October 31, 2006
If they do it too much, they should be told not to do it at all
Yes, I know: stated so baldly, this zero-tolerance policy (ZT-1) sounds extreme, not to mention unlikely to be effective unless constantly and severely enforced. Nevertheless, advisers on style sometimes end up following ZT-1, and also the related policy
ZT-1 is one of the factors that leads to the proscription Avoid Passive; student writers use passive clauses more than their teachers think they should, so they're told to avoid them wherever possible. ZT-2 is one of the factors that leads to the proscription Avoid Pronouns; student writers (well, actually, all writers) occasionally produce sentences with unclear or incorrect pronominal reference, so some teachers, remarkably, tell them not to use pronouns.
Recently it occurred to me that ZT-1 might be part of the history of what I have come to call Garner's Rule (after Bryan Garner, who is its most vigorous current exponent), proscribing sentence-initial linking however, as in "You may bring paper to the exam. However, you are allowed to bring only one page."
First, rather a lot of background about Garner's Rule. (And an acknowledgment: what I'm saying here represents joint work by me and Douglas Kenter.)
Garner gives a full statement of the rule in his 1999 book of advice for legal writers, The Winning Brief:
Replacing however by but is what he recommends first (and most often), so from here on I'll use "Garner's Rule" to refer to the stronger form:
Garner's Rule has a long history, going back at least to -- wait for it -- William Strunk Jr.'s 1918 Elements of Style, which says (as Mark Liberman and Geoff Pullum noted on Language Log a while back) sternly and uncompromisingly:
(The proscription is softened some in the later Strunk & White version: "The word serves better when not in first position.")
Garner's The Winning Brief assembles advice from over a hundred years that variously recommends using discourse connectives in general (certainly good advice), proscribes sentence-initial however, explains this proscription, argues that there's nothing wrong with beginning sentences with but (keep this in mind), and recommends a fix for sentence-initial linking however (usually either replacement by but or moving however inside the sentence).
So you're asking: What's wrong with sentence-initial however? Garner tells us, in his 1998 Dictionary of Modern American Usage, that it
The objection is aesthetic, a matter of personal taste and judgment. Garner finds sentence-initial however "ponderous" and "unemphatic", and a number of other writers agree with him -- for instance, Lucile Vaughan Payne, in her 1965 The Lively Art of Writing (cited by Garner in The Winning Brief), who disarmingly admits that it's all rather mysterious:
(Note the reference to student writers. I'll come back to that.)
However, still other writers have different tastes and (rightly) object to having their judgments dismissed by airy assertions about what sounds good, ponderous, or (un)emphatic. (I'm not much of a user of sentence-initial however myself, as I noted in an earlier posting, but I see no reason to impose my personal style on other people.)
Where do these aesthetic judgments come from? Mark and Geoff suggested that Strunk's stylistic preferences came from the writing he was exposed to as a young man. This makes sense; you develop your sense of style from the models around you.
You also develop your sense of style from explicit teaching and advice. Once a proscription against sentence-initial however was articulated, it had a life of its own and could be passed from one generation of writers and teachers, in communities of stylistic practice, to the next. Like other fashions in taste, it diffuses.
Is diffusion a sufficient explanation for the stylistic tastes of Garner and others? Maybe so, but I can think of two other factors that might contribute to a dispreference for sentence-initial however. Before I discuss them -- yes, we're going to get back to ZT-1 -- I want to take up, and dismiss, another argument against sentence-initial linking however that I've seen in net discussions: that it introduces an ambiguity.
The argument goes as follows: when you read a sentence beginning with however, or hear one, you don't know whether this is linking however or concessive however (as in "However you got that dog, you can't keep it" or "However many times you tell me that, I won't believe it"). So the sentence so far is ambiguous. On the other hand, initial but would be unambiguous. [Update: Bruce Rusk writes to point out that even this but is (temporarily) ambiguous, thanks to the fact that there's an exclusionary prepositional idiom but for 'if it weren't for the existence of', as in these contrasting pairs: "Writing well is not easy. But for grammarians it is impossible." (contrastive coordinating but) vs. "Writing well is not easy. But for grammarians, it would be impossible." (exclusionary prepositional but for). Potential ambiguity is everywhere.]
This is an extraordinarily silly argument. To start with, as long as the writer is punctuating properly, sentence-initial linking however is unambiguously signaled by a following comma, and in speech it's usually associated with the prosody that the written comma indicates. There's no ambiguity even at the first word. Then, once you get past the first word, any unsureness on your part as to which however was intended is quickly eliminated by the following material.
I believe that ambiguity-avoidance arguments for particular stylistic choices are always flawed, but this one is particularly lame, since a huge proportion of sentences begin with words whose identity can be determined only when the sentence is continued: "he's" could be "he is" or "he has", "that" could be a complementizer or a demonstrative, "is" could be copular be or the be of the progressive or the be of the passive, "later" could be an adjective or an adverb, and so on, endlessly. If we objected to this sort of local indeterminacy for a "however", we would be objecting to almost everything.
Now to two considerations that actually might contribute to a feeling against initial however.
The first consideration is a kind of "division of labor" argument for initial but over however. Here's how it goes:
2. The linker however can occur in either place.
3. The labor of signaling contrast could then be divided between the two linkers if however was restricted to sentence-internal position: but only sentence-initially, however only sentence-internally.
Ok, class, where have we seen this argument before? Yes, in Fowler's famous suggestion (we've now posted so much on the That Rule, or as I now prefer to call it, Fowler's Rule, that I hardly know which posting to link to, but here's one of my favorites) that the labor of signaling relative clauses might be divided between that and which:
2. The relativizer which can occur in either place.
3. The labor of signaling relatives could then be divided between the two relativizers if which was restricted to nonrestrictive relative clauses: that only in restrictives, which only in nonrestrictives.
Perfectly parallel reasoning in the two cases. If you're the sort of person who likes the division-of-labor argument for Fowler's Rule -- and a great many people do -- then you should also like that argument for Garner's Rule. I've never really understood why anyone would want to trade in variation for complementary distribution, so I don't buy the argument in either of these cases (or any others). But tastes evidently differ.
Finally, we get to ZT-1. Recall Payne's remark that student writers (she means, for the most part, college student writers) "invariably" put however in initial position. Other writing teachers have remarked to me that their students are very fond of however as a discourse connective, in particular as a marker of contrast, and that they almost always put it in initial position, and my own experience teaching accords with these observations. We could, of course, be wrong; possibly no one has studied the matter systematically, just because everyone is pretty sure what the facts are.
In any case, there seems to be a general belief among writing teachers that college students overuse initial however. This would lead them to be prejudiced against it and, in some cases, to advise their students not to use it at all. That's an instance of ZT-1.
I'll leave for a follow-up posting the question of why college students might like the discourse connective however so much -- there's a delicious irony in there -- and why they prefer it in initial position. If you are a college student yourself, you might think about your own practice and the reasons for it. If you have college students handy, you might ask them.
For now, I'll content myself with a few comments on zero tolerance policies, in general and with respect to stylistic choices.
Zero tolerance policies can be found many places: Alcoholics Anonymous and school drug policies, for example. They require enforcement, either informal (AA) or institutionalized (school drug policies), and it's not clear how effective they are in eliminating the targeted behavior. In the case of stylistic choices, the goal should really be not to eliminate one of the choices, but only to reduce its use, either in sheer frequency (in favor of a greater variety of choices) or in potentially problematic situations. ZT-1 and ZT-2 are overkill.
They are also almost surely ineffective, at least if the goal is to get the students writing clear, smooth, interesting prose. One easy response to a prohibition against initial however is to follow the strong form of Garner's Rule: whenever you find yourself tempted to begin a sentence with linking however, replace it with but. The result is that overuse of however becomes overuse of but. To my mind, this is no advance (and I'm a big but-user). Another easy response is to just delete the however, thereby much reducing the number of explicit discourse connectives, certainly not a result we want.
There are techniques that could be effective. A piano student who's inclined to overuse the sustain pedal -- it can cover a lot of finger sins -- might be told to play some pieces without the sustain pedal, either a few times or for some period, after which the sustain pedal is reintroduced. Similarly a sports player who's inclined to favor one particular move very heavily might be told not to use it, either for one practice or for some period, after which the ban is lifted. The aim is to expand a repertoire.
This could easily be done in writing classes: not a lifetime ban on initial however, but a short-term ban, during which alternatives are offered, perhaps even required: "Your essay must have at least two occurrences of sentence-initial but, two of sentence-internal however, and two occurrences of other discourse connectives". Writing teachers already give assignments that make the students follow special rules, requiring or prohibiting particular bits of form or content, either in their own writing or in editing material provided by the teacher. The discourse adverbial however could easily be folded into such assignments. (And probably has been, by teachers not totally under the sway of Garner's Rule.)
zwicky at-sign csli period stanford edu
Political correctness, biology and culture
Yesterday ("Two new reviews of Brizendine", 10/30/2006) I quoted Rebecca Young and Evan Balaban's description of a primal melodrama: "the foil of 'political correctness' against which the author wages a struggle for truth". Independent of the logical content of the debate over the biology and culture of sex differences, there is certainly also a larger ideological struggle, in which several intellectual armies have been campaigning for centuries. I mentioned one skirmish on one of the fronts of this war -- Paul Ekman's fight with Margaret Mead, Gregory Bateson and Ray Birdwhistell -- and promised to tell the story in another post. Here's the first installment: setting the stage for the battle.
In 1998, HarperCollins published a new edition of Charles Darwin's "The Expression of the Emotions in Man and Animals", with an Introduction, Afterword and Commentaries by Paul Ekman. Although Darwin's work is available for free on line (here, here, etc.), this book is worth buying for Ekman's additional contributions.
Ekman's Afterword is subtitled "Universality of Emotional Expression? A Personal History of the Dispute". It starts like this:
There is a story to be told. Not just the scientific story of how Darwin's views on expression were confirmed (or not) by research in the hundred years after his death. There is a story about how the clash of strong personalities, world politics, and the role of friendship and loyalty influenced the judgments of key figures in the scientific community. It is a drama that involves strong feelings and concealment, a drama not entirely over as I write, with the actors struggling over the ownership and interpretation of Charles Darwin's legacy about facial expressions of emotion.
Ekman explains that
I considered limiting myself to the scientific evidence, but if I had, readers might not understand what all the furor is about. The story involves more than Darwin's evidence, or evidence found since then. For readers to understand the controversy and make their own judgments, they need to know what is not in the scientific reports; they need to know the motives, history and social factors which influenced the principal antagonists. It was only a small group of actors. I was one of them, and I knew all the others, and am the only one still alive to tell this story.
The other key actors were Margaret Mead, Gregory Bateson, Ray Birdwhistell and Sylvan Tomkins. Ekman says of himself:
I am the last actor, entering this fray as an unknown scientist, half the age of each of these luminaries when I began my research on expression in 1965.
1965, when I started college, was a time when empiricist epistemology -- the view that what we think and feel is entirely a reflection of our experiences -- was still intellectually dominant. Ekman puts it this way:
Through the first half of this century, the behaviorists in psychology claimed that learning was responsible for all that we do and all that we are, including our attitudes and personalities. Individual differences could be wiped out if everyone had the same environment. THere would be no differences between men and women if they were only brought up in the same say. Parents were held responsible by psychiatrists for the neuroses and psychoses of their children. If they had acted differently, their offspring would be healthy, creative and productive. In education, differences in cognitive skills were attributed solely to poor schooling and impoverished home environments, with no acknowledgment that there might be inborn differences in kinds of intelligence. In anthropology, the cultural relativists triumphantly produced accounts of exotic cultures where people lived, mated and raised their offspring in ways so different from ours. The first half of the twentieth century was a time of optimism about the perfectibility of man. There was no acknowledged limit to how much human nature could be reconstructed by changing the environment. Change the state, educate the parents, modify child-rearing practices and we would have a nation of renaissance men and women. Nothing was innate. Our genes played no role in any of the differences in talent, ability or personality. Everything about our social lives was thought to be created by experience, and experiences could be changed and improved. As Margaret Mead put it in her book Sex and Temperament in Three Primitive Societies (published in 1935), 'We are forced to conclude that human nature is almost unbelievably malleable, responding accurately and contrastingly to contrasting cultural conditions.'
Ekman notes that "This one-sided viewed developed in part as a backlash against Social Darwinism, eugenics and the threat of Nazism", and quotes a passage from Margaret Mead's autobiography, where she explains that "we knew how politically loaded discussions of inborn differences could become ... [and so] ... it seemed clear to us that the further study of inborn differences would have to wait upon less troubled times".
Ekman's reaction to this ideological stance is mixed:
I sympathize with Mead's political concerns, but she had more than postponed the study of inborn differences. She had argued forcefully that biology played no role in human nature ... Her concern that racists would misuse evidence of biologically based individual difference led her to attack any claim for the biological basis of social behavior, even when biology is responsible for what unites us as a species, as in the case of univeral expressions of emotions.
For decades any scientist who emphasized the biological contributions to social behavior, who believed in an innate contribution to individual differences in personality, learning, or intelligence, was suspected of being racist. ... In that political climate the claim that facial expressions are the product of culture was accepted without evidence, but no one looked for evidence. It was obvious, it fitted so well with the reigning dogma.
Mead's student Ray Birdwhistell developed and applied the system of kinesics to describe body language, and he concluded (on the basis of microscopic analysis of very small samples of behavior from various cultures and contexts) that
As research proceeded ... it became clear that this search for universals was culture bound .. there are probably no universal symbols of emotional states.
Ekman observes that Margaret Mead prepared a 1955 edition of Darwin's Expression, in which she "included pictures from a conference on kinesics", and wrote an introduction in which she "did not say anything of Darwin's proposal that expressions are universal, nor did she mention the word 'emotion'."
Ekman concludes this section with a sentence that Geoff Pullum will appreciate:
I wonder how Darwin would have felt had he know that his book was introduced by a cultural relativist who had included in his book pictures of those most opposed to his theory of emotional expressions.
In a Language Log post a few days ago ("Embedded rhetorical questions", 10/29/2006), Geoff asked whether it's possible for "an interrogative content clause that [is] the complement of a verb like wonder [to have] rhetorical force". He proposed an artificial example, and asked readers to "send me good, clear, attested examples if you happen to spot them in texts or hear them viva voce".
I think it's clear that Ekman believes that Darwin would have indignantly repudiated Mead's introduction, and that he assumes that his sympathetic readers will believe the same thing. Thus his "I wonder how Darwin would have felt..." is actually an invitation to contemplate the way that he believes, and believes that we believe, Darwin would have felt.
Some other time , I'll sketch the fascinating scientific and personal story that unfolded on the stage that Ekman has set. For now, let me just observe that my favorite sentence, from what I've quoted so far, is this one -- presented here in a slightly abstracted form:
In that political climate the claim that ____ was accepted without evidence, but no one looked for evidence. It was obvious, it fitted so well with the reigning dogma.
Ironically, this is the same process at work when proponents of "the emerging science of sex differences" present traditional sexual stereotypes amid a flurry of irrelevant references to scientific publications. Political correctness serves no single master.
[The story continues here.]
Merely great, not unconscious
Linda Seebach reports what may be a new usage in the bad=good genre. This is from the Powerline blog ("The St. Louis Cardinals -- A Closer Look", 10/28/2006):
At the end of May, [St. Louis] had the best record in the National League. Pujols was unconscious; his numbers projected to 80 homers and 220 RBIs. He severely strained a muscle in his ribcage at the beginning of June and went on the DL. When he came back, he was merely great, not unconscious.
I've never seen this before -- if it's familiar to you, let me know.
It may be one of those sporadic, spontaneous value-inversions, like the use of "wicked retarded" that came up in an earlier LL post:
Last night the roomies and I went to Katie's for a potluck so good the food was wicked retarded. It was creepy how well everything went together everyone made dishes with fall veggies
[Update -- Jamie Dreier explains:
It's fairly common in sports talk. It's close to or synonymous with "playing over one's head". The idea is that your instincts take over, you aren't consciously controlling your movements.
My sense is that it's used more about basketball players than other athletes. Here's an example:
Not only were the Cavs a step slow, but the Pistons were playing unconscious basketball.
And from some "notes on teaching shooting to others":
You may have heard a player being referred to as "unconscious" while hitting shot after shot in a game. Great shooting has to be done from developed habits that don’t require mental preparation during the act. The game moves too fast. Habits formed for this level of use must be ingrained. This takes time, feedback, and success. A one-on-one situation allows the player to get a reaction from the teacher every time a shot is attempted. This is the fastest way to get results.
I've heard this kind of thing in basketball contexts. But from the Powerline example, it seems that the meaning has been generalized from "playing with instinctive skill" to "playing uncannily well", or something like that.
And Leigh Hunt adds:
I've seen and heard this before. I also found a relevant hit searching for "sports 'played unconsciously'".
The usage seems to reflect the contemporary sporting belief that athletes perform best in "the zone," which is supposed to be, as best I can make out, a mental state in which high-level thought yields to a kind of effortless intuition. That is, it's quite unlike "wicked retarded" in that the meaning of the negative-sounding word hasn't changed all that much--it's more that bad really is good in the given context.
Yes, I agree that this is not a bad=good example after all -- it's a different sort of semantic shift.
And not a recent one, either -- Roger "Unconscious" Shuy takes it back to neolithic times
It's not exactly clear to me what you (and Linda) find odd here. I don't take the meaning of "unconscious" as bad, since high school I've heard this to mean something really good in certain contexts, especially sports. In one school basketball game back then, for some reason every shot I took went in the basket. The coach called me "unconscious Roger" and told me to keep on doing whatever it was I was doing. He meant that I was "in a zone," using today's language for the same or similar things (unfortunately I never managed to be unconsciously good again). To be unconscious seems to mean that you can do everything right without thinking about it. Pujols is a great hitter who, at the beginning of the year, was even better, unconscious that is. Even when merely good, he's great. So I took this contrast about Pujols to be between greater (unconsciously so) and great (less so).
But then Ben Zimmer comes back with this:
I think there might actually be a family resemblance between the sports usage of "unconscious" and your "wicked retarded" example. They could be thought of as members of a larger category of approbative terms having to do with the loss of rational faculties. One could trace this category back to the "hot" jazz era of the '20s-'30s -- think of "mad" or "(stone) crazy" as terms of approbation. The lineage continued through to the hiphop era of the '80s and onwards, which has given us "ill", "sick", "stupid", "retarded", etc. In musical contexts, such terms often relate to an ethos of improvisation, as found in both hot jazz and hiphop freestyling: true creativity can only be achieved by letting go of cautious, studied technique. "Unconsciousness" in basketball or other sports would seem to mirror this abandonment of calculated effort.
]
[ And Darryl writes in with evidence to support Ben:
A possible source for wicked retarded might be related to the partying. In that context "retarded" has a meaning derived from its original meaning: "get retarded" means to dance in an uncontrolled though not swift manner, perhaps remeniscent of a seizure, hence "retarded". It's easy to see how that could be extended to mean that a party was wild ("it was retarded"), then from that it's easy to get "awesome" from it as well.
Black Eyed Peas, "Let's Get Retarded"
We got five minutes for us to disconnect from all
intellect and like the ripple effect
Bout' to lose her inhibition. Follow your intuition.
Free your inner-soul and break away from tradition.
...
Lose control, of body and soul.
Don't move too fast people, just take it slow.
...
Lose control, of body and soul.
Don't move too fast people, just take it slow.
...
Lose your mind this is the time,
Y'all test this drill, Just and bang your spine.
(Just) Bob your head like epilepsy,
up inside your club or in your Bentley.In the same song there's a number of references to not being consciously dancing or being in complete control of your movements, very similar to the use of "unconscious" in sports. BEP makes further analogy, using stupid ("stoopid"), cukoo, and ignorant ("ig'nant"), as well as the unrelated "hectic", to mean the same thing.
Also worth noting is that for a while now hip hop artists, BEP included, as well as Busta Rhymes, have used "break your neck" to mean bobbing your head while dancing, or perhaps dancing in general.
]
October 30, 2006
The Book of Lost Books
It's not all snarking here at Language Log Plaza. Sometimes we want to tell you about admirable things, or just explore data. Today I'm here to appreciate Stuart Kelly's The Book of Lost Books: An Incomplete History of All the Great Books You'll Never Read (Random House, 2005), a wry account of books destroyed, misplaced, never finished, or never even begun. From far ancient times to Sylvia Plath and Georges Perec, books have been wiped out by their authors (or their families), through accident or forgetfulness, and (far too often) in the purifying fire of ideology.
With considerable learning, Kelly covers high culture in the literate world, from Greece and Rome through China, India, the Arabic lands, Japan, later Europe (including Russia), and the U.S. (Nothing from Canada, Latin America, Africa, or Australia.) It's mostly a tale of monstrously ambitious men; of the 79 named authors, only four are women (and though you can be expected to have heard of Sappho, Jane Austen, and Sylvia Plath, you've probably never come across Faltonia Betitia Proba, from whom only one poem survives, and that's a cento, a pastiche of lines from other writers), and the women are not notably over-reaching, while most of the men had over-sized egos and aims, which of course gives something of an edge to the narratives.
Here are seven bits that caught my eye.
1. Ovid and linguistic field work:
2. Milton misplaced;
Our forgetful authors.
3. Gibbon and the great work of his life:
Earlier, visiting Rome, he had entertained the idea of writing about the decline and fall of the city. After the Swiss debacle, he returned to the Roman project, now expanded to the whole empire. Bingo.
I can't read this without a shiver. Not to mention some anxiety about whatever happened to various manuscripts of mine that never found a publishing source.
4. Scott I, the unpersuadable:
"No persuasion could arrest him" is delicious, not the least for being entirely comprehensible while also being well off the idiom of modern English.
There were two works, both still (sort of) extant in manuscript, though John Buchan in his life of Scott prays that "it may be hoped that no literary resurrectionist will ever be guilty of the crime of giving them to the world."
5. Scott II, the punctuation-free:
Omit needless words!
Relying on printers to supply punctuation is a remarkable touch. [Update: As Andrew Gray tells me, not so remarkable at all, but fairly common 18th-century practice. Authors could have a chance at fixing spelling, punctuation, and capitalization once the compositors were done with their work, but probably many did not bother.]
6. Austen begs off a task:
Jane Austen is invited by James Stanier Clarke, the prince regent's librarian, to write (following a plot outline he proposed) The Magnificent Adventures and Intriguing Romances of the House of Saxe Coburg. She demurs:
"Gloriously arch, and daringly candid", Kelly says.
7. Flaubert and taboo avoidance:
The scandale ensured healthy sales. (p. 271)
Well, of course.
[Update: Languagehat supplies a pointer to a remarkable lost book story, not in Kelly's book: Bakhtin smoking his own manuscript -- using (up) its pages as cigarette papers!]
zwicky at-sign csli period stanford period edu
Stupid timewasting insincere voicemail blather
I just called the number of an office whose identity will not be revealed because they definitely should have been open till 12 noon and not gone to lunch early, and I got the familiar slow, time-wasting, prerecorded voice ("You have reached the office of the Division of Humanities here at the University of California, Santa Cruz..."), and I was reminded of something about voicemail systems: every occurrence of "You have reached" that begins a phone conversation is a lie.
John Q. Smith at Allied Enterprises never picks up his phone and says "You have reached the desk of John Q. Smith at Allied Enterprises Incorporated, and I'm available to take your call right now." Whenever you are told over the phone that you have reached someone or something, you have not reached him or her or it.
But hey, you knew that already. You're just as irritated by voicemail as I am. I momentarily forgot that. Sorry. Just venting.
You have reached Language Log here at One Language Log Plaza, http://www.languagelog.com. Have a nice day.
By the way, people tell me I have a habit of lambasting things as
stupid and thus must be a very intolerant person. This charge is
stupi
totally unjust. I have never called anything stupid on Language
Log, except... well, let me see...
Stupid prophylactic public statement blather
Stupid wild over-the-top anti-linguist rant
Stupid time-wasting insincere voicemail blather
Stupid self-defeating warning label nonsense
Stupid machine-generated spiritual blather
Stupid title blather for language articles
Stupid bank transfer scam email
Stupid redundant warning blather
Stupid contentless political blather
Omit stupid grammar teaching
Stupid junk mail envelope blather
Stupid fake pet communication tricks
Well, all right, there have been just a very few exceptions. So who died and left me the job of being Mr Tolerant about everything, huh?
Two new reviews of Brizendine
Two very skeptical reviews of Louann Brizendine's The Female Brain have recently appeared, both under cleverly impolite headlines.
Rebecca M. Young and Evan Balaban (or the editors of Nature) make a pun on "psychoneuroendocrinology", titling their review "Psychoneuroindoctrinology" (Nature 443(7112), p. 634, October 2006). Young and Balaban are brutally critical: they say that the book "fails to meet even the most basic standards of scientific accuracy and balance", "is riddled with scientific errors", and "is misleading about the processes of brain development, the neuroendocrine system, and the nature of sex differences in general". Perhaps their most important single point is this:
Human sex differences are elevated almost to the point of creating different species, yet virtually all differences in brain structure, and most differences in behaviour, are characterized by small average differences and a great deal of male–female overlap at the individual level.
I've made free to put a copy of this review on the Language Log server, since I believe that a much broader audience will be interested in this topic than those who can justify the $199/year that I pay to subscribe.
Liz Lopatto's review in Seed Magazine has been given an even more startlingly impolite headline: "The Female Brain Fart". Lopatto went beyond checking Brizendine's references: she called up some of the cited authors, who said things like "My data don't speak at all to whether or not girls are compelled from an early age to attend to faces" (Erin McClure), and ""There is nothing in my study that seems to warrant this reference" (Ron Stoop).
Lopatto also links to a list of sexual biology posts on Language Log ("David Brooks, Neuroendocrinologist"), and then creates a sort of virtual debate between Dr. Brizendine and me:
Brizendine said, via email, that she inserted citations in order to "provide a resource for those young researchers and students who wanted to go deeper into the field of gender-specific biology," rather than to assert something conclusive.
But Liberman suggests these references actually serve to present her as an authoritative voice. While scientists publishing the results of their research in journals are held to rigorous standards of peer-review, the standards for popular science books are much more lax, Liberman said. He said he finds it disturbing that Brizendine chose to invoke the scholarly form of using citations.
"Brizendine and other authors like Leonard Sax,"—a physician and author of the 2005 book Why Gender Matters—"are interesting in that they have quite an elaborate scholarly apparatus: They have endnotes and extensive bibliographies," he said. "There's a substantial amount of credibility from credentials and employment, and the long list of references and footnotes present a certain impression about the solidity of the assertions that are made: This is not just an opinion and not just the opinion of an expert, but the backed-up opinion of an expert."
To avoid a possible misunderstanding, let me explain that I don't "find it disturbing that Brizendine chose to invoke the scholarly form of using citations". I think it's a Good Thing for works of popular science to cite their sources. What bothered me was the fact that she -- like Leonard Sax and some other writers on this topic -- cites sources that are irrelevant or even contrary to the specific (controversial or false) assertions in the text.
[By the way, I may be too old-fashioned, but I thought that Seed's headline was inappropriate. This is partly because the scatology seems like a cheap shot, but also because none of the meanings of the term "brain fart" really seems to fit this case. Sources on the internet offer glosses such as "A lapse in the thought process; an inability to think or remember something clearly" (Wiktionary); "The actual result of a braino, as opposed to the mental glitch that is the braino itself. E.g., typing dir on a Unix box after a session with DOS" (Jargon File); "An inelegant way of saying, 'I forgot,' it refers to your mind going blank. Someone may say, 'Sorry, I just had a brain fart.' It can also refer to a situation in which someone speaks 'out of turn,' especially to a superior. For example, if you march into your boss's office and speak your mind without first thinking about the possible consequences, you've just had a brain fart." (NetLingo); "Quick-and-dirty creative output. The byproduct of a mind stuffed with food for thought that can therefore produce information without effort." (WordSpy). Only the last of those has any plausible connection with Brizendine's book -- its problems appear not to be due to forgetfulness or lapses in thought, but rather to the elevation of ideology over science, and to something between sloppiness and misrepresentation in the use of references.]
I'll close with the ending of the Young and Balaban review, which expresses the culture-wars aspect of this issue clearly:
Like other popular books on the biology of human nature, The Female Brain has a rigid plot line: the foil of 'political correctness' against which the author wages a struggle for truth. We are told that the media, feminists, pointy-headed intellectuals and a vaguely specified 'culture' dogmatically insist that gender or racial differences in personality and behaviour are entirely cultural, an observation that is hard to reconcile with the volume and tone of media attention to the biology of gender and sexuality. [...]
Ultimately, this book, like others in its genre, is a melodrama. Common beliefs are recast as imperilled and then saved. Stark, predictable protagonists (an initial "cast of neuro-hormone characters" that reads like a guide to astrological signs) interact linearly with foreseeable results. The melodrama obscures how biology matters; neither hormones nor brains are pink or blue. Our attempts to understand the biology of human behaviour cannot move forward until we try to explain things as they are, not as we would like them to be.
That melodramatic plot line is sometimes a true picture of the situation -- certainly there are plenty of people who deny any human sex differences in cognition as a matter of ideological commitment rather than empirical fact -- and so perhaps there is a bit of truth in this aspect of the story told by Brizendine, Sax and others. The clearest example of such a melodrama that I know about was Paul Ekman's struggle, against the likes of Margaret Mead, Gregory Bateson and Ray Birdwhistell, to establish that human facial expressions are not socially constructed. But that's a topic for another post.
October 29, 2006
Embedded rhetorical questions
Ivano Caponigro gave an excellent talk to my university's Department of Linguistics last Friday (abstract available here). The subject was rhetorical questions. Ivano was concerned to explicate the view that the hallmark of a rhetorical question is (roughly) that its answer is not just known (or believed) but mutually known (or believed) by the participants (the utterer and the addressee). The lively discussion that followed developed a case that this needs to be rendered a little more subtly to allow for situations like (for example) a disingenuous speaker among a group of hypocrites uttering "Would any of us here today ever tell a lie?" can be a rhetorical question, inviting the answer "No, of course we wouldn't", even if the speaker knows darned well he told a lie just this morning; what is important is not that utterer and addressee should actually believe (let alone know) that the answer is in the negative, but that the intent of the question is to provoke an admission of general agreement (even if insincere) to the effect that the answer is in the negative.
That sort of stuff was the main drift of the talk and the question period. But one other point that came up briefly was Ivano's claim that you can embed rhetorical questions — an important point for his thesis that rhetorical questions are absolutely not to be understood as "really" expressing statements (a wrong-headed view that some have advanced). There was some demurral at the embedding claim; not everyone seemed to be in full agreement. I think Ivano is exactly right, though. An embedded interrogative clause (an interrogative content clause in the terminology of The Cambridge Grammar) can have the force of a rhetorical question. I mention the point here so that readers who think they can find good attested examples of this can send them to me (mail pullum at gmail.com). In what follows I will show the flavor of what I think is possible by citing a couple of constructed examples.
Imagine someone addressing a city council meeting in Santa Cruz, arguing that the city is being unfair in its enforcement of the ordinance forbidding people to sleep in a motor vehicle (along with other kinds of illicit camping within the city limits: the target is of course homeless people):
I feel I want to ask how many rich people this law has ever been applied to.
The point is that the speaker's aim, pragmatically, might not be in any sense be to ask the question that the underlined part expresses, or to wonder about what the answer to it might be, or to express the feeling of wanting to ask it. The speaker knows full well that the city has never once hauled a millionaire into court for dozing in his Lincoln Town Car while parked on West Cliff Drive after a nice dinner at Casablanca, and they know the speaker knows that, and they know the speaker knows they know, and so on. It's got the characteristics of rhetorical questions in the strongest form. The pragmatic point is to draw attention to the fact that everyone knows what the answer is, and to bring out a comforting chorus of "Hear, hear!" in agreement among the general public in the audience.
During the discussion Ivano admitted that it was hard to imagine an interrogative content clause that was the complement of a verb like wonder having rhetorical force; but I don't think he needed to make that concession. I think we can contextualize that too. Imagine a Republican candidate for Congress making a stump speech and saying this:
I'm wondering what the Democrats think Iraq would be like a month from now if we brought all our troops home today.
Everybody knows what Iraq would be like a month from now if all American troops were home by tonight. It would be the scene of a bitter and massively violent civil war between Shiite and Sunni Muslims, probably also involving the Kurds. And you can imagine the candidate knowing that everyone agrees on that point. The force of the underlined clause can be that of a rhetorical question — the intent being not to raise the question for discussion but to put out on the table the fact of the general agreement concerning what the answer is.
So that's my view: the Caponigro claim that there can be rhetorical embedded interrogative clauses is correct, possibly even more so than he thought on Friday. Do send me good, clear, attested examples if you happen to spot them in texts or hear them viva voce.
Two meta-snowclones
Arnold Zwicky points us to yesterday's Zippy the Pinhead:

