco Ruzzante, that I've learned to free myself from conventional literary writing and to express myself with words that you can chew, with unusual sounds, with various techniques of rhythm and breathing, even with the rambling nonsense-speech of the grammelot".http://mercury.web.ca/archives/caea-l/2004-October/001672.html:
The Italian Cultural Institute, in association with BellaLuna Productions Presents a one-day workshop with Mario Pirovano, Italian protégé of Nobel Prize-winning Playwright Dario Fo.: Part 2 ... Grammelot re-invented by Dario Fo and its present-day relevance.http://lists.econ.utah.edu/pipermail/marxism-thaxis/1997-October/003972.html:
His one-man tour de force, "Mistero Buffo" ("Comic Mystery"), written in 1969, finally had its United States premiere at the Joyce Theater in Chelsea in 1986. It has its stylistic roots in the strolling players and minstrels of the Middle Ages. But it was also a timely satirical blast at religion and politics, delivered in Grammelot, a kind of double-speak masquerading as a language, wholly invented by Fo himself.
Apparently "Ruzzante" (real name Angelo Beolco) wrote in Paduan dialect. Whether the bits of German and so on that Fo remarks on were part of the rural speech of the period, or Beolco's introductions, is not clear to me.
Ray adds:Although similar languages have precedents - eg Lingua Franca, Polari - it wouldn't surprise me if Fo had coined the term "Grammelot".
Reinventing macaronic language seems to be a particular fascination for modern Italian authors (this recalls Umberto Eco - Salvatore in "The Name of the Rose" and the peasant hero of "Baudolino" use similar languages).
Ray also points out this article entitled "The Modern Macaronic", by Albert Sbragia, dealing especially with Carlo Emilio Gadda. An interesting quote:
The Renaissance macaronic in its purest form is a northern Italian creation with its precedents in medieval burlesque, goliardic verse and sacred parodies, and with extra-Italian continuators and resonances in various European countries and in Rabelais. Its origins lie in the late fifteenth-century Benedictine athenaeum of Padua and specifically in the linguistic experimentalism of Tifi Odasi, whose poem Macaronea defines the genre. Its fame was assured in the first half of the following century by Odasi's Mantuan pupil and emulator Teofilo Folengo (pseudonym Merlin Cocai). Folengo's Baldus (four editions: 1517, 1521, 1534-35, and posthumously in 1552) is a mock-epic poem of giants and farfetched chivalric adventures including the discovery of the mouth of the Nile and a final descent into Hell. Baldus is the genre's acknowledged masterpiece, and it enjoyed a notable popularity in the 1500s with over a dozen editions and reprintings. It was not without influence on Rabelais's Gargantua and Pantagruel, in which it is cited more than once. Such was the perceived connection that the first French translation of Folengo's works in 1606 bore the title Histoire maccaronique de Merlin Coccaie, prototype de Rablais.
The original macaronic is characterised linguistically by its vocabulary of Italian, dialect, and Latin words within a substantially Latin morphological, syntactic, and prosodic form. The hybridisation is typically trilingual in the northern Italian macaronic poets involving Latin, Italian (Tuscan), and Po Valley dialects. Not the natural or ingenuous product of a native plurilingualism, the Italian macaronic is a sophisticated caricatural artifice, a linguistic parody which exploits the situation of polyglossia experienced by the cultural elite. The demise of the original macaronic is due precisely to the success of the Italian humanists in their philological recuperation of classical Latin which had made possible the complexity of macaronic verse in the first place. Latin as a literary language was frozen in a normative a chronological straitjacket as an eminently noble but irremeably ancient language. As a result, Tuscan Italian was finally able to assert itself fully as the contemporary national language of letters, and it underwent much of the same normative and chronological classicising restrictions as had Latin. From a state of triglossia the linguistic and literary evolution the Italian peninsula would evolve more clearly as a case of fragmented diglossia, with numerous epicentres of dialect in tension with written and literary Italian.
]
[Update -- more on grammelot here.]
March 10, 2005
Stunningly inept modifier manners
A small circle of grammarians that I belong to (Rodney Huddleston, Chris Potts, Arnold Zwicky, and me) collects "dangling modifier" examples (I said something about some related examples in this recent post). That is, we are collecting published sentences in which a fronted modifier constituent that is intended to have a predicative interpretation (roughly, it is meant to have an understood subject) gets interpreted with something other than the matrix clause subject as its intended subject, or fails to be interpreted with an appropriate subject at all. Arnold Zwicky recently collected a speciment in a Palo Alto Daily News story (March 5, page 69) about the Palo Alto Toyota dealership, which is probably going to have to move to a larger site outside of the city to gain higher sales volume, according to the manager, Mr Kopacz. The story focuses mainly on the plans for the new site. But then it continues:
Generating $66 million in sales revenue last year, Kopacz estimates that a larger dealership with a freeway billboard could generate $130 to $140 million in sales.
Who's doing all that generating? Kopacz?
As Arnold remarked when he sent this example around, there's no way you can get that initial clause generating $66 million in sales revenue last year to feel like it's about the present dealership. Struggling to find a suitable subject for generating, one comes upon the main clause subject Kopacz, and one inexorably comes to think for a few seconds that he is the one generating that sales revenue. But's that's not what they meant. They meant that the old dealership soon to be replaced generated $66 million last year. But they didn't make that clear.
Arnold calls the sentence "stunningly inept". I agree with him. The line we take on examples of this kind, you see, is not that they violate the syntactic correctness conditions for English — they are simply too common for that to be the case. Roughly, what we think is that the syntax of English leaves things open for you to design your paragraphs in such a way that preposed non-finite adjunct clauses will, in context, be easily and naturally linked up with suitable understood subjects. And as always when you are left some freedom to do things whichever way you judge to be appropriate, you can screw it up. You can write something stunningly inept that baffles the heck out of an intelligent reader for several seconds. As I've said before, that should at the very least count as bad grammatical manners, the syntactic analog of dining goofs like rinsing your fingers in the consommé, or eating the butter from the butter dish.
Fragments from my to-blog list
Blogdigger is a useful way to search blogs, somewhat complementary to technorati (and lots faster).
Jean Véronis documents a strangely exact doubling of Yahoo's search count. And I've been meaning for a while to link to his exploration of yoghurt spelling on the web (in French).
Chris Waigl links to Avibase, "a multilingual bird database with 1.9 million entries on 10,000 species and 22,000 sub-species. In case you need to know that the Black-crowned Sparrow-Lark is called Saharanvarpuskiuru in Finnish."
There's a story in Wired on the Phraselator speech-to-speech translation device, which has been used in recent tsunami relief operations as well as in Afghanistan and Iraq.
Cultural Constraints on Grammar
Dan Everett wrote to say that his paper "Cultural Constraints on Grammar" will be published in Current Anthropology as a main article, for which the journal will solicit 15 commentaries.
Here's the abstract:
The Pirahã language challenges simplistic application of Hockett's (1960) nearly universally-accepted 'design features of human language', by showing that some of these design features (interchangeability, displacement, and productivity) may be culturally constrained. In particular Pirahã culture constrains communication to non-abstract subjects which fall within the immediate experience of interlocutors. This constraint explains several very surprising features of Pirahã grammar and culture: (i) the absence of creation myths and fiction; (ii) the simplest kinship system yet documented; (iii) the absence of numbers of any kind or a concept of counting; (iv) the absence of color terms; (v) the absence of embedding in the grammar; (vi) the absence of 'relative tenses'; (vii) the borrowing of its entire pronoun inventory from Tupi; (vi) the fact that the Pirahã are monolingual after more than 200 years of regular contact with Brazilians and the Tupi-Guarani-speaking Kawahiv; (vii) the absence of any individual or collective memory of more than two generations past; (viii) the absence of drawing or other art and one of the simplest material cultures yet documented; (ix) the absence of any terms for quantification, e.g. 'all', 'each', 'every', 'most', 'some', etc.
It's worth underlining that Dan sees the situation in terms of "cultural constraints on grammar". Some people see the question as whether language constrains (individual) thought, with culture emerging as a kind of amalgam of the psychology of individuals. Dan takes a different perspective:
Before beginning in earnest, I should say something about my distinction between 'culture' and 'language'. To linguists this is a natural distinction. To anthropologists it is not. My own view of the relationship is that the anthropological perspective is the more useful. But that is exactly what this paper purports to show. Therefore, although I begin with what will strike most anthropologists as a strange division between the form of communication (language) and the ways of meaning (culture) from which it emerges, the conclusion of the paper is that the division is not in fact a very useful one and that Sapir, Boas, and the anthropological tradition generally has this right. In this sense, this paper may be taken as an argument that anthropology and linguistics are perhaps more closely aligned than, say, psychology and linguistics, as most modern linguists (whether 'functional' or 'formal') suppose.
Thus Dan is separating Whorf (at least as he is generally understood) from Sapir, and aligning himself with Sapir:
I also argue against a simple Whorfian view, i.e. against the idea that linguistic relativity or determinism alone can account for the facts under consideration. In fact, I also argue that the unidirectionality inherent in linguistic relativity may offer an insufficient tool for language-cognition connections more generally, for failing to offer a more fundamental role for culture in shaping language.
Dan's article is an important one, and if you're interested enough in language to be perusing this blog, you should read it.
Exercise for the reader: if Dan's analysis of Pirahã is correct, what are the implications for studying languages like English? Turning it around, what are the implications for these ideas of what we know about languages like English and the cultures they're embedded in?
March 09, 2005
Up for the downshift
My radio alarm is set to my local public radio station. This morning, I woke up to hear the following:
... and then rotate it clockwise, as I'm looking at it ...
It turns out this was the second part of a two-part story on two wounded Marines, and Marine 1st Sgt. Brad Kasal was talking about a contraption on his wounded leg; as NPR's Joseph Shapiro explains: "Twist one of the screws, and Kasal's bone is literally pulled apart, just a tiny bit. That stimulates the bone to grow; the muscles, nerves, blood vessels, and skin too. Eventually, Kasal will turn these screws himself, a little every day." Kasal goes on: "Right now the doctors are still doing it, and it's relatively simple. It's a little bit uncomfortable ... well, quite a bit uncomfortable ..."
Now I have no idea what this contraption (called a "ring external fixater") looks like or how the screws are oriented, but I think it's safe to assume that the distinction between turning them clockwise and turning them counterclockwise is pretty important. This reminded me of the (comparatively far more trivial) discussion a few months ago about shuttle-loop directions and related matters (see here, here, here, here , here, here, here, and even over there).
Actually, I've just been searching for an excuse to come back to this issue, because I spent quite a bit of time thinking about it in relation to bicycles -- specifically, the gear shifters on mountain bikes. (If you're really interested in the technicalities of this topic, I suggest looking here and/or here. I need to get into a few technicalities here, but I'm putting aside the more complicated and interesting ones in the interests of my own time.)
In case you didn't know, gear shifters are the things on your handlebars that allow you to change gears. The shifter on the left-hand side of the handlebar (as you're mounted on the bike -- the shifter you would control with your left hand while riding normally) controls the front derailleur and the one on the right-hand side controls the rear derailleur. As explained here:
The derailleur is the device that changes gears by moving the chain from one sprocket to another. There are two derailleurs: one on the rear and one on the front. The highest ratio (when the bike can go fastest) is produced when the chain is on the biggest sprocket in the front and the smallest in back. The lowest ratio (the bike is easiest to pedal up hills, but very slow) is produced when the chain is on the smallest sprocket in front and the biggest in back.
In the front, the biggest sprocket is on the outside and the smallest is on the inside; in the back, the smallest is on the outside and the biggest is on the inside. Thus, when you're in the lowest gear, the chain is more or less parallel and flush with the bike frame; when you're in the highest gear, the chain is parallel but furthest away from the frame.
A lot of this information is second nature to many biking enthusiasts, but the average bike-riding person doesn't care about anything other than the following distinction: shifting one way makes it easier to go uphill, shifting the opposite way makes you go faster otherwise. Reflecting this need of the average Joe, many (standard) gear shifters have numbers to indicate the difficulty of the gear. For example, a 21-gear bike (3 sprockets in the front, 7 in the back) has numbers 1-3 (easiest-hardest) indicated on the left-hand shifter and 1-7 (also easiest-hardest) on the right-hand shifter.
Over the past 15 years or so I've ridden mountain bikes with three types of shifters, which I believe entered the market more or less in the following order. (There are probably other, newer, cooler, better, more expensive ones now; I limit my attention to these three.)
- "lever shifters", with which you shift gears by moving a lever back and forth with your thumb and/or forefinger -- or maybe left and right or up and down, depending on the lever's orientation on the handlebars. Moving the lever one way shifts to a higher gear, moving it the other way shifts to a lower gear.
