December 31, 2005
Pointers, References, and the Rectification of Names
Mark's discussion of Joel Spolsky's rant about young programmers who haven't learned C and Scheme provides a probable example of a real effect of language on the way we think, though one that is not usually considered part of the Sapir-Whorf effect. To recap, Spolsky argues that programmers who learn C learn about pointers and the data structures that can be built with them, such as linked lists and hash tables, while those who learn Java do not learn about pointers and therefore do not learn about such data structures. Mark and an unnamed Penn computer science faculty member whom he quotes take the position that Java does have pointers and that students taught using Java do learn about data structures like linked lists.
Spolsky is right in saying that Java does not have pointers. In the now standard usage in discourse about programming languages, Java is said to have references but not pointers. The Wikipedia articles on pointers and references treat pointers as a particular type of reference and explicitly state that Java has a kind of reference but not pointers. Similarly, Java in a Nutshell, which in spite of its name is, at 969 pages, a reference manual, in the enormously popular and often authoritative O'Reilly series, contrasts C pointers with Java references thus at p. 75:
It is very important to understand that, unlike pointers in C and C++, references in Java are entirely opaque: they cannot be converted to and from integers, and they cannot be incremented or decremented.
It is true that some people use pointer in a broader sense more-or-less equivalent to reference, so the distinction made above is not universal. I think that it is fair to say that when people are talking seriously about programming language design they generally do make this distinction.
On the other hand, Spolsky is wrong in thinking that Java's lack of pointers prevents Java from being used to build the kinds of data structures for which pointers are used in C. Here's a little Java program illustrating the use of linked lists constructed using references. The first three lines tell us that an object of class link consists of a string and a reference to an object of class link. The fourth through eighth lines define a constructor method for links, that is, a function that creates new instances of the class. The remainder is a program that illustrates the use of linked lists.
public class link {
public String value;
public link next;
public link(String s, link ln)
{
value = s;
next = ln;
}
public static void main(String args[])
{
link head = null;
//Insert command line arguments into list
for (int i = 0; i < args.length; i++) {
head = new link(args[i], head);
}
//Write out the list
link p = head;
while (p != null) {
System.out.print(p.value);
System.out.print(' ');
p = p.next;
}
System.out.print('\n');
}
}
This program creates a linked
list of the strings passed on the command line, then prints them out
starting at the head of the list. Since it inserts each new node at the head of the
list, the strings are printed out in the reverse order in which they are supplied
on the command line. If, for example, you execute this program with the command
line (after first compiling it, in my case with: javac link.java):
java link cat dog elk fox
it will print:
fox elk dog cat
Linked lists such as this are one of the data structures that Spolsky claims that you don't get experience with in Java. He's right that it is important for students of computer science to learn about them; he's wrong in thinking that Java doesn't support them.
So, where did Spolsky go wrong? It is possible that he just doesn't know that there are kinds of references other than pointers or doesn't know that Java has them, but I suspect that he fell victim to reasoning on the basis of the names of things rather than their properties, something like this:
- Pointers are used to construct data structures like linked lists.
- Java lacks pointers.
- Therefore one cannot create data structures like linked lists in Java.
The flaw is in the unstated inference from the proposition that pointers are used to construct linked lists in C, which is true, to the proposition that one must have pointers in order to construct linked lists, which is false. References are sufficient, if you have them. Of course, since C has only pointers, not references, it is true that in C you can't create linked lists without pointers. One of the ways in which language is useful is that we can rememember the names of things rather than their properties, but this carries with it the danger of falsely attributing properties to things based on their names.
The anonymous Penn computer science faculty member whom Mark quotes makes another invalid argument from language in using the existence in Java of an exception called a NullPointerException as evidence that Java has pointers. This exception is misnamed - it really should be NullReferenceException. This exception is thrown on an attempt to access a field or call a method of a null object, and the null value is of type reference. The people who designed Java knew C and intended references to be a safer way of doing most of the things that are done with pointers in C, so they inadvertently used the term pointer in naming this exception, but that doesn't change the fact that it is an exception thrown on illegal use of a reference, not a pointer.
This sort of erroneous reasoning has been recognized for a long time. One of the central doctrines of Confucian philosophy, the 正名 "Rectification of Names", is concerned with the false reasoning to which misleading names can lead. Here is the famous passage (13.3) from the 論語 Analects on the importance of the rectification of names:
子路曰: 衛君待子而為政,子將奚先?
子曰: 必也正名乎!
子路曰:有是哉?子之迂也!奚其正?
子曰: 野哉,由也!君子於其所不知,蓋闕如也。名不正,則言不訓;言不訓,則事不成;事不成,則禮樂不興;禮樂不興,則刑罰不中;刑罰不中,則民無所措手足。故君子名之必可言也,言之必可行也。君子於其言,無所茍而已矣![You can find the complete text here. Incidentally, when in search of Chinese language resources, I recommend Marjorie Chan's magnificent ChinaLinks.]
Those whose classical Chinese is rusty may find Legge's translation helpful:
Tsze-lu said, "The ruler of Wei has been waiting for you, in order with you to administer the government. What will you consider the first thing to be done?"
The Master replied, "What is necessary is to rectify names."
"So! indeed!" said Tsze-lu. "You are wide of the mark! Why must there be such rectification?"
The Master said, "How uncultivated you are, Yu! A superior man, in regard to what he does not know, shows a cautious reserve. If names be not correct, language is not in accordance with the truth of things. If language be not in accordance with the truth of things, affairs cannot be carried on to success. When affairs cannot be carried on to success, proprieties and music do not flourish. When proprieties and music do not flourish, punishments will not be properly awarded. When punishments are not properly awarded, the people do not know how to move hand or foot. Therefore a superior man considers it necessary that the names he uses may be spoken appropriately, and also that what he speaks may be carried out appropriately. What the superior man requires is just that in his words there may be nothing incorrect."
December 30, 2005
Opa!
I'm in New York for the American Philosophical Association's Eastern Division meetings, and I'm having breakfast at the Art Cafe on Broadway, at 52nd Street. It's all bustling efficiency, staff zooming hither and thither. Two eggs up with bacon and wheat toast arrive within a couple of minutes. Suddenly there's a shattering crash from behind the counter, and the Greek proprietor is looking down mournfully at the coffee cup he dropped on the tile floor to smash into a thousand pieces. Four or five nearby waitresses turn in shock. For two seconds of silence they stare at the scene of the accident. And then one of the waitresses yells excitedly: "Opa!" — the traditional Greek cry of encouragement to dancers and musicians and drinkers at those wild parties where they smash plates on the floor as they dance just to show what a great time is being had. And then the entire staff cracks up, and they all resume working at high speed, but now laughing till tears come to their eyes — the boss included. It's only breakfast time in New York, but already, thanks to one well-chosen interjection, it's like a party.
Old school
Joel Spolsky demonstrates what he calls his "descent into senility" in a classic "kids these days" rant, about how today's programming courses are too easy because they use Java. He sums it up at the end with a version of the old joke,
A: In my day, we had to program with ones and zeros.
B: You had ones? Lucky bastard! All we got were zeros.
On his way to the punch line, he tells us "Java is not, generally, a hard enough programming language that it can be used to discriminate between great programmers and mediocre programmers". This is in contrast to the old-school courses based on Scheme and C, whose difficulty Spolsky remembers as "astonishing". Spolsky "struggled through such a course, CSE121 at Penn". He tells us that he "watched as many if not most of the students just didn't make it. The material was too hard. I wrote a long sob email to the professor saying It Just Wasn't Fair. Somebody at Penn must have listened to me (or one of the other complainers), because that course is now taught in Java."
Now he wishes that my colleagues in computer science at Penn hadn't listened to him, because he feels that today's Java-based courses don't teach about pointers (which are a central issue in C programming) and recursion (which is central in Lisp). And according to him,
beyond the prima-facie importance of pointers and recursion, their real value is that building big systems requires the kind of mental flexibility you get from learning about them, and the mental aptitude you need to avoid being weeded out of the courses in which they are taught. ...
Nothing about an all-Java CS degree really weeds out the students who lack the mental agility to deal with these concepts.
He compares this to the gatekeeper function once played by Latin and Greek:
... in 1900, Latin and Greek were required subjects in college, not because they served any purpose, but because they were sort of considered an obvious requirement for educated people. In some sense my argument is no different that the argument made by the pro-Latin people (all four of them). "[Latin] trains your mind. Trains your memory. Unraveling a Latin sentence is an excellent exercise in thought, a real intellectual puzzle, and a good introduction to logical thinking," writes Scott Barker. But I can't find a single university that requires Latin any more. Are pointers and recursion the Latin and Greek of Computer Science?
I suspect that the "Latin trains your mind" argument became prominent just when the real practical reasons for a grounding in classical languages had largely vanished, and when obligatory teaching of Latin was therefore under successful attack. In the seventeenth century, an educated person needed to know Latin in order to read the current literature: Newton's Philosophiae Naturalis Principia Mathematica was published in Latin in 1687, and was not translated into English until 1729. But long before 1900, it was difficult to find practical arguments for the role of Latin in career development, outside of Catholic theology and a few areas of history and literature. Latin (and to a lesser extent Greek) had been reduced to the status of a cultural common ground for (the more traditionally-minded strata of) the educated and professional classes, and a barrier to entry into those strata.
And just as Spolsky was wrong in 1987 if he believed that it was the use of Scheme in Penn's CSE 121 that made it too hard, he's wrong now to complain that the use of Java means that such courses now necessarily fail to ground students in foundational concepts such as pointers and recursion. A colleague who has recently taught that course writes:
This is total BS. Java has pointers (has Spolsky ever heard of NullPointerException?), and we spend a lot of time on recursion and data structures, and very little time on OOP terminology. It also demonstrates the cult attitude of a certain kind of programmer, with rites of passage, the chosen and the fallen, etc. We teach in Java because it is the best compromise for a set of conflicting requirements. It's only people who can't teach who rant on about "pure" approaches. Reminds me of a certain kind of academic "radical" activist of my youth.
Well, in fairness to Spolsky, he does lead with a jokey admission that he's descending into senility, and he quotes from the start of Monty Python's Four Yorkshiremen skit:
“You were lucky. We lived for three months in a brown paper bag in a septic tank. We had to get up at six in the morning, clean the bag, eat a crust of stale bread, go to work down the mill, fourteen hours a day, week-in week-out, and when we got home our Dad would thrash us to sleep with his belt.”
(And do read the rest of it, if you haven't done so recently.)
I went to a secondary school where Latin was still required, and I think that I benefited from it. However, that's mainly because grammar, logic and rhetoric are a good foundation for a general education, and careful analysis of admired works in a foreign language is a good way to provide that foundation. My objection to language education today is not that schoolchildren are no longer required to learn Latin, but that most of them are no longer taught linguistic analysis of any sort at all.
I suspect that there's a similar basis for Spolsky's frustration at the quality of job applicants that happen to be coming his way these days. If they can't "rip through a recursive algorithm in seconds, or implement linked-list manipulation functions using pointers as fast as they could write on the whiteboard", it's because they haven't learned the relevant concepts and skills, not because their intro programming courses didn't use LISP and C.
Senility and Monty Python jokes aside, there are some serious and important educational issues here. But it just confuses matters to focus on Scheme and C or Latin and Greek, instead of on pointers and recursion or IPA and parsing.
[I guess I should add that other undergraduate computer science courses at Penn require the use of other languages, including not only Scheme and C/C++, but also OCaml, Prolog, Python and Matlab, depending on what makes sense for the content and structure of the course in question. I believe that this is typical of good computer science programs in the U.S. these days. ]
[Update 1/9/2006: Since some people are still linking here, I'll add a link to a thoughtful post by a current Penn undergrad, and to Bill Poser's terminological disquisition.]
How often does your mother say "butt"?
So asks Benson Smith, proposing a novel and interesting hypothesis that may shed new light on the contested origins of the phrase "butt naked":
Your post "new intensifiers" was linked recently from a German/English translation forum I like to read. I thought you might enjoy my pet theory:
1) in German, the word "aber" is used as an intensifier in the same way (es ist ABER kalt! = it's REALLY cold!)
2) "aber" is...wait for it...German for "but"
3) there have been a lot of German settlers in America, including, for example, Iowa
4) my mother, who is from Iowa, occasionally says "it is *but(t)* cold outside"
5) how often does your mother say "butt"?Conclusion: the expression was originally "but X" -- but cold, but ugly, etc. It comes from German settlers speaking English too literally. Naturally, native English speakers misinterpreted "but" as "butt", since "but" is not used as an intensifier in English.
Well, this morning Google does have 908 hits for {"butt cold"}. Unfortunately, Google Maps won't yet let us display an overlay of dots for the native region of the authors -- or even for the geographical location of the IP addresses of the sites, like these maps of recent Language Log visitors (produced by sitemeter, not by Google):
More seriously, one of the things I've come to realize about this sort of etymological discussion is that there may sometimes be more than one right answer. Ben Zimmer has promoted Alan Metcalf's five FUDGE factors for predicting the success of neologisms (Frequency of use, Unobtrusiveness, Diversity of users and situations, Generation of other forms and meanings, and Endurance of the concept), adding his own sixth factor Resistance to public backlash. This gives us FUDGER, and I don't see any graceful way to add another pronounceable letter (maybe fudgery?), so I'll give up on the acronymic theme, and just add my suggestion in plain prose.
Multiple sources, interpretations and resonances increase the fitness of a word or phrase. Regionalisms, archaisms, technical terms, substrate influences and euphemistic (or scatalogical) alternatives can all help. Whatever and whenever the earliest uses of "butt naked" and "buck naked" were, it seems clear that both have been around for a while, with plausible independent modes of interpretation, connected to some of the ordinary meanings of butt and buck. There might also have been some support from a calque representing common usage in German, the non-English language spoken by the largest number of immigrants to the U.S. over the course of its history. I haven't seen any real evidence for this theory -- with all due respect to Benson Smith's mother -- but evidence that the intensifier sense of butt has other roots is not necessarily evidence against his suggestion. And vice versa.
From Nabisco to NaNoWriMo
In my post yesterday critiquing Kevin Roberts' coinage of sisomo (an acronymic blend of "sight, sound, and motion"), I stated that "extracting the first two letters from each word in a series is not a productive source of English neologizing." This was a bit too glib a dismissal, since there is some precedent for such orthographic blends, especially if we consider not just two-letter "Consonant-Vowel" components but the combination of initial syllables or syllable-parts more broadly.
The birth of modern English acronymy can be traced to the early years of the 20th century (though there is some evidence for acronymic thinking — mainly in the form of backronyms — from the 19th century and earlier). In 1901, the National Biscuit Company filed a trademark for a shortened form of the company name: Nabisco. The following year (as noted by David Wilton on the American Dialect Society mailing list and in his book Word Myths), Sears, Roebuck & Company began advertising under the trade name Seroco. Similar corporate acronyms quickly followed, particularly in the petroleum business. In 1905, the Texas Company sought a trademark for Texaco, and other oil companies such as Sunoco (Sun Oil Company), Amoco (American Oil Company), and Conoco (Continental Oil Company) followed suit by the 1920s. The shared component in these blends is the final -co, short for company in all cases. (It could even appear medially, as in Socony, for Standard Oil Company of New York). This is clearly derived from the abbreviation Co., which developed a spelling pronunciation of /koʊ/ (independent of the pronunciation of the first syllable of /'kʌmpəni/) that was then available for acronymic combination. We can see a similar process with other abbreviation-derived components, such as So. and No. in acronyms like SoCal (Southern California) and NoCal (Northern California).
Seroco and all of those oil companies ending in -oco must have exerted an influence on English speakers' acronymic patterning, since we find a marked propensity towards orthographic blends involving rhyming -o syllables throughout the late 20th century. In the mid-1960s, the Howard Johnson restaurant chain came to be known as HoJo or HoJo's (evidently popularized by the introduction of "HoJo Cola" in 1964). It would then be the fate of anyone named Howard Johnson, be he a New York Met or president of MIT, to be assigned the nickname HoJo. On the HoJo model, track star Florence Griffith-Joyner was popularly known as FloJo when she won three gold medals at the 1988 Olympics. Similar rhyming nicknames continue to develop, such as ProJo for the Providence (R.I.) Journal and more recently MoDo for New York Times columnist Maureen ("Mo") Dowd (used as early as Sep. 2002 by Andrew Sullivan).
Since the 1970s, blends à la HoJo have extended beyond personal nicknames. The region of lower Manhattan below Houston Street was originally known as "South Houston Industrial Area," but this was shortened by city planners to the snappier SoHo around 1970. The new name was interpreted as a blend of "south of Houston" and was soon joined by NoHo ("north of Houston"), not to mention various other non-rhyming blend-names for Manhattan neighborhoods (TriBeCa, NoLiTa, etc.). Other acronymic legacies of the 1970s include slomo for "slow-motion" and froyo for "frozen yogurt" (though these at least match up phonemically with the source material, unlike the other strictly graphemic blends discussed here). The 1980s of course brought us pomo for "post-modern(ist)" approaches to art and literature. And in 2000, David Brooks introduced his own contribution to the field in the title of his book Bobos in Paradise, where bobo stands for "bourgeois bohemian" (in turn apparently modeled on the old shortening of bohemian to boho).
No other vowel comes close to o in the production of rhyming orthographic blends. The only serious competitor is i, largely on the strength of two popular coinages from the mid-20th century: hi-fi for "high fidelity" (appearing as early as 1947 in an issue of Popular Science Monthly uncovered by Barry Popik) and sci-fi for "science fiction" (dated to 1949 in a letter by Robert Heinlein tracked down by Jeff Prucher of the Science Fiction Citations project). More recently we have Wi-Fi, which many assume stands for "wireless fidelity" on the analogy of hi-fi. But Phil Belanger, a founding member of the Wi-Fi Alliance, recently revealed that Wi-Fi wasn't originally intended to stand acronymically for anything (though obviously there must have been an implicit modeling on hi-fi).
Note that hi-fi and sci-fi both use the /aɪ/ pronunciation for the letter i, which phonemically matches each blend's first component (high and science, respectively). The second syllable (fi in both cases) follows with /aɪ/, despite the fact that the i in the first syllables of fidelity and fiction are actually pronounced as /ɪ/. This is for the sake of the rhyme, but also because the rules of English phonotactics disallow words ending in /-Cɪ/. (The schwa sound /ə/ is available word-finally, so presumably hi-fi could have ended up sounding like Haifa. But the rhyme was clearly too appealing to early hi-fi enthusiasts.)
So how does Roberts' creation of sisomo stack up to these neologistic forebears? The final two syllables with their matching o's don't seem so bad, especially since there are precedents for using so to stand for sound (as in sonar) and mo to stand for motion (as in slomo). But that first syllable — si for sight — is still rather odd, since Roberts wants us to pronounce it as /sɪ/ (based on the synthesized voices that keep obtruding on his website). Why not /saɪ/, which would not only match up phonemically with sight but would also resonate with earlier blends like hi-fi and sci-fi ? Odder still, when we hear the creator himself pronounce the word by clicking on "Kevin Roberts' message" on the site, he's pronouncing it with initial-syllable stress as /'sɪsəmoʊ/, which both draws attention to the clumsy first component and destroys the euphony one would expect from rhyming o's. (Roberts, by the way, is a New Zealander working in New York for a London-based firm, so his speech pattern has a certain "International English" flair to it.)
Finally, I should note that what I sense as artificial and awkward in sisomo might actually work for other pairs of ears. On Erin O'Connor's LiveJournal blog there has been a lively debate on the coinage, with most commenters objecting on semantic grounds or a general impression of "yuckiness." But one contributor mentioned a recent acronymic blend that strikes me as structurally quite similar to sisomo: NaNoWriMo, which stands for "National Novel Writing Month." Since the launch of NaNoWriMo in 1999, companion blends have appeared like NaNoEdMo (National Novel Editing Month), NaNoWriYe (National Novel Writing Year), and NaNoPubYe (National Novel Publishing Year). So perhaps this type of acronymic pile-up really is the wave of the future and I'm just being a stick in the mud. I probably would have griped about Nabisco in 1901.
[Update #1: Jeff Russell emails with some examples of "Stanford-speak":
Your Language Log post on initial-syllable acronymy struck a chord with me, since it's particularly prevalent at my recent alma mater Stanford University, where this pattern is referred to as "Stanford-speak". Some words are rolled out mostly during admit weekend (usually referred to as "ProFro weekend", from "prospective freshman") and feel artificial even to us undergraduates, but most of these words are used without any self-consciousness by mid-freshman year. In fact, it would garner strange looks or confusion to refer to the CoHo as "the coffee house", to the dorm FloMo as "Florence Moore", or to FroSoCo as "Freshman-Sophomore College". "Memorial Church" is MemChu, "Memorial Auditorium" is MemAud, "Tresidder Express" is TresEx, and "Residential Education" is ResEd. In writing, these appear with our without spaces, and with or without the capital letters.
As you observed, rhyming -o syllables, are particularly common, even to the point of co-opting other vowels (though the "fro" in "freshman" may arise from "frosh"). One interesting thing is that attempts to coin new Stanford-speak--and they are often made--usually fail. "MuFuUnSun" (for Music and Fun Under the Sun, an annual event) and "HooTow" (for Hoover Tower), while in use, never sound anything but contrived, and most (like "FoHo" for fountain-hop, or "StanSpe" for Stanford-speak) are non-starters. ]
[Update #2: Jonathan Epp writes in with another NaNoWriMo spinoff and a question about the pronounceability of such acroblends:
I had seen NaNoWriMo used in blogs before your "From Nabisco to NaNoWriMo" post, but had never imagined that anyone would actually say it verbally. (Although, that may say more about the circle of people I speak with than anything else.) I've also seen NaDruWriNi (National Drunk Writing Night) used in blogs, which would seem even more awkward to use in conversation. Given the context though, that may be half the fun. ]
December 29, 2005
Asbestos she can
A few days ago, Nathan Bierma asked me (by email) whether the construction exemplified by "as best (as) I can" might be a blend of "the best (that) I can" and "as well as I can". The puzzle is why we say "as best (as) I can", but not "as hardest (as) I can", or indeed "as ___ (as) I can" for any other superlative.
Whatever the exact history, "as best <SUBJ> <MODAL>" is an old pattern. For instance, an anonymous drama from 1634, "The Mirror of New Reformation", has the lines
... I wil straight dispose,
as best I can, th'inferiour Magistrate ...
And in "The Taming of the Shrew" (1594), Shakespeare has Petruchio say
And I haue thrust my selfe into this maze,
Happily to wiue and thriue, as best I may ...
The pattern "as best as" seems to be more recent. The earlier citation I could find was from 1856, in "Night and Morning" (a play adapted from the novel by Bulwer-Lytton), where Gawtry says:
In fine, my life is that of a great schoolboy, getting into scrapes for the fun of it, and fighting my way out as best as I can!
It continues to be used by reputable authors, as in William Carlos Williams' poem 1917 poem "Sympathetic Portrait of a Child":
As best as she can
she hides herself
in the full sunlight
But whatever the origins and history of the construction, Nathan's suggestion might have something to do with the forces that keep it in current use. So I thought I'd look at some current web counts; and since different search engines sometimes give counts that differ in random-seeming ways, I tried MSN, Yahoo and Google. I started by looking at the patterns "as best __ can" and "as best as __ can", across the different pronouns. I might still discover something relevant to Nathan's question, but along the way I stumbled on a strange pattern in the web search count, which I'll share with you now.
| [MSN] | I |
you |
he |
she |
it |
we |
they |
[total] |
| as best __ can | 183,672 |
152,044 |
31,785 |
11,353 |
28,837 |
217,952 |
98,167 |
|
| as best as __ can | 74,551 |
35,688 |
4,869 |
1,938 |
6,133 |
33,812 |
12,724 |
|
| best/best as ratio | 2.4 |
4.3 |
6.5 |
5.9 |
4.7 |
6.4 |
7.7 |
4.3 |
| [Yahoo] | I |
you |
he |
she |
it |
we |
they |
[total] |
| as best __ can | 1,070,000 |
659,000 |
210,000 |
80,300 |
114,000 |
853,000 |
495,000 |
|
| as best as __ can | 438,000 |
148,000 |
33,400 |
2,800 |
30,300 |
148,000 |
67,500 |
|
| best/best as ratio | 2.4 |
4.5 |
6.3 |
28.7 |
3.8 |
5.8 |
7.3 |
4.0 |
Helpful Yahoo asks "Did you mean 'asbestos they can'?", although the suggested substitution gets only 95 yits compared to 67,500 for "as best as they can", andYahoo doesn't make any such suggestion for any of the other pronouns in this pattern.
| [Google] | I |
you |
he |
she |
it |
we |
they |
[total] |
| as best __ can | 830,000 | 466,000 | 132,000 | 51,000 | 95,100 | 667,000 | 377,000 | |
| as best as __ can | 320,000 | 102,000 | 21,600 | 851 | 22,400 | 114,000 | 49,300 | |
| best/best as ratio | 2.6 | 4.6 | 6.1 | 60.0 | 4.2 | 5.9 | 7.6 | 4.2 |
In this case, the (proportional) counts are generally pretty consistent across the search engines:
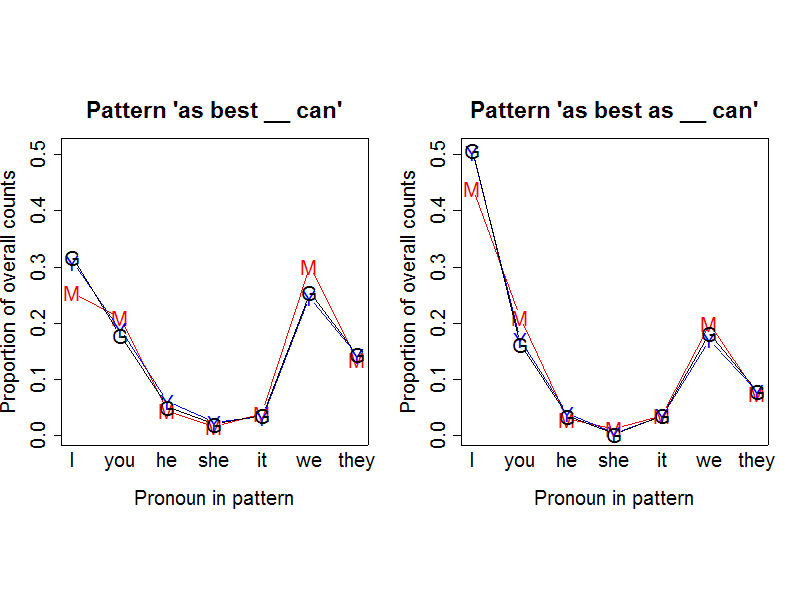
However, there's something funny going on with "she", as we can see better if we display the proportions on a log scale:
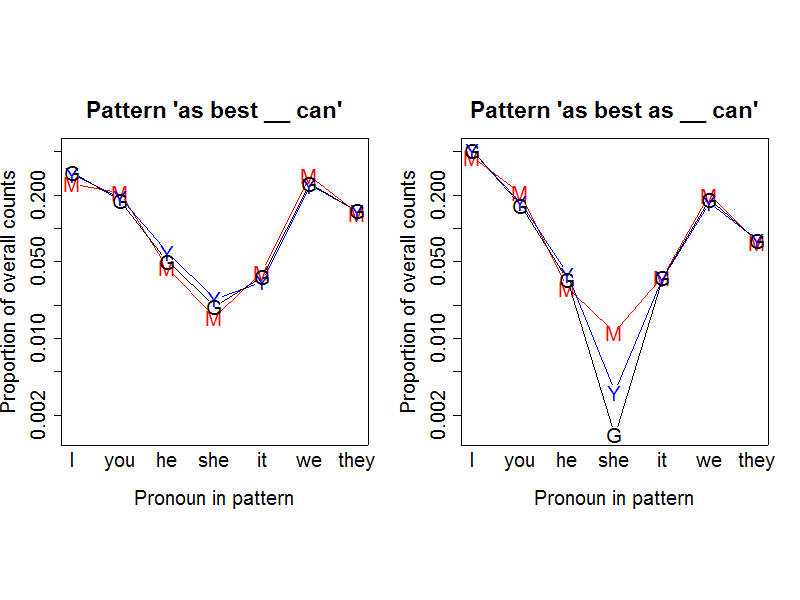
The oddity is even clearer if we plot the best/best as ratios:
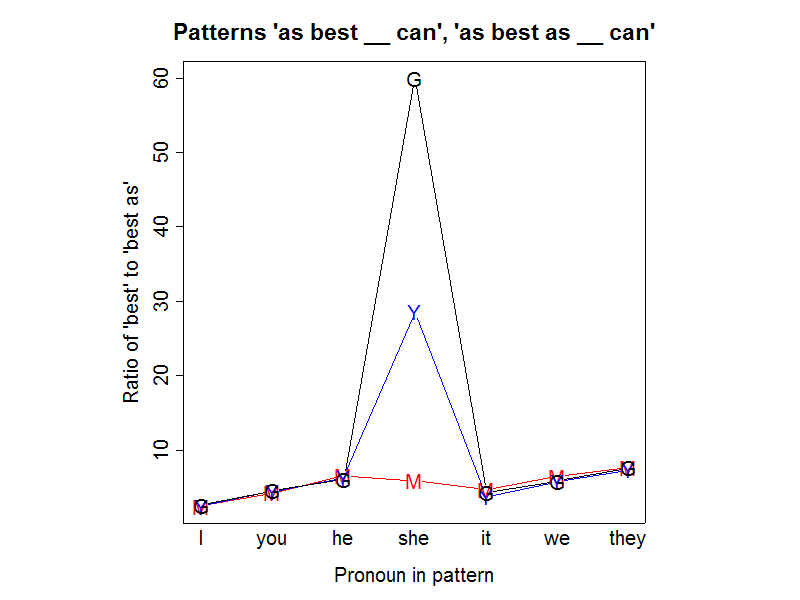
Google and Yahoo have many fewer hits for the string "as best as she can" than they ought to, in proportion to their counts "as best she can" and their counts for other pronouns in both patterns. What could be going on?