And Jennifer Leo writes that
In the September-October 2006 issue of mental_floss, an article on animal learning included the gem that "rats have about as many ways of avoiding poison as Eskimos have of denying that myth about words for 'snow.'"
Finding the truth by compiling a list of falsehoods
I hear rumors that Language Log has been giving linguists a reputation for cynicism. Being myself a positive and even enthusiastic person, I prefer to think of this as the regrettable by-product of a commitment to scientific methods, as discussed in an earlier post "Hungarian speech rate and the tribunal of revolutionary empirical justice" (10/16/2006). But the modern culture of rational inquiry has roots in the humanistic tradition as well. I recently learned something new about this, which I thought I'd share with you.
In 1692, Pierre Bayle announced his intention to "compile the largest possible collection of mistakes that can be found", as a method for finding truth by exclusion:
[S]i par example j'étois venu à bout de recueillir sous le mot Seneque, tout ce qui s'est dit de faux de cet illustre Philosophe, on n'auroit qu'à consulter cet article pour savoir ce que l'on devroit croire, de ce qu'on liroit concernant Seneca dans quelque livre que ce fût: car si c'étoit un fausseté, elle seroit marquée dans le recueil, & dès qu'on ne verroit pas dans ce recueil un fait sur le pied de fausseté, on le pourroit tenir pour veritable.
If for example I had come to the end of collecting, under the word Seneca, everything false that is said about this illustrious philosopher, one would need only to consult this article in order to know what one should believe, of what one might read about Seneca in whatever book it might be: for if it were a falsehood, it would be listed in the collection, but given that one did not see a fact in this collection under the heading of falsehood, one could take it for the truth.
(from Project d'un Dictionaire Critique, 1692)
This struck me at first like a typical example of enlightenment naiveté, but then I thought: snopes.com.
And according to the entry for Pierre Bayle in the Stanford Encyclopedia of Philosophy, "for a century he was one the most widely read philosophers ever. In particular, his Dictionnaire historique et critique was the single most popular work of the eighteenth century." It's not clear to me whether this means "the single most popular work of philosophy", or "the single most popular work, period" -- and in either case, I don't know how to check the assertion, since Pierre Bayle died in 1706, and snopes.com doesn't evaluate legends about 18th-century book sales.
One small piece of positive evidence: Thomas Jefferson's 1771 list of recommended books for starting a library, sent to his brother-in-law Robert Skipwith, does include "Bayle's Dictionary. 5 v. fol. pound 7.10." under the heading History. Antient. (£7.10 was a lot of money in 1771, when a teacher in England made about £16 a year, and a "high-wage" government employee about £100, according to Jeffrey G. Williamson, "The Structure of Pay in Britain, 1710-1911", Research in Economic History, 7 (1982), 1-54. quoted here. Certainly Bayle's Dictionary is the most expensive item in Jefferson's list, outranking "Blackstone's Commentaries. 4 v. 4to. pound 4.4", and " Cuningham's Law dictionary. 2 v. fol. pound 3", and "Voltaire's works. Eng. pound 4.")
All the same, I'll confess that I'd never heard of Bayle, before reading chapter seven of Anthony Grafton's The Footnote: A curious history (1997), which devotes a chapter to Bayle's Dictionaire Critique as one of the origins of the modern footnote. Grafton dates the invention of the modern citation by quoting a mid-18th-century letter from Hume to Walpole, apologizing for "my negligence in not quoting my authorities", since "that practice ... having been once introduc'd, ought to be follow'd by every writer". Grafton comments:
This clue, the most precise we have yet turned up, indicates that we should look for the origins of the historical footnote a generation or two before Hume -- sometime around 1700, or just before. And in fact, as Lionel Gossman and Lawrence Lipking have pointed out, one of the grandest nd most influential works of late seventeenth-century historiography not only has footnotes, but largely consists of footnotes, and even footnotes to footnotes. The vast pages of that unlikely best-seller, Pierre Bayle's Historical and Critical Dictionary, offer the reader only a thin and fragile crust of text on which to cross the deep, dark swamp of commentary.
The description of Bayle's Dictionary in the Stanford Encyclopedia continues:
The content of this huge and strange, yet fascinating work is difficult to describe: history, literary criticism, theology, obscenity, and much more, in addition to philosophical treatments of toleration, the problem of evil, epistemological questions, and much more. His influence on the Enlightenment was, whether intended or not, largely subversive. Said Voltaire: “the greatest master of the art of reasoning that ever wrote, Bayle, great and wise, all systems overthrows.”
The BNF's Gallica project offers scanned copies of several of Bayle's works, including the 1692 Projet et fragmens d'un dictionnaire critique, and a later 16-volume version of the whole work, as expanded by others.
Bayle's 1692 Projet (in the form of a letter to "Mr. du Rondel, Professeur aux Belles Lettres à Maestricht") seems to me to present his personality very vividly. This is someone who would have loved to live in the 21st century, and someone I would have enjoyed knowing. So I typed in a couple of segments -- one from the beginning, and one from the middle -- to give you the flavor.
Here's a quick and careless translation of one characteristic passage::
After having read the critique of a work, we feel disabused of several false facts that we took for true in reading it. We thus change from affirmation to negation; but if we happen to read a good response to that critique, we will certainly return in certain things to our original affirmation, while on the other hand we turn to the negation of other things, which we had believed on the testimony of the critique. We experience a similar change, when we come to read a good reply to the response. Now, isn't this likely to throw most readers into continual mistrust? Who will not be suspected of falsehood, by those who don't have in their hand the key of the sources? If an author puts things forward without citing where he got them from, we can believe that he speaks only from hearsay; if he cites sources, we fear that he may report the passage badly, or that he understood it badly, since we always learn by reading a critique, that there are many similar faults in the book that is criticized. What should we do then, to remove all these reasons for mistrust, since there are so many books that have never been refuted, and so many readers who don't have the books containing the rest of the literary disputes? Shouldn't we wish that there were in the world a Critical Dictionary that we could refer to, in order to ensure that what we find in the other collections, and in every other sort of book, is truthful? This would be the touchstone of other books, and you know a man (a bit precious in his language) who will not miss the chance to call this work The Insurance Company of the Republic of Letters.
In later years, this role was taken up by the encyclopedia and the public library; today, by the internet.
Here's the longer selection that I (carelessly) typed in -- I don't have time to translate the rest:
Monsieur,
Vous serez sans doute surpris de la resolution que je viens de prendre. Je me suis mis en tête de compiler le plus gros recuiel qu'il me sera possible des fautes qui se rencontrent dan le Dictionaires, & de ne me pas renfermer dans les espaces, quelque vastes qu'ils soient, mais de faire aussi des courses sur toutes sortes d'auteurs, quand l'occasion s'en presentera. Quoy, direz-vous, un Tel de qui on attendoit toute autre chose, & beaucoup plûtôt un Ouvrage de raisonnement, qu'un Ouvrage de compilation, va s'engager à une entreprise où il faudra faire plus de depense de corps que d'esprit; c'est une très fausse demarche. Il veut corriger les Dictionaires; c'est tout ce que luy auroient pu prescrire ses plus malicieux ennemis, s'il avoient eu sur sa destinée le même pouvoir qu'avoit Eurythée sur celle d'Hercule; c'est pis qu'aller combatre le monstres; c'est vouloir nettoyer les étables d'Augias; c'est enfin la penitence que l'on devroit imposer à ses brouillions, qui ont abusé de leur loisir & de la credulité des peuples, pour annocer au nom & en l'authorité de l'Apocalypse toutes sourtes de chimeres, jussit quod splendida bilis. Je le plains; que ne laissoit-il cette occupation à ses robustes savans, qui peuvent étudier seize heures par jour sans prejudice de leur santé, infatigables en citations, & en toutes autres fonctions de Copiste, bien plus propres à faire savoir au public les choses de fait, que celles de droit?
[...]
Vous avez vû un reflexion que m'a fournie la lecture de quelques-unes de ces disputes, qui contiennent reponse, replique, duplique &c. en voicy une autre sortie de la même source. Après avoir lue la Critique d'un Ouvrage, on se croit desabusé de plusieurs faits faux, que l'on avoit pris pour vrais en le lisant. On passe donc de l'affirmation à la negation; mais si l'on vient à lire une bonne reponse à cette Critique, on ne manque gueres à l'égard de certaines choses de revenir à sa premiere affirmation, pendant que d'autre côté on passe à la negation de certaines choses, qu'on avoit crues sur la foy de cette Critique. On éprouve une semblable revolution, quand on vient à lire un bonne replique à la reponse. Or cela n'est il pas capable de jetter la plus grande partie des lecteurs dan une defiance continuelle? Qu'y a-t-il qui ne puisse devenir suspect de fausseté, à ceux qui n'ont pas en main la clef des sources? Si un Auteur avance des choses sans citer d'où il les prend, on a lieu de croire qu'il n'en parle que par oui-dire; s'il cite, on craint qu'il ne raporte mal le passage, ou qu'il ne l'entende mal, quis qu'on ne manque gueres d'aprendre par la lecture d'une Critique, qu'il y a beaucoup de pareilles fautes dan le livre critiqué. Que fair donc, Monsieur, pour ôter tous ces sujets de defiance, y ayant un si grand nombre de livres qui n'ont jamais été refutez, & un si grand nombre de lecteurs, qui n'ont pas les livres où est contenue la suitte des disputes literaires? Ne seroit-il pas à souhaitter qu'il y eût au monde un Dictionaire Critique auquel on pût avoir recours, pour être assuré si ce que l'on trouve dan les autres Dictionaires, & dans toute sorte d'autre livres est veritable? Ce seroit la pierre de touche des autres livres, & vous conoissez un homme un peu precieux dan son langage, qui ne manqueroit pas d'apeller l'ouvrage en question, La chambre des assûrances de la Republique de Lettres.
Vous voyez là en gros l'idée de mon project. J'ay dessein de composer un Dictionaire, qui outre les omissions considerables des autres, contiendra un recueil des faussetez qui concernent chaque article. Et vous voyez bien, Monsieur, que si par example j'étois venu à bout de recueillir sous le mot Seneque, tout ce qui s'est dit de faux de cet illustre Philosophe, on n'auroit qu'à consulter cet article pour savoir ce que l'on devroit croire, de ce qu'on liroit concernant Seneca dans quelque livre que ce fût: car si c'étoit un fausseté, elle seroit marquée dans le recueil, & dès qu'on ne verroit pas dans ce recueil un fait sur le pied de fausseté, on le pourroit tenir pour veritable. Cela suffit pour montrer que si ce dessein étoit bien executé, il en resulteroit un Ouvrage très-utile, & très-commode à toutes sortes de lecteurs. Je sens bien, ce me semble, ce qu'il faudroit faire pour executer parfaitement cetter entreiprise, mais je sens encore mieux que je ne suis point coapable de l'executer. C'est pourquoy je me borne à ne produire qu'une Ebauche, laissant aux personnes qui ont la capacité requise le soin de la continuation, en case qu'on juge que ce Projet, rectifié par tout où il sera necessaire, merite d'occuper la plume des habiles gens.
October 28, 2006
Evil
On Thursday, John Quiggin posted something at Crooked Timber about "European Russia". In the very first comment, "marcel" took him to grammatical task:
Reading recent posts, it’s clear nearly everyone here knows more about Eastern Europe than me,
“Than me???” C’mon John, even you know more (grammar) than that.
After another few comments, some of which were actually about the topic of John's post, "christopher m" invoked an old post of mine in John's defense:
Language Log on the “than I”/”than me” contretemps.
Linguist Mark Liberman’s conclusion (based on the most authoritative descriptive grammar of English in existence): “As is often the case with such prescriptions, the underlying grammatical analysis [that would hold ‘than me’ incorrect] is faulty.”
You can read the rest of the discussion yourself, if you want, but there was one bit of it that I found amusing. In comment #13, "dearieme" agreed with my conclusion while attacking my profession:
“than me” is not only legit, but surely massively preferable – who on earth invented the cock-and-bull story about a [do] that’s “understood”? “me and my girlfriend”, on the other hand, is tosh.
And who invented the linguists’ quasi-religious doctrine about its being evil to prescribe? And do they apply it when bringing up their own children?
I'll leave it to Arnold Zwicky to determine which self-appointed authority deserves the blame for first inventing the theory that English than never takes an immediate complement. But dearieme's questions about "the linguists" deserve an answer.
First, let me distance myself from the view -- religious or otherwise -- that it's "evil to prescribe".
- Sometimes, as in the "than me" affair, prescription is based on mistaken analysis, false history or bad logic. This is foolish, but it's not evil.
- In other cases, prescription is based on resistance to innovation. This is usually futile, but it's not evil.
- It's not clear whether discussion about performance errors of various sorts should be considered prescriptive, but it's certainly not evil. And linguists don't recommend performance errors, though we sometimes study them.
- Some prescriptive advice deals with style, tone, or communicative effectiveness. Advice of this sort may be right or wrong, useful or useless, but it's not evil. Here at Language Log,we often have advice of this kind to offer, though we're careful to distinguish linguistic norms from stylistic preferences.
- In our discussions of eggcorns, snowclones, overnegations, linguifications and so forth, it's clear that we're talking about violations of lexical, syntactic, semantic or stylistic norms. We don't recommend such violations, though we often enjoy them.
- Publications often choose a "house style" that prescribes what to do with possessive plurals and the like -- such style books disagree, and linguists (like other people) sometimes disagree with particular choices, but there's no evil here.
As for the role of linguistic prescription in "bringing up [our] own children", I feel that there's a mistaken assumption in dearieme's question. As far as I can tell, the way to help kids master the orthographic, lexical, grammatical and stylistic norms of English is to make sure that they have plenty of good examples to follow, and plenty of practice in following them. My own parents sometimes corrected my spelling and my typographical errors (this role has now been taken over by Geoff Pullum), and I can recall my mother occasionally making fun of a phrase that she thought was pompous or infelicitous, but for the most part, I learned the norms of English from reading and listening to writers and speakers that I saw as models worthy of imitation.
Teaching kids the skills of practical linguistic analysis is also probably a good thing. (And explicit instruction in spelling would surely have done me good.) But that's different from putting explicit "rules" at the center of the process -- I'm skeptical that this is either necessary or effective. And if the "rules" are the standard list of mistaken and incoherent prescriptivist bugbears, then ineffectiveness is the best you can hope for. Still, contemporary linguistic prescriptivism is not evil. Frequently foolish, usually futile, and often hypocritical, yes. Evil, no.
[Note: It's possible that "dearieme" is also a victim of the confusion that Geoff Pullum dissected in his 1/26/2005 post "'Everything is correct' versus 'nothing is relevant'".]
[Update -- Emily Bender writes:
I can think of one case where prescriptivism is evil, or at least is inspired by another evil (namely racism or classism): When speakers of minority dialects are told that their native varieties are illogical etc. because they don't conform to the (prescriptive) norms of the local standard, or worse, told that they themselves must be lacking in intellectual ability to be using such a variety. In such cases, prescriptive grammar becomes the handmaiden of institutionalized racism (or classism). It might not be the root of the evil, but it can be a means through which those in power belittle, demean or otherwise demoralize some segment of the population.
True. Though I'd question the use of the word "minority" here -- in most places and times, speakers of the favored, standard varieties of national languages have been a minority of the population, and usually a rather small one. At the risk of being prescriptive, let me suggest that we shouldn't generalize the recent usage of "minority" to mean "non-white" so that "minority" comes to mean "non-elite, common people", i.e. the majority. (More on the terminological issue here.) ]
October 27, 2006
Terrorists Target the CIIL
The Hindu is reporting that two Pakistani men arrested today as terrorists in Mysore planned to attack the Vikasa Soudha in Bangalore, a replica of the more famous Karnataka State capitol building the Vidhana Soudha that now houses the ministerial offices, and the Central Institute for Indian Languages in Mysore. I guess we should take this as a back-handed compliment - linguistics is important enough to be a target for terrorists.
Here at Language Log Plaza, where we use the grammatical function hierarchy rather than numbers or colors to denote threat levels, we are now at DEFCON "Indirect Object".
Envy, navy, whatever
 Consider the lead of a recent story by Celeste Biever, "It's the next best thing to a Babel fish", New Scientist, 10/26/2006 :
Consider the lead of a recent story by Celeste Biever, "It's the next best thing to a Babel fish", New Scientist, 10/26/2006 :
Imagine mouthing a phrase in English, only for the words to come out in Spanish. That is the promise of a device that will make anyone appear bilingual, by translating unvoiced words into synthetic speech in another language.
The device uses electrodes attached to the face and neck to detect and interpret the unique patterns of electrical signals sent to facial muscles and the tongue as the person mouths words. The effect is like the real-life equivalent of watching a television show that has been dubbed into a foreign language, says speech researcher Tanja Schultz of Carnegie Mellon University in Pittsburgh, Pennsylvania.
Existing translation systems based on automatic speech-recognition software require the user to speak the phrase out loud. This makes conversation difficult, as the speaker must speak and then push a button to play the translation. The new system allows for a more natural exchange. "The ultimate goal is to be in a position where you can just have a conversation," says CMU speech researcher Alan Black.
You might not guess from this -- or from the rest of the article -- that (a) the cited research does not make any contribution to automatic translation, but rather simply attempts to accomplish practical speech recognition in a single language from surface EMG signals rather than from a microphone; (b) the (monolingual) recognition error rates from EMG signals are now at least an order of magnitude worse than from microphone input, yielding from 20-40% word errors even on simple tasks with very limited vocabularies (16 to 108 words); (c) there are significant additional problems, including signal instability from variable electrode placement, which would cause performance in real applications to be much worse, and for which no solution is now known.
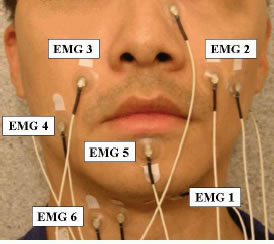
Several other news sources have picked up this story: (BBC news) "'Tower of Babel' translator made"; (BBC Newsround) "Instant translator on its way"; (inthenews.co.uk) "Device promises ability 'to speak in tongues'"; AHN: "Language Translator Being Developed by U.S. Scientists". (Discovery Channetl) "Scientists one step closer to Star Trek's 'universal translator'". As is often the case, the BBC will probably be the vector by which this particular piece of misinformation infects the world's news media. (See this link for an earlier example.) Especially interesting are the staged (or stock) photographs, with no visible wires, which the BBC chose to use to illustrate its stories (compare the picture above, which comes from one of the CMU researchers' papers):
 |
 |
Now the quoted people from CMU -- Tanja Schultz and Alan Black -- are first-rate speech researchers. I was at CMU 10 days ago, giving a talk in the statistics department, and I spent a fascinating hour learning about some of Alan Black's current work in speech synthesis. (I should really be telling you about that. Why have I let myself be tempting into cutting another head off of the science-journalism hydra? This is the occupational disease of blogging, I guess.) And Tanja and Alan really are involved in a team that has been doing great work on the (very hard) problem of speech-to-speech translation.
But these news stories -- like most science reporting in the popular press -- are basically fiction. This is not as bad as the cow-dialect story, in that there is actually some science and engineering behind it, not just a PR stunt. However, these stories give readers a sense of where the research team would like to get to, but no sense whatever of where the technology is right now, what contributions the recent research makes, and what the remaining problems and prospects are. It doesn't surprise me that the BBC uses the occasion as an inspiration for free-form fantasizing, but it's disappointing that New Scientist couldn't do better.
For those of you who care what the facts of the case are, here's a summary of two recent papers by the CMU group, along with links to the papers themselves.
The first one is Szu-Chen Jou, Tanja Schultz, Matthias Walliczek, Florian Kraft, and Alex Waibel, "Towards Continuous Speech Recognition Using Surface Electromyography", International Conference of Spoken Language Processing (ICSLP-2006), Pittsburgh, PA, September 2006.
This paper points out the first big challenge here:
EMG signals vary a lot across speakers, and even across recording sessions of the very same speaker. As a result, the performances across speakers and sessions may be unstable.
The main reason for variability across sessions is that the signals depend on the exact positioning of the electrodes. The CMU researchers didn't tried to solve this problem, but instead avoided it:
To avoid this problem and to keep this research in a more controlled configuration, in this paper we report results of data collected from one male speaker in one recording session, which means the EMG electrode positions were stable and consistent during this whole session.
The goal of the research reported in this paper was to compare the performance in EMG-based speech recognition of different sorts of signal processing. It's worth mentioning that more is required here than just to "simply attach some wires to your neck", as one of the BBC stories puts it:
The six electrode pairs are positioned in order to pick up the signals of corresponding articulatory muscles: the levator angulis oris (EMG2,3), the zygomaticus major (EMG2,3), the platysma (EMG4), the orbicularis oris (EMG5), the anterior belly of the digastric (EMG1), and the tongue (EMG1,6) [3, 6]. Two of these six channels (EMG2,6) are positioned with a classical bipolar configuration, where a 2cm center-to-center inter-electrode spacing is applied. For the other four channels, one of the electrodes is placed directly on the articulatory muscles while the other electrode is used as a reference attaching to either the nose (EMG1) or to both ears (EMG 3,4,5). [...]
Even so, they apparently needed to place eight electrodes to get six usable signals:
...we do not use EMG5 in our final experiments because its signal is unstable, and one redundant electrode channel ... has been removed because it did not provide additional gain on top of the other six.
The recognition task was not a very hard one:
The speaker read 10 turns of a set of 38 phonetically-balanced sentences and 12 sentences from news articles. The 380 phonetically-balanced utterances were used for training and the 120 news article utterances were used for testing. The total duration of the training and test set are 45.9 and 10.6 minutes, respectively. We also recorded ten special silence utterances, each of which is about five seconds long on average. [...]
So the test set was ten repetitions of each of 12 sentences. To make it easier, they limited the decoding vocabulary to the 108 words used in those 12 sentences:
Since the training set is very small, we only trained context-independent acoustic models. Context dependency is beyond the scope of this paper. The trained acoustic model was used together with a trigram BN language model for decoding. Because the problem of large vocabulary continuous speech recognition is still very difficult for the state-of-the-art EMG speech processing, in this study, we restricted the decoding vocabulary to the words appearing in the test set. This approach allows us to better demonstrate the performance differences introduced by different feature extraction methods. To cover all the test sentences, the decoding vocabulary contains 108 words in total. Note that the training vocabulary contains 415 words, 35 of which also exist in the decoding vocabulary.
The baseline system that they adapted to use surface EMG signals as input wa the Janus Recognition Toolkit (JRTk)
The recognizer is HMM-based, and makes use of quintphones with 6000 distributions sharing 2000 codebooks. The baseline performance of this system is 10.2% WER on the official BN test set (Hub4e98 set 1), F0 condition.
That's the published 1998 HUB4 evaluation data set and one of the conditions specified in this evaluation plan. They don't report how well their baseline acoustic recognizer did on the task they posed for the surface-EMG recognizer. Given that the acoustic system that has only a 10.2% Word Error Rate on a task with multiple unknown speakers and unlimited vocabulary, my guess is that in a speaker-trained test on sentences containing 108 words known in advance, its performance should be nearly perfect.
How did the surface-EMG-based recognizer do? It depended on the signal-processing method used, which was the point of the research. Here's the summary graph:
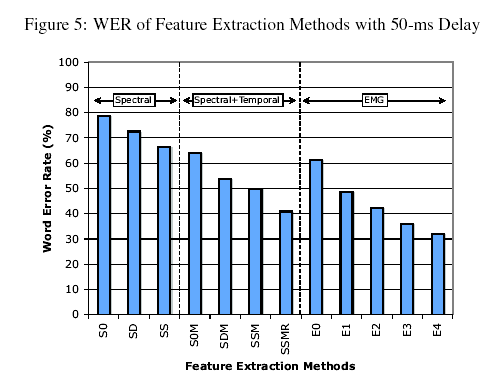
The underlying input in all cases was the set of signals coming from the surface EMG electrodes. The different bars represent the error rates given different kinds of signal processing applied to these signals. The details of the signal-processing alternatives are interesting (read the paper if you like that sort of thing, as I do), but the differences are not relevant here -- the point is that the best method they could find, adapted to the particular electrode placements of this experiment on this speaker, with decoding limited to the exact 108 words in the test set, had a word error rate of a bit over 30%.
What this shows, obviously, is that speech recognition from surface EMG signals is indeed a research problem.
Here's the second paper: Matthias Walliczek, Florian Kraft, Szu-Chen Jou, Tanja Schultz, and Alex Waibel, "Sub-Word Unit based Non-audible Speech Recognition using Surface Electromyography", (ICSLP-2006), Pittsburgh, PA, September 2006.
This paper looks at a variety of alternative unit choices for EMG-based speech recognition: words, syllables, phonemes.
To do this, the researchers
... selected a vocabulary of 32 English expressions consisting of only 21 syllables: all, alright, also, alter, always, center, early, earning, enter, entertaining, entry, envy, euro, gateways, leaning, li, liter, n, navy, right, rotating, row, sensor, sorted, sorting, so, tree, united, v, watergate, water, ways. Each syllable is part of at least two words so that the vocabulary could be split in two sets each consisting of the same set of syllables.
This time they used two subjects, one female and one male, and recorded five sessions for each speaker. Some limitations were imposed to make the task easier (for the algorithms, not for the speakers):
In each recording session, twenty instances of each vocabulary word and twenty instances of silence were recorded nonaudible. ... The order of the words was randomly permuted and presented to the subjects one at a time. A push-to-talk button which was controlled by the subject was used to mark the beginning and the end of each utterance. Subjects were asked to begin speaking approximately 1 sec after pressing the button and to release the button about 1 sec after finishing the utterance. They were also asked to keep their mouth open before the beginning of speech, because otherwise the muscle movement pattern would be much different whether a phoneme occurs at the beginning or the middle of a word.
The first phase of testing compared the performance of the different unit sizes and features:
First the new feature extraction methods were tested. Therefore, all recordings of each word were split into two equal sets, one for training and the other for testing. This means that each word of the word list was trained on half of the recordings and tested on the other half. After testing sets were swapped for a second iteration. All combinations of the new feature extraction methods were tested, a window size of 54 ms and 27 ms, with and without time domain context feature. We tested the different feature sets on a word recognizer, a recognizer based on syllables as well as phonemes.
The results?
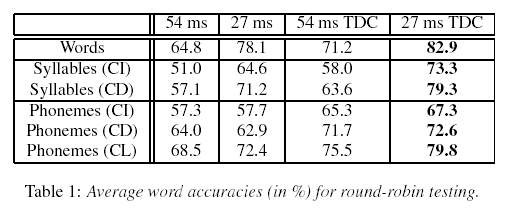
In other words, a speaker-dependent isolated-word recognition system, with a 32-word vocabulary, had a word error rate of about 20% using EMG signals as input. Again, the researchers don't tell us what a state-of-the-art acoustic system would do on this task -- my prediction would be an error rate in the very low single digits, roughly an order of magnitude lower than the error rate of the EMG system. Again, a demonstration that EMG-based recognition is a hard research problem -- much further from solution than an acoustically-based speech recognition, which is not an entirely solved problem either, as far as that goes.
The researchers then went ahead and tried a harder problem -- using the subword units to test words not in the training set:
While in the previous tests seen words were recognized, we test in this section on words that have not been seen in the training (unseen words). Therefore, the vocabulary was split into two disjoint sets, one training and one test set. The words in the test set consist of the same syllables as the words in the training set, so that all phonemes and syllables could be trained. For an acoustic speech recognition system training of phonemes allow the recognition of all combinations of these phonemes and so the recognition of all words consisting of these combinations. This test investigates whether EMG speech recognition performs well for context sizes used in ASR or whether the context is much more important and goes beyond triphones. To do so we tested both a phoneme based system and a syllable based system. While the syllable based system covers a larger context, the phoneme based system can obtain more training data per phoneme.
As expected, the results on unseen words were considerably worse -- around 40% word error rate on a 16-word vocabulary:
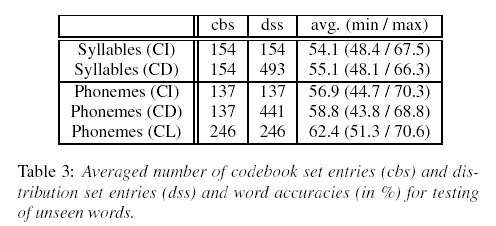
Here's the confusion matrix:
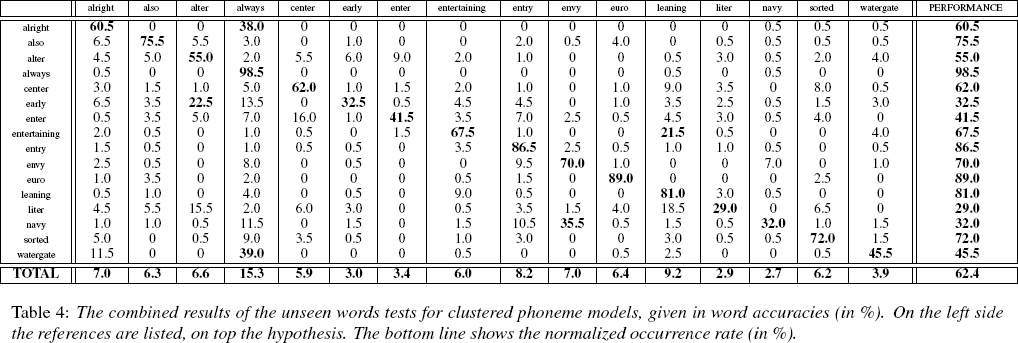
The researchers comment:
From the mapping between phonemes and muscle movements we derived that the muscle movement pattern for vocalizing the words navy and envy are quite similar (except the movement of the tongue, which is only barely detected using our setup). So the word envy is often falsely recognized as the word navy.
In an unlimited-vocabulary system, this effect will be multiplied many-fold -- leaving out the issues of stable electrode placement and acquisition of adequate training data. It's obvious that more research is needed, to say the least, before this system could be the front end to a communicatively effective conversational translation system.
[As I read the papers, the cited experiments don't test the EMG from subvocalizing -- silently mouthing words, much less thinking about silently mouthing words -- but rather the EMG generating while speaking out loud. I believe that EMG from subvocalizing will be more variable and thus harder to recognize. How much of a problem this might turn out to be is unclear.]
[Update -- Julia Hockenmaier writes, in respect to the New Scientist:
My flatmate in Edinburgh had a subscription, so I used to read this over breakfast. I don't recall ever seeing a computer-science/AI related article that didn't seem like complete fiction...
Oh well, I guess I was fooled by the packaging into thinking that this is a publication that takes science (and engineering) reporting seriously.]
[Update #2 -- Blake Stacey writes:
This may be germane to the recent talk around Language Log Plaza about New Scientist magazine, and in particular to Julia Hockenmaier's comment posted in the update. Recently, New Scientist drew a hefty amount of flak from the physics community for their reportage on the "EmDrive", the latest in a long series of machines which promise easy spaceflight at the slight cost of violating fundamental laws of nature. First to criticize the magazine was the science-fiction writer Greg Egan, whose open letter can be found here:
http://golem.ph.utexas.edu/category/2006/09/a_plea_to_save_new_scientist.html
The events which followed may be of interest to those who study how disputes unfold on the Internet. Since the discussion spread erratically around the blogosphere (touching also upon New Scientist's Wikipedia page), it is difficult to get the whole story in one place. I wrote up my perspective on the incident at David Brin's blog:
http://davidbrin.blogspot.com/2006/10/architechs-terrific-and-other-news.html
(Unfortunately, the Blogspot feature for linking directly to comments appears to be broken.)
]
October 26, 2006
The therapeutic power of rhyme
Two days ago, Scott Adams, author of Dilbert, reported some extraordinary news on his blog. Poetry has cured him. Not just any poetry, either, but rhymed and metered verse. Well, specifically, a nursery rhyme:
Jack be nimble, Jack be quick.
Jack jump over the candlestick.
Fans will be glad to know that those trochees haven't cured Scott's dyspeptic reaction to modern management, office politics, and the eternal cycle of suckers and cynics. Today's strip:

Rather, Adams was cured of an incurable disease: spasmodic dysphonia.
Here's Wikipedia on the syndrome:
Spasmodic dysphonia (or laryngeal dystonia) is a voice disorder characterized by involuntary movements of one or more muscles of the larynx ... during speech. Individuals who have spasmodic dysphonia may have occasional difficulty saying a word or two or they may experience sufficient difficulty to interfere with communication. Spasmodic dysphonia causes the voice to break or to have a tight, strained or strangled quality.
S.D. Schaefer, "Neuropathology of spasmodic dysphonia", Laryngoscope 93(9) 1183-204 (1983) describes it as "a devastating voice disorder of unknown etiology, with a variable clinical presentation and response to treatment", and suggests that is is "one of several spasmodic brain stem disorders with variable presentation which are known by the cranial nerve nuclei or pathways of major clinical involvement". T. Finitzo et al., "Spasmodic Dysphonia, Whether and Where", JSHR, 32 541-555 (1989), could identify no brain lesions in 16% of patients, with "isolated, multifocal, cortical lesions" in over 50%, "mixed subcortical and cortical pathology" in 25%, and only subcortical lesions in 7%. K.D. Pool et al., "Heterogeneity in spasmodic dysphonia", Archives of Neurology, 48(3) (1991) conclude that "spasmodic dysphonia is a manifestation of disordered motor control involving systems of neurons rather than single anatomical sites".
Adams explains that in some cases, including his, the symptoms depend on the type of speech and the context of speaking:
The weirdest part of this phenomenon is that speech is processed in different parts of the brain depending on the context. So people with this problem can often sing but they can’t talk. In my case I could do my normal professional speaking to large crowds but I could barely whisper and grunt off stage. And most people with this condition report they have the most trouble talking on the telephone or when there is background noise. I can speak normally alone, but not around others. That makes it sound like a social anxiety problem, but it’s really just a different context, because I could easily sing to those same people. [...]
The commonest therapy for spasmodic dysphonia is to paralyze the affected muscles with botulinum toxin, as Adams explains:
While there’s no cure, painful Botox injections through the front of the neck and into the vocal cords can stop the spasms for a few months. That weakens the muscles that otherwise spasm, but your voice is breathy and weak. [...]
I stopped getting the Botox shots because although they allowed me to talk for a few weeks, my voice was too weak for public speaking. So at least until the fall speaking season ended, I chose to maximize my onstage voice at the expense of being able to speak in person.
And here's how the poetry worked:
The day before yesterday, while helping on a homework assignment, I noticed I could speak perfectly in rhyme. Rhyme was a context I hadn’t considered. A poem isn’t singing and it isn’t regular talking. But for some reason the context is just different enough from normal speech that my brain handled it fine.
Jack be nimble, Jack be quick.
Jack jumped over the candlestick.I repeated it dozens of times, partly because I could. It was effortless, even though it was similar to regular speech. I enjoyed repeating it, hearing the sound of my own voice working almost flawlessly. I longed for that sound, and the memory of normal speech. Perhaps the rhyme took me back to my own childhood too. Or maybe it’s just plain catchy. I enjoyed repeating it more than I should have. Then something happened.
My brain remapped.
My speech returned.
Not 100%, but close, like a car starting up on a cold winter night. And so I talked that night. A lot. And all the next day. A few times I felt my voice slipping away, so I repeated the nursery rhyme and tuned it back in. By the following night my voice was almost completely normal.
When I say my brain remapped, that’s the best description I have. During the worst of my voice problems, I would know in advance that I couldn’t get a word out. It was if I could feel the lack of connection between my brain and my vocal cords. But suddenly, yesterday, I felt the connection again. It wasn’t just being able to speak, it was KNOWING how. The knowing returned.
I still don’t know if this is permanent. But I do know that for one day I got to speak normally. And this is one of the happiest days of my life.
It's always inspiring to hear good news, and this story has a bunch of extra feel-good dimensions: persistence in the face of adversity, curing the incurable by the power of poetry, creating new brain pathways by reactivating old memories, magical invocation of verses learned in childhood.
Adams' experience reminds me of a treatment for aphasia invented in the 1970s, "melodic intonation therapy".
Neurological researchers Sparks, Helm , and Albert developed melodic intonation therapy in 1973 while working with adults in the Aphasia Research Unit at the Boston VA Hospital (Marshal and Holtzapple 1976). MIT is based on the hypothesis of these researchers that “increased use of the right hemisphere dominance for the melodic aspect of speech increases the role of that hemisphere in inter-hemispheric control of language, possibly diminishing the language dominance of the damaged left hemisphere” (Marshal and Holtzapple 1976:115). In order to do this common words and phrases are turned into melodic phrases emulating typical speech intonation and rhythmic patterns (Davis et al. 1999, Marshal and Holtzapple 1976, and Carroll 1996). One study using PET (positron emission tomography) scans found that areas controlling speech in the left hemisphere were “reactivated” by the end of MIT.
That's P. Berlin et al., "Recovery from nonfluent aphasia after melodic intonation therapy: a PET study:", Neurology 47(6) 1504-1511 (1996):
Without MIT, language tasks abnormally activated right hemisphere regions, homotopic to those activated in the normal subject, and deactivated left hemisphere language zones. In contrast, repeating words with MIT reactivated Broca's area and the left prefrontal cortex, while deactivating the counterpart of Wernicke's area in the right hemisphere. The recovery process induced by MIT in these patients probably coincides with this reactivation of left prefrontal structures.
At the time MIT (= "melodic intonation therapy") was being developed at the Boston VA, I was a few miles away at MIT (= "Massachusetts Institute of Technology"), working on models of the rhythms and pitch contours of normal speech (The Intonational System of English, MIT dissertation, 1975). So when MIT failed to become a very widely used therapy, because it doesn't help all or even most aphasic patients, I was disappointed. Nevertheless, MIT sometimes produces remarkable results. (This is true under both interpretations.)
Perhaps whatever Melodic Intonation Therapy is doing, in the cases where it works, is similar to what Scott Adams accomplished for himself with his nursery rhyme. The usual way of reciting such poems is similar to the way that MIT turns "common words and phrases ... into melodic phrases emulating typical speech intonation and rhythmic patterns".
October 25, 2006
Margaret Atwood, alas
Wired magazine asked "sci-fi, fantasy, and horror writers from the realms of books, TV, movies, and games" to emulate Ernest Hemingway's six-word story ("For sale: baby shoes, never worn.").
Two are worth quoting:
Joss Whedon: "Gown removed carelessly. Head, less so."
Margaret Atwood: "Longed for him. Got him. Shit."
It seems odd to find Atwood categorized as a genre writer. Maybe the odd thing, really, is making the distinction in the first place. But I wonder, did Pynchon and Vonnegut turn them down?
Here's another short work by Atwood, a poem from Power Politics (1971):
you fit into me
like a hook into an eyea fish hook
an open eye
English in China
A letter from Victor Mair:
This past weekend I went to Kenosha, Wisconsin to participate in a China Studies Institute at Carthage College. It just so happened that while I was there I met 10 English teachers from the school system of Huairou District in China:
http://en.wikipedia.org/wiki/Huairou_District
The teachers were all female and they were in America on a three-week visit to Huairou's sister city of Kenosha. They were primary and secondary school teachers. One morning over breakfast, the women matter-of-factly informed me that all students in their district begin studying English in the first grade, and many start even in kindergarten. They went on to say that beginning English in the first grade is typical all over China, except in the most remote and backward places, where it might be delayed by a few years.
I will have more to say on this subject in the coming weeks and months. Judging from all that I have seen and heard during the last couple of years, however, it is apparent that the role of English in China will continue to grow at an exponential rate. The implications of this massive expansion of English in China will inevitably have a corresponding impact upon local language usage. In fact, the profound effects of the current surge in English usage upon Mandarin and other Chinese languages is already obvious in many respects.
And next, facial poo
Or maybe hand poo. In either case, hand milled, of course. Via Darth Spacey, my new favorite example of back-formation:

Meanwhile, in the opposite direction, Miles Lubin writes to observe that
A few weeks ago I caught myself saying "he got an ahundred on the test." It *sounded* perfectly fine at the time (and still does), but obviously it's not standard English. Today I heard a friend use the same phrase "got an ahundred," which for me promoted this personal observation into a phenomenon. I know there are previous examples of the indefinite article mixing with the noun, but I haven't seen this one documented anywhere.
Me either, but I agree with the intuition. I think I've also heard things like "it was an ahundred-degree day", or "I've got an ahundred-dollar bill says you're wrong."
I guess this has to do with the fact that you can count "..., ninety eight, ninety nine, a hundred, a hundred one, ..." so that "a hundred" can be interpreted by the "look-it-up" part of the brain as just another number.
But how to spell it? Miles' solution looks wrong, but "he got an a hundred" looks wronger. Well, just as wrong, anyhow.
October 24, 2006
Verbs are what make video games work
I'll bet you didn't know that. But then probably you don't think that verbs are the same thing as (violent) actions.
In "sex, lies, and video games" (The Atlantic Monthly, November 2006, p. 84), Jonathan Rauch writes about video game designers Michael Mateas and Andrew Stern:
Yup. Blowing shit up is just one of the verbs you can find in the typical video game.
Calling Dr. Words N. Things! Calling Doctor Words N. Things!
zwicky at-sign csli period stanford period edu
This post fails to connect the unconnectable
A reader has sent me a linguification that truly highlights the depths of the dumbness into which a writer is likely to descend when using this trope. (I can acknowledge him only as HL; the nature of his work means that his name cannot be disclosed here, so don't ask. But he makes almost all of the points that I present here.) The New York Times has a review by Janet Maslin of Stephen King's new book, and it opens with this sentence:
This sentence is about to do the unthinkable: connect James Joyce and Stephen King.
Now think about that for a moment.
Set aside the philosophical aspects of the self-reference here, because it's a red herring. The sentence is coherent, and has clear truth conditions. (It turns out to be false.) What is its pragmatic intent? The writer's goal is to express the extreme unrelateness of two things (the oeuvres of Joyce and King), and chooses to do it by the device of tacitly claiming instead that the words typically used to name these two things are rarely encountered in the same linguistic expression. Yet this very use of the device self-defeatingly demonstrates its strange hollowness, for it demonstrates that fitting the two names into the same sentence can easily be achieved without in any way associating the things or the concepts.
The sentence actually asserts nothing except that it is about to perform an unthinkable act of connection; but it doesn't perform it. The phrase "is about to" makes a reference to future time; but presumably the time referred to must be regarded as having ended when the sentence is over or when we have finished understanding it. The sentence concludes without any connection between James Joyce and Stephen King having been made, so the almost-empty self-referential claim about its own future is in fact a false claim. It may be compared with something like This sentence contains more than nine words, which by its own form guarantees that it cannot be true.
I suppose a desperate defender of Maslin's prose could say that her sentence is true in a sense: simply by putting the names of Joyce and King into the sentence together she has created one connection, in that we attentive readers will have connected the two named authors in our minds. Whatever concepts we may have of Joyce (Irish guy who wrote a book I never read that they once tried to ban) and King (horror novelist who was nearly killed by a truck near his home in Maine) will be connected for us in that we will have thought about them both in the same short period of time after reading their names. Well, yes, sort of. But if provoking a thought like "Janet Maslin has just told me falsely that the sentence I am now reading is about to establish a connection between A and B" really counts as connecting A and B, the notion of connecting two topics has pretty much been reduced to a triviality, has it not?
Maslin's sentence is a remarkable example of what I continue to find a baffling phenomenon. Figures of speech are generally used because they work. They do something for the exposition that would not otherwise be done quite so well. But linguification does not accomplish a writer's purpose in a better way than non-figurative devices. Often (as here) it appears to obstruct the writer's aims without succeeding in anything. Yet this perversely pointless trope seems to me to be gaining popularity in contemporary writing. I have no idea why.
Form, function and content
Over the past half century, our culture has moved about as far as it's possible to go in valuing content over form, and practice over analysis. At least, that's what you'd have to conclude from the way we teach reading, writing and speaking, both in English and in foreign languages. The fact that "grammar school" is now mostly grammarless is a symbol of this larger trend. And there's been a comparable long-term shift in the research and teaching that goes on in university departments of language and literature where (for example) it's not now expected that a specialist in poetry ought to be able to scan metered verse, or to analyze the phonological, syntactic or semantic structures of any sort of poetry at all.
Recently, I've seen a few signs that the cultural pendulum might have started to swing back towards the center. The most recent one was a story in yesterday's Washington Post (Daniel de Vise, "Clauses and Commas Make a Comeback", 10/23/2006), which features a teacher known as "Grammar Greiner":
Ten or 20 years ago, Greiner might have been ostracized for his views or at least counseled to keep them to himself. Grammar lessons vanished from public schools in the 1970s, supplanted by a more holistic view of English instruction. A generation of teachers and students learned grammar through the act of writing, not in isolated drills and diagrams.
Today, Greiner is encouraged, even sought out. Direct grammar instruction, long thought to do more harm than good, is welcome once more.
Of course, "grammar" for the purposes of this article seems to consist mostly of spelling, punctuation and the "correct" use of pronominal case in phrases like "it is I". But maybe that's just the reporter's take on the situation; and for a teacher to ask students to engage in any sort of analysis of any sort of linguistic form may be taken as a sign and a portent.
Another recent straw in the wind: Stanley Fish, who says provocative things like "meaning is always the enemy of writing instruction". Here's a characteristic sample, from his NYT blog, which is hidden behind the Times Select wall and thus not as widely read as it might be ("The writing lesson", 5/4/2006):
The focus of writing instruction should be form, and only form. The moment an idea or piece of content is allowed to take center stage (except as an illustration of an abstract formal operation) is the moment when the game is lost. Some readers of that Op-Ed piece were properly skeptical and feared that I was urging a series of arid exercises that could not possibly engage the interest of any student. I have not found this to be true. There is nothing arid about this way of teaching writing, although I acknowledge once again that the question of whether or not it actually does teach writing remains open. It should be noted that none of the more substantive, content-based approaches to the task seem to teach writing at all. We’ve now had decades of composition courses in which students exchange banal opinions about the hot-button issues of the day, and student writing has only gotten worse. Doesn’t it make sense to think that if you are trying to teach them how to use linguistic forms, linguistic forms are what you should be teaching?
There's a discussion of the cited op-ed piece, with a link to a durable copy of it, in an earlier Language Log post ("Blinded by content", 6/4/2005). However, Prof. Fish's writing lesson makes it clear that when he says "form", he actually means "function":
This week I spent a happy Tuesday afternoon doing one of the things I most like to do. I was teaching — or trying to teach— a student how to write. Success in this area comes hard. The occasion for the lesson was a final paper that displayed a range of organizational and grammatical problems. I always begin on the level of sentences, but early on, it became clear that this student, who had turned 31 the day before, didn’t have a firm grasp on what a sentence is. I gave him my standard mantra — a sentence is a structure of logical relationships — but that didn’t help. What did help — and usually helps, I find — is a return to basics so basic that it is almost an insult.
I asked him to write a simple three-word English sentence. He replied immediately: “Jane baked cookies.” Give me a few more with the same structure, I said. He readily complied but one of his examples was, “Tim drinks excessively.” The next 40 minutes were spent getting him to see why this sentence was not like the others (a kind of “Sesame Street” exercise), but he couldn’t do that until he was able to see and describe the structure of sentences like, “Jane baked cookies.”
I pointed to “baked” and asked him what function the word played. He first tried to tell me what the word meant. No, I said, the word’s meaning is not relevant to an understanding of its function (meaning is always the enemy of writing instruction); I want to know what the word does, what role it plays in the structure that makes the sentence a sentence and not just a list of words. He fumbled about for a while and finally said that “baked” named the action in the sentence. Right, I replied, now tell me what comes along with an action. Someone performing it, he answered. And in the sentence, who or what is performing the action? “Jane,” he said happily. Great! Now tell me what function the word “cookies” plays. Progress immediately stalled.
For a long time he just couldn’t get it. He said something like, “ ‘Cookies’ tells what the sentence is about.” No, I said, that’s content and we’re not interested in content here (content is always the enemy of writing instruction); what I want to know is what structural relationship links “cookies” to the other parts of the sentence. More confusion. I tried another tack. What information does “cookies” provide? What question, posed implicitly by another of the sentence’s components, does it answer? It took a while, but that worked. It answers the question, “What was baked?” he offered. Yes, I said, you’ve almost got it. Now explain in abstract terms that would be descriptive of any sentence with this structure, no matter what its content or meaning, the structural logic that links a word like “baked,” a word that names an action, to a word like “cookies.” More fumbling, but then he said “cookies” is what is acted upon. By God, he got it! It was only then that I told him that in the traditional terminology of grammar, the thing acted upon is called the object. Had I given him the term earlier, he would have nodded, but he wouldn’t have understood a thing. Now, he had at least the beginning of an understanding of how sentences are constructed and what work a sentence does; it organizes relationships between actors, actions and things acted upon.
Since it's midterm time for us academics, I'll phrase my comments in the form of questions for the reader:
1. What problems will arise if you succeed in persuading students that "a sentence ... organizes relationships between actors, actions and things acted on"? (Hint: pick one of Prof. Fish's own phrases -- say the first one, "This week I spent a happy Tuesday afternoon doing one of the things I most like to do" -- and try to figure out who is performing which actions on which objects.)
2. Where might students (or professors) go to learn more about the systematic relationships among linguistic form, function and content? (Hint: it's not in law school, nor is it in a course in English literature.)
3. What questions about disciplinary trends and educational practices, suggested by his argument, does Professor Fish fail to ask? Why?
[Some background reading:"The plastic fetters of grammar" (10/21/2003)
"Grammar education: Making up for a lost century" (4/12/2004)
"Two out of three on passives" (5/8/2004)
]
[And if you wonder whether contemporary intellectuals are really confused about grammatical concepts and grammatical terminology, search the comments on this recent post by Ann Althouse for phrases like "passive case" and "subjunctive voice", and try to figure out who's joking and who isn't.]
October 23, 2006
Bill Bright in the New York Times
It isn't often that the New York Times publishes an obituary for a linguist, but they have one for Bill Bright.
The bull watch
For some time now we've been watching the media -- in particular, National Public Radio and the New York Times -- cope with two books with "bullshit" in their titles (On Bullshit and Another Bullshit Night in Suck City), here, here, and here. The Times has settled on "bull––" (but with a 4-em dash instead of two 2-em dashes) as its cleaned-up version, and in this Sunday's Magazine (10/22/06), in a brief interview (p. 29) with philosopher Harry G. Frankfurt (the author of On Bullshit and a new book On Truth), Deborah Solomon absolutely revels in this substitute: eleven occurrences in fifteen short exchanges between Solomon and Frankfurt. Four of the exchanges are about Frankfurt's childhood, meaning that there's one occurrence of "bull––" for each of the exchanges where the word "bullshit" might conceivably be relevant.
This is amazingly ostentatious avoidance. You have to wonder who the paper thinks it's protecting with its avoidance tactic, while it waves a transparent allusion to the word in front of the reader every whipstitch.
zwicky at-sign csli period stanford period edu
The structure of Daylight Saving Time
This is a public service announcement from the Past and Future Tense Desk at Language Log Plaza: Daylight Saving Time (DST) in the U.S. ends (and Standard Time begins) at 2:00am this Sunday, October 29. (For readers in the EU: DST ends at 1:00am GMT.) At that time, it'll all of a sudden be one hour earlier again. You'll have an extra hour of sleep. It'll be great. Unless, of course, you live in one of those parts of the world that doesn't observe DST in the first place, in which case you don't get any extra sleep -- but you also won't lose an hour of sleep again in the Spring, so quit your whining.
Note! Before you write to tell us you've found a typo: that's the language-related bit that I'll get to in a moment. But first, back to the rest of the public service message. (Unless noted otherwise, the source of the basic information here is this site -- one of the "exhibits" on the very interesting WebExhibits site -- and the quotations are from this page of the exhibit, most of it drawn from this book.)
For the past 20 years, Daylight Saving Time (DST) in the United States has begun at 2:00am on the first Sunday of April and has ended at 2:00am on the last Sunday of October (save for states with overriding legislation, allowing DST not to be observed). For 20 years before that, U.S. DST began on the last Sunday of April. DST has been observed in the U.S. in some form since 1918, but observance is more variable before 1966, both Federally and at the state level. There was a time when localities could choose to start and end DST at different times. Some examples:
Widespread confusion was created during the 1950s and 1960s when each U.S. locality could start and end Daylight Saving Time as it desired. One year, 23 different pairs of DST start and end dates were used in Iowa alone. For exactly five weeks each year, Boston, New York, and Philadelphia were not on the same time as Washington D.C., Cleveland, or Baltimore -- but Chicago was. And, on one Ohio to West Virginia bus route, passengers had to change their watches seven times in 35 miles! The situation led to millions of dollars in costs to several industries, especially those involving transportation and communications. Extra railroad timetables alone cost the todays equivalent of over $12 million per year.
Worldwide observance of DST has never been standardized. In the European Union, for example, DST begins at 1:00am Greenwich Mean Time on the last Sunday of March and ends at 1:00am GMT on the last Sunday of October. (Although all EU clocks change at the same moment in time, most of the EU is east of GMT. Most EU folks thus change their clocks at 2:00am, and some -- for example, in, Greece -- change their clocks at 3:00am.)
By a new Federal law passed last year (the Energy Policy Act of 2005), the bounds of U.S. DST will change again in 2007. Next year, DST will begin on the second Sunday of March and end on the first Sunday of November. Whether this change will hold in subsequent years will apparently depend on a report of the impact of the change from the Department of Energy. Based on the following, I'm thinking it'll stick:
Following the 1973 oil embargo, the U.S. Congress extended Daylight Saving Time to 8 months, rather than the normal six months. During that time, the U.S. Department of Transportation found that observing Daylight Saving Time in March and April saved the equivalent in energy of 10,000 barrels of oil each day -- a total of 600,000 barrels in each of those two years.
Likewise, in 1986, Daylight Saving Time moved from the last Sunday in April to the first Sunday in April. No change was made to the ending date of the last Sunday in October. Adding the entire month of April to Daylight Saving Time is estimated to save the U.S. about 300,000 barrels of oil each year.
In any event, there has long been another reason folks have wanted to change at least the end date of DST:
Daylight Saving Time in the U.S. always ends a few days before Halloween (October 31). A bill to extend DST to Halloween is proposed in almost every session of Congress, with the purpose of providing trick-or-treaters more light and therefore more safety from traffic accidents. Childrens pedestrian deaths are four times higher on Halloween than on any other night of the year. Also, for decades, candy manufacturers have lobbied for a Daylight Saving Time extension to Halloween, as many of the young trick-or-treaters gathering candy are not allowed out after dark, and thus an added hour of light could mean a big holiday treat for the candy industry.
OK, now back to the language-related thing. On the second page of the DST exhibit, there's a section called Spelling and grammar, which somewhat pedantically notes:
The official spelling is Daylight Saving Time, not Daylight SavingS Time.
Saving is used here as a verbal adjective (a participle). It modifies time and tells us more about its nature; namely, that it is characterized by the activity of saving daylight. It is a saving daylight kind of time. Similar examples would be dog walking time or book reading time. Since saving is a verb describing a single type of activity, the form is singular.
Nevertheless, many people feel the word savings (with an 's') flows more mellifluously off the tongue. Daylight Savings Time is also in common usage, and can be found in dictionaries.
Adding to the confusion is that the phrase Daylight Saving Time is inaccurate, since no daylight is actually saved. Daylight Shifting Time would be better, but it is not as politically desirable.
The "flows more mellifluously off the tongue" part makes it sound like this is a phonetic or phonological matter -- more precisely, that it is some sort of articulatory issue (as opposed to an acoustic one, or it might have said something like "flows more mellifluously into the ear"). But I think this is one of those cases where the appeal to something-about-the-tongue (or -the-ear) is a substitute for the absence of an educated linguistic guess: we know how we say things, but we often have no idea why we say them that way. Linguists are people who do have ideas about why we say things the way we do. The ideas may be wrong, but they're not baseless.
I have an idea about the 's' in Daylight Savings Time -- which, incidentally, is the way I've always said it, apparently incorrectly but certainly not apologetically. But first, I have to address the idea quoted above, that Saving is a "verbal adjective" and that Daylight Saving Time is thus like dog walking time or book reading time -- though perhaps a better example to compare is picture taking time, which has the same number of syllables as Daylight Saving Time.
Here's why this idea can't be right. Examples like picture taking time (which, FWIW, I would probably write picture-taking time) are pronounced with the main stress on the stressed syllable of the first word: PICture-taking time. This is because the structure of these examples is as follows (see the youth and popular culture desk report on the relation between stress and structure in examples like these here):