- "click shifters", which which you shift gears by clicking one of two buttons, usually oriented one on top of the other within easy access of the thumb and/or forefinger. Clicking one button shifts to a higher gear, clicking the other shifts to a lower gear.
- "grip shifters", with which you shift gears by turning a knob embedded in the handlebar grips themselves, such that you simply have to rotate your wrist one way or the other (toward you or away from you). Rotating your wrist one way ... well, you get the idea.
Here in San Diego I own a bike with click shifters, but while I was in Vancouver last term I bought a used bike with grip shifters. While riding the Vancouver bike I noticed something interesting (and relevant to the shuttle-loop business): with the right-hand shifter, I had to rotate my wrist away from me to shift to a higher gear (which is sort of intuitive -- it feels more or less like "up", and "up" = "higher"), but with the left-hand shifter I had to rotate my wrist toward me to shift to a higher gear (which is sort of counterintuitive, mutatis mutandis).
If you're having trouble picturing this, here's another way to look at it. Suppose I'm on my bike and you're standing beside it, facing it from the right-hand side (like this). To shift to a higher gear, I would rotate my right wrist in such a way that it would turn clockwise from your point of view. If you changed your point of view by standing on the other side of my bike, my left wrist would also turn clockwise when I shift to a higher gear.
{kind=link}
But as the person riding the bike, I only have one possible point of view -- and from that point of view, my wrists rotate in opposite directions to achieve what is essentially the same goal. Why did the bike (part) manufacturers do this? My brother, an avid cyclist, suggests that maybe it's because the real goal is not higher vs. lower gear, but smaller vs. larger chain sprocket. (Recall that the effect of shifting to the larger chain sprocket in the front is the same as shifting to the smaller one in the back and vice-versa.) He may be right, but this seems about as un-user-friendly as you can get in terms of design.
Another possibility I'm entertaining (at least until someone else suggests something else, or better yet settles the matter) is that someone at least as convincing as Geoff Pullum was somehow involved in the early design phase of the original grip shifters. This hypothetical person persuaded the engineers that the way to look at the shifters was from each side of the bike, and that the distinction between "clockwise" and "counterclockwise" should be perfectly understandable to anyone. The engineers, not wanting to seem like idiots, agreed.
[ Comments? ]
More bullshit grammar
In addition to referring to a bunch of nouns as adjectives, Timothy Noah's review of Harry Frankfurt's On Bullshit makes a second error in grammatical analysis.
Noah writes:
Although Frankfurt doesn't point this out, it immediately occurred to me upon closing his book that the word "bullshit" is both noun and verb, and that this duality distinguishes bullshit not only from the aforementioned Menckenesque antecedents, but also from its contemporary near-relative, horseshit. It is possible to bullshit somebody, but it is not possible to poppycock, or to twaddle, or to horseshit anyone. When we speak of bullshit, then, we speak, implicitly, of the action that brought the bullshit into being: Somebody bullshitted. In this respect the word "bullshit" is identical to the word "lie," for when we speak of a lie we speak, implicitly, of the action that brought the lie into being: Somebody lied.
But actually, of the 14 "Menckenesque antecedents" that Noah cites (humbug, poppycock, tommyrot, hooey, twaddle, balderdash, claptrap, palaver, hogwash, buncombe (or "bunk"), hokum, drivel, flapdoodle, bullpucky), four are given a verbal sense by the American Heritage Dictionary: humbug, twaddle, palaver, and drivel.
A quick check in the OED adds some others from the list that are cited as verbs:
1821 W. IRVING in Warner Life (1882) 136 A fostered growth of poetry and romance, and balderdashed with false sentiment.
1893 Westm. Gaz. 11 July 2/1 He flapdoodled round the subject in the usual Archiepiscopal way.
The OED also reveals that some of these were verbs before they were nouns (at least in the bullshit-related sense) -- thus drivel as a verb meaning "To talk childishly or idiotically; to let silly nonsense drop from the lips; to rave" from 1362, vs. drivel as a noun meaning "Idiotic utterance; silly nonsense; twaddle" from 1852.
Several of the others on Noah's list are sometimes painlessly verbed, as a simple net search verifies:
Balderdashing into doom [6/22/2004 WaPo headline]
Who's this hokey honky tryin to hooey? (link)
When Gianera let the casual acquaintance into his home, Mullin cried “You’re claptrapping me!” and shot Jim as he tried to escape. (link)
And I am not horseshitting you, I really did do it. (link)
It appears Marilyn Stowe was hogwashing us. (link)
It's certainly true that bullshit is used more commonly as a verb than these other words are -- but it's also used more commonly, period (e.g. 3,040,000 ghits for bullshit vs. 171,000 for twaddle or 84,800 for horseshit).
Unlike the "nouns are adjectives" mistake, this one seems to arise from carelessness about what is being claimed and lack of concern for what the relevant facts really are. So ironically, the insight about the word bullshit that Noah starts his column with -- is itself bullshit. I mean this in the specific technical sense of the term that derives from Frankfurt: "bullshitters seek to convey a certain impression of themselves without being concerned about whether anything at all is true".
Noah's review seems to be calculated to place the rhetorical ball so that he can spike it into the teeth of the Bush administration. He ends this way:
The Bush administration is clearly more bullshit-heavy than its predecessors. Slate's founding editor, Michael Kinsley, put his finger on the Bush administration's particular style of lying three years ago:
If the truth was too precious to waste on politics for Bush I and a challenge to overcome for Clinton, for our current George Bush it is simply boring and uncool. Bush II administration lies are often so laughably obvious that you wonder why they bother. Until you realize: They haven't bothered.
But by Frankfurt's lights, what Bush does isn't lying at all. It's bullshitting. Whatever you choose to call it, Bush's indifference to the truth is indeed more troubling, in many ways, than what Frankfurt calls "lying" would be. Richard Nixon knew he was bombing Cambodia. Does George W. Bush have a clue that his Social Security arithmetic fails to add up? How can he know if he doesn't care?
Social Security surely matters more than grammatical terminology does. But Noah's disdain for GWB's carelessness about the analysis of budgets would be more convincing if Noah himself were not so careless about the analysis of words.
The grammar of bullshit
On March 2, Timothy Noah in Slate reviewed Harry Frankfurt's 1986 monograph on bullshit. Here's Noah's fourth sentence:
How does bullshit differ from such precursors as humbug, poppycock, tommyrot, hooey, twaddle, balderdash, claptrap, palaver, hogwash, buncombe (or "bunk"), hokum, drivel, flapdoodle, bullpucky, and all the other pejoratives* favored by H.L. Mencken and his many imitators? [emphasis added]
The asterisk on "pejoratives" leads to this footnote:
Correction, March 4, 2005: An earlier version of this article mistakenly described these words as adjectives. In fact, they are nouns.
Kudos to Slate (and Noah) for footnoting the correction rather than just fixing it silently. The mistake is not critical to Frankfurt's ideas or Noah's review of them. (Well, maybe it suggests a certain lack of concern for what words actually mean, which is not entirely unconnected to what Frankfurt thinks bullshit is.) However, it does underline a point that we've made again and again in this blog. Most Americans learn almost nothing about how to describe and analyze the sound, structure and meaning of the English language. This includes most American intellectuals, whose degree of ignorance in this area is historically unprecedented. It extends to many of those who are being trained, at the best universities, in the discipline known as "English", and even more strongly to those trained in other fields.
As I've explained before, I blame the linguists.
[Note, by the way, that Noah's confusion about humbug etc. can probably be explained by the same reasoning that Geoff Pullum used in the case of Jon Stewart's confusion about terror. ]
OED Science Fiction update
A note from Jesse Sheidlower about improvements in the (already very cool) OED Science Fiction site:
For those interested: the Oxford English Dictionary Science Fiction project at http://www.jessesword.com/sf has been redesigned and relaunched.
The biggest change is that the OED's database of citations of SF words is now made (mostly) available via the website. The OED does not usually make its work available in this way, but OED has agreed to publicly open up this part of its database to acknowledge the great contribution volunteers have made to this project.
That means that if you contribute a cite, it's viewable by everyone. Here's a link with more information about the citations
http://www.jessesword.com/sf/about_citations
We are also adding quite a few new words: there is an internal list of pending words we have been maintaining and over the next few weeks many of those words will be moved to the main pages. This link:
http://www.jessesword.com/sf/newest_adds
takes you to a list of the most recent additions.
We hope these changes make the site into more of a general resource for the vocabulary of SF, instead of just a catalogue of OED research needs.
March 08, 2005
Jive etymologies
In reference to the October post "Trevor's Law of Hip Etymology," I must agree with the verdict that the black English terms HIP, DIG, and JIVE are not borrowings from Wolof. However, the proof that most compels me is from a wider view of where slaves in America came from and how Black English arose.
Clarence Major proposed that, for example, HIP comes from Wolof's HEPI "to see" in the early seventies, when the study of just where slaves in a given colony were drawn from in Africa was in its infancy. At the time, the general sense was that slaves had come from a wide variety of locations, and that for that reason, pretty much any African language was fair game for an etymology. In these days, it was typical to see even obscure languages like Vai and Susu and Kpelle treated as sources for this word or that feature.
But nowadays, creolists and specialists on Black English know more about how these varieties arose and which slaves were most important in creating them. And that light, 35 years later Major's etymologies, piquant though they were, must be gently consigned to the realm of history.
For one thing, although the Wolof are relatively prominent to many Americans because of the large number of Senegalese immigrants in this country, and to black Americans because the Goree Island slaving settlement is a popular tourist attraction, the fact is that there is no evidence that Wolof speakers were predominant among slaves in the United States, numerically or culturally. For example, Lorenzo Dow Turner's seminal work on the provenience of African names among Sea Islanders (rural blacks who speak Gullah Creole) points to countless languages up and down the African coast: Wolof is just one of the many.
Of course we might say that lots of other groups were making their contributions, and that HIP, DIG and JIVE were just the two cents that the small number of Wolof speakers tossed in. But this means that we should expect that dozens of other Black English words had been traced to, say, Bambara, Mende, Twi, Yoruba, Efik, Umbundu, and so on. But they haven't. Most Black English slang clearly traces to words that started out in Merrie England. No one proposes that a word like PHAT -- roughly equivalent to the once-celebrated use of BAD to mean GOOD -- just sounds like FAT but actually traces to Igbo. There is no handful of cool black slang words that we are told trace back to Kikongo. Rather, the grand old HIP/DIG/JIVE trio stands out by itself, endlessly quoted over the decades.
In fact, if there any one African language that we could even begin to treat as "black Americans' native tongue," it is Mende of Sierra Leone. This is the language that some old Sea Islanders still sing folk songs in, although no longer knowing their meaning. If Wolof had ever had enough juice that its speakers would contribute vibrant words that would last centuries, then we would expect Wolof folk songs.
Finally, the Wolof etymology doesn't even help if we look at earlier stages of African slaves' varieties of English that fed into what happened here in America. A good portion of the slaves who helped to found the Charleston colony, for instance, were brought in after having served in Barbados, rather than directly from Africa. They spoke the Barbadian variety of Caribbean Creole English, such that Gullah is one more variation on that pattern. But Caribbean Creole English, again, exhibits no especial Wolof contribution. Its grammar, for example, reflects languages of Ghana, Togo, Benin and Nigeria -- but there is not a hint of Wolof's very different structure.
The HIPI myth has even made it across the ocean. Years ago I gave some lectures in Dakar where a local English teacher was quite taken with the idea that the HIP and JIVE he had learned about in black Americans' English were Wolof words. I didn't see any point in arguing with him, but for Language Log I thought it might be better to give the facts -- you dig?
Box spaghetti straight
Harry Shearer's radio program "Le Show" has a segment nearly every week in which Harry does all the voices for a sketch involving the 60 Minutes team and various other TV newspeople. Last Sunday morning it was Dan Rather chatting in folksy Texas phrases as he packs his boxes to move out of the NBC building, and at one point he describes another TV newsman approvingly as "box spaghetti straight". (The phrase appears to get no Google hits, by the way.) The phrase provides not just one but two beautiful arguments against the policy of almost all traditional English grammar as regards defining notions like "adjective" and "adverb".
Traditional grammars always tell you that adjectives are defined as words that modify nouns, and adverbs can be defined as words that modify other parts of speech -- they modify verbs, adjectives, other adverbs, and prepositions. As Shearer's fictionalized Dan Rather would say, that dog won't hunt. I have no idea why it has proved so robust, but it sure isn't correct.
Under the traditional view, since things that modify nouns are ipso facto adjectives, it follows that in box spaghetti (meaning "spaghetti that comes in a box"), the word box has to be an adjective. But if it were an adjective, although you would expect a comparative form (*boxer than the other one) and a superlative form (*the boxest I ever saw), instead you get a plural form boxes and a genitive form box's. Clear signs of nounhood. If box isn't a solid, true-blue noun, there aren't any. Calling it an adjective is completely nuts.