If all three search engines showed the same deficit, we might explore the idea that this is telling us something about our culture's thought and language. But they don't, and so I strongly suspect that instead this is showing us something about the algorithms that Google and Yahoo use to prune SEO-blackhat web pages.
For linguistic as well as algorithmic comparison, here are the analogous numbers and pictures for the pattern "the best (that) __ can":
| [MSN] | I |
you |
he |
she |
it |
we |
they |
[total] |
| the best __ can | 462,164 | 659,558 | 65,128 | 23,822 | 284,798 | 508,639 | 277,363 | |
| the best that __ can | 64,998 | 60,047 | 7,715 | 2,812 | 36,476 | 52,614 | 43,164 | |
| best/best as ratio | 7.1 | 11.0 | 8.4 | 8.5 | 7.8 | 9.7 | 6.4 | 8.5 |
This time, by the way, helpful MSN asks "Were you looking for 'the beast that we can'?"
| [Yahoo] | I |
you |
he |
she |
it |
we |
they |
[total] |
| the best __ can | 2,940,000 | 3,180,000 | 422,000 | 183,000 | 1,050,000 | 2,700,000 | 1,350,000 | |
| the best that __ can | 343,000 | 267,000 | 47,300 | 4,240 | 127,000 | 244,000 | 168,000 | |
| best/best as ratio | 8.6 | 11.9 | 8.9 | 43.2 | 8.3 | 11.1 | 8.0 | 9.8 |
| [Google] | I |
you |
he |
she |
it |
we |
they |
[total] |
| the best __ can | 1,830,000 | 1,700,000 | 280,000 | 93,100 | 795,000 | 1,660,000 | 1,280,000 | |
| the best that __ can | 225,000 | 175,000 | 28,600 | 12,600 | 75,100 | 161,000 | 126,000 | |
| best/best as ratio | 8.1 | 9.7 | 9.8 | 7.3 | 10.6 | 10.3 | 10.2 | 9.5 |
Again, the (proportional) counts are generally pretty consistent across the search engines:
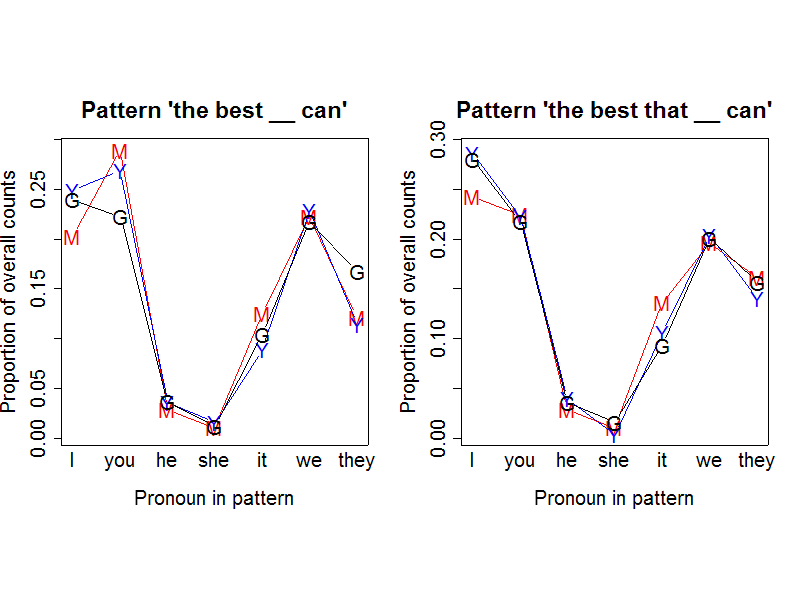
But again, there's something funny going on with "she", though this time it only shows up in Yahoo's counts:
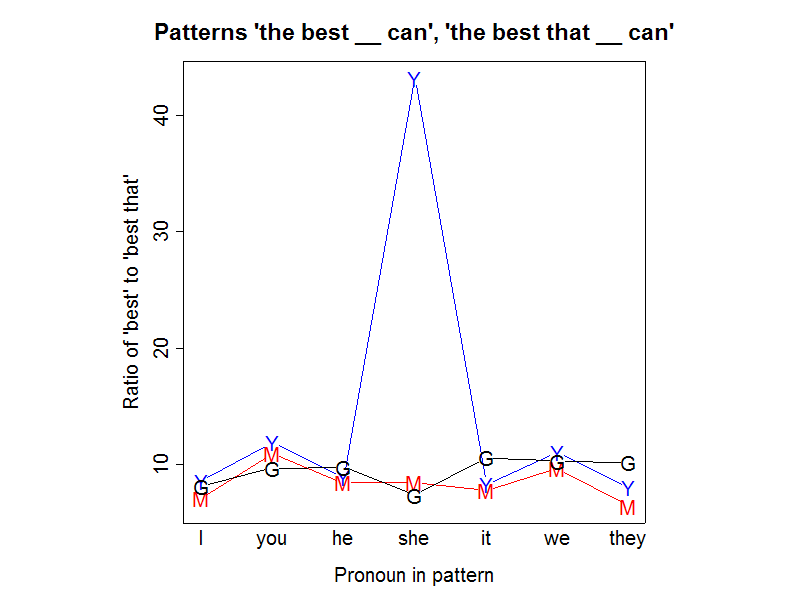
I remain puzzled about what is really behind this -- maybe something about the typical language of porn site link nests? My interest in reverse engineering search engines is not great enough to motivate me to spend much more time investigating it. But if you know, or have a good guess, tell me and I'll tell the world.
Does sisomo have sisomomentum?
 Sometimes it's easy to spot neologisms that are bound to fail. But there can be a multitude of reasons why a freshly minted word or phrase turns out to be a nonstarter. As noted here previously, Allan Metcalf discerned five factors necessary for a neologism to catch fire, acronymized as FUDGE: Frequency of use, Unobtrusiveness, Diversity of users and situations, Generation of other forms and meanings, and Endurance of the concept. To these five we might add a sixth criterion: Resistance to public backlash. Of course, that's mainly a concern for coinages that are foisted on the public for possibly cynical marketing purposes. One recent example was Cyber Monday, specifically designed to boost post-Thanksgiving online purchases. Now comes the latest self-conscious creation from the world of advertising: sisomo.
Sometimes it's easy to spot neologisms that are bound to fail. But there can be a multitude of reasons why a freshly minted word or phrase turns out to be a nonstarter. As noted here previously, Allan Metcalf discerned five factors necessary for a neologism to catch fire, acronymized as FUDGE: Frequency of use, Unobtrusiveness, Diversity of users and situations, Generation of other forms and meanings, and Endurance of the concept. To these five we might add a sixth criterion: Resistance to public backlash. Of course, that's mainly a concern for coinages that are foisted on the public for possibly cynical marketing purposes. One recent example was Cyber Monday, specifically designed to boost post-Thanksgiving online purchases. Now comes the latest self-conscious creation from the world of advertising: sisomo.
No, it's not some new variant of sudoku (or suduko, or sudoko, or soduko, or...). It's the brainchild of Kevin Roberts, CEO of the advertising giant Saatchi & Saatchi, and it's an acronymic blend of "sight, sound, and motion," trumpeted as "a new word for a new world." The website that Roberts created to popularize the word supplies the pronunciation upon loading, whether you want to hear it or not: it's /sɪsoʊmoʊ/, with roughly even syllabic stress (though that stress pattern is likely due to the synthesized voices that contribute to the site's earnestly techno-futuristic flourishes).
Strike one against sisomo: it's a graphemic blend rather than a phonemic one, taking the first two letters of each of the component words regardless of the resulting mismatch between sound and spelling. (Perhaps they test-marketed the fully diphthongized sighsoumo and it didn't fly.) Graphemic blends do occasionally crop up in English, particularly those of the acronymic type that take the first letter or two from words in a phrase, such as sonar from "sound navigation ranging," or COBOL from "COmmon Business-Oriented Language." But extracting the first two letters from each word in a series is not a productive source of English neologizing. (You never know, though — sisomo could be thought to have a particularly "modern" sound, as sonar and COBOL were no doubt considered at the time of their coinage.)
The word was introduced at last month's Ad:Tech conference in New York, where Roberts unveiled it as his label for a purportedly new advertising imperative: the need to combine sight, sound, and motion in an emotionally captivating package, now typically mediated by multiple video screens (TVs, cellphones, computers, etc.). Unsurprisingly, he also announced that his buzzword is the topic of a new book he was plugging, Sisomo: The Future on Screen.
Roberts further explained his push for the new word in an article in the Dec. 29 New Zealand Herald:
"Revolution starts with language," he said - quoting publisher Alan Webber. "So, creating a new word was a deliberate move."
It's technically a noun, but Roberts has no shortage of ideas for how it can be dropped into casual conversation as a verb. How about: "We're sisomoing all our ideas" ... or "The story sisomoed up really well."
I think Roberts might be jumping the gun in his pursuit of one of Metcalf's five factors, "generation of other forms and meanings." He's not only imagining a transition from noun to verb but also to an idiomatic phrasal verb, sisomo up. (And not just a phrasal verb but an intransitive one. Even particularly successful neologisms like google usually stay transitive when making the phrasal-verb leap, though there are scattered examples of people talking about the things that google up when they're a-googlin'.)
Roberts is also fond of blending upon his blend: the text of his Ad:Tech speech reveals sisomovers, sisomojo, and sisomotivators. One blogger at the conference, who also mentioned Roberts' use of sisomoments and sisomovies, thought that this made it a "fun" word; others might find these strained attempts at whimsy to be mildly annoying. And again, isn't this jumping the gun just a bit? Has Roberts forgotten the cautionary tale of 2004 presidential candidate Joe Lieberman and his self-defeating proclamation of Joementum?
A cardinal rule of neologizing is that one person can't carry the load of hyping the coinage, even a master hyper (a hyper-hyper, if you will) like Roberts. Others may be building on the blend, however. Another blogger from the world of advertising has suggested the further acronymic elaborations of misisomo (marketer-inspired sight sound and motion) and cisisomo (consumer-inspired sight sound and motion).
Obviously, Roberts is going to need recognition beyond advertising circles if he hopes to achieve neologistic nirvana with sisomo. In the New Zealand Herald article, he claims that the buzz is building:
Roberts said a lot of the interest in the concept was coming from the news media, the big retailers and the electronics companies. ...
Roberts launched the word sisomo at an advertising industry conference in New York last month.
Since then he has made two US TV appearances and attracted many articles in business sections. One internet-based English dictionary has sisomo on its list of candidates for inclusion. But Roberts is hoping for more of a global linguistic splash.
"I've just been in Russia and Korea talking about it and they can all say sisomo," he said. "We just want to see it becoming part of the lexicon."
I'm pretty certain that the "internet-based English dictionary" mentioned in the article is none other than Grant Barrett's Double-Tongued Word Wrester, a favorite at Language Log Plaza. DTWW was on the case almost immediately, with a citation posted Nov. 9. (The citation was from a live-blogger at the Ad:Tech conference, whose mention that Roberts "coined a word" must have set off bells at DTWW's blog-tracking facilities.)
I'm not so sure that inclusion in the DTWW citation queue is really an indication of the incipient popularization of sisomo. After all, the queue has room for such marginal coinages as hideawfulous and charmesty. But Roberts might be on to something with his realization that sisomo presents no pronunciation problems for Russians or Koreans. Even if sisomo proves to be a dud stateside, it could be the neologistic equivalent of movies like Kingdom of Heaven: disappointing domestically, but an impressive performer overseas.
[Update: More on the history of such orthographic blends in this post.]
December 27, 2005
The brave new world of computational neurolinguistics
Yesterday I wrote about an ITV documentary, airing today, that promises to unveil some weird-sounding "neurolinguistic" research on the endorphin-stimulating effects of Agatha Christie's prose style. I asked British readers for more information, and even before seeing the program, Ray Girvan was able to help:
Being commissioned for a ITV documentary marking the 75h anniversary of the creation of Miss Marple, the exercise has "promotional" written all over it. ITV has an ongoing coproduction agreement with Chorion plc, rights owners and makers of Agatha Christie TV films.
The premise of the enduring popularity of Christie's text doesn't entirely bear scrutiny. Sales of her books were declining in the late 1990s, and have only risen again after extensive rebranding and promotion by Chorion plc, who bought the rights in 1999.
Now why didn't the Times, the Guardian, the BBC and the rest of the British mainstream media give us this sensible account of the commercial forces behind the Agatha "research"?
Take a look at the breathless BBC story headlined "Scientists study Christie success". Its subhead was "Novelist Agatha Christie used words that invoked a chemical response in readers and made her books 'literally unputdownable', scientists have said." The lead sentence was "A neurolinguistic study of more than 80 of her novels concluded that her phrases triggered a pleasure response".
The BBC article gives us no hint that ITV has a financial interest in the "enduring popularity" of Christie's work. The article is in the entertainment section, not the science section or the business section; but a majority of readers will surely see it as a story about the popularization of scientific research, not a story about a public relations stunt in support of a commercial partnership. (There may well be some real science behind the program -- I'll reserve judgment on that until the work is described somewhere in enough detail to evaluate.)
Well, I've made a New Year's resolution to look on the bright side, so I'm going stop berating science journalism at the BBC-- clearly a lost cause -- and focus instead on the wonderful new opportunity here for enterprising teams of computational and neurological linguists.
The recipe is simple. Take one fading literary property with a cash-rich proprietor, one statistical string analysis algorithm, and a sheaf of brain images with hot and cool color patches. Mix well. Sprinkle with neurotransmitters; add sex and violence to taste; and serve on a bed of fresh press releases.
A few years in the future, I look forward to reading the first of a veritable river of publications from the Doubleday Institute of Computational Neurolinguistics at UCSC: Pullum, G. et al., "The obsessive-compulsive code: effects of anarthrous noun phrases on striatal dopamine D2 receptors".
[I should stress that the neuroscience of language is an eminently respectable field, where rigorous and exciting work is being done; and that integration of advanced computational techniques into this field is one of its most promising areas. In this post, I'm poking fun at a case where press reports suggest that the field is being exploited for publicity purposes by a partnership of media companies.]
[Update: Ray Girvan emailed:
I watched the programme, and updated my weblog entry with the notes I made. I admit I'm biased - I think Agatha Christie's work is execrable - but the programme was nevertheless very poor science.
They did various computer analyses of word and phrase distribution: pretty standard computational linguistics stuff. The shaky part was the interpretation of the results by various non-mainstream pundits - a Lacanian psychoanalyst, a stage hypnotist, and two Neuro-linguistic Programming experts - who all asserted that the observed word distributions literally hypnotised the reader.
In his weblog entry, Ray Girvan describes the program at greater length:
The main experts were computational linguist Dr Pernilla Danielsson (billed as "academic champion of communications") and Dr Markus Dahl, a research fellow (a Johnny Depp lookalike, including top hat) at the University of London Institute of English Studies. The camera tracked around them portentously as they sat at glowing laptops in a dimly-lit smoky room and, bit by bit, revealed the purported secret of Christie's success. As LL guessed, Dr Roland Kapferer wasn't among them; he was revealed in the credits as the associate producer/writer for the programme.
The science boiled down to a) computerised textual analysis - word frequencies, and so on - and b) subjective psychological interpretation of the results thereof. Christie's nearly invariable use of "said", rather than said-bookisms, was claimed to enable readers to concentrate on the plot. Her works' narrow range on a 3D scatter plot (axes and variables unknown) indicated a consistent style, assumed to be a Good Thing compared to Arthur Conan Doyle. Sudden coherent sections in her otherwise messy notebook indicated her getting "into the flow" - a trancelike writing state (Darian Leader, a psychoanalyst, endorsed the idea that she had been in a similar, deeper trance during her famous 10-day disappearance) and Dr Dahl argued that this trance transferred to the reader.
The trance theory was the central thrust of the programme. David Shephard, a Master Trainer in Neurolinguistic Programming, asserted that the level of repetition of key concepts over small spaces (e.g "life", "living", "live", "death" in a couple of paragraphs) consolidated concepts in the reader's mind. He claimed further that we can only hold nine concepts in the mind at once (I assume a reference to Miller's classic Seven plus or minus two figure for short-term memory capacity) and that Christie's use of more than nine characters overloads the reader's conscious mind, making them literally go into a trance. Dr Dahl cited a further textual result - Christie's "ingenious device" of controlling the reading speed by decreasing the level of detail toward the ends of books, and stage hypnotist Paul McKenna claimed that this invoked the neurotransmitters of craving and release, making the books addictive.
Finally they rolled out the big gun, Dr Richard Bandler, "father of Neurolinguistic Programming", who repeated the assertion of Christie literally hypnotising readers, and said the lack of detail helped maintain that trance. And that was it: "extensive computer analysis", concluded the Joanna Lumley voiceover, has enabled a "quantum leap" in understanding the source of Christie's enduring popularity. Why, surely only a cynic could remain unconvinced by such rigorous science...
I expect we Americans will be able to see this on the Discovery Channel or the History Channel before long. If so, my New Year's Resolution to focus on the positive side of linguistics in the media will be subjected to a rigorous test. ]
December 26, 2005
Kenzi, Camerair, and other hybrid beasts
The recent outbreak of blends combining famous names — from Brangelina to Scalito — was notable enough to merit inclusion in the New York Times' annual roundup of buzzwords. Though it seems that the faddish blending of celebrity couples is finally on the wane, political portmanteaus continue to emerge on a regular basis. Such name-blends are sometimes coined to underscore the similarity of two politicians, especially if they belong to opposing parties and should ostensibly be on different sides of the ideological fence. In his Dec. 24 column, conservative pundit Robert Novak mentions one recent example:
Republican senators complain that Sen. Edward M. Kennedy, liberal lion of the Senate, has taken over effective control of the Senate Health, Education, Labor and Pensions Committee because the Republican chairman, Sen. Michael Enzi of Wyoming, defers to him so much. In an era of intense partisanship, Kennedy and Enzi collaborate on spending and regulatory measures before their committee. ... Behind his back, Republican staffers have come to refer to the chairman as Sen. "Kenzi."
Unseemly bipartisanship is apparently enough to trigger a disparaging name-blend in the current Congress (particularly if there is a felicitous intersection of phonetic material, as with /'kɛnədi/ and /'ɛnzi/). Across the Atlantic, Conservative and Labour party faithful similarly express their wariness of bland centrism through onomastic fusions. In the Guardian, Timothy Ash suggests a blend to highlight the shared banality of Tory leader David Cameron and the man he hopes to replace as prime minister, Labour's Tony Blair: Camerair. Ash notes that Nick Cohen of the New Statesman has already beaten him to the punch with a different blend: Blameron. But Ash says he prefers his version since it "hints at the essential mixture of television cameras and hot air." (I'd say that Camerair is also preferable for its cheesy connotations, as it's reminiscent of Camembert.)
Camerair and Blameron have a clear progenitor in British political parlance. When Rab Butler, a Tory, replaced the Labour Party's Hugh Gaitskell as Chancellor of the Exchequer in the 1950s, the Economist satirized Butler's similarities to his predecessor by imagining a hybrid of the two chancellors named "Mr. Butskell." Conservative-Labour consensus politics then came to be labeled Butskellism.
Though there isn't such a high-profile precursor in U.S. political name-blending, it's not a particularly new phenomenon in this country either. In the April 1934 issue of American Speech, Robert Withington noted a name-blend in a book that had been published the previous year, William Aylott Orton's America in Search of Culture. Orton makes reference to "the Hoolidge era," conflating the presidential terms of Hoover and his predecessor Coolidge. Unlike Kenzi, Camerair, or Butskell, the Hoolidge blend combines members of the same party, suggesting the homogeneity of two successive Republican administrations rather than bipartisan blandness. (Withington also discerns in Hoolidge echoes of hooligan, evoking "a certain ridicule for the chicken-in-the-pot era which stressed material prosperity." This connotation would be missing if Orton had coined a chronologically ordered blend like Coover or Coolver.) There are no doubt earlier name-blends to be found in American political history — after all, one of the most famous political coinages is a blend of man and beast, dating to 1812: Gerrymander, combining Gerry (i.e., Massachusetts Governor Elbridge Gerry) with salamander.
Name-blending also has a durable lineage in literary criticism. In 1888, an article in the Saturday Review belittled the illustrious crank Ignatius Donnelly and his newly published book The Great Cryptogram, which supposedly uncovered the hidden ciphers proving that Shakespeare's plays were written by Sir Francis Bacon. The article, entitled "Ignatius Shacon," took great delight in satirizing Donnelly and his followers, the Shaconians (and their supposed foes, the Bakespearians). Shaconian hasn't had much staying power (except among curators of obscure words, variously deemed grandiloquent, luciferous, or simply worthless). A more famous literary name-blend appeared in a 1908 essay by George Bernard Shaw, in which Shaw conceived of a mythical four-legged creature combining aspects of his colleagues G.K. Chesterton and Hillaire Belloc. He called it the Chesterbelloc. I wonder what Shaw would have made of our current menagerie of Bennifers, Tomkats, and Vaughnistons?
(And speaking of blends, merry Chrismukkah, or Chrismahanukwanzakah if you prefer.)
The Udmurtian code: saving Finno-Ugric in Russia
The Finno-Ugric family of languages contains Finnish, and its close relative Estonian, and Sami (the language of the Lappish people of the far north), and various related languages languages in Russia (Komi, Mari, Udmurt), along with a distant southern relative, Hungarian. It's actually not that easy to show with clear etymologies and sound changes that Finnish and Hungarian really are cousins. There are maybe 200 solid cognates. (A cognate is a word showing in both its pronunciation and its meaning or grammatical properties that it was ancestrally shared by the relevant languages, and was transmitted in altered phonological form down the centuries rather than being directly borrowed between modern languages.) The Economist (December 24th, page 73) has a very interesting article about the way Finno-Ugric languages are dying in Russia. In connection with the discussion of linguistic relatedness, it cites Estonian philologist Mall Hellam as having come up with a sentence that should be intelligible to Finnish, Estonian, and Hungarian speakers alike:
| Finnish: | Elävä kala ui veden alla. |
| Estonian: | Elav kala ujub vee all. |
| Hungarian: | Eleven hal úszkál a víz alatt. |
The translation is "The living fish swims in water." Looking at the examples (which are in the standard spellings for the three languages) set me to wondering if there is indeed mutual intelligibility here, as opposed to just full cognate status for all words. It seems rather implausible to me that a monolingual Hungarian would be able to understand even one sentence of Finnish unless they took it on as a puzzle-solving exercise. I guess I know how to find out: I can pronounce Finnish well enough, and I have Hungarian friends who don't read Language Log. I'll do some work on the question.
[In fact I have already heard from a Finn living in Hungary, Vili Manula, who says no Hungarians understand the Finnish sentence, and certainly no Finn would understand the Hungarian one. So the experiments are done, and my suspicions are justified. And a thread on the discussion forum sci.lang pretty much demolishes the mutual intelligibility claims; it seems the sentences have a long history in the Finno-Ugric world, and calling them mutually intelligible was always way, way exaggerated.]
Talking of things being far-fetched, one member of the Finno-Ugric movement headquartered in Talinn (Estonia), fearing that publishing things like a slim volume of poetry in Mari was not going to be enough to ensure the survival of Finno-Ugric in the Russian area, remarked to The Economist's reporter that what they really need is The Da Vinci Code in Udmurt. Which set me to wondering whether you would need to translate it into bad Udmurt to get the feel of the original.
The Agatha Christie Code: Stylometry, serotonin and the oscillation overthruster
Agatha Christie, who died in 1976, has been in the news a lot lately. Atai Winkler's "research" for lulu.com on the statistics of book titles, discussed on Language Log a couple of weeks ago, gave rise to some of the headlines, for example "Computer Model Names Agatha Christie's 'Sleeping Murder' as 'The Perfect Title' for a Best-Seller". But others reference a different piece of techno-literary sleuthing. Richard Brooks of the Sunday Times tells us, in "Agatha Christie's grey cells mystery", that "leading universities" have discovered that Christie's appeal is due to "the chemical messengers in the brain that induce pleasure and satisfaction":
The mystery behind Agatha Christie’s enduring popularity may have been solved by three leading universities collaborating on a study of more than 80 of her crime novels.
Despite her worldwide sales of two billion, critics such as the crime writer P D James pan her writing style and “cardboard cut-out” characters. But the study by neuro-linguists at the universities of London, Birmingham and Warwick shows that she peppered her prose with phrases that act as a trigger to raise levels of serotonin and endorphins, the chemical messengers in the brain that induce pleasure and satisfaction.
Some might think that this is a complicated way of saying that people like the way she writes, but I'll reserve judgment until I see how the researchers themselves put it.
Meanwhile, Russell Jackson in The Scotsman takes a different tack in "Experts solve mystery of Agatha Christie's success". Apparently "linguistics experts" have discovered that the secret is a mathematical formula:
The study was carried out by linguistics experts at Warwick, Birmingham and London universities and the results are to be revealed in an ITV1 documentary on 27 December.