The example we're interested in is different, because the main stress is on the second word, not the first: it's Daylight SAVing Time, not DAYlight-Saving Time. Something about Daylight SAVing Time must differ from PICture-taking time. (Try saying picture TAKing time -- not very mellifluous.)
Is it a difference in structure? I don't think so. Everything about Daylight SAVing Time indicates to me that it patterns with examples like foreign LANguage test, which have this structure:

The critical difference is that the first word in this structure (foreign) is an adjective (with the label A), not a noun (with the label N) in the PICture-taking time example above. I think Daylight likewise functions as an adjective here -- one derived from a noun, but an adjective nonetheless -- which means that Saving must be the noun that this adjective is modifying:

This brings us back to the question about the 's' that "many people" seem to think is more mellifluous. The issue, I think, is this: the word saving, like other -ing participles, is not commonly used as a noun, but the word savings is. This is especially true in the context of money, and there's a well-known metaphorical link between money and time (see this page for some discussion; search for "time is money"). So, at least for "many people", the most accessible relevant noun is savings, not saving. The reasoning that Saving here is a "verbal adjective" is just hooey.
Of course, this entire story hinges on the fact that the stress pattern is Daylight SAVing Time, not DAYlight-Saving Time: this stress pattern leads to the structural analysis that leads to the relevant word-choice. But why is the stress pattern like that in the first place? I don't have a well-thought-out answer to that one yet, but perhaps it will be fodder for a future post.
[ Comments? ]
The seventh question
 I recall being taught in elementary school that a newspaper article is supposed to answer six questions. Some things have changed since I was a kid, and the most important one is the internet. So I'd like to suggest that the traditional list of six should be expanded to seven: who, what, where, when, why, how and URL. For all I know, those traditional six questions are the journalistic equivalent of the Eskimos' snow words, so let me put it more directly: reporters and editors, give me the *!%&@ URLs!
I recall being taught in elementary school that a newspaper article is supposed to answer six questions. Some things have changed since I was a kid, and the most important one is the internet. So I'd like to suggest that the traditional list of six should be expanded to seven: who, what, where, when, why, how and URL. For all I know, those traditional six questions are the journalistic equivalent of the Eskimos' snow words, so let me put it more directly: reporters and editors, give me the *!%&@ URLs!
I thought of this when I read an article by Larry Rohter in today's New York Times ("At Long Last, a Neglected Language is Put on a Pedestal" 10/23/2006), about a new Museum of the Portuguese Language in São Paolo. The article's lede:
More people speak Portuguese as their native language than French, German, Italian or Japanese. So it can rankle the 230 million Portuguese speakers that the rest of the world often views their mother tongue as a minor language and that their novelists, poets and songwriters tend to be overlooked.
An effort is being made here in the largest city in the world’s largest Portuguese-speaking country to remedy that situation. The Museum of the Portuguese Language, with multimedia displays and interactive technology, recently opened here, dedicated to the proposition that Portuguese speakers and their language can benefit from a bit of self-affirmation and self-advertisement.
Along with the multimedia displays and interactive technology, I bet that the museum has a web site. Unfortunately, Rohter's article doesn't give it to us.
Luckily, the first Google hit for {"museum of the portuguese language"} is the Wikipedia article on "Portuguese language". This article also includes the answer to one of the six traditional questions that Rohter's article also doesn't answer, namely when:
In March of 2006, the Museum of the Portuguese Language, an interactive museum about the Portuguese language, was founded in São Paulo, Brazil, the city with the largest number of Portuguese speakers in the world. [emphasis added]
(I guess that seven months ago is "recently", if you're thinking about the time course of language change...)
The link takes us to the Wikipedia site for the museum itself, where we also learn the answer to another of the traditional six questions, namely what -- or at least the Portuguese name of the museum (Museu da Língua Portuguesa) -- as well as some interesting information about who that is also lacking in the NYT article:
The idea for the museum came from Ralph Appelbaum, who also developed the United States Holocaust Memorial Museum in Washington D.C., and the fossil room of the American Museum of Natural History in New York City. The architectural project was undertaken by Brazilian father-son duo Paulo and Pedro Mendes da Rocha. The director of the museum is sociologist Isa Grinspun Ferraz, who coordinated a team of thirty Portuguese language specialists for the museum. The artistic director is Marcello Dantas.
This is perhaps more information than an American newspaper article really needs, especially one whose focus is the Portuguese language as much as the museum itself. However, you'd think that American and especially NYC audiences would be interested in the role of Ralph Appelbaum, whose credits also include the Ellis Island Immigration Museum, the United States Capitol Visitor Center, and the Newseum.
Given how easy it was to find the relevant links via Google and the Wikipedia, I guess I shouldn't complain that of the five hyperlinks in the (online version of the) NYT article, four are distracting and irrelevant (George Bernard Shaw, Brown University, the United Nations, and "Nobel laureate"), while one is of marginal relevance (Brazil). And for similar reasons, perhaps I shouldn't complain that the only semi-concrete piece of information in the article about the Portuguese language is this:
The issue is not just the contrast between the mellifluous, musical accent of Brazil — “Portuguese with sugar,” in the words of the 19th-century realist Eça de Queiroz — and the clipped, almost guttural sound in Portugal. There are also marked differences in usage that have traditionally led to misunderstandings and provided fodder for jokes.
In Portugal, for example, a word for a line (the waiting kind) is to Brazilians a derogatory slang term for a homosexual. A Portuguese word for a man’s suit of clothes means a fact or piece of information in Brazil.
If you're going to tell us about accents, how about a sidebar with audio clips? And if you're going to tell us about usage differences, how about telling us what the actual words are?
The Wikipedia article on Portuguese offers an interesting display that helps give readers a quick sense of the diversity among Romance languages:
In spite of the obvious lexical and grammatical similarities between Portuguese and other Romance languages outside the West Iberian branch, it is not mutually intelligible with them to any practical extent. Portuguese speakers will usually need some formal study of basic grammar and vocabulary, before being able to understand even the simplest sentences in those languages (and vice-versa):
- Ela fecha sempre a janela antes de jantar. (Portuguese)
- Ela fecha sempre a fiestra antes de cear. (Galician)
- Ella cierra siempre la ventana antes de cenar. (Spanish)
- Ella tanca sempre la finestra abans de sopar. (Catalan)
- Lei chiude sempre la finestra prima di cenare. (Italian)
- Ea închide întodeauna fereastra înainte de a cina. (Romanian)
- Elle ferme toujours la fenêtre avant de dîner. (French)
- She always shuts the window before dining.
Something similar could have been done for the differences between Brazilian and European Portuguese.
Anyhow, one of Ralph Appelbaum's other designs, the Newseum, is an interesting and perhaps relevant case. According to its Wikipedia page,
The world’s first interactive museum of news, the Newseum, opened in Rosslyn, Virginia in Arlington County, on April 18, 1997. Its stated mission is "to help the public and the news media understand one another better". In five years, the Newseum became an internationally recognized attraction, drawing more than 2.25 million visitors and receiving some critical acclaim for its exhibits and programs. The plaudits, however, were not universal. Thomas Frank wrote a particularly scathing review in his 2000 book, One Market Under God:
Maybe Arlington is where journalism has come to die, in a place as distant as could be found from the urban maelstrom and the rural anger that once nourished it, within easy reach of the caves of state, sunk deep in the pockets of corporate power, here where busloads of glassy-eyed, well-dressed high schoolers from the affluent suburbs of Virginia can play anchorman on its grave.
In 2000, Freedom Forum leadership determined that the best way to increase the impact and to appeal to much larger audiences would be by moving the Newseum across the Potomac River to Washington, D.C. The original Newseum was closed on March 3, 2002 in order to allow its staff to concentrate on building the new, larger museum.
After obtaining a landmark location at Pennsylvania Avenue and Sixth Street, the design of the building and its exhibits became the focus. The Newseum Board selected noted exhibit designer Ralph Appelbaum, who had designed the original Newseum in Arlington, Virginia, and architect James Stewart Polshek, who designed the Rose Center for Earth and Space at the American Museum of Natural History in New York City to work on the new project.
The new Newseum is still under construction, but the artists' renderings suggest that it'll be a grand edifice:

And the way things are going, maybe they should rename it the Newsoleum.
Meanwhile, the Wikipedia also gave me the URL of the web site for the Museu da Língua Portuguesa. It's a nice short one: http://www.estacaodaluz.org.br.
[I should add that the museum's web site is disappointing -- there are very few good websites on varieties of language, and this is not one of them. But that's a topic for another post.]
October 22, 2006
F-words
In the 10/14/06 issue of The Economist, the report from Russia (p. 55) is titled "The hardest word", with the summary:
And which f-word would that be?
The word is revealed in the last paragraph (p. 56) of the story:
"F-word" (or "F word" or "f-word" or several other variants) has been in play for a while as an allusion to the word fascism -- in discussions of the use of "Islamic fascism" or "Islamofascism" to characterize terrorism associated with Islam (see Geoff Pullum's 8/11/06 take on this here) and in references to the Bush administration's policies, as in this 5/8/03 rant from Ben Tripp:
These people are fascists, and they make Mussolini look like a mezzafinook. There is no component of American liberty of which they are unwilling to relieve us, and no aspect of American life upon which they are unwilling to relieve themselves.
"F-word" is designed to capture the status of fascism (and fascist) as a "bad word", specifically a word intended as, or perceived as, a slur -- a word some might be reluctant to say, a word like the pre-eminent F-word fuck, or its little brother faggot/fag.
Also very common is "F-word" used to stand in for feminism (or feminist), largely, as far as I can see, by feminists defiantly confronting scornful uses of feminism, as on the British feminist site "the f-word".
Then we get small numbers of occurrences of "F-word" for other words (some) people might want to avoid: fat, for instance, or in specific contexts, finesse (in football, reported on by Ben Zimmer here), fossils (with regard to NASA's reluctance to talk about the possibility of fossils on Mars, noted here), forgiveness (in an exhibition mounted by the Forgiveness Project), even folk [music] (in an internet radio station devoted to folksy artists). At some point it begins to look like "F-word" has been chosen simply for its value as an eye-catcher.
That point has certainly been reached when we get to "The F-Word", a U.K. television show about cooking and eating hosted by Gordon Ramsay. Yes, the F-word in question is food.
[Update. David Denison supplies more context: "I've never watched his TV programmes, but Gordon Ramsay is famous for his foul-mouthed invective in the kitchen, unleashed routinely and lavishly on any hapless apprentice or fellow-chef (or even diner, I believe) who displeases him. So it sounds to me as if the programme title is a perfectly appropriate piece of euphemism-play."]
zwicky at-sign csli period stanford period edu
October 21, 2006
"Private prayer language"
According to the AP ("Seminary passes resolution against speaking in tongues", 10/19/2006), the trustees at Southwestern Baptist Theological Seminary recently voted 36-1 that "Southwestern will not knowingly endorse in any way, advertise, or commend the conclusions of the contemporary charismatic movement including 'private prayer language.'"
This is not the first recent vote on this subject by Southern Baptist institutions. According to Christianity Today,
Trustees for the Southern Baptist Convention's (SBC) International Mission Board (IMB) have voted to bar new missionary candidates who practice a "private prayer language" from serving on the mission field.The trustees voted 50-15 for the new guidelines on November 15 [2005], during their meeting in Huntsville, Alabama. [...]
Candidate guidelines approved by IMB trustees at the meeting state, "In terms of worship practices, the majority of Southern Baptist churches do not practice glossolalia," or tongues. "In terms of general practice, the majority of Southern Baptists do not accept what is referred to as 'private prayer language.' "
"Private prayer language" seems to be a relatively recent descriptive term -- or perhaps a euphemism -- for (some of) a set of practices that are more commonly referred to as "speaking in tongues". According to ProQuest's historical newspaper databases, the phrase "private prayer language" has never been used in the pages of the New York Times, the Los Angeles Times, or the Wall Street Journal, nor in a number of other ProQuest databases, including the American Periodicals Series 1740-1900, the Alternative Press Watch, the Ethnic NewsWatch, etc. Search on the NYT web site itself also returned nothing -- the Gray Lady apparently did not find either of the two recent anti-"private prayer language" votes fit to print.
Searching for "private prayer language" on LexisNexis Academic in the "Major Papers" category, I found six hits, four of which refer specifically to the two votes mentioned above. The other two uses are both in quotations. One is from a 1994 story (Esther Talbot Fenning, "Charismatic Renewal: Movement in Worship", St. Louis Post-Dispatch, August 19, 1994), about practices in among Catholics involved in "Charismatic Renewal" (emphasis added):
Charismatics believe that speaking in tongues, healing and prophecy are gifts of the early church and are still available to people who are open to them, says Bonnie Dillard of the People of Praise, a prayer group at St. Elizabeth Ann Seton Church in St. Charles.
"Most Catholic pastors are frightened of the Charismatic Renewal," Dillard said. "Part of the reason is that they've seen people get into it and go on to leave the church."
Dillard said that speaking in tongues and prophetic utterances also are disconcerting to some Catholics.
"Tongues is simply a private prayer language consisting usually of a few nonsense syllables," she said. "It has no basic function at large gatherings."
The other is from a 1999 story (Lindsay Peterson, "The Human Touch", The Tampa Tribune, December 12, 1999):
They heard about a fiery young minister leading Bible studies in local homes. They began taking their children to the meetings, amazed at his spellbinding power.
He encouraged an aggressive, charismatic worship with praying so fevered and focused that people cried out and spoke in tongues.
They called out their visions.They laid hands on the sick.
They sang, "God's got an army that's marching through this land with deliverance in their souls and healing in their hands."
Sallee had never experienced anything like this Pentecostalism, and she found it exhilarating.
She saw no visions of her own, she said, but did begin speaking in tongues, what she called her private prayer language.
In contrast, a LexisNexis search returns 2,688 hits for "speaking in tongues" from the same sources.
Similarly, there are 16,900 Google hits for {"private prayer language"}, compared to 1,400,000 for {"speaking in tongues"}.
The report from the SBTS trustees' fall 2006 meeting explains their decision in more detail:
In response to an August 29 chapel sermon by trustee Dwight McKissic regarding private prayer languages, the trustees adopted the following statement:
“The Southwestern Baptist Theological Seminary is a school affiliated with the Southern Baptist Convention for the sole purpose of training men and women to understand the Bible in all its ramifications in order to facilitate the assignment of Christ as provided in the Great Commission (Matt. 28:18-20). We wish to remain faithful to the biblical witness and its emphases, taking into careful account the historic positions of Baptists in general and Southern Baptists in particular.
“As it concerns private practices of devotion, these practices, if genuinely private, remain unknown to the general public and are, therefore, beyond the purview of Southwestern Seminary. Southwestern will not knowingly endorse in any way, advertise, or commend the conclusions of the contemporary charismatic movement including “private prayer language.” Neither will Southwestern knowingly employ professors or administrators who promote such practices.
“Southwestern will remain focused on historic New Testament and Baptist doctrine and will lend its energies to the twin tasks of world missions and evangelism. Thus, we intend to sustain these emphases, which were characteristic of our founders, B.H. Carroll, L.R. Scarborough, and George W. Truett.”
Van McClain (N.Y.), chairman of the Board of Trustees, said, “ I believe the board has addressed the issues of the August 29 chapel by this statement. Dr. Patterson has handled this matter appropriately. There is no need for the Board of Trustees to make any further statements at this time.”
The dissenting vote was cast by Dwight McKissic himself, whose sermon had raised the issue in the first place. He's the senior pastor of the Cornerstone Baptist Church, in Arlington TX. You can find further discussion of the theological issues in this exchange posted at Marty Duren's SBC Outpost, which includes a letter from McKissic to Dr. Paige Patterson, the seminary's president, and a lengthy commentary, with footnotes. Duren quotes Timothy George to the effect that "recent efforts to exclude from missionary appointment all who have a ‘private prayer language’ seemed to many ordinary Baptists both intrusive and unnecessary", and adds his own comment:
The overall impression I get from talking to my peers (mainly younger pastors) is outright confusion: “Why are they doing this? What are they thinking?”
The Rev. McKissic's letter suggests that there may be a racial as well as theological dimension to this controversy:
Just as you suspect that most of the faculty and trustees at SWBTS do not believe the Bible affirms a private prayer language, the leading evangelical African-American churches in America including Black Southern Baptists, would affirm the practice of a private prayer language by those who are so gifted by the Holy Spirit. They would certainly not invoke a policy denying freedom of a gifted person to practice a private prayer language.
For a much more hostile view of the social tensions involved, see this review of the Rev. McKissic's sermon on the theme "To equate civil rights with gay rights is to compare my skin with their sin", which asserts that "when a black man joins and lines his church up with an old wealthy organization with a rich and deep history of racism and sexism [it] speaks VOLUMES".
Nevertheless, it's clear that people of many racial and ethnic backgrounds practice religious glossolalia, both in public and in private, as explained by Cecil M. "Mel" Robeck in a recent edition of NPR's Speaking of Faith program, "Spiritual Tidal Wave: the Origins and Impact of Pentecostalism", 4/27/2006. The program's web site introduces the subject this way:
Glossolalia, commonly known as "speaking in tongues," is the ecstatic utterance of unintelligible sounds by individuals in a state of religious excitement or fervor. Pentecostal revivals are often accompanied by manifestations of glossolalia. Its biblical basis is rooted in the Acts of the Apostles and Paul's first letter to the Corinthians. Xenoglossy, the ability to speak another human language that was previously unknown to the practitioner, is viewed as a means to reversing the confusion experienced at the Tower of Babel.
The audio in the program was recorded during the opening of the Azusa Street Centennial procession which began on Bonnie Brae Street in Los Angeles. Listen to a complete recording of Billy Wilson's opening remarks and the speaking in tongues taking place in the crowd. Also, you can hear two women from the Foursquare Gospel Church in Pasadena describe how the gift of speaking in tongues occurs in their daily lives.
However, neither on that page nor elsewhere on the Speaking of Faith web site does the phrase "private prayer language" occur.
There's a good deal more to say about the linguistics, psychology and neurology of glossolalia and xenoglossy, religious and otherwise. Sally Thomason has studied cases of hyponotically-induced xenoglossy in detail (Sarah Gray Thomason, "Do you remember your previous life's language in your present incarnation?", American Speech, Vol. 59, No. 4. (Winter, 1984), pp. 340-350), and there is a small but interesting literature of other such analyses.
But that's a topic for another post -- the topic here is just the (apparently brief) history of the phrase "private prayer language". I tentatively conclude that this began as descriptive phrase for (some types of ?) religious glossolalia, which began to be used in the 1990s by people in various denominations involved in the Pentecostal movement. Some people seem to refer to all sorts of religious glossolalia as "private prayer language", while others seem to reserve the term for glossolalia in individual prayer as opposed to public worship.
I conjecture that both those who favor religious glossolalia and those who oppose it now have theological and polemical motivations for using this new phrase, in place of older and more common phrases like "speaking in tongues". One motivation may be to distinguish glossolalia in individual prayer from glossolalia in public worship, perhaps because private religious glossolalia might be thought to be permitted by denominations that discourage public "speaking in tongues". If you can clarify these issues, please let me know.
[Tip of the hat to Abnu at Wordlab]
[Someone might want to tell the folks at Cornerstone Baptist Church that their domain name expired on Oct. 5]
[Update -- Stephen C. Carlson from Hypotyposeis explains the theology behind the terminology:
Though it is possible that mainline, liturgical denominations open to the charimatic renewal might be motivated along the lines that you suggest (since the traditional worship services do not allocate time for speaking in tongues), that is generally not the main factor motivating charismatics to make this distinction, particularly because a lot of charismatics are involved in non-denominational churches
Rather, the distinction between public and private speaking in tongues is driven by 1 Cor. 14:27-28, which reads: "If anyone speaks in a tongue, let there be only two or at most three, and each in turn, and let one interpret. But if there is no one to interpret, let them be silent in church and speak to themselves and to God." Thus, if one follows this scripture, a person publicly speaking in tongues would have to be accompanied by someone with the gift of interpretation to translate it. The latter gift, however, is quite uncommon.
Furthermore, the concept of praying in tongues is found in 1 Cor. 14:14 ("For if I pray in a tongue, . . ."). Some pentecostal and non-denominational charismatic churches will permit private prayers during worship, which means that people can use their private prayer language without running afoul of 1 Cor 14:27-28.
For those denominations or non-denominational churches that adhere to the doctrine of "cessationalism" (cf. 1 Cor. 13:8-10), speaking in tongues is not permitted either in public or in private. This doctrine holds that tongues ceased when the New Testament was completed, making the distinction between public and private speaking in tongues irrelevant.
]
[Update #2 -- David Chiang wrote:
My guess about the use of this term is that some churches and missionary organizations have tried to steer a middle course: they forbid any public use of tongues or other charismatic practices, but don't make any prescription about a person's private spiritual life. The SBC, by forbidding any "private prayer language", is making clear that it is not steering this middle course but wants to forbid all charismatic practices public or private. I have usually seen this referred to as "private use of tongues" so I don't have a good guess for why the term "private prayer language" is used instead -- I assume it's something to do with the thorny issues in defining what "tongues" are.
Well, it doesn't seem that "private prayer language" is any more exactly defined, but maybe it doesn't carry the same baggage.
And Kelly Shropshire writes to suggest that the "private prayer language" terminology dates back 30 years or so:
I first read the phrase "private prayer language" in pentecostal literature back in the late 70's. It is considered a gift from God to aid the recipient in expressing themselves. ... A private prayer language is usually considered just that, as opposed to other glossalalic utterences which are meant as messages to the congregation and are usually followed by translations. However there was one member of the Foursquare Church who once offered to demonstrate her prayer language because she thought it would do me some spiritual good to hear it. I never got to hear it though.
As for the Baptists, I'm surprised that there was a vote. Most baptist denominations are officially suspicious of a all claims of "spiritual gifts", not just speaking in tongues. ... To deliberately seek out such gifts seems like a sign of weak faith, an exercise in self delusion, or even an invitation to demonic possession. But pentecostal denominations not only encourage seeking the gifts, some even claim that the gifts are the best confirmation of one's faith. There's been friction between the two groups for a long time over this.
(Sub-update: another reader challenges the view that baptists are "suspicious of all claims of 'spiritual gifts'", citing for example an article titled "Help Your People Discover Their Spiritual Gifts" by C. Gene Wilkes, pastor of a Baptist church in Plano TX. And David Chiang observed in response that the key difference seems to be between miraculous gifts and other gifts; but at this point, the discussion adjourns to the vestry...)
In the SBC, it seems that "private tongues" are seen as the thin edge of the charismatic wedge, both by supporters and by opponents. You can see this in the quotations from SBC leaders in the news stories about the SWBTC vote (the AP story, or the earlier story in the Fort Worth Star-Telegram (Brett Hoffman, "Policy bans promotion of speaking in tongues", 10/18/2006), in the discussion on SBC Outpost, or in the stories about the earlier IMB decision.
In particular, it's clear that the practice of "private tongues" has long been found among some SBC members, including (for example) the president of the missionary board:
Because the ruling is not retroactive, it will not apply to IMB president Jerry Rankin. "I acknowledged even in the discussions that [tongues] has been a continuing practice [of mine] for 30 years," Rankin told CT. The trustees who elected him president in 1993 knew he prays in tongues.
And the SWBTS statement included the sentence "As it concerns private practices of devotion, these practices, if genuinely private, remain unknown to the general public and are, therefore, beyond the purview of Southwestern Seminary." The point of contention is whether to allow people to "endorse ..., advertise or commend" these "practices". For an outsider, it's surprising to find that the Baptists are apparently less open on this matter than the Catholics and Eastern Orthodox are.]
October 20, 2006
Terrific is even creepier than uncanny
In response to a recent Language Log post ("It is so neat and creepy", 10/19/2006), Dan Fuchs suggests that creepy is following a path blazed by terrific. He points to the online etymological dictionary entry for terrific
1667, "frightening," from L. terrificus "causing terror or fear," from terrere "fill with fear" (see terrible) + root of facere "to make" (see factitious). Weakened sensed of "very great, severe" (e.g. terrific headache) appeared 1809; colloquial sense of "excellent" began 1888.
His comment: "So it went from 'really horrible' to 'really excellent' in a mere 200 years -- and without blogs or MySpace!"
Well, the OED entry (the earliest citation for each sense is given below) suggests that it might have been more like 260 years:
1. Causing terror, terrifying; fitted to terrify; dreadful, terrible, frightful.
1667 MILTON P.L. VII. 497 The Serpent..with brazen Eyes And hairie Main terrific.
2. a. Applied intensively to anything very severe or excessive. colloq. (Cf. awful, terrible, tremendous.)
1809 J. W. CROKER in Croker Papers 12 Oct., I am..up to my eyes in business, the extent of which is quite terrific.
b. As an enthusiastic term of commendation: superlatively good, ‘marvellous’, ‘great’. Also Comb. colloq.
1930 D. G. MACKAIL Young Livingstones xi. 271 ‘Thanks awfully,’ said Rex. ‘That'll be ripping.’ ‘Fine!’ said Derek Yardley. ‘Great! Terrific!’
Still, it's creepy (in the new sense) how words change their meaning over time, and terrific is an even creepier example than uncanny is. And then of course there's the adverbial evolution of awfully...
[And as several readers have pointed out, there's awesome. The OED's senses, with the date of the earliest citation for each one:
1. Full of awe, profoundly reverential. [1598]
2. Inspiring awe; appalling, dreadful, weird. [1671]
3. a. In weakened sense: overwhelming, staggering; remarkable, prodigious. colloq. (orig. and chiefly U.S.). [1961]
b. In trivial use, as an enthusiastic term of commendation: ‘marvellous’, ‘great’; stunning, mind-boggling. slang. [1980]
"In trivial use"? ]
[Chris Christensen points out that negative connotations come as well as go, via the quote attributed to S.M. Stirling:
Words mean what they're generally believed to mean. When Charles II saw Christopher Wren's St. Paul's Cathedral for the first time, he called it "awful, pompous, and artificial." Meaning roughly: Awesome, majestic, and ingenious.
]
[Update 10/23/2006 -- Dave Lebling writes:
Chris Christenson's quote on "awful, pompous and artificial" is not from S. M. Stirling, but rather an earlier science fiction writer, Poul Anderson, in his short story "A Tragedy of Errors."
My recollection is that the story revolves around a planet where the word "friend" has come to mean pirate/terrorist/bad-guy due to raids by bad guys who call themselves "friends."
]
Annals of self-censorship: avoiding the F-letter
A reader sent in a couple of examples where the letter F is omitted from the abbreviated form WTF, producing WT_:
(link) I submitted over 75 bugs to their (now closed?, wt_?) bug tracking system
(link) No Firefox... WT_??? If you are not ready to support Modern Browsers, then you are NOT READY!!!!!
Although just searching for {WT_} mostly turns up trash, there are plenty more genuine examples of initial-letter-avoidance out there:
(link) WT_ is this anyways???
(link) WT_ is going on ?
(link) wt_ is wrong with giant and espn's avatar ! ?
(link) Woodchip . . . wt_ are you smokin ?
However, I haven't yet been able to find any examples of the logically-related step, which would be for people to start talking about the _-word, the _-bomb, and so on. (Or should it be the *-word?) Anyhow, in the next stage after that, the underscores and asterisks themselves would have to be omitted -- in favor of what?
Arnold Zwicky has compiled a convenient archive of Language Log postings on taboo vocabulary, but I believe that this is the first case in which the taboo item was a single letter.
]
[Update 10/21/2006 -- Omri Ceren writes:
This might not be self-censorship as much as geek wordplay. Playing around with brb and wtf in order to make them more or less words is kind of a witticism / showy way to play around...
So occasionally I'll be in conversations where someone will say "double-u tee eff" instead of "what the fuck" - it's not self-censorship, it's just super-self-referential geekiness
I think that this wt_ could be the same thing - it's playing around with the abbreviation itself (i.e. "I couldn't write out 'fuck', 'f' stands for 'fuck', let's highlight that by censoring it") It's just geeks trying to put a new spin on a set of letters you see 100s of times a day, not prudes.
That could well be true. But one of the funny things about "WTF" is that it's neither an acronym (in the technical sense of a sequence of initial letters pronounced like a word, e.g. NASA), nor an initialism (initial letters pronounced individually, as in IBM) -- instead, it's usually just a short-hand way of writing the three words whose initial letters it spells. Thus leaving out the F stands for typographically bleeping the expression, in a way that omitted the F in F-word wouldn't...]
October 19, 2006
Welsh Beef
This week's Macleans has a little piece on page 82 entitled "This Week's Special…Welsh-speaking Beef".
A farm is supplying the British Mark's & Spencer chain of stores with Welsh beef known for its tenderness. The secret, according to an M&S spokesman, is that, at Cig Calon Cymru farm, the Welsh Black cows take their leisure on foam mattresses while farmhands whisper to them only in Welsh. The language, explains Manchester University linguist Martin Berry, "is more melodic than English," and that relaxes the animals.
Hmm. It is plausible that animals that are more relaxed will produce better beef. Stress-levels affect hormone production, which could have an impact on the meat. But do cows really find Welsh more relaxing than English? I checked with Martin Barry (which is the correct spelling of his name), who tells me that he said no such thing. He reports that when he was asked about this by a reporter, he replied that Welsh English is said to be more "lilting" than other varieties of English, which probably reflects a difference in pitch accent alignment, but that he had no idea whether cows find Welsh more relaxing than English. This is why many scholars won't talk to reporters.
Whether the Prince of Wales uses Welsh when he speaks to plants has not been reported, but if they'll send along some of that beef, Language Log Labs will be glad to check out its tenderness.
The grammar of anti-microbial peptides
Several people have written to ask me about the work recently in the news under headlines like "Grammar helps biologists invent 40 bacteria fighters", "Grammatical rules spell out new drugs", "Grammar may help fight bacteria", "Bacteria, meet your new enemy: Grammar", "Scientists use grammar rules to slay killer germs", and (my personal favorite) "DaVinci Code meets CSI in bacteria battle".
So let's go directly to the paper itself: Christopher Loose, Kyle Jensen, Isidore Rigoutsos and Gregory Stephanopoulos, "A linguistic model for the rational design of antimicrobial peptides", Nature 443, 867-869(19 October 2006). Here's the abstract:
Antimicrobial peptides (AmPs) are small proteins that are used by the innate immune system to combat bacterial infection in multicellular eukaryotes1. There is mounting evidence that these peptides are less susceptible to bacterial resistance than traditional antibiotics and could form the basis for a new class of therapeutic agents. Here we report the rational design of new AmPs that show limited homology to naturally occurring proteins but have strong bacteriostatic activity against several species of bacteria, including Staphylococcus aureus and Bacillus anthracis. These peptides were designed using a linguistic model of natural AmPs: we treated the amino-acid sequences of natural AmPs as a formal language and built a set of regular grammars to describe this language. We used this set of grammars to create new, unnatural AmP sequences. Our peptides conform to the formal syntax of natural antimicrobial peptides but populate a previously unexplored region of protein sequence space.
Before we get to the details, some crucial background is in order, which I'll provide in the form of some structured links to the wikipedia.
A protein is a "large organic compound made of amino acids arranged in a linear chain and joined by peptide bonds". There are 20 "standard amino acids" used in proteins by living things on earth, and for convenience, these can be put into correspondence with the 20 letters {ARNDCEQGHILKMFPSTWYV}. Thus the primary structure of any protein can be specified as a single string of letters drawn from this alphabet. (Most proteins then fold up in complicated secondary, tertiary and quaternary structures, and these folded structures are crucial to their function, but that's another story).
Formal language theory, as developed by linguists, mathematicians and computer scientists during the second half of the 20th century, deals with the properties of (typically infinite) sets of (typically finite) strings made up of elements drawn from a (typically finite) vocabulary. Formal grammars are used to specify the properties of particular formal languages. Such grammars, and the languages they specify, can be arranged in a hierarchy of increasingly powerful types, known as the Chomsky hierarchy (because it was first worked out by Noam Chomsky and Marcel-Paul Schützenberger). The simplest, most limited, easiest-to-process type of grammar in this hierarchy is a regular grammar (also sometimes called a finite-state grammar).
Because proteins (and other biological macromolecules such as DNA and RNA) are finite-length strings of elements drawn from a finite alphabet, it's natural to describe them grammatically. And as a result, computational biology has long since borrowed the mathematical and computational tools of computational linguistics, and made good use of them in applications from gene-finding to protein-structure prediction. One of the first researchers to see the potential of such methods was David B. Searls, one of the founders of the Center for Bioinformatics at Penn, and now at GSK; a good source of insight is his 2002 Nature review article "The language of genes" (or try this link).
Continuing with the Loose et al. paper:
Our preliminary studies of natural AmPs indicated that their amphipathic structure gives rise to a modularity among the different AmP amino-acid sequences. The repeated usage of sequence modules—which might be a relic of evolutionary divergence and radiation—is reminiscent of phrases in a natural language, such as English. For example, the pattern QxEAGxLxKxxK (where 'x' is any amino acid) is found in more than 90% of the insect AmPs known as cecropins. On the basis of this observation, we modelled the AmP sequences as a formal language—a set of sentences using words from a fixed vocabulary. In this case, the vocabulary is the set of naturally occurring amino acids, represented by their one-letter symbols.
We conjectured that the 'language of AmPs' could be described by a set of regular grammars. [...]
Specifically, they decided to explore the hypothesis that AmPs are texts made up of 10-letter sentences:
To find a set of regular grammars to describe AmPs we used the Teiresias pattern discovery tool. With Teiresias, we derived a set of 684 regular grammars that occur commonly in 526 well-characterized eukaryotic AmP sequences from the Antimicrobial Peptide Database (APD). Together, these ~ 700 grammars describe the 'language' of the AmP sequences. In this linguistic metaphor, the peptide sequences are analogous to sentences and the individual amino acids are analogous to the words in a sentence. Each grammar describes a common arrangement of amino acids, similar to popular phrases in English. For example, the frog AmP brevinin-1E contains the amino-acid sequence fragment PKIFCKITRK, which matches the grammar P[KAYS][ILN][FGI]C[KPSA][IV][TS][RKC][KR] from our database (the bracketed expression [KAYS] indicates that, at the second position in the grammar, lysine, alanine, tyrosine or serine is equally acceptable). On the basis of this match, we would say that the brevinin-1E fragment is 'grammatical'.
By design, each grammar in this set of ~ 700 grammars is ten amino-acids long and is specific to AmPs—at least 80% of the matches for each grammar in Swiss-Prot/TrEMBL (the APD is a subset of Swiss-Prot/TrEMBL) are found in peptides annotated as AmPs.
They then used a simple method to find new "grammatical" sequences to synthesize:
To design unnatural AmPs, we combinatorially enumerated all grammatical sequences of length twenty (see Methods) in which each window of size ten in the 20-mers was matched by one of the ~ 700 grammars. We chose this length because we could easily chemically synthesize 20-mers and this length is close to the median length of AmPs in the APD. From this set, we removed any 20-mers that had six or more amino acids in a row in common with a naturally occurring AmP; we then clustered the remaining sequences on the basis of similarity, choosing 42 to synthesize and assay for antimicrobial activity.
They created some obvious control sequences:
For each of the 42 synthetic peptides, we also designed a shuffled sequence, in which the order of the amino acids was rearranged randomly so that the sequence did not match any grammars. These shuffled peptides had the same amino-acid composition as their synthetic counterparts and thus, the same molecular weight, charge and isoelectric point (bulk physiochemical factors that are often correlated with antimicrobial activity). We hypothesized that because the shuffled sequences were 'ungrammatical' they would have no antimicrobial activity, despite having the same bulk physiochemical characteristics. In addition, we selected eight peptides from the APD as positive controls and six 20-mers from non-antimicrobial proteins as negative controls.
Then they tested their 42 synthetic peptides, along with the controls, against Bacillus cereus and Escherichia coli, "as representative gram-positive and gram-negative bacteria". Here's their schematic diagram of the method:
And here's their summary of the results:
In general, the reports in the popular press are not too bad, though I don't think that most of them really give readers much of a sense of what was really done and why it made sense to try it. As usual, the AP story scrapes the bottom of the science-journalism barrel exhibits extraordinary interpretive creativity:
Biologists reached back to elementary school to discover a promising new way to fight nasty bacteria: Apply the rules of grammar.
The unusual method to try to defeat drug-resistant microbes and anthrax borrows a page from ``The Da Vinci Code'' and the TV show ``CSI: Crime Scene Investigation.''
But the kind of grammar that kids (used to) learn in elementary school has almost nothing in common but a name with the kind of grammar that Loose et al. used. And it never would have occurred to me that you could help readers to understand the role of formal language theory in this piece of research by reference to those two estimable works of popular culture, The Da Vinci Code and CSI. But now that I come to think of it, I can see that this method of getting science across to the public has real legs:
Physicists reached out to the National Football League to find a way to create the heaviest element yet.
Or:
To understand the recent Hawaiian earthquakes, seismologists borrowed a page from "American Idol" and "Pirates of the Caribbean".
What does it mean? Who knows. Does it sell papers? Apparently.
[By the way, not everyone is impressed by the Loose et al. paper. For example, Derek Lowe at In the Pipeline writes that
There's nothing here that any drug company's bioinformatics people wouldn't be able to do for you, as far as I can see.
So why haven't they? Well, despite the article's mention of a potential 50,000 further peptides of this type, the reason is probably because not many people care. After all, we're talking about small peptides here, of the sort that are typically just awful candidates for real-world drugs.
I'm not going to try to evaluate either the novelty or the value of the work. But I do think that it's interesting to try to figure out why this particular letter to Nature got such a comparatively big play in the world's media. Is "grammar" really all that catchy a hook?]
[Update -- Fernando Pereira writes
I feel that the use of the term "grammar" in the paper is misleading. Sure, these regular patterns are grammars in the formal sense, but they yield finite languages, so there isn't any anything there different from the standard techniques (eg. position-dependent weight matrices) for representing such motifs in computational biology. Their use of Teiresias is pretty standard too for that particular tool. Teiresias can only discover non-recurring (Kleene star-free) patterns yielding finite languages. This is quite adequate for motif discovery, but would be useless for cases with recurring (eg. some transmenbrane proteins) or recursive (eg.certain RNA and protein folds) structure. Those were the applications of formal grammar that were discussed in David Searls' pioneering paper, not mere motif discovery.
That's a fair criticism. Of course, it applies to the paper's authors and to the editors of Nature, not to the popular press, who would have been just as happy to make an unenlightening connection to the kind of grammar that Americans used to learn in "grammar school", even if the paper in question had been about patterns that required grammars rather than position-dependent weight matrices to describe.]
Vaslav Tchitcherine, call your office
For deep background on the orthographic imbroglio in the news from central Asia ("Kazakh central bank misspells 'bank' on money", Reuters 10/18/2006; "Kazakh bank gets own name wrong", BBC News 10/19/2006), see chapter 34 of Gravity's Rainbow (pp. 338-359 in the 1995 Penguin edition). If you don't have a copy at hand, a convenient summary is available from Language Log ("How alphabetic is the nature of molecules", 9/27/2004; "Birlashdirilmish yangi Turk alifbesi", 9/27/2004; "Ask, and ye shall receive", 9/29/2004).
Let me point you in particular to a passage that describes an analogous controversy about the treatment of velar consonants in loanwords:
Most distressing of all is the power struggle he has somehow been suckered into with one Igor Blobadjian, a party representative on the prestigious G Committee. Blobadjian is fanatically attempting to steal ƣs from Tchitcherine's Committee, and change them to Gs, using loan-words as an entering wedge. In the sunlit, sweltering commissary the two men sneer at each other across trays of zapekanka and Georgian fruit soup.
There is a crisis over which kind of g to use in the word "stenography." There is a lot of emotional attachment to the word around here. Tchitcherine one morning finds all the pencils in his conference room have mysteriously vanished. In revenge, he and Radnichny sneak in Blobadjian's conference room next night with hacksaws, files and torches, and reform the alphabet on his typewriter. It is some fun in the morning. Blobadjian runs around in a prolonged screaming fit. Tchitcherine's in conference, meeting's called to order, CRASH! two dozen linguists and bureaucrats go toppling over on their ass. ... Could Radnichny be a double agent?
I haven't been able to find any news reports that explain which letters the current controversy over bank actually deals with: 'k' vs. 'q', or perhaps 'x'? If you know, please tell me and I'll tell the world.
[Several readers have written to suggest that the error might be the substitution of Қ for K, where the one in red is Unicode U+049A "CYRILLIC LETTER KA WITH DESCENDER", representing a uvular stop (IPA /q/), rather than Unicode U+041A "CYRILLIC CAPITAL LETTER KA", representing a velar stop (IPA /k/).
The site for the Kazakh Central Bank suggests that their name should be rendered as ҚАЗАҚСТАН ҰЛТТЫҚ БАНКІ:

So based on the Reuters story, which says that "On the new note, the word was written with an alternate Kazakh form of the letter K", you might guess that the mistake was to write БАНҚІ instead of БАНКІ.
However, according to Michele Berdy
Russian sources say that the letter "i" is missing from the end of the word; looks like both the Western sources got the story wrong. [...] The news reports in Russian state that the computer program at the mint dropped the letter.
I have to say that I find this a little depressing, and not just because it's one more embarrassment for the poor Kazakhs.
There's a simple matter of fact here. Did the banknote use the wrong form of "K" (and if so, what are the different forms of K, and which one should have been used)? Or did the banknote drop the final "I"?
It's not like you need a PhD in physics or neurophysiology to get that straight. You'd think that Reuters, "the world's largest international multimedia news agency", could afford to hire reporters and editors who would take the trouble to figure this out and communicate it to their readers, if they're going to bother to report it in the first place. ]
[Update -- a couple of minutes of poking around on the Kazakh Central Bank's web site turned up a picture of (what I think is) one of the bills in question:

If that's it, then the offense was to use Х U+0425 CYRILLIC CAPITAL LETTER KHA in place of the K, and the Russian news sources are wrong, whereas Reuters was merely vague (or wrong, if you don't believe that X is "an alternate Kazakh form of the letter K").
I suspect Radnichny, myself.]
[Update -- the mystery deepens... Michele Berdy writes:
Well, I was right when I thought my trust in the Russian media was misplaced. Now the question is: can we trust Russian speaking Kazakhstani blogs?
The bloggers say that:
при написании "Казақстаң Республикасың Ұлтық Банкі" была допущена ошибка "Банқі", хотя должно быть написано "Банкі" согласно правил казахского языка.
(In writing "Kazakhstan Republic Central Bank" there was a mistake in "Bank" [written banҚi] although [sic] it should have been written "BanКi," according to the rules of the Kazakh language.)
Another Russian-speaking blogger on another Kazakh blog notes the "K with a tail" that should have been a K "without a tail."
Neither matches the picture on the Central Bank site.
Hm.
Қ, K, Х, final vowel or not -- what is the truth about the Kazakh currency miscue?
Somehow these alternatives are all interconnected, because (I conjecture):
1. Kazakh has front-back harmony, in which velar consonants [k], [ɡ] and [ŋ] pattern with front vowels, while uvulars [q], [ʁ] and [ɴ] occur with back vowels.
2. Between vowels, the uvular stop [q] becomes the corresponding fricative [χ].
3. Therefore, if the borrowed word "bank" were construed to have front harmony (as the vowels А and İ rather than Ә and И in the National Bank's banner, above, seem to indicate), then the correct consonant should be K. But if the Kazakh version of "bank" were taken to have back harmony, then the uvular Қ would become (at least in pronunciation) Х -- if there is a final vowel!
4. On the other hand, there may be some question about whether this borrowed word participates in the native harmony system or not.
I emphasize that this is a guess, based on what (little) I know about general Turkic morphophonology.
In any case, Reuters, the BBC and Pravda apparently are not going to tell you what's actually going on here, so keep checking Language Log to find out.]
It is so neat and creepy
About a year ago, a certain 10-year-old started a conversation on the way to school by asking me "Isn't it creepy how Trinidad qualified for the World Cup?"
This puzzled me, because I knew that he was a great admirer of the Socca Warriors. So I tried to persuade him that creepy doesn't just mean "striking, interesting by virtue of being unexpected", but has overtones of horror and repugnance. However, my advice had no effect -- creepy, in a sense apparently devoid of any negative evaluation, has become a regular feature of his vocabulary. I thought that this was an idiosyncratic development. But I was wrong.
A couple of evenings ago, I overheard this exchange between two female undergraduates:
A: Where are you from?
B: Near <big city>.
A: Me too!
B: I'm from <suburb X>
A: No way! I'm from <nearby suburbY>!
B: Omigod! That's so creepy!
And here are some random examples from the net:
Isn't it creepy how many singers names start with J?
this is like my twin if i was asian and a grl i mean its so creepy how similar we are but shes like the grl i can count on being there and shes funny
I found this poem and its just really creepy how well it fits into my life with the Tyler ordeal.
It is so neat and creepy how accurate it is.
It's plausible to think of this as a case of metaphorical generalization follow by semantic bleaching. On this theory, creepy started out meaning something like "producing a sensation of uneasiness or fear, as of things crawling on one's skin"; then generalized to mean "annoyingly unpleasant; repulsive". This turned into "unusual in an unpleasant way", and then the unpleasantness became increasingly peripheral, and finally faded out entirely.
Another possibility is that this is an independent development form the original metaphor. What makes your skin crawl may sometimes be awe at something with a supernatural quality, rather than disgust at something repulsive:
TVGuide.com: Playing Ray Charles' longtime manager, Joe Adams, you had some nice front-row seats watching Jamie Foxx create his Oscar-winning portrayal. At the time, did you sense Ray would be something special?
Lennix: We certainly sensed that Jamie was going to deliver something very special — it was creepy how he channeled Ray Charles, and simply remarkable to watch — but we didn't know how people would respond to it. We were just proud of the story we were telling and how we were telling it.
Or maybe there was an abrupt inversion of evaluative sign, as when words like bad, wicked, evil, dope etc. come to be used in a positive way. Here's a suggestive net-example:
Last night the roomies and I went to Katie's for a potluck so good the food was wicked retarded. It was creepy how well everything went together everyone made dishes with fall veggies
By any of these routes, this development is natural enough that it probably has occurred many times, sporadically and independently, before beginning to pick up a critical mass of users (or at least some pockets of them). I wonder whether the beginnings of the current development are recent enough that the process could be tracked on the basis of evidence from informal text on web.
[Several readers have written to suggest that this all just represents the use of creepy in the sense of "uncanny". That's essentially the second sort of semantic dynamics that I suggested as a possible route to the examples I cited. Wherever they come from, though, these examples remain unexpected and even anomalous for people like me, to whom creepy has unavoidable associations of repugnance.]
[Update -- Becci writes that's she's a member of the creepy=uncanny generation:
Hi! I just wanted to add myself to the list of people who use "creepy" to mean "uncanny". I use "weird" in the same way. (I do use both words in a traditional sense as well, though!) For the record, I am 25 years old and until last year, lived in a suburb of Colorado. My husband, who is the same age but grew up in Toronto, is constantly baffled when I refer to something as "creepy" or "weird" but don't mean it in a negative way. I have no idea where I picked it up, but it seems very natural to me. Basically, yours was a very timely and appropriate post! Thanks!
And Craig Russell suggests that he's a half a generation behind:
I too have noticed the new sense of the word 'creepy' that you mention in your Language Log article. This seems to be a part of my younger brother's usage, but I had assumed that it was particular to him or, at least, him and his group of friends (I'm 26; he's 16). I think I have some sense of the path of the word's change. Even to me, one of the senses in which I understand and use the word is "coincidental in such a shocking way that one begins to sense that it is perhaps not a coincidence at all," as in "it's creepy how every time she takes a walk, *he's* there," (the implication being that he's stalking her).
I get the feeling that that it's from this specific sub-meaning that the new development has arisen; most of the examples you give are of coincidences that are judged to be almost TOO unlikely to have happened. Perhaps there is also an element of the supernatural at play; the sense could also be "so coincidental and unlikely that one suspects there are some divine or supernatural forces at work." I imagine that one of the commonest occasion when one hears "creepy" is during movies or TV shows about the supernatural (which seem to be extremely popular for teenagers; how many horror movies are released each month?), so "possibly involving the supernatural" has come to be one of its normal definitions.
And of course, as you say, it is easy to imagine the word from any of these meanings losing its negative sense.
And Ben Zimmer observes that uncanny itself may have followed an analogous path earlier:
On "creepy" creeping into "uncanny" territory... Keep in mind that "uncanny" can often have overtones of horror and repugnance. This is especially the case when "uncanny" is used as a translation-equivalent for German "unheimlich", as in Freud's famous essay "Das Unheimliche" (1919), usually translated as "The Uncanny". From a translation:
http://www-rohan.sdsu.edu/~amtower/uncanny.html The subject of the 'uncanny' is a province of this kind. It is undoubtedly related to what is frightening — to what arouses dread and horror; equally certainly, too, the word is not always used in a clearly definable sense, so that it tends to coincide with what excites fear in general. Yet we may expect that a special core of feeling is present which justifies the use of a special conceptual term. One is curious to know what this common core is which allows us to distinguish as 'uncanny'; certain things which lie within the field of what is frightening.
In fact, the glosses given for uncanny by the OED are:
1. Mischievous, malicious. Obs.
2. Careless, incautious.
3. Unreliable, not to be trusted.Obs.
4. Of persons: Not quite safe to trust to, or have dealings with, as being associated with supernatural arts or powers.
5. Unpleasantly severe or hard.
6. Dangerous, unsafe.
In modern American usage, I have the impression that most of the negative associations of this word have been bleached out. Consider for example this SI passage, where uncanny just seems to mean "unusually skillful":
What was readily apparent from the moment he won the opening face-off is that Malkin is an entertainer. He's hockey's equivalent to a Jose Canseco or David Ortiz, a bomber who demands your constant attention because a highlight reel moment is possible every time he joins the play. He demonstrated that throughout the night, with his Gumby-like maneuverability when carrying the puck, or his uncanny passing. Memorably, in the third period he laid one seeing-eye beauty that darted its way through three Devils defenders and onto the tape of Whitney, who blasted it wide.
]
October 18, 2006
And after R comes S
Jonathan Starble, writing in Legal Times:
As one of its final acts last term, the U.S. Supreme Court issued Kansas v. Marsh, a case involving the constitutionality of a state death-penalty statute. The 5-4 decision exposed the deep divide that exists among the nation’s intellectual elite regarding one of society’s most troubling issues—namely, whether the possessive form of a singular noun ending with the letter s requires an additional s after the apostrophe. [ "Gimme an S", 10/9/2006]
[Hat tip to Margaret Marks at Transblawg]
One of the interesting aspects of Starble's piece is that he documents variation not only among the justices, but also within the writings of one of them, namely Antonin Scalia:
In Marsh, Scalia wrote a separate opinion that concurred with the substance of the majority opinion but nonetheless revealed a clear ideological discord with Thomas. Unlike his colleague, Scalia appears to believe that most singular nouns ending in s still demand an additional s after the apostrophe. Thus, in his Marsh concurrence, Scalia repeatedly referred to the relevant law as Kansas's statute. He similarly added an s to form the words Ramos's and witness's.
Yet in other parts of the opinion, Scalia added only an apostrophe to form the words Stevens', Adams', and Tibbs'. Based on this, it would seem that he believes the extra s should be omitted if the existing s is preceded by a hard consonant sound. So, whereas Thomas makes his s determination based strictly on spelling, Scalia appears to look beyond the spelling and examine pronunciation as well. [...]
...[O]ne would assume that a noun with a vowel as its penultimate letter and its final sound would present the most compelling possible case for adding an s after an apostrophe. Yet in a 2003 opinion, Kentucky Association of Health Plans v. Miller, Scalia repeatedly referred to the possessive of Illinois as Illinois' rather than Illinois's. He has also shown other inconsistencies, such as his repeated use of the word Congress', which is inexplicable in light of his acknowledgment of the word witness's in his Marsh concurrence and his use of the word Congress's in his 2004 majority opinion in Vieth v. Jubelirer.
On this question, I agree with Associate Justice Scalia. At least, I'm rarely certain what the spelling should be in such cases, and so I add s or not, as the spirit moves me. If this is the thin edge of the moral-relativist wedge, so be it -- Antonin and I stand together, behind the right to follow the dictates of conscience in each individual s+possessive circumstance.
In any case, let the record show that I resisted the temptation to draft a title along the lines of "Possessive is nine tenths of the law"...
[On a slightly more serious note, here are some earlier LL posts on the use of metaphors from law, religion, morality and hygiene in discussing linguistic usage:
"The theology of phonology" (1/2/2004)
"A field guide to prescriptivists" (4/13/2004)
"Disgust for accents: pre-adaptation or figure of speech?" (8/12/2004)
"Horace and Quintilian on correct language" (1/9/2005)
"Wrong for so long" (4/13/2005)
]
[Update -- Joseph Ruby writes:
S sounds like z (Adams) -- no additional s -- Adams'
S sounds like s (Kansas) -- add the s -- Kansas's
This is not original with Scalia. See, e.g., http://www.kentlaw.edu/academics/lrw/grinker/LwtaApostrophes.htm. It may be Supreme Court style for all I know.PS- the Illinois corollary appears to be that when the s is silent, no additional s is required. The apostrophe indicates that the silent s is now to be sounded.
Hmm. Given the rest of Starble's examples, it seems unlikely that this is SCOTUS style in general. And does Ruby's exegesis imply that Justice Scalia usually (but not always) pronounces Congress with a final [z]? No, I think that the "situational (orthographic) ethics" theory fits the data better.
(Note that if we were being serious about this, which we're not, we'd start by distinguishing usage in pronunciation (is an extra [əz] added to the sound?) from usage in orthography (is an extra s added after the apostrophe?) In the cases under discussion, both kinds of usage seem to be variable, but in somewhat different ways.) ]
Today's blog is brought to you by the letter R
 And today, we're going to talk about the moon
again. A little time ago, a nice man called Peter Shann Ford told us a
story about
the moon. Do you remember? That's right, he told us about the first
thing that was spoken by the first man on the moon, who is called
Neil. He is an astronaut. Peter told us that Neil, who is a nice
astronaut, said "That's one small step for a man, a giant leap for
mankind." What a nice thing to say! And it fits so well here on this
little bloggy thing called Language Log that you're reading, because we
are all about being nice. But hold tight: I have to tell you that some
very bad people, called
cynics, have said that Neil made a slip-up and said "for man" instead
of "for a man." Let's not be bad people. Let's believe what the nice
man called Peter told us that the nice astronaut said.
And today, we're going to talk about the moon
again. A little time ago, a nice man called Peter Shann Ford told us a
story about
the moon. Do you remember? That's right, he told us about the first
thing that was spoken by the first man on the moon, who is called
Neil. He is an astronaut. Peter told us that Neil, who is a nice
astronaut, said "That's one small step for a man, a giant leap for
mankind." What a nice thing to say! And it fits so well here on this
little bloggy thing called Language Log that you're reading, because we
are all about being nice. But hold tight: I have to tell you that some
very bad people, called
cynics, have said that Neil made a slip-up and said "for man" instead
of "for a man." Let's not be bad people. Let's believe what the nice
man called Peter told us that the nice astronaut said. And let's not fret. There are so many things not to fret about, that it will be easy. Let's not fret about the fact that the nice man called Peter did not use the very pretty pictures that bad people called linguists who are villains like to use to see what someone has said. They call them "spectrograms" which sounds like a very evil thing that a very bad villain person would use to take over the world. (Say "Mwahahahaha! Muhuhahaha! Mwahahaha!" Now you know what crazy bad villain linguists sound like, so you can be on your guard. Don't *ever* let a linguist give you sweeties.) And let's not fret about the fact that there wasn't any more time between "for" and "man" than there was between "for" and "mankind" when the nice man called Neil said "for mankind" which was an especially nice thing for Neil to say. It's nice to do things for mankind. That shows how nice Neil is. And most of all, let's not fret about how people say "r".
The nice man called Peter said that when people say "r" they put their tongue up extra high. It's not rude to do that, because it's inside your head! (No not "upside your head" - I don't even know what that means. Say "oops upside your head," say "oops upside your head." Wasn't that fun!) And when people have finished saying a word with an "r" at the end, Peter said they quickly put their tongue back down again. Do you know what happens when you put something down quickly, or even super dooper whooper quickly? Why, it makes a great whoooooshing noise!!!! And Peter says that after the nice man called Neil finished saying "for," he still had his mouth open. It wasn't rude to have his mouth open for three reasons. First, he wasn't eating. Second, he was wearing a big ol' space helmet, so nobody could see that his mouth was open. And third - now this is the important one - it was ok for Neil to have his mouth open because he was trying to say "a." You don't believe me! Well, I never. OK, boys and girls and journalists: try saying "a" with your mouth closed. Hah, hah! That wasn't an "a" sound! It sounded just like "mmmm", or else the noise that a gang of those linguist villains make when you round them up and duct tape their mouths.
Anyway, you remember that the nice astronaut man called Neil had his tongue up in the air because he was saying "r" at the end of "for" and then, keeping his mouth open so as to say "a", he put his tongue down super dooper whooper quickly, and it made a whooshing noise. But it was only a little whooshing noise because Neil's tongue is not a very big thing. And for many, many years nobody noticed that whooshing noise. And then the nice man called Peter came along and he looked at nice pictures called "waveforms" showing what Neil had said. And do you know what? Peter could *see* the whooshing noise on the nice pictures he made. It looked like a little bumpy bit. And that's how Peter knew that Neil had been trying to say "a." If Neil hadn't been saying "a" he would have closed his mouth first, because even with a space helmet on when you're not eating it might be a little bit rude to keep your mouth open, and second because he was about to say "m" and everybody knows you can't say "m" with your mouth open. Let's try it! Naaaah, that wasn't an "mmm" sound, it sounded like the noise your editor makes impatiently when your hot science news article has unnecessary details like references and facts, or like the noise those bad villain linguists make after you bloody them up just a little bit.
Isn't it amazing! One little drop of a tongue makes a whoosh that means that lots of bad cynical people were wrong about the nice astronaut for years and years and years, and the nice astronaut was right after all! What a nice story the nice man called Peter came up with! And shame on any wicked linguists who point out that people don't always lift up their tongues when they say "r" in the way that the nice man Peter said they did. No, you say - surely it can't be that linguists are so wicked that they would rain on Peter's parade? Well, you might think nobody would be so horribly horrible as to do things that might ruin such a very good story. That's what I would think too. But Mark Tiede at Haskins Lab and Suzanne Boyce at the University of Cincinnati, which must be bad places, even though Mark and Suzanne helped me write this blog post for which I'm grateful, have done something very evil called "research" which is what mad scientists do. You can see what bad people these linguists are if you look at the pictures underneath, but first try making an "r" sound in 33 different ways. Isn't it fun! But, seriously, I have to tell you that the pictures were made using money which the government took from your mom and dad. Scary, huh?

Yuuuuuuchhhhhhh. It looks like the wicked linguists working for evil government people waited until people were saying "r" and then cut their heads right down the middle. I wish we had color.
You know what a wicked linguist would think if the wicked linguist were here now? The wicked linguist would think that people make the letter "r" in oh so many ways, like in the pictures, and that when people finish saying "r" and move their tongue back into a rest position they might not flick it down quickly in a way that would make a big whoosh but might just relax it so that the bulge went out of it which might not make a whoosh at all though nobody really knows until they make whoosh measurements, and that if that's what the nice astronaut called Neil does when he's finished saying "r" then it wouldn't make a whoosh at all, and then the little bumpy bits on the nice man called Peter's nice waveforms wouldn't really tell us even the tiniest little anything at all about whether the nice astronaut called Neil was trying to say "a", and then the whole beautiful story wouldn't be at all like anything that really happened for real but would just be a fairy tale, and fairy tales are great but don't really belong in newspapers and on news websites and on news programs on the radio and on news programs on TV because fairy tales are not news. Evil people have very long thoughts, you see. It's called "mania."
But we don't need to listen to what some imaginary evil maniac linguist would say. We can listen to what the nice astronaut said. A nice man called Garth Wiebe did a clever thing and then told us about it at Language Log. He slowed down some of what the nice astronaut said so it lasts 10 times longer. Try saying it that way yourself, and bounce up and down slowly like you were on the moon: "ffffffffffoooooooooorrrrrrrrrr aaaaaaaaaa mmmmmmmmmmaaaaaaaaaannnnnnnnnn. That was super fun!!! Now you can listen to what a super slow astronaut sounds like - it makes him sound like a very nice whale!
October 17, 2006
Ask Language Log: dotless in Georgia
Matthew Stuckwisch asks
I'm a frequent reader of Language Log and figured this particular thing I started noticing in Georgia would interest you. More and more when I drive through to Atlanta, road signs no longer say, for instance, "Marietta", rather "Marıetta". It seems that the newer signs have begun to substitute <ı> for <i> across the board. However, I've never seen the dotless-i in English otherwise. Is there a progression that I don't know about to get rid of the dot, or is it some odd thing that Georgia is doing? It's definitely not just one or two signs whose dots have fallen off, it's common enough that it has to be a style issue.
Pending a response from the Georgia DOT about whether they have a new policy to go DOTless, I certainly can't offer any authoritative comment. However, Turkish (and some other Turkic languages) have both dotted and dotless upper- and lower-case i; some typophiles apparently prefer dotless i in some contexts; and there are some corporate logos that use dotless i, e.g.
So perhaps some highway signage authority might have decided to go with a font whose i's are dotless?
If you have any more information on this possible trend, let me know.
[Update -- Jon Peltier suggests an economical or perhaps ecological motivation:
In one of the Paul Bunyan type stories I recall from childhood, the accountant for the lumberyard learned to stop dotting his i's and crossing his t's, in order to save gallons of ink. He wrote large, apparently.
And Joe Stynes points out an Irish connection:
In the 1940s, Irish spelling was simplified and the uncial script font used thitherto was replaced with modern Latin typefaces. One proposal was to replace i with ı, to contrast better with í. This was not implemented for printed matter, but more recently (perhaps in the last 20 years), it has come into use on bilingual roadsigns, where title-case Irish names are displayed above upper-case English ones. I don't know if this is a revival of the 1940s proposal or part of a global dotless-signage trend.
]
[Update #2 -- Michael B. Klein wrote:
I think I've found where Georgia is sending all those surplus dots -- they deliver them to The New Yorker and The Economist magazines, where they're used to create superfluous diaereses in words like "coöperate," "reënactment," and "preëxisting."
My own suspicion is that surplus road-sign dots are being recycled into heavy-metal umlauts -- surely The New Yorker and The Economist use only the finest European cold-pressed virgin diaereses? <Sub-update -- Lane Greene points out something that I should have noted myself, namely that "The Economist doesn't use the dieresis, the heavy-metal umlaut or any other kind of two-dot marker, except in German names with umlauts. To seperate doubled letters belonging to different morphemes and looking bad next to each other, we use hyphens: re-election, book-keeping, co-operation, etc." But I'm sure that if The Economist *did* use diaereses, they would use only the finest quality dots -- though perhaps with some recycled content to help preserve the environment.>
Meanwhile, Dick Margulis has taken action:
I posted a link to your post over on comp.fonts and alt.binaries.fonts. I know there is a recently released highway signage font that resulted from several years of research on legibility under driving conditions; I do not know whether that font is dotless, nor do I know whether it has been adopted by Georgia. But someone in one of those two news groups will know the answer to that and should write to you about it at some point in the next day or so.
So I took action, too -- I asked Google about {highway signage font}, and learned that:
America's big green highway signs are about to become more legible. Type designer James Montalbano announces that after years of development, the US Federal Government has finally given official interim approval for his Clearview to be used on all Federal roads.. The ClearviewHwy site covers some of the extensive research Montalbano has presented at various type conferences.
However, the samples presented on the cited page are not dotless:
and thus we'll need to find another explanation for any errant dots in Atlanta.]
[Update #3 -- two new theories. Angela Tompkins thinks that the (alleged) Georgia sign-makers have started using ligatures:
The dotless i is what is known in typography as a ligature. They are used where a combination of letters would be less legible without them (most commonly fi, fl, ffi and ffl). The letter forms are replaced with one form designed to work together better, reworked in the area where the glyphs interfere with each other.
The ri ligature is somewhat uncommon compared to the ones mentioned above, and I would need to see more examples of signs to know for sure, but this might be an answer to what is going on in Georgia.
But Matthew Feinstein writes:
I searched Google images with 'Georgia Highway Signage' and found the attached image. It suggests that there's a problem in Georgia that goes beyond dotting the i's.

I believe that Matthew is suggesting that Georgia sign-makers are somewhat randomly mixing upper and lower-case letters. If so, that would explain a rash of dotless i's -- they're not dotless, they're majuscule.
I hope it turns out that actual dotless-i signs are actually spreading in the Atlanta area -- the least interesting explanation would be that someone made a random local mistake, or a random local stylistic choice.]
[Update #4 -- Slibib Bibils writes
More trıvıa: the band Spinal Tap sports a dotless i. Georgian sign font could be an homage.
Of course, they did make up for the missing i-dot with a heavy-metal umlaut over the n:

And Charles Martin has a (very plausible) materialistic explanation:
I suspect there's an even easier explanation for the "dotless i' issue: those signs are basically made with retroreflective tape. The letter standard (http://en.wikipedia.org/wiki/FHWA_Series_fonts) includes dots ... but little dots, which have comparatively much edge to total adhesive surface, tend to peel off easily. So what they're seeing are very probably signs that have just lost their dots.
This wouldn't explain why there should be a cluster of cases around Atlanta -- but of course our evidence for that clustering is not exactly compelling, so far. And if the cluster really exists, I guess that the Atlanta sign-makers might have gotten a shipment of marginal tape, or something like that.
Finally, Peter Metcalfe observes: "I'm impressed at all this research over an iota of difference..."
We can't compete with the energy that went into the argument between ὁμοούσιος and ὁμοιούσιος, back in the fourth century. But these days, where else but in the blogosphere can you hope to find so much informed speculation about such a small point? At least, it'll turn out to a small point if there's a pattern of Atlanta-area facts to explain in the first place. Otherwise, I guess, it's a purely spiritual exercise.]
[I thought we were done here, but all the way from Perth, Western Australia, Robert Corr writes in with some actual evidence about the typography of road signs in Georgia:
You might be interested in this site, which includes a great many pictures of Georgia's roads and road signs:
http://www.gribblenation.com/gapics/gallery/
Most of the photos are several years old, but some are from May 2006. My quick squiz didn't reveal any shortage of dots.
But the dotless i's are in there! Here's one:

And here's another:

And a third:

And here's one where we can see the dots in the very process of starting to wander off:

All from the Atlanta area! Ain't the internets wonderful?]
[Update 10/20/2006 -- Eric Vinyl writes:
Almost all the street name signs in L.A. have dotless Is. With the abundance of Spanish toponyms, I thought I would have noticed whether or not the lowercase Js in the City of Los Angeles are dotless as well, but I have not. Perhaps an astute Angelino can inform.
A Google query turns up some pictures and discussion (from astute L.A. residents) here. Example of "[t]he modern, dot-less street name sign. The one in most common use today. Boasts the cool flair design, in which the edge of the street name sign is cut at an angle.":