And considering the whole phrase box spaghetti straight, what the fictional Rather meant by it is "straight in the way that box spaghetti is straight". It's parallel to rock solid, which means solid in the way that rocks are solid: rock modifies the adjective solid. But if the things that modify adjectives are ipso facto adverbs, then rock has to be an adverb in rock solid — and in box spaghetti straight, the phrase box spaghetti has to be an adverb.
All these consequences come right from the planet Zorbo. The right way to describe things is the way it is done in The Cambridge Grammar of the English Language. Instead of confusing the idea of being an adjective with the idea of being a modifier of a noun, and confusing the idea of being an adverb with the idea of being a modifier of a non-noun, we separate these notions.
The constituent that comes before a head in a phrase to qualify its meaning has the function modifier. Although the modifier in a noun phrase will often be an adjective, it doesn't have to be. In a phrase like London fog, we have a proper noun serving as a noun modifier. In a phrase like box spaghetti, we have a common noun serving as a noun modifier.
And although the modifier in an adjective phrase will often be an adjective, it doesn't have to be. It can be a noun, as in rock solid, or a phrase formed by a noun and its modifier (The Cambridge Grammar calls this a nominal), as in box spaghetti straight.
Box is a noun, spaghetti is a noun, straight is an adjective. Together they form an adjective phrase. This is not what your traditional grammar books will tell you. But that's because those books get it wrong. You can trust me; on matters like this, I'm box spaghetti straight.
The progress and prospects of the digital BNF
A terrific post by Andrew Joscelyne at Blogos discusses a Le Monde interview with Jean-Noël Jeanneney, the head of the French National Library ( Bibliothèque Nationale de France, or BNF) who wrote a few weeks ago about Google's challenge to Europe. The most interesting part, to me anyhow, is Andrew's memory of an earlier BNF disaster. More precisely, this was an earlier case in which an obsession with industrial competitiveness, combined with top-down decision making by technically clueless bureaucrats, wasted many tens of millions of new francs.
Andrew wrote:
I remember attending a demo in the early pre-web 1990s given by Cap Gemini (or whatever the IT services company was called at the time) which had been charged with designing a ‘scholar’s workstation’ for the brand new BNF, looming with its four monstrous bookend towers and damp wooden platform over the Seine opposite the old wine depot of Bercy. The idea was to offer serious readers digitized and bitmapped versions of books from every age, allowing both access to the text as a corpus, and as a set of specially designed original pages. All wonderful stuff, yet predicated on a massive digitization campaign. However, as Jeanneney admits today, the BNF has managed to digitize only 80 thousand works in a decade, compared with Google’s project of 15 million in about half that time. Why so few?
Alas, the BNF has created nowhere near 80,000 e-texts, as we'll see shortly. But let's focus first on this BNF workstation. I never saw a demo, but I did attend more than one presentation by its funders and developers. "Wonderful stuff" is a phrase that never occurred to me at the time, and it seems even less appropriate in retrospect.
If my memory is correct, the following things were true:
1. The workstation (called PLAO, "poste de lecture assistee par ordinateur" or "computer-assisted reading environment") was based on new, proprietary hardware and software. Why? To promote the French IT industry.
2. According to the original plan, the BNF digital library would be accessible only via special PLAO workstations at the BNF site in Paris. There would be no provision for any sort of remote access, not even dial-up, much less via the (American!) internet. I recall asking questions about this at one of these presentations, around 1994 or 1995: the speaker looked pained, as if I'd suggested putting ketchup on my croque-monsieur.
The PLAO thus set its face directly against the two biggest technology trends of the decade, namely commodity computing and the internet.
I emphasize that this is my memory from a couple of presentations that I heard a decade ago or more, and may be inaccurate or incomplete -- I welcome additions and corrections from more knowledgeable readers. I presume that PLAO is in the dustbins of technological history; in any case, BNF's digital library is now accessible on the web via the Gallica site.
I've used Gallica with gratitude in the past, and expect to use it again in the future, but based on my interactions with the site, I'm confident that many fewer than 80,000 works are really available -- in text form, anyhow. The number of works returned by my searches seems to suggest a significantly smaller number, and indeed Gallica has a list of documents in text mode, which includes merely 1,118 works.
A quick check on the Interrogation du catalogue page suggests that this list might be a bit out of date, but not by much. There are six types of document: "Ouvrages en mode texte", "Monographies en mode image", "Périodiques en mode image", "Lots d'images", "Documents sonores", and "Documents manuscrits" ("works in text mode", "monographs in image mode", "periodicals in image mode", "sets of images", "audio documents", "manuscript documents"). If you search the "Ouvrages en mode texte", you'll get hit counts like 935 for France, 1,135 for terre, 1,131 for chose, 1,043 for parmi, and so on. (It won't work to search for common function words like "mais" or "non" -- these are apprently stop words, and -- silently -- return nothing.)
So apparently the BNF's efforts over the past decade have given Gallica e-text holdings of about 1,200 works. The all-volunteer Project Gutenberg has produced more than 13,000 e-texts over roughly the same period of time.
A couple of other comparisons: if I ask Google for pages in the French language that contain the word France, I get 24,000,000 hits. If I ask amazon.com for books on the subject of France, I get 26,100 hits. If I ask the Literature Online ("LION") database for texts containing the word France, I get 26,880 instances in 7,959 distinct works. Asking LION for earth gets 201,326 instances in 69,425 distinct works -- out of the "more than 350,000 works of poetry, drama and prose" that LION offers.
If Brussels gives M. Jeanneney the "plan pluriannuel" with a "budget généreux" that he's asking for, let's say that it'll be a triumph of hope over experience.
[Let me be clear that I'm all for pluralistic efforts, and especially European efforts, in the digital libraries arena. And I also believe that government-supported efforts could have a crucial role to play, especially if the result were to be e-texts in the public domain or otherwise openly available (and not just through one entity's web site). But I also believe that the best way to predict what (well-established) institutions will do in the future is usually to look at what they've done in the past.]
WTF grammar
We need a new term. Prescriptive grammar says "thou shalt not say (things that meet conditions) XYZ". Descriptive grammar says "love the vernacular, and say what you like". But what do we call it when you're taken grammatically aback by something you hear or read, and then try to figure out what the problem was?
This process is somewhat prescriptive, in that it starts with a perceived violation of internalized norms (what Geoff Pullum and Barbara Scholz call correctness conditions). But it's also rather descriptive, in that you try to understand the problem by means of a systematic investigation of relevant patterns of usage. So how about reactive grammar? Or more informally, WTF grammar?
Case in point: Eric Bakovic's reaction to a sentence in an old Mac OS X manual.
If you have an older Mac and upgraded the processor, don't expect it to work or support from Apple.
Eric's reaction: "It's just bad." He has a story to tell about why it's bad, but his badness reaction comes first, and his explanation comes second.
And sometimes the explanation phase turns out to be remarkably difficult.
Back last summer, Eric had another one of those WTF moments when he read this sentence about resistentialism:
Here, at last, was a word for the rug that quietly curls up so it can snag your toe, the sock gone AWOL from the dryer, the slippery piece of toast that always hits the floor jelly side down.
This hit Eric with an image of the writer experimentally dropping the same bit of breakfast over and over again, though it's clear that we're supposed to generalize over encounters with many different instances of jelly-clad toast. Eric analyzed the problem as "the use of the word always, universally quantifying over the predicate of the relative clause (hits the floor jelly side down) that in turn modifies a singular definite noun phrase (the slippery piece of toast)".
David Beaver suggested a different analysis: "The problem is simply that relative clauses, as has often been observed, are what we term scope islands".
I in turn objected to David's story, pointing out examples like
(link) Their Barbera is a fun and fruity wine that always pleases us...
(link) My mother used to make a fantastic beef stew that always tasted better the next day.
David responded with an account in terms of Carlson's distinction between different types of generic sentences, "only some of which involve reference to kinds", suggesting that "'piece of' resists being kind denoting". (If this isn't completely clear to you, that's the point -- it's high semantic wonkery, and if David's account is correct, you'll need quite a bit of background to understand what's really going on here.)
This morning, Gabriel Nivasch wrote to me with a different proposed explanation:
Regarding your post on the toast falling with the jelly side down:
There is a difference between "food", "wine", and "seafood" on one hand, and a "toast" on the other. The former are non-countable nouns, and the latter is a countable noun. Therefore, you can say
"food that always satisfies"
because each time it is a different piece of food that is being eaten, yet they're all placed together under the word "food". The same applies to "wine" and "seafood".
On the other hand, if you say
"a piece of toast that always falls"
it seems to say that the *same* piece of toast is falling one time after the other, so it sounds a little weird.
One problem up front is that toast isn't all that countable -- we usually say "Do you want some toast?" or "Do you want a piece of toast?", not "*Do you want a toast?"
Anyhow, I don't think that Eric's original WTF reaction was caused by "the piece of toast" being a count-noun kind of expression. Consider this quote from the brochure for the 1968 Renault 1100:
This is the car that's always been DIFFERENT and for 1968 it's differenter!
This quantifies over generic experiences with cars in different Renault model-years, not over experiences with any specific vehicle -- but car is certainly a count noun.
The best story still seems to be David Beaver's observation that piece of "resists being kind denoting". This is not entirely unconnected with the mass/count distinction, since piece of was motivated in the original sentence in order to countify toast, so to speak. However, I'm still not sure that this story is the right one.
So eight months and five analysts later, we've still got Eric's bizarreness reaction -- which most but not all people seem to agree with -- without any clear prescription about how to write so as to avoid it. This situation is not at all typical, because most grammatical WTFs have a simple explanation, easily accessible to someone with linguistic training. Nevertheless, this case emphasizes the fact that explicit grammatical principles are post hoc explanations of the phenomenology of linguistic experience. Norma Loquendi rules.
Don't expect this post to make sense or any help from me
It's amazing the things you find when you're not really looking. While working on some paper revisions today, I had this extraordinary urge to clean up the pile of books and papers that had gathered around my feet over the past week (of working on paper revisions, of course). Somehow, a three-year-old note to myself found its way into this pile. It's a sentence that I wrote down, from an old book on Mac OS X. On p. 206, Gene Steinberg wrote:
If you have an older Mac and upgraded the processor, don't expect it to work or support from Apple.
I can see what this sentence means, and I can understand how Steinberg may have reasoned that it was better than the alternative:
... don't expect it to work, and don't expect support from Apple.
Problem is, the sentence Steinberg wrote does not satisfy (what I think are) my syntactic correctness conditions. It's just bad. The problem, as I see it, is that Steinberg has attempted to conjoin an infinitival sentence (it to work) with a noun phrase (support from Apple).
Now I'm sure that CGEL has some more accurate analysis of the relevant facts (perhaps even a better term than infinitival sentence?) but I'm too tired and lazy to walk all the way across Language Log Plaza to Geoff's office to see what it is. Anyway, I know there are some patterned exceptions to the generalization I'm about to make, but typically, only syntactic phrases of the same type can be conjoined. So it should be perfectly fine to conjoin two noun phrases as complements of expect, and indeed it is:
Don't expect my everlasting love or a bouquet of roses.
It should also be perfectly fine to conjoin two infinitival sentences as complements of expect, and it is -- but for me, if the subject of the second infinitival sentence is a pronoun, a for is (mildly) required before that pronoun. On the other hand, for is absolutely forbidden before the first infinitival sentence (whether or not its subject is a pronoun), and it's completely optional otherwise:
Don't expect (*for) the car to drive itself or (for) the sky not to fall on your head.
Don't expect (*for) it to work or *?(for) them to help you.
Well, that kept me occupied for a full half hour or so. Then it was back to work ... cleaning up the mess on the floor. Then the revisions. Now bed.
Update, Mar. 9: Neal Whitman writes:
Your latest post on Language Log was of special interest to me, since I have a collection going of utterances such as, "It makes it hard for him to get [his stuff done] and [to bed on time]," and "She wants [an engagement ring] and [her boyfriend to stop dragging his feet]," and "Don't eat [fast food], or [at restaurants, food-service companies, or caterers]." In case you're interested, I discuss coordinations like these in a paper that appeared in the Sept. 2004 issue of Language. It covers adjunct-with-adjunct, complement-with-complement, and adjunct-with-complement coordinations.
The "She wants ..." example is OK for me, but only with "for" before the second conjunct; the "Don't eat ..." example is perfect. I look forward to reading Neal's paper.