Dr Roland Kapferer, the project's leader, said: "It is extraordinary just how timeless and popular Agatha Christie's books remain. These initial findings indicate that there is a mathematical formula that accounts for her success."
Again, this seems to be a complicated way of saying that Christie's success is due to identifiable properties of her writing, rather than a special intervention of divine providence in the marketplace. I haven't read the rest of the news reports, but no doubt other journalists have explained that Ms. Christie's enduring success has been shown to be an emergent property of the arrangements of atoms and molecules in the printed copies of her works.
This 12/19/2005 news release from the University of Birmingham explains more about the formulae involved: this part is apparently work by Pernilla Danielsson, a computational linguist in the Department of English:
Agatha Christie used a limited vocabulary, repetition, short sentences and a large amount of dialogue in her text according to research carried out by the University of Birmingham for ITV 1’s special Christmas programme about the author.
Dr Pernilla Danielsson from the University’s Department of English has analysed the type of words that Christie used in her detective novels to develop a better understanding of her writing style and to find out why she is the world’s best selling author. To do this she has also compared Christie’s writing to that of Arthur Conan Doyle, author of Hound of the Baskervilles.
This sounds like a plausible project in stylometry, but there's nothing about it yet in any of Dr. Danielsson's works that Google or Google Scholar can find. And the Birmingham press release doesn't mention anything about serotonin or endorphins.
I couldn't find anything about this project on the University of Warwick's web site, or various of the University of London's sites. A search for "Agatha Project" on Google Scholar and other indices of scientific and technical publications turned up only some references to a completely different "Agatha Project", an old HP expert system for diagnosing PA-RISC processor board failures.
And I couldn't find anything anywhere about Dr. Roland Kapferer, "the project's leader", unless he's the Roland Kapferer referenced here as a "film and television producer and freelance writer based in London and Sydney", with "a PhD in Philosophy from the University of Macquarie", who may also be the same as the Roland Kapferer who is the lead singer for Professor Groove and the Booty Affair. If so, then he's a sort of real-world Buckaroo Banzai: could the rest of the Hong Kong Cavaliers be somewhere in the background, measuring those serotonin levels?
The ITV1 program " The Agatha Christie Code" is being "revealed" tomorrow at 16:00, so perhaps some British readers will be able to provide additional information about this research. Who, for example, is responsible for the "neuro" aspect? How did they measure serotonin and endorphins, or is that all journalistic free association? Is there going to be a publication at some point, or was this research done exclusively for the ITV Special? And has anyone seen Penny Priddy?
So far, the "Agatha Project" shares a crucial negative feature with the Lulu Titlescorer and last fall's "infomania study": there's no publication or documentation. No equations, no published data, no fitted models, no source code. Just press releases and (in the case of Agatha) a TV program. Until what they did is documented in enough detail for others to evaluate, the press reports are the same category as Professor Hikita's Oscillation Overthruster: evocative fiction. Looking on the bright side, I guess it's nice to see some popular evocative fiction with a linguistic theme.
[Update: the BBC, vying with The Sunday Timies in earnest credulity, provides some juicy details apparently supplied by Dr. Kapferer -- a few of the specific "language patterns" which "stimulated higher than usual activity in the brain" and "triggered a pleasure response".
The team found that common phrases used by Christie acted as a trigger to raise levels of serotonin and endorphins, the chemical messengers in the brain that induce pleasure and satisfaction.
These phrases included "can you keep an eye on this", "more or less", "a day or two" and "something like that".
"The release of these neurological opiates makes Christie's writing literally unputdownable," Dr Kapferer said.
If it weren't so obviously unethical -- and also so obviously ineffective -- I'd suggest a small experiment at your local watering hole:
| You: | Can you keep an eye on this while I visit the restroom? |
| Attractive potential new friend: | Um, OK. |
| You: | You seem trustworthy, more or less. |
| A.P.N.F.: | [uneasily] Uh huh... |
| You: | I won't be gone more than a day or two. |
| A.P.N.F.: | Visiting the restroom. |
| You: | Something like that. |
Intoxicated by potent neurological opiates, your new friend will be thenceforth be addicted to your company. Really, the BBC says so. ]
[Update: more on this here.]
December 25, 2005
Not a brilliantological invention
Gene Shalit's opinion of the new King Kong is that it is "so gargantuan that I must create new words to describe it: fabularious... a brilliantological humongousness of marvelosity". There's that funny layperson's fetishizing of words again: why do people think that to say something impressive you need new words? What you need is skill in deploying the ones we already have. You should at least have a crack at explaining your view before giving up and alleging inadequacy in the English word stock.
But enough curmudgeonliness, let's just do some empirical work. Did Gene's amateur efforts in lexical morphology actually result in any new words? It turns out that inventing words for a language as well stocked as English is not quite as easy as you might think.
First, fabularious is not original; it was invented (not necessarily for the first time) by a blogger named Sam in an affectionate comment addressed to a blogger named Julia on February 11, 2004 ("You are hilarious and fabulous, so much so that I am combining it into a single word--Fabularious. Use it, love it"). Second, marvelosity is not new either: it gets 377 Google hits. Third, humongousness certainly isn't new; the jocular adjective it is regularly derived from, humongous, gets about 2.37 million hits, so I was surprised to find that humongousness got only 471; but that's still enough to quash the claim of inventing new words.
So Gene is down to just one out of four. And brilliantological isn't exactly brilliant, is it? Just about every native speaker knows that for any morpheme X of the appropriate sort, the appropriate sort being either a noun or what The Cambridge Grammar calls a combining form (like geo- or morpho-), Xological means having to do with or belonging to Xology, and Xology is the academic study of whatever the root X denotes (e.g., the earth if X = geo). So ‘King Kong’ has something to do with the academic study of... brilliant?
As we have definitely remarked before here on Language Log, sometimes you just absolutely know that a word is not going to catch on, don't you?
December 24, 2005
"60 Minutes" doomed to repeat itself
About halfway through the fourth quarter of the NFL matchup between the Indianapolis Colts and the Seattle Seahawks, one of the announcers for the CBS telecast delivered the standard rat-a-tat promo for upcoming shows on the network:
Tomorrow on "60 Minutes"... A year after the tsunami. In a culture that has no concept of time, how did one group of people know ahead of time that it was coming?
Yes, it's the return of the Moken, the "sea gypsies" living on islands in the Andaman Sea that a "60 Minutes" crew visited in the wake of the tsunami. Back in March, Bob Simon informed us (extrapolating wildly from sketchy comments by anthropologist Jacques Ivanoff) that because the Moken language doesn't display the temporal markers that Western languages do, the islanders therefore have "no notion of time."
Now here we are again a year after the tsunami, and the show is still peddling the same "Whorf Lite" nonsense. It almost makes you wonder — despite the tick-tick-tick of Western modernity emblematized by the "60 Minutes" stopwatch, perhaps it's American TV journalists who live in an unchanging, ahistorical present tense, not those "primitive" islanders.
L(a)ying snow
Some of the more antisocial neighbours near where we live did not bother to bestir themselves with a snow shovel the way we did after the big early snowfall that hit the Boston area on December 9. Their laziness, plus some partial meltings and re-freezings, has turned parts of the sidewalks between our Inman Square apartment and the Harvard/Radcliffe area into a treacherous glacier. The walk to the Radcliffe Institute that Barbara and I have to do each morning has become difficult and dangerous. We were surprised to learn from our friend Tom Lehrer at lunch yesterday that snow laziness is a famous cultural feature of Cambridge quite specifically. David T. W. McCord (Harvard class of ’21) used to write a column in the Harvard Alumni Bulletin called "The College Pump", and sometimes he would add in little verses to make columns fit. The verse he published on March 15, 1940, went like this:
In Boston when it snows at night
They clean it up by candle-light;
In Cambridge, quite the other way,
It snows and there they leave it lay.
But of course, that's one of the instances of lay that should have been lie, isn't it?
You knew that. You remember it from my advice column on the topic, which you understood in full and were not the slightest bit confused by. When Boston's weather spirits decide to lay down some snow and people leave it alone, they let it lie. (The construction leave it lie is unusual in modern Standard English; let it lie or leave it there are standard, but leave it lie is not.)
The snow lay there, crushed and frozen and slippery, until today's thaw, in fact. That occurrence of lay is OK, it's a preterite. Like the one in this Christmas carol:
Good King Wenceslas looked out
On the feast of Stephen
When the snow lay all about
Deep and crisp and even
There it's lay not lie because although it's intransitive the verb looked tells you we're in the past so you get the preterite of intransitive lie which looks exactly like the present of transitive lay (whereas the preterite of lay doesn't look like either lay or lie). Would I lie to you?
Merry Christmas!
December 23, 2005
Multiplying ideologies considered harmful
Tim Groseclose and Jeff Milyo's recently-published paper ( ("A Measure of Media Bias", The Quarterly Journal of Economics, Volume 120, Number 4, November 2005, pp. 1191-1237) has evoked plenty of cheers and jeers around the web. The complaints that I've read so far (e.g. from Brendan Nyhan, Dow Jones, Media Matters) have mainly focused on alleged flaws in the data or oddities in the conclusions. I'm more interested in the structure of their model, as I explained yesterday.
As presented in the published paper, G&M's model predicts that perfectly conservative legislators -- those with ADA ratings of 0% -- are equally likely to cite left-wing and right-wing sources, basing their choices only on ideology-free "valence" qualities such as authoritativeness or accessibility. By contrast, perfectly liberal legislators are predicted to take both ideology and valence into account, preferring to cite left-wing sources as well as higher-quality or more accessible ones. Exactly the same pattern is predicted for media outlets, where the conversative ones should be indifferent to ideology, while the more liberal the media, the more strongly ideological the predicted motivation.
Common sense offers no reason to think that either politicians or journalists should behave like this, and everyday experience suggest that they don't -- the role of ideology in choice of sources, whatever it is, doesn't seem to be qualitatively different in this way across the political spectrum. Certainly Groseclose and Milyo don't offer any evidence to support such a theory.
This curious implication is a consequence of two things: first, G&M represent political opinion in terms of ADA scores, which vary from 0 (most conservative) to 100 (most liberal); and second, they put political opinion into their equations in the form of the multiplicative terms xibj (where xi is "the average adjusted ADA score of the ith member of Congress" and bj "indicates the ideology of the [jth] think tank") and cmbj, where cm is "the estimated adjusted ADA score of the mth media outlet" and bj is again the bias of the jth think tank.
As I pointed out yesterday, the odd idea that conservatives don't care about ideology can be removed by quantifying political opinion as a variable that is symmetrical around zero, say from -1 to 1. (It's possible that G&M actually did this internal to their model-fitting, though I can't find any discussion in their paper to that effect.) However, this leaves us with two other curious consequences of the choice to multiply ideologies.
First, on a quantitatively symmetrical political spectrum it's the centrists -- those with a political position quantified as 0 -- who don't care about ideology, and are just as happy to quote a far-right or far-left source as a centrist source. This also seems wrong to me. Common sense suggests that centrists ought to be just as prone as right-wingers and left-wingers to quote sources whose political positions are similar to their own.
A second odd implication of multiplying ideologies is that as soon as you move off of the political zero, your favorite position -- the one you derive the most utility from citing -- become the most extreme opinion on your side of the fence, i.e. with the same sign. If zero is the center of the political spectrum, and I'm a centrist just a bit to the right of center, then I'll maximize my "utility" by quoting the most rabid right-wing sources I can find. If I happen to drift just a bit to the left of center, then suddenly I'm happiest to quote the wildest left-wing sources. This again seems preposterous as a psycho-political theory.
I'm on record (and even with a bit of evidence) as being skeptical of the view that the relationship between ideology and citational preferences is a simple one. And I'll also emphasize here my skepticism that political opinions are well modeled by a single dimension. But whatever the empirical relationship between political views and citational practices is, it seems unlikely that ideological multiplication captures it accurately.
On the other hand, does any of this matter? It's certainly going to do some odd things to the fitted parameters of G&M's model. For example, if they really treated the conservative position as the zero point of the political spectrum, then I'm pretty sure that their estimated "valence" parameters (which they don't publish) will have encoded quite a bit of ideological information. If we had access to G&M's data -- it would be nice if they posted it somewhere -- we could explore various hypothesis about the consequences of trying models with different forms. Since (as far as I know) the data isn't available, an alternative is to look at what happens in artificial cases. That is, we can generate some artificial data with one model, and look to see what the consequences are of fitting a different sort of model to it.
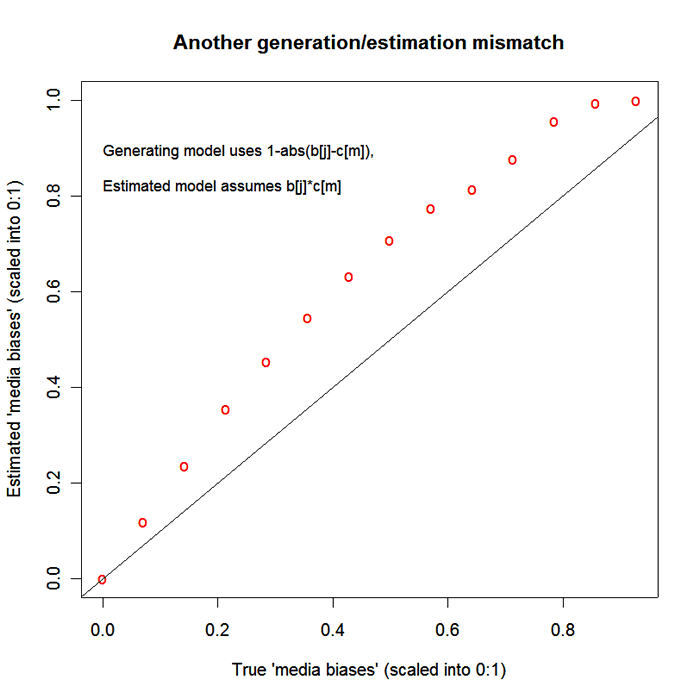
I had a spare hour this afternoon, so I tried a simple example of this. I generated data with a model in which people most like to quote sources whose political stance is closest to their own -- left, right or center -- and then fitted a model of the form that G&M propose. The R script that I wrote to do this, with some comments, is here, if you want to see the details. (I banged this out rather quickly, so please let me know if you see any mistakes.) One consequence of this generation/fitting mismatch seems to be that the "valence" factor for the think tanks (which I assigned randomly) and the noise in the citation counts perturb the "ideology" and "bias" estimates in a way that looks rather non-random. I've illustrated this with two graphs showing the difference between the "true" underlying media bias parameters (with which I generated the data) and the estimated media bias parameters given G&M's model. The first graph shows a run in which nearly all the media biases are overestimated,
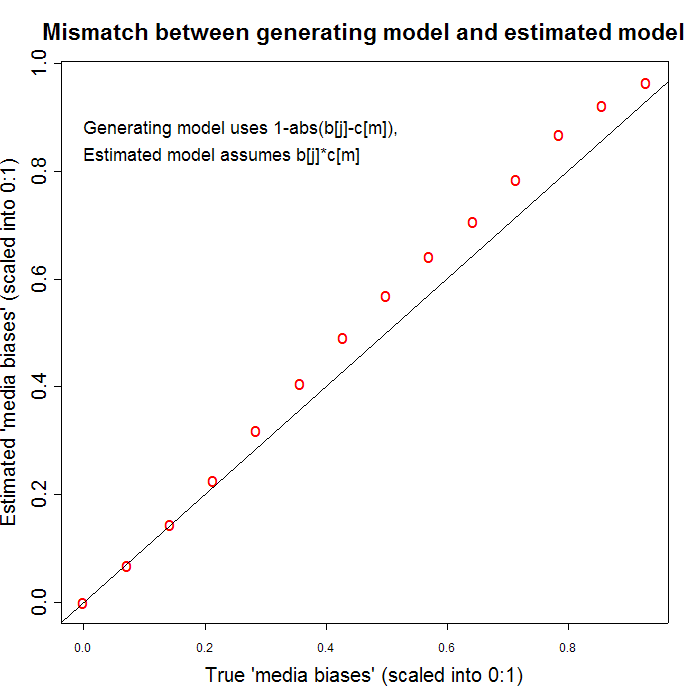
while the other shows a run in which nearly all the media biases are underestimated.
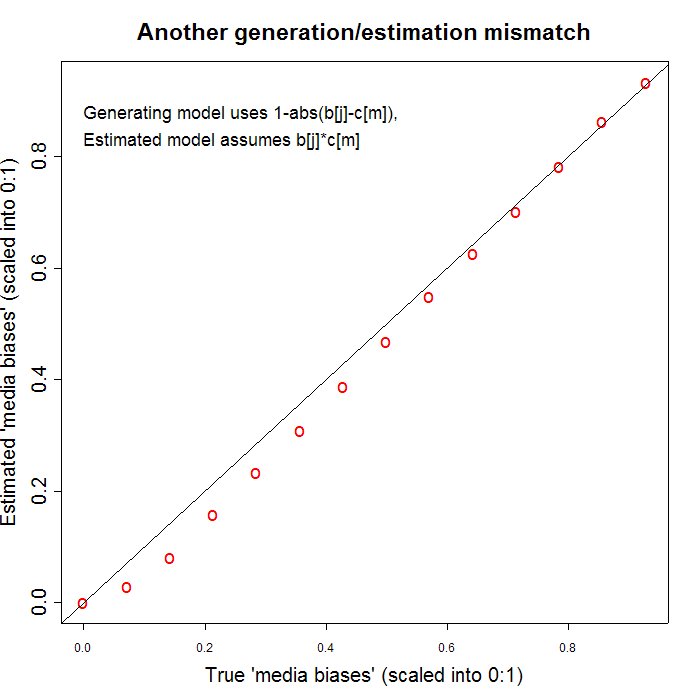
The only difference was different seeds for the random number generator. I used rather small amount of noise in the citation counts -- noisier counts give bigger deviations from the true parameter values, like this one:
Presumably similar effects could be caused by real-word "valence" variation or by real-world citation noise. Nearly all runs that I tried showed this kind of systematic and gradual bending of the estimates relative to the real settings, rather than the sort of erratic divergences that you might expect to be the consequences of noise. Since R is free software, you can use my script yourself as a basis for checking what I did and for exploring related issues.
(By the way, the mixture of underlying 'ideology' into estimated 'valence' can be seen clearly in this modeling exercise -- here's a plot illustrating this:
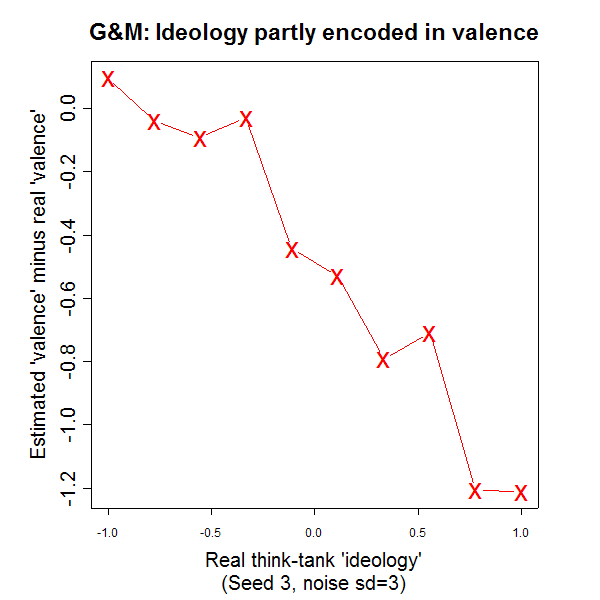
)
I'm not claiming to have shown that G&M's finding of quantitative media bias is an artefact. I do assert, though, that multiplying ideologies to get citation utilities (and through them, citation probabilities) is a choice that makes very implausible psychological claims, for which no evidence is presented. And fitting ideology-multiplying models to data generated by processes with very different properties can definitely create systematic artefacts of a non-obvious sort.
No regular readers of Language Log will suspect me of being a reflexive defender of the mass media. I accept that news reporting is biased in all sorts of ways, along with (in my opinion) more serious flaws of focus and quality. I think that it's a very interesting idea to try to start from congressional voting patterns and congressional citation patterns, in order to infer a political stance for journalism by reference to journalistic citation patterns. I also think that many if not most of the complaints directed against G&M are motivated in part by ideological disagreement -- just as much of the praise for their work is motivated by ideological agreement. It would be nice if there were a less politically fraught body of data on which such modeling exercises could be explored.
December 22, 2005
Linguistics, politics, mathematics
In the end, this post is about the recently-published study of media bias by Tim Groseclose and Jeff Milyo ("A Measure of Media Bias", The Quarterly Journal of Economics, Volume 120, Number 4, November 2005, pp. 1191-1237). Earlier versions of that study have been widely reported and discussed over the past year and a half, including here on Language Log, with a critique by Geoff Nunberg, a response by Groseclose and Milyo, and a few other comments (here, here, and here). I started to play around with their model on the computer, and at the first step, something about the structure of the model took me aback. But before I get to the point, let me set the stage.
Last week, Penn's president had a holiday party for the faculty, in a big tent behind her house. In the midst of the throng I was talking with Elihu Katz and some other people from the Annenberg School for Communication, when another colleague, on being introduced, asked how we happened to be acquainted. Interpreting this as a question about academic disciplines rather than personal histories -- what could a sociologist have in common with a linguist? -- someone said something about a shared interest in communication. Elihu, who knows a thing or two about social networks, waved his hand at the crowd and said "well, I bet that 60% of the people here work on something connected to communication".
In fact, there's a cultural gulf between people who study large-scale communication -- media, politics, advertising -- and people who study small-scale communication -- individual speakers and hearers. This is one of the many boundary lines in the intellectual Balkans of research on language, meaning and communicative interaction, but I've felt for a long time that it's one of the borders where freer trade is most needed.
Some of us at Penn have recently gotten an NSF IGERT ("Interdisciplinary Graduate Education and Research Training") grant on the theme of "Language and Communication Sciences". Starting in January, I'm co-teaching a "Mathematical Foundations" course for this program, aimed introducing graduate students to a wide range of mathematical topics that are relevant to animal, human or machine communication. So I thought I'd take a small step in the direction of intellectual free trade by importing a problem or two from relevant areas of economics, political science or sociology.
One possibility is the model that Groseclose and Milyo have used to study media bias. This model is mathematically simple, and a version of it, I thought, could be applied to data from weblog links harvested (semi-)automatically. So I started playing around with an implementation of the model in R, initially using made-up data created by plugging appropriate sorts of random variables into the relevant places in the equations. And indeed this looks promising as a pedagogical exercise. But as I did this, I realized that the model starts with a very peculiar assumption about the relationship between political opinion and the choice of authorities to cite.
Let's pick up their "simple structural model" on p. 1208:
Define x i as the average adjusted ADA score of the ith member of Congress. Given that the member cites a think tank, we assume that the utility that he or she receives from citing the jth think tank is
(1) aj + bjxi + eij
The parameter bj indicates the ideology of the think tank. Note that if xi is large (i.e., the legislator is liberal), then the legislator receives more utility from citing the think tank if bj is large. The parameter aj represents a sort of “valence” factor (as political scientists use the term) for the think tank.
They then go on to specify an equation for the probability that the ith congresscritter will cite the jth think tank, given some assumptions about the distribution of the error term eij. And then they add a similar equation for media citations of think tanks, and use the model to work backwards from media citation counts to estimates of media ADA scores. But never mind that for now. I'm interested in a weird assumption built into equation (1).
Let's take it apart term by term. As they explain, xi is the "average adjusted ADA score of the ith member of Congress". Americans for Democratic Action (ADA) "scores" are denominated in percent, representing the percent of the time that a given legislator voted the way the ADA thinks (s)he should have. These scores thus run from 0 to 100, with 0 being the most "conservative" possible voting record and 100 being the most "liberal" possible record, given that we let the ADA define the "liberal" position. (G&M's "adjusted score" is as "constructed by Groseclose, Levitt, and Snyder [1999]" in order to make the scores "comparable across time and chambers". The details of the adjustment don't matter here, and the results are still numbers between 0 and 100.).
As for eij, it's just an error term of the kind that you have in any statistical model.
That leaves aj and bj, both of which are parameters associated with the jth think tank. As they explain, bj "indicates the ideology of the think tank", because "if xi is large (i.e., the legislator is liberal), then the legislator receives more utility from citing the think tank if bj is large".
OK, that seems reasonable. What about aj? They tell us that it "represents a sort of “valence” factor (as political scientists use the term) for the think tank". I didn't know how political scientists use the term valence, so I checked, and found an (implicit) definition in T. Groseclose, "A model of candidate location when one candidate has a valence advantage", American Journal of Political Science, 45 (4): 862-886 Oct. 2001:
This article extends the Calvert-Wittman, candidate-location model by allowing one candidate to have a valence advantage over the other, due to, say, superior character, charisma, name recognition, or intelligence. Under some fairly weak assumptions, I show that when one candidate has a small advantage over the other, this alters equilibrium policy positions in two ways. First, it causes the disadvantaged candidate to move away from the center. Second, and perhaps more surprising, it causes the advantaged candidate to move toward the center. I also show that, under some fairly weak assumptions, for all levels of the valence advantage, the advantaged candidate chooses a more moderate position than the disadvantaged candidate. Empirical studies of congressional elections by Fiorina (1973) and Ansolabehere, Snyder, and Stewart (2001) support this result.
So a candidate's valence is an "advantage" that's not associated with location on the spectrum of political opinions, but has to do instead with things like "superior character, charisma, name recognition, or intelligence". In the case of a think tank, "name recognition" can be applied directly, and the other qualities translate to things like perceived quality and integrity, level of funding, degree of access to publicity networks, and so on. Again, this seems fair enough: regardless of my political position, it's reasonable that I derive more utility from citing a well-known and widely respected think tank than from citing some small-time K street shell with a shady reputation, independent of my degree of agreement with the political slant of either outfit.
But if we think about the meaning of G&M's equation (1) as a whole, something very strange emerges.
Consider four (imaginary) think tanks, with these "valences" and "ideologies":
| Valence aj | Ideology bj | |
| Bleeding Heart Institution | 100 |
0.9 |
| Red Meat Foundation | 100 |
0.1 |
| Americans For Conservative Things | 10 |
0.1 |
| People For Liberal Things | 10 |
0.9 |
And consider two congresspersons with these "average adjusted ADA scores":
ADA score |
|
| Mildred Moonbat | 100% |
| Walter Wingnut | 0% |
G&M's model now assigns the following "utilities" (ignoring the error term):
| Mildred M | Walter W | |
| Bleeding Heart Institution | 100 + 0.9*100 = 190 |
100 + 0.9*0 = 100 |
| Red Meat Foundation | 100 + 0.1*100 = 110 |
100 + 0.1*0 = 100 |
| Americans For Conservative Things | 10 + 0.1*100 = 20 |
10 + 0.1*0 = 10 |
| People For Liberal Things | 10 + 0.9*100 = 100 |
10 + 0.9*0 = 10 |
This model says that because of Walter Wingnut's 0% ADA rating, he doesn't care at all about the ideology of the think tanks he cites. That's because an institution's "ideology" is multiplied by his ADA factor of 0, and so his "utility" depends only on the ideology-free "valence" of the institution. Mildred Moonbat's 100% ADA rating, on the other hand, means that she pays a full measure of attention both to "valence" and to "ideology".