More information is here. Meanwhile, should that be "Angelino" or "Angeleno"? Or are they different?]
[Update 10/21/2006 -- Paige Scandell (who may or may not be the same person as Eric Vinyl) explains
My bad. I ain’t from SoCal (and proudly not so!)
A cursory Google search (`los angeles angelino OR angeleno') does show that, indeed, the preferred spelling is Angeleno. The thing that threw me off is that it’s anglicized, the final syllables pronounced much the same way -ino would be in Spanish. I just assumed this was from angeleño, but googling `gentilicio los angeles' reveals this thread on Word Reference. It’s even in the DRAE (which lists angelino first as someone from Los Angeles, Biobio) and some Catalana who stayed in La-la Land for a minute confirms:
I lived in LA for a while and yes, "angeleno" (in English) was the common word, as "angelino" was for Spanish speakers.
I couldn’t say whether I picked that up from reading La Opinión or not. And, I should have been clear; it can be any astute Angelen@.
]
October 16, 2006
Language Log changes personality
There have been rumblings. It has been hinted by some out there in cyberspace that all we do on LL is call bullshit. Journalist/politician/academic says X about language, LL says it's BS. Enough of your complaining about our complaining - we will complain no more. From now on, it's all good.
Now, let's see, what did this morning's mailbag bring in? Why, Eric Bakovic spotted a wonderful article about language in the UK's Daily Telegraph, a broadsheet which, with a sensuously right winged tinge to its reporting, embodies all that is good in the British press. On the basis of a study of bilinguals speaking in different language, it turns out that "English-speaking Americans are typically more conscientious, agreeable and outgoing than native Mexicans, but also less neurotic.'' Well, who'd have thought?
Here's the masterpiece in full:
| A
second language 'changes personality' By Robert Matthews (Filed: 03/07/2005) If only Basil Fawlty had learnt a little Spanish. Psychologists have discovered that people take on the characteristics of foreign nationals when they switch into their language - and such a change in the embittered hotel owner could well have improved life for the hapless Manuel. The personality changes, however, run deeper than a desire to gesticulate wildly when talking in Italian or to plunge into gloom when speaking Russian. According to research, using different languages alters basic characteristics traits such as extroversion and neuroticism. Researchers at the University of Texas made the discovery while studying the personality traits of bilingual English and Spanish speakers in the United States and Mexico. They began by establishing the attributes of native speakers, using the results of personality tests on almost 170,000 people. The results showed that English-speaking Americans are typically more conscientious, agreeable and outgoing than native Mexicans, but also less neurotic. |
By the most minor of oversights, the article's explicit citation to the original study was accidentally cut off by the typesetters. Not that we mind. Why confuse the reader with details like who wrote the thing, when "Researchers at the University of Texas" tells us all we need. But you know how we are at Language Log - bunch of geeks. Details, details, details. We can't help ourselves. So we couldn't help asking some of our friends to track down the original study. And they did. It's Do bilinguals have two personalities? A special case of cultural frame switching, by Ramirez-Esparza, Gosling, Benet-Martinez, Potter, & Pennebaker, Journal of Research in Personality, 2006. Three of the five authors are indeed colleagues of mine at UT Austin (I have a split academic personality, but expect to be cured soon), and so I emailed a couple of them. The first author, Nairan Ramirez-Esparza asked me to post this link to an article which says what they did in their own words. And these words are just the slightest little bit different from those in the Telegraph. They don't conclude that English-speaking Americans differ from Mexicans, but rather that along various dimensions bilinguals speaking English score differently on various personality scales than when they are speaking Spanish. It's a careful piece of work, and a cute result.
But there *are* some results mentioned in the original paper that more closely resemble what is concluded in the last sentence of the Daily Telegraph article, and these are based on results of studies using internet questionnaires (discussed in Should we trust Web-based studies? A comparative analysis of six preconceptions about Internet questionnaires, Gosling, S. D., Vazire, S., Srivastava, S., & John, O. P. (2004), American Psychologist, 59.) It is the case that when Mexicans fill out these online studies, they end up as a group with slightly different mean scores than Americans, and the differences are statistically significant. Another cute result. And it means the Telegraph article really isn't that far off base, though the wording is perhaps a tad careless.
Now if I was a cynic, I might wonder. What I might wonder is: is it reasonable to use the fact that the same person scores differently on the test in different languages to reveal differences in people's behavior when they speak different languages? Or should we use the same results to normalize the tests across the two different languages? This could be used to counteract any biases potentially introduced into the language of the personality tests when the experimenters designed the bilingual materials? But I'm not a cynic, so I shouldn't wonder. At Language Log, everything smells of roses, right?
Well, OK, maybe I'm a little bit of a cynic. And I must make clear that the researchers were fully aware of the possibility that translating questions in the materials would itself introduce bias. They used a sophisticated statistical comparison to control for such biases in individual questions. And they did, in fact, determine that in one case, the translation of a question might not be faithful to the original, while for the remainder of the 40 questions there was no evidence of such bias. Still, I think it's fair to say (and this echoes the closing discussion of the Ramirez-Esparza et al paper) that the results obtained on differences between speakers using different languages, while striking, are hard to interpret.
[Acknowledgments: Eric Bakovic spotted the Telegraph article via http://digg.com/general_sciences/A_second_language_changes_personality, itself by way of http://lingnews.net/story/152/. Qing Zhang and Nikki Seifert identified the relevant study. And thanks to Nairan Ramirez-Esparza, who was very quick to reply to my email asking for information.]
The passive in law
A friend who's in law school reports that concern about the passive voice surfaces every so often there. In one context, the passive is (effectively) required, in another, prohibited.
In Evidence class, the professor recently pointed out that in summation to the jury, "The evidence has not been disputed" is fine, but "The defendant did not dispute the evidence" is prohibited by the rules, because the defendant's right to refuse to testify cannot be questioned.
Meanwhile, in Legal Writing classes, the professors insist on Avoid Passive for briefs and memos. Here I see the long influential arm of Bryan Garner, whose The Winning Brief: 100 Tips for Persuasive Briefing in Trial and Appellate Courts (2nd ed. 2004) and earlier books on legal writing come down hard on the passive voice (and restrictive relative which and sentence-initial linking however, among other things).
zwicky at-sign csli period stanford period edu
Guys are a bit gabbier in Dutch, too
Hugo Quené, "Multilevel modeling of between-speaker and within-speaker variation in spontaneous speech tempo" (ms., 11 Oct. 2006) "investigates several factors affecting tempo in a corpus of spoken Dutch, consisting of interviews with 80 high-school teachers". Among the findings: "male speakers produce longer phrases (containing 11.1 syllables on average) than female interviewees (10.4 syllables)"; and as a result (since longer phrases are well known to have a shorter average word or syllable duration), "male speakers produced significantly shorter syllables (i.e. faster tempo) than female speakers". Also:
"...the sex difference is also observed in the total number of syllables in each interview: for female speakers, the average interview length is 3541 syllables (s = 765), for male speakers 3855 syllables (s = 499); t(67) = −2.173, p = 0.033. Thus male interviewees are indeed more talkative than female ones."
So here is more data, from a different sort of talk in a different language, that contradicts Louann Brizendine's widely-quoted but empirically unsupported assertions that women talk more than men, and also talk faster.
Hugo goes on to point out that
[s]milar gender differences in talking behaviour have been reported for a large corpus of telephone conversations, where male speakers produced more words than female speakers (mean 926 words vs. 867 words, respectively, in mixed-sex conversations; Liberman (2006)), as well as for formal meetings, where male participants talk longer, and interrupt more often, than female participants (Holmes (1995)). These small but significant differences are most likely coupled to gender differences in the speakers’ social dominance and status.
Liberman (2006) is a Language Log post ("Gabby guys: the effect size", 9/23/2006). Holmes (1995) is Janet Holmes, Women, Men and Politeness (Longman, London).
Hugo is working with a published corpus, so you can check his work or add to it:
The Corpus of Spoken Dutch (Oostdijk (2000)) was used to investigate which factors contribute to (variation in) speaking rate. For this purpose, we concentrated on the subcorpus containing interviews with N = 80 high-school teachers of Dutch in the Netherlands (Van Hout et al. (1999)). Interviewed speakers (‘interviewees’) were stratified by dialect region (four regions within the Netherlands), sex, and age group (below 40 vs. over 45 years of age), with n = 5 speakers in each cell. All speakers are assumed to speak a variety of Standard Dutch as used in the Netherlands. All interviews were conducted by the same interviewer (male, age 26), and similar topics were discussed across interviews. Hence, language variety, conversation partner, and conversation topics were eliminated as confounding factors, and the speech samples were highly comparable among speakers.
Note that there's some reason to think that the women in this sub-corpus might have been slightly more talkative if the interviewer had been female -- there's some discussion of this point in the cited LL post -- but we're a long way away from the claim that women produce two to three times more words than men do, or that they talk twice as fast.
Sex (anti-)stereotypes aside, Hugo's paper offers an interesting lesson in scientific reasoning. He starts by replicating a previously-published result about the effects of region, sex and age on speaking rate:
Results for this model (1) confirm previous analyses of speakers’ average tempo in this corpus (Verhoeven et al. (2004)). First, comparisons of the four regional means show that speakers from the West region (the linguistic center of the Netherlands) produced significantly shorter syllables (i.e. faster tempo) than did those from the other regions (Χ2 = 16.6, df = 3, p = .001). Second, male speakers produced significantly shorter syllables (i.e. faster tempo) than female speakers (Verhoeven et al. (2004)). Third, older speakers produced significantly longer syllables (slower tempo) than younger speakers. For each additional year of age, ASD increases with 0.87 ms. With a grand mean ASD of 212 ms, the tempo difference between speakers aged 25 and 65 is (40 × 0.87)/212 or about 16%. This age effect is well above the JND for speech tempo of about 5% (Quené (2006)).
However, when he also models the effect of phrase length, he finds that the "facts" turn out to be different. Maybe region, sex and age don't really influence speaking rate after all, except indirectly via their influence on phrase length:
First, results confirm that phrase length indeed has a large and highly significant effect on speaking rate, as known from previous research ... Speakers produce longer phrases with shorter average syllable duration, hence with faster speech tempo. Secondly, the effects of the between-speaker predictors (sex, age, and region) all disappear, if phrase length is included as a predictor in the model.
In other words, it seems that speakers of different ages, sexes and regions are producing phrases of somewhat different lengths, on average; and phrases of different lengths vary in tempo; but once this indirect effect is allowed for, there are no longer any statistically-significant differences in speaking rate among the classes of speakers.
Issues like this come up in any correlational study, and responsible scientists spend a lot of time thinking them through, and trying different sorts of analyses (or different sorts of experiments) to sort them out. It's nice to see such a clean example of this process.
[The reasons for the phrase-length effect are discussed in another Language Log post, "The shape of a spoken phrase", 4/12/2006, and in a paper, Jiahong Yuan, Mark Liberman and Christopher Cieri, "Towards an Integrated Understanding of Speaking Rate in Conversation", ICSLP 2006.]
Bill Bright, 1928-2006
From the chair of the department of linguistics at the University of Colorado:
It with sadness that I write to let you know of the passing of a great linguist, friend, teacher and mentor. Lise has asked me to let you know that Bill Bright died today. I know that all of you will join me in mourning his passing and in sending our love and thoughts to Lise and her family. Bill was such a towering figure in the field and such a good friend to so many of us that it's hard to summarize his contributions. For those of you who are interested in learning more about his life and achievements, I recommend his detailed website: http://www.ncidc.org/bright/. I don't think we will soon see another linguist of Bill's stature: he had expertise in Native American linguistics, South Asian linguistics and sociolinguistics, and edited the flagship journal in our field, Language, for more than 20 years. He served as president of the Linguistics Society of America. He was also editor of the journal Language and Society. He was a prolific writer and an outstanding editor. He helped to bring an appreciation of linguistic research to the public through his work on Native American placenames in the US. Finally, he contributed to the life of the CU Linguistics department in more ways than I can mention. We will all remember the generosity that he showed to students who sought his expertise and the ways in which he brought his research to life through his lectures and public talks.
The Department is planning a memorial service for Bill, to be held on campus within the next couple of weeks. Our current plan is to hold the service on a Sunday afternoon. We will invite all who wish to share their memories of Bill to say a few words. I will let you know more details about the service as we solidify our plans. This service will be for the entire community, so I will most likely ask your help in disseminating the details.
Requiescat in pace.
October 15, 2006
Dietetic phonetics, exposed!
Here's the latest shocker from that bastion of journalistic integrity, The Weekly World News:
SWALLOW CONSONANTS, FEEL FULL ALL DAY
Hey, if the BBC Science Section can report, with a straight face, "'Vowels to blame' for German grumpiness," then is this headline really so far-fetched?
WWN has really nailed the art of faux-science reportage:
FLINT, Mich.--The French ability to remain slimmer than Americans despite a diet higher in fats and overall calorie density has puzzled nutritionists for decades. But a new study suggests that scientists are looking in the wrong place for the secret of Gallic leanness, and that staying svelte may have nothing to do with food at all.
"The answer is swallowed consonants," said Dr. Eric Gross, professor of biology at Lester College in Flint. "We're finding that the pronunciation of these sounds can induce a feeling of satiety in French speakers, and can lead, over the long-term, to lower body weight."
In French phonology, nearly all terminal consonants tend to be 'swallowed'--silenced via a complex sequence of mouth and throat movements. Researchers still debate the mechanism by which these movements result in feelings of fullness. Nevertheless, most scientists have focused their investigations on the flow and vibration of air in speakers' nasal passages. The hypothalamus--which regulates hunger--sits directly above these passages, and may be affected by air movements beneath.
Regardless of the cause, the salutary effects of French phonology remain certain. Dr. Gross' correlational study, soon to be published in the journal Nomos, reveals that university students enrolled in French language classes actually dropped four to six pounds during the course of a twelve-week semester.
"Obviously, the degree of weight-loss increases in language-immersion programs, like the Lester College Junior Year Abroad in Aix-en-Provence," Dr. Gross said.
Some scientists have rejected the new data, citing smaller portion size in French culture, or the effects of increased wine consumption, as the real determinants of Gallic thinness. But Dr. Gross predicts that these researchers will abandon their theories when faced with the flood of data from a global swallowed-consonant craze.
"They'll be eating their words, like everyone else," Dr. Gross said.
Before you start Googling for a biologist named Eric Gross, a journal called Nomos, or a Lester College with a campus in Flint, Michigan and a year-abroad program in Aix-en-Provence, first familiarize yourself with WWN's disclaimer: "the reader should suspend disbelief for the sake of enjoyment." And honestly, if mainstream news outlets are going to feed us nonsense about cow dialects and female volubility, then I think we might as well enjoy pseudoscience in its pure unadulterated form.
(Hat tip, Barry Popik.)
[Update: See this Languagehat post and comments thereon for further discussion.]
The end of the chapter: not a linguification
Let me mention one other thing about the recent this New York Times story about the death of Gerry Studds. The Times reports that Mr. Studds's husband, Dean T. Hara, said this in a statement:
Gerry often said that it was the fight for gay and lesbian equality that was the last great civil rights chapter in modern American history. He did not live to see its final sentences written, but all of us will forever be indebted to him for leading the way with compassion and wisdom.
Some Language Log readers who have followed the linguification thread might imagine that I would regard "He did not live to see its final sentences written" as a linguification. Not so.
This reference to seeing sentences written is a genuine metaphor, unlike most linguification as far as I can see. It happens to metaphorize something non-linguistic as something linguistic: episodes in history are metaphorized as chapters in a book of history, and thus the final events of an episode are seen, in terms of the metaphor, as the concluding sentences of a chapter. But this isn't what I call a linguification.
When we make the necessary substitutions to get back from the metaphorical image (sentences and chapters and word sequences) to the real world (events and episodes and time flow), the statement made is just right: Gerry Studds did not live to see the end of the episode (which Hara assumes we are living through the early stages of) in which full marriage equality is instituted for gays everywhere.
Linguification is very different. When David Leonhardt said in the Times recently that the phrase spiraling costs had "virtually become a prefix for the words" ‘health care&rsquo, he substituted an entirely false statement about word sequences (that the sequence health care virtually always has the sequence spiraling costs right before it in English running text) for an arguably true statement about the world (that there has been a great deal of public discussion of increases in health care expense over the past few years). The prefixing isn't a metaphorical image for temporal precedence or anything like that. He's not using a metaphor in any sense that I can see.
Metaphorical statements stay true under the translation to or back from the domain used as the source of the metaphorical imagery. If I say the boss is a pussycat (and let's agree for the sake of argument that it's a metaphor, not a novel word sense for pussycat, because those are different), I substitute some highly complex combination of stereotypical properties (like furriness, lovableness, strokableness, ease of handling, and delight in playing with balls of wool) for some highly complex combination of actual properties (things like informality, tractability, pleasantness, harmlessness, non-threateningness, and lack of aggression); but under that translation (which would be very difficult to be fully explicit about), my claim stays true: the boss is claimed to have the latter properties just as a kitten has the former set.
Again, take people who say Iraq is a quagmire. They are making a claim about the real Iraq by translating to another domain where it is portrayed as a bog you can get your feet stuck in. In the real world, difficulty of extracting US armed forces and other personnel (even when they are hated) from a country that needs protection from the danger of all-out civil war and expensive rebuilding and protection of its infastructure; in the analogous imagined world used for the metaphoric imagery, difficulty of extracting your feet when they are stuck in a bog. It's a good metaphor. And what makes it good is that its relevant details are pregnant with implications you can draw: just as your panicked struggles to escape from being stuck in a bog only makes your feet sink deeper in, so struggling to get out of a military occupation in an incipient civil war similarly makes things harder (packing to leave makes an army look vulnerable and ripe for attack; setting a departure time encourages insurgents to think they can win if they just hang on till that time, so they fight harder), and you sink deeper in.
The whole point about metaphor is that the things highlighted in the metaphorized picture should be just as true as the things about the real world that it metaphorically represents. We wouldn't use metaphor as a rhetorical device if it was just a matter of perplexingly replacing statements that are true by other claims that aren't. Metaphor isn't for bafflement. It doesn't slow comprehension down; it speeds it up.
His husband
The phrase "his husband" gets only about 127 kilohits on Google, which is not very many. Despite the various countries and states that have now made legal provision for gay marriage, I don't think I had ever noticed any phrase of this sort (husband as head noun with a masculine genitive NP determiner) turning up in national news sources before the death of ex-Congressman Gerry Studds this weekend. But the phrase Mr. Studds's husband occurs in this New York Times story, and I also heard it in one NPR radio news spot (though in another reading of the news later the same day the word "husband" had been replaced by "partner"). Not that long ago, linguists might well have referred to phrases like his husband as semantically anomalous; and I can well imagine that there might be languages (with both inalienable possession marking and obligatory gender agreement) into which it was not straightforwardly and directly translatable at all. But things can change in the legal and cultural spheres, and when they do, language use slowly changes as a result.
Notice that I do not have much time for the widely accepted notion that language determines culture / our perceptions / our concepts / our world, etc. I don't think the linguistic tail wags the cultural dog very much. The law was changed in Massachusetts, and as a result certain phrases in English that would previously have been regarded as bizarre changed their status, and were no longer legally bizarre at all. Retrospectively, and perhaps only reluctantly, language use will follow along behind.
More on pitch and time intervals in speech
 This is W.H. Auden, reading the first two lines of his villanelle "If I Could Tell You":
This is W.H. Auden, reading the first two lines of his villanelle "If I Could Tell You":
Time will say nothing but I told you so,
Time only knows the price we have to pay;
The picture shows the dipole statistics of pitch intervals in his voice. What does it mean? I'm not sure whether it means anything at all, but I thought it was a pretty picture, and it's part of an interesting exploration, so I'll share it with you.
This all started because I was curious about a paper by Maartje Schreuder and others, arguing that there are musical intervals implicit in the pitch contours of spoken Dutch (and other languages), which relate to the expression of emotions in the same way that such intervals do in music ("Poem in the key of what", 10/9/2006). I expressed some skepticism about the role of musical intervals (i.e. small-integer pitch ratios) in speech, but I was intrigued by the appearance of clear modes in the distribution of pitches in (at least some) spoken phrases. I suggested that "dipole statistics" might be an interesting way to look at distributions of intervals in speech, without requiring the segmentation of speech into "notes" -- and this picture is one of the first fruits of such an exploration. The details are below.
First, some background. The idea of looking at the pitch patterns of speech in musical terms is an old one. Until fairly recently, people explored this area by ear. For example, in 1775, Joshua Steele published Prosodia Rationalis: An Essay towards Establishing the Melody and Measure of Speech to be Expressed and Perpetuated by Peculiar Symbols, in which he tried to work out spoken pitch contours by removing the frets from his viola da gamba, imitating the vocal patterns on the instrument, and then transcribing the results.
These days, we can use computer programs to estimate the local periodicity of the voice, and plot the results as a "pitch track", in which the usual convention is to plot time from left to right, and fundamental frequency (often symbolized as F0) from bottom to top, in the same geometry as a musical staff. Here's a pitch track for the two lines of Auden quoted above. This is Auden himself reading the poem, and an audio clip is linked to the picture:
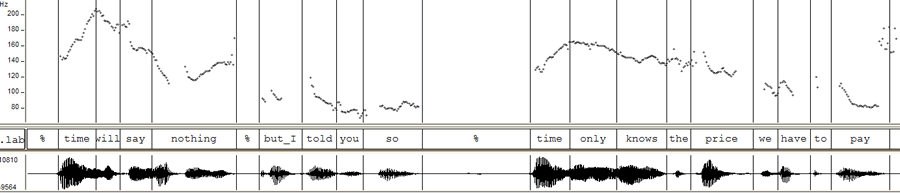
(This particular pitch track was calculated by a program originally written by David Talkin (now at Google) when he was at Bell Labs, based on an algorithm proposed by George Doddington when he was at Texas Instruments, and integrated into a free-software program called WaveSurfer created by Kåre Sjölander and Jonas Beskow at the Royal Institute of Technology in Sweden. It's one of the better pitch-trackers out there, though you have to realize that the pitch-tracking problem is difficult to solve well, and impossible to solve completely.)
The pitch track itself is of course a long list of numerical estimates, typically calculated a hundred times per second. For example, the numbers behind the plot above start out this way:
377.524475098 146.773223877 811.74230957 141.53427124 1352.58544922 144.847839355 1881.64099121 142.978637695 1937.74511719 143.269439697 2044.27075195 146.828552246 2099.38745117 150.982391357 1904.56750488 161.24609375 1822.4486084 165.136077881 1727.72424316 167.19380188 1704.8605957
The first row (where the pitch is labelled "N/A" for "not available") is the last of the series of centisecond frames where there isn't any voiced speech, and then we get into ten frames that track the pitch across the first tenth of a second of the beginning of Auden's pronunciation of the syllable "time". The F0 estimates aren't nearly as accurate as the displayed number of decimal places might suggest -- that's just what the program produces as decimal representations of its internal numbers. In a case like this, different plausible choices in the estimation process would give us slightly different values, and I'd guess (without trying it in this case) that there are by that criterion three or four significant figures here.
Once we have the pitch track, there are many different ways to reduce this long list of numerical values to a form that lets us talk about pitch values or ranges or intervals as properties of vowels, syllables, words or phrases. One traditional method is to pick peaks and valleys -- local maxima and minima of the contour -- while trying to avoid being fooled by occasional scattered points that lie outside the smoothly-varying range (or by the common octave errors in estimation). Another method is to divide the speech into phonetic segments, corresponding to consonant closures, open portions of vowels, and so on, and to derive characteristic values for these segments in some way -- the mean, or the median, or the maximum and minimum, or the median of the middle third, or various other percentiles, or some sort of amplitude-weighted measure. Other methods schematize the contour by fitting more sophisticated models of one sort or another (e.g. TiLT or Stem-ML or MOMEL/INTSINT).
If there were indeed musical intervals somehow involved -- as is undoubtedly the case in a capella singing -- none of these methods would necessarily bring those intervals out in a clear way. And the idea of looking at modes in the histogram of F0 estimates, used by Schreuder et al., is a cute one. It doesn't require any linguistic segmentation, it's relatively robust to occasional estimation errors, its structure can be related straightforwardly back to the original estimated pitch values, it's easy to compute. And such histograms, especially if we limit our attention to one or two spoken phrases at a time, seem to have quite a bit of structure. Here's the pitch histogram for the same two Auden phrases:
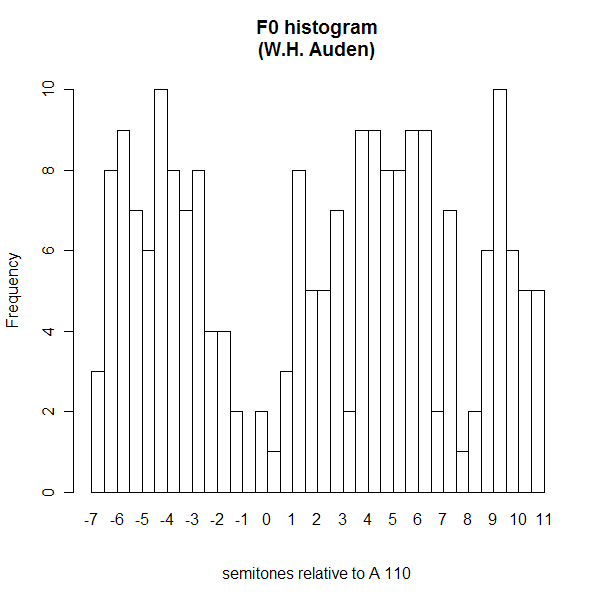
But what this structure really is, and what it means, is far from clear. The usual story would be: the modes in the histogram are relatively uninteresting artifacts, a simple consequence of the fact that pitch contours often involve fairly smooth peaks and valleys, whose relative pitch-values are part of the intonational pattern, but are not in any sense musical tones or musical intervals (i.e. pitch-classes related by a system of small-integer ratios). Another story -- the one that Schreuder et al. tell -- says that the modes are in fact symptoms of a pitch-interval system that functions in speech just as it does in music.
Although it's easy to calculate pitch histograms for spoken phrases, this doesn't directly address the question of what intervals (musical or otherwise) might be involved. So we might want to look at the distribution of intervals instead. But this raises the question of time -- which pairs of time-points should be compared?
The simplest answer would be to look at all time-relationships. Thus if we have six seconds of speech, with 600 pitch estimates, we would compare every estimate to all 599 other estimates, yielding 200*199 = 359,400 intervals to be counted up. But maybe temporally remote intervals don't really matter much -- in the case of the Auden lines we've been looking at, do we care that the pitch interval between a point in the middle of "will" and one at the end of "price", 4.394 seconds later, is 1.47? What about relations between the start of the poem and the end, a couple of minutes later? And maybe too-near intervals shouldn't be counted in the same way either -- do we care that we can find that same pitch ratio of 1.47 within the rapidly-rising pitch of the single syllable "time"? At least, it seems that we risk counting up apples and oranges in the same histogram bins.
One obvious alternative, at least for the purposes of exploratory data analysis, is simply to add the time difference as an additional dimension. Thus we'll look at all the pairs of pitch-values that are X centiseconds apart, for X={1,2,3, ..., N}, up to whatever time-span we think might be relevant, and make a separate histogram of pitch intervals for each time interval. Then we can plot the results with time differences on one axis, and pitch differences on the other axis, and some false-color representation of the count at each pixel. (This is related to concepts such as Buffon's Needle, and more closely to the idea of dipole statistics as a way of characterizing image textures, originally developed 45 years ago by my old neighbor at Bell Labs, Bela Julesz).
So I wrote a little R function to do this, using R's filled.contour( ) function to plot the resulting two-dimensional histogram. And this is what the result looks like for the two lines of Auden:
Note that in this plot negative pitch differences represent higher-to-lower pitch intervals -- thus the point at [-3, 12] represents the count of pitch-estimates 0.120 seconds apart where the second estimate is 3 tempered semitones lower than the first one (i.e. the two estimates are roughly in the ratio of 1.189 to 1). Hotter pixel values represent higher counts. Also, because the counts trail off very rapidly away from the maximum at [0,0], I've plotted the counts to the power of 0.33, so as to bring out the structure in the lower-count regions.
What does this mean? Like I said, I don't really know. The fact that there are a lot more falling counts than rising counts (i.e. more counts to the left of the midline than to the right -- 7908 vs. 2925, if we look at time intervals up to 80 centiseconds) is obviously related to the general pitch downtrends that are apparent in the pitch contour. The structures trending diagonally upwards and to the left, and diagonally upwards and to the right, obviously reflect the average rates of short-term fall and short-term rise, respectively. But these are things that we can see in the original pitch contour -- their reflection in this two-dimensional histogram of intervals is pretty to look at, but so far it's not bringing any additional insight, as far as I can tell.
At least it's true that different pitch patterns show up as different-looking patterns in plots of this kind. Thus if we compare the Auden clip to three other more-or-less-random selections of similar length, recycled from earlier Language Log posts, we see this:
|
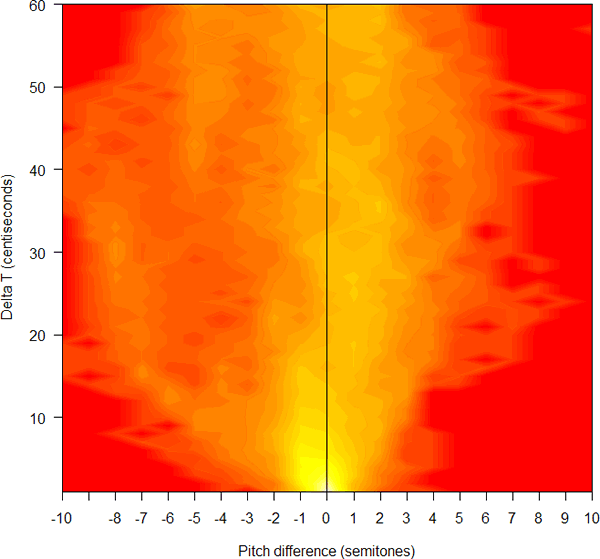 |
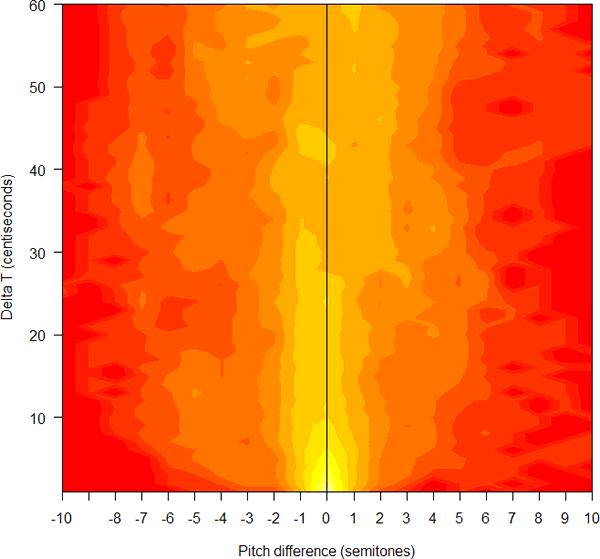 |
|
The first comparison is with a phrase from Ali G's interview with Noam Chomsky. ("Ali G in the land of colorless green ideas", 4/21/2006). Ali asks: "So when animals chat to each other, does them talk in language?" Here's the pitch contour (audio clip linked as usual):