[ Comments? ]
March 07, 2005
Raising standards -- by lowering them
Chris at Mixing Memory reports that blogging about (his end of) science is discouraging:
As an academic, I have spent a lot of time hiding away in the ivory tower, oblivious to the larger world around me. As a graduate student, especially, I had almost no time to pay any attention to what non-scientists were saying about cognitive science. However, on a fateful day in early 2004, I chose to crawl out of my hole and actually look at what other people were saying. I started reading blogs. And now I want to crawl back in!
I'm happy to say that he's decided to resist the urge, and to keep fighting the good fight. His stuff is smart, well informed, and well written -- take a look at his posts on Lakoff and framing, for example, or on recovered memories, or his most recent post on corpus-based approximations to meaning. However, I'm going to disagree with his advice to people writing about science.
Actually, his advice is specifically directed at "anyone who wants to talk about cognitive science, but has not spent a lot of time studying it", but the things that bother him are characteristic of science writing in general, and so his prescriptions apply more generally as well. You should read his Five Points for yourself, but here's my summary:
1. Do a lot of background reading before writing anything.
2. Ignore what's in the popular press (aka MSM).
3. Ignore popular books.
4. Read the peer-reviewed literature.
5. Consult experts.
Chris says that "if everyone followed these guidelines when they wrote about fields in which they are not experts, maybe the public wouldn't have such a god-awful understanding of the sciences."
Though I sympathize deeply with Chris' frustration, I disagree completely with his prescriptions, for two main reasons.
First, if everyone followed his guidelines, there'd be an order of magnitude less science writing than there is, and there's already too little. Instead of putting up higher barriers to entry, we should be encouraging more people to do more thinking and writing about mathematics, science and technology (and history and literature and art, too, but that's another story). A rising tide of interest and involvement will lift all intellectual boats, even if some unsavory stuff floats up off the mud flats.
Second, the peer-reviewed literature may be the best thing we've got, but it's not very good. There's an enormous quantity of irrelevant junk in it, and a certain amount of out-and-out crap. Much of it is unreadable or misleading. Worse, a lot is missing -- questions that don't get asked, negative results that don't get published, whole problem areas that don't get addressed for decades at a time. And you don't have to agree with Steve McIntyre's views on global warming to sympathize with his complaints about "disclosure and due diligence" in the refereed literature.
So here's my alternative prescription for improving scientific communication:
1. Encourage everyone to think about science, and to write about it on the web, whether they know anything about it or not. And encourage them to criticize what others write, and to read others' criticisms, and to tell their friends about the best stuff that they find, whether in the popular media, or in the technical literature, or in weblogs. I claim that open intellectual communities intrinsically tend to generate a virtuous cycle: if there were an order of magnitude more science writing in blogs, there'd be less than an order of magnitude more crap, and more than an order of magnitude more good stuff. (The same is probably true for science writing in newspapers, though the network effects are smaller there.) This follows from a scientific version of Moglen's Metaphorical Corollary to Faraday's Law: add more wires, lower the resistance, and more intellectual current is induced.
2. Improve the (professional) scientific literature. Here's a three-point plan:
1. Open access on the web for all scientific publications, with durable doi-style references.
2. Open access on the web for all data and programs involved in scientific publications.
3. Standard APIs for references in all scientific publications, and methods for inducing trackbacks across all achives of such publications.Point 1: Open access lowers encourages people to read (and evaluate!) primary sources, not just someone's summary. More people reading more papers is good.
Point 2: All the data and programs behind published claims should be published in electronic form, so that readers can check methods and results, try alternative models, and (most important) build on others' work. This shortens the half-life of mistakes, and accelerates the spread of good ideas.
Point 3: Now that nearly all journals, proceedings etc. are on the web, there's no excuse not to make it trivial to extract the citation graph (i.e. who cites whom for what). Then users can wander around in the graph, use it to calculate value via the analog of page-rank, and do all sorts of other neat things. The way things are currently done, finding the citation graph is a non-trivial exercise in text analysis and reference normalization, even for the documents that are not hidden behind a publisher's barrier. This is one place where "semantic web" ideas really ought to be imposed.
There will of course be cases where this much openness is not possible -- e.g. where data can't be published for privacy or intellectual property reasons. But such cases should be treated like the use of anonymous sources in journalism -- permitted only where the results are valuable enough, and there's no alternative.
All this stuff is happening anyhow. Let's do it faster.
W.O.D.
Andrew Joscelyne at Blogos explains what's going on with "Webster's Online Dictionary (The Rosetta Edition)", a vast project initiated and managed by Philip Parker. The goal: "the biggest multilingual dictionary site on the web", constituting an “N-dimensional cube of words in every language to every language,” currently said to weigh in a terabyte or so. Margaret Marks at Transblawg complains about the treatment of translator, and calls the WOD ""huge and bizarre".
Take a look at the entry for language. There's some useful stuff in there, but I think I'd think twice before believing what this source told me about words in a language I didn't know. You might get something like the "synonyms within context", which seems to include every Roget's category in which any term contains the word language, and therefore covers many things that are not synonyms at all, within context or without it -- personality, vigor, raciness, authorship, gravity and so on.
[Update: Abnu from Wordlab emailed to point out that he "was not impressed with the naming of Webster's Online Dictionary. Shouldn't we expect something original from a Chaired Professor of Innovation?". Well, perhaps sometimes it's innovative to be derivative.
March 06, 2005
butt to buck, start to stark, or vice versa?
Back in August, I looked into the butt naked vs. buck naked issue, and concluded that it's a draw. Scholars disagree about which was the original expression, and current usage is roughly split as well. I referenced that discussion in my post today on Hobbesian choice, and Prof. Paul Brians wrote to disagree.
On your very interesting Web site you challenge my claim that "buck naked" is older than "butt naked." I'd be interested to see evidence of any use earlier than my first encounter with the latter, less than ten years ago. In 37 years of reading student writing and popular journalism, it's only recently that I've encountered the "butt" variation.
The Cassell Dictionary of Slang lists "buck naked" as early 19th Century and speculates, as did one of your sources, on "buck" as a variation on "butt"; but until someone comes up with an actual early citation, I'll stand by my etymology as more likely. Lightly clad blacks and Indians were commonly called "bucks" in the 19th century.
Though it has a different origin, I associate this also with the common "nip it in the butt."
I certainly don't have any 19th-century citations for "butt naked", and I agree that Prof. Brians might well be right that "buck naked" is the original phrase. I'm not challenging his claim, just observing that others disagree, and determinative evidence seems to be lacking. However, I'm fairly confident that "butt naked" is more than ten years old. I recall hearing it as a child, as does someone posting on the phrases.org.uk bulletin board:
Half century ago in the rural southeast US the expression was "butt naked" (only we said something closer to "butt necked") and it just ment naked.
And several fairly authoritative dictionaries (in addition to the Cassell's reference that Prof. Brians mentions) suggest that "buck" was originally a euphemism or other alteration of "butt". The Dictionary of American Regional English (DARE) has
BUCK NAKED - adjective. Also buck-ass naked, buck-born ~, stark buck ~. Origin uncertain, but perhaps alteration of butt/buttocks. Entirely unclothed.
and the American Heritage Dictionary (perhaps echoing DARE) has
Etymology: buck- (perhaps alteration of butt) + naked.
So as far as I can tell, the jury is still out.
And though I don't have a citation, I do have a curiously exact precedent to point to. Starting around 1530, another expression of the form "X naked", where X was a word for "buttocks" ending in a /t/, was changed into a new expression "Y naked", where Y was X with the final /t/ changed to /k/. "Y naked" made just as much sense as "X naked", but it was politer. And this time the OED gives us the citations.
The OED glosses start naked as
Entirely naked; = STARK-NAKED a.
and explains the etymology as
[App. f. START n.1 + NAKED a.
The literal sense would seem to be ‘naked even to the tail’. Start has not been found in Eng. with the sense ‘buttocks’ (= TAIL n.1 5), but the MDu. and Ger. equivalents are so used.]
Citations start in 1225 -- and continue to the 19th-century American south:
a1225 Juliana 16 (Roy. MS.), & he het hatterliche strupen hire steortnaket [Bodl. MS. steort naket].
a1225 Ancr. R. 148 Heo haueð bipiled mine figer..despoiled hire stert [printed sterc] naked, & iworpen awei [etc.].
Ibid. 316 Bicleope þine sunne steornaked; þet is, ne hele þu nowiht of al þet liþ þer abuten.
13.. Pol. Songs (Camden) 336 Sholde he for everi fals uth lese kirtel or kote,..He sholde stonde start [printed starc] naked twye o day or eve.
c1320 Cast. Love 431 in Minor Poems fr. Vernon MS. xxxviii, And I-strupt him al start-naked.
a1325 in Horstm. Altengl. Leg. (1878) 140 Þai lay þerin all star naked.
1892 Dialect Notes (Amer. Dial. Soc. 1896) I. v. 234 Start-naked: stark naked. ‘He is a start-naked villain.’.. Mr. A. W. Long, of North Carolina, reports that he never heard any other form than start-naked used in conversation in that state; and that two of his friends --- one from Virginia, and the other from South Carolina -- make the same statement for those two states.
The OED entry for stark naked states unequivocally that it is "altered from the earlier START-NAKED", with the earliest citation from 1530:
1530 PALSGR. 842/1 Starke bely naked, tout fin mere nud... Starke naked, tout fin nud.
1560 J. DAUS tr. Sleidane's Comm. 356 They left them starcke naked.
So "butt naked" would be a straightforward calque of a common expression whose word for "butt" had dropped out of the language. Of course, this would be much more persuasive if someone could find a citation...
By the way, the "bely" in the first citation is belly, and the expression "stark belly naked" also has a citation in the entry for belly (and several others in the LION database):
1611 COTGR., Tout fin mere nu, all discouered..starke bellie naked.
The OED entry for stark naked references sense 2 of stark as adverb, glossed as "To the fullest extent or degree; absolutely, utterly, quite". A phrase meaning "absolutely naked" is at least as reasonable as one meaning "naked to the tail" -- though for the first hundred years or so, people often stuck in another piece of anatomy, just for good luck:
165 And then forth shalt thou, sterk belly naked,
166 With dogs arrand quen, thou shalt be bayted.
(Walter Smith, 1525, "The fyfth mery Iest, or etc.")601 Glad was this man, and with his gladnesse waked,
602 But scarcely had he opened both his eyes,
603 Before he felt his wife starke belly naked:
604 And found his finger hid betweene her thighes.
(Robert Tofte, 1611, "THE FOVRTH SATYRE OF Ariosto")
[A curious side note: according to an article in Slate by Mark Scheffler, in Liberia around 1989, Joshua Milton Blahyi went under the name of "General Butt Naked", commanding the "Butt Naked Battalion". That takes butt naked back 15 years, but more important, it suggests that "butt naked" is the normal expression in vernacular forms of Liberian English, where it may have traveled an independent path for the past 150 years or so.]
An eggcorn hatches
OK, it's official. Hobbesian choice is now the blue-state equivalent of the French choix cornélien: a forced choice between two unattractive alternatives. Well, it's not exactly official -- there's no Blue State Academy to decide these things -- but after reading James Wolcott's 3/2/2005 attack on Kurt Anderson, it looks to me like we've passed the sociolinguistic tipping point on this one.
You can read all about the Great Hobbesian Choice Brouhaha in this 2/19/2005 post, but here's a quick summary. Back in April of 2003, Peter Wood at the National Review trashed John Payton, who argued for the University of Michigan in Gratz v. Bollinger, for using the phrase "Hobbesian choice". Wood took this to be a malapropism for the long-established idiom "Hobson's choice", indicating that "diversity's defenders came across as stridently self-righteous and pretty sloppy about the details". Then Kurt Anderson wrote in the 2/21/2005 New York Magazine about our "Hobbesian choice" in Iraq -- "either we hope for the vindication of Bush’s risky, very possibly reckless policy, or we are in a de facto alliance with the killers of American soldiers and Iraqi civilians", according to him. Some bloggers rapped his knuckles for the apparent mistake, and I agreed: "Even if there is a valid and coherent reason for Anderson to see his choice as a 'Hobbesian choice', he can't use that phrase without taking literate readers aback, and leading some of them to make fun of him. Unless, of course, he can convince them that the whole thing was a clever pun all along." Then Anderson wrote to Jim Hanas that indeed, he meant the phrase as a piece of word-play.
Now James Wolcott has posted a stinging attack on Kurt Anderson under the heading "Take this binary mode and shove it": "bright and intelligent in a completely uninteresting way", "glib in a Manhattan Mandarin manner that conceals the glibness behind a knowingness that itself conceals a lack of deeper, driving conviction", "one of those media personalities who's always 'positioning' himself without ever taking a real position".