Walt Wingnut is just as happy to cite the Bleeding Heart Institution as the Red Meat Foundation, and likewise just as happy to cite People For Liberal Things as Americans For Conservative Things. Millie Moonbat, on the other hand, is 73% happier to cite Bleeding Heart as Red Meat, and fully five times happier to cite People for Liberal Things as Americans for Conservative Things.
I submit that this is preposterous.
The model's prediction of the probability for a given congressperson to cite a given think tank is the exponential of the congressperson's utility for that think tank divided by the sum of the exponentials of their utilities for all think tanks. Because of the exponentials, the numbers assigned as valences -- and the resulting utilities -- will need to be much more tightly clustered if we want to get a reasonable amount of probability mass distributed over less-favored think tanks. But the basic mathematical fact remains the same: think tank ideology, according to this model, only matters to liberals. Or to put it another way, the more liberal the congressperson, the more weight they give to ideology; the more conservative they are, the closer they come to paying attention only to "valence", i.e. ideology-free quality.
Now, I freely admit that I'm not a social scientist. I'm not used to thinking about this particular kind of model, and maybe there's something obvious that I'm not seeing here. If so, I'm sure that someone will point it out to me.
But if I'm understanding this equation right, I don't understand how we got to this point in the discussion of this interesting and important piece of work without addressing this fundamental assumption of its defining equations. And I'm as guilty as anyone else, since I read a version of the paper back in July of 2004.
[Update: several people have written to observe that the problem that I describe does not arise if the conservative-to-liberal spectrum is made symmetrical around 0, e.g. -1 for most conservative to +1 for most liberal. Indeed -- that's what I assumed they were doing, when I first wrote about the details of their model back in October of 2004, because (I thought) that's the only version of the approach that seems to make sense. But in fact G&M's recent QJE article is quite explicit that their xi values, representing the ith congressperson's political position, are exactly ADA scores, which run from 0 (most conservative) to 100 (most liberal). They list these numbers in Table II, from Maxine Walters at 99.6 down to Tom DeLay at 4.7. The same thing holds for their cm values, the parameters representing the bias of the mth media outlet, which are denominated on exactly the same 0-to-100 scale, and which play an identical role in the equation specifying the utility that the mth media outlet derives from citing the jth think tank. Their Table III gives estimated c values for (some of?) the outlets in their study, from the Washington Times at 35.4 to the Wall Street Journal at 85.1.
Other people wrote to ask what effect if any the odd structure of their equation (1) might have had on outcome of the process of estimating the ADA ratings of media outlets by reasoning from the citational habits and ADA ratings of congresscritters. The answer is that I don't know, except to observe that from someone with an ADA rating of 0, their model gains information only about think tank valences and not at all about think tank ideologies. The estimate of think tank ideologies is influenced more and more strongly by the citational habits of more and more liberal congresspersons. I'm not sure what effect this had on the parameters they derived -- the result depends on the data as well as on the structure of the model -- but I'd be surprised if it didn't affect the outcome pretty strongly one way or another. It almost certainly means that the estimates of "valence" will in fact be some amalgam of valence-like factors and conservatism; and there will surely be some artefacts introduced into the estimates of think tank ideologies and media biases as well.]
[More better stuff on this same topic is here.]
December 21, 2005
Non-Mayan
The Apocalypto trailer is here. Lots of bangs, growls and grimaces -- but so far, not even a syllable of Mayan. I'm disappointed.
Spell simply and carry a big stick
Rob Malouf wrote to draw my attention to a cartoon, dated yesterday, expressing an apparently popular view of Dutch spelling reform.

The title translates as "Fokke and Sukke keep it simple", and as Fokke and Sukke walk away, one of them says to the other "So, was that a spelling-reformer or a spellingS-reformer?" Apparently the official distribution of linking -s- in compounds is one of the arbitrary things that have recently changed.
The response: "It's a dead one", where (I'm told) "dooie" is a non-standard spelling of "dode", representing a colloquial pronunciation.
Violent folk, those Dutch, at least when spelling is at issue.
[Update: Bruno van Wayenburg wrote:
Hah, keeping you quite busy, our spelling reform.
In this case, you could argue Fokke and Sukke's beef is about language, not only spelling, as the so called 'tussen-s' (between-s) in spellingShervormer *is* pronounced (although the meaning of both forms is the same), contrary to the tussen-n, which is involved in this spelling reform and which already generated much resistance when rules about it changed in 1995.
Fokke and Sukke, probably among the very few cartoon characters in major newspapers sporting genitals, have chameleon-like characters, and can get quite violent and crude, even when spelling is not at issue.This sort of answers an earlier query on Language Log asking whether violent anger about spelling and language issues is an exclusively Anglosaxon issue. Dutch ducks and canaries are also affected.
Bruno is referring to this query, with a follow-up here.]
[Note that if the title of the comic makes you(r inner 7th grader) start to giggle, you're apparently not alone, but still misguided.]
Unnecessarily unclear and ugly
Expatica News has been interpreting the controversy over new Dutch spelling reforms for non-Dutch-readers: "New Dutch dictionary sparks debate" (10/13/2005), "Media revolts against 'double-Dutch' revision" (12/19/2005), "Dutch language 'too complicated' for locals" (12/20/2005). A quote from the last-cited article:
The new spelling rules that come into force on August 2006 are unknown to 67 percent of the public. ...
Only 28 percent of the respondents feel they have mastered the 1995 standard, as laid out in 'De Groene Boek' (the Dutch language 'bible'), and an equally large number of people say they still use the pre-1995 spelling.
The latest revision of standard Dutch has caused a lot of debate in recent days. Several Dutch newspapers, magazines, the national news broadcaster NOS, and news website Planet.nl have announced they will boycott the new spelling.
The editors claim the latest revision makes the language unnecessarily unclear and ugly.
This kind of fuss is an apparently inevitable consequence of trying to treat language as a "made order" rather than a "grown order", even in the area of orthography, where arbitrary standards seem to the modern mind to be not only desirable but even essential. We think this even though Shakespeare and the other Tudor and Elizabethan writers somehow got along with catch-as-catch-can spelling. Since those days, the users of English have managed to create and impose spelling standards without designating any single official authority. Of course, we've paid the high social and educational cost of maintaining an orthographic system that is unnecessarily complex, inconsistent and hard to learn. Maybe an occasional top-down spelling reform would have been a good thing -- certainly we share with the Dutch a situation in which voluntary reform seems to be essentially impossible.
But what I want to know is, is "double Dutch" a calque of a Dutch expression that has been used to describe the 1995+2006 spelling reforms, or was the Expatica headline writer just using quotes to draw our attention to a bit of wit intelligible only to English readers? I somehow doubt that there can be a direct Dutch equivalent, since I guess the allusion must be to the English expression double dutch meaning "a language that one does not understand, gibberish" (according to the OED's gloss), rather than to double dutch meaning "A game of jump rope in which players jump over two ropes swung in a crisscross formation by two turners" (according to the AHD's gloss).
The Expatica link came from Arne Moll, who observes that journalistic discussions of this sort of thing seem inevitably to confuse "language" with "spelling". Thus the first sentence of the last-cited Expatica article is
Dutch is a complicated and illogical language, according to 60 percent of the Dutch people taking part in a new opinion poll.
The rest of the story makes it clear that they are talking about spelling (and especially changes in spelling, intended to make it simpler and more logical), not the subtleties of Dutch pronunciation, nor the suprising cross-serial dependencies in Dutch syntax, nor any of the other genuinely linguistic complexities of Dutch. Of course, this is an English-language article -- do we find this confusion even among the journalists of the country where the excellent language-oriented magazine Onze Taal is widely read?
And if you can read Dutch -- in any spelling -- with less pain that I can, you can see a rational discussion of the spelling reformat Onze Taal's site here and here.
[Update: Arne Moll responds:
To answer your last question: yes, unfortunately even among the Dutch there is plenty of confusion between language and spelling matters. For example the Dutch research agency that carried out the quoted research has rougly the same news headline as the Expactica one, and confuses the respondents of the questionnaire by using the words 'language' and 'spelling' without proper definition within the same question.
What I find surprising is that most commentators seem to dismiss new (and hence still 'complex') spelling matters such as "in which context should we write 'Middeleeuwen' [middle ages] with a capital M and one with a small m" as highly irrelevant and confusing, yet become very emotional when one suggests that in fact *all* spelling is rather arbitrary and could easily have been arranged differently.
More generally, I suspect people tend to get very emotional about rules they do know how to apply, and are indifferent about and even hostile towards rules they don't know how to apply. It would be interesting to test this hypothesis in other languages as well.
Perhaps we should say that many people are attached to familiar patterns, and suspicious or antagonistic towards unfamiliar ones. And as in other areas of culture, people often seem ready to conclude that those who don't display normative linguistic patterns are morally flawed. Trevor summed this up by changing one letter in Walter Davis' lyric:
You been doing something wrong
I can tell by the way you spell.
]
[And Bruno van Wayenburg writes:
No, 'Double Dutch' doesn't have an equivalent in Dutch (I remember actually being somewhat miffed when learning that the word 'Dutch' figured in so many negative meanings in English idioms). So the Expatica headline is genuine witty headline English, not a calque.
To answer your question about above-average linguistic awareness in the country of Onze Taal: most of the discussion is explicitly about 'spelling', not 'language'. In all the hubbub, I don't remember anybody lamenting that our language is going to the dogs because of the new rules (although it's of course going to the dogs for many other reasons, the main one being borrowing from English).
But the rope-skipping kind of "double Dutch" is not at all negative -- on the contrary! And the gibberish sense of "double Dutch" seems to go back to a time when Dutch meant something like "Germanic". At least, the OED gives "high Dutch" as an alternative phrase with the same meaning:
]1789 DIBDIN Poor Jack ii, Why 'twas just all as one as High Dutch.
Negation, over- and under-

Anything amiss in Monday's installment of "Hagar the Horrible"? Well, other than the fact that — in the words of Josh Fruhlinger at The Comics Curmudgeon — "Hagar and Lucky Eddie are Odin-revering pagans and wouldn't care about this so-called 'Christmas' anyway"? Readers of the Comics Curmudgeon blog were quick to point out another problem. Hagar says he misses not having a nine-to-five job, when the punchline, such as it is, suggests that the opposite is true: he misses having a nine-to-five job (and the Christmas party that goes with it). Hagar's usage is a very common overnegation, not just among anachronistic English-speaking, Christmas-celebrating Viking marauders. Last year Mark Liberman did a quick Google survey of "miss not VERBing" and found that the vast majority of such constructions are instances of overnegation.
Another apparent overnegation was recently spotted by Steve at Language Hat. It appears in a column by Leonard Quart in the Dec. 16 edition of the Berkshire Eagle, in which Quart compares contemporary Brooklyn to days gone by. In one section, Quart describes the imminent trendification of the neighborhood dubbed "Dumbo" (Down Under the Manhattan Bridge Overpass):
But the painter who said to me that he liked the fact that Dumbo is relatively undeveloped also knows that it will soon go the way of SoHo.
Dumbo will ultimately become so dominated by boutiques and condos that young painters like himself will no longer be unable to afford to live there.
The word "unable" is italicized in the original, which confuses
matters even further. A couple of Language Hat commenters suggested
that the italicization is evidence that Quart intended the double
negation, in an attempt to make a (rather obscure) joke about painters
needing to be in neighborhoods where they're unable to afford to live.
I commented that I doubted Quart was making an intentional joke, given
that "(will) no longer
be unable to VERB" is an overnegation about as common
as "miss not VERBing." Some examples provided by Google:
If a spring is exposed to that frequency as the motors rpm's increase, the vibration will rapidly build up to such an extent that the spring will no longer be unable to control its own motion. (link)
As the population ages, many amongst us will find that eyesight deteriorating and we will no longer be unable to drive as safely. (link)
If you earn 1 negative feedback your account may be suspended depending on the circumstances, and you will no longer be unable to list or bid. (link)
You will no longer be unable to add items to your Store unless you delete existing items or upgrade your account to a larger item limit. (link)
Most of my work is using these images and lyrics, so I regret that I will no longer be unable to post things here. (link)
Another commenter on the Language Hat posting was Martin Langeveld, who happens to work for the Berkshire Eagle's publishing company. Langeveld provided an insider's perspective on how the "no longer unable" construction might have entered Quart's column:
It seems to me this and the rest of the Google citations for "not ... unable" are typos rather than new usage memes. In other words, it's an artifact of the word-processor: Quart starts to write that young artists "will no longer be able to afford to live there," changes his mind to say, "will be unable to afford to live there," which sounds better, and then forgets to delete "no longer". Hand-writing, or even typing on a typewriter, you'd be more likely to remember the deletion. I see this kind of thing in news copy all the time. The languagelog example like "don't fail to miss it" are a different thing.
I agree wholeheartedly that unintentional overnegations have flourished in the age of cut-and-paste word processing. But I don't think that these examples are qualitatively very different from the other cases of overnegation catalogued here in the past. Even if we choose to call them "typos" rather than "usage memes," the question still remains: why are such overextensions of negation so easy to fail to miss? Quart's column presumably passed under the careful eyes of editorial-page editors and copy editors, and yet the overnegation stood. (Or perhaps the editors assumed that the sentence was indeed intended to be a joke of some sort.)
As we well know, all sorts of goofs get past even our most august journalistic bastions, so it should be no surprise that unintentional undernegation can also slip by. A Dec. 11 article in the Los Angeles Times about shock-jock Howard Stern's move to satellite radio included this sentence:
As for the medium he leaves behind, Stern not surprisingly is optimistic about its future.
A week later, the paper issued the following correction (as reported on Regret the Error, a blog that revels in such apologies):
An article about radio personality Howard Stern last Sunday mistakenly said that he is optimistic about the future of broadcast radio. It should have said he is not optimistic.
What happened here? I suspect that the offending sentence was the result of the type of cut-and-paste carelessness described by Langeveld. Perhaps the sentence originally read, "Stern is not optimistic about its future," and then when "not surprisingly" was inserted, the second not was lost in the shuffle. But it's doubtful that the sentence "Stern is not surprisingly not optimistic about its future" would have survived the editing process. For euphony's sake, one of the not's would have to go: either it would end up reading "Stern is unsurprisingly not optimistic" or "Stern is not surprisingly pessimistic."
The difficulty that formal written English has with double not's is perhaps a clue to how this error was allowed to pass. If the sentence that made it to print is read quickly, the single not seems like it could be pulling double duty, negating both surprisingly and optimistic. Formal English syntax doesn't really work that way, but it might be one unreflective method of dealing with the discordant double not in a construction like "not surprisingly not optimistic."
Something similar is apparently at work in another case of undernegation previously examined here in exquisite (or excruciating?) detail: still unpacked, when used to mean still ununpacked. (See installments 1, 2, 3, 4, 5, and 6, as well as commentary from Language Hat and the Boston Globe's Jan Freeman.) On the level of the individual word, the doubled negation represented by the two un- prefixes of ununpacked is, for most speakers, morphologically ill-formed. (This is despite the fact that the two prefixes can be construed as semantically distinct; if the first un- is taken to mean 'not' and the second indicates the reversal or undoing of a process, then ununpacked is understood as 'not yet having the process of packing reversed or undone.') Geoff Nunberg suggested that the simplification of ununpacked to unpacked constitutes "an idiosyncratic sort of haplology," another way of saying that the semantic content of the disallowed double prefix unun- gets packed into a single un-.
In the case of "not surprisingly not optimistic" inadvertently getting changed to "not surprisingly optimistic," the undernegation doesn't resolve an ill-formed construction, merely one that lacks euphony. Since this sort of proximate use of two not's is avoided in formal English, a writer or speaker might decide (without much reflection) that one will do the trick, just as one un- suffices for still unpacked.
This is somewhat different from another type of undernegation: the much-maligned transformation of couldn't care less into could care less (see this post and earlier commentary linked therein). Could care less was originally considered a negative polarity item, requiring a negative trigger like not or hardly. But over time it developed its own negative force for some speakers through what John Lawler has called "negation by association," thus obviating the need for an additional negative trigger.
A similar impulse may be at play in both types of undernegation, however: the desire to simplify perceived "double negatives." The aversion towards stigmatized "double negatives" is particularly strong when the same item is repeated twice (such as not or un- in the above examples). But it might also help explain the initial shift in polarity of could care less, based on a hypercorrection to resolve the cooccurrence of a negative trigger like not and the negative-sounding less in the idiomatic phrase.
Of course, this explanation has its limits, as not all "double negatives" get resolved through undernegation. On the contrary, as the many cases of overnegation demonstrate, speakers and writers of formal English sometimes pile up negations exuberantly. (Mark Liberman called this "the temptation of overnegation," explicable either as a confusion over the resulting polarity of multiple negations, or as a reversion to the negative-concord patterns of various colloquial English dialects.) The trick, then, is to try to determine which cases of cooccuring negations are identified as "double negatives" (and thus stigmatized), and which pass under the linguistic radar, to the extent that they are tolerated or even preferred in the seemingly illogical cases of overnegation. Not an easy task, not at all.
December 20, 2005
Merry Kitzmas!
Two months ago it was Fitzmas. Now the blend du jour is Kitzmas, and the occasion is the decision handed down today in Kitzmiller vs. Dover, the case regarding a Pennsylvania school board that tried to enforce the teaching of "Intelligent Design" in its science curriculum. U.S. District Judge John E. Jones has ruled that the Dover Area School Board violated the constitutional separation of church and state, and that Intelligent Design may not be taught in the school district's science classrooms. (AP report here, decision by Judge Jones here.)
There is understandably much rejoicing among those who care about the proper teaching of evolutionary science in the public schools. Biologist Paul Z. Myers, writing on the science blogs Pharyngula and The Panda's Thumb, was evidently the first to wish everyone a "Merry Kitzmas" when the news was announced earlier today, but the blend is already beginning to spread through the blogosphere. We'll see if it displays the rapid neologistic success of its predecessor, Fitzmas.
(Thanks to science writer Carl Zimmer, whose blog The Loom is unmatched in its lucid and eloquent commentary on evolution and other biological subjects. And I'd think that even if he wasn't my brother.)
[Update: Via Dennis Des Chene at Philosophical Fortnights, a survey of other Xmas coinages. As for Xmas where X = X, see the historical discussions at Abecedaria and Language Hat.]
Can You Tell a DVD by Its Publisher?
I went to the video store last night and discovered that there is a DVD out entitled The Origins of the Da Vinci Code. It claims to provide the factual background to Dan Brown's much-derided thriller, complete with a video tour of Rennes-le-Château guided by Henry Lincoln, author of Holy Blood, Holy Grail. The publisher is listed on the cover as "The Disinformation Company"! No kidding. Check out the link above. It's to the Disinformation Store web site. What would Harvard symbologist Robert Langdon make of that?
Trembling to be wrong
What do you call it when someone repeats a short phrase-initial word over and over again, like "a- a- a safe haven for Al Qaeda"? Stuttering?
Not according to Peter Howell, "Assessment of Some Contemporary Theories of Stuttering that Apply to Spontaneous Speech", Contemporary Issues in Communication Science and Disorders, vol. 31, pp. 122-139, 2004, who writes that
Failures in the normal mode of interaction between the [planning] and [execution] processes can lead to fluency failures when plans are too late in being supplied to the motor system. Generically, “fluency failure” arises whenever there is this underlying problem but ... there are two distinct types of responses available to the speaker in these circumstances. These are (a) whole function word repetition and hesitation (referred to here as disfluency), and (b) problems on parts of content words (a feature mainly seen in persistent stuttering).
Howell points out that this way of thinking makes sense of the fact that phrase-initial function words are often repeated, while phrase-final ones rarely are:
... If there is a sequence of simple words followed by a complex one, planning and execution of the simple words will both be rapid. At conjunction points, during the short time that the last simple word is being executed, the complex word that follows needs to be planned. The short execution time only allows a short planning time, but the complex word requires a long planning time. There will thus be an increased chance of fluency failure at this point. ...
For example, "we confirmed it" is much more likely to become "we- we confirmed it" than "we confirmed it- it."
Howell also suggests that "function word repetition and hesitation", although types of disfluency, "are associated with fluent speech control", and are both commoner and less disruptive of normal communication than stuttering is.
Indeed, disfluency of this sort is common even in the spontaneous or semi-scripted speech of professional "talking heads". For example, in Jim Leher's 12/16/2005 interview of George W. Bush, one of Lehrer's questions begins [ 20:16, audio]
The [pause] public opinion polls show that you are losing ((in-)) the- the confidence of the American people, in the way you're [pause] been conducting the war. Do you think ...
There are two pauses and one function-word repetition, each after a phrase-initial specifier. This is consistent with Howell's general approach, but several interesting aspects of the distribution of such disfluencies remain to be accounted for.
For instance, it's not entirely plausible that Lehrer is having trouble thinking of public as the second word in a question about "public opinion polls", nor does it seem likely that he needs extra time to devise its motor plan. Perhaps this pause is really staged for effect, to emphasize the noun phrase that follows by setting it off with an initial silence; or perhaps the whole phrase is queued up and ready to go, but there's a genuine difficulty in producing public while continuing to inhibit polls for a little while longer.
The pause after you're seems to reflect a genuine planning glitch, in which "you're conducting" and "you've been conducting" are in competition, and what emerges is a blend of the two. This is the kind of commonplace production error that (unfairly in my opinion) sometimes makes it into Jacob Weisberg's Bushisms column in Slate.
The Lehrer quote brings up another question for which I don't think anyone has a good answer at present: why do some "fluency failures" result in repetitions, while others result in silent pauses or "filled pauses" (e.g. uh and um)? There's been some interesting research (by Herb Clark, Jean Fox Tree and others, referenced here, here and here) suggesting that filled pauses and some other speech-production variants act in many ways rather like ordinary lexical items.
One common-sense factor that hasn't been featured in such research is stress. Not lexical or prosodic stress, but psychological stress, and in particular the stress associated with intense worry about saying the wrong thing. It's a commonplace of folk psychology that the response to being asked an embarassing question, or being caught in an apparent contradiction, is to sweat and stammer. Certainly politicians seem to experience higher-than-normal rates of disfluency when they're asked a question that requires them to navigate a narrow rhetorical passage between the Scylla of truth and the Charybdis of political constraint. As Byron wrote about a court poet,
He toils through all, still trembling to be wrong:
For fear some noble thoughts, like heavenly rebels,
Should rise up in high treason to his brain,
He sings, as the Athenian spoke, with pebbles
In's mouth, lest Truth should stammer through his strain.
I cited some examples of this effect in one of Bill Clinton's town meetings.
OK, having established that all God's children are often disfluent, and having put this fact in psycholinguistic and rhetorical context, I can safely expose the few of you who are still reading this to a sample of the truly spectacular specimens of initial-repetition disfluency on George W. Bush's side of the 12/16/2005 interview with Jim Lehrer:
[1:29, audio] I- I- we- we- we- we don't talk about sources and methods
[8:43.7, audio] At one point in time, if- if I'm not mistaken, looked like they- the- the- the- the- the- democracy was in the balance
[10:11.6, audio] so that political people can use police forces to [pause] seek retribution uh in i- i- i- in society
[11:26.3, audio] and- uh and- and- look we- we- and- and- and- by the way
[12:00.4, audio] Yeah, it's- it's- it's- the biggest priority is winning.
[17:53, audio] that's what- that's- that's what people- I think- I've always known that ...
[21:46.5, audio] He ju- I- I- I- I'm worried about a theocracy. [Lehrer says "yeah" three times in the background]
[24:42, audio] Yeah. It's a- it's a- it's a- it's a- it's b- belief in the system,
[26:05, audio] I- I- I- and- I- dealing with John McCain is not ((a-)) [pause] a- a reluctant adventure for me, I enjoy it.
If you look at that contexts of those passages, I think you can sense a connection between the degree of stress induced by the topic and the amount of disfluency. Unfortunately, I can't specify any political stress-o-meter that would let us quantify this in a non-circular way.
In the same interview, there are several examples of a rather different kind of phrase-initial disfluency, which for want of a more technical term might be called "muttering". For example:
[20:27.1, audio] {breath} ((I've be- oh look I mean heh)) {breath} uh
And finally, a bravura display of hesitations, repetitions and corrections, ending with a lovely example of ironic overarticulation:
[19:25.9, audio]
One thing Charles Duelfer did find --
is- he's the in-
uh the i- i-
the guy went in to look for weapons,
the- the uh-
{breath}
um
the-
the-
weapons inspector inspector {heh}
It's probably not an accident that the British games we Americans have borrowed don't include Just a Minute.
December 19, 2005
Euphemism of the week
In a 12/16/2005 PBS interview with Jim Lehrer, President Bush answered a question about Gulf Coast housing issues by saying, in part [audio link]:
More people are able to get back to Mississippi than
to New Orleans right now
because there's not a lot of trailers there, and so
we're working through the housing issues,
providing- making sure people know there's temporary help
to continue uh uh
their status as a p-
((you know)) somebody not home
I imagine him running through the alternatives in his mind, looking for one that won't be offensive, before finally settling on a somewhat lame paraphrase -- with that little intonational shrug at the end.
December 17, 2005
Judging a Book by Its Cover
According to British statistician Atai Winkler, the likelihood of a novel's success can be predicted with about 70% accuracy by a simple analysis of its title, reports the Vancouver Sun. You can try out a computer program that implements his algorithm. I tried it on a few titles, a number of which, to be fair, are not the titles of novels.
| The Da Vinci Code | 10.2% |
| Guns, Germs, and Steel | 10.2% |
| Lincoln's Doctor's Dog | 14.6% |
| Debbie Does Dallas | 14.6% |
| War and Peace | 31.7% |
| Jaws | 35.9% |
| Principia Mathematica | 37.0% |
| The Tale of Genji | 41.4% |
| The Cambridge Grammar of the English Language | 41.4% |
| The Sound Pattern of English | 41.4% |
| The Way of Analysis | 41.4% |
| Southern Cross | 41.4% |
| Gone with the Wind | 44.2% |
| Rising Sun | 55.4% |
| Roots | 63.7% |
Geoff Pullum will no doubt be delighted to see that his grammar's chances are markedly better than those of The Da Vinci Code, but disappointed that it isn't quite up there with Gone with the Wind. On the other hand, I am disappointed that Guns, Germs and Steel doesn't score higher. I like the title and the book. None of my examples get close to Winkler's best scorer: Agatha Christie's Sleeping Murder at 83%.
The article doesn't explain what factors contribute to success, but one could figure them out by experimenting with the web interface.
Up against the wall, Marshalls shopper
 Jim Hanas thinks that "Marshalls Law" might not be an appropriate theme for a retail advertising campaign. But the responsible ad agency promises "a Big BANG! ... that enables a brand to explode into the marketplace", and who can provide a bigger bang than the armed forces? The actual laws in the ad copy are pretty wimpy, but a little editing would fix them: "You don't need
Jim Hanas thinks that "Marshalls Law" might not be an appropriate theme for a retail advertising campaign. But the responsible ad agency promises "a Big BANG! ... that enables a brand to explode into the marketplace", and who can provide a bigger bang than the armed forces? The actual laws in the ad copy are pretty wimpy, but a little editing would fix them: "You don't need mistletoe an M-16 to get your hands on something cute"; "The best way to hint at what you want, is to
buy one for yourself convene a military tribunal"; "If you don't save on gourmet holiday cookware, your goose is
cooked subject to extraordinary rendition".