Here's the pitch histogram:
And here's the plot of time- and pitch-intervals:
Note the larger amount of stuff to the right of the midline (7018 vs. 7317 counts), corresponding to the greater role of short-term pitch rises instead of falls.
The second comparison is to Taylor Mali reading the first few phrases of his poem "Totally like Whatever" ("This is, like, such total crap?", 5/15/2005)
In case you hadn't realized,
it has somehow become uncool
to sound like you know what you're talking about?
Here's the pitch contour:
Here's the pitch histogram:
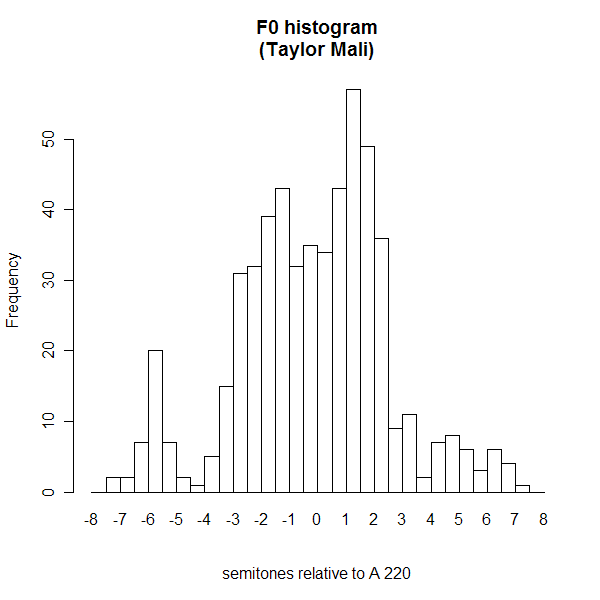
And here's the time/pitch-interval plot:
One thing that the time/pitch-interval plot brings out -- though it's also visible in the basic pitch contour -- is that Mali's performance is actually dominated by long stretches of relatively level pitches, both phrase-medial and phrase-final, rather than by the occasional low-to-high final rises that he also uses. You can see that by the relatively large number of counts at pitch-intervals near zero and time-intervals from 1 to 40 centiseconds or so.
The third comparison is to a couple of phrases from another angry guy, George C. Deutch ("Angry rises", 2/11/2006). Mr. Deutsch was a political appointee at NASA, who lost his job after allegedly trying to suppress reports of global warming. This is from the peroration of an interview with a Texas radio station, and his emotions are running high, at least judging from the sound:
There's no censorship here! This is -- an agenda! It's a culture war agenda! They're out to get Republicans, they're out to get Christians, they're out to get people who are {breath} helping Bush; anybody they perceive as not sharing their agenda, they're out to get!
Here's the pitch contour for the first three phrases:
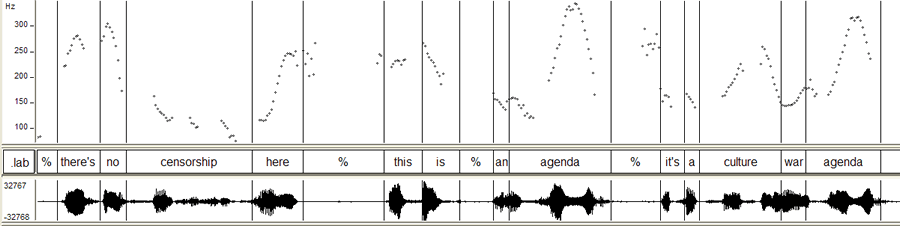
Here's the pitch histogram:
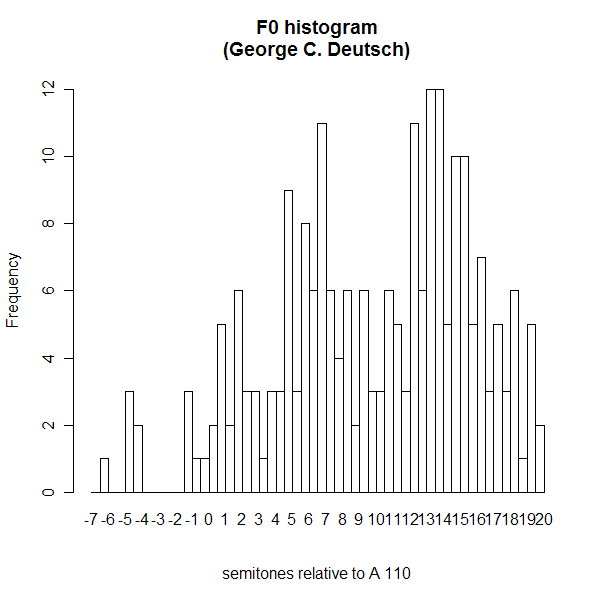
And here's the time/pitch-interval plot:
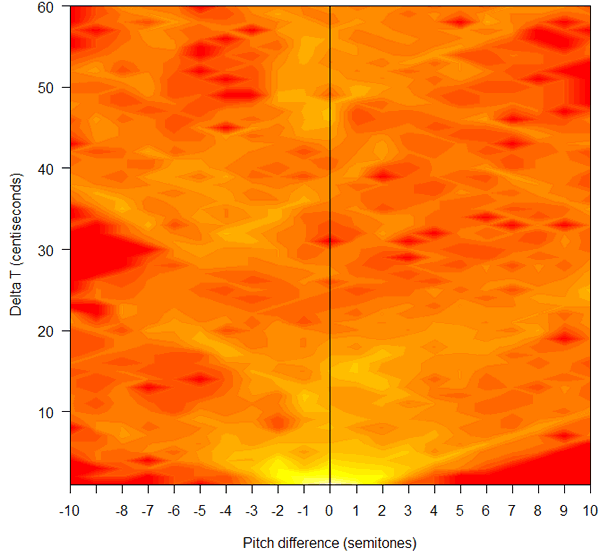
Like the original pitch contour, this shows us that Mr. Deutsch's pitches are rising and falling rapidly and frequently, across wide ranges of pitch values, expressing his soul's agitation.
Do these various time/pitch-interval plots compel belief in a musical system of pitch classes related by small-integer ratios? Not so far. Do they provide other novel insights into English intonation in general, or into the pitch patterns of the four short segments that we've examined in particular? Not so far. They're kind of pretty to look at, though.
[Here's the R script I used to create the Auden picture:
F1 <- getf0("IfICouldTellYou1.f0")
sF1 <- h2st(F1,110)
sD1 <- dipole3(sF1[1:600], 0.5)
filled.contour(1:21,1:60,sD1[3:23,1:60]^(.33),color=heat.colors,
ylab="Delta T (centiseconds)",
xlab="Pitch difference (semitones)",
plot.axes={ axis(1, at=1:21, labels=(-10:10)); axis(2); points(c(11,11),c(0,60),type="l") }
)
The extra functions used (like getf0 and h2st) can be found here. ]
October 14, 2006
What was the question?
There's a classic type of question that linguists, logicians, and lawyers often talk about; it's what's commonly called a loaded question. Here at Language Log Plaza some of the senior staffers like to play "the loaded question game" with the new interns. A favorite example of a question from the game is some variation on the following:
Have you stopped acting like an idiot yet?
The problem with loaded questions, linguistically-speaking, is that they are loaded with a potentially damaging presupposition, a hidden assertion that makes the question inappropriate if that presupposition happens to be false. The presupposition in this case is that the intern being addressed in the question has acted like an idiot in the past. If it's not true that the intern has acted like an idiot in the past, then the question is inappropriate; the intern cannot answer the question with a simple "yes" or "no" without also allowing that the presupposition is true. In short, answering a loaded question without major qualifications might be taken as an admission of guilt.
Now keep in mind that questions themselves, even loaded ones, are neither true nor false. The only thing that can be true or false about a question is any presupposition that the question carries, which really only becomes an issue if and when the question is answered. So even though you can get caught off-guard by a loaded question -- for example, while you're nervously answering a barrage of questions from senior Language Loggers or from a lawyer while you're on a witness stand -- you can always qualify your answer or not answer the question in the first place. (I'm no legal expert, but I'd be surprised if a judge would require that you answer a loaded question with no qualification whatsoever. The senior Language Log staffers require unqualified answers from the interns, but that's just because it makes the loaded question game more fun.)
Even if a question itself doesn't appear to be loaded, however, I would still warn all Language Log readers to be on their guard. Presuppositions are everywhere, just waiting for you to be tangled up in their webs. Consider, for example, this story about a survey recently given to parents of students at an elementary school in Jackson, MS. I haven't seen the survey itself, but I gather that the relevant question was something along the lines of "Would you like to get involved with the P.T.A.?" Nothing wrong with that presupposition-wise, right? Several answer-options for how to get involved were apparently provided, like a multiple-choice exam. For parents who can't afford to get involved, or who just don't want to, the answer-option provided was this one:
"No, I do not want to get involved. I want my children to be thieves, drug addicts and prostitutes."
This answer is loaded with not just one but two presuppositions, and so selecting it allows that those presuppositions are true. One of the presuppositions is that there is a positive correlation between non-participation in the P.T.A. and kids becoming thieves, drug addicts and prostitutes. The other is that anyone who chooses not to be involved in the P.T.A. does so because they want their kids to be thieves, drug addicts and prostitutes. The first presupposition may very well be true, though I doubt there's any hard evidence one way or the other. The second, more damaging presupposition is very likely 100% false, however, and so I for one applaud the school administration for taking steps to ensure that something like this doesn't happen again.
Members of the P.T.A. appear to be unrepentant. The survey apparently also included "information on how parent involvement could help in the success of their children", and P.T.A. members say that "the comment in question was included to also encourage parents to view, [sic] and act upon that information." The P.T.A. president, Dr. David Gatlin, says that "he didn't mean to offend anybody, but doesn't see anything wrong with the language he used, meant to grab people's attention."
Dr. Gatlin, you're welcome to come by the Plaza to play the loaded question game with our interns anytime. Just call first to see if we're in.
[ Comments? ]
Every * seconds
OK, everyone can stop emailing me about how common "every 53 seconds" is on the web.
The main point of my post about Louann Brizendine's claim that "85 percent of twenty- to thirty-year-old males think about sex every fifty-two seconds" was that I could find no support for those numbers in any of the works referenced in her end-note on the passage in question. A secondary point was that an independent literature search also turned up no support for the claim, but instead found quite a different number: an average of 7 sexual thoughts per day for a sample of "49 male heterosexual undergraduates" from an intro psych course in an American university in 1990. Finally, I looked on the web for any other possible sources of the "every 52 seconds" idea, and didn't turn up anything relevant.
But I did turn up a few hundred references to other things that allegedly happen every 52 seconds, and I made a little joke that maybe sometimes people just like the way that number sounds. This obviously made me curious about whether 52 is an especially common choice in the frame "every * seconds" -- so I checked, producing the following table:
| "every __ seconds" | 45 | 46 | 47 | 48 | 49 | 50 | 51 | 52 | 53 | 54 | 55 |
| Google count | 79,500 | 421 | 290 | 758 | 209 | 20,200 | 141 | 344 | 24,300 | 319 | 541 |
(Actually, I went on up to 65, but I got tired of adding stuff to the table, so I'll leave it where it was at breakfast on Friday.)
Now, it's not completely clear what's going on here. It's sensible that 45 and 50 would be frequent, since they're multiples of 5 -- but it's not clear why 55 is way lower. And what about 53? Scanning the first ten pages of hits makes it seem that we're dealing mostly with a statistic about the frequency of strokes, and secondarily one about how often laptops are stolen -- and these could be true, who knows? There's also one Brizendine review that mis-transcribes her statistic as 53...
Anyhow, my post on the "think about sex every fifty-two seconds" claim was already way too long, and the interpretation of the table presented above is neither very clear nor (as far as I can tell) very interesting (OK, I admit that my standards for interest and clarity are sometimes pretty low, but there are limits to everything), so I left it out.
Big mistake.
I've gotten more email about this than almost anything else I've ever posted. In particular, if I'm counting correctly, 22 of you have now written to clue me in that 53 is more popular than 52 in this frame, and many of you have sent whole vectors of Google counts.
So thanks, but you can stop now. I do enjoy hearing from readers, and all kudos, corrections and complaints are welcome -- but this one's been done.
Arabic at the FBI
Ah, the FBI now has, hold on to your hats, a total of 33 agents with even a limited proficiency in Arabic, reports Dan Eggen in a Washington Post article on October 11, 2006,
Pumping this number up to include "agents who know only a handful of Arabic words--including those who scored zero on a standard proficiency test," yields a minuscule percentage of Arabic users among their 12,000 agents. The article reports that only four agents in the government's two International Terrorism Sections (ITOS) have even elementary proficiency in Arabic.
Should we worry about national security? Maybe not. Our agents don't really need Arbic skills, according to the head of ITOS. Get this from him:
As John Stewart might comment, "maybe they don't utilize Arabic because they don't have any."
The FBI says we're in no danger because they can make use of translators who are available within 24 hours. Whew! That's good news. Despite this distinct advantage, they say they're trying to hire some Arabists (well, maybe not gay ones). But there just aren't many of them around to hire and those that are have the misfortune to have Arabic families, friends and acquaintences -- and some of them were even born in foreign countries. Trying to hire Arabists seems like an odd thing to do, however, if, as the head of ITOS says, there are no positions at any level that utilize the language. Maybe someone should look into that one.
Who is to blame for this confusing (sorry?) situation? It's American society, says the director of communications at the American Council on the Teaching of Foreign Languages, because language instruction is "undervalued in the US schools." He's partly right, of course. But since when has the American society been the "Decider?"
Imagine the following scenario at an FBI office:
Underling: No, language instruction is undervalued in the schools but we have translators on call 24 hours a day.
FBI boss: Get one quick!
Underling (on the telephone): We're also getting a phone call from a terrorist on a commercial airplane and we're afraid he might be planning to crash it into a city building. Somebody better talk to him.
FBI boss: Get that damn translator in here right now!
Language Log postings on taboo vocabulary
For your reference pleasure, an inventory of Language Log postings on taboo vocabulary, arranged by date, from the beginning to yesterday.
Each entry identifies the poster:
BP Bill Poser
BZ Ben Zimmer
EB Eric Bakovic
GN Geoff Nunberg
GP Geoff Pullum
ML Mark Liberman
RS Roger Shuy
and gives the date, title, and URL (with a link), plus rough topic labels:
use: open use of these words
regulation: regulation of taboo words in public
avoidance: schemes for avoiding taboo words
grammar: the grammar of taboo words
[...]: more specific characterization
If you catch any errors or omissions, let me know.
GN, 11/3/03: On second thought, make that 'fuckingly brilliant':
http://itre.cis.upenn.edu/~myl/languagelog/archives/000077.html
use, regulation, avoidance, grammar
ML, 12/28/03: Bad words getting better?:
http://itre.cis.upenn.edu/~myl/languagelog/archives/000267.html
regulation
ML, 1/25/04: Maybe better make that "freaking brilliant":
http://itre.cis.upenn.edu/~myl/languagelog/archives/000385.html
regulation
BP, 1/25/04: Some people should get a life:
http://itre.cis.upenn.edu/~myl/languagelog/archives/000388.html
regulation, tabooing
ML, 1/25/04: The FCC and the S word:
http://itre.cis.upenn.edu/~myl/languagelog/archives/000389.html
regulation, tabooing
BP, 1/25/04: The Ngadjonji and the PTC:
http://itre.cis.upenn.edu/~myl/languagelog/archives/000390.html
regulation, tabooing
GN, 3/21/04: Imprecational categories:
http://itre.cis.upenn.edu/~myl/languagelog/archives/000614.html
grammar
ML, 4/21/04: The FCC and the S-word (again):
http://itre.cis.upenn.edu/~myl/languagelog/archives/000796.html
regulation
ML, 6/12/04: The S-word and the F-word:
http://itre.cis.upenn.edu/~myl/languagelog/archives/001042.html
tabooing
GP, 10/29/04: The unspeakable:
http://itre.cis.upenn.edu/~myl/languagelog/archives/001608.html
avoidance
ML, 1/19/05: Twat v. Browning:
http://itre.cis.upenn.edu/~myl/languagelog/archives/001812.html
tabooing
GP, 3/1/05: Now the FCC tells us, three months too late:
http://itre.cis.upenn.edu/~myl/languagelog/archives/001940.html
regulation
GP, 3/11/05: Bovine excrement on NPR:
http://itre.cis.upenn.edu/~myl/languagelog/archives/001975.html
avoidance
AZ, 3/19/05: Another bullshit night in suck city:
http://itre.cis.upenn.edu/~myl/languagelog/archives/001994.html
avoidance
ML, 6/23/05: Adios, FCC?
http://itre.cis.upenn.edu/~myl/languagelog/archives/002260.html
regulation, avoidance, use
ML, 7/1/05: [Expletive discussed]:
http://itre.cis.upenn.edu/~myl/languagelog/archives/002277.html
avoidance
ML, 7/17/05: You taught me language, and my profit on't/Is, I know how to curse:
http://itre.cis.upenn.edu/~myl/languagelog/archives/002336.html
tabooing
AZ, 7/20/05: Curses!:
http://itre.cis.upenn.edu/~myl/languagelog/archives/002347.html
tabooing, use, grammar
AZ, 8/17/05: Modesty at Henry Holt:
http://itre.cis.upenn.edu/~myl/languagelog/archives/002403.html
avoidance
AZ, 8/17/05: No fuckin' winking at the Times:
http://itre.cis.upenn.edu/~myl/languagelog/archives/002406.html
avoidance
GP, 8/24/05: An unspeakable title:
http://itre.cis.upenn.edu/~myl/languagelog/archives/002420.html
avoidance
ML, 8/31/05: Leading questions and frickin' cooks:
http://itre.cis.upenn.edu/~myl/languagelog/archives/002442.html
[transcribing informal speech]
AZ, 9/6/05: Call me... unpronounceable:
http://itre.cis.upenn.edu/~myl/languagelog/archives/002461.html
avoidance
AZ, 9/13/05: Effing avoidance (cont.):
http://itre.cis.upenn.edu/~myl/languagelog/archives/002471.html
avoidance
AZ: 10/6/05: Plain speaking:
http://itre.cis.upenn.edu/~myl/languagelog/archives/002520.html
use
BZ, 11/29/05: Football's F-word:
http://itre.cis.upenn.edu/~myl/languagelog/archives/002677.html
tabooing
ML, 3/29/06: Delete expletives:
http://itre.cis.upenn.edu/~myl/languagelog/archives/002972.html
tabooing
BZ, 3/30/06: Twonk!:
http://itre.cis.upenn.edu/~myl/languagelog/archives/002973.html
tabooing
RS, 4/1/06: The LMU: a new formula for measuring effective writing:
http://itre.cis.upenn.edu/~myl/languagelog/archives/002978.html
[April Fool posting]
BZ, 4/2/06: "Thinking specifically about the F-word...":
http://itre.cis.upenn.edu/~myl/languagelog/archives/002979.html
tabooing, use
AZ, 6/5/06: Words that can't be printed in the NYT:
http://itre.cis.upenn.edu/~myl/languagelog/archives/003228.html
avoidance, use
AZ, 6/7/06: Goram motherfrakker!
http://itre.cis.upenn.edu/~myl/languagelog/archives/003235.html
avoidance
AZ, 6/7/06: Mock modesty at the NYT:
http://itre.cis.upenn.edu/~myl/languagelog/archives/003236.html
avoidance
ML, 6/10/06: The history of typographical bleeping:
http://itre.cis.upenn.edu/~myl/languagelog/archives/003244.html
avoidance
ML, 6/15/06: The earliest typographically-bleeped F-word:
http://itre.cis.upenn.edu/~myl/languagelog/archives/003253.html
avoidance
ML, 6/22/06: Beetle Bailey goes positively meta:
http://itre.cis.upenn.edu/~myl/languagelog/archives/003278.html
avoidance, tabooing
BZ, 6/25/06: Obscenity as commodity:
http://itre.cis.upenn.edu/~myl/languagelog/archives/003285.html
avoidance, use
AZ, 7/4/06: Avoiding the other F-word:
http://itre.cis.upenn.edu/~myl/languagelog/archives/003319.html
avoidance, use
BZ, 7/17/06: Presidential expletive watch:
http://itre.cis.upenn.edu/~myl/languagelog/archives/003360.html
avoidance, use
AZ, 7/18/06: Drawing the line:
http://itre.cis.upenn.edu/~myl/languagelog/archives/003362.html
avoidance
BZ, 7/19/06: Taking shit from the President:
http://itre.cis.upenn.edu/~myl/languagelog/archives/003367.html
avoidance, use
EB, 7/19/06: Words of curse:
http://itre.cis.upenn.edu/~myl/languagelog/archives/003368.html
use
AZ, 7/30/06: On the taboo watch: The rock report:
http://itre.cis.upenn.edu/~myl/languagelog/archives/003401.html
avoidance
AZ, 7/31/06: Automatic asterisking:
http://itre.cis.upenn.edu/~myl/languagelog/archives/003403.html
avoidance
AZ, 8/7/06: C*m sancto spiritu:
http://itre.cis.upenn.edu/~myl/languagelog/archives/003427.html
avoidance
BZ, 8/8/06: They called Hillary a whaaa?:
http://itre.cis.upenn.edu/~myl/languagelog/archives/003431.html
avoidance
AZ, 8/10/06: Moral panic in asterisking:
http://itre.cis.upenn.edu/~myl/languagelog/archives/003439.html
avoidance
ML, 8/30/2006: Oh sleepies!
http://itre.cis.upenn.edu/~myl/languagelog/archives/003521.html
AZ, 10/4/06, Further annals of taboo avoidance:
http://itre.cis.upenn.edu/~myl/languagelog/archives/003637.html
avoidance
AZ, 10/9/06: Avoidance omnibus:
http://itre.cis.upenn.edu/~myl/languagelog/archives/003653.html
avoidance
AZ, 10/13/06: What the L?!:
http://itre.cis.upenn.edu/~myl/languagelog/archives/003671.htmll
avoidance
GP, 10/13/06: Pubic information:
http://itre.cis.upenn.edu/~myl/languagelog/archives/003672.htmll
avoidance
zwicky at-sign csli period stanford period edu
[A quick update to 4/28/2007, by myl -- with author HH (Heidi Harley) added:
Annals of self-censorship: avoiding the F-letter 10/20/2006 ML
Taboo avoidance in Dilbertland 11/6/2006 AZ
Swear it 11/8/2006 AZ
Try and stop me, FCC 11/8/2006 GP
Expletive inserted 11/19/2006 GP
Typographical bleeping antedated to 1591 11/20/2006 ML
Oh tabernacle! What the wafer! 12/5/2006 RS
More about cussing in Quebec 12/6/2006 RS
Linguistic cartoon update 12/9/2006 ML
Linguistic cartoon update update 12/9/2006 HH
Nigger, nigger, on the wall 12/11/2006 GP
Merry... umm... Christmas, Will! 12/25/2006 GP
Linguistic filth at the movies 12/26/2006 GP
Conventionalized oaths 1/1/2007 AZ
Ultimate avoidance 1/7/2007 AZ
2500 words for cursing the weather 1/18/2007 ML
Mind your Hindi! 1/30/2007 AZ
Taboos of the Nation 2/2/2007 GP
Calling people faggot 3/6/2007 GP
Interlingual taboos 1/12/2007 ML
Wilmore/Oliver Investigates: N-word! 3/30/2007 HH
More N-word meta-humor 3/30/2007 BZ
Automotive naming (and more) 4/21/2007 AZ
]
October 13, 2006
Pubic information
Intrigued by Arnold Zwicky's story of an MSNBC news item too prudish to actually use the word that appeared by misprint on a ballot in Ottawa County, Michigan, yet not intrigued enough to actually want to go look up the ballot language in question, I was left merely imagining what could possibly be in a ballot issue (which I take to mean a referendum proposition, like California's unending series of such propositions) that could induce a genuine ambiguity about whether public or pubic was meant. (The law says that if the error could alter the "context" of a ballot issue, the ballots must be reprinted, and they decided they did have to reprint.) My best guess was that it would have to be something like:
It shall be illegal to smoke in any {pubic / public} area.
Which reminds me inexorably of the good old dirty joke that I'm sure all Language Log readers will remember from junior high school. But this one trades on a nice lexical polysemy; and besides, you can never hear a good old dirty joke too many times. So here it is again, kids!
Q: Do you smoke after sex?
A: I don't know. I never looked.
What the L?!
From the Annals of Taboo Avoidance, an elegant solution to avoiding a not-very-taboo word, and another ostentatious avoidance from the New York Times.
First, from Charlie Clingen, an MSNBC tale of a typo:
Misspelling of 'public' forces Michigan county to reprint ballot for $40,000
Updated: 4:21 p.m. PT Oct 10, 2006
GRAND HAVEN, Mich. - Ottawa County will pay about $40,000 to correct an embarrassing typographical error on its Nov. 7 election ballot.
That's how much it will cost the county to reprint 170,000 ballots that were missing the letter "L" in the word "public."
They give you the intended word and tell you how to derive the actual word printed. Thus is the word "pubic" avoided. A bit more detail from the story:
"It's just one of those words," Krueger said. "Even after we told people it was in there, they still read over it."
... If a printing error is discovered before an election and the mistake changes the context of a ballot item, the ballot needs to be reprinted, he said. The cost will come from the county's general fund.
I'm a bit surprised that the error was judged to change the context of the ballot item. I wonder who makes these calls.
Googling on <public pubic misspelling> gets thousands of occurrences, most of them stories of people who embarrassed themselves by writing or typing "pubic" for "public". There are, however, some errors in the other direction, and some of these might be eggcorns:"public lice" for "pubic lice", for example. Ken Lakritz on the Eggcorn Forum, 10/25/05, reported getting over 50,000 hits on "public hair" (for "pubic hair").
Meanwhile, New York Times reporter Joyce Wadler found herself dealing with the very outspoken art critic Robert Hughes and decided to show some of his earthy side. But this being the Times, she had to euphemize (and then allude to the original language indirectly). From "After Calamity, Critic's Soft Landing" in the Home & Garden section of 10/12/06 (pointer from Sim Aberson):
Actually, there are at least three candidates for the word euphemized as "excrement". My guess is that it was the old reliable "shit", but I can't at the moment confirm that.
zwicky at-sign csli period stanford period edu
From Spam to McDonald's in the trademark wars
Bill Poser's recent post, Spam Will Be Spam, describes the claims of Hormel that it had sole rights to the use of the name of its canned meat product and that use of this word for unsolicited commercial email is improper. Poser is surely right that it would be very difficult to show that consumers are confused by the two. Linguists who have worked on trademark cases are familiar with the major questions about trademark infringement. Do the names sound the same? Do they mean the same? These are good subjects for the use of phonetics and semantics. In some cases the question of whether the names look alike can be addressed by semiotic analysis, although issues of trade dress often fall into other categories of expertise. I'll save dealing with trademark laws abut "dilution" for another time, but clearly consumers are not very likely to confuse email spam with Hormel's meat product.
It's the more recent meaning of "spam" that is salient here. Poser points out that the European Union recently rejected Hormel's claim of trademark infringement. Hormel complained that spam once meant only Hormel's product and now has taken on a second meaning, unsolicited commercial email, but the EU's Office of Trade Marks and Designs, using a Google search, turned up a vastly greater number of hits for the "unsolicited email" meaning than it got for Hormel's meat product, and ultimately ruled against Hormel.
Trademark laws and practices can get pretty complex. Witness the 1988 trial of McDonald's Corporation v. Quality Inns International, Inc. Quality Inns (which later changed its name to the corporate umbrella title of Choice Hotels International) wanted to develop, for some unexplained reason, a chain of some 200 inexpensive hotels called McSleep Inns. McDonald's didn't care much for this idea and took QI to court, charging trademark infringement, largely concerning the prefix, Mc-, even though the hotel would have no food service and would, therefore, not compete with the fast food business of McDonald's.
Here the "Aunt Jemima Doctrine," which deals with potential confusion, comes to play:
Aunt Jemima Mills Pancake Batter held a trademark against which Aunt Jemima syrup was found to infringe, because syrup and flour were said to be food products that are commonly used together. Some, including Quality Inns, found it difficult to imagine how a hotel business that doesn't serve food could be confused with a fast food business. In the same way, some would find it hard to believe that Hormel's meat product could be confused with unsolicited commercial email. There are many precedents about this, including Notre Dame University v. Notre Dame cheese, Bulova watches v. Bulova shoes, and Alligator raincoats v. Alligator shoes, all of which were permitted to coexist. So there must be something else going on here.
To counter McDonald's claim, Quality Inns offered four arguments:
1. It argued, relying on the Aunt Jemima Doctrine, that there is no likelihood of confusion between McSleep and McDonald's.
2. It argued that the uses were not in competition.
3. It argued that it could not be denied the right to use McSleep because Mc- was already being used before common nouns. Searches of telephone directories, credit reports, and media uses produced 94 currently used examples, including McArt, McCinema, McPaper, McTelevangelism, McJobs, McOil Change, McPrisons, and even McLaw, all of which conveyed most if not all of the meanings of basic, convenient, inexpensive, and standardized products and services, none of which referred to fast food or hamburgers.
4. It argued that the Mc- prefix in McDonald's had now become generic, like the patronym from which it derived, and therefore had entered the lexicon of English with a recognized meaning of its own--basic, convenient, inexpensive, and standardized. Fast food is basic (not gourmet), is found everywhere (convenient), is relatively inexpensive, and consumers can be sure that the food they buy one day will be the same as the food they buy the next (standardized).
It seemed clear that the bound morpheme, Mc-, with the encouragement of McDonald's massive marketing, had undergone the process of lexical shift and lexical generalization. Whatever Mc- once meant about family ancestry, it now meant speed, efficiency, consistency, and basic standardization. Quality Inns tried to show that the claim that Mc- always means McDonald's is simply not true. Through it's own marketing, McDonald's had changed the lexical landscape.
These arguments failed to prevail. The judge ruled that Mc- had not become generic, that there was indeed a likelihood of confusion, and that Quality Inns could not use Mc- in the name of its proposed hotel chain (probably a good thing for Quality Inns, although not what they wanted).
Poser's last point in his post, "language changes and the world changes in ways that may adversely effect a business," didn't quite work out that way in this case. Apparently not all judges think that way.
The underlying theme in the judge's decision was that McDonald's had spent millions of dollars advertising and marketing its name, prefix included, and something called "secondary meaning" won the day. One is left wondering why it is that the expenditure of money can determine who can have ownership of a word, much less a bound morpheme prefix.
Since the trial, McDonald's has gone on to apply for legal trademarks for many other words, including McSpace Station, McTime, McFamily, McMom, McSmile, McTravel, McBaby, McProduct, and McBunny. This company appears to have a monopoly on the prefix, Mc-, and the rest of us will have to get along as best we can. The funny thing is that after Quality Inns renamed their chain Sleep Inn, it became well known as a hotel chain that is basic, convenient, inexpensive and standardized, even without using the prefix, Mc-.
Note: For more details about how linguists worked in this case, see chapter 8 of my book, Linguistic Battles in Trademark Disputes, Palgrave Macmillan, 2002.
Yale and the persuasive words: the final nail in the coffin
Just in case anyone is still holding on to the notion that Yale
researchers really did uncover the
twelve
most
persuasive
words
in English, let's hear from an actual Yale researcher. The
following tidbit can be found in the 2004 book Experiments
With People: Revelations From Social Psychology, written by Robert
P. Abelson with Kurt P. Frey and Aiden P. Gregg (text available on Questia):
Love, Oh Love, Oh Proven Love!
Did you hear about the Yale study that discovered the 12 most persuasive words in the English language: 'love,' 'beauty,' 'proven,' etc.? At the Yale Communication and Attitude Change Project throughout the 1950s and 1960s, we would get a letter every two months or so, asking who ran this study, and whether we had the data. During this period, the results appeared in a widely read airline magazine, among many other publications.
One of the authors [i.e., Abelson] was part of the Yale Project, and remembers other members asking everybody they knew who the author of the study was. It sounded like a pretty silly thing to waste time on, but in any case, no indication was ever found that anyone connected with Yale had done such a study. We suspected that it was a Madison Avenue project. Or perhaps a research assistant who had once been a Yale undergraduate put a misleading Yale imprimatur on the story. (p. 194)
So there you have it. If there really were such a study of persuasive words conducted at Yale, Abelson (an esteemed professor of psychology who passed away last year at the age of 76) would surely have known about it. Abelson was actively involved in Carl Iver Hovland's Communication and Attitude Change program, a Rockefeller Foundation-funded research project initiated after World War II. The researchers produced such works Communication and Persuasion: Psychological Studies of Opinion Change (1953). So if there was some media coverage of Yale studies on persuasive communication in the '50s and early '60s, then it's easy to see how the Yale name could have been attached to the "persuasive words" list if someone wanted to imbue the supposed findings with some added prestige.
And if this really was all a Madison Avenue project (as those two ads from 1961 certainly suggest), then we have to acknowledge that it was a wildly successful one. Here we are nearly half a century later still hashing it out. Talk about persuasive words.
"Every 52 seconds": wrong by 23,736 percent?
Well, I wasn't going to blog this, because it's got nothing directly to do with speech and language. But it does have to do with rhetoric, and with the use of authoritative-sounding assertions backed up by empty references to scientific studies, a topic that we've been featuring recently. And several readers have asked me about it, based on my earlier posts about the "emerging science of sex differences". So here goes.
On page 91 of The Female Brain, Dr. Louann Brizendine writes (emphasis added):
Males have double the brain space and processing power devoted to sex as females. Just as women have an eight-lane superhighway for processing emotion while men have a small country road, men have O'Hare Airport as a hub of processing thoughts about sex whereas women have the airfield nearby that lands small and private planes. That probably explains why 85 percent of twenty- to thirty-year-old males think about sex every fifty-two seconds and women think about it once a day -- or up to three or four times on their most fertile days.
This striking different in rates of sexual thoughts is also one of the bullet points on the book's jacket blurb -- but there, female sex-thought frequency is downgraded from "once a day" to "once every couple of days":
- Thoughts about sex enter a woman's brain once every couple of days but enter a man's brain about once every minute
Whatever the exact numbers, it's an impressive-sounding difference -- scientific validation for a widespread opinion about what men and women are like. And this is interesting stuff, right at the center of social and personal life, so you're probably wondering about the details of the studies that produced these estimates.
The end-notes for the quoted segment from p. 91 yield the following references:
1. Bancroft, J. (2005). "The endocrinology of sexual arousal." J Endocrinol 186(3): 411-27
2. Laumann, E. O., A. Paik, et al. (1999). "Sexual dysfunction in the United States: Prevalence and predictors." JAMA 281(6): 537-44.
3. Laumann, E. O., Nicolosi, et al. (2005). "Sexual problems among women and men aged 40-80: Prevalence and correlates identified in the Global Study of Sexual Attitudes and Behaviors." Int J Impot Res 17(1): 39-57.
4. Lunde, I., G.K. Larsen, et al. (1991). "Sexual desire, orgasm, and sexual fantasies: A study of 625 Danish women born in 1910, 1936 and 1958." J Sex Educ Ther, 17:62-70.
Well, if you've been reading my earlier posts on (the popular presentation of) the "emerging science of sex differences", you can guess how this is going to come out. But let's go to the archives anyhow:
1. The abstract for Bancroft (2005) begins:
The relevance of testosterone, oestradiol and certain peptides (oxytocin (OT), ß-endorphin and prolactin (PRL)) to sexual arousal in humans is reviewed. In addition to behavioural studies, evidence of distribution of gonadal steroid receptors in the brain and the limited evidence from brain imaging are also considered.
These two sentences are a good summary of the paper as a whole, which says nothing whatever about how often women or men think about sex.
2. The abstract for Laumann (1999):
Context While recent pharmacological advances have generated increased public interest and demand for clinical services regarding erectile dysfunction, epidemiologic data on sexual dysfunction are relatively scant for both women and men.
Objective To assess the prevalence and risk of experiencing sexual dysfunction across various social groups and examine the determinants and health consequences of these disorders.
Design Analysis of data from the National Health and Social Life Survey, a probability sample study of sexual behavior in a demographically representative, 1992 cohort of US adults.
Participants A national probability sample of 1749 women and 1410 men aged 18 to 59 years at the time of the survey.
Main Outcome Measures Risk of experiencing sexual dysfunction as well as negative concomitant outcomes.
Results Sexual dysfunction is more prevalent for women (43%) than men (31%) and is associated with various demographic characteristics, including age and educational attainment. Women of different racial groups demonstrate different patterns of sexual dysfunction. Differences among men are not as marked but generally consistent with women. Experience of sexual dysfunction is more likely among women and men with poor physical and emotional health. Moreover, sexual dysfunction is highly associated with negative experiences in sexual relationships and overall well-being.
Conclusions The results indicate that sexual dysfunction is an important public health concern, and emotional problems likely contribute to the experience of these problems.
There is nothing at all in this paper about how often women or men think about sex.
3. The abstract of Laumann (2005):
The Global Study of Sexual Attitudes and Behaviors (GSSAB) is an international survey of various aspects of sex and relationships among adults aged 40–80 y. An analysis of GSSAB data was performed to estimate the prevalence and correlates of sexual problems in 13 882 women and 13 618 men from 29 countries. The overall response rate was modest; however, the estimates of prevalence of sexual problems are comparable with published values. Several factors consistently elevated the likelihood of sexual problems. Age was an important correlate of lubrication difficulties among women and of several sexual problems, including a lack of interest in sex, the inability to reach orgasm, and erectile difficulties among men. We conclude that sexual difficulties are relatively common among mature adults throughout the world. Sexual problems tend to be more associated with physical health and aging among men than women.
Again, there is nothing at all in this paper about how often women or men think about sex.
4. I haven't been able to read Lunde (1991), because Penn's library doesn't have the Journal of Sex Education & Therapy before the year 2000. But here's the abstract from PsycInfo, which suggests that the article focused on the relevance of social factors (since women of different generations report rather different numbers).
Studied female sexuality in 3 generations. A standard interview schedule was used, consisting of 300 precoded questions about sexuality, social conditions, and health. At the time of interview the women in each generational group were 70, 40, and 22 yrs old. Of these women, 72%, 67%, and 95%, respectively, had experienced spontaneous sexual desire, and 88%, 96%, and 91% had experienced orgasm. Also, 38%, 47%, and 81%, respectively, had masturbated at least once, and fantasies during masturbation were used by 50%, 48%, and 68%. Seven percent of the women born in 1910 and 44% of women born in 1958 had sexual fantasies in general, and 14% and 39% had fantasies during intercourse.
It's not clear whether the frequency of these women's thoughts about sex was covered. In any case, the paper only deals with women, and so could not have included any relevant information about the frequency of men's sexual thoughts. This paper is discussed briefly in Andersen, Barbara L.; Cyranowski, Jill M. "Women's sexuality: Behaviors, responses, and individual differences." Journal of Consulting and Clinical Psychology. 63(6), Dec 1995, 891-906, which summarizes its relevant findings as follows:
Epidemiologic data indicate that women use sexual fantasies to increase sexual desire and facilitate orgasm (Lunde, Larsen, Fog, & Garde, 1991).
Andersen and Cyranowski do, as it happens, report some other research that actually measured the frequency of sexual thoughts among women and men -- with results totally at variance with Brizendine's assertions:
Data comparing the frequency of internally generated thoughts (fantasies) and externally prompted thoughts (sexual urges) among young heterosexual men and women indicate that men report a greater frequency of urges than do women (4.5/day vs. 2.0/day), although the frequency of fantasies were similar (2.5/day; Jones & Barlow, 1990).
That reference is Jones, J. C., & Barlow, D. H. (1990). "Self-reported frequency of sexual urges, fantasies, and masturbatory fantasies in heterosexual males and females." Archives of Sexual Behavior, 19, 269-279. (According to its PsycInfo abstract, this study involved "49 male and 47 female heterosexual undergraduates" -- probably one introductory psychology course -- who "self-monitored the frequency of fantasies, urges, and masturbatory fantasies for 7 consecutive days". And "urges" are "externally provoked sexual throughts", while "fantasies" are "internally generated sexual thoughts".)
Hmm. Adding up this study's tally of undergraduate male sexual thoughts, we get 4.5 male urges + 2.5 male fantasies per day on average, for a total of 7 sexual thoughts, or one every (24*60*60/7 =) 12,342 seconds. Compare Dr. Brizendine's figures: "85 percent of twenty- to thirty-year-old males think about sex every fifty-two seconds". That's more than 237 times hornier -- even if the other 15 percent never thought about sex at all, the average frequency would still be at least two orders of magnitude greater than Jones & Barlow report. (And they sampled male undergraduate psychology students, who must surely be near their life maximum of sexual consciousness.)
How about the female numbers? Jones and Barlow's student diaries yielded 2 female urges + 2.5 female fantasies per day on average, for a total of 4.5 sexual thoughts per day. That's 450% greater than the "once a day" that Brizendine cites in the book's text, and 900% greater than the "once every couple of days" rate in the jacket blurb. Not that the average self-reports from the "47 female undergraduates" in Jones and Barlow's 1990 American sample should be taken to stand for the nature of all women in all times and places -- but this is still 47 more women than we've been able to connect with Brizendine's estimates, at least so far.
Note also that the Jones and Barlow numbers for women amount to one sexual thought every (24*60*60/4.5 =) 19,200 seconds. But you're not going to sell any books by writing that "Men think about sex every 12,300 seconds, while women only have a sexual thought every 19,200 seconds".
OK, so where did Dr. Brizendine get her numbers? Not from the references that she cites, that's for sure. If you can find the source, please tell me.
While I'm waiting, I'll tentatively adopt the view that the 52-seconds part has something to do with these other statistics I found on the web:
Every 52 seconds, a marijuana smoker is arrested in America.
At high-volume sites, someone does a scan every four seconds and a search every 52 seconds, on average.
Once we got rolling, we were pushing an empty concrete truck out of here and back on the road every 52 seconds.
The site has become so popular that two million names are being added every month, with families being connected every 52 seconds.
Every 52 seconds during the school day, a Black high school student drops out.
Genes Connected has become so popular it is now connecting families every 52 seconds*² from a database of over 10 million names.
Ezzatollah Molainia, deputy director-general of State Prisons Organization, said yesterday: "The available statistics show that every 52 seconds, one person is taken to prison in Iran."
In continued testing, first-time users have proven to develop a unique idea every 52 seconds, and help solve a more significant "problem" within 30 minutes.
Diabetes, the body's failure to metabolize blood sugar properly, now strikes Americans at the rate of one new case every 52 seconds.
Unless sh*t blows up every 52 seconds, the audiance walks away with a "Worst. Movie. Ever." attitude.
Right now I'm in the second day of a bad cold, which has caused me to sneeze approximately every 52 seconds for 48 hours.
On the average, a home fire in the US breaks out once every 52 seconds.
Some of the moves they manage to pull off are incredible, and you have to realise that the 70 star one manages an average of a star every 52 seconds.
NARPAC's numerologist has developed some sympathy for the DC 911 operators who are apparently answering a call every 52 seconds, 24 hours a day, year round.
Seven years later the company was producing a lawnmower every 52 seconds.
Human Rights Watch estimates a man is raped every 52 seconds in the US.
There are three lines in Georgetown, so that means that they produce 3 brand new cars every 52 seconds, 18 hours a day!!!
The Seventh-day Adventist denomination is one of the fastest growing churches in the world, baptizing one new member on the average of every 52 seconds.
I'm already clearing out a spam from my inbox once every 52 seconds.
Every 52 seconds in the United States, someone has an acute ischemic stroke.
On the internet, we also find these alleged quotations involving the number 52:
I refuse to admit that I am more than fifty-two, even if that does make my sons illegitimate. (Nancy Astor)
The Eskimo has fifty-two names for snow because it is important to them; there ought to be as many for love. (Margaret Atwood)
When you get to fifty-two food becomes more important than sex. (Tom Lehrer)
For it was Saturday night, the best and bingiest glad-time of the week, one of the fifty-two holidays in the slow-turning Big Wheel of the year, a violent preamble to a prostrate Sabbath. (Alan Sillitoe)
Nothing's a gift, it's all on loan. Out of every hundred people, those who always know better: fifty-two. (Wislawa Szymborska)
I was asked to come to Chicago because Chicago is one of our fifty-two states. (Raquel Welch)
And where do all these people get the number 52? Well, 52 is the number of weeks in the year and the number of cards in the deck, as well as the fifty-two stages of bodhisattva practice. But in some cases, I'm guessing, people just kind of like how it sounds. For example, a paper by A K O Brady of the Judge Institute of Management at Cambridge University ("Profiling Corporate Imagery: a Sustainability Perspective") includes this sentence:
Last year Skoda sold one car every 52 seconds, enjoying total sales of just over 450000 units.
Um, one car every 52 seconds would be 365*24*60*60/52 = 606461.5 cars per year . The cited 450,000 units would actually be one car every 70 seconds. But this is a minor mistake, merely a deflation of 35%, small by the standards of the corporate accountants of our era, and nothing at all compared to Brizendine's 23,736% inflation of male sexual urges.
[My attempts at exact quantification are frivolous -- but this is a blog post, right? If you want a serious review of the literature on relevant issues, try Roy F. Baumeister et al. "Is There a Gender Difference in Strength of Sex Drive? Theoretical Views, Conceptual Distinctions, and a Review of Relevant Evidence", Personality and Social Psychology Review, 5(3) 242-273, 2001. They agree with Brizendine's general point that "the weight of evidence points strongly and unmistakably toward the conclusion that the male sex drive is stronger than the female", and that "there is increasing evidence for the role of hormones in determining human sexual behaviors and motivations". However, neither the "every 52 seconds" phrase nor anything implying it is mentioned anywhere in their 32-page article, although they describe a systematic search of the literature as of 2001, including "over 3,400 citations" from PsychInfo and "approximately 2,000 citations" from MEDLINE.
Another useful survey is Leitenberg, H., & Henning, K. (1995). "Sexual fantasy". Psychological Bulletin, 117, 469-496. One relevant paragraph:
In a different approach to assessing frequency of sexual fantasies in general, Cameron (1967) asked 103 male participants and 130 female participants to estimate what percentage of the time they thought about sex. Of those who responded with a specific number, 55% of the male participants and 42% of the female participants said greater than 10% of the time. In a related study, Cameron and Biber (1973) interviewed 4,420 individuals and asked them whether they had had a sexual thought in the past 5 min (“Did you think about sex or were your thoughts sexually colored even for a moment?”); some interviews were conducted in the morning, some in the afternoon, and some in the evening. In the age range 14 through 25, approximately 52% of the male participants said yes, in comparison with only 39% of the female participants. In the 26- to 55-year age bracket, the respective percentages were approximately 26% for men and 14% for women. When asked what had been the central focus of their thought in the past 5 min, the percentage who indicated that it was related to sex was much less (approximately 9% for male participants 14 through 55 years old and 5% for female participants across this same age range), but the same gender difference was apparent. In the recently released national survey of human sexuality, in which a true random probability sample of 3,432 men and women were interviewed, 54% of the men and 19% of the women said they thought about sex every day or several times a day (Laumann, Gagnon, Michael, & Michaels, 1994). It appears clear from these studies that men report thinking about sex more often than do women, which is certainly consistent with the general stereotype.
So the studies certainly support the stereotype -- but nowhere can I find the slightest hint of empirical support for the "men every 52 seconds vs. women once a day" claim. Again, if you can turn up a source, please let me know, so that I can correct any perhaps erroneous implication that Dr. Brizendine is making stuff up.]
[Ellen Caswell writes:
About 30 years ago I read a book that may or may not be the source of these numbers, but it wouldn't surprise me if it is. I don't remember enough to identify the book, though someone else may recognize it, but it left a vivid impression.
What I do remember:
The book was written by two women who were consultants. It was advice to women in the workplace; I *believe* it was about taking on leadership roles--I associate it with the 1970s rise in feminism. I remember liking the book.
The section in question essentially said that it's useless for women to expect men to refrain from thinking of them sexually. My memory of it goes something like this:
Someone asked the authors to find out how often men and women think about sex, so they asked a number of people. The men said things like "All the time," "Once a minute," "Every thirty seconds." The women said things like "Every two or three days," "I don't have to think about sex because I have a satisfying sex life," "A couple of times a day." (All quotes, obviously after 30 years or so, are inexact.)
I originally figured that the "every 52 seconds vs. once a day" meme probably came from the demi-monde of self-help books, relationship counseling, pop psychology and workplace consulting. But in the case of the "words per day" meme, simple search techniques turned up dozens of instances -- whereas I haven't been able to find plausible prior or variant examples of the sex-thoughts frequency meme on the web, other than the even more preposterous urban legend, discussed on snopes.com, that "On average, men think about sex every seven seconds." If you locate some variants of this claim in semi-serious contexts, let me know.]
[Update 1/19/2007 -- Dr. Paige Muellerleile writes:
It turns out that I do not have a source for the 52 seconds "statistic," but our medical library does have access to the Journal of Sex Education & Therapy back to 1991, so I looked up the Lunde et al. article and found that the researchers in that article did not measure frequency of thoughts about sex. They did ask about lifetime prevalence (had they *ever* had a sexual thought or a sexual fantasy) but did not ask about frequency of such thoughts in a way that could yield some sort of thought-per-day figure.
I'm sure this is all very old news and that you have moved away from Brizendine, but in the event that it is not or you haven't--you can rest assured that this article, like the other three, is not focused on the frequency of sexual thoughts.
]
spam will be spam
 The European Union has
rejected Hormel's attempt to claim Spam
as a trademark for unsolicited commercial email. Hormel is the manufacturer of Spam™, the
canned pork product, shipments of which by the United States were reportedly credited by Nikita Khruschev with feeding the Red Army
during the Second World War. Not surprisingly, Hormel takes Spam very seriously - they even have a
Spam Museum.
The European Union has
rejected Hormel's attempt to claim Spam
as a trademark for unsolicited commercial email. Hormel is the manufacturer of Spam™, the
canned pork product, shipments of which by the United States were reportedly credited by Nikita Khruschev with feeding the Red Army
during the Second World War. Not surprisingly, Hormel takes Spam very seriously - they even have a
Spam Museum.
Hormel's existing trademark is for canned meat products, but what Hormel has been unhappy with is the use of the word "Spam" in the names of anti-spam businesses such as SpamArrest, which is not covered by their trademark. They therefore attempted to acquire the trademark for Spam with the meaning of "unsolicited commercial electronic mail". The EU was correct in denying this application since spam in this sense is already a well established generic term and it would be unfair to allow Hormel to privatize it.
Trademark owners generally have one of two concerns. If someone selling a similar product is using a similar term, their concern is that they will lose sales to the other company, or, if the other company has a bad reputation, be tainted by association with it. That isn't a concern here: nobody is going to confuse an anti-spam service with canned ham. The other concern that they may have is that other uses of the term will "dilute" their trademark by moving it in the direction of a generic term. This isn't a real concern either: using the term spam in the name of an anti-spam service cannot have any effect on the genericity of the term for canned meat.
Hormel lets on to what their real concern is in this statement:
Ultimately, we are trying to avoid the day when the consuming public asks, 'Why would Hormel Foods name its product after junk e-mail?
They are correct in thinking that where spam once had no meaning other than their product it now has a second meaning that is probably more salient. Indeed, the EU decision, using a research technique they may have learned here on Language Log, provides evidence that this is already the case:
The European Office of Trade Marks and Designs, noting that the vast majority of the hits yielded by a Google search for the word made no reference to the food, said that "the most evident meaning of the term SPAM for the consumers ... will certainly be unsolicited, usually commercial e-mail, rather than a designation for canned spicy ham."
I don't know whether this will reduce their sales, but they are wrong to think that trademark law, or any linguistic legislation, can help them. Language changes and the world changes in ways that may adversely affect a business.
October 12, 2006
Persuasive words: the middle years
So far, Ben Zimmer has taken the persuasive words quest back to 1961, in a New York Times ad (11 words, "safety" missing) and a Washington Post ad (11 words, "new" missing), both attributing the list to either an unnamed marketing magazine or a specific publication called Marketing Magazine, it's hard to tell which, and then forward to a Bennett Cerf column in 1963 (10 words, "health" and "safety" missing; list attributed to a "big advertising agency"), an L. M. Boyd column in 1970 (all 12 words; list now attributed to "researchers in the Yale psychology departrment"), and other sources through the 1970s.
Now we can add more details from the turbulent middle years of the magic words.
From the You Just Knew It Was Going To Happen Department: an attribution to HARVARD (from Elizabeth Daingerfield Zwicky):
The usual list, with "discover" instead of "discovery".
Elizabeth also unearthed what will surely be the most entertaining reference we'll find, a column by John Bohannon ("Power words: they are the ones advertisers use when they want us to run out and buy, buy, buy") in the July-August 1991 issue of the Saturday Evening Post. It starts small:
But then we move into familiar territory:
The canonical list, but missing "new" and with "discover" instead of "discovery". (You begin to savor these little differences in the lists.)
So far we have an unnamed Power Word expert at an unnamed ad agency and an unnamed (but female -- a nice tiny touch of specificity) psychologist at an unnamed university (but in the northeast -- another tiny touch of specificity). If you can't smell the rotting fish by this point, you should get help.
But it gets better. Enter an unnamed reporter (sex not specified) for an unnamed publication. And we get a fairly long report of the interview with the professor, complete with direct quotes and personal touches. It begins:
and goes on with the professor displaying some (unimpressive) computer-generated poetry and some translation from English to Russian and back to English again: yes, the hoary mechanical translation joke about "The spirit is willing, but the flesh is weak." We seem to have fallen out of the genre of fabricated reports of research and into the genre of mockery of computational linguistics.
Elizabeth's third contribution, an on-line article "Communication Factors" by Russ Peterson and Kevin Karschnik, takes us back to Yale (once again, recently) and adds someone with (part of a) name:
· Easy
· Results
· Guarantee
· Need
· Proven
(Just a sampling from the canonical list. Peterson and Karschnik also (mis)report Mehrabian's research.) You might think that we could now track down this Dr. Levinson at Yale. But if you've been following this story, you'll realize that that would be a fool's errand. In fact, I suspect that the name Levinson got into this tale from still another source, Jay Conrad Levinson, the exponent of "guerilla marketing"(see the Wikipedia page), who has, as far as I know, neither an association with Yale nor a doctorate. (Thanks to Kevin Smith for the pointer to Levinson.)
Starting with his 1982 book Guerilla Marketing, Levinson has churned out an astonishing amount of material advising people how to run small businesses on tight advertising budgets. Among other things, he recommends using "magic words". Here (from Smith) is what he says on p. 121 of Guerilla Marketing Excellence: The 50 Golden Rules for Small-Business Success:
(I've bold-faced words that are on the canonical list or are variants of these.) Elsewhere Levinson has shorter lists, but I'm not about to plow through the mountain of his stuff on marketing to see what they look like. What's interesting about Levinson's lists is that he cites no sources beyond "other guerillas", so giving the impression that he devised the lists himself. Well, he's selling this stuff.
While we're back in the early 1980s, here's a passage (found by Marcus Hum) from a 1984 book on writing (not a marketing or self-help book), The Writing Workshop, vol. 2 by Alan Ziegler:
We're back at Yale, and with the full list in its canonical form.
Oh yes, Mark Liberman's posting on persuasive words quoted Ernest Nicastro's on-line column, which in turn cited Denny Hatch's Method Marketing (1999) as referring to an old Goodman Ace column in the Saturday Review. Since Ace died in 1982, this might be a line back to material in the period between Ben Zimmer's cites and mine above. On the other hand, Hatch might have misremembered Bennett Cerf as Goodman Ace.
zwicky at-sign csli period stanford period edu
And now a word from the Spam Analysis Division
It's been several months since the Spam Analysis Divison of Language Log has reported in (see here, here, and here). I don't know about the rest of the staff but my posts must be giving me away somehow. I don't know how this happened but the nice people who send me spams must really have my number. From reading my posts they seem to have discovered that:
- I am sex starved,
- I have puny equipment,
- I desperately need a loan,
- I can get a spiffy new ring tone,
- I've won a lottery prize (several, in fact),
- I could use a good dose of ephedra,
- I don't have the J.C. Penny credit card that will solve all my shopping needs,
- I can get any type of college degree that I lack,
- I should get out more and meet the local singles,
- I need a new car,
- I can learn how to be a hypnotist,
- I can get a really scary Halloween costume,
- I need a better mortgage,
- I need an Elmo,
- I can get cheaper health insurance,
- I've won a trip to Las Vegas, and, perhaps most interesting of all,
- I ought to have my colon cleansed.
Somehow, I didn't realize that my life was so bereft of these wonderful things. They must have a staff of diligent readers poring over places like Language Log to figure this out. The upside, however, is that recently I haven't received any messages from all our needy African friends who want to launder large amounts of money in exchange for a hefty percentage of it all for myself. I guess this one got away from me.
If the spammers of the world are reading this, I'm only kidding, of course. But please don't send more. I'm not sex starved, I seldom use the telephone, my mortgage is just fine, I like my Toyota, I don't even know what an Elmo is, I hate Las Vegas, and I don't much like the notion of becoming a hypnotist. What's more, I have all the college degrees I can use and my recent surgery has left me with only half a colon, which has helped me, lo these many years, finally learn how to use a semicolon.
Legal regulation of language use: a radical proposal
So, the lines are drawn. In Turkey, it is a criminal offense to assert that the Turks engaged in a genocidal massacre of hundreds of thousands of Armenians in the early years of the 20th century. And now the lower house of the French parliament proposes to make it a criminal offense to deny that the Turks engaged in a genocidal massacre of hundreds of thousands of Armenians in the early years of the 20th century. There is a clash here — and not a trivial one, given that Turkey wishes to join the European Union of which France is an influential member. Some kind of resolution seems to be needed.
Language Log does not meddle much in international politics or criminal law, but has a suggestion to offer concerning how a modern culture might design its criminal laws respecting language use in a reasonable way. (The following idea is radical, but hear me out.) The idea is to define the criminal laws in such a way that, in the case at hand, it would be fully legal either to assert that the massacre did take place or to assert that it did not take place (and analogously for any other public statement a person might wish to make), but also to endeavor to shape the general intellectual culture in such a way that people expect a serious person to be able to provide evidence and coherent argument in support of their claims — expression and publication of such evidence and argument being similarly protected from prosecution. The idea is (am I explaining this clearly enough?) that the truth values of contingent propositions would not be a matter of legal stipulation. And expressing propositions would be, well, sort of... free. You see the idea? (All right, you hate it. Never mind. I did say it was radical.)
Two new things from Europe
I was going to post about my latest discovery in the "12 most powerful words" saga -- an Akkadian tablet from 1200 BC, which attributes the list to an unspecified Sumerian haruspex. But I ran into problems embedding the cuneiform font, so instead, I'll interrupt our regularly-scheduled linguistic mythbusting to point you to two new things from the far side of the Atlantic.
The first is a cute web app: Wortschatz. The authors (from the University of Leipzig) have processed and indexed text corpora in 17 languages in various ways, and for each word, their web application will show you (quoting their help page):
- Frequency information (both absolute and relative to the most frequent word in the corpus)
- Sample sentences containing this word.
- Cooccurrences: Other words, occurring significantly often together with the given word; either as immediate left or right neighbor, or within the same sentence. They are ordered by significance with respect to the log likelihood measure.
- The strongest cooccurrences (at sentence level) are visualized as a semantic map.
You can download the (relational) databases and the browser used to access them, as well as a recent paper discussing the application: Quasthoff, U.; M. Richter; C. Biemann, "Corpus Portal for Search in Monolingual Corpora", Proceedings of the fifth international conference on Language Resources and Evaluation, LREC 2006, Genoa, pp. 1799-1802.
The second is a new book on political discourse. But this time it's not about Republicans as strict parents, or Democrats as latte-sipping elitists, it's about French presidential candidates as -- well, you'll have to judge for yourself. The book is by computational-linguist-blogger Jean Véronis and his colleague Louis-Jean Calvet, and the book is "Combat Pour l'Elysée: Paroles des prétendents".
The publisher's blurb:
La politique est, depuis la nuit des temps, une affaire de jeu avec les mots. Platon déjà fustigeait les sophistes, ces antiques "conseillers en communication " qui monnayaient leurs services linguistiques auprès des politiciens de l'époque, leur enseignant comment accommoder la Vérité à leurs fins. Les choses n'ont guère changé. En cette période pré-électorale où les candidats potentiels essaient de nous convaincre et de nous séduire, Louis-Jean Calvet et Jean Véronis décident de les prendre au mot et de décortiquer leur parole. Langue de bois, petites phrases, bons mots et lapsus, rumeurs du Web, sont ainsi systématiquement passés au crible de leurs analyses linguistiques et informatiques. Nouvelle manière de comprendre le politique, ce livre, à la fois sérieux et hilarant, propose un portrait cruel et inédit des différents prétendants à l'élection présidentielle.
And the authors have a book blog.
October 11, 2006
Persuasive words: the early years
The list of the most persuasive (or powerful) words in the English language — variously attributed to researchers at University of California, Yale University, and Duke University — is actually a musty bit of lexical lore long predating the Internet. The earliest reference I've found in the newspaper databases is from way back in November 1963. And the source is not a surprising one: Bennett Cerf, a prolific vector of urban folklore (see, for instance, his numerous appearances on Snopes.com, the urban legend clearinghouse). Here's the item that appeared in Cerf's syndicated column, "Try and Stop Me":
A poll by a big advertising agency established the fact that in the eyes of a representative segment of the American public the ten most persuasive words in the English language — in the order named — are You, Easy, Money, Save, Love, New, Discovery, Results, Proven, and Guarantee.
[Vidette-Messenger (Valparaiso, Ind.), Nov. 1, 1963, p. 4; Lowell (Mass.) Sun, Nov. 4, 1963, p. 5; Northwest Arkansas Times, Nov. 7, 1963, p. 4; etc.]
So at the time, the poll from the (conveniently unnamed) "big advertising agency" only isolated 10 persuasive words. But it wouldn't take too long for the list to expand to 12, with the name of Yale and other prestigious-sounding institutions attached along the way.
In January 1970, another syndicated columnist named L. M. Boyd (something of a successor to Cerf) presented a list of 12, with the first attribution to Yale that I've found:
Language Man: The 12 most persuasive words in the English language are: you, money, save, new, results, health, easy, safety, love, discovery, proven and guarantee. Or such is the claim of researchers in the Yale psychology department. No salesman should forget this.
[Fresno (Calif.) Bee Republican, Jan. 20, 1970, p. 7; Yuma (Ariz.) Daily Sun, Jan. 20, 1970, p. B6; Burlington (N.C.) Daily Times-News, Jan. 20, 1970, p. 6A; etc.]
So this list is the same as Cerf's with the addition of health and safety. That's the version that circulated most frequently in the '70s, with various vague attributions lending a patina of authoritativeness. Here's an Associated Press item from January 1972, in which the list takes on significance by being quoted from the Canadian Consumer Magazine, which in turn credits an unnamed "research report":
The Canadian Consumer Magazine quotes a research report saying that the 12 most persuasive words in the English language are: You, money save, new, results, health, easy, safety, love, discovery, proven and guarantee. That three-letter word "sex", didn't even make the top 12.
[Gettysburg (Pa.) Times, Jan. 17, 1972, p. 9; Wisconsin Rapids Daily Tribune, Jan. 31, 1972, p. 12; etc.]
Bill Gold repeated the list in his Washington Post column "The District Line" in July 1978. Again, the list seems authoritative because it is quoted from a trade journal (in this case Association Trends), citing a nebulous "study by experts":
Trade and industry associations make up an important part of our area's economy, and they make a lot of news. So I try to keep an eye on them.
Many association executives read Association Trends , a weekly news magazine tailored to their interests.
In a recent issue, Trends reported that a study by experts had identified the 12 most persuasive words in the English language. They were listed as: "money, save, new, you, results, health, safety, easy, guarantee, discovery, proven and love."
The magazine suggests that if the research is valid, this headline ought to get almost everybody's attention: "If you love to save money safely, get Plorg - the proven health discovery for guaranteed, easy results."
I was pleased to find "love" included in the list, but surprised to learn that "sex" is no longer considered the eye-catcher it once was.
Trends also mentions that public relations people and advertising copy writers are wondering how the study managed to overlook "free," which along with "new," was long considered one of "the best-selling words in the language."
[Washington Post, July 27, 1978, p. 12]
The omission of free noted by Gold has been corrected in many versions, such as this one attributed to Duke University researchers, where safety has been removed to make way for free. Since save is already on the list, perhaps safety was seen as a tad redundant.
Forty-three years of this lingua-canard, with no end in sight...
[Update, 10/12/06: A little more digging turns up two examples of the "persuasive words" list predating Cerf's column by two years, both appearing in ads wryly commenting on survey results from a generic (and possibly fictitious?) "Marketing Magazine." The ad on the left appeared in the New York Times on Aug. 14, 1961 (p. 15), while the ad on the right appeared in the Washington Post on Oct. 11, 1961 (p. C2):