The character evaluation aside, Wolcott quotes approvingly from Matt Taibbi:
"'Each of us has a Hobbesian choice concerning Iraq' [Andersen writes]. This is horseshit on its face. Even the original Hobbesian choice was horseshit, especially in the eyes of the stereotypical New York liberal Andersen is addressing. We no more have to choose between chaos and authoritarianism than we do between rooting for Bush and rooting for the insurgents. There is a vast array of other outcomes and developments to root for."
Taibbi assumes without comment that "the original Hobbesian choice" was between chaos and authoritarianism, and Wolcott accepts that assumption without comment. I think it's going to be impossible to put this horse back in Hobson's stable, even if we wanted to -- there's a second idiom now.
There are plenty of precedents for the stable [sorry] co-existence of eggcornic idiom pairs: "butt naked" vs. "buck naked" (where scholarship seems unable to establish which was the original), and "home in" vs. "hone in", "deep seated" vs. "deep seeded", and many more. What's interesting about this case is that there's also a subtle but clear difference in meaning: a Hobson's choice between something bad and nothing, and a Hobbesian choice between equally unwanted opposites.
*
N stars in quotes now mean zero or N words, but nothing in between zero and N. According to Google. I'm pretty sure it didn't used to mean that (correct me if I'm wrong by email: dib AT stanford DOT edu). But times have changed. Google reality is fleeting.In a quoted Google string search, * used to match exactly one word, any word at all. So "language * log" would have produced similar (or identical) hits to "language * log" -"language log". Not so any more! Iván García-Álvarez, a graduate student at Stanford University's linguistics department, pointed out to me that a * now sometimes matches zero words. The full story is even more complex.
"there is * * * * a house in New Orleans" gets, at time of writing, precisely the same number of hits, 3560, as "there is a house in New Orleans", and they all seem to be hits on "there is a house in New Orleans", although the hits are not in the same order. I can't even be sure whether they are the same hits, since I would only be able to check 1000 of them.
On the other hand "there is * * * * house in New Orleans" only gives 3 hits, and all of them are for "there is house in New Orleans". Meanwhile "there is * house in New Orleans" matches both (i) the three "there is house in New Orleans" strings, which are in fact top ranked, and (ii) "there is a house in New Orleans". Google claims 4550 hits for this one star search, though whether there is an actual surplus of matches beyond the sum of "there is house in New Orleans" and "there is a house in New Orleans" I don't know. Add one more star, i.e. "there is * * house in New Orleans" and we get 5 hits. As far as I can tell, these consist of cases where "* *" matches either zero words or two.
More generally, I hypothesize that N stars now matches either zero or N words, where by words I mean non-empty strings containing nothing Google treats as separators. Which means that the meaning of * is now context sensitive. It used to match exactly one word, and it carried on meaning this when there were other *s around. Not so any more: now we cannot give a natural interpretation to a single * within a list of *s, but rather have to interpret the whole list. (BTW: you don't actually need spaces between *s. "there is * * house in New Orleans" is interpreted by Google in exactly the same way as "there is ** house in New Orleans".)
It probably does not matter to many people that the meaning of * is no longer context free. And if what you want to do is match N words and not zero words, you can just use the minus operator, as in "there is ** house in New Orleans" -"there is house in New Orleans", although admittedly it is a pain in the butt. But as a linguist who likes to do rapid prototyping of theories using Google, all this is a little scary.
Google's semantics is in such rapid flux that my little web experiments become even more unrepeatable than they would do if we only had to deal with the ever changing web. And what if someone has been tracking how some aspect of the web changed over time using a string search involving stars? They would now have to change their search pattern, and probably start their cyberdiachronic investigation from scratch. Then again, maybe there is no such thing as a cyberdiachronist who uses starry Google strings. Then double-again, maybe there is such a person, but I don't yet know how to search for them. But then triple-again, and to paraphrase Berkeley: if a tree falls in the forest, but it doesn't show up on Google, did it really happen? Now perhaps you begin to see why the ethereal transcience of Google scares me so much...
Google usage
I'm fond of McSweeney's. For example, the article currently featured on the web site is Chris Gavaler's "Who's on First?", which is pretty funny in a quiet sort of way. And many of the things on the new lists page are also funny. But when I read Adam Koford's list of "Adjectives rarely used by wine tasters", I was skeptical. After a series of posts last summer on the language of wine tasting and similar enthusiasms, I retain a sort of general sense of what kind of descriptions wine aficionados are likely to use, and I was pretty sure that Adam had not pushed the envelope nearly far enough.
So I checked with Google. Adam's first "rarely used" adjective is chunky -- but {chunky wine} has 208,000 web hits on Google, most of which seem to just the sort of thing that Adam thinks shouldn't come up. Nine out of the first ten, for example:
From the hot 2003 vintage in Europe, this is a chunky wine that is perfect for your mid-week meals with our Own Pasta and Meat Sauce with Roasted Eggplant and Peppers as a side dish.
A well structured, chunky wine with hints of figs and raisins.
A big, chunky wine that is typical of the Okahu style.
A solid, chunky wine with a Vogel's toast nose, lashings of creamy, rich fruit through the middle and a savoury finish.
Chewy, big chunky wine with a lot of tannin.
Chunky, tarry, spicy wine. ... Firm tannins, however not slaughtered by oak and despite its chunky and rustic nature, it was a tasty wine with this dish.
As for a "Chunky wine" [...] That would mean young,huge tannins, toasty oak and a big finish...almost "Chewy".
The Amarone, a proverbially big and chunky wine, had died in the bottle.
This is a nice savoury, chunky wine that's drinking beautifully now.
Made with extra thick glass, this chunky wine goblet is a durable and versatile choice for casual entertaining.
Adam's second "rarely used" adjective is super-charged -- but {super-charged wine} has 37,800 whG. Again, nine of the first ten hits are just what Adam doesn't expect:
This was the third time I had encountered Chateau Angelus, a massive, super-charged wine that just seems more monolithic each time I taste it.
Leonetti winemaker Gary Figgins has it down, blending his best selections from the Seven Hills, Windrow and Spring Valley vineyards into this super-charged wine.
Huge and thick with fruit on the palate, this super-charged wine is impeccably well balanced, with fine focus, ripe tannins, and a long, complex, tidal wave of a finish.
Wow! This is like a supercharged Rhone.
From a newish estate in South Africa, this has a striking, paint-box colour of vivid purple and intense aromas of super-charged blackcurrant and mint, brambles and an earthy depth.
A brilliant, supercharged white wine.
It is richly oaked, with minty fruit and a slightly syrupy texture. Extraordinary stuff. Excellent, provided that you like this supercharged style.
A super charged Sauvignon Blanc.
I’ve heard of using strong black tea as a tannin additive and of using coffee in brewing recipes for a super-charged stout but I’ve never heard of making coffee wine.
Full-bodied, with great intensity, tremendous purity, sweet, well-integrated tannin, and a long, blockbuster finish that lasts for 40+ seconds, it offers both power and finesse, a rarity in the super-charged world of big California reds.
(And the tenth is a "super-charged stout", discussed in the context of wine-making. Note, by the way, that Google now seems to match super-charged, super charged and supercharged to "super-charged" -- the last especially is a pleasant surprise.)
Well, I won't go on beating the dead horse. And perhaps Adam knew about this all along, in which case I've fallen for the joke hard enough already. Anyhow, folks, remember -- if you're about to make a generalization about usage, even as a joke, check with Google first.
March 05, 2005
Computer does something-or-other to Moby Dick -- in 9.5 seconds
According to a March 3 NYT article by Noah Shachtman, a company named Attensity has developed software that can "parse" Moby Dick in 9 and a half seconds. Why? "By labeling subjects and verbs and other parts of speech, Attensity's software gives the documents a definable structure, a way to fit into a database. And that helps turn day-to-day chatter into information that is relevant and usable." And the CIA, which helped fund the company, doesn't care about Moby Dick, but wants to use Attensity's software to "comb through e-mail messages and chat room talks".
This general sort of technology comes under the heading of "Information Extraction from Text", sometimes abbreviated "IE", or "text data mining", or "Automatic Content Extraction". (I'm a member of a group at Penn that's been working on information extraction from biomedical text.) The NYT article also describes applications that are really "information retrieval" (IR) rather than IE: "Looking through a company's customer file for a person named Bonds, for example, is fairly simple. But if the data is unstructured - if the word 'bonds' hasn't been classified as the name of a ballplayer or as an investment option - searching becomes much more difficult."
The NYT article also mentions Inxight, Intelliseek, and some other companies. To put this work in context, you'd want to sketch the history of DARPA's TIPSTER program, the series of "Text Retrieval", "Multilingual Entity" and "Message Understanding" conferences (TREC, MET and MUC), DARPA's ACE program, DARPA's CALO project, the failure of Whizbang! (some of whose technology went to Inxight, who in turn licensed it to Intelliseek, who also hired some of the people from Whizbang!'s Pittsburgh lab), and a few other things as well. Against this background, you'd want to know what kinds of analysis Attensity's software is really doing, and how accurate the various types of analysis are. That would enable you to (begin to) evaluate how well the software works in one sort of application or another. The software's speed is also worth knowing, but it's a second-level question. (And it also matters what the hardware is: "analyzing 200,000 words in 10 seconds" doesn't mean much, unless we know whether this is being done on a single machine, or a cluster of 1,000.)
Alas, the article gives us no real idea at all what Attensity's software is doing. Shachtman doesn't give us any coherent technical description of its analyses, or any examples of the analysis that it performs on any specific sentences. As a result, we can't tell whether it's trying to provide a full parse, or is just doing part-of-speech tagging and perhaps some noun-phrase or clause chunking. It's apparently doing some tagging of some types of entity references, but we have no idea which ones, or how well. It may be trying to infer some relations among text strings, or relate text strings to stable cross-document references (e.g. as identifiable people, places, organizations and so on). It's possible that it's even trying to do some sort of predicate-argument analysis, or at least analysis of the relations implicit in certain specified types of events and actions. That's certainly the implication of the description given by an Attensity customer:
"Attensity shows how the words all relate to one another - all the actors, objects and actions in a document, and how they connect."
But Shachtman seems confused about what the differences might be among these various sorts of analysis:
MAYBE sixth-grade English was more helpful than you thought. One of the dullest grammar exercises is being used to help find potential terrorists, and save companies a bundle.
Diagramming sentences - picking out subject, verb, object, adjective and other parts of speech - has been a staple of middle and high school grammar lessons for decades. Now, with financing from the Central Intelligence Agency, a California firm is using the technique to comb through e-mail messages and chat room talks, which can be a rich lode of corporate and government information, and a tough one to mine.
Shachtman seems to think that "diagramming sentences" is a matter of assigning part-of-speech labels to words. But actually, it's a kind of parsing, which assigns structural labels and relationships, recursively, to groups of words. On the other hand, "subject" and "object" are not "parts of speech", but rather (simplifying a bit) relationships between a noun phrase and verb. So Shachtman is recursively confused -- "diagramming sentences" is more than "picking out parts of speech", but two of the four examples he gives of "parts of speech" are actually examples of the type of relationships among groups of words that "diagramming sentences" is supposed to describe. And showing "all the actors, objects and actions in a document" would be another level of analysis entirely.
Shachtman's confusion, I'm afraid, reflects a historical mistake in his lede. Grammatical analysis of whatever kind -- whether diagramming sentences, assigning parts of speech, determining (co-)reference, or analyzing semantic relationships among words or their referents -- is far from being a "staple" of middle and high school education. Rather, it's become more and more rare in the American educational system at all levels. When it's done at all, it's less and less likely that the teachers themselves actually know how to do what they're trying to teach, since they themselves have never learned. And neither, it seems, have the reporters.
The botched description of "grammar exercises" in Shachtman's lede is not important at all. But it does help us understand why he apparently had no conception at all of what sorts of analysis Attensity's software might be doing, and therefore didn't ask any of the relevant questions while reporting his article, or present any of the relevant answers when he wrote it.
[Update: Martha Palmer emailed:
Check out David L. Bean and Ellen Riloff, "Corpus-Based Identification of Non-Anaphoric Noun Phrases", ACL-99,pp. 373-380.
It looks like good ol' muc technology, souped up regular expression pattern matching....w/ some pos tagging and some semantic grammar rules...
(and lots of hype, or course!)
(David L. Bean is co-founder and CTO of Attensity)
Well, there might have been some changes in their algorithms since 1999. And there's nothing wrong with a little good old American hype when you get a chance to be featured in the NYT. But in the best of all possible worlds, the tech writer assigned to a story like this at the NYT would understand the linguistic issues well enough to identify the underlying technology briefly but accurately -- instead of incoherently and misleadingly. ]
[Update 3/7/2005: Shachtman's article appeared on 3/5 in the IHT under the headline "Grammar become tool for CIA and businesses." ]
[Update 2/7/2005: Cassandre Creswell points out a more recent article: David Bean and Ellen Riloff, " Unsupervised Learning of Contextual Role Knowledge for Coreference Resolution", HLT-NAACL-2004.