The real shocker, according to Jim, is that this campaign echoes the now-forgotten events of March, 1999 in France, when
In response to weeks of rioting and panic in the streets of France’s major cities, French Premier Jacques Chirac declared a state of Marshalls law yesterday. The measure, which Chirac says was necessary to prevent anarchy in the economically and existentially troubled nation, is the first time that the French government has declared a state of emergency modeled on an American discount apparel retailer. ...
"All constitutional civil liberties are hereby suspended in France," he said. "In this, our time of utmost emergency, we will be governed by only a single precept: the availability of brand-name family apparel, giftware, domestics and accessories, at much lower prices than you’d pay at department stores."
[Update: Lane Greene points out that the Weekly Week's joke is weakly weakened, if not entirely spoiled, by the fact that France doesn't really have an office appropriately translated in English as "premier". The closest thing is the "prime minister", which Jacques Chirac was in the 70's and again in the 80's. In 1999 he was the president, as he has been since 1995. In 1999, the prime minister was Lionel Jospin.
Of course, this is the same article that tells us that
In the 1990s, two factors have indelibly altered the landscape of France and placed it on shaky footing as a nation. The first is its devastated economy, with little to no growth and an unemployment rate that has hovered around 20%. The second is the realization that they have no actual language but are merely saying the phrase "Je be de" in different intonations, pretending that they understand each other in accordance with a centuries-old unwritten pact. ("I like the 'English', with the actual words," said one Paris resident.)
]
December 16, 2005
... working the control yoke with his toes
The Fellowship of the Predicative Adjunct welcomes another journalistic gem to its collection. This one is from an article in The Sun:
And despite being restrained with plastic handcuffs, the pilot decided he had no choice but to divert the 777 jet to Bermuda.
The headline reads "Mile high fight club pair", and the context (from the start of the article) is
A COUPLE caught bonking in the loo of a holiday jet forced the captain to make an emergency landing after they flew into a drunken rage.
Stunned passengers watched in horror as the randy couple attacked cabin crew after being told to return to their seats.
They shouted abuse and spat as they grappled with the British Airways staff who forced them back into their business class seats.And despite being restrained with plastic handcuffs, the pilot decided he had no choice but to divert the 777 jet to Bermuda.
The article ends by telling us that
... the duo, of Luton, Beds, face being charged with air rage ...
Is there really such a crime in British law?
[Story first noted by Chuck at To Be Determined.]
Is there any gobbledegook?
I'm not even sure that Mr Morgan's sentence "The only thing which isn't up for grabs is no change and I think it's fair to say it's all to play for, except for no change" is "cliché-ridden" (see previous post). It contains two idioms meaning something like "open and available for consideration or negotiation": up for grabs and to play for. Another idiom with this meaning is on the table. He's saying that the one thing that is not on the table for discussion or negotiation is to simply continue without change. That is one hundred percent clear. And although it uses three tokens of two idioms, does that make it cliché-ridden?
Are there some among us whose speech never contains common idioms? Should we even try to speak in a way that never contains common idioms? Wouldn't that (by definition) involve speaking in a way that didn't really sound very much like being an English speaker at all?
The fact is, the Plain English Campaign has been so unrelievedly ineffective in its efforts to find examples of administrative gobbledegook from public officials that one is forced to wonder: is there any gobbledegook? Or are our public officials and political leaders doing a remarkable job, under often stressful circumstances (like talking to a roomful of baying reporters all hoping that you'll say something newsworthily stupid), and broadly using their native language fairly well, to communicate with us in a moderately clear way?
If there were really instances of officalese and gobbledegook being perpetrated by public servants all the time, you'd think the Plain English Campaign might, after looking for them all year, be able to find some. Could it possibly be that the Plain English Campaign is a bunch of pompous turkeys who don't really have very much to say as regards linguistic critique, because there isn't much gobbledegook around, and what little there might be they aren't very good at spotting? Could it? I ask merely for information.
December 15, 2005
No ideas, please, we're the Plain English Campaign
Well, the frost is on the punkin and the fodder's in the shock, and you hear the kyouck and gobble of the Plain English Campaign's annual award for gobbledegook. This time, we'll let Oliver Kamm comment:
The winner was the Welsh First Minister, Rhodri Morgan, for stating: “The only thing which isn’t up for grabs is no change and I think it’s fair to say it’s all to play for, except for no change.” It is Mr Morgan’s second award; the first was in 1998 for asking: “Do one-legged ducks swim in circles?”
Yet, while Mr Morgan’s winning entry is cliché-ridden, it is not gobbledegook. It is a statement, comprehensible on first reading, that many outcomes are possible, excepting only stasis. Likewise, Mr Morgan’s comment about ducks, in context, is a clear and arresting metaphor. Had Mr Morgan used the hackneyed equivalent phrase about ursine toilet habits, the Plain English Campaign would have taken no notice.
Every year undeserved attention is paid to a group that might more accurately be called the Obscurantism Organisation. Its gobbledegook award is not about English usage so much as a populist suspicion of ideas.
Kamm quotes Geoff Pullum's critique of the 2003 award to Donald Rumsfeld, and cites additional evidence that the P.E.C. awards committee can neither read nor think:
Gordon Brown, when Shadow Chancellor, won for a speech about “post-neoclassical endogenous growth theory”. This is not gobbledegook either. All disciplines have terms that are valuable shorthand for specialists. Endogenous growth theory is an important branch of economics, and if you know what “endogenous” means, you can make an informed guess about its subject matter.
And there's more, as Kamm explains in a note added later:
A prominent political journalist writes to say that the Gordon Brown remarks are an even worse case for the Obscurantists to cite than I had given credit for. He listened to the speech in 1994, and recalls that Brown remarked that "post-neoclassical endogeous growth theory" was not the stuff of soundbites, i.e. it was a self-mocking reference...
At this time of year, I guess that journalists are happy to scarf up press releases from groups like the P.E.C. And I shouldn't complain, because the P.E.C. has managed to play us for suckers, after our own fashion: look at all the Language Log posts these know-nothings have incited:
Baffling award of the year, again (12/7/2004)
The poetry of Donald Rumsfeld and other fresh American art songs (5/29/2004)
Stone the crows (5/25/2004)
Diamond geezer? (4/25/2004)
Irritating cliches? Get a life (4/25/2004)
Fed up with "fed up"? (4/24/2004)
Economist follows Language Log (12/7/2003)
No foot in mouth (12/2/2003)
Clear Thinking Campaign gives "fogged spectacles" award to John Lister (12/2/2003)
[Update: The post that I originally linked to on Oliver Kamm's web site is not available there at the moment. Most of it can be found here, in his 12/15/2005 Times column. That column of course omits Kamm's weblog post scriptum that included the link to Geoff Pullum's Language Log post, and the note about the context of Gordon Brown's remarks. Kamm's website was entirely unavailable for a while, and now is back with entries only through 12/9/2005 -- perhaps a disk failure and recovery from back-ups? ]
[Update 1217/2005: Kamm's site, or at least the relevant link, is back up./
Lundin calling
Among the many seasonal party invitations that I've gotten recently was one with an attached .jpg that read
HOLIDAY LUNDIN
with <ORGANIZATION>
<DATE>, <TIME>
<LOCATION>
amid a seasonally appropriate pattern of snowflakes and such. I did a double-take on "lundin" -- was it a typo for "luncheon"? some sort of Cajun religious festival in honor of the reconstruction of New Orleans? I was lexically lost, so I tried a Google search, which turns up more than 2 million hits for lundin, but nothing on the first couple of pages was helpful. Searching for {"holiday lundin"} didn't make it any better. The OED has nothing at all. I asked the host, and learned that it's a blend of lunch and dinner. So that's my new word for the week.
Uptalk uptick?
People have reacted to President George W. Bush's recent series of speeches on Iraq in generally predictable ways. Andrew Sullivan is pleased:
Something remarkable has been going on these past few weeks. The president has begun to be a real war-leader. He is conceding mistakes, he is preparing people for bad news, he is leveling with the American people, he is taking questions from audiences who aren't pre-selected or rehearsed. Some of us have been begging him to do this for, er, years. Now that he is, his ratings are nudging up.
Others, unsurprisingly, are not as enthusiastic. This being Language Log, I'll focus on something that other commentators have missed: an apparent uptick in presidential uptalk.
In his 12/12/2005 speech at the Philadelphia World Affairs Council (transcript and video stream at the White House web site), the president leads with 18 seconds of phrases with final rises :
Thank you. Thanks for the warm welcome / Thank you for the chance to come and speak to the - Philadelphia World Affairs Council. / This is an important organization that has uh since 1949, has provided a[@C] forum for debate / and discussion on important issues. /
To be more precise, his phrase-final pitch contours range from slightly falling, to level, to sharply rising. All are within the range of what would called "uptalk" if produced by a young woman from the San Fernando Valley -- though in fact this pattern has always been widely distributed among American regions, classes and sexes:
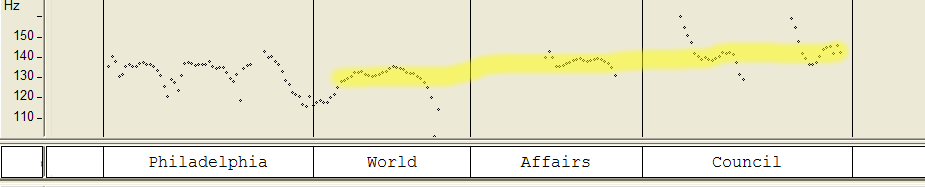

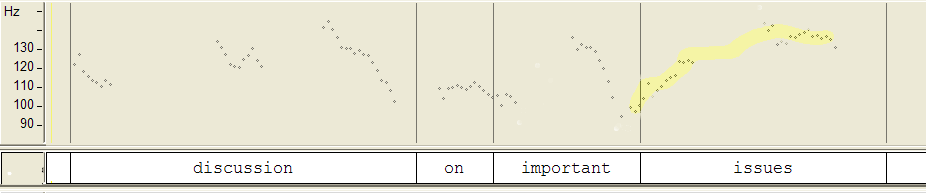
The president then switches to a few phrases ending with the intonational falls that are more normal in his speeches (audio clip):
I've come to discuss an issue - that's really important, \ and that is victory in the war on terror. \ And that war started on September the 11th, 2001, \ when our nation awoke to a[@C] sudden attack. \ Like generations before us, we have accepted new responsibilities, \ confronting dangers with new resolve. \
Then he deploys a few up/down alternations -- a common rhetorical pattern:
We're taking the fight to those who attacked us / and to those who share their murderous vision for future attacks. \ We will fight this war without wavering, / and we'll prevail. \ The war on terror will take many turns, and the enemy must be defeated on many b- - on- on every battlefield, from the \ streets of Western cities to the mountains of Afghanistan, to the tribal regions of Pakistan,- to the islands of Southeast Asia and to the Horn of Africa. \ Yet the terrorists have made it clear that Iraq / is the central front in their war against humanity, \ so we must recognize Iraq is the central front - in the war on terror. \
And then comes the part that caught my attention: 43 seconds of relentless uptalk (audio clip):
Last month, my administration released a[@C] document called - the "National Strategy for Victory in Iraq" / and in recent weeks I've been discussing our strategy with the American people. / At the U.S. Naval Academy, I spoke about our efforts to defeat the terrorists / and train Iraqi security forces so they can provide safety for their own citizens. / Last week before the Council on Foreign Relations, / I explained how we are working with Iraqi forces / and Iraqi leaders / to help Iraqis improve security and restore order, / to rebuild cities taken from the enemy, / and to help the national government revitalize Iraq's infrastructure and economy. /
To highlight the prosodic issues here, consider the difference in sound -- and in the appearance of pitch tracks -- between the up-talk rendition of "economy" at the end of the passage quoted above, and a final-falling version of the same word in the middle of a sentence later in the same speech (audio clip):
On the economic side, / we're helping the Iraqis restore their infrastructure, \ reform their economy, \ and build the prosperity that will give all Iraqis a stake \ in a free and peaceful Iraq. \

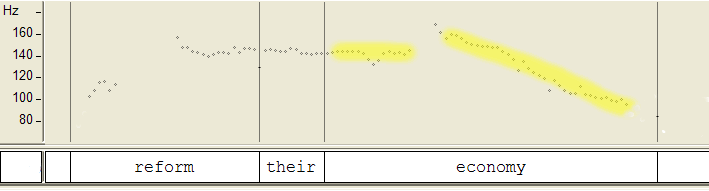
Although I haven't checked this systematically, I've listened to quite a few of President Bush's speeches, and the long stretches of uptalk in this speech strikes me as a very unusual pattern for him.
What does it mean? Why did President Bush use final rises so often in (certain parts of) this speech? And in this speech, why does he use final rises on some phrases, and falls on others? Listen to the speech, and think about it for yourself. I'll explain my own evaluation in another post.
[For a hint about one aspect of the answer, read this.]
[Other Language Log "uptalk" posts:
This is, like, such total crap? (5/15/2005)
Angry Rises (2/11/2006)
Further thoughts on "the Affect" (3/22/2006)
Uptalk is not HRT (3/28/2006)
]
December 14, 2005
The Bilabial Trill Has Had Its Moment
There is a small error in the New York Times article on the addition of a symbol for the labiodental flap to the International Phonetic Alphabet that Geoff mentioned: the bilabial trill does not still await its day. Actually, it has been in the IPA for many years. I've drawn a circle around it below:
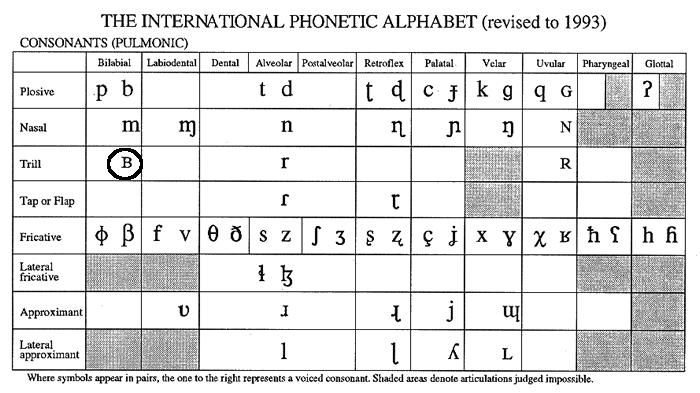
That's U+0299 in Unicode, like this: ʙ. The bilabial trill is better known in the United States as the "Bronx cheer". It isn't very common, but it does enliven phonetics classes.
The sound that has yet to receive an official symbol is a "voiceless bilabial trill preceded by a dental stop, forming a single unit". It is not presently known with which borough of New York, if any, this sound is associated.
December 13, 2005
From TV to text, Part 1

The Google Foundation recently announced an intriguing philanthropic partnership with an organization called PlanetRead, designed to improve literacy levels in India. As described on the official Google Blog, PlanetRead's goal is to increase literacy by means of "Same-Language Subtitling" (SLS), which provides on-screen subtitles for television programming. So far, PlanetRead has focused primarily on subtitling music videos for songs in various Indian languages, with text streaming across the bottom of the screen karaoke-style. As the organization's president Dr. Brij Kothari explains in the blog entry, SLS is a cost-effective method of providing reading practice for more than 200 million "early-literates" in India, most of whom live in poverty.
Google has provided PlanetRead with a grant to support SLS programs and is also hosting content via Google Video, a Google Labs project that is still in beta testing. So far the PlanetRead videos hosted by Google are limited to a handful of samples, consisting of some newly composed Telugu folk songs (with Telugu subtitles in both Indic script and Roman transliteration, as well as a running English translation) and clips of Bollywood musical numbers (Hindi subtitles only, in Indic script). Somewhat surprisingly, Google Video does not allow searching on the subtitles of these videos (regardless of the language or script), only on the accompanying descriptive text. That's a shame, as it would be great for researchers to have access to such multilingual text samples — a linguistic fringe benefit to an admirable philanthropic endeavor.
The lack of searchability on the PlanetRead subtitles would seem to
go against Google's aim of maximizing the global search. But Google
Video only indexes text that is provided to them in the form of metadata. An earlier
version of Google Video included screen shots of U.S. television
programming with searchable closed-captioning transcripts, but they
have evidently removed all of the TV material from their database due
to rights issues (even though the About Google Video
page still acts as if the TV screen shots and transcripts are available). As Google Video director Jennifer Feikin recently discussed
at a Silicon Valley conference, the video project has moved on to a new
phase, relying entirely on user-provided video content (and metadata).
There are hints
that Google Video will soon begin offering commercial video content
from TV and elsewhere, but the company seems mainly concerned these days
with figuring out how to charge people for viewable content. Under such a scheme, searchable closed captioning might at least be offered as an enticement
to get people to pay for content, as long as the snippets of
transcripts are considered "fair use" (mirroring some of the controversy
involving the Library Program of Google
Book Search, formerly Google Print).
If Google Video eventually brings back searchable transcripts of closed-captioned TV shows (from the US or other countries), it would be a fascinating addition to the field of Googlinguistics. Granted, snippets of closed captioning wouldn't provide anywhere near the transcriptional precision that one might expect from data collected by researchers of spoken interaction, such as the corpus of telephone conversations compiled by the Linguistic Data Consortium. But as we've seen with Googlinguistics more generally, sheer quantity of data can sometimes overcome shortcomings in quality. Just as Google searches can yield a rich variety of written texts from the most formal to the most informal registers, so too could a database of closed-captioning transcripts illuminate a broad cross-section of mass-mediated discourse, from scripted dramas to celebrity interviews to the more free-and-easy conversational exchanges seen on American shows presided over by the likes of Jerry Springer or Judge Judy. And as long as the corresponding video clips are easily accessible, even inaccurate or limited transcriptions can serve as a rough guide for pinpointing relevant stretches of discourse to analyze.
Ultimately, one of Google's competitors may step up to the plate first and make TV clips with closed-captioning transcripts widely available. Yahoo Video Search could very well take the lead, if the recently announced partnership between Yahoo and Tivo is any indication. Currently another Internet player is exploring this market: Blinkx, one of Time Magazine's "50 coolest websites of 2005." Blinkx pulls together a wide variety of clips from TV shows (not just American ones), and does its own indexing — not with closed captioning but via some in-house speech-recognition technology (details here). Blinkx also indexes podcasts, but they may be losing that territory to podcast-specific search engines using speech-to-text automation such as Podzinger and Podscope. See this AP article for a comparison of Blinkx, Podzinger, and Podscope, and see Part 2 of this post for some fun with Blinkx transcriptions.
From TV to text, Part 2
I thought I'd try out Blinkx to see if the transcriptions it creates for searching video clips might have any value for linguistic research. So far, it looks like the television transcripts are more valuable as evidence of how far the company's automated speech-to-text technology still has to go. I took a look at four snippets of transcripts (two from US-based FOX News and two from UK-based GMTV), which I happened to discover while searching on terms of interest to me and finding false matches.
A search on Malaysia, for instance, turns up this transcript snippet from FOX News, Oct. 25, 2005:
the conviction idea my principal is getting very bad this sort of not Malaysia but this sordid tale the feeling in Washington
A look at the video reveals that this comes from an interview with Sen. Bill Frist on "Hannity & Colmes." Here's the relevant section of the transcript as it appears on the Nexis news database:
Right now there's not a lot on offense, leading by conviction, by idea, by principle. It's getting buried by this sort of, not malaise, but this sort of down feeling in Washington.
Lining up the transcripts, we get this unit-by-unit comparison:
[right now there's not a lot on offense leading] by conviction by idea by principle
the conviction
idea
my
principal
it's getting buried by this sort of not malaise is getting very bad this sort of not Malaysia
but this sort of down
feeling in Washington but this sordid tale the feeling in Washington
This example has an error rate comparable to many of the transcriptions I've seen from Blinkx. We can see that speech-recognition errors often emerge due to quasi-homonymic pairs (malaise-Malaysia, sort of-sordid). Other errors stem from the software's reliance on collocational data — for instance, the transcription follows sordid with tale, which appears to be nothing more than a hunch based on the frequency of the collocation sordid tale.
Frist's speech is relatively measured and proceeds without
interruption from the interviewers. We would naturally expect a higher
error rate for speech that is rapid, overlapping, or indistinct. Here's
a more muddled example from FOX News, Dec. 3, 2005:
no one should not we should be cutting education likely of people in his mind and a shock to the ballot identify cardiac arrest and taken from Malaysia to a town in shock everybody clear
In the video we see that this is taken from a demonstration of a home defibrillator by Ed Stapleton of the American Heart Association. Stapleton is explaining how to use the defibrillator as recorded instructions issue from the device (indicated in italics):
Here is how the transcriptions line up:No one should touch the patient.
Nobody should be touching the patient. I'd clear people at this point.
Analyzing. Shock advised.
Now it's identified cardiac arrest, ventricular defibrillation. It will tell me to shock. Everybody clear.
no one should touch the patient
nobody should be touching the patient no one should
not we should be cutting education
analyzing shock advised I'd clear people at this point
likely of people in his mind and a shock to the
now it's identified cardiac arrest ventricular defibrillation
ballot identify cardiac arrest and taken from Malaysia
it will tell me to shock everybody clear
to a town in
shock everybody clear
The error rate is predictably higher here, and we also see some
runaway collocational guesswork going on, with "...ventricular
defibrillation. It will tell me..."
getting transformed into "...and taken from Malaysia to a town in...".
Next let's turn to the two GMTV examples. (I collected these last
week, but now it appears that GMTV's transcript snippets are no longer
displayed in the Blinkx search results, replaced instead by descriptions of
the videos. The video clips will still appear when words in the
transcript text are searched on, though now one needs to play the clip
to determine if a particular match is false or not.) The first video
is an interview with the American recording artist John Legend on Sep. 1, 2005,
which includes this
exchange about his album "Get Lifted":
GM: Oh it's just lovely. I think it's good music for the whole time. There's just been a resurgence of real music, hasn't there, lately?
JL: A little bit, yeah.
GM: Well certainly in this country anyway. "Get Lifted" has sold millions everywhere...
Here is how the actual transcript compares with a snippet that
Blinkx provided last week:
oh it's just lovely I think it's good music
for the whole time
see him about his kidney
for the whole time
there's just been a resurgence of real music hasn't there lately this has been a resurgence of real music as a Malay
a little bit yeah well certainly in this country anyway
I'm a bit here whatsoever in this country anyway
Get Lifted has sold millions everywhere
get the lift it has sold millions everywhere
There are decent stretches in this example, though the whole thing is
rather undermined by the inexplicable transmogrification of "Oh it's
just
lovely, I think, it's good music..." into "See him about his kidney."
Finally, here is an excerpt from a GMTV interview with Emma Thompson about her movie Nanny McPhee, broadcast on Oct. 18, 2005:
ET: Cos you know what it was, her great-grandfather used to make up stories about her naughtiness when she was little, and then she wrote it into this kind of made up, he'd made up this awful, dreadful-looking nanny.
GM: Nurse Matilda.
ET: Called Nurse Matilda, exactly, and we changed that for obvious reasons...
And here is the comparison with the Blinkx snippet:
[her great-grandfather used to make up stories about her naughtiness when she was little]
and then she wrote it into this kind of made up Valenti rate here into this camp is made up
he'd made up this awful
dreadful looking nanny he'd made up of all four were dreadful looking man he
Nurse Matilda
called Nurse Matilda exactly
knew LASIK lawyer called natural hair day factory
and we changed that for obvious reasons
we save that for obvious reasons
Again, reliable bits of transcription are undercut by bizarre transformations. "Nurse Matilda" first turns into "knew LASIK lawyer" and then moments later becomes "natural hair day." It's possible that the speech-recognition software used by Blinkx has been trained to work more effectively on U.S. accents, increasing the error rate when transcribing the speech of U.K. speakers.
In the AP article I mentioned in Part 1 of this post, one of the founders of Blinkx acknowledged the limitations of their speech-recognition technology but remained optimistic about future progress:
The good news for speech-to-text services is that they might improve with use. That's partly because the engines can learn better ways to determine words from their context.
Blinkx co-founder Suranga Chandratillake illustrates the process this way: If a podcast were made about the topics in this story, a computer probably would be right if it detected the phrase "recognize speech."
But in a podcast about last year's tsunami, the computer would do better to hear almost the same sounds as "wreck a nice beach."
For now, if nothing else, the automated transcriptions provided by Blinkx are at least good for some comic relief.
Linguistics hot this week
New symbols are not added to the International Phonetic Association's alphabet very often, but the Association has just agreed to include a new symbol for writing a curious labiodental flap sound that is moderately common in African languages though just about unheard of outside that continent. Michael Erard has just made this into a big New York Timesworthy story.
Linguistics is having a big week, in fact, because in addition the latest Science News has a big cover story taking up the whole of the center pages of vol. 168, no. 24 (December 10, 2005), pp.376-377, about Daniel and Keren Everett's researches on the Pirahã. Is linguistics ever hot.
December 12, 2005
Instant boilerplate email reply key
In recent weeks my email from Language Log readers has involved certain specific topics so frequently that I am finding I have to send out huge numbers of replies that are almost identical. In order to save bandwidth and typing time, I am preparing standardized replies to the points that are most frequently put to me in emails, and I list them here. I hope in future to be able to just write back and say "See my boilerplate reply #3" or something like that, and you will be able to look up the full courteous reply here. I hope that's all right. Here are the first five standardized answers, each of which contains material I have had to send to readers over and over again. Where there are passages in curly brackets, please strike out what is not applicable.
Reply #1. Dear _____: Yes, it is fairly clear that the solution to the puzzle of why *If you don't yet know her, get to is ungrammatical is that ‘get to know NP’ is an idiom; its meaning ("become acquainted with NP") is not fully predictable from the meanings of its parts, and it strongly resists being syntactically broken up. Chris Culy points out that there is other evidence: when you negate it, you can only negate the whole thing: I didn't get to know her while I was there is grammatical but *I got not to know her while I was there is ungrammatical. (Compare with I didn't try to look interested and I tried not to look interested, both of which are OK.) So you are right in pointing out the idiomaticity; I agree with you. Thank you for your message.
Reply #2. Dear _____: I am grateful to have your interesting reminiscences of working in an {ice cream parlor / fast food joint / coffee shop / bookstore / venereal disease clinic} some {five / ten / fifteen} years ago in the {northeast / midwest / west} of the country and finding that you fell into the practice of saying Can I help who's next? even though you thought at the time it was not grammatical. (The largest number of emails in this that I have had comes from the upper Midwest; it reallly does look like it might have come into being in the Michigan area in the late 1980s, though one never really knows.) I guess your use of it despite reluctance just goes to show the force of the social pressure that they used to measure with those social psychology experiments where you sit with (unknown to you) four accomplices of the researcher and listen to a bell sound five times and everyone else says it was six and you go along with them even though you were quite sure it was only five. We like to think that we would stand firm and say "No, it was five." But the empirical evidence says we would not. Gullible and easily led social mammals that we are.
Reply #3. Dear _____: Thank you for your kind words; I'm glad you liked my posts about {The Da Vinci Code / Angels and Demons / Deception Point / Digital Fortress}. I guess I'm not going to be able to sell my old used copies of Dan Brown novels to you, am I? (Grin.)