So make that forty-five years and counting...]
On to North Carolina!
So far we've been to the University of California and Yale University, in search of the source of the 12-most-powerful-words list. Now Elizabeth Daingerfield Zwicky has wandered off to Duke University, back in the 1970s, in research on, oh dear, Neuro-linguistic programming. It's still the same old list. And an actual study has still to be found.
She found four sites. Two of them -- "The twelve words of power" on Everything2.com and "Real Secrets of Coercive Persuasion" on maxxsystems.com -- have almost identical wording (and both are unsigned). From Everything2.com:
Well, this has a bit more substance than the California and Yale reports, but a search on <"Duke University" "Neuro-linguistic programming" powerful> produces nothing useful. The Wikipedia entry on Neuro-linguistic programming does not mention Duke. (Or Yale. It does mention the University of California, specifically UC Santa Cruz, though.)
The other two sites mention Duke but not Neuro-linguistic programming. First, there's Mark Joyner's "Do You Believe It When Someone Says, 'I Won't Lie to You?'", which begins:
The last one, Dorothy Leeds's "Power Words + Power Language = Powerful Sales" (copyright 1998), takes us to Duke and lists the magical 12 words, but doesn't connect them (and cites no source at all for the list of words with powerful "emotional content"). Duke gets into the picture in her section "Powerful Speech Avoids Passive Language" (yes! passivity in language again!):
Say what you think right out, no qualifiers. You'll be a more powerful person. Try it. Now.
Okay, we've now heard from the West Coast, New England, and the South. Any other regions ready to weigh in with a claim on the magic words? Middle Atlantic? Midwest? Southwest? Rocky Mountain States? The Northern Tier? Or maybe something from Canada? We're waiting by the phone for your calls.
zwicky at-sign csli period stanford period edu
Yale and the 12 magical words
After I
reported on Allan and Barbara Pease's allusion to a University of
California study identifying the twelve most persuasive words, the
hounds of Language Log have been searching for a source. Andy
Hollandbeck wrote that he'd poked around and found nothing that could
be connected to the University of California, but did find three
references to a study at Yale with exactly the same results (or,
perhaps, "results"). Mark
Liberman also ended up at Yale, via another set of articles giving
advice for businesspeople, ad writers, and the like. All
unsourced.
I've now added five more to Hollandbeck's list. Summary to follow.
But first, a small criticism of Mark's parenthetical remark:
The number of University of California campuses is scarcely bewildering. It is 10, recently up from the 9 with the addition of Merced. I am able, in fact, to list them in a few seconds without looking anything up.
California State University, on the other hand, has 23 campuses, and I couldn't list them all to save my life.
Now the references to the elusive Yale University study. The first three are from Hollandbeck. The other five are some new ones I got from a Google web search on <"Yale University" "powerful words">; these are from the first 50 of the ca. 591 hits I got. The Yale study has a larger web presence than even this list would suggest, since some of these columns have been reprinted on several sites; I list the first site I found, without any attempt to trace things back to their original sources.
Each entry gives:
the title of article, plus date if the article is dated
how the words are characterized
how Yale's involvement is referred to in the article
the number of words in the list. If this is 12, without further note, the words are exactly as in my previous posting; otherwise, divergences are noted.
Scott Bywater
"Yale University Researchers Reveal 12 Powerful Words To Increase Your Profits" (1/17/06)
"most powerful"
"researchers at Yale University"
12
Shelley Lowery
"Secret Formulas for Writing Headlines That Sell"
"most powerful"
"according to a Yale University study"
12
Steven Boaze
"Copywriting Principles for Successful Headlines" (4/29/06)
"most personal and persuasive"
"recent research conducted at Yale University"
12
Candy Tymson
"Words That Work!"
"most persuasive"
"Yale University considers these..."
12
Rhonda Winn
"The Seven Second Race: How to Draw Attention Your Ad [sic]"
"most powerful"
"according to Yale University"
10 ("proved" instead of "proven"; "love" and "need" missing)
Daniel Wadleigh
"Marketing the 13 Power Words"
"very powerful words"
"a study done at Yale University"
12 (+ "free" added by Wadleigh)
Connie Glaser
"Winning at Work" column, "A tip to improve public speaking" (9/5/05)
"most powerful"
"Yale University researchers"
12
David Bell
"Tips On Writing a Successfull [sic] Ad"
"most powerful"
"researchers at Yale University"
12 (+ "free" added by Bell)
I'm a bit alarmed by the attributions to Yale as a whole ("Yale University considers these...", "according to Yale University"). I would hate to see some of my Language Log postings characterized as the opinion of Stanford University, and I'm sure the Stanford administration feels the same way.
In any case, this little inventory illustrates how ideas can diffuse rapidly (and, in this case, with reasonable fidelity) within a community and how the attractiveness of the ideas, their fit to folk beliefs, can lead people to accept them without even wondering where they came from -- or, of course, whether they are verifiable.
zwicky at-sign csli period stanford period edu
Yale University Researchers Reveal 12 Powerful Words To Increase Your Profits
That's what quite a few web pages tell us: {Yale you save money easy guarantee health proven safety discovery new love results}. I haven't checked out all 102,000 of the hits, but a sample of the first few pages leaves me skeptical that any journal citations will be forthcoming from the rest of them. Nor does Google scholar turn up any "Yale University researchers" claiming responsibility for this list.
Arnold Zwicky pointed out this morning that Alan and Barbara Pease, in their work The Definitive Book of Body Language, attribute the discovery of this same set of words to "a study at the University of California". I happen to own a copy of the Pease's book, and I'll echo Arnold's observation that they don't offer any further details -- not even what campus. (And though the University of California has a bewildering number of campuses, I'm pretty sure that none of them is named "Yale".)
Another set of web pages tell us that this list was invented by the American humorist Goodman Ace: {"Goodman Ace" you save money easy guarantee health proven safety discovery new love results}. Some of these are much more circumstantial than the Peases' account: thus Ernest W. Nicastro advises us, in his opus Five Never Forgets for Sales Letter Success, to follow the maxim
4. Never forget to use the magic words - In Denny Hatch's great book, Method Marketing, he writes about the time early on in his career when his boss gave him a half-hour lecture on direct mail. According to Mr. Hatch, at one point his boss pulled out a column from the old Saturday Review wherein the writer, humorist Goodman Ace, listed what he considered to be the twelve most powerful and evocative words in the English language. Those words are -
you, save, money, easy, guarantee, health, proven, safety, discovery, new, love, results.
To these twelve Hatch adds one more -- FREE -- citing legendary direct marketer Dick Benson who said, "'Free' is a magic word." So, for that matter, are the other twelve. Look for every opportunity to use these thirteen magic words in your sales letter copy. Use them properly and they will work magic on your response rates.
I'll give you another writing tip that Ernest W. Nicastro unaccountably failed to follow -- a new discovery of my own that's easy to use, guaranteed to impress people, and offered to you entirely free of charge:
4a. When you want people to believe something, attribute it to "X University researchers", for X = one of {Harvard, Yale, Princeton, Oxford, Cambridge, etc.}, or to "a Y study", for Y = one of {U.S. Government, University of California, Harvard, etc.}.
Although providing this form of attribution is a bit dishonest -- in fact, it's a bald-faced lie -- you can use it in complete confidence and safety, because no one ever checks. (Well, no one used to check. This is the era of blogs and WCFCYA -- but if you get a good publisher, a hundred people will buy your book for every one who finds out that you're making the whole thing up.)
If you want to move up a notch in the intellectual food chain, you can go ahead and provide an end-note referencing an actual scientific publication.. It's easy -- just search in Google Scholar to find a paper whose title or abstract contains some vaguely relevant words. For example, the fact that claims in self-help books are mostly bogus, but no one ever checks the references, is documented in A. Moyer, "Accuracy of Health Research Reported in the Popular Press", Health Communication, 1995.
Or maybe not. I didn't read the article. But it's true, right?
[Note that I'm not accusing Alan and Barbara Pease of lying -- I'm just saying that if you were to follow my advice to invent an authoritative attribution for something you just made up, or vaguely remember from a lecture, or found somewhere on the internet, you'd be, in the technical sense of the word, lying. As far as the Peases are concerned, I'll look forward to someone telling me about the actual University of California study that discovered the 12 powerful words. Because I'd hate to think that a work of popular science, published by Bantam Books and reviewed admiringly (if a bit cynically) in the New York Times, was full of lies.]
[Update -- Ned Wolfenbarger has a confession:
I'm a big fan of Language Log, and your recent "12 Powerful Words" post reminded me of a technique that I often used in college in the pre-internet days. Since there was no Google Scholar at the time, I would look up keywords in Bartlett's Familiar Quotations or in some other likely reference book and copy that book's references for use in my papers. I didn't actually read or even see or typically ever even have heard of the referenced work. I'm afraid to say that not only was I never caught, I was never even questioned.
]
The final word on words that end in -gry

[ Hat-tip to Bridget. ]
[ Comments? ]
Messages, verbal and nonverbal
Without appreciating that the review in the New York Times Book Review came from that prominent anthropologist and social psychologist Christopher Buckley, and without recalling Mark Liberman's mentions, in his pursuit of Louann Brizendine's claims about male/female differences, of Allan Pease's earlier books, I was moved by the review to buy The Definitive Book of Body Language by Allan and Barbara Pease (Bantam Books, 2006). Well, I buy a lot of books. I thought this one would be popular science (in the sense of science writing for the nonspecialist), but it seems to be folk-pop science, playing to folk beliefs and hawking a pop self-improvement message: YOU can learn to read and manipulate body language to your advantage (in the business world, especially).
If you read at all critically, you'll be deeply suspicious of the book within a few pages. It's full of wide-ranging unsourced claims about what research has shown (women are more perceptive than men, better at multitasking, and much more), bold assertions about what particular gestures and stances "mean", and other dubious statements. When I've been easily able to investigate the claims, they are drastically overblown. And often I have no easy way to evaluate them.
Query: what are "the most persuasive words in spoken language"? The Peases tell us that "a study at the University of California" (not further identified) found a dozen, and they counsel us:
While you're mulling over persuasive words, let me note that on p. 9 the Peases report that
What Mehrabian says on his website is a much more limited claim:
Total Liking = 7% Verbal Liking + 38% Vocal Liking + 55% Facial Liking
Please note that this and other equations regarding relative importance of verbal and nonverbal messages were derived from experiments dealing with communications of feelings and attitudes (i.e., like-dislike). Unless a communicator is talking about their feelings or attitudes, these equations are not applicable.
The Peases are repeating a widespread misinterpretation of Mehrabian's claims -- something much more stunning than what he actually said (and even that could probably bear some looking at).
Okay, those persuasive words. There were heavy hints in the quotation about them above:
I suspect that the Peases have blown up the research they're reporting on here, just as in the Mehrabian case.
zwicky at-sign csli period stanford period edu
October 10, 2006
Fable 2.0
Here's something new from one of my day jobs. FABLE ("Fast Automated Biomedical Literature Extraction") version 2.0 is now online at http://fable.chop.edu. The FABLE blurb:
FABLE performs document retrieval and gene list extractions of MEDLINE abstracts for queries of genes, transcripts, and proteins by annotating text in a completely automated process. The system is currently optimized for human genes. FABLE combines a named entity recognition extractor and a human gene normalizer that have been applied to all MEDLINE records. A query interface allows users to search for articles mentioning particular genes or proteins of interest, or to generate lists of genes mentioned in articles associated with any keyword(s). Identified articles and gene lists can be sorted in various ways, depending upon users' preference. FABLE also allows users to download articles and gene sets using a variety of formats.
FABLE was developed by the BioIE group at the University of Pennsylvania and the Children's Hospital of Philadelphia. FABLE and BioIE are supported in part through grants from the National Science Foundation and the National Institutes of Health.
The great new thing is a "Gene Lister" application that creates lists of relevant human genes from the biomedical literature, based on arbitrary boolean combination of keyword searches. Keywords can reference drugs, diseases, people, places, institutions, genes, proteins -- or any other text in the indexed literature.
Pete White's email announcing the application gives these as "for instance" searches:
Identify genes associated with a disease: {schizophrenia AND bipolar NOT depression}
Identify genes associated with a disease attribute: {metastasis AND "colon cancer"}
Identify genes associated with a person: {asthma AND "Doe JA"}
Identify genes associated with a place: {"University of Pennsylvania" AND "heart disease"}
Identify genes associated with genes: {myoglobin NOT hemoglobin}
Identify genes associated with techniques: {luciferase}
For example, if you type {metastasis AND "colon cancer"} into the "Gene Lister" field, you'll get something like this:
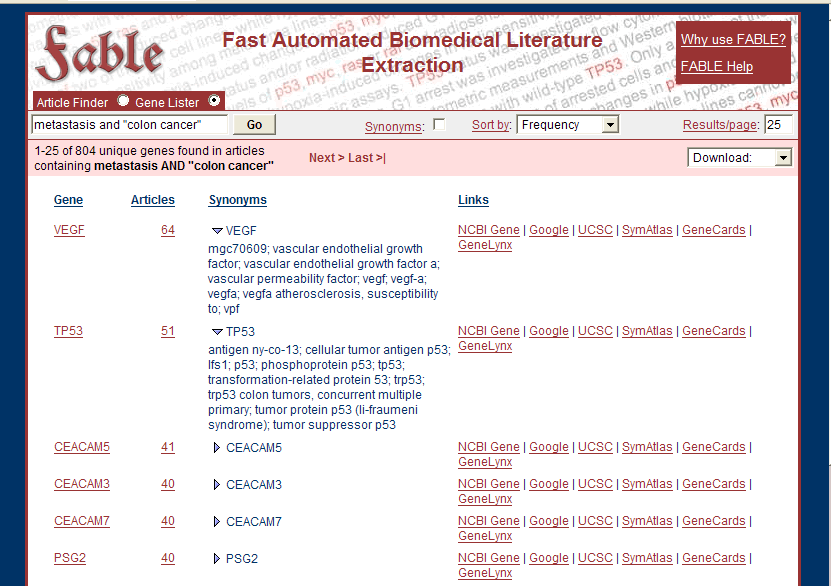
Note that you can click next to the gene symbols in the results, to see a list of synonyms.
The motivation for creating "Gene Lister" came from some experiments done last year by our collaborators at Children's Hospital. Here's a description of one of those experiments, from our yearly report to the National Science Foundation last summer:
We created a list of genes implicated in a specific biological process by applying our gene tagger and a rudimentary normalization process (case-insensitive exact string matching) to a set of 41,000 MEDLINE abstracts mentioning angiogenesis. A list of 2,460 genes extracted from and normalized in these documents was then compared against a manual list of 247 genes that was compiled by angiogenesis experts.
All but 2 of the genes in the manual list were also identified by the text-mined list. The text-mined list was relevance ranked based on the number of documents in which each gene was mentioned, and the 247 highest-ranking genes were compared with the comparably-sized manual list for precision. All of the 50 highest-ranked text-mined genes were identified as being legitimately associated with angiogenesis after further literature review. Furthermore, article recall was 17-fold higher than for articles linked to genes in Entrez Gene, and gene recall was 95-fold higher than for genes assigned to angiogenesis-related GO terms through AMIGO, demonstrating the current under-annotation of these resources for human genes.
The comparably-sized manual and text-mined lists were then compared by their respective correlations with gene expression profiles in low stage (rarely angiogenic) and advanced stage (angiogenic) neuroblastomas; by their correlations with protein pathways preferentially implicated in cancer; and with Gene Ontology annotations. In each case, the text-mined gene list correlated more closely with angiogenesis than did the manual list. Furthermore, blind evaluation of the highest-ranked text-mined genes by biomedical domain experts determined that the text-mined predictions were more accurate than expert opinion.
Importantly, the results of this exercise were deemed successful by the domain expert, as a slightly edited version of the text-mined list is now being used by Dr. X's lab as an initial screen for genes of interest in neuroblastoma progression. These results indicate that even a completely unsupervised process of compiling gene lists performs at high accuracy with our system.
The technology in the "Gene Lister" application is improved in several ways over what was used in the experiment described -- the gene tagger is somewhat better and the normalizer is a lot better -- so we have high hopes that it will be useful.
The data indexed by FABLE is refreshed weekly from MEDLINE®/PubMed®.
School shootings and passive constructions
The BBC, mindful of the fact that children also listen to the news when parents do, tries to maintain certain principles in coverage of truly distressing events such as the recent school shootings (an appalling four significant incidents in the last two weeks in the USA, some with fatalities). Tim Levell states ("The Editors", October 3):
We aim therefore to stand in the gap, and provide a simple, factual explanation of what happened. Specifically:
- We don't dwell on the details (which can make it so much more real to children, and mean they start putting themselves in that place)
- We use passive constructions ("Five girls have died", not "The man went in and shot five girls")...
Passive constructions? The example given, Five girls have died, is not a passive clause at all. The past participle died is required by the fact that it is the head of the complement of the perfect tense auxiliary have. The clause is in the active voice, not the passive. As we have pointed out before (here, and here, and here, and here), people often talk about the passive voice and how to avoid it without having any idea of how to identify a passive clause. If avoiding passives is going to be, for example, a key editorial precept for a book series, and now using them is going to be official policy for a worldwide news organization like the BBC, then some instruction is needed in how to tell when you have one of the pesky things and when you don't. As Arnold Zwicky points out (here), you can't just rely on your common-sense notions of what involves passively waiting or experiencing as opposed to actively doing or causing. Not if you mean "passive" in the grammarian's sense, which is surely the sense of the word in Tim Levell's claim that they "use passive constructions" in writing BBC news copy.
[Thanks to Karen Davis for the tipoff.]
October 09, 2006
Hangul Day 2006
Today, October 9th, is Thanksgiving in Canada and Columbus Day in the United States. For linguists everywhere, it is Hangul Day.
Avoidance omnibus
This is an omnibus issue of Annals of Taboo Avoidance, with seven items, going back to June 7th and forward to today.
1. Back in June, I mocked the New York Times for not letting a reporter use the French word merde and pushing him into ostentatious avoidance in describing
At the time, I reported Mark Liberman's discovery that over the years the NYT had not in fact been particularly shy about printing the word (in French); even William Safire used it. But another discovery of Mark's got to me too late for inclusion in my posting: since 1981, the paper had printed "dog poop" (not a bad translation of the name of the gnocchi in question) 17 times, so it would have been available as an alternative to this baffling allusion to the name of the dish.
I've reported here that the Times has set itself a tough task in dealing with taboo vocabulary. On the one hand, it absolutely insists that taboo words not be printed, even in quotations where they would cast some light on the character or emotional state of a speaker or writer -- though on occasion (most recently, in July) it makes an exception for the President of the United States.
On the other hand, it has a stated policy of not using ostentatious avoidance: no "F-word", "F-bomb", "freaking", "expletive deleted", "S---", or the like. In cases where someone at the paper (writer or editor) thinks some allusion to the taboo word is called for, it will stretch this second principle to allow things like "a word that cannot be printed in this newspaper" or "a name that cannot be printed in a family newspaper" (as above, with reference to the gnocchi). But the paper's practice is inconsistent, no doubt because different editors choose to perform this balancing act in different ways. And so we get things like
which I reported on a little while ago.
Now two more from the Times that slipped past during the summer.
2. On July 7th, an article by Kirk Johnson told about the journal kept by Columbine High School killer Eric Harris, including the report that
There's a fairly easy fix for this, something along the lines of:
3. On July 23rd, guest "On Language" columnist Ashley Parker wrote about word truncations in the lingo of some young women she knows. At the conclusion, one of them (Parker's younger sister Justine) deflects a maternal punishment:
My mom let her go with just a warning. When Justine relayed the whole story to me the next day, I gave the only appropriate response I could think of: "She didn't punish you? What the freak-a-leak."
What the freak-a-leak indeed.
Matthew Hutson, who wrote me about this column, marveled at the way the Times balked at "f-bomb" but was willing to print "freak-a-leak" (twice, in fact). But Parker wanted to illustrate that she had picked up a lot of her sister's lingo herself, so it's hard to see how to write around the avoidance word "freak".
4. Then from Eric Jusino came a pointer to an article in the Boise State University Arbiter of July 26th, complaining about the extreme heat at the time, under the headline
This is very ostentatious avoidance indeed (though Justino and I both thought it was clever), and, not surprisingly, elicited an angry letter (of August 21st) from a faculty member protesting the "abbreviated form of the 'f-word'" in the paper:
5. Next an AP story of October 6th ("Sienna Miller Apologizes to Pittsburgh"), passed on to me by Edward Carney:
Rolling Stone quotes "Shitsburgh" as is.
[Addendum, 10/10: Charles Belov points out that "a name that sounds like Pittsburgh, but contains an expletive" would be "Pissburgh"; "Shitsburgh is a name that RHYMES with "Pittsburgh" and contains an expletive. Inept euphemizing!]
6. From yesterday's Observer Magazine -- the Observer is the Sunday counterpart to the Guardian -- a jokey taboo avoidance that echoes the Dean quotation above, pointed out to me by Jasper Milvain:
7. Finally, from Aaron Dinkin, a report of an interview on Philadelphia NPR station WHYY this morning, in which the interviewer Q (Marty Moss-Coane) and the interviewee A (John F. Harris) try to negotiate what you can say on the air in the United States. The exchange went:
A: "... they just don't give a ... uh ... darn -- I'm not sure what I can say --"
Q: "'Darn' is okay."
A: "'Darn' is okay."
There's a question about whether "darn" is okay? What have we come to?
zwicky at-sign csli period stanford period edu
Chomsky killed by interpreter?
Addressing the United Nations General Assembly on September 20, Venezuelan President Hugo Chávez spoke approvingly of Noam Chomsky's Hegemony or Survival: America's Quest for Global Dominance, resulting in a massive uptick in sales for the book. (Tensor imagined what might have happened if Chávez had plugged another work of Chomsky.) It was also widely reported that Chávez spoke of Chomsky in a subsequent press conference as prematurely deceased. Here is how the New York Times presented the news:
Mr. Chávez ... brandished a copy of Noam Chomsky's "Hegemony or Survival: America's Quest for Global Dominance" and recommended it to members of the General Assembly to read. Later, he told a news conference that one of his greatest regrets was not getting to meet Mr. Chomsky before he died. (Mr. Chomsky, 77, is still alive.)
The Times even spun out an entire follow-up story on the Twainian theme that reports of Chomsky's death were greatly exaggerated. But on Oct. 6, a belated correction was appended to both of the articles:
In fact, what Mr. Chavez said was, "I am an avid reader of Noam Chomsky, as I am of an American professor who died some time ago." Two sentences later Mr. Chavez named John Kenneth Galbraith, the Harvard economist who died last April, calling both him and Mr. Chomsky great intellectual figures.
Mr. Chavez was speaking in Spanish at the news conference, but the simultaneous English translation by the United Nations left out the reference to Mr. Galbraith and made it sound as if the man who died was Mr. Chomsky.
Readers pointed out the error in e-mails to The Times soon after the first article was published. Reporters reviewed the recordings of the news conference in English and Spanish, but not carefully enough to detect the discrepancy, until after the Venezuelan government complained publicly on Wednesday.
Editors and reporters should have been more thorough earlier in checking the accuracy of the simultaneous translation.
The video of the press conference is available from the UN Webcast Archives, with the relevant section occurring about 37 minutes and 30 seconds in. All that can be heard on the video (presumably what the Times and other news organizations relied upon) is the simultaneous translation of the U.N. interpreter in voiceover, not Chávez's own voice. ABC News Now (via LexisNexis) transcribed the interpeter's translation thusly:
(Through translator) You asked how to achieve the, overthrow the, of imperialism. The political work of Chomsky, which has been very important for many decades. I am an avid reader of Noam Chomsky. An American professor who died some time ago. I wanted to meet that man, but he was aged. He was 90 years old. John Kenneth Galbraith, I have been reading him since I was child, and so Noam Chomsky. They are, these are great intellectuals of the United States. The people of the United States should read what they have written, much more than they do instead of watching 'Superman" and 'Batman and Robin" movies that delve people's and young people's minds....
As can be seen on the UN Webcast video, Chávez continued to hold up the copy of Chomsky's book, as he had done in his General Assembly speech, while the interpreter said, "I am an avid reader of Noam Chomsky. An American professor who died some time ago..." The use of the prop likely misled the interpreter, who assumed "an American professor who died some time ago" referred to Chomsky, rather than the as-yet-unnamed figure of John Kenneth Galbraith. The interpreter's phrasing certainly makes it sound like Chomsky is the one that Chávez is eulogizing.
So it appears that the interpreter was relying on contextual cues during an on-the-fly translation to determine who the speaker was talking about. Little did she know that Chávez had already shifted his topic from Chomsky to Galbraith. (We can't hear the Spanish to know if there were any other clues to indicate a change in topic, but the Times correction implies that even in the original Spanish the discursive shift was subtle.) For any reporters listening to the simultaneous translation, or following the transcript later on, there was little indication that "an American professor who died some time ago," as well as subsequent deictics, ("that man", "he") coreferred with Galbraith instead of the already mentioned Chomsky. The Times correction also claims that "the simultaneous English translation by the United Nations left out the reference to Mr. Galbraith." That makes it sound as if the interpreter omitted the reference to Galbraith altogether, but I think it simply means that the two referents were not clearly distinguished in the translation (as in the corrected version: "I am an avid reader of Noam Chomsky, as I am of an American professor who died some time ago").
Despite the life-or-death implications for Mr. Chomsky, this all seems like a typical translational snafu. Chávez supporters, however, would probably portray this as part of an American media conspiracy against the president. I see no such conspiracy, though I do wonder why it took the Times so long to issue a correction, if they were alerted to the error so soon after the first article was published. (By contrast, the BBC issued a correction on September 30, at least on its Spanish-language site.) Apparently it took a public castigation by the Venezuelan government for the Times to make its sheepish apology. Perhaps they had a fleet of bilingual fact-checkers on the case, carefully Zaprudering the Chávez video to determine what exactly was said. More likely, it was just the typical snail's pace of fact-checking at the Grey Lady, a process that one Times editor likened to "trying to drink from a fire hose or bail Lake Michigan with a teaspoon."
[Update, 10/14/06: CM of Working Languages helpfully points to his consideration of what Chávez actually said (video here), with a sharp critique of how news organizations relied on the faulty translation. At the time I wrote the above post, I hadn't been able to find any such analysis of the original Spanish. CM's post makes it quite clear that both the Times and the BBC did a terrible job both in their original reporting of the Chávez press conference and in their issuing of weak and belated corrections.]
Poem in the key of what
Being a positive and constructive kind of person, I'm really tired of complaining about bad science writing and similar negative stuff. So to strike a more hopeful note, I've spent three full breakfast blogging sessions, over the past week or so, exploring some interesting ideas that I found in a recent paper by Maartje Schreuder, Laura van Eerten & Dicky Gilbers, "Speaking in major and minor keys" [hat tip to JC Reed]. (I don't mean that I've written three blog posts, alas -- only that I've spent about two hours, spread over three days, producing this post.) Below, I'll explain what I've found, and give pointers to some programs that you can use to continue exploring on your own, if you're interested in such things.
The idea behind this paper is that the pitch contours of speech naturally express the same sorts of melodic intervals that occur in music. This is an old idea, prominent already in Paṇini's work two and a half millennia ago, but Schreuder et al. have a new idea about how to look for the phenomenon. While it's clear that musical intervals are part of the stylized forms of speech that we call "chanting", I've always been skeptical that well-defined intervals (in the sense of small-integer ratios of pitch values) play a role in unchanted speech. I'll explain some reasons for my skepticism later in this post. However, it would be fun to be wrong on this one.
Here's what Schreuder et al. did:
In order to obtain different emotions in speech, we asked five primary school teachers to read selected passages in Dutch from A.A. Milne’s Winnie the Pooh, in which Tigger, who is energetic and happy, and Eeyore, who is distrustful and sad, are presented as talking characters. We expect that Tigger represents a major modality, and Eeyore a minor modality in their speech. [...]
The passages in which Tigger and Eeyore were speaking were extracted and concatenated to ten files each varying from 8 to 53 seconds. These files were sampled every 10 milliseconds and the pitch data of each sample were obtained using PRAAT. In this way we obtained a pitch contour which we compared to the original one. Because of the great similarity, we decided that the sample rate of 10 milliseconds was sufficient for our experiment.
Subsequently, we did a cluster analysis of the pitch data in order to find out which frequencies occurred most in each contour. [...] The obtained pitch values were clustered i.e. rounded off downwards or upwards to the value of the nearest semitone.
And here are samples of their results:
 |
 |
I'm not 100% convinced by these plots; and also I think their selected examples might be stacking the deck a bit, since Eeyore is stereotypically (since the Disney movie, at least) someone who signals a depressed state by speaking almost in a chant, in which minor-third intervals are prominent. But still, this is really interesting stuff.
To see how this general approach might work, let's start out by trying it on some singing. I picked the first couplet of Janis Joplin's a capella prayer (from Pearl, 1971):
Oh Lord, won't you buy me a Mercedes Benz?
My friends all drive Porsches, I must make amends.
Here are the waveforms and pitch tracks for these two lines (an audio clip is linked to the pitch contour display):
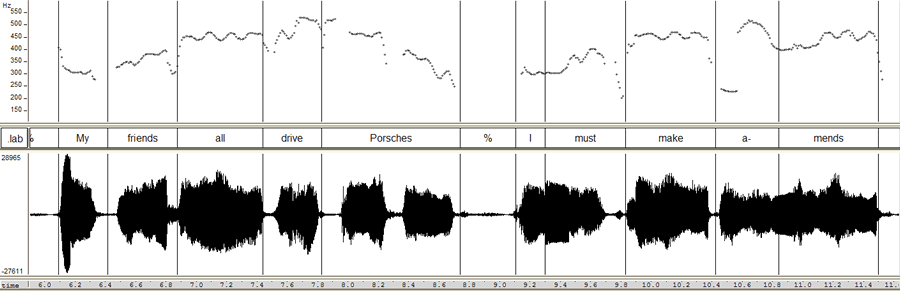
(I've used the free software program WaveSurfer here, rather than the free software program Praat, which Schreuder et al. used. Both programs are excellent -- Praat has many more features, and is more widely used; WaveSurfer is perhaps somewhat easier to learn to use in simple ways, and its pitch tracker (originally written by David Talkin when he was at Entropic Research Laboratory) seems to be somewhat better, overall). The most obvious approach to checking out the pitches would to look at the average fundamental frequency of particular syllables; here that might get us e.g.
Word |
Average F0 |
Note (in abc notation) |
Oh |
299 |
D+ |
Lord |
454 |
A+ |
buy |
302 |
D+ |
Mercedes |
288 |
C#+ |
Benz |
226 |
A,+ |
interpreted with respect to the pitches of equally-tempered semitones relative to A 440:
| A | A# | B | C | C# | D | D# | E | F | F# | G | G# | A | A# |
| 220 | 233 | 247 | 262 | 277 | 294 | 311 | 330 | 349 | 370 | 392 | 415 | 440 | 466 |
Thus this couplet features pitches that are about a quarter-tone sharp relative to D, A, C#. But as Schreuder et al. suggest, we can also see this by looking at a histogram of pitch estimates. So I asked WaveSurfer to write out its F0 estimates for each centisecond of the two phrases shown above (right-click on the pitch pane, select "Save Data File"), and used the free software program R to calculate a histogram in quarter-tones relative to A 440 (the functions that I wrote to help do this are here).
I used a histogram in quarter-tones, rather than rounding the data off to the nearest semitone as Schreuder et al. did, because I thought that might be more revealing. (Actually, I started out using eighth-tones, but I decided that was unnecessarily finely divided.) Anyhow, the result shows us peaks at pitches similar to those that we measured locally:
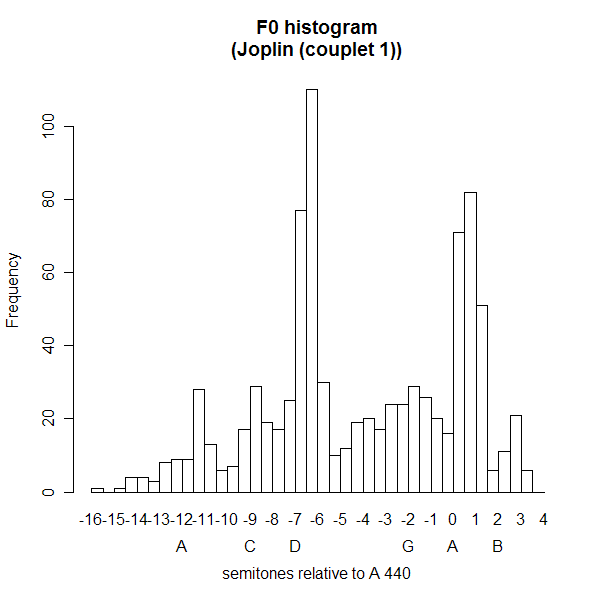
OK, cool! There's much more to be explored here -- but it's clear that there are well-defined modes in the histogram, and surely they must correspond to the pitches of the sung melody. But what would we see if we looked at something spoken rather than sung? Well, it happens that Janis introduces that song with a spoken phrase:
Like to do a song of great social and political import.
so here's the same analysis, starting with the pitch contour:
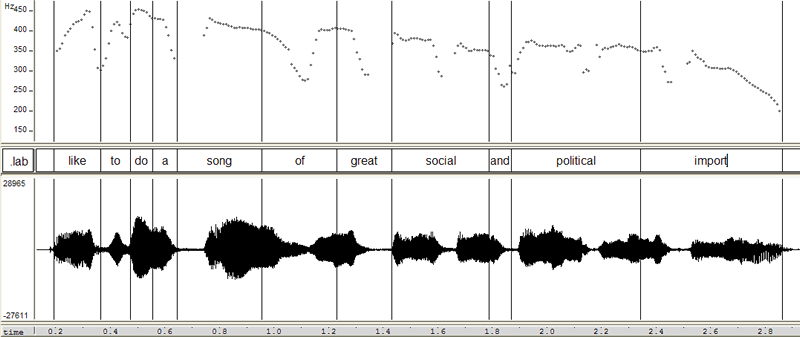
and continuing with the quarter-tone histogram:
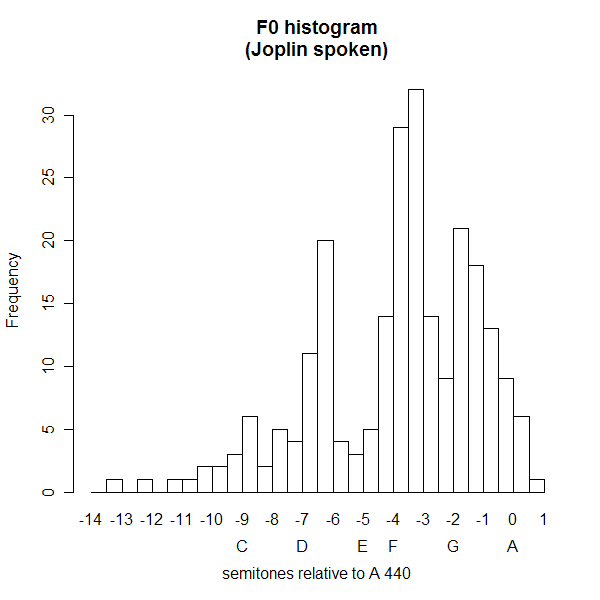
Cool -- modes again! Does this phrase really feature pitches (just sharp of) C, D, F and G? Or is this some sort of artefact? Maybe a bit of both, but in any case, this way of looking at F0 distributions seems really interesting and suggestive.
Let's try something else -- the start of Sylvia Plath reading her poem "Daddy":
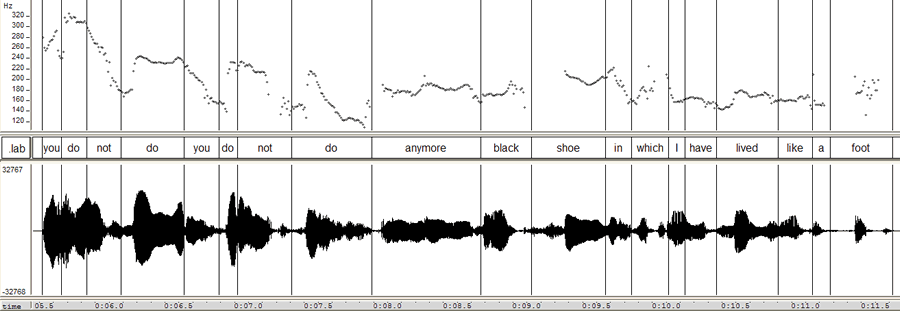
Modes again! That's modes in the sense of "peaks in a distribution" -- but maybe, as Schreuder et al. believe, it's also modes in the sense of "organized set of musical pitch classes"... And here's the histogram for the whole poem:
Hmm. The modes are less clear -- pitches drifting around a bit in the performance? -- but still, it's not at all the smooth distribution that I might have predicted. (By the way, the script for producing the two previous histograms is here.)
Or, for example, the (fairly) smooth distribution that we see, more or less, in Alan Ginsberg's reading of his poem "A Supermarket in California":
FYI, here are the pitches of the relevant region of the tempered chromatic scale for Sylvia Plath's pitches -- you can divide them all by two, roughly, for Alan Ginsberg's pitch range.
| A | A# | B | C | C# | D | D# | E | F | F# | G | G# | A | A# |
| 110 | 117 | 123 | 131 | 139 | 147 | 156 | 165 | 175 | 185 | 196 | 208 | 220 | 233 |
OK, one last example, a phrase from a random radio talk show (Marty Moss-Coane's Radio Times, 8/10/2005):