You Ain't Haydn Nothin'
Amandalucia at We are Free Morphemes followed the links from Geoff Nunberg's recent Annals of Ambiguity post, and she has some editorial advice for presenters at the Eastern Psychological Association meeting:
Have these people not heard of the "Short Catchy Phrase: (colon) Longer Explanatory Phrase Detailing the Study" school of paper titling?
Her illustrative examples include (her addition in italics): "You Ain't Haydn Nothin': Gender Differences in Evaluations of Classical Musical Performances".
There's an opportunity for some historical sociostylistics here. Conference programs all the way back to the founding of scholarly and scientific organizations are available in libraries, and many of them are on line now. When did the CatchyPhrase: ExplanatoryPhrase model get started? In what fields? How did it spread? And what about variants such as DescriptivePhrase: CuteQuote, or ExplanatoryPhrase: AdditionalExplanatoryPhrase?
For particular examples, see for instance the program of the AHA's 2005 meeting, whose first few sessions include these colonated titles:
Existential Thought and Culture in Transnational Perspective: Authenticity, Morality, and Murder (session title)
"Dionysian Enlightenment": Walter Kaufmann and the American Nietzsche
Dasein, Death, and Dope: Martin Heidegger’s Lost Place in the History of American Existentialism
"Many Great Deliverances": Boston King’s Atlantic Revolution
Revisiting the Victorian "Crisis of Faith": The Transformation of the Religious Impulse in Physics, Feminist Literature, and Art (session title)
The Modern Art Museum as Sacred Space: Reformers, Aesthetes, and the Crisis of Faith
New Women, New Religion: Feminism and the Victorian Crisis of Faith
In Search of Epistemological Certainty in the Wake of the Victorian “Crisis of Faith”: Mind, God, and Meaning in the Physics of Sir Oliver Lodge
Racial Anthropology: The Galton Society and its Effects on American Physical and Cultural Anthropology
The Strange Death of Sociobiology and Evolutionary Psychology: The Case of Roswell Hill Johnson
Eugenics, Biomeritocracy, and the Reconstruction of Democracy: The Case of the High School Textbook, 1914–48
Defective or Disabled? Southern Physicians, Eugenics, and the Therapeutic Relationship, 1890–1930
War and the Modern City: Community Building and Urban Reconstruction during World War II (session title)
Global War, Local Battles: World War II and the Growth of Compton, California
Working-Class Utopia: Community Centers, Neighborhood Units, and American Architecture during World War II
Disease, Health, and the State in the Late Nineteenth- and Early Twentieth-Century United States: Charting the Colonial Connections (session title)
"The First Duty of a Citizen Is to Be Healthy": Health Education and U.S. Imperialism in the Early Twentieth Century
"Loathsome Necromancy": Health and Power around Puget Sound, 1967–90
"Suitable Care of the African When Afflicted With Insanity": Race and the Insane Asylum in the Nineteenth- and Early Twentieth-Century United States
There are some nice examples of the pattern Amandalucia referenced: "Dasein, Death, and Dope: Martin Heidegger’s Lost Place in the History of American Existentialism"; "'Loathsome Necromancy': Health and Power around Puget Sound, 1967–90". However, others suggest a more elaborate taxonomy of colon-divided titles, still to be catalogued by some enterprising meta-scholar. There's plenty of data out there.
[Update: I should mention that I've known several academics -- at least one linguist and one philosopher -- who were willing to do several months of research in order have a good reason to use a clever pun in a paper title. The Red Queen said "First the sentence, then the evidence". These scholars followed the maxim "First the title, then the evidence". In both cases, the goal is a useful source of motivation, I guess. ]
March 04, 2005
Stop him before he invents again
A brief piece in this month's Technology Review chilled me to the bone:
Imagine picking up a novel at a bookstore, and instantly your cell phone receives a text message containing your friends opinions of the book, as well as suggestions for films you might enjoy.
Media Lab doctoral candidate Hugo Liu is creating just such a system, called Ambient Semantics: a sensor embedded in a ring or wristwatch will read a radio frequency identification tag affixed to an object; the system will then search a database for information about the object and, on the basis of the wearers interests, send pertinent data as well as recommendations to his or her cell phone or PDA.
Ambient spam is more like it. I don't want to seem like an antitechnology sort of person, but the day that picking up a novel in a bookstore causes my cell phone to ring with a text message will be the day that I give up either bookstores or cell phones.
Ambient Semantics is powered by a database Liu built by gleaning information from Web pages, online communities, and social networks. The database, comprising some two million relationships between 100,000 items, can be used to predict personal preferences. For example, if a person likes Led Zeppelin, the database might indicate that she would also like the film School of Rock.
I see, it's like turning your real-world shopping over to amazon.com's feeble-minded model of personality. Future plans include putting your social life into the cyber-hands of a psychotic cruise line social director:
Liu says the next step for the system is feedback during personal interactions. Eventually, he says, when two strangers shake hands, their sensor devices will display their common interests and mutual friends, preventing missed opportunities.
This leads towards one of the stock characters encountered in dystopian science fiction novels, the animated billboard with the personality of a streetwalker or a used car salesman. These are generally backgrounded as routine annoyances of future life. But Mr. Liu's invention could spark a whole new back-to-nature movement.
I'm afraid that steering one Media Lab grad student in more reasonable directions would not help -- NTT's RedTacton technology is designed for exactly this sort of thing. (NTT site here, with sample applications starting here). Seriously, there are a lot of neat possibilities for this as well as now-conventional wireless technologies, but somehow I have a feeling that for every application I like, there are going to be several that I don't.
[Update 3/5/2005: Benoit Essiambre emailed:
I hope it was clear that I was talking in a joking way about the intrusive tendency of communications technologies, and not really about Liu at all. And Benoit may well be right about the fault in this case being as much in the brief journalistic write-up as in the underlying work. However, when you combine an attempt to "give modern devices common sense" so that they can "reason about the world as intimately as people do" with an attempt to "postulate things about identity and the Self, as reflected in the social fabric of the online world" it would be naive not to recognize that this capability is most likely to be used not only for "simplifying and humanizing the technology and tools of the digital age", but also to sell us stuff. If the cell-phone-in-the-bookstore example was the journalist's invention rather than Liu's, it was an obvious and appropriate extrapolation.The tech review article dumbed down his research so much that I can understand your concerns. Having your cell phone ring in the common circumstances described would be very irritating. However Liu's specialty is NLP. Looking at his website I am convinced that the choice of cell phone as an example medium was done because it is an example that concretizes the theory to a gadget a layperson can relate to. All the appeal of the system is in the powerful common sense semantic analysis going on in the background. Liu's specialty is natural language processing. His inclination towards art ( http://web.media.mit.edu/~hugo/research/index.html#aesthetiscope) and his work based on common sense knowledge (http://commonsense.media.mit.edu/cgi-bin/search.cgi) makes me think he could turn his system into something appealing.
Let me make it clear that I'm not against merchandising. I like advertising. But I'm not a big fan of spam, and a world full of networked objects engaged in common-sense reasoning about my goals, preferences, social networks and personal history is going to be a world full of spambots.
The idea of networked "do what I mean" technology embedded in everyday objects also raises its own reasons for concern, marketing misuses aside. But that's a topic for another post. ]
March 03, 2005
Speaking truth to TOEFL
There is much to shock the director of any program in the teaching of English as a foreign language (or indeed, the teachers) on the englishdroid site. For example, in its glossary of English language teaching it says this about the TOEFL test:
TOEFL Bizarre American exam, in which candidates listen to robots intoning things such as, 'Wow, I sure hope my meticulously assembled entomology collection has not gotten misplaced by the faculty janitors.' A deep-voiced robot then asks, 'What does the woman mean?'
And there's more under "Types of classes":
TOEFL classes Peculiar American test of a language deceptively similar to English. Combines archaic, formal grammar with folksy idioms. Mostly multiple-choice.
The listening test features unemployable actors or robots reading out unnatural sentences in plodding monotones, or with inflections in the wrong places. Childishly crude 'distracters' (red herrings) enable you to answer most of the test without even listening to the tape. There are some tricky ones, eg 'It is not impossible that the team will be less than successful in the final.' - 'What does the man mean?' (Answer: Fuck knows.)
TOEFL tests language structures that are obsolete outside the snootier American universities. For example, inversion after a comparative: 'Roger likes classical music more than does Rita.'
Ghastly stuff. But I fear it's not much of an exaggeration. This the sort of thing that does go on in the English language testing industry, as we have observed several times before on Language Log. The ETS is responsible for most of the sins committed in this area. Why should their Test Of English as a Foreign Language be any different?
I shudder to think that when I was a Dean of Graduate Studies and Research on my campus I had to oversee the process of making sure all foreign admittees had taken the TOEFL, and of denying admission to those whose scores were lower than the Graduate Council deemed acceptable. I really have been responsible for great evil. There must be dozens of talented Chinese physicists whose ambition to study at my university was forever frustrated because they could not tell from one hearing of a robot voice whether it was or was not impossible that the team would be less than successful in the final, or whether Roger did like classical music more than did Rita.
I feel honor bound to warn the casual surfer of the gross cynicism and unforgivable tastelessness of the englishdroid site. It can really only be excused on the grounds that teaching English as a foreign language is such hard work that after school hours its practitioners need a cheap laugh and a cold beer. And it will provide the former. You will giggle, as long as you can just prevent any goodness, decency, sympathy, respect or optimism from welling up inside you unbidden. I mean really, check this out: one-stop shopping for bad taste and slack professional ethics. Considering what a serious-minded, ethical, pro-feminist, responsible scholar I am, I can't imagine why I browsed this site for as long as I did...[Should that be "for as long as did I"? Just asking. —Ed.]
Especially since the glossary has the temerity to say this about grammar:
grammar The G word. Once taught only by unimaginative fascists, but now possibly coming back into vogue.
(Possibly? Grammar is back, buddy, so watch it! And don't you call us fascists. Tomorrow belongs to us.)
On the other hand, you simply have to love a site that says this:
This site has no fucking pop-ups, no fucking adverts, no fucking Flash, no fucking frames, almost no fucking JavaScript (just the two quizzes, which wouldn't work otherwise, and the link on this page, an attempt to avoid fucking spam), no fucking fixed font sizes, no image rollovers that take fucking ages to load, no links that open in new fucking windows, no pages that 'work best' in Internet fucking Explorer, nor, I hope, anything else that drives cantankerous web users like me fucking bonkers.
The englishdroid site was recommended to me by Stephen Jones, who should be fucking ashamed of himself.
[All material in this post has been sent for review by the Federal Communications Commission for advance approval, though admittedly they have not yet reported back.]
Disagreements continue about "Hobbit" brains
 Science Express has just published a new study of (a virtual endocast from) the skull of (specimen LB1 of) Homo floresiensis. The abstract:
Science Express has just published a new study of (a virtual endocast from) the skull of (specimen LB1 of) Homo floresiensis. The abstract:
The brain of Homo floresiensis is assessed by comparing a virtual endocast from the type specimen (LB1) with endocasts from great apes, Homo erectus, Homo sapiens, a human pygmy, a human microcephalic, Sts 5 (Australopithecus africanus) and WT 17000 (Paranthropus aeithiopicus). Morphometric , allometric and shape data indicate that LB1 is not a microcephalic or pygmy. LB1's brain size versus body size scales like an australopithecine, but its endocast shape resembles that of Homo erectus. LB1 has derived frontal and temporal lobes and a lunate sulcus in a derived position, which are consistent with capabilities for higher cognitive processing.
However, an AP wire service story on the paper quotes "some other researchers" as "sticking to their opinion that the Hobbit probably suffered from a form of microcephaly, a condition in which the brain fails to grow at a normal rate, resulting in a small head with a large face, and even dwarfism."
What it is not, says primatologist Robert Martin, provost of the Field Museum in Chicago, is a scaled-down version of a Homo erectus or a new transitional species that held on for millennia in tropical isolation.
As I noted in an earlier post, "this is all a bit of a black eye for physical anthropology. If paleontologists (and Science magazine!) can't agree about such a basic question, something is wrong."
In particular, the amount of quantitative data on statistical norms for various modern populations seems to be surprisingly small. At least, not much of it is used in this Science paper, whose plots and tables generally represent each species or group as a single point (e.g. in the plot of endocast Height/Breadth against Breadth/Length reproduced below, where there are individual points for "Homo sapiens", "Pan", "Pygmy" and "Microceph", as well as for various individual fossil skulls).