Reply #4. Dear _____: No, I'm afraid I cannot tell you how Mark Liberman manages to post so many interesting things when there are only 24 hours in a day. I have absolutely no clue about this. I have hung around outside his office at 1 Language Log Plaza and watched him work, and he concentrates pretty hard, but he types at about the same speed as an average person, and takes phone calls, and gets up now and then to get more coffee. He probably puts his pants on one leg at a time like anyone else, I would think (I've never had occasion to watch that). So I'm unable to help you. Contrary to your speculation, I do not think that any deal with the devil is involved; the Language Log Board does not permit assigning one's soul to Satan; there is a no-compete clause in our contracts.
Reply #5. Dear _____: I am so glad you like the picture on my personal web site, and I am flattered by your suggestion; it arouses my interest, and more besides. But unfortunately here at Language Log we have strict ethical guidelines that forbid any more intimate relationship with our readers than the one inherent in the blogger/bloggee bond. Either you would have to absolutely promise to stop reading Language Log, or I would have to stop writing for it and leave Language Log Plaza; but strict corporation rules forbid my embarking on a relationship with you that is of anything like the kind you suggest. I'm sorry, but rules are rules. That oral stuff was hot, though. Tell me a bit more about that. By the way, I'm typing this naked.
Like a rolling stone
From this NYT article on the filming in Los Angeles of Oliver Stone's movie-in-progress about the events of 9/11 in New York:
"Obviously, not to do it in New York was crucial, because it would offend the sensibilities of some New Yorkers," said Mr. Stone, who is one himself.
(From the Fun With Binding Bureau at Language Log Plaza. Don't try it at home with your own anaphora -- only under linguistic supervision,
[ Update: Language Log has clearly gotten too serious for some folks. The first comment on this post says:
in my opinion nothing about that quote is close to being weird enough to merit being a post to language log. stylish, but to me, fine. or is your point that it shouldn't be ok according to some theory, but still is?
I didn't feel like I needed to explain it, but here it is: Oliver Stone is either himself a New Yorker or ... a stone. Get it? ]
Je pense, donc je suis un lapin
 The first French telecommunications innovation since the Minitel is a WiFi rabbit, mysteriously named Nabaztag. It can produce sounds, move its ears and turn internal colored lights on and off. Apparently an accompanying application informs you about incoming email, the weather and so on, and also allows you to send an audio message (called a nabcast) to others. There is "an API you can use to directly adjust your rabbit's parameters: lightshows, ear position, TTS, music", so it can be nabhacked to do more interesting nabthings.
The first French telecommunications innovation since the Minitel is a WiFi rabbit, mysteriously named Nabaztag. It can produce sounds, move its ears and turn internal colored lights on and off. Apparently an accompanying application informs you about incoming email, the weather and so on, and also allows you to send an audio message (called a nabcast) to others. There is "an API you can use to directly adjust your rabbit's parameters: lightshows, ear position, TTS, music", so it can be nabhacked to do more interesting nabthings.
Comments in the Francoblogosphere are mostly enthusiastic froth:
Il vous en faut absolument un pour Noël !!!
J'ai ! J'ai !! J'ai !!!
Bon, si on en a un jtenverrai un ptit signe d'oreille lol!
and so on.
However, the French education system being as it is, someone of course has brought up Descartes:
Alors attends, c'est pas fini, tu peux aussi parler dans le lapin : "Le nabcast est disponible".
En gros, tu crée un Nabcast et tu peux parler de tout ce qui t’intérresse à la communauté des propriétaires de lapin.On est donc en présence d’un nouveau média physique qui s’enrichira de contenu auto produit tout comme le blog, qui est donc la représentation physique d’un blog.
Si le lapin est donc la représentation réelle d’un media virtuel, cela veut donc dire que grâce à lui je suis virtualisé dans la réalité. Je m’exprime à travers lui pour mes amis, ma présence réelle est donc virtualisée mais se représente dans le réel par un lapin, il faudrait donc changer Descartes, « je pense donc je suis un lapin »
But wait, there's more, you can talk in the rabbit: "The nabcast is available".
Basically, you create a Nabcast and you can talk about everything that interests you to the community of rabbit owners.We are thus in the presence of a new physical media [sic] which will be enriched by autonomously-produced content, just like blogs, which is thus the physical representation of a blog.
If the rabbit is thus the real representation of a virtual media, that means that thanks to it I am virtualized in reality. I express myself through it for my friends, my real presence is thus virtualized but represents itself in reality by means of a rabbit, [so that] we must therefore change Descartes, "I think, therefore I am a rabbit".
I predict an epidemic of WiFi animals in cubicles and on shelves and tables around the world. And I need to ask, has the first piece of nabspam already been transmitted?
[Note that the company needs a bit of copy-editing help -- the current nabaztaland page explains that
Nabcast is available ! At last ! You can also speak through every rabbit! What are you waiting for? Create your own Nabcast!! So that you can spaek for the hole community.
and
Nabaztag Directory !
Yep! You're seaking another rabbit to speak to, use our directory. The only one!
I'm glad to see that they've got the folks from fafblog writing their ad copy, however. But if this were dystopian SF...]
December 11, 2005
Rats beat Yalies: Doing better by getting less information?
Louis Menand's review of Philip Tetlock’s book “Expert Political Judgment" makes the point that in "more than a hundred studies that have pitted experts against statistical or actuarial formulas, ... the people either do no better than the formulas or do worse". Menand suggests that the experts' downfall "is exactly the trouble that all human beings have: we fall in love with our hunches, and we really, really hate to be wrong". Tetlock puts it like this (p. 40): "the refusal to accept the inevitability of error -- to acknowledge that some phenomena are irreducibly probabilistic -- can be harmful. Political observers ... look for patterns in random concatenations of events. They would do better by thinking less."
Tetlock illustrates this point with an anecdote about an experiment that "pitted the predictive abilities of a classroom of Yale undergraduates against those of a single Norwegian rat". The experiment involves predicting the availability of food in one arm of a T-shaped maze.The rat wins, by learning quickly that is should always head for the arm in which food is more commonly available -- betting on the maximum-likelihood outcome -- while the undergrads place their bets in more complicated ways, perhaps trying to find patterns in the sequence of trials. They guess correctly on individual trials less often than the rat does, although their overall allocation of guesses matches the relative probability of finding food the two arms very accurately.
This is a good story, and Tetlock's description of the facts is true, as far as it goes. But one crucial thing is omitted, and as a result, Tetlock's interpretation of the facts, repeated with some psychological embroidery by Menand, is entirely wrong. As usual, the true explanation is simpler as well as more interesting than the false one. It illustrates a beautifully simple mathematical model of learning and behavior, which accounts for a wide range of experimental and real-world data besides this classroom demonstration. And there's even a connection, I believe, to the cultural evolution of language.
The same experiments are described in a similar way (though with slightly different numbers) on pp. 351-352 of Randy Gallistel's wonderful book "The Organization of Learning" (which MIT Press has unconscionably allowed to remain out of print for many years). These experiments are examples of a paradigm called "probability learning" or "expected rate learning", in which the subject (human, rat or other) is asked to choose on each trial among two or more alternatives, where the reward and/or feedback is varied among the alternatives probabilistically.
Tetlock suggests that humans perform worse in this experiment because we have a higher-order, more abstract intelligence than rats do: "Human performance suffers [relative to the rat] because we are, deep down, deterministic thinkers with an aversion to probabilistic strategies... We insist on looking for order in random sequences." Menand, on the other hand, thinks it's just vanity:
The students looked for patterns of left-right placement, and ended up scoring only fifty-two per cent, an F. The rat, having no reputation to begin with, was not embarrassed about being wrong two out of every five tries. But Yale students, who do have reputations, searched for a hidden order in the sequence. They couldn’t deal with forty-per-cent error, so they ended up with almost fifty-per-cent error.
Tetlock may be right that we humans like deterministic explanations, at least as a rational reconstruction of our ideas. And Menand may be right about the anxieties of Yale students. However, both are entirely wrong about this experiment. It's not about the difference between humans and animals, or between Yalies and rats. It's about information. The students were given different information than the rat was, and each subject, human or animal, reacted according to its experience.
As Randy Gallistel, who helped run the experiments, explains:
They [the undergraduates] were greatly surprised to be shown when the demonstration was over that the rat's behavior was more intelligent than their own. We did not lessen their discomfiture by telling them that if the rat chose under the same conditions they did -- under a correction procedure whereby on every trial it ended up knowing which side was the rewarded side -- it too would match the relative frequencies of its initial side choices to the relative frequencies of the payoffs (Graff, Bullock, and Bitterman 1964; Sutherland and Mackintosh 1971, p. 406f).
And if the students had chosen under the same conditions as the rat, they too would have been "maximizers", zeroing in on the more-likely alternative and choosing it essentially all the time.
To see the trick, we have to start by describing the apparatus a little more carefully. On a randomly-selected 75% of the trials, the left-hand side of the T was "armed" with a food pellet; on the other 25% of the trials, the right-hand side was. (These are Gallistel's numbers -- Tetlock specifies 60%/40%.) On trials when the rat took the "armed" side of the maze, it was rewarded with a food pellet. Otherwise, it got nothing. But what about the students? Well, on top of each arm of the maze was a shielded light bulb, visible to the students but not to the rat. When the rat pressed the feeder bar, the light bulb over the armed feeder went on -- whether this was the side the rat chose, or not.
Why does this matter? Why does the extra feedback lead the students to choose a strategy that (in this case) makes worse predictions?
For an authoritative review of this overall area of research, find yourself a used copy of Gallistel's book. But here's a slightly oversimplified account of what's going on in this particular case.
We start with a version of the "linear operator model" of Bush & Mosteller 1951:
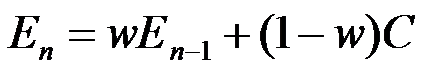
This equation tells us how to update the time-step n estimate En (of resource density, or event probability, etc.) as a function of the estimate at time n-1 and the current experience C. The update could hardly be simpler: it's just a linear combination (i.e. a weighted sum) of the previous estimate and the current experience. In this simplest version of the model, there's just one parameter, the memory constant w, which tells us how much to discount previous belief in favor of current experience.
Electrical engineers will recognize this as a "leaky integrator", a first-order recursive filter. Its impulse response is obviously just a decaying exponential. It can easily be implemented in biochemical as well as neural circuitry, so that I would expect to find analogs of this sort of learning even in bacteria.
To apply this model to the rat, we'll maintain two E's -- one estimating the probability that there will be a food pellet in the left-hand maze arm, and the other estimating the same thing for the right-hand arm. (The rat doesn't know that the alternatives are made exclusive by the experimenters.) And we'll assume the golden rule of expected rate learning, expressed by Gallistel as follows:
[W]hen confronted with a choice between alternatives that have different expected rates for the occurrence of some to-be-anticipated outcome, animals, human and otherwise, proportion their choices in accord with the relative expected rates…
On trials where the rat chooses correctly and gets a food pellet, the model's "current experience" C is 1 for the maze arm where the pellet was found, and 0 for the other arm. On trials where the rat chooses wrong and gets no reward, the "current experience" is 0 for both arms.
If we set the model's time-constant w=0.3, and put the food pellet on the left 75% of the time and on the right 25% of the time, and start the rat out with estimates of 0.5 on both sides, and have the rat choose randomly on each trial based on the ratio of its estimates for the "patch profitability" of the two sides, then the model's estimates will look like this:
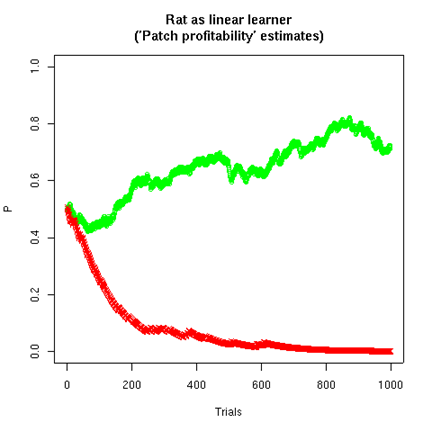
Note that the estimates for the two sides are not complementary. The estimate for the higher-rate side tends towards the true rate (here 75%). The estimate for the lower-rate side tends towards zero, because the (modeled) rat increasingly tends to choose the higher-rate side. If we plot the probabilities of choosing the two sides, based on the "patch profitability ratio" model, we can see that the model is learning to "maximize", i.e. to choose the higher-probability side.
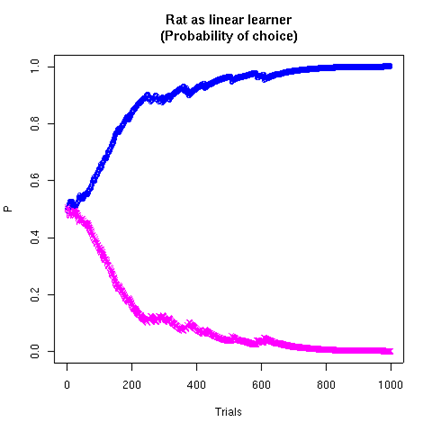
At the asymptotic point of choosing the left side all the time, the rat will be rewarded 75% of the time. (I suspect that rats actually learn faster than this model does, i.e. they act as if they have a lower value for w.)
To model the undergraduates, we use exactly the same model. However, the information coming in is different. On each trial, one of the two lights goes on, and therefore that side's estimate is updated based on a "current experience" of 1, while the other side's estimate is update based on a "current experience" of 0. Everything else is the same -- but the model's behavior is different:

The estimates for the two sides are complementary, and tend towards 0.75 and 0.25. Therefore the students' probability of choice also tends towards 0.75 for the left-hand side, and 0.25 for the right-hand side. Their overall probability of being correct will tend toward 0.75*0.75 + 0.25*0.25 = 0.625, i.e. 62.5%, which is lower than the rat's 75%.
So as it turns out, the rat and the students were arguably applying the same behavioral rule to the same sort of estimate of the situation, and using the same simple learning algorithm to derive that estimate. The difference was not their interest in deterministic theories, nor their concern for their reputations. The difference was simply that the students got more information than the rat did.
At least, there's a simple model that predicts the difference in those terms; and the predictions of that model are apparently confirmed by the results of many thousands of other published experiments in probability learning and expected rate learning.
But why does more information make for worse performance? We're used to seeing evolution develop optimal solutions to such basic problems as choosing where to look for food. So what's gone wrong here? If animals have accurate estimates of how much food is likely to be where -- however those estimates are learned -- then the rule of "[proportioning] their choices in accord with the relative expected rates" is the students' solution, not the rat's solution. The rule says to allocate your foraging time among the alternative locations in proportion to your estimate of the likely pay-off. That's what the students did. But the maximum-likelihood solution is to put all your chips on the option with the highest expected return -- what the rat did.
Did evolution screw up, then? No. In a situation of competition for resources, if everyone goes to the best feeding station, then that turns out not to be such a great choice after all. In that case, if you happen to be the only one who goes to the second-best place, you're in terrific shape. Of course, if lots of others have that idea too, then maybe you'd better check out the third-best. Overall, the best policy -- for you as an individual -- is to follow a strategy that says "allocate your foraging time probabilistically among the available alternatives, in proportion to your estimate of their profitability". At least, this is an evolutionarily stable strategy, "which if adopted by a population cannot be [successfully] invaded by any competing alternative strategy".
We often see a beautiful theory spoiled by an inconvenient eruption of fact. An honest investigator not only acknowledges this when it happens, but searches for such refutations, although no one should rejoice to find one. Here a good story is spoiled by a beautiful theory. That's a trade worth accepting cheerfully at any time.
This post is already too long, so I'll reserve for another day an account of how you can test this theory with a couple of loaves of stale bread and a flock of ducks. And then the really interesting part is how this same idea might help explain the emergence of linguistic norms and other shared cultural patterns. For a preview, if you're interested, you can take a look at a couple of versions of a talk I've given on this subject -- an html version from 2000, and a powerpoint version from 2005.
Elizabethan English: Undead in Appalachia?
The myth that pure Elizabethan English, as in Shakespearean English, is spoken in Appalachia lives on: I just heard it from a folklorist on NPR, who reported that isolated English settlers in Appalachia maintained Shakespeare's English -- an example, he claimed, of the nonchanging periphery of the spread of a tale or language variety, vs. its alteration in the place it came from, in this case Merrie Olde (16th-century) England.
Wrong, wrong, wrong. There are said to be features of Shakespeare's English that are preserved in Appalachian English but not in Standard English; but they would be noticeable only because they have vanished from Standard English. The many features of Shakespeare's English that remain in Standard English are not noticeable: they're just ordinary -- though they are of course what makes it possible for American high-schoolers to read Shakespeare today. I bet Appalachian English has lost some Shakespearean linguistic traits that Standard English has retained, too. Differential retention of inherited linguistic features is one thing that characterizes divergent dialects of the same language. It's not a surprise, and it's not evidence of super-archaicness in any dialect.
December 10, 2005
Porous another one
Today's NYT has a piece by Paul Vitello headlined "Hold the Limo: The Prom's Cancelled as Decadent". At the end of the story, Jim Rooney, the principal of Rye High School in Westchester County, discusses the limitations of his school's elaborate precautionary measures:
After-prom parties happen. It is almost assumed that students will seek memorable experiences according to their own standards.
"A lot of them go off to these Chelsea bars," Mr. Rooney said. "I understand that most of those places are quite porous."
I guess that "porous" here refers to laxity in enforcing the minimum drinking age. The AHD gives "easily crossed or penetrated" as a metaphorical third sense for porous. Google finds plenty of discussions of {porous security} with this meaning. However, {porous bar} returns mostly discussions of relatively long, straight, rigid pieces of ceramics, plastic, chocolate and so on that admit the passage of gas or liquid through pores or interstices. Since the context is journalistic rather than literary, we'll leave it at that.
News flash: "dyke" not (necessarily?) disparaging
The USPTO has reversed itself, and taken initial steps to allow the San Francisco Women's Motorcycle Contingent, a.k.a. "Dykes on Bikes", to register their nickname as a trademark. As we explained here and here, the application was previously refused because the Lanham Act forbids the registration of marks that are "disparaging". According to Lynne Beresford, a U.S. commissioner for trademarks quoted in the S.F. Examiner story, "The applicant came in at the last moment with a lot of evidence to show that the community did not consider it disparaging".
You can find those "last minute" declarations by linguists, lexicographers, sociologists, psychologists and others in the case file here, including submissions from Jesse Sheidlower and Ron Butters.
According to the TARR record for the Dykes on Bikes application
Current Status: Approved by the examining attorney for publication for opposition. This is NOT the beginning of the Opposition period. In approximately two months, please visit the web site to learn the actual date of publication for opposition in the Trademark Official Gazette. Date of Status: 2005-12-05
The TARR record for the abandoned attempt to register a "Dykes on Bikes" clothing trademark is here. Other abandoned registration attempts include DYKE WEAR ("clothing and headgear, namely, hats, shirts, neck ties, belts, suspenders, vests, sweaters, coats, pants, dresses, robes, aprons, socks, blazers, beachwear, overalls, gloves, jumpers, suits, pajamas, underclothes and lingerie, scarves and shorts", filed 1997-06-20), DYKE DISH ("printed magazines and computer on-line magazines/web-cites on all aspects of cultural and social events, restaurants, dance clubs, bars, shops, groups, advertisements and resources", filed 1996-06-11), and SUPERDYKE ("clothing; namely, T-shirts", filed 1992-10-26).
I wonder if the new "Dykes on Bikes" precedent will affect the fate of VELVETPARK DYKE CULTURE IN BLOOM ("Magazines Addressing Lesbian Issues", filed 2004-07-08), DYKESINTHECITY ("Clothing, namely, t-shirts, tanks, long-sleeve shirts, sweatshirts, baseball caps, visors, beanie hats, wristbands, underwear, dog tees for dogs, stickers and temporary tattoos, belts and necklaces", filed 2005-01-12), DYKE TV (Television broadcasting services; cable television transmission, namely the transmission of audio and video via cable television; satellite transmission, namely the transmission of audio and video via satellite; digital transmission of audio and video; communication services, namely transmission of streamed sound and audio-visual recordings via a global computer network", filed 2002-07-24) and DYKE DOLLS ("Dolls and accessories therefor", filed 2004-10-9), whose applications are still alive and in process, though beleaguered. The last one in particular has a logo that demonstrates considerable typographical creativity.
And what about COMPO-DYKE, which was filed 1980-06-2 by Utica Tool Co. as a brand name for a "Hand Operated Cutting Tool-Namely, Compound Action Plier", and as of 1982-07-17 was "Abandoned after an inter partes decision by the Trademark Trial and Appeal Board"? Was the "opposition" that was "sustained for Proceeding" on 5/17/1982 due to the disparaging character of the dyke morpheme? Or was Utica Tool persuaded that their proposed brand name would cause too much giggling in shop class? Whatever the reason, there's nothing now on the web about "compo-dykes" or "compodykes" -- Helpful Google asks Did you mean: "compadres"?
We followed up on the original "Dykes on Bikes" story with a investigation into the curious failure of English-language dictionaries to record the use of dyke (or dike) as term for "diagonal cutting pliers" (here and here). Note that the 1980 registration attempt for Compo-Dyke is not the first attested use of the spelling "dyke" for a kind of pliers, but it's not much later than the 1977 hardware-store ad that Ben Zimmer found.
 This reminds me of a puzzling gap in tool nomenclature. There's a kind of shears with compound-action handles that (as far as I know) is generally known by the unwieldy name of "compound snips" or "aircraft snips". It gets worse, because there are three kinds: left-handed, for cutting to the left; right-handed, for cutting to the right; and straight-cut. These are definitely snips, not dykes, but for people who work with sheet metal, they are among the commonest of tools. Just as "diagonal cutting pliers" turned into dykes, you'd think that "compound snips" would turn into comps or compos or pounds or something like that. But when I was working in airframe repair, I'd hear things all the time like "OK, who took my f-ing left-hand compound snips?" Where is Whorf when you need him?
This reminds me of a puzzling gap in tool nomenclature. There's a kind of shears with compound-action handles that (as far as I know) is generally known by the unwieldy name of "compound snips" or "aircraft snips". It gets worse, because there are three kinds: left-handed, for cutting to the left; right-handed, for cutting to the right; and straight-cut. These are definitely snips, not dykes, but for people who work with sheet metal, they are among the commonest of tools. Just as "diagonal cutting pliers" turned into dykes, you'd think that "compound snips" would turn into comps or compos or pounds or something like that. But when I was working in airframe repair, I'd hear things all the time like "OK, who took my f-ing left-hand compound snips?" Where is Whorf when you need him?
December 09, 2005
Jackass of the Week
Language Log's Jackass of the Week award goes to principal Jennifer Watts of Kansas City, Kansas' Endeavor Alternative School for suspending student Zach Rubio for two days for speaking Spanish in school. Fortunately, as soon as superintendent Bobby Allen learned of the suspension he reversed it. The school district has no policy forbidding the use of Spanish or other languages. This evidently is, however, Ms. Watts' policy. According to the Washington Post, in a written explanation for the suspension she stated that:
This is not the first time we have [asked] Zach and others to not speak Spanish at school.
According to Superintendent Allen's report, Watts said that it is important that the teachers be able to communicate and know what the students are saying. That teachers need to be able to communicate is true, but what has it got to do with whether students use Spanish in private conversations? (There is no issue here of encouraging Rubio to learn English - he is a fluent native speaker of both English and Spanish.) That teachers need to know what students are saying in private conversations is false. They don't need to know and they can't, even if the students always speak English. Both in school and out of school students have far too many opportunities to communicate out of range of their teachers for schools to know everything they say. By Watts' Orwellian reasoning, students should be required to wear microphones that transmit everything they say so that it can be monitored at the school office. Even the Soviet Union didn't go that far.
According to Zach's father Lorenzo, when he confronted Watts she said: "We are not in Mexico, we are not in Germany", and "I don't want to hear it [Spanish] in my building". This sounds more like plain old bigotry than educational policy.
Get to
I was writing to a linguist at the University of Toronto about the fact that a friend of mine, a brilliant philosopher, had just moved there, and I found myself writing something which, now that I quote it to you, I feel I have to prefix with the ungrammaticality-marking asterisk:
*If you don't know her, get to.
For me, the verb phrase ellipsis fails there. (Purely an intuitive judgment of ungrammaticality, not intersubjectively checkable. I don't see how to test it by googling. Your mileage may differ.) I have absolutely no idea why it would be ungrammatical. The sentence ought to be a perfectly ordinary and acceptable way to say "If you don't know her, get to know her." Compare with this:
If you haven't heard from her yet, expect to.
That means "If you haven't heard from her yet, expect to hear from her", and there's nothing weird about it at all. I'll tell you, with each successive month I study language, it seems to me to get more and more mysterious.
December 08, 2005
A result that no sensible person could have intended
When intelligent and sensible people discuss the meaning of a piece of speech or writing, they naturally combine dissection of the text itself with analysis of what the author seems to have meant to convey by producing it. If the authorship is unknown or multiple, people still reason about authorial or editorial intent, either by imagining a coherent authorial voice, or by framing hypotheses about a less coherent process of collaborative creation. The reason is simple: much of what we understand as the clear meaning of a text can't be derived without reasoning about communicative intentions.
As we mentioned here earlier, Justice Antonin Scalia nevertheless argues that the analysis of communicative intent has no place, as a matter of principle, in discussions of meaning. Over the past couple of weeks, I've been doing some background reading about the philosophy of legal meaning, and also reading many of Justice Scalia's judicial opinions. I'm still digesting the philosophical discussions, but I've noticed two things about Scalia's opinions that I'm ready to share. One observation is that his linguistic exegesis is insightful and even compelling. Whether or not I like his conclusions, his interpretation of the text usually convinces me. But I've also noticed that he doesn't follow his own prescription: like everyone else, he often brings communication-intention, implicitly or explicitly, directly or counterfactually, into his analysis of the meaning of texts.
First, let's document Scalia's textualist creed. In a recent review of Steven Smith's book Law's Quandary, discussed here earlier, he wrote:
The portion of Smith’s book I least understand—or most disagree with—is the assertion ... that it is a “basic ontological proposition that persons, not objects, have the property of being able to mean.” “Textual meaning,” Smith says, “must be identified with the semantic intentions of an author..."
According to Scalia's view, meaning has to do only with understanding texts or utterances, and not at all with anyone's intent to use them to communicate:
Smith confuses, it seems to me, the question whether words convey a concept from one intelligent mind to another (communication) with the question whether words produce a concept in the person who reads or hears them (meaning).
Scalia counters Smith's radical purposivism by arguing at some length for an equally radical textualism, giving examples like this:
Two persons who speak only English see sculpted in the desert sand the words “LEAVE HERE OR DIE.” It may well be that the words were the fortuitous effect of wind, but the message they convey is clear ...
and this:
If the ringing of an alarm bell has been established, in a particular building, as the conventional signal that the building must be evacuated, it will convey that meaning even if it is activated by a monkey.
He concludes that
What is needed for a symbol to convey meaning is not an intelligent author, but a conventional understanding on the part of the readers or hearers that certain signs or certain sounds represent certain concepts.
He sometimes makes related points more briefly in the context of his judicial opinions, for example:
Legislative history that does not represent the intent of the whole Congress is nonprobative; and legislative history that does represent the intent of the whole Congress is fanciful.
Our opinions using legislative history are often curiously casual, sometimes even careless, in their analysis of what "intent" the legislative history shows. ... Perhaps that is because legislative history is in any event a make weight; the Court really makes up its mind on the basis of other factors. Or perhaps it is simply hard to maintain a rigorously analytical attitude, when the point of departure for the inquiry is the fairyland in which legislative history reflects what was in "the Congress's mind." ...
After recounting the drafting history, the Court states that "nothing in §4010(f)'s text suggests that Congress meant the Federal Reserve Board to function as both regulator and adjudicator in interbank controversies." .... Quite so. The text's the thing. We should therefore ignore drafting history without discussing it, instead of after discussing it.
[Bank One Chicago, N. A. v. Midwest Bank & Trust Co. (94-1175), 516 U.S. 264 (1996)]
His points about legislative history -- that it's undemocratic, unreliable and incoherent -- seem to be reasonable ones, but they don't prevent him from reasoning frequently about the meaning of legal texts in terms of the intentions of those who framed them. For example, in his opinion in Crawford v. Washington, he follows a long and interesting description of the common-law history of the right to confront one's accusers with this conclusion:
This history supports two inferences about the meaning of the Sixth Amendment.
First, the principal evil at which the Confrontation Clause was directed was the civil-law mode of criminal procedure, and particularly its use of ex parte examinations as evidence against the accused. ...
The historical record also supports a second proposition: that the Framers would not have allowed admission of testimonial statements of a witness who did not appear at trial unless he was unavailable to testify, and the defendant had had a prior opportunity for cross-examination. The text of the Sixth Amendment does not suggest any open-ended exceptions from the confrontation requirement to be developed by the courts. Rather, the “right … to be confronted with the witnesses against him,” Amdt. 6, is most naturally read as a reference to the right of confrontation at common law, admitting only those exceptions established at the time of the founding. ...
Where testimonial statements are involved, we do not think the Framers meant to leave the Sixth Amendment’s protection to the vagaries of the rules of evidence, much less to amorphous notions of “reliability.” ...
As another example, in California Div. of Labor Standards Enforcement v. Dillingham Constr., N.A., Inc., he addresses the problem of ERISA's pre-emption section, 29 U.S.C. § 1144(a), which states that ERISA “shall supersede any and all State laws insofar as they may now or hereafter relate to any employee benefit plan” covered by ERISA, and observes that
Hence the many statements, repeated today, to the effect that the ERISA pre-emption provision has a "broad scope," an "expansive sweep," is "broadly worded," "deliberately expansive," and "conspicuous for its breadth." But applying the "relate to" provision according to its terms was a project doomed to failure, since, as many a curbstone philosopher has observed, everything is related to everything else. ... The statutory text provides an illusory test, unless the Court is willing to decree a degree of pre-emption that no sensible person could have intended--which it is not.
In other words, the text of the statute can't possibly meant what it seems to say, or at least what his colleagues on the Supreme Court have taken it to say, because the result would be an interpretation "that no sensible person could have intended". I find this argument compelling, to the extent that I understand it -- but one thing that I definitely understand about it is that it argues for a textual interpretation based on reasoning about communicative intentions.
I could multiply examples -- searching for Scalia at Cornell's Legal Information Institute site returns 2,974 results, and most of them that I've read so far turn up something interesting from this perspective. However, I'll close for now with one other case, John Angus Smith v. United States.
Here's the background. US Code § 924(c)(1) says that
... any person who, during and in relation to any crime of violence or drug trafficking crime ... uses or carries a firearm ... shall... be sentenced to a term of imprisonment of not less than 5 years ... If the firearm possessed by a person convicted of a violation of this subsection ... is a machinegun or a destructive device, or is equipped with a firearm silencer or firearm muffler, the person shall be sentenced to a term of imprisonment of not less than 30 years.
Though the story line might have been devised by Elmore Leonard, the narrator in the following passage is Justice Sandra Day O'Connor:
... John Angus Smith and his companion went from Tennessee to Florida to buy cocaine... While in Florida, they met ... Deborah Hoag ... [who] accompanied [Smith] and his friend to her motel room, where they were joined by a drug dealer. While Hoag listened, petitioner and the dealer discussed petitioner's MAC-10 firearm, which had been modified to operate as an automatic. ... The dealer expressed his interest in becoming the owner of a MAC-10, and [Smith] promised that he would discuss selling the gun if his arrangement with another potential buyer fell through.
Unfortunately for [Smith], Hoag had contacts not only with narcotics traffickers but also with law enforcement officials. In fact, she was a confidential informant. ... The [Broward County] Sheriff's Office responded quickly, sending an undercover officer to Hoag's motel room. ... Upon arriving at Hoag's motel room, the undercover officer presented himself to petitioner as a pawnshop dealer. [Smith] ... presented the officer with a proposition: He had an automatic MAC-10 and silencer with which he might be willing to part. Petitioner then pulled the MAC-10 out of a black canvas bag and showed it to the officer. The officer examined the gun and asked petitioner what he wanted for it. Rather than asking for money, however, petitioner asked for drugs. He was willing to trade his MAC-10, he said, for two ounces of cocaine.
In the majority opinion, Justice O'Connor wrote that
Surely petitioner's treatment of his MAC-10 can be described as "use" within the every day meaning of that term. Petitioner "used" his MAC-10 in an attempt to obtain drugs by offering to trade it for cocaine. Webster's defines "to use" as "[t]o convert to one's service" or "to employ." Webster's New International Dictionary of English Language 2806 (2d ed. 1949). ... Indeed, over 100 years ago we gave the word "use" the same gloss, indicating that it means " `to employ' " or " `to derive service from.' " Astor v. Merritt, 111 U.S. 202, 213 (1884). Petitioner's handling of the MAC-10 in this case falls squarely within those definitions. By attempting to trade his MAC-10 for the drugs, he "used" or "employed" it as an item of barter to obtain cocaine; he "derived service" from it because it was going to bring him the very drugs he sought.
Justice Scalia dissented:
In the search for statutory meaning, we give nontechnical words and phrases their ordinary meaning. ... To use an instrumentality ordinarily means to use it for its intended purpose. When someone asks "Do you use a cane?" he is not inquiring whether you have your grandfather's silver handled walking stick on display in the hall; he wants to know whether you walk with a cane. Similarly, to speak of "using a firearm" is to speak of using it for its distinctive purpose, i.e., as a weapon. To be sure, "one can use a firearm in a number of ways," ... including as an article of exchange, just as one can "use" a cane as a hall decoration--but that is not the ordinary meaning of "using" the one or the other. The Court does not appear to grasp the distinction between how a word can be used and how it ordinarily is used. It would, indeed, be "both reasonable and normal to say that petitioner `used' his MAC-10 in his drug trafficking offense by trading it for cocaine." ... It would also be reasonable and normal to say that he "used" it to scratch his head. When one wishes to describe the action of employing the instrument of a firearm for such unusual purposes, "use" is assuredly a verb one could select. But that says nothing about whether the ordinary meaning of the phrase "uses a firearm" embraces such extraordinary employments. It is unquestionably not reasonable and normal, I think, to say simply "do not use firearms" when one means to prohibit selling or scratching with them. [emphasis added]
Scalia's argument, which I find entirely convincing, is perhaps not rigorously enough defined that we can be certain whether its final sentence is an essential part. My own opinion is that the force of the entire paragraph depends implicitly on reasoning about how someone ought to talk as a function of what he or she intends to communicate. In any case, the last sentence expresses such reasoning explicitly, and the goal of the whole passage is to lead us on this basis to a correct understanding of the text of the statute.
[Other relevant posts:
"Scalia on the meaning of meaning" (10/29/2005)" Legal meaning: the fine print" (11/2/2005)
"Is marriage identical or similar to itself?" (11/2/2005)
]
December 07, 2005
Pick-up basketballism reaches Ivy League faculty vocabulary
The authoritative discussion of the phrase "my bad!" at this Random House site says it originates in pick-up basketball as a phrase used by young urban players when admitting to an error. It has spread to other domains and is now used widely to mean something like "I admit that I have made a mistake." It was nominated for "word of the year" (not that it's a word, it's clearly a phrase) in 1999, but in fact it was already at least twenty years old by then. The upsurge in its popularity is claimed to have a lot to do with its having been used in the 1995 movie Clueless. Well, let the record show that it has now truly arrived. It has reached the vocabularies of Ivy League faculty. Or one Ivy-League faculty member's vocabulary, anyway. I recently heard it used, not at all self-consciously and not really jocularly, by an assistant professor of philosophy from Princeton giving a lecture in the Department of Philosophy at Harvard. (It was in this sort of context, though I didn't transcribe the actual one: "Now, you might think that the response by the antirealist to this objection could be just to say, ‘Whoops, my bad’, and weaken the main thesis without giving it up . . .").
I take it that to be used by a Princeton faculty member giving a lecture at Harvard must be, for a word or phrase, like playing Carnegie Hall for a musician. It must be the sort of thing that a new coinage longs for, the sort of occurrence that makes its mother's heart swell with pride. So I would predict that "my bad" is here to stay for a while, in mainstream use, in the vocabulary of grownups.
Added later, after a little help from my friends: Ken Arneson emailed me to say that he heard the phrase was first used by the Sudanese immigrant basketball player Manute Bol, believed to have been a native speaker of Dinka (a very interesting and thoroughly un-Indo-Europeanlike language of the Nilo-Saharan superfamily). Says Arneson, "I first heard the phrase here in the Bay Area when Bol joined the Golden State Warriors in 1988, when several Warriors players started using the phrase." And Ben Zimmer's rummaging in the newspaper files down in the basement of Language Log Plaza produced a couple of early 1989 quotes that confirm this convincingly:
St. Louis Post-Dispatch, Jan. 10, 1989: When he [Manute Bol] throws a bad pass, he'll say, "My bad" instead of "My fault," and now all the other players say the same thing.
USA Today, Jan. 27, 1989: After making a bad pass, instead of saying "my fault," Manute Bol says, "my bad." Now all the other Warriors say it too.
So all of this is compatible with a date of origin for the phrase in the early 1980s (Manute Bol first joined the NBA in 1985 but came to the USA before that, around 1980). Professor Ron McClamrock of the Philosophy Department at SUNY Albany tells me he recalls very definitely hearing the phrase on the basketball court when he was in graduate school at MIT in the early 1980s, so the news stories above could be picking the story up rather late; but it is still just possible that Manute Bol was the originator, because he played for Cleveland State and Bridgeport University in the early 1980s, and his neologism just could have spread from there to other schools in the northeast, such as MIT.
December 06, 2005
Mid-sentence person shifting
Science News (November 19, 2005, p. 331) has this quote from scientist Matthew Burrow, who was doing cancer research at Tulane University until Hurricane Katrina wrecked his entire program by destroying his crucially important collection of cell lines:
It's not just that our work has been set back 6 months to a year, but you've suddenly lost all your tools.
I noticed it because it was pulled out and printed again as one of those pull-out-quote column interrupters that they use to catch your eye. And the shift of person from first person plural (our) to the informal indefinite use of the second person (you, your) did catch my eye. It's a slip, I think. I wouldn't recommend such switching to a foreign learner who was learning Standard English. I don't mean this remark as a criticism of Matthew Burrow, to whom my heart goes out; if a hurricane had destroyed my entire research program and I had to talk to a reporter about it on the fly, one might well hear us tangle your pronouns a bit as one struggled to express myself. I wouldn't want the result to be that I was nibbled to death by ducks for it on Language Log. But I noticed the utterance because it's a nice attested oral example of an ill-advised mid-sentence shift of person. Usage books warn against doing this when composing English prose, and I think they're right. Notice, the quoted sentence can't really be said to violate any syntactic constraint: our work has been set back 6 months to a year is a grammatical declarative sentence, and so is you've suddenly lost all your tools, and where P and Q are grammatical declarative sentences, there's nothing grammatically wrong with using them in the construction it's not just that P, but Q. So what Matthew said is not syntactically ill-formed. It's just ill-advised on a discourse level, because it confuses the hearer/reader about what perspective to take.
Added later: Barbara Partee writes to point out that my parodying of person-shifting above ("one might well hear us tangle your pronouns a bit as one struggled to express myself") goes beyond anything that could conceivably be regarded as grammatical, because it actually switches pronoun lexeme choice clause) between complements of the same verb (the subject and object in the express clause do not match, as they are required to by the grammar of reflexivization). Guilty as charged. I was kidding, of course. And since I hate to see cheating of that kind in the writings of prescriptivists, who criticize a grammatical usage by inventing an exaggeration of it and mocking that, I guess I really should be ashamed of myself. I hope you will note that my attitude above is sympathetic: I was not saying that Matthew Burrow was an ignorant twerp or that he didn't know English, or handing out any of the sort of abusive nonsense you get from real prescriptivists. Nonetheless, I think I may turn myself in to the enforcement authorities at Language Log Plaza for some punishment. We have various unpleasant tasks that we reserve for reminding our staff writers of their duty not to be the linguistic analog of Blue Meanies. Cleaning the basement toilets with Clorox and an Oral B toothbrush is one. Another is reading aloud the whole of page 48 of the 4th edition of Strunk & White, three times. I think I'll go for the toilets.
December 05, 2005
Snowclones hit the big time
The humble study of snowclones, pursued in this space intermittently over the past two years, may be getting a significant boost in attention. David Rowan, who writes on "trendsurfing" for the (UK) Times, has devoted his most recent column to "'Snowclone' Journalism":
Sometimes a trend comes along that is brutally painful for a self-respecting journalist to acknowledge. So it is with some embarrassment that I report on the latest obsession buzzing through the arcane fields of linguistics and lexicography, one that will resonate with any Times reader who values well-written English. We hacks, it seems, have become so enamoured of lazy, formulaic turns of phrase that we have inspired a new academic sport devoted to chronicling them. They even have their own name: snowclones. Snowclones? Darling, as journalistic clichés go, snowclones are the new black.
Rowan peppers the column with various snowclones collected here in the past, from "have X will travel" to "X eats, drinks, and sleeps Y." (For a comprehensive list of snowclone posts see Mark Liberman's update on Geoffrey Pullum's baptismal announcement of Jan. 16, 2004.) Not all of the snowclones mentioned in the column derive from the friendly confines of Language Log Plaza. For instance, "X, the hidden epidemic" was first noted on Jan. 29, 2004 by Danyel Fisher (who also contributed "X, the second-oldest profession" and "X considered harmful"). Rowan remarks that snowclone-spotting is a game everyone can play (not just those obsessive scholars of linguistic arcana!), and he encourages his readers to send in examples they've come across.
I don't see the column in the online version of the Times (though it should be appearing soon on the Factiva and Proquest news databases). Still, this publicity may presage the incipient mainstreaming of snowclonology. Just a couple of months ago, a Wikipedia entry for "snowclone" was deleted because "it was decided that it is a neologism that is not used widely enough to warrant an entry in an encyclopedia." But a new entry emerged shortly thereafter, and Rowan's column and its follow-ups may help convince the Wikipedians that snowclones are here to stay.
December 04, 2005
Can I help who's next?
In Rockport, Massachusetts, I observed another grammatical construction that might well have been thought extinct for many decades, but like the ivory-billed woodpecker and the supplementary relative that-clause, it seems to have survived in one very limited contextual environment. I was waiting in line in a small coffee shop and I heard a young woman behind the counter call for the next customer by saying "Can I help who's next?". This wasn't my first observation; I hear the phrase in Santa Cruz, California, too (and since first posting this I have heard that it is familiar elsewhere, from ice cream scoopers in Cleveland, Ohio, to bank tellers in Gainesville, Florida). So it's not local; it's spread across the entire breadth of the continent. What's interesting about it is that it's a fused relative construction with human denotation, headed by the relative pronoun lexeme who. And that is a possibility that has mostly been extinct for some fifty to a hundred years.
It's very important here to distinguish two separate structures for who's next. One of the two is an interrogative content clause, and that's commonplace. There is nothing remarkable about examples like this:
I wonder who's next.
Let's go and inquire who's next.
Who's next is completely unclear.
Who's next doesn't matter.
In all of these, the who's next is interrogative. There are various tests for this. A fairly good one is to see if you can add else. If you can its an interrogative. Since only one person can be the next and nobody else can, there is a semantic incompatibility with else here, but notice that in all of the above examples you could replace who's next by something like who else was involved, and the results are fully acceptable. That tells us that the construction is an interrogative complement clause in each case.
Now, interrogatives often have exactly the same form as corresponding fused relatives. Take a constituent like what Frankenstein created in his laboratory. It goes well as the complement of a verb like inquire or the subject of something like is completely unclear:
Let's go and inquire what Frankenstein created in his laboratory.
What Frankenstein created in his laboratory is completely unclear.
These are interrogative uses (and notice, adding else after what produces perfectly grammatical results). But the same string of words can also be a fused relative: a noun phrase constituent in which, in effect, the words the thing that (or the thing which, or that which) are fused into the single word what. When it's a fused relative noun phrase construction, such a word sequence can be the subject of a straightforward verb phrase denoting an action:
What Frankenstein created in his laboratory subsequently killed him.
Here what Frankenstein created in his laboratory can be paraphrased as "the thing that Frankenstein created in his laboratory", which is not at all like its interpretation in the earlier examples. And if you try the else test on this, and in my judgment it fails:
*What else Frankenstein created in his laboratory subsequently killed him.
Now consider whether you can use something like who taught Frankenstein his medical skills as a fused relative. In the following pair, the first uses it as an interrogative content clause and the second uses it as a fused relative. In my judgment, the second one is completely ungrammatical.
Who taught Frankenstein his medical skills is unclear.
*Who taught Frankenstein his medical skills did him no favors.
In general, fused relatives with who just aren't used in contemporary English. In Shakespeare's time it was commonplace (recall Iago's remark in Othello: Who steals my purse steals trash; 'twas mine, 'tis his, and has been slave to thousands). It survived down to the 19th century. But it did not survive down to the present day.
Except in this peculiar use in coffee shops and the like, because in Can I help who's next? we have a fused relative construction: it's the object of help.
Notice, I've been talking about phrases like who taught Frankenstein his medical skills and who's next. Things are completely different if we consider not the lexeme who but instead the compound lexeme whoever. That (like all the wh + -ever words) is freely used in fused relatives. If I was hearing Can I help whoever's next? I wouldn't have written this post at all. There'd be nothing interesting to say. And no, I don't think we're looking at a contraction of whoever. You can't just posit random omissions of two-syllable sequences, especially when they just happen to result in something that is almost grammatical and used to be fully grammatical. And particularly not in this kind of case, where the -ever part is meaningful.
[Lots of people have now written to me to confirm hearing or using the expression in coffee shops, bookstores, or whatever, up to about fifteen years ago, especially in the upper Midwest, which could be the cradle of the phrase. Interestingly, though, one of the first messages I got after posting this was from some supercilious snooty guy who wanted to tell me that the people who serve behind counters in coffee shops "probably never read Shakespeare and have a limited grasp of the English language", as if this was about dinging a young working woman for being ignorant. It's about nothing of the sort. It's about the grammatical possibility of human-referring fused relatives, and the complexity of the picture we face when a single language is in use by a billion people with dates of birth spread over about a century, and about the odd survivals and exceptions that can lurk in the syntactic patterns found in everyday use. One person who is now a linguist wrote me to say that even when she first heard this expression in an ice cream place 15 years ago she thought even then that it was odd. I'm explaining that she's right: it is odd. It seems to be an isolated survival of an extinct construction type. And you don't account for its existence across a continent by positing unconfirmable (and implausible) individual ignorance.]
December 03, 2005
liberal linguists
In a post I discuss in an update to my note on the use of elite to denote individuals, Ranesh Ponnru identifies me as "Geoffrey Nunberg, the liberal linguist." Fair enough, at least according to principles of semantic compositionality -- I plead guilty to both. Still, the locution struck me as odd in a Gricean way, maybe because we linguists don't think of our political views as relevant to our research in the way they are for political scientists or economists. To my ear, "liberal linguist" evoked the same how's-that-again? reaction you'd get from a phrase like "liberal biochemist" -- or for that matter, "liberal phonologist."
Of course people often refer to Chomsky as a "radical linguist, "left-wing linguist," "leftist linguist," "loony-left linguist," and so on, but despite any number of ingenious efforts to link Chomsky's linguistics to his politics, I don't think many linguists buy the connection. Even if the majority of linguists have left-of-center political views, there's nothing in the average syntax article that would give you any insight into the author's political views (well, apart from the example sentences, on occasion -- though Chomsky himself rarely strays from examples involving John and Mary). But I wonder how many people outside the field would tend to read a phrase like "leftist linguist" as equivalent to "practitioner of leftist linguistics," rather than simply as a concise identifier. Just curious.
December 02, 2005
We Have Always Been At War With Oceania
The upcoming Canadian election has brought out an interesting example of linguistic sleight of hand for political purposes. Language Log reader Chris Culy has pointed out that Conservative Party leader Stephen Harper is playing fast and loose when he makes claims like these:
[The Liberal party]... that has been named in a judicial inquiry, a royal commission, been found guilty of breaking every conceivable law in the province of Quebec with the help of organized crime... CBC News.
We've seen the Gomery report, we heard the Gomery testimony, we've heard testimony of reports of money-laundering, kickbacks, brown envelopes of illegal cash, threats and intimidation. And this went on for years. I don't think I need to say more. That's the definition of organized crime where I come from, but I'll at least give them boldness for trying to pretend it never happened. CBC News
What Harper refers to are improprieties in the administration of what is know as the Sponsorship Program, the subject of a recent report by the Gomery Commission. The extent of the corruption is disputed, but it seems clear that high-ranking members of the Liberal party were involved in some significant funny business. What is misleading is the attempt to connect this misconduct with organized crime, which makes us think of the Mafia and other, similar, ethnically based criminal organizations with a reputation for violence. In fact, there is no evidence of any connections to organized crime in this sense. The misconduct seems to have involved various politicians, bureaucrats, and business people and to have been organized only in the sense that some of these people conspired with others. There is certainly much political fodder here for the opposition parties, but Harper's references to organized crime represent an attempt to turn the corruption into something worse than it is.
Indeed, the very name of the Conservative Party is arguably a linguistic trick of the same sort. Once upon a time the Progressive Conservative party was one of the major parties in Canada. When the PC government fell in 1993, the party very nearly disintegrated and ceased to have much political influence. Meanwhile, the Reform Party, founded in 1987 by disgruntled Western Canadian right-wing politicians, grew into an increasingly influential party of national scope. In 2000 the Reform Party morphed into the Canadian Reform Conservative Alliance, popularly known as the Canadian Alliance, which in turn, in December of 2003, merged with the residue of the Progressive Conservative party and assumed the name Conservative Party of Canada.
What many people consider misleading about the assumption of the Conservative name is that the old Progressive Conservative party had a rather different character from the new Conservative party, which is really the Reform Party under a different name. The Progressive Conservatives were moderate and pan-Canadian. The Reform Party was a good bit farther to the right and attracted the support of extremists such as the Heritage Front, a neo-Nazi group. It was also associated with Western Canadian discontent with Ottawa, opposition to distinct status for Quebec, and opposition to the policy of official bilingualism. A number of leading members of the Progressive Conservatives, most notably former Prime Minister Joe Clark, strongly opposed the merger and refused to join the new party. By taking on the name of the much smaller party which it absorbed, the Reform Party/Canadian Alliance attempted to give itself the warm and fuzzy image of the Progressive Conservatives.
The United States strives for leadership in all fields, so it is not surprising that a much more egregious example of linguistic sleight of hand for political purposes is US President George Bush's baldfaced lie that "We do not torture" (CNN). The evidence that the United States is engaged in systematic torture is so overwhelming that few people, even politicians, could say such a thing with a straight face. Bush is no doubt relying on his administration's widely criticized attempt at limiting the scope of the term torture to the imposition of pain comparable to that of major organ failure.
Lest it seem that I am picking on the right wing, I note that the same phenomenon can be observed on the left. Does any thinking person really believe that university "diversity" programs are about diversity? Admitting a suburban upper-middle class black man increases diversity but admitting a rural Nigerian or a woman from a poor family in Appalachia doesn't? The reality is that "diversity" is just another name for "affirmative action". When affirmative action became unpopular, its proponents renamed it in an attempt to make it more palatable.
Examples of this sort abound. A couple that I've mentioned here before are the redefinition of anti-Semitism by Arab anti-Semites and the resistance to characterizing the genocide in Darfur as such. George Lakoff (better picture here) in various publications discusses other examples.
Merriam-Webster Open Dictionary
Merriam-Webster has added to their online dictionary an open dictionary where anyone can submit entries for words not present in the online dictionary. It has already received over 2,300 submissions, which you can browse.
My own small contribution is the noun microhol, the substance with chemical formula M$2H5OH, in which the two carbons of ethanol are replaced with M$. microhol is said to have the effect of rendering anyone who consumes it susceptible to the influence of Microsoft..
Wrathful Dispersion Theory
Q Pheevr takes up the latest educational controversy:
Linguists here in Canada have been following closely, with a mixture of amusement, bemusement, and, it must be admitted, a little trepidation, the deliberations of our neighbours to the south, who are currently considering, in a courtroom in Pennsylvania, whether "Wrathful Dispersion Theory," as it is called, should be taught in the public schools alongside evolutionary theories of historical linguistics. It is an emotionally charged question, for linguistics is widely and justifiably seen as the centrepiece of the high-school science curriculum—a hard science, but not a difficult one to do in the classroom; an area of study that teaches students the essentials of scientific reasoning, but that at the same time touches on the spiritual essence of what it means to be human, for it is of course language that separates us from our cousins the apes.
You should go read the whole essay now. Although we urged linguists to boycott the hearings on "Intelligent Design", we can't in good conscience fail to respond to the challenge of the "Wrathful Dispersion" movement, especially since some of its supporters have been weaving quotes from Language Log into their arguments.
Neologism-tracking down under
The monitoring of newly coined English words and phrases is, of course, not strictly an American activity, though it tends to be centered in the U.S. since that's where so much of the neologistic action is these days. A new contribution to the field of study has just been released in Australia (though much of the material is American): Ruth Wajnryb's Funktionary: A Cheeky Collection of Contemporary Words published by Lothian. Wajnryb, who also recently authored the (anti-linguist?) book Expletive Deleted: A Good Look at Bad Language, wrote about her research for Funktionary in today's Sydney Morning Herald, where she has a regular column on words.
As an example of an unusually successful recent neologism, she discusses wardrobe malfunction, the euphemism inspired by Janet Jackson's infamous Super Bowl appearance last year. Wajnryb explains that a wardrobe malfunction is also known as a Janet moment (not to be confused with a senior moment, an Oprah moment, or an ohnomoment). Wardrobe malfunction has already entered the seventh edition of Collins English Dictionary, proof that it scores well on the FUDGE scale. "FUDGE", a backronym coined by Allan Metcalf in his book Predicting New Words, spells out a set of criteria for judging the viability of neologisms: Frequency of use, Unobtrusiveness, Diversity of users and situations, Generation of other forms and meanings, and Endurance of the concept.
Though the publisher site for Funktionary says it was released in November, it apparently hasn't yet been distributed outside of Australia. Amazon UK lists a publication date of April 30, 2006, while the main US-based Amazon site doesn't have it at all. To paraphrase an old linguistic punchline, it's enough to make you wonder what the book hasn't made it out from Down Under for.
IPA Beer
The International Phonetic Alphabet now has its own beer! Look what I found in the liquor store here in Prince George:

A careful reading of the fine print on the bottle reveals that IPA stands for India Pale Ale, but I like my interpretation better.