[Update: There's a NYT article today (2/4/2005) by John Noble Wilford, with a somewhat clearer quote from Martin:
Dr. Robert Martin, a primatologist at the Field Museum in Chicago, said that he and colleagues in Britain were preparing a paper contending that the examined braincase was too small to be explained easily by ordinary dwarfism or the tendency of isolated people on islands to become smaller over generations. In such cases, Dr. Martin said, brain size would usually not diminish by the same amount as body size. Dr. Martin said that he was not ready to rule out microcephaly on the basis of a test of a single microcephalic braincase.
One other thing that bothers me a little about this discussion is that the original find was not actually a fossil -- in the sense of being mineralized -- but was preserved in some other way that left it with a consistency described as similar to "mashed potatoes" or "wet blotting paper" (see the quote from the original issue of Science in my post here). Given this, how secure can anyone's estimate of the skull's aspect ratio really be? ]
Hindi and math skills
Let me add a brief remark to Sally Thomason's comments in the previous post, but couched in somewhat stronger terms. The conclusions she is dubious about concern the hypothesis that mathematical ability is retarded for English speakers because the root "ten" is not visible in a word like "fifteen" (indeed, the root "five" isn't very clearly visible there either). But these conclusions seem to me not just questionable but completely fatuous. It is having learned to count to 100 in Hindi that convinces me of this. To a rough approximation, there are no real signs of any transparency at all in the numeral words from 1 to 100 in Hindi. The morphophonemic alterations that have taken place over the millennia (a consequence, I would think, of a long tradition of rote learning of the numerals in purely oral form) are so radical that you could learn to count all the way up to n and still not be able to guess what the word for n + 1 will sound like, for any n < 101 (it gets easier after 100). Yet — and this is the point — anyone who thinks Hindi-speaking people are among the mathematically incapable knows nothing about India, or about California higher education, or the sociology of present-day Silicon Valley.
[Added later: All right, all right, I know I'm being utterly and unscientifically careless here, because India has thousands of languages and dialects, and many Silicon Valley programmers come from the Dravidian area in the south where the languages are less closely related to Hindi than English is. I know, I know. So all I'm saying is that I simply don't believe that a math deficit will some day be identified in Hindi speakers as a group that isn't there in Tamil speakers as a group and the explanation will turn out to be the transparency of the morphology in the numeral system. I'm not going to investigate it because I think the idea is completely loony. It wasn't me that raised this crackpot idea, was it?]
I won't type from 1 to 100 — spare me — but just to give a sense of the horrors that await, of how opaque the Hindi numerals are, I'll give the list from 1 to 20. (Phonetic nerd note: Single a is schwa, double is long [a], e and o are long, au is Cardinal Vowel #6 and ai Cardinal Vowel #3 for many speakers; ch is prepalatal stop, capital T is retroflex and t and d are dental, all aspirated if and only if h follows.)
1 one ek 11 eleven gyaaraa 2 two do 12 twelve baaraa 3 three tiin 13 thirteen teraa 4 four chaar 14 fourteen chaudaa 5 five panch 15 fifteen pandraa 6 six chhai 16 sixteen solaa 7 seven saath 17 seventeen satraa 8 eight aaTh 18 eighteen aTharah 9 nine nau 19 nineteen unniis 10 ten das 20 twenty biis
The really extraordinary thing is that it doesn't get much easier for the next eighty numeral words.
Does English Hinder Math Skills?
In the March 4 edition of The Chronicle of Higher Education an article on `Why Chinese Students Score High in Math' (p. A16) reports a claim by a University of Michigan psychologist that the greater transparency of numeral words for 11-19 in East Asian languages accounts in part for young Chinese, Japanese, and Korean students' superior learning of math by comparison to American students. Professor Kevin F. Miller comments:
"American children are confused by the fact that you name seventeen but you write it as ten-seven...Most first graders, at the end of the school year, if you ask them how many 10s there are in 17, they'll say 7."
The article (and presumably the scholar as well) acknowledges that other factors also contribute to Asian students' greater success in learning math, but the article emphasizes the argument that both the ordering of the numerals in the compound English 'teen words (3+10, 4+10, ...) and the semantic opacity of the words eleven and twelve make math learning harder for American first-graders.
The article is too short to raise, much less answer, some obvious questions: what about Asian-American students raised in traditional households but with English as their only first language? Is the same effect detectable in young students from other language backgrounds with numeral systems similar to the East Asian one reported here? How about students whose first languages have numeral systems that are more transparent or significantly less transparent than the English and East Asian patterns?
I was curious, so I conducted a quick and dirty survey of some of the grammars on my shelves. The Chinese-Japanese-Korean pattern is a bit more common in my nonscientific sample than the English pattern, with varying degrees of opacity in both types. Some examples: Hungarian, Swahili, Tagalog, Cherokee, Mundari, Turkish, Vietnamese, Dakota, and several Salishan languages all have the East Asian pattern, often with a particle or other connective separating the parts of the complex numerals. Most of these are fairly transparent systems, but the usual Dakota words for the 'teens seem to be composed of a particle meaning `again' + the unit (`again' + 1, `again' + 2, etc.). One grammar explains this as a shortening of the full form, which is (10 +) `again' + 1, etc.
On the other side, Russian, Finnish, Cherokee, Comanche, Colloquial Egyptian Arabic, Kurdish, and possibly Hindi and Urdu have systems similar to the English one, at least in that the words for 11-19 start with `1', `2', and so forth. But in this set of languages there are many very opaque 'teen forms. The Hindi and Urdu words don't appear to have `10' in them at all, and some of them don't even clearly have the numerals 1-9. Kurdish (which is not too distantly related to Hindi and Urdu) has more recognizably compound forms for the 'teens, but the phonetic distortion is sufficient to obscure the connection between the `10' element in these compounds and the word for ten. The Russian system also has some phonetic distortion in the `10' half of the compound, but overall it's more transparent than the English 'teen words. The second element in the Finnish 'teen words means `second', not `ten', and the second element in the Comanche words probably means `to go in/out'.
It would be nice if scholars would investigate a greater diversity of languages and systems before drawing conclusions about links between numeral structure and math learning. As reported in the Chronicle, the claim about the linkage strikes me as simplistic. In particular, the relative opacity of the English system could well mean that young children have learned the 'teen words as wholes, or as units plus an otherwise meaningless suffix, rather than as combinations of unit + ten; in that case, the compositional opacity might be the relevant factor, not the ordering unit + ten vs. the East Asian ten + unit pattern: as far as I can tell from the grammars (which, admittedly, usually give only the orthography for these numerals, not the pronunciation), the three East Asian languages mentioned in the article all have quite transparent compound numerals for the 'teen words.
Pechelingues
What with getting ready for Thanksgiving and all, I somehow missed Trevor's 11/15/2004 post entitled "Pirates and Kleinecke's etymology of 'pidgin'".
He starts from the multinational pirates known as pechelingues, pichilingues, or pechelingas in Spanish-American slang of the 16th and 17th centuries. Another point of reference is "a trade pidgin known as Pichingli" in the Canary Islands in the 19th century. There are several other intriguing historical notes, including a 1641 term for small change of diverse origin.
Trevor makes a suggestion about the origin of the word pechelingue (he finds the story about Spanish mispronunciation of the Dutch port of Vlissingen (Flushing) unconvincing), and a second suggestion about the origin of the word pidgin, namely that it was originally a term for the language of the pechelingues, which might originally have been spoken among the ethnically and linguistically diverse pirates of the Barbary coast (scroll down to "No hay nación de cristianos en el mundo de la cual no haya renegado y renegados en Argel"). He puts this up against the OED's story about the origin of pidgin, namely that it's
A Chinese corruption of Eng. business, used widely for any action, occupation, or affair. Hence pidgin-English, the jargon, consisting chiefly of English words, often corrupted in pronunciation, and arranged according to Chinese idiom, orig. used for intercommunication between the Chinese and Europeans at seaports, etc. in China, the Straits Settlements, etc.; also transf. (quot. 1891).
and a more recent suggestion by Kleinecke " that ‘pidgin’ may derive from a Yayo (South American) form ‘-pidian’, meaning ‘people’ and occurring in such tribal names as ‘Mapidian’, ‘Tarapidian’."
A useful introduction to the "Barbary pirates" can be found here. Last fall, on the occasion of "type like a pirate day", I pointed out their role as opponents in an earlier American-led global war on terror, complete with reluctant Europeans and other historical analogies.
March 02, 2005
annals of ambiguity
Scott Parker of American University sends me the intriguing title of a paper to be presented at the poster session of the Eastern Psychological Association in Boston next week:
Gender Differences in Rates of Breast Self-Exam and Testicular Self-Exam Amongst A Sample of Residents In A College Community
Not a very newsworthy result, was my first thought.
Gari
Today's New York Times (p. F11) has a review of a Japanese restaurant called Gari. It describes the food and atmosphere in some detail, but doesn't explain the name, so I will.
/gari/, usually written がり, is the special term used for red pickled ginger when it is served with sushi. The ordinary term is 紅生姜 or in kana べにしょうが /beni sjo:ga/ "red ginger". When you buy pickled ginger in a store the container is labelled 紅生姜, but when you eat it in a sushi shop you call it /gari/.
Ginger isn't the only thing that has a special name in a sushi shop. Green tea is normally called 煎茶 せんちゃ /sentja/, but in a sushi shop the special term 上がり /agari/ is used. Strictly speaking, /agari/ means "freshly brewed green tea", but you hear it mostly in sushi shops. /agari/ is a word with quite a few meanings. The most generic is "rise, slope, ascent", but among other things it is the term used to describe the death of fish and insects.
Structures of words vs. structures of numbers
A paper has just been published in the Proceedings of the National Academy of Sciences (PNAS) that offers a new perspective on several recent themes. The authors are Rosemary A. Varley , Nicolai J. C. Klessinger , Charles A. J. Romanowski and Michael Siegal, and the paper is called "Agrammatic but numerate" (PNAS, March 1, 2005, vol. 102 no. 9, 3519-3524).
Here's the abstract:
A central question in cognitive neuroscience concerns the extent to which language enables other higher cognitive functions. In the case of mathematics, the resources of the language faculty, both lexical and syntactic, have been claimed to be important for exact calculation, and some functional brain imaging studies have shown that calculation is associated with activation of a network of left-hemisphere language regions, such as the angular gyrus and the banks of the intraparietal sulcus. We investigate the integrity of mathematical calculations in three men with large left-hemisphere perisylvian lesions. Despite severe grammatical impairment and some difficulty in processing phonological and orthographic number words, all basic computational procedures were intact across patients. All three patients solved mathematical problems involving recursiveness and structure-dependent operations (for example, in generating solutions to bracket equations). To our knowledge, these results demonstrate for the first time the remarkable independence of mathematical calculations from language grammar in the mature cognitive system. (The full paper is available on the PNAS site only to subscribers, but a copy of the .pdf version appears to be here.)
By "bracket equations" the authors mean arithmetic expressions in which the scope of operators is indicated by matched parentheses or brackets, e.g. 4 + 11 x (3 x 2) vs. (4 + 11) x 3 x 2.
The results are certainly striking. These patients are profoundly aphasic, as would be predicted given the extent of their dominant-hemisphere perisylvian lesions -- each row of images below belongs to one of the three patients surveyed:
Their "severe disruptions in grammatical performance across language modalities" included ability to "[perform] no greater than at a chance level on understanding reversible sentences in both spoken and written modalities". ("Reversible sentences" are things like "The lady is calling the man", where it's equally plausible for the man to be calling the lady, so that you need to know more than the identity of the verb and the two noun phrases in order to guess correctly who did what to whom.) The patients also had other linguistic disabilities.
Despite their negligible syntactic ability in English, these patients could still do quite a bit of mathematics, of a kind that seems to require analogous syntactic processing. For example, in the "bracket expression" subtest,
Each patient calculated the sum of 90 expressions containing brackets. These included 64 expressions where the brackets were syntactic; i.e., if the participant adopted a serial order strategy, the result would be incorrect; e.g., 36 ÷ (3 x 2). The remaining interspersed 26 items were nonsyntactic: e.g., (3 x 3) - 6. The syntactic bracket expressions consisted of 38 items with a single level of embedded brackets and 26 items with apparent doubly embedded bracket structure. To avoid training performance, only 13 of these 26 items required serial computation of numbers contained within both sets of brackets, i.e., 50 - [(4 + 7) x 4] versus 3 x [(9 + 21) x 2]. Responses to the syntactic bracket expressions were scored for accuracy and presence of serial order calculation errors, e.g., 2 x [(5 x 2) + 5] = 25.
The results ( the three patients are called S.A., S.O. and P.R.):
S.A. |
S.O. |
P.R. |
|
| Calculation accuracy | 45/64 |
52/64 |
43/64 |
| Serial order errors | 4 |
1 |
2 |
This was just one of 14 mathematical subtests, and the patients' performance on all of them was strikingly better than their performance on analogous linguistic tasks.
This connects, at least loosely, to different sides of two recently-discussed stories. One is the role of language in mathematics, and especially in the most basic form of mathematical thought, namely counting. We discussed this in posts on the Pirahã (here, here, here) and the Mundurukú (here and here). The other is the role of recursion in language, discussed here, here, here and here.
In their conclusions, Varley et al. say that
In terms of the relationship between language and mathematics, our findings indicate considerable independence between the structure-dependent operations of language and number in an established cognitive architecture. Although agrammatic, all patients displayed sensitivity to, and use of, parallel syntactic principles in mathematics. Their responses are incompatible with a claim that mathematical expressions are translated into a language format to gain access to syntactic mechanisms specialized for language.
These results allow consideration of two alternative interpretations regarding the syntactic mechanisms of language and mathematics. One is that a common and domain-general syntactic mechanism underpins both language and mathematics but that mathematical expressions can gain direct access to this system without translation into a language format. In the case of patients with agrammatic aphasia, language representations are disconnected from the syntactic mechanism, but mathematical expressions can still gain access. The second alternative is that in the mature cognitive system, there are autonomous, domain-specific syntactic mechanisms for language and mathematics. Autonomy in the adult state does not entail independence throughout the developmental course of a system, and one mechanism might bootstrap the second. However, the presence of dissociations between mathematics and language in people with developmental language impairments indicates the potential for autonomous mechanisms throughout the lifespan and suggests that a language-specific mechanism does not bootstrap a nonlinguistic syntactic system.
[...]
With regard to the number lexicon, number words were unlikely to be the code in which calculations were performed; both S.A. and S.O. showed inefficiencies in using phonological and orthographic number words. Despite this, both were able to perform exact calculations involving two- and three-digit numbers. If, indeed, linguistic number words were the code in which calculations were performed, the inefficiencies inherent within these codes would have resulted in high error levels in mathematical tasks. All patients were efficient in processing Arabic numerals, suggesting that this code and its underlying conceptual base are sufficient for calculation.
The article left me with several questions.
One is whether this pattern (relative sparing of mathematical abilities) is typical of similarly agrammatic patients. If so, how has this fact remained unknown for so long? What other surprising dissociations are out there waiting to be discovered?
Another is how much use the patients made of pencil and paper techniques in solving the mathematical problems, since to some extent the learned procedures for arranging partial results on paper might substitute for (or at least assist) impaired ability to retain and manipulate the structure of mathematical expressions.
[Varley et al. link via email from Cosma Shalizi.]
Baby got what?
In my humble opinion, this is sacrilegious, while this is merely profane.
March 01, 2005
It was a clever pun all along :-)
With respect to discussions like this one about his use of the phrase Hobbesian choice in a New York magazine column, Kurt Anderson has explained himself by email to Jim Hanas, who posted the message at Encyclopedia Hanasiana.
Revenge of the Codex People
I've made a couple of references in passing to Michael Gorman's anti-Google and anti-blog screeds. Now the Online Computer Library Center blog reveals that these documents have deep historical roots.
The OCLC blog has several other relevant posts as well. And also see this OCLC report "2004 Information Format Trends: Content, Not Containers".
[Update 3/2/2005: for an antidote to Gormanitis, see Karen Schneider's post at Free Range Librarian. ]
[Link via email from Rich Alderson]
Now the FCC tells us, three months too late
It is astonishing that FCC chairman Michael Powell should tell us now, weeks after 66 TV stations made the decision not to show the movie Saving Private Ryan on Veterans' Day in case they were fined for the swearwords in the soundtrack (which for contractual reasons could not be edited or bleeped out of Spielberg's film), that really (now it can be told) the movie was OK for network television after all! My own opinion is that in a free society it is unacceptable for any words in the lexicon to be tabooed to such an extent that radio and TV stations can be retrospectively fined if they turn up in a broadcast (even one that the station did not write or produce). But if we are to adhere to the quaint old idea that there are taboo words of such potency that the government should be in charge of their use, the FCC should at least be prepared to say in advance what is going to be allowed and what is not. How can a responsible and decent organization like Language Log make its decisions about what words are fit to put before the public if the answer to its questions about what is currently taboo aren't even known by the fucking FCC? Oops...
"The horror of war and the enormous personal sacrifice it draws on cannot be painted in airy pastels. The true colors are muddy brown and fire red, and any accurate depiction of this significant, historical tale could not be told properly without bringing that sense to the screen," said Mr Powell, in some unusually colorful prose. (Who writes this stuff? And why do they take so long? The decision was actually reached on February 3rd.) Well, I should damn well think so: war is hell. But lots of things are hell. Are we allowed to swear about them occasionally in a free country, or not? The one prime condition to be met by a society whose laws make sense is that you should be able to know up front whether you're about to do something illegal. "We don't know whether we'll fine you or not" isn't good enough. I can hardly believe there has been so little critical coverage of this ridiculous episode of tacit censorship.
Horace diagnoses Ivan Watson's mistake?
This morning, Geoff Pullum noticed an "astonishing dangling modifier" on NPR:
Without Washington's support, however, Saddam Hussein quickly crushed the revolt.
Geoff was "quite surprised to catch such a great example of the sort of dangler you should avoid at all costs ... in scripted speech on National Public Radio". I agree, but I have a suspicion about how it happened.
Perhaps Watson (or whoever wrote the piece) originally had something like
Without Washington's support, however, the revolt was quickly crushed [by Saddam Hussein] ...
However, a later editorial eye saw an opportunity to replace a passive verb ("was quickly crushed") with its active counterpart, in order to become "more direct and vigorous". Result: the modifier was left dangling.
As Horace explained more than 2,000 years ago, "in vitium ducit culpae fuga, si caret arte". Avoidance of an error leads to a fault, if it lacks skill.
Without Washington's support... who??
An astonishing dangling modifier from Ivan Watson on National Public Radio's "Morning Edition" show this morning (listen to the story here; the example is just after three and a half minutes in). Talking about the Kurds and the brief period during which they overcame old feuds and rose in a united rebellion against Iraqi Arab rule, Watson goes on:
Without Washington's support, however, Saddam Hussein quickly crushed the revolt.
How's that again? Who was without the support of Washington?
Here's the technical grammatical description. The preposition phrase without Washington's support functions here as a clause adjunct at the beginning of the clause. It is understood as modifying the clause, but in a predicative way. It means what "without receiving Washington's support" would mean. We have an implicit argument slot to fill: who is it that didn't have Washington's support?
What we need is a target for the predication — roughly, a logical subject we could put with "receive American support" to make a clause with a meaning that makes things explicit in the right way. In such cases, it is extremely common for the subject of the matrix clause to be the key to making things clear. To take a couple of random examples pulled from the text of Bram Stoker's Dracula, when we read "Without saying any more he took his seat", we understand that the person who did not say any more was the person referred to as "he" (Quincy Morris, in this case). When we read "Without taking his eyes from Mina's face, Dr. Van Helsing motioned me to pull up the blind", we understand that it was Dr. Van Helsing who did not take his eyes from Mina's face.
"Dangling modifier" is the name prescriptive grammarians have given to the kind of construction where the main clause subject does not make clear the identity of the unexpressed target of the predication that is expressed in the adjunct. In many cases this causes little trouble, as the better usage books agree. But in the worst cases for intelligibility, the matrix clause subject is a disastrously wrong choice for the target of predication, with sometimes misleading and sometimes ludicrous effect. The first example cited by The Penguin Dictionary of American English Usage and Style (by Paul W. Lovinger; New York: Penguin Reference, 2000) is as clear a case as one could want, taken from a book about cannabis (if you could steel yourself, please, I want no politically incorrect giggling at this one):
Although widely used by the men, Bashilange women were rarely allowed to smoke cannabis.
Adopting the matrix clause subject (Bashilange women) as the target of predication for used by the man yields a truly unfortunate misunderstanding.
I know that a linguist like me is always assumed by the prescriptivist community to instantiate what E. B. White calls "the modern liberal of the English Department, the anything-goes fellow", as he tells his editor firmly that he will make no compromise with "the Happiness Boys, or, as you call them, the descriptivists" ( click here for White's remarks in context). But in fact, despite my scientific interest in describing languages as they actually are, I am as free as anyone else to have negative reactions to unintentional bathos or unhelpful confusion caused by bad writing. I think cases as plangent as the Bashilange example fully deserve the ridicule and censure that prescriptivists are so eager to heap upon them. However, it should not be overlooked that they're actually rather rare. Most dangling modifier cases slip by smoothly in context without anyone noticing them, which probably does mean there is no rigid syntactic prohibition against them built into the correctness conditions for the language; the principles they violate are more subtle pragmatic ones about normal understanding of implicit arguments in context.
I was quite surprised to catch such a great example of the sort of dangler you should avoid at all costs, and to find it in scripted speech on National Public Radio. Leaving it unclear whether it was the betrayed rebels or the nightmare dictator who lacked American support is a pretty gross error, especially given the history of America's vacillating alliances in Iraq during the 1980s and the 1990s.
On the characteristics of natural languages and certain European nationalities
 Ever since I was an undergraduate, Barbara Partee has been one of my heros in the field of linguistics. So I was tickled to discover that the reading list for her (fall 2004) course "Linguistics 726 – Mathematical Linguistics (really: mathematics for and in linguistics)" includes a number of Language Log posts. The context is Barbara's Lecture 13: "Are Natural Languages finite-state languages? (and other questions)".
Ever since I was an undergraduate, Barbara Partee has been one of my heros in the field of linguistics. So I was tickled to discover that the reading list for her (fall 2004) course "Linguistics 726 – Mathematical Linguistics (really: mathematics for and in linguistics)" includes a number of Language Log posts. The context is Barbara's Lecture 13: "Are Natural Languages finite-state languages? (and other questions)".
In her lecture notes as well as in the reading list, Barbara intersperses discussion of published articles (from Science, Psychonomic Bulletin and Review, and Cognition) with some less formal publications, including the Language Log pieces. If you're interested, read the whole thing: as you'd expect if you know Barbara's work, it gives a lucid and crisp exposition of a complex set of interesting issues.
You'll find a very different sort of exposition in Michael Gorman's much-discussed commentary in Library Journal, "Revenge of the Blog People!". Stung by negative reaction to his snarky op-ed on Google Print, Gorman strikes back:
A blog is a species of interactive electronic diary by means of which the unpublishable, untrammeled by editors or the rules of grammar, can communicate their thoughts via the web. (Though it sounds like something you would find stuck in a drain, the ugly neologism blog is a contraction of "web log.")
[...]
Given the quality of the writing in the blogs I have seen, I doubt that many of the Blog People are in the habit of sustained reading of complex texts. It is entirely possible that their intellectual needs are met by an accumulation of random facts and paragraphs. In that case, their rejection of my view is quite understandable.
Given all of this, I was surprised to find that one of the papers on Gorman's web site, entitled "How the English see the French", starts with this quote:
"A Frenchman must be always talking, whether he knows anything of the matter or not; an Englishman is content to say nothing when he has nothing to say -- Samuel Johnson (1790)"
Gorman goes on to assert that he is a "typical Englishman". Apparently things have changed since 1790.
The dogs of speech technology
 The association of dogs and speech research in Geoff Pullum's recent post reminds me of a story. The time was 1977, about 3:00 a.m. one cold winter night. The place was Murray Hill, N.J., the home of AT&T Bell Labs research. Building 2, wing D, 4th floor, in the console room of the DDP-224 interactive computer. Joe Olive and I had been programming since dinner, and our new speech synthesis system was pronouncing its first phrases: "The birch canoe slid on the smooth planks." "Mesh wire keeps chicks inside." "The spot on the blotter was made by green ink." It sounded really good to us, maybe not totally natural, but clear as crystal.
The association of dogs and speech research in Geoff Pullum's recent post reminds me of a story. The time was 1977, about 3:00 a.m. one cold winter night. The place was Murray Hill, N.J., the home of AT&T Bell Labs research. Building 2, wing D, 4th floor, in the console room of the DDP-224 interactive computer. Joe Olive and I had been programming since dinner, and our new speech synthesis system was pronouncing its first phrases: "The birch canoe slid on the smooth planks." "Mesh wire keeps chicks inside." "The spot on the blotter was made by green ink." It sounded really good to us, maybe not totally natural, but clear as crystal.
One of the night-shift cleaning crew came in to empty the trash can. He looked around, puzzled, for the source of the sound. "Y'all got dogs in here?"
This was a good lesson on the role of expectations in speech perception, and the importance of formal intelligibility testing.
A similar point is one of the themes of Solzhenitsyn's novel "The First Circle", which deals with speech research in a Stalinist labor camp. But that's a story for another time.