Christmas trees and holiday trees
Both here in Boston and at the Capitol in Washington DC, the annual Christmas tree is being officially referred to as a "holiday tree". And Jerry Falwell has immediately jumped on this as an issue for the Christian right (the people that, as Tom Wolfe points out, we used to just call Christians): he thinks secularists are "trying to steal Christmas". Well, I'm firmly for inclusiveness, and firmly against both religious bigotry and hostility to religion, and I see nothing sensible going on here. Beam me up, Scotty. This shouldn't be a religious issue at all. What is supposed to be the rational basis for objecting to the term "Christmas tree" as a name for the evergreens that are traditionally erected and bedecked with lights at this time of year? That the etymology of Christmas has "Christ" and "mass" in it? You can't expunge religion by switching to "holiday": the etymology of holiday has "holy" in it! And the etymology of the word "Saturday" has the name of the Roman god Saturn in it, but that doesn't mean we should rename Saturday to avoid offending those who honor it as their sabbath, by implying that we honor the pagan gods of ancient Rome. We don't call it that to honor Saturn. Nor do we honor the Norse goddess Freya (who rides into battle on a boar called Hildisvin the battle-swine, by the way) when we call Islam's holy day "Friday". (Notice, in all of these cases phonological change has wrecked the similarity that used to obtain: [kris] doesn't sound anything like [kraist], for example.)
As everyone knows, open commercial promotion of Christmas starts before Hallowe'en (October 31) in this country, and pretty soon it's jingle bells and holly and ivy and silent night in every mall in the land. There's nothing religious about this harmless Christmas nonsense, and it's good for the economy, and you can't conceal which traditional festival is being celebrated. Yes, I say that what President Bush lit up at the White House yesterday is a Christmas tree, and — for once I agree with him and Laura — we should call it that. You see a lot of Christmas trees in America in December, just like you see stars of David and menoras in windows of Jewish homes, and during Ramadan you see a lot of Muslims checking their watches near sundown to see if they can grab something to eat yet... This is a religiously diverse country, with a bunch of well-established holidays, some of which have religious significance for some people. Deal with it. When we break out the eggnog in Language Log Plaza the week after next, I'll be going to — and calling it — the third annual Language Log Christmas party.
The long tail: in which Gauss is not mocked, but TWiTs (and dictionaries) are
This all started a couple of weeks ago, when I listened to the podcast TWiT 30: Live from the Podcast Expo. TWiT stands for "This Week in Tech" (motto: "Your first podcast of the week is the last word in tech"). Here tech really means something like "California IT-industry gossip", but it's a fun show, full of good-natured geekoid banter, and I listen to it regularly. So I was shocked to discover that neither host Leo Laporte nor any of the other TWiTs has apparently ever learned any statistics. At least, none of them knows the sense of the word tail as (in the words of the OED) "An extremity of a curve, esp. that of a frequency distribution, as it approaches the horizontal axis of a graph; the part of a distribution that this represents".
Here's the evidence, in the form of some transcription fragments from the show. (There's a lot of what a social psychologist might call "co-construction of discourse", i.e. everybody talking at once, so the sequencing is approximate and some of the attributions may be wrong.)
Leo Laporte introduces one of the guests:
| Leo Laporte: | uh to begin kind of our- our round table of podcasters, Digital Bill from uh The Wizards of Technology, an old friend, and a great friend, and wearing a kilt in honor of Patrick Norton. |
Leo and Bill geek out for a while about microphone brands and model numbers -- Leo is excited about his new Heil PR-40, designed by "the former sound guy for the Grateful Dead", which was his prize for winning the People's Choice podcast award. (I'm using the pound sign # to indicate interruption points.)
| Digital Bill: | The question will be, can it happen again? |
| Leo Laporte: | Never. You know, I- I- I'm firmly of the opinion that the tech podcasts are on top now because that's who can get # podcasts. |
| Digital Bill: | The tech audience. |
| Doug Kaye: | Right. |
| Leo Laporte: | But I think by this time next year, it'll be- I hope it'll be a mainstream audience, don't you think, Bill? # I mean uh |
| Digital Bill: | Yeah, I- I- I do, I- I mean, We've been walking around and th- the thing that was always amazing to me is how many people come up to us a- you know as a tech podcast, and they're like "well it's- it's Wizards of Technology, we're not quite used to that", but some of the guys that came up and talked to us are people who have their own podcasts, uh the RaiderCast, uh the guy that has a podcast about didgeridoos, right, the Australian # instrument. |
| Leo Laporte: | I'd love that. [Begins imitating a didgeridoo...] |
Note that for Digital Bill, "mainstream audience" apparently means "people who are not interested in technology", including for example those who are interested in podcastsabout didgeridoos.
| Digital Bill: | He says he kn- he knows- he knows both of the guys in- in San Francisco that play them, and- but |
| Leo Laporte: | It's a small community but powerful. |
| Digital Bill: | they're- they're way out on the long tail, right, these are the guys who are but- but there's an interest for that, and no matter what you have to talk about, in podcasting, you have uh- whatever your passion is- |
| Leo Laporte: | There's somebody # to listen. |
| Digital Bill: | somebody's gonna want to listen, because you're not the only person that likes digeridoos, there are other people that do. |
There's some back-and-forth with Doug Kaye (of IT Conversations) about podcasts about knitting, and then Leo picks up an earlier thread:
| Leo Laporte: | So uh you said something th- that I keep hearing at this conference, Digital Bill, and I want to know what the hell it means: "long tail". |
| Digital Bill: | Oh, the "long tail". I don't know- |
| Leo Laporte: | Everybody's talking about the frickin "long tail". |
| Digital Bill: | Yeah. |
| Leo Laporte: | Is that the # word of the week? I don't- |
| Doug Kaye: | You don't have one? |
| Digital Bill: | ((I'll check: no.)) I had mine removed, actually, it doesn't look good with the kilt. |
| Leo Laporte: | You still have the bump, though, I understand. |
| Digital Bill: | You noticed that? |
| Leo Laporte: | Yeah. |
| Digital Bill: | Okay. |
| Doug Kaye: | [significantly] Okay... |
After this homoerotic interlude, Digital Bill takes up the challenge of explaining the "long tail":
| Digital Bill: | The- the long tail is the part of- of consumable stuff, I forg- you can probably explain this better than me, Doug, but it's- it's you know, there's an initial high-end of # demand |
| Doug Kaye: | That's the early adopters. |
| Digital Bill: | ...the early adopters, you know, they're the first per- people to jump on to any- any # new thing. |
| Leo Laporte: | So we're the fat part of the tail. |
| Digital Bill: | This- this # whole... |
| Leo Laporte: | The fat head. |
| Digital Bill: | ...this- this whole audience is- uh are early # adopters. |
| Leo Laporte: | So it's kind of like a spermatozoa? |
| Doug Kaye: | On the leading edge. |
| Digital Bill: | Uh it could be like that. And then i- it- you know that- that demand tapers off in kind of this uh you know tail-shaped uh pattern, but uh I think Ama- Amazon were the ones who kind of discovered it through all their data mining and so forth is that they have the- a larger percentage of their total sales volume come from those small demand things, but there's just so many of # them out there, |
| Leo Laporte: | Aaah. |
| Digital Bill: | that- that it- it- it adds up to such a large volume, they're- |
The TWiTs then agree that all this has something to do with the internet and business models and stuff:
| Leo Laporte: | So the long tail really is important in an e- in a- in internet sense, when you have massive # numbers. |
| Digital Bill: | Well and remember that we all decided that the internet is now not a fad. for a l- remember the internet itself was originally bl- oh, that's just- that's just a fad, yeah? |
| Doug Kaye: | No and I- I- I think also that the uh uh Netflix is- is a perfect example of someone # who's taking full advantage of the long tail, |
| Digital Bill: | Yeah, Netflix is one too, yeah. |
| Doug Kaye: | ...where most- a lot of times what you think of is, I can go get that at Netflix, wh- I can't get that anywhere else. |
| Leo Laporte: | Right. |
| Doug Kaye: | So a lot of their business- their whole business model is based on the ability to do that. |
| Leo Laporte: | So if Amazon didn't have every book, or Netflix didn't have every movie, there'd be no long tail. |
| Doug Kaye: | Yeah, I mean it really came fr- it was uh coined by Chris Anderson at Wired Magazine and he did the first article, and he's got a book coming out about the long tail, which I # ((believe it)) |
| Digital Bill: | How to have a long tail. |
| Doug Kaye: | Yeah, exactly. But it was- it was literally Amazon was his first case, and it said ... |
Well, you can read Chris Anderson's article for yourself. And if you search Google Images for "long tail", you'll find lots of copies of pictures like this one, which will give you an idea of what this is all about. It may also suggest why the TWiTs (who have probably seen slides like this) have gotten all confused about the relationship of the "long tail" to their beloved early adopters: for books and movies, most sales are soon after release.
However, Anderson's "long tail" is not about those who are not early adopters, any more than "mainstream audiences" are those who are interested in didgeridoos and knitting. In fact, the usage doesn't come from any of the temporal senses of tail, such as (from the OED again) "The terminal or concluding part of anything, as of a text, word, or sentence, of a period of time, or something occupying time, as a storm, shower, drought, etc.", or "The rear-end of an army or marching column, of a procession, etc.". Instead, the source is the statistical sense quoted earlier: "An extremity of a curve, esp. that of a frequency distribution, as it approaches the horizontal axis of a graph; the part of a distribution that this represents". The OED's first citation for this sense comes from Karl Pearson more than a century ago:
1895 K. PEARSON in Phil. Trans. R. Soc. A. CLXXXVI. 397 We require to have the ‘tail’ as carefully recorded as the body of statistics. Unfortunately the practical collectors of statistics often..proceed by a method of ‘lumping together’ at the extremes of their statistical series.
What makes a statistical tail "long"? To understand this, we've got to start with the Central Limit Theorem, which says that the sum of many independent random variables with finite variance will be approximately gaussian, i.e. "normal", with the approximation improving as the number of variables increases. This might seem like an obscure idea, as remote from internet marketing buzz as didgeridoos are from mainstream media. But in fact it's a major theme of 20th-century science, and exactly the sort of thing that I would have thought that a bunch of tech geeks would be steeped in.
To give a sense of the status of the CLT, I'll quote a bit from Cosma Shalizi's lovely weblog post of 10/28/2005, "Gauss is not mocked".
Let me turn the microphone over to Francis Galton (as quoted in Ian Hacking's The Taming of Chance):
I know of scarcely anything so apt to impress the imagination as the wonderful form of cosmic order expressed by `the law of error.' A savage, if could understand it, would worship it as a god. It reigns with severity in complete self-effacement amidst the wildest confusion. The huger the mob and the greater the anarchy the more perfect its sway. Let a large sample of chaotic elements be taken and marshalled in order of their magnitudes, and then, however wildly irregular they appeared, an unexpected and most beautiful form of regularity proves to have been present all along.
As Hacking notes, on further consideration Galton was even more impressed by the central limit theorem, and accordingly replaced the sentence about savages with "The law would have been personified by the Greeks and deified, if they had known of it." Whether deified by Hellenes or savages, however, the CLT has a message for those doing data analysis, and the message is:
Thou shalt have no other distribution before me, for I am a jealous limit theorem.
When I took probability and statistics as an undergraduate in 1966 or so, we spent the whole first semester deriving several different versions of the Central Limit Theorem in several different ways from several different sets of axioms. It was strangely like medieval schoolboys being drilled in Aquinas' five proofs of the existence of God. Only in the second semester, after a suitable reverence for the CLT had been impressed on us, did we actually encounter any of the apparatus of 20th-century inferential statistics that is based on it.
When I got to Bell Labs in 1975, it was refreshing to be exposed to the counter-cultural resonances of John Tukey's skeptical take on the bad effects of (often untested) assumption of normality. This started (I think) with his much-cited 1960 paper "A Survey of Sampling From Contaminated Distributions" (in Contributions to Probability and Statistics, Olkin, ed.). Tukey's 1977 books Exploratory Data Analysis and Data Analysis and Regression sold this idea to a wider audience. A key point was that real-world distributions often have "longer tails" than the gaussian approximation characterized by sample estimates of mean and variance. In other words, you find a much larger proportion of your observations further away from the commonest range of values than this fitted "normal" approximation predicts. Tukey argued that this fact can often result in errors of statistical inference.
The "long tail" might arise because the real data distribution has tails that don't decay exponentially, the way the gaussian or normal distribution's tails do, for example if the real underlying distribution is a 1/F or power-law distribution. However, as Cosma's post suggest, it can be for other reasons as well. Thus Tukey's original 1960 paper dealt with the "contaminated" normal distribution, which is a mixture of two gaussians, one with a much higher variance than the other.
In the 1970s and 1980s, statisticians and other became very interested in distributions with "long tails". You can find thousands of papers like Montroll, Elliott W. and Shlesinger, Michael F. "On $1/f$ noise and other distributions with long tails", Proc. Nat. Acad. Sci. U.S.A. 79 (1982). As that particular title suggests, the attention generated by Turkey's concern for robust statistical estimation was soon turbo-charged by popular interest in fractals, self-similar distributions, Zipf's Law, Pareto's Law, and similar themes of 1980s math-geek culture. Perhaps the apotheosis of this buzz was Per Bak's (apparently mistaken) 1988 argument that 1/F noise is a sign of "self-organized criticality", which is turn was argued to be How Nature Works. By 1988, the 1960s' focus on admitting data points far from the norm had been incorporated into the mainstream, in applied math as in the society at large.
So by the time the internet came along, "long tailed" distributions (whether 1/F or not) were part of the standard conceptual toolkit of elementary applied mathematics, and the term "long tail" was widely used in this context. Thus in Bernardo A. Huberman, Lada A. Adamic's paper, "Growth dynamics of the World-Wide Web" (Nature 401(9), September 1999), we find
"But although it is skewed and has a long tail, the log-normal distribution is not a power-law one."
As Amazon and other internet retailers have demonstrated, long-tailed distributions of consumer demand -- in the sense of distributions where a large fraction of the probability mass is in the tail -- are a Good Thing for companies that can cope efficiently with orders for the very large array of books, CDs, movies and so on that are not among the top sellers. That's where Chris Anderson's Wired article "The Long Tail" starts. He claims that a much bigger fraction of the (potential sales) mass than you might think is out in the tails of the distribution of consumer demand, and he turns the phrase "long tail" into a bugle call for the redesign of post-modern life:
You can find everything out there on the Long Tail. ... There are niches by the thousands, genre within genre within genre ...
And the cultural benefit of all of this is much more diversity, reversing the blanding effects of a century of distribution scarcity and ending the tyranny of the hit.
Such is the power of the Long Tail. Its time has come.
I have no doubt that Gauss and Turing are raising a glass or two with John Tukey, in celebration of this development.
Meanwhile, the "tail of a distribution" sense of tail is not only news to the TWiTs, it's missing entirely from the American Heritage Dictionary, from Merriam-Webster Online, and from Encarta. It's even missing from Merriam-Webster's Unabridged (3rd Edition), which gives no fewer than 21 other senses, including obscure ones like "a sprout of barley" or "the exposed lower end of a slate, tile or rafter". So now that the time of the Long Tail has come, perhaps its terminological parent should be admitted into dictionaries other than the OED?
December 01, 2005
An ivory-billed relative clause
Matthew Hutson wrote me (a while ago, actually, back at the beginning of September) to ask this:
I'm aware of the general Language Log consensus on the which/that "rule": which is acceptable in most places where adherents to the rule would argue that is required. But what about the rare reverse case:
"The key point, that all the popular reports missed, is that FOXP2 is a transcription factor..." (http://itre.cis.upenn.edu/ ~myl/ languagelog/ archives/ 002456.html) Would which — or else the removal of the commas, depending on what he meant — be required here?
Thanks
Matt
Great question. The answer is no, it's not wrong; no correction is needed; but it is true that the subordinator that is now fantastically rare in the role of introducing what The Cambridge Grammar calls a supplementary relative (a more traditional name for them is "appositive" or "non-restrictive" relative clauses). It used to be more common (Jespersen's grammar cites a few), but today you have to hunt around for months and months to find a single example, and it could be years. But Matt has spotted one. The sentence he quotes, which I quoted from an article about the FOXP2 gene in a post I didn't want to interrupt in order to comment, is a genuine case of a recent modern English supplementary relative clause introduced by that. Treasure it, Matt. It's like spotting the syntactic analog of an ivory-billed woodpecker.
Some rather grouchy email from a couple of correspondents suggests to me that I should clarify at least three things about the above.
- The example is not a perfect sighting of the ivory-bill; it's just a blurred video frame. Ideally you should be able to tell from the syntax of the construction that it can't be anything other than a supplementary relative. This is sometimes possible, but not here. The example could just be referring to the key point that all the popular reports missed, and putting in commas erroneously. But my reading of the context of the original was that he was saying that the key point was that FOXP2 is a transcription factor, and all the popular reports had missed that — not merely that this was the key point from among those that the popular reports had missed, but that it was the key point. If I'm right, then this is a supplementary relative. [Update, December 4: And I am right. I contacted the author of the sentence, Alec MacAndrew, and asked him what sense he had in mind when he wrote the article in question. He has kindly confirmed that I correctly divined his intention: he did indeed intend the supplementary semantics, where the meaning is "The key point — and incidentally, all the popular reports missed it — is that FOXP2 is a transcription factor". So we do have a genuine observation here.]
- The reason I don't simply say that with an occurrence rate that low the construction is simply ungrammatical is just that I'm conservative enough to think that the language changes only slowly and we shouldn't be hurrying it up. Supplementary relatives with that are now extremely rare, but not totally impossible to find. Though I will add this: if teachers taught foreign students that they were simply not grammatical at all, and copy-editors refused to allow them to reach print, they would not be far wrong, and it would do no great harm. (This is not the case with restrictive relatives with which; those are very common, and to teach that they are ungrammatical would be tantamount to lying to the students.)
- But you certainly can't use that to introduce a supplementary relative clause if the head noun is human; it is totally ungrammatical: *I asked Vice Chancellor Bradshaw, that I have known for many years, whether he agreed. Even examples such as these used to occur, around a hundred years ago, but I don't think they could be regarded as anything other than a mistake today.
Wordplay Watch #1: Cruciverbalism on the silver screen
What Spellbound did for spelling bees and Word Wars did for Scrabble, a new documentary hopes to do for the world of crossword puzzling. The Sundance Film Festival has announced its 2006 lineup, and among the 16 entries in the documentary competition is a film called Wordplay, directed by Patrick Creadon. This should be of even greater interest to word buffs than Spellbound or Word Wars, since as Lauren Squires recently pointed out on Polyglot Conspiracy, national spelling bees and Scrabble tournaments are "not really about the words."
(Sundance will also be screening a film called The Secret Life of Words, which unfortunately is not the etymological blockbuster we've all been waiting for. Instead it's a film by Spanish director Isabel Coixet, starring Sarah Polley and Tim Robbins, about a nurse who treats a man with severe burns on an oil rig. By which I mean that the burns are on the man, not the oil rig.)
Here's the brief description for Wordplay supplied by Sundance:
An in-depth look at the New York Times crossword puzzle and its editor Will Shortz, and the wonderfully unique and loyal fan base he has built and nurtured during his 12-year tenure at the paper.
But that doesn't do justice to the film's content, apparently. For the real scoop, check out the blogs of Trip Payne and Ellen Ripstein. Payne and Ripstein are among the perennial champs at the American Crossword Puzzle Tournament, held each year in Stamford, Connecticut. According to the cruciverbalist blogs, Creadon's focus was originally just on Shortz and his tenure at the Times. But it ended up being more about the competitive side of puzzling, particularly the nerdy intensity of the Stamford tournament, which Shortz directs. (Readers of the New Yorker may recall an article on the topic a few years ago by Burkhard Bilger, featuring Shortz, Payne, and Ripstein, among others. I'm guessing that Bilger's loving portrait may have served as an inspiration for Creadon's film.)
A screening at Sundance of course doesn't immediately translate into a distribution deal so that the rest of us can see it, but there are some hopeful signs that the film could be alluring to movie distributors. Spellbound and Word Wars have already proved the marketabilty of the word-nerd genre. But Wordplay has something that neither of those documentaries has: star power. According to Payne, Creadon interviewed "a number of big-name celebrities." Cagily, he adds, "I won't spoil the surprises, but when I say big, I mean BIG. No, bigger than that." So that might be just the enticement distributors need to convince them to get the film into wider circulation.
I don't know if any Hollywood superstars will pop up, but I'll make an educated guess and say that Bill Clinton, a longtime fan of Will Shortz, will make an appearance in the film. Something tells me our current president would be slightly less likely to make a cameo.
[Update, 1/23/06: You can read about Wordplay's debut at Sundance here. Turns out I was right about Clinton.]
Wordplay Watch #2: The hunt for the ten-square
In other word-wrangling news, the Times of London has published an article on progress towards constructing a special kind of crossword called a word square, in which entries read the same across as down. The creation of a 10x10 word square (or "10-square") has been something of a holy grail in the field of recreational linguistics, also known as "logology" (a term coined by the late Dmitri Borgmann, author of the 1965 classic Language on Vacation and founder of Word Ways: The Journal of Recreational Linguistics). Ideally, one would want to construct the square using only entries found in a single dictionary, or, barring that, a small number of dictionaries and other English-language references. So far, only 9-squares have been composed meeting that standard of rigor.
The Times article reports breathlessly but rather incomprehensibly on the search for the 10-square. Confusion begins with the rambling headline: "'Su Doku' word game that baffled Ancient Greeks took an expert 7 years to crack — you've got 10 minutes (and a little help)." It's a real stretch to compare word squares to Sudoku, the number puzzle that has become immensely popular first in the U.K. and now in the U.S. (The article proudly but irrelevantly points out that the Times first introduced Sudoku to British readers.) Other than the fact that word squares and Sudoku puzzles are both arranged in square grids, they really don't have much in common.
Next is the business about the "ancient Greeks," which continues in the lead sentence: "A British engineer claims to have solved a puzzle that has counfounded some of the world's best brains since the time of the Ancient Greeks." There's no evidence that the composition of word squares, let alone 10-squares, was a pastime in ancient Greece. The Greeks did enjoy making acrostics, but that's a different kind of wordplay (despite the fact that the Times confusingly calls word squares "acrostic squares"). The ancient Romans, on the other hand, gave us the first known word square, the so-called sator square, found in the ruins of Pompeii and elsewhere:

This has the added virtue of being palindromic, as well as (supposedly) making an intelligible Latin sentence, something like "The sower Arepo holds the wheels with effort." (The Times confuses matters further by printing the sator square upside down, with rotas at the top.)
After we get through the befuddling opening of the article, we are told that Ted Clarke, an engineer from Cornwall, claims to have constructed the "best yet" 10-square. But his composition "does not satisfy some experts" who "say that because one of his words does not appear in any dictionary it should be disallowed."
Let's take a look at Clarke's creation (which the Times offers as a puzzle for their Sudoku-addled readers):
{kind=link}

First of all, it's unclear why the Times thought that this was at all newsworthy, considering that Clarke announced his discovery of the square back in April 1999, in an issue of his e-zine WordsWorth. The "seven years" that it took Clarke to construct it may have begun in 1992, but the Times never says. Secondly, though Clarke came enticingly close to an acceptable 10-square, the "word" that "does not satisfy some experts" doesn't even a resemble a word. It's NONESEVENT, which Clarke breaks down as nones-event, supposedly meaning an event taking place during the nones (on the Roman calendar, the ninth day before the ides of a month — that would be day 5 or 7, not the "end of the month" as the Times definition reads). Not only does this "word" not appear in any reference book, the collocation "nones event" hasn't been attested in any source outside of Clarke's own writings.
Clarke's square is just one in a long line of near-misses since Dmitri Borgmann and other logologists first started working on the 10-square problem. Personally I prefer some other attempts that have appeared in Word Ways (the best are by Jeff Grant and Rex Gooch). All of them have their shortcomings, such as using obscure toponyms or names from telephone directories, but I prefer obscurity to the utter spuriousness of nones-event. Clearly, as Jeff Grant and Ross Eckler (current editor of Word Ways and author of Making the Alphabet Dance) both say in the article, the search for an acceptable 10-square is far from over. [*]
One final source of bewilderment in the Times article: Tony Augarde, author of the Oxford Guide to Word Games, is quoted as saying:
It's not perfect but it's the best I've seen. Previous attempts used words that no one had heard of or tautonyms, words that repeat the same sound like orangutan, which made it easier.
Based on the inaccuracies elsewhere in the article, I'll give Mr. Augarde the benefit of the doubt and surmise that he was misquoted. Not only is orangutan not a tautonym (a word formed by reduplication), it's not even ten letters long! I believe that the confusion is over one of Dmitri Borgmann's early efforts, which used both orangutang and urangutang, plus eight tautonyms (actually five, since three are repeats):
ORANGUTANG
RANGARANGA
ANDOLANDOL
NGOTANGOTA
GALANGALAN
URANGUTANG
TANGATANGA
ANDOLANDOL
NGOTANGOTA
GALANGALAN
I don't have Borgmann's original work at hand to supply definitions for all of these (andolandol seems particularly obscure), but they were all located in English-language reference books. The big problem with Borgmann's approach is of course the repeated entries. But it's possible to construct a 10-square with eight tautonyms and no repeats, if it looks something like this:
ORANGEPEEL
RANGARANGA
ANDOLANDOL
NGOTANGOTA
GALANGALAN
ERANGEPEEL
PANGAPANGA
ENDOLENDOL
EGOTAEGOTA
LALANLALAN
This type of construction is probably insurmountably difficult using only English-language references, but I'd imagine it's possible in an Austronesian language like Malay/Indonesian where plurals and intensives are formed by reduplication. Any takers?
[* Update, 12/7/2005: Rex Gooch emails to note yet another inaccuracy in the Times article. He quotes Word Ways editor Ross Eckler as saying the following:
I was misquoted in the Dec 1 article by de Bruxelles in saying that the ten-square problem was "still waiting to be solved". I actually believe that various ten-squares published in Word Ways in the past four years essentially solve the problem; all words or names appear in standard English-language references. Allowing invented phrases has not been allowed, since it reduces a tough problem to triviality.
The Daily Mail also reports on Clarke's ten-square and observes that nones event isn't the only dubious entry in Clarke's square — states wren is also not attested in any known reference. These flaws put Clarke's square significantly behind the 2002 efforts by Gooch and Grant.]
Icelandic Studies Shifting to English?
The Iceland Review reports that Icelandic scholar Tryggvi Gíslason has proposed that courses in Icelandic mediaeval studies should be conducted in English. The reason? Over the past thirty years non-Icelandic scholars have come to dominate the field, but they are generally not able to present their findings or take permanent university positions in Iceland because they do not speak modern Icelandic sufficiently well.
This isn't an entirely unfamiliar development: there are other fields in which foreigners play a major, if not the major, role. Indeed, it is really what we should expect. So long as a field attracts the interest of outsiders, given that the number of outsiders is larger, often much larger, than the number of natives, statistically speaking we should expect to see foreigners play the larger role. Of course, disparities in access to education and interest in scholarship will affect the relative prominence of different countries, as will differences in access to important resources and motivation. No one should be surprised that Arabs are not prominent in glaciology or that few experts on camels are Scandinavian.
What is interesting here is that the subject in question is the sort that is often taken to be at the heart of the national character, one that only a native can fully appreciate. One hesitates to imagine the reaction to a proposal that French university courses on mediaeval French language, literature, and history should be conducted in English on the grounds that foreign scholars now dominate the field. I don't know if Tryggvi Gíslason is foolhardy or brave or if Icelanders are just so much more self-confident than most others that this proposal will not trigger the outrage that it would elsewhere.