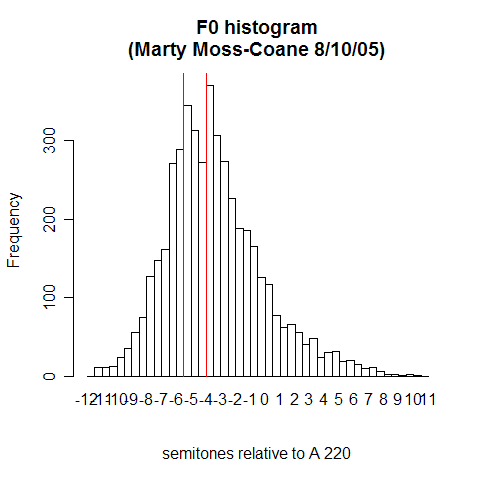
Well, this is going to take some further investigation -- but, as the old Russian expression goes, it smells of horizons.
As for why I've always been somewhat skeptical about this whole musical-intervals-in-speech business, it goes like this. (You can find a more extensive discussion of these general issues in Mark Liberman and Janet Pierrehumbert, "Intonational invariance under changes in pitch range and length", pp. 157-233 in M. Aronoff and R. Oehrle, Eds., Language Sound Structure, MIT Press, 1984. The plots below are all taken from that paper, and if you don't follow the rather sketchy discussion here, you can read more about it in the scan of the paper that I've put online.)
Let's ignore the fact that pitch contours in speech rarely involve steady values maintained long enough to give a clear impression of a well-defined "note", but rather usually involve glissandi or pitch slides. After all, some melismatic styles of singing also rarely rest very long on any one pitch value. So is speech just an especially melismatic form of singing?
The first point to be made is that a given spoken phrase can be produced in a wide variety of pitch ranges. And the scaling of corresponding pitches does not, in general, preserve musical intervals. For example, as you "raise your voice" (for example so as to speak to someone who is further away, or to speak over a louder level of background noise), the high pitches generally go up by higher multiples than the lower pitches do:
In addition, there is a tendency (known as "declination") for pitch contours to slope downwards, on average, within a phrase. For example, we took the first few dozen phrases from a radio news broadcast (spoken by a single speaker), normalized their time spans to a constant length, and averaged the F0 by position. The resulting plot looked like this:
As we explain in the cited paper, there are several different factors leading to this declination tendency. But in this context, what matters is that local pitch relationships are shifted up and down depending on their location in a phrase; and the shifting, again, is not strictly multiplicative, as it would need to be if musical intervals were to be preserved. One way to see that is to observe that the down-drifting of relatively-high-pitched stressed syllables follows an exponential decay to a non-zero intercept -- except for the final one, which is lowered further:
There are other ways to see that pitch scaling in speech does not preserve musical intervals -- or in other words, does not follow purely multiplication patterns. For example, we can look at the relationship of peak values in double-focus phrases with "foreground" and "background" accents, like these:

As we vary pitch range (in this case, by asking the subject to address someone at different distances), this relationships varies in lawful ways, which can be well approximated by simple models of a type discussed in the cited paper. The figure below shows some experimental data and the fit of a particularly simple model:
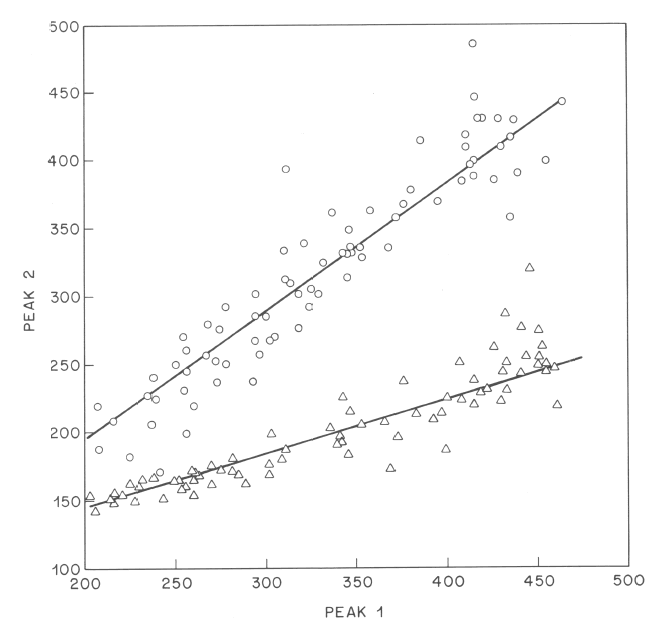
You can see that the relationship between the peak pitch of the first accent and the peak pitch of the second accent can be approximated by a straight line. However, if the relationship were that of a fixed musical interval, the intercept of the line should be zero -- but these lines have clearly non-zero intercepts.
As discussed in the linked 1984 paper, this is basically the same fact as the existence of the non-zero asymptote in the declination data. A simple version of this story is that each person has a "baseline" pitch value, and that higher pitch values scale proportionally above this baseline. This predicts that pitch relationships in speech should have an additive component as well as a multiplicative one, and this is indeed what seems to happen. It's hard to square this with a view of intonation that gives a key role to musical intervals, much less scale types such as major and minor (not to speak of Dorian, Mixolydian, Bhimpalashri or whatever).
All the same, some of those F0 histograms seem to have very clear multi-modal structure. This is entirely consistent with a view of pitch scaling in which the relationships are not purely multiplicative -- there might indeed be a limited set of discrete favored pitch-classes, and/or a set of favored "intervals" in some extended sense, e.g. in ratios of baseline-units above a baseline. But free pitch-range variation, general down-drift and various other phenomena ought to produce pretty smooth F0 histograms most of the time. If that doesn't happen, it would be nice to know why. And looking at F0 histograms (allowing for the manifold problems of pitch tracking errors, segmental effects, etc.) is an interesting idea about how to look for patterns in the melodies of speech, without imposing any particular assumptions about which parts of the contour matter and which don't. Dipole statistics might be even more interesting.
[Update: more here]
Virtually a prefix for the words
Of all the topics I have addressed on Language Log, the one that brought me the most flak and the least sympathy has been my critical remarks about linguifying. And what is linguifying, newbies may ask? From Jesse Sheidlower comes this beautiful textbook example (one could scarcely ask for a better one):
The average cost of a family insurance plan that Americans get through their jobs has risen another 7.7 percent this year, to $11,500... These spiraling costs—a phrase that has virtually become a prefix for the words "health care"—are slowly creating a crisis.
(David Leonhardt, New York Times 27 Sept. 2006)
The main claim here is that the spiraling costs of health care are slowly creating a crisis. But dropped in the middle is a parenthetical interruption that at first sight is an astonishing irrelevance, since it has to do with language: a claim that the phrase "spiraling costs" has virtually become a prefix for the words "health care". I take that to mean that where you find the words "health care" you will find, or generally find, that the phrase "spiraling costs" immediately precedes them.
Now, to be picky, *spiraling costs health care is not grammatical and does not occur at all, but let's be generous, and allow the insertion of the obligatory of or other material to restore grammaticality. The claim is that virtually all occurrences of health care are in sequences of the form spiraling costs ... health care. Let me present the facts, as roughly estimated by a comparison of Google countsearly on October 9, 2006. (Kevin Smith reminded me that both the British and the American spellings should be taken into account; in the first version of this post I mistakenly used the British spelling throughout. It's the one feature of the difference between British and American spellings that I never properly internalized after my emigration. I'll list the results for the two spellings separately.)
| "health care" | 315,000,000 |
| "spiralling costs of health care" | 75 |
| "spiraling costs of health care" | 648 |
| "spiralling costs * health care" | 132 |
| "spiraling costs * health care" | 914 |
Even if we forget about the idea of prefixing and just ask that "health care" and "spiraling" and "costs" in other combinations, the figures are not vastly different:
| "spiralling health care costs" | 2,100 |
| "spiraling health care costs" | 39,200 | "health care" "spiralling costs" | 15,200 |
| "health care" "spiraling costs" | 58,400 |
Bottom line: the occurrences of "health care" that do not have "spiral(l)ing costs of" immediately before them outnumber those that do, by vast factors, ranging from thousands to millions. In fact on average you need to read through thousands and thousands of pages mentioning "health care" before you find one that even has the phrase "spiral(l)ing costs" somewhere else in the page, regardless of where. It's not exactly looking like invariant prefixing of one phrase by another, is it?
I have asked before and I'll ask again: why would someone do this? Why take a claim about the medical care industry that might well be true (that health care costs have been rising) and turn it into a flagrantly, disastrously false claim about occurrence of word-token sequences in published texts?
When I say this, people write me patronizing messages to explain this sort of thing away, talking to me as if I were roughly five years old. People will probably write to me to explain that what Leonhardt really means is that lots of people talk about spiraling costs of health care. I know that. My whole point is that while he means lots of people talk about increasing health care costs, which is no doubt true, he doesn't say it. Instead he asserts something wildly false about occurrence of word sequences. Why?
Other people will write to me to explain confidently that it is hyperbole, i.e., exaggeration. It isn't. To say "There have been three billion articles on the rise in health care costs in the past two weeks" would be an exaggeration; but to say something about the word sequences that typically precede the sequence health care in English text is to completely change the subject.
Still others will tell me confidently that it's a "metaphor". This is a very broad claim indeed, but even if some linguifications can indeed be said to fall within the domain of metaphorical usage, that misses my point. In general, for most kinds of metaphors, it is easy to understand why people use them. They get the point across briefly and vividly. To say that the new office manager is a pussycat establishes instantly — just as a good caricature might — that the man's general demeanor and behavior suggests a cute, cuddly, playful, non-serious, easy-to-deal-with, tractable, non-fearsome nature that otherwise might take a considerable amount of time-wasting careful description to get across.
But I simply do not understand why people use linguification. If it gets the point across at all, it does it only indirectly and clumsily: we have to infer from statement about word distributions, usually one that is false, some underlying statement that is only very imperfectly connected to it.
Lots of people seem to think I am being judgmental or prescriptive about this. Not really. Lots of journalists seem to think this is just the kind of effect they want. I'm not saying there is something linguistically incorrect about it. I'm saying I just cannot see an explanation for the way people choose to use this particular rhetorical device, when it seems (unlike a well-chosen metaphor) almost always to work against their interests rather than for them.
October 07, 2006
Fun quiz of the day
Fev at Headsup: The Blog is running a quiz on science journalism. He starts his post this way:
Hey, I know. Let's have a quiz! Here's a story, with heds, as it appeared today on the Web site of a major metropolitan daily. There's a brief quiz (true-false and multiple guess) at the end. Post your answers as comments or send 'em to the address at right.
Extra credit: One point for finding a copy of the abstract by first-edn deadline (let's say that's 9 p.m. Saturday in whatever time zone you're in). Two points for finding the article itself by that deadline.
I'll post answers when I'm done pounding nails into my skull.
Media erode men's self-esteem
Study links TV to risky behavior, aggression
Well, I'm not going to make Fev's extra-credit deadline, because I didn't read his email inviting me to participate until half an hour ago. But I'm going to take his quiz anyhow, since it's a sort of perverse comfort to find that science reporting is just as bad when it's not about speech or language. And at the end, I have a question for him -- and I invite the rest of you to offer your own answers in the comments to his post.
What had Fev pounding nails into his head is this section of a (widely reprinted AP wire) story:
In the past, research has understandably focused mostly on women, and the dangerous eating disorders that can stem from body-related emotional issues. And when looking at men, researchers asked the wrong questions, Schooler argues.
"Asking men about just weight or size misses the boat," Schooler, a research associate at Brown University, said in a telephone interview. What men are more concerned about, she says, are other "real-body" factors, like sweat, body hair and body odor.
In a study published last spring and recently featured in Seed magazine, Schooler, then at San Francisco State University, and a colleague looked at 184 male college students. The more media these young men "consumed" - especially music videos and prime-time TV - the worse they felt about those "real" aspects of their bodies, the researchers found.
Further, they found that such negative feelings impacted their sexual well-being, in some cases leading to more aggressive and risky sexual behavior.
The study in question was: Deborah Schooler & L. Monique Ward, "Average Joes: Men's Relationships With Media, Real Bodies, and Sexuality", Psychology of Men & Masculinity, 7(1) 27-41, January 2006.
1) This study measures "self-esteem" in men.
a) True
b) False
Dunno. "Participants completed several survey measures", including the "Body Esteem Scale" and the "Body Comfort/Body Modesty Measure". These questionnaires surely measure some aspects of self-esteem. On the other hand, the subjects were 184 students from "two undergraduate psychology classes at a large midwestern university", minus five who self-identified as "gay", which might be regarded as a less-than-representative sample of "men".
2) Consider the image in the lede. Did the study find that men who read lots of fitness and porn magazines have:
a) More positive body esteem?
b) Less positive body esteem?
Here's the table with the results of their multiple regression:
Neither reading Playboy and Penthouse (their proxy for porn magazines), nor reading Men's Health and Muscle and Fitness (their proxy for fitness magazines) had any statistically-significant effect on the "Own Body Comfort" index. All of the predictors they used were only able to account for 17% of the variance in this index. The most effective predictor was body mass index, unsurprisingly.
As for the two BES scales, reading porn mags had a significant positive connection with both; reading fitness magazines had a marginal positive connection with the "upper body strength" scale and no connection with the "physical condition" scale. All of the independent variables combines explained only 3% and 5% of the variance in those measures, respectively.
3) How many times would you estimate the words "aggression" or "aggressive" appear in the study?
a) None
b) 2-5
c) 6-10
d) 11 or more
We don't need no stinkin' estimates. By actual count, the number is zero.
4) Findings from this study can confidently be generalized to:
a) Men
b) Men aged 18 to 35
c) Straight male undergraduates in introductory and general psyc classes at Michigan State
d) None of the above; generalizing from convenience samples is inappropriate
I'd go with (c), with the caveat that the method of recruiting subjects (offering extra credit in psych class) might have created some bias. If I weren't such a positive and easy-going kind of person, I might go with option (d).
5) How would the researchers characterize the "real body comfort" measure used here?
a) Well established in a number of social science fields
b) New and not yet broadly established as valid
c) Well known in experimental psychology but new elsewhere
d) Hypothetical and used here for the first time
According to the article, their "body comfort" scale is based on a weighted combination of answers to certain questions taken from a recent study of "women's reproductive attitutes" (Merriwether, A., & Ward, L. M. (2002, August). Comfort in our skin: The impact of women's reproductive attitudes. Poster presented at the annual meeting of the American Psychological Association, Chicago). This seems to be the first time it has been used. That's not a bad thing, in my opinion -- but it didn't exactly shine, in this case, in terms of any discovered relationship to anything else. They'd probably have gotten more statistical juice out of asking about hobbies and recreational activities.
6) Among subjects in this study, comfort with "real body" factors predicts:
a) More sexual assertiveness and less sexual risk-taking
b) Less sexual assertiveness and less sexual risk-taking
c) Less sexual assertiveness and more sexual risk-taking
d) More sexual assertiveness and more sexual risk-taking
Here's the table.
The answer is "none of the above", as far as I can tell: "own body comfort" and "comfort with women's bodies" were both significant predictors sexual assertiveness, but neither was significantly predictive of sexual risk-taking. But note that all predictors combined accounted for only 16% of the variance in "sexual assertiveness" and for less than 2% of the variance in "risky sexual behavior". In a sample that size, you could probably predict 2% of the variance in risky sexual behavior from the subjects' astrological sign. (Or from a table of random numbers.)
7) The only significant demographic predictor of risky sexual behavior in this study is:
a) Religiosity
b) Being Asian
c) Own body comfort
d) Comfort with women's bodies
The answer is (b), being Asian. But it's not much of a predictor, since all the factors together accounted for only 2% of the variance.
8) The study found a causal relationship between negative feelings about the "real body" and aggressive sexual behavior.
a) True
b) False
False. The study asked about "sexual assertiveness", not aggression, but in any case, it found that greater "own body comfort" slightly predicted greater "sexual assertiveness".
9) The study found that men are more concerned about "real body" factors than about weight or size.
a) True
b) False
The answer is (b). The question is not addressed directly, but there (for example) participants estimated their "comfort with own real body" at an average of 5.41, whereas their "body esteem" factors were 3.43 for "upper body strength" and 3.46 for "physical condition".
10) The strongest predictor of whether men in the study were comfortable with their own bodies was body-mass index.
a) True
b) False
True -- see the table reproduced above.
Now I've got a question for Fev.
The science journalists whose work is typified by this story are
a) stupid
b) lazy
c) cynical and dishonest
This is not a rhetorical quiz-question -- I'm genuinely puzzled. It's clear that such people can read and write and think -- so why do they appear to misunderstand so completely? And I'm sure that you can't become a successful journalist without years of hard work -- so why don't they bother to take a few minutes to look up original articles and read what they say?
The only answer that I can come up with is (c) -- they think that the real story would not be nearly as interesting to their readers (and perhaps to their editors?) as the crap that they make up is.
Or am I misunderstanding something here?
[Update -- on reflection I need to add two more possible answers:
d) gullible
e) math phobic
In some cases, scientists (or the PR agents of their institutions) may promote research in very different terms from those in which they describe it in their formal publications (which in any case may not exist at the time of the promotion). And maybe journalists tend to take them at their word, thus exhibiting the relevance of answer (d). That's clearly what happened in the infamous "modern electronic communication is worse for you than marijuana" case, Of course, a certain amount of (a), (b) and/or (c) is also needed on the part of the journalists and editors involved.
And also, I do realize that some people freeze up and stop thinking whenever they see a mathematical symbol or term (even something routine like r2 or p<.05). In this state of intellectual desperation, if forced by circumstance to pretend to understand what's going on, they clutch reflexively whatever simple-minded description comes most quickly to hand. This certainly happens sometimes on exams, and perhaps some journalists have a similar experience when assigned to a science story.
In any case, I blame myself. At least, I blame the profession of college teachers that I belong to. We seem to be turning out many students who can't understand relatively simple sorts of modern science, but lack the ethical gumption to admit it. Unfortunately, this ignorance and pretense combine with darker motives of sensationalism and pandering to stereotypes, creating a perfect storm of misinformation.]
The Spanish Inquisition, that's a tilde
Jon Stewart weighs in on the comma metaphor -- the relevant bit starts around 2:10 of this video clip:
(If you know how to convey a starttime parameter to flash videos from youtube, please let me know.)
[Daily Show tip from Steve Jones.]
Unkempt secrets
In the Oct. 5 edition of "Post Politics Hour," the Washington Post's online chat with the newspaper's political reporters, this week's host Peter Baker fielded the following reader comment:

David Bowie brought this to the attention of the American Dialect Society mailing list as a potential eggcorn, noting:
If you read this as phonological confusion between unkept and unkempt, and the meaning of unkempt as involving messiness (and this is certainly a messy situation for a number of people!), it works.
Though "unkempt secret" certainly works as an eggcorn, what if this
is actually a spellchecker artifact — namely, yet another
manifestation of the Cupertino
effect?
The custom dictionary for Microsoft Word (at least the 2002 version)
doesn't recognize unkept and
helpfully suggests unkempt:
Like other chats hosted by newspaper websites, the Post Politics Hour is a moderated affair, with a queue of emailed questions from readers filtered by the staff before appearing online. I would guess the moderators run each question quickly through a spellchecker, either initially or later on when the transcript of the chat appears. So it would be easy for a spellcheck goof like unkempt for unkept to creep in.
Google turns up several dozen additional unkempt secrets, and there are even more unkempt promises, or promises unkempt. Some examples appear to be intentionally playful substitutions, but many others are clearly slipups, either of the mental or computer-generated variety. In such cases it can be difficult to delineate what is poetic, what is eggcornish, and what is Cupertinoesque.
October 06, 2006
Armstrong's abbreviated article: Peter Shann Ford responds
 In response to our postings on his argument
that Neil Armstrong said "small step for *a* man", Peter Shann Ford
sent an email, which, with his permission, I include in full and
unedited form below the fold. (Editing the message would reduce
transparency, he points out.)
In response to our postings on his argument
that Neil Armstrong said "small step for *a* man", Peter Shann Ford
sent an email, which, with his permission, I include in full and
unedited form below the fold. (Editing the message would reduce
transparency, he points out.)In case you need to catch up, here are our postings so far on the issue, it being typical of linguists that the smaller the word, the more we have to say about it:
One small step backwards
One 75-millisecond step before a "man"
Armstrong's abbreviated article: the smoking gun?
Armstrong's abbreviated article: notes from the expert
First Korean on the moon!
What Neil Armstrong said
Email from Peter Shann Ford, October 6, 2006:
Dear Professor Beaver Professor Hansen was kind enough to forward me your links, and I've just read them. It's very good that someone with your specialized expertise has turned his attention to this. As you'll see in the paper, I've made full revelation and attribution regarding the GoldWave software used to analyze the NASA WAV file, full annotation of the UMD oral diagrams including its specific URL (www.wam.umd.edu) and full revelation of my own background - no more, no less. I'm certain your academic analyses would typically be empirical and free of anything but focus on the subject, and I look forward to discussing the sound file with you if you like. In fact as I've discussed with Jim Hansen, if more professional academics enter this amiable discussion with a proper level of skepticism and expertise, we'll more efficiently see if this holds up. I agree with your inference that whatever linguistic, physiological and signal analyses are brought to bear on this can only be productive in verifying or refuting the presence of the elusive "a". Of course you'll appreciate from Jim's excellent biography, "First Man" that authorship and intent regarding the sentence reside in the same person: Neil Armstrong's recollection to Jim was that he composed the sentence, "That's one small step for a man, one giant leap for mankind" and fully intended to say "for a man" when he stepped onto the surface, and given the precision with which he did everything else on his agenda that day, it's reasonable to believe him. Regarding the oral graphics: having studied English, Russian and Mandarin (I claim to speak none of them better than appallingly, even after more than a decade of voice coaching), I understand that there are certainly measurable differences in the way speakers of each language develop physiologically from their formative years to maturity: people with almost identical physical characteristics at birth - as you will know better than most - exhibit palatal development, from childhood to adulthood if their primary language is Mandarin, that is discernibly different from those whose primary language is Russian: similar distinctions may be suggested for primary speakers of German, French and Yankuntjatjara (a language spoken in the central desert of Australia). However the diagrams - I imagine you'll agree - are of a scale and style that cannot pretend to demonstrate these distinctions with any level of necessary subtlety and nuance. Rather they show the general relevant positions of the lips, tongue and mandible (and the colored arrows indicate the basic directions of lingual and labial movement) during the transition from the "r" in "for" to the "m" in "man" if the speaker intends to say "for man" or "for a man". With great respect to you, the fact that the original three diagrams were used on a Korean subject site on the UMD web, viz. Workstations at Maryland, do not seem from this perspective to be relevant; though I am more than willing to be logically persuaded by you if you disagree. The best part of these discussions would be for academics to bring their formidable knowledge and wisdom to bear on this in concert with any amateurs who believe - like so many amateurs through history who stumbled upon a truth that was later verified with greater erudition by superior intellects - that on July 20 1969, one man did what we all dreamed of doing, and like the iconic hero of Joseph Campbell's empirical journey, did it for us, took the risk for us, and in those now immortal words, spoke for us - completely, and correctly. My belief based on the sound file and supported by Neil Armstrong's own account to Prof. Hansen is that he did; my hope is that you are successful in helping to confirm, with far greater acuity and sagacity, that he did indeed say what he meant to that day. I look forward to your thoughts. Kind regards Peter |
Peter's thoughtful message is much appreciated. I don't know whether we linguists can live up to our billing as acute and sagacious. (I thought Saga City was just a town in Japan.) But resolving the issue of the missing "a" is the sort of teaser that gives linguists inexplicable pleasure, so it's worth a crack. If any phoneticians out there have some relevant insights, please let us know!
R-fulness on the march
In response to my post on non-portable water, John Wells sent me this version of a sneaky little creeping /r/ that he discovered on the quayside at St. Johns, Antigua, in the Leeward Islands. The native language there is English or English Creole. Imagine getting off a cruise ship to have a go at the local activities, then running into this:

Okay, in Antiguan creole, "pork" and "poke" are homophones, so maybe we should cut the casino some slack here.
And if you don't cotton to slots or roulette, you might try "crap action," which as Wells points out, elicits snickers from British tourists, as it would from Americans as well. But things are not what we think. Wells points out that the Antiguans, like other Creole speakers, are a bit uncertain about distinctions between singular and plural.
What Neil Armstrong said
OK, now that everyone is thoroughly sick of all the stuff we've already posted about Neil Armstrong's missing "a", here's a small pile of additional data, some discussion, and a tentative conclusion. I put this data and discussion together because I'm giving a tutorial on acoustic analysis for my introductory linguistics course this afternoon, and I figured that it might add some interest to the exercise if we took a look at the Armstrong case.
[I'm afraid that I use some technical terms like "third formant" and "schwa" without defining them -- if I have time, I'll come back later and make the explanation a bit more self-contained. Meanwhile, if you're really interested, you can refer to Rob Hagiwara's spectrogram-reading tutorial, and the SIL's IPA help page. The rest of you will probably want to read about Malaysian salad language, or the latest manifestation of the Cupertino effect, while you wait for one of us to figure out a linguistic angle on the Foley scandal. Or you can page down to the bottom line, if you want to see what I think about the missing moon-walk mouth movement.]
I searched PodZinger for {"for a man"} and {"for men"}, and picked the first ten examples of each that I found (eliminating mistranscriptions, cases where the audio quality was too poor, non-American accents, etc.). I used "for men" rather than "for mankind" because essentially all the examples of the latter phrase came from discussions of Armstrong's pronunciation, and this seemed too self-referential.
The pronunciations of "for a" in this set fell into three classes:
Type 1: Syllabic [ɹ] -- which could also be viewed as a rhotic or r-colored schwa -- followed by a non-rhotic reduced vowel, of the type that is usually transcribed with the symbol schwa (an upside-down letter 'e'). Note that the third formant (which is low in American English [ɹ]) is already low at the release of the [f], and then rises shortly before the [m]-closure, since the schwa is non-rhotic or at least less r-colored. Examples (1), (2), (6), (7), (8), (10) are of this type.
Type 2: A low back vowel, roughly the quality of "open o" [ɔ], followed by a transition into a typical American [ɹ] (the tongue-blade approximant which is our way of saying /r/), followed by a transition into a schwa. Note that in this case, F3 start out high, moves low for the [ɹ], and then rises again (at least a little bit) for the schwa. Examples (3), (4), (9) are of this type.
Type 3: A rhotic schwa (as in type (1)) followed by a region of glottalization (which emphasizes the existence of the article "a") followed by a less rhotic schwa. Example (5) is of this type.
(In the table below, the audio for each "for a man" segment is linked to the spectrogram, while link to a longer audio clip is available from the sentential context given underneath it.)
| (1) |  |
(2) |  |
|
| "I think it's the height of arrogance for a man..."[audio] | "Her brother is a man who is house-sitting for a man who plays a man house-sitting on television." [audio] | |||
| (3) |  |
(4) |  |
|
| "... especially for a man who was known to be gay." [audio] | "that was the bond set for a man charged with murdering two people" [audio] | |||
| (5) |  |
(6) |  |
|
| "...who was posing as a woman on line looking for a man to fulfill her rape fantasy..." [audio] | "... it's thirty six years in prison for a man who shot and wounded singer-songwriter Mark Coomb last year" [audio] | |||
| (7) |  |
(8) |  |
|
| "...he's surprising gentle for a man who grew up pushing a giant wheel..." [audio] | "...want the court to reinstate the death penalty for a man convicted of killing a nineteen-year-old woman..." [audio] | |||
| (9) |  |
(10) |  |
|
| "...searching for a man accused of stabbing a homeowner while trying to steal a bike." [audio] | "The search continues in central Florida for a man suspected of shooting two sheriff's deputies" [audio] |
The pronunciations of "for" in "for men" fell into two classes, basically corresponding to types (1) and (2) of the "for a" pronuncations discussed above:
Type 1: the vowel of "for" is just a syllabic /r/ (or rhotic schwa, or what have you), pretty much a monophthong, with F3 low from the start. In the table below, examples (1), (3), (5), (7), (8), (9) and (10) are of this type.
Type 2: the vowe of "for" starts out much less rhotic, with F3 higher, and then transitions into an [ɹ] region with low F3. Example (2) and (4) below are of this type, with example (6) tending a bit in this direction.
| (1) |  |
(2) |  |
|
| "...stood for 'men with zippers' ..." [audio] | "... that the office of elder is restricted for men..." [audio] |
|||
| (3) |  |
(4) |  |
|
| "... some sort of cosmetic treatment for men." [audio] | "...the difference between writing for men or for women..." [audio] |
|||
| (5) |  |
(6) |  |
|
| "It was a figure of six percent for women and five and a half percent for men..." [audio] | "... you hope it's gonna be the same for men" [audio] | |||
| (7) |  |
(8) |  |
|
| "...showed that for men, two thirds of men believed..." [audio] | "...pleasure toys and beer-fetchers for men." [audio] | |||
| (9) |  |
(10) |  |
|
| "...brought to you by autotrader.com and Milton's the Store for Men." [audio] | "..was also the accusation that the highest level of memberships were reserved for men..." [audio] |
In the case of the "for men" examples, the start of the [m] is often rhoticized as well.
OK, now what about Neil Armstrong's phrase?
Here are the two plausible hypotheses about its analysis.
Hyothesis A: he said "for man", as in the Type (1) pronunciation of the "for men" examples above. This is how most people have always heard it.

Hypothesis B: he said "for a man", as in the Type (1) pronuncation of the "for a man" examples above. This is Peter Shann Ford's hypothesis, as far as I can understand it. I've tried to transfer his transcription into IPA and onto the spectrographic representation below:

The acoustic evidence seems to be against Ford's theory. In particular, there's no indication of the third formant rising at all before the closure of the [m].
And the timing pattern is closer to what we'd expect for the "for man" hypothesis, especially in phrase-final position.
In particular, let's take a look at the stretch from the release of the [f] to the closure of the [m]. In the 10 examples of "for a man", the durations of this region (in milliseconds) were: {125, 137, 343, 245, 197, 155, 142, 116, 161, 124}. The mean of these is 175 msec., SD 71. In the ten examples of "for men", the corresponding regions had the durations {62, 148, 61, 125, 128, 116, 70, 72, 64, 80} milliseconds, mean 93, SD 33.
The duration of this region in Neil Armstrong's pronunciation of "for X man"? 97 milliseconds. A quick calculation suggests that this duration is about four times likelier for "for man" than for "for a man". And if we focused only on phrase-final examples, I think that the preference might be stronger.
My conclusion: I have no doubt that Neil Armstrong meant to say "for a man". And perhaps he produced an unusually rapid performance of the "for a" part, with a brief syllabic /r/ followed by an even briefer and very weakly de-rhoticized schwa. But it seems more likely that what he actually said was just what everyone has always heard, namely "for man".
I would change my mind if it turns out that Armstong often fully assimilates schwa after /r/, or if this is a characteristic of the speech of people in the part of the midwest that he comes from. If anyone knows of any (earthly) recordings of Neil Armstrong's speeches or interviews for me to look at, please let me know.
[Update -- Kevin Marks writes:
I think this is statistically flawed, as Podzinger is using speech recognition software to transcribe the text. Accordingly, searching for 'for a man' you are only going to find examples where the distinction is clear-cut enough for the speech recognition code to have already made this determination.
Thus you have a strong sample bias here.
Fair enough. I also have a rather small sample size. More data from a better sampling method is invited. When I have time, I'll try some other approaches, if someone else doesn't do it first.]
October 05, 2006
Malaysia cracks down on "salad language"
 The Associated
Press reports that Malaysia's Minister of Culture, Arts and Heritage, Rais
Yatim, has announced a crackdown on the misuse of the national language
of Malay. Anyone displaying Malay signage that is deemed incorrect
by government authorities can be fined up to 1,000 ringgit ($271) after
a first warning. The
Star, The
New Straits Times, and the national news agency Bernama
provide more detail on the draconian measures, which will be enforced
by Dewan
Bahasa dan Pustaka (DBP), the agency charged with formulating
Malaysia's language policies.
The Associated
Press reports that Malaysia's Minister of Culture, Arts and Heritage, Rais
Yatim, has announced a crackdown on the misuse of the national language
of Malay. Anyone displaying Malay signage that is deemed incorrect
by government authorities can be fined up to 1,000 ringgit ($271) after
a first warning. The
Star, The
New Straits Times, and the national news agency Bernama
provide more detail on the draconian measures, which will be enforced
by Dewan
Bahasa dan Pustaka (DBP), the agency charged with formulating
Malaysia's language policies.
The particular offense that will be penalized is the commingling of Malay and English, which the AP notes is sometimes referred to as "Manglish" (a blend of Malay and English which implicitly suggests that any such mixture is a mangled version of one language or the other). Locally, such Malay-English mingling is usually referred to as bahasa rojak, or "salad language" (rojak being a spicy mix of fruits and vegetables popular in Malaysia). The "salad" idiom is actually used throughout Southeast Asia to disparage code-switching and other linguistic mixtures. A popular term for bilingual Javanese-Indonesian usage, for instance, is bahasa gado-gado, with gado-gado denoting another type of vegetable salad. (See the chapter on "language salad" in Joseph Errington's study of Javanese-Indonesian linguistic interaction, Shifting Languages.)
In the case of Malaysia, the attempt to ban salad language is part of a concerted attempt to bolster Malay nationalist integrity through "purification" of the national language. English, as in so many other parts of the world, is seen as the gravest threat to local linguistic purity, and in former British colonies like Malaysia that perceived threat is interlaced with fears of English as a neo-colonizing force deleterious to an independent nation. In Malaysia and elsewhere, however, there is a great tension between wariness of English linguistic imperialism and the recognition that English proficiency is a key for success in the globalized economy, particularly in technological fields. (The same tension has cropped up recently in the Indian state of Karnataka, including the high-tech hub of Bangalore, where a controversial ban on English-language classes has been enforced to support instruction in the local language of Kannada.)
Bloggers in Malaysia have, not surprisingly, reacted with a great deal of skepticism to the new measure. Here are snippets from two representative blog posts:
It seems as if our government does not really know what it wants to do and is staggering like a blind man without a cane in an unfamiliar place. On one side it laments the poor command of English especially among graduates, most of them Malays and on the other it continues to play the field with concocted threats to the national language and imagined attempts to downgrade it; a ploy that works well with the paranoid, the insecure and the Malay language fanatic. (The Malaysian)
[S]ign and billboard makers the nation over will probably rejoice at this news. What better way to rejuvenate the sign industry than to legislate language? Not so very long ago, Indian sign-makers had a big windfall when Bombay, Calcutta and Madras changed their names to Mumbai, Kolkata and Chennai respectively.
Let's look at an obvious example - all the 7-Eleven stores nationwide (around 700 outlets, and growing) would have to change their signage to 7-Sebelas. Think of how lucrative that signage contract is going to be. (myAsylum)
Others have questioned the proposed policy that commonly appearing English words and phrases should be replaced by new Malay nativizations, such as replacing Touch 'N' Go with Sentuh Dan Pergi, or Boulevard with Lebuh Perdana. Still others have mocked the idea that government authorities might change the name of MyKad, the Malaysian Government Multipurpose Card (a smart identity card that includes biometric information). MyKad is an interesting bit of bilingual play, combining kad (the Malay nativization of English card, representing a pronunciation spelling of non-rhotic British English) with my, which functions both as a first-person possessive pronoun and as a techie designation for Malaysia (it's the ISO country code and the top-level domain name for Malaysian websites). Despite its loanword status, kad is presumably considered a legitimate Malay word by the DBP, because it has been nativized since colonial times. But the my element is now suspect because of its Englishness, despite its subtle resonance with Malaysia's high-tech, Internet-savvy image. Such clever language play apparently has no place in Malaysia's new salad-free linguistic future.
Eggcorns in the Grauniad
We're happy to report that the term eggcorn — a Language-Loggian coinage to describe orthographic or phonological reshapings that seem to make semantic sense — continues to worm its way into the public consciousness, thanks to some enlightened souls in the media. The latest journalistic report on eggcornology appears in the pages of the Guardian, a paper that knows a thing or two about misshapen orthography. Guardian reader David Kenning alerted the editors to the study of eggcorns in connection with a dispute over plashy fens (an expression appearing in John Milton's History of England) versus splashy fens (an eggcornish version appearing in some editions of Evelyn Waugh's Scoop). That led Guardian reporter Emine Saner to devote a whole article to eggcorns, complete with the Language Log backstory and a healthy sampling of citations culled from Chris Waigl's Eggcorn Database (mostly compiled by Chris, Arnold Zwicky, and myself [*]).
([*] As for this non-reflexive usage of myself, previously covered here, see Nathan Bierma's recent column in the Chicago Tribune.)
Microbial Grice
In response to my call for "a description of bacterial fermentation in cheese that's as appetizing as Mary Falk's prose poem about the molds", Rosie Redfield tunes up with
Yeast transform dreary starches and sugars into intoxicants and fragrances.
but concedes that she'll "need to work on the bacterial perspective".
Rosie also sent along a paper about bacterial quorum sensing (Rosemary Redfield, "Is quorum sensing a side effect of diffusion sensing?", Trends in Microbiology 10(8), August 2002), which seems to me to raise some interesting questions about what we mean by "communication".
There's a familiar issue with intention in human communication, as in Grice's analysis of "speaker's meaning":
A (an agent) meant something ... by x (an utterance or gesture) if and only if A intended the utterance or gesture x to produce some effect in an audience by means of the recognition of this intention.
This seems to make sense of much of our reasoning about communication. For example, if someone says something hurtful or insulting, we typically try to figure out "what they meant by it" in terms of an analysis of their intentions. Did they understand that their remark would be taken as an insult, or did they think it was really neutral or even a compliment? Did they perhaps intend to refer to something completely different from what we thought they were talking about? Our evaluation and response depends on the answers.
But even for humans, it's often obscure who had which intentions when, and the application of this kind of reasoning to non-human animals is even murkier, as all of the debates about animals' "theory of mind" show. From a certain common-sense point of view, it may seem preposterous to imagine that a bacterium could have a communication-intention of Grice's kind. However, Daniel Dennett and other smart people think that thermostats and alarm clocks have beliefs and intentions, and bacteria are much more complex machines than that.
What's interesting about Rosie Redfield's paper, in this context, is that it deals in detail with a parallel sort of reasoning about certain acts performed by bacteria:
Many bacteria appear to communicate by releasing and sensing autoinducer molecules, which are believed to function primarily as sensors of population density.However, this quorum-sensing hypothesis rests on very weak foundations, as neither the need for group action nor the selective conditions required for its evolution have been demonstrated. Here, I argue for a more direct function of autoinducer secretion and response – the ability to determine whether secreted molecules rapidly move away from the cell. This diffusion sensing allows cells to regulate secretion of degradative enzymes and other effectors to minimize losses owing to extracellular diffusion and mixing.
As Rosie explained her theory in email to me, "the whole process is more like radar than radio, in that they're emitting 'signals' to sense the properties of their environment rather than to change the behaviour of recipients".
Note that everyone agrees about what the bacteria do -- they emit certain molecules, and also sense the local concentration of those molecules and modify their behavior as a result. The argument, in some sense, is about what the bacteria mean. At least, it's about the purpose of what they're doing -- is it their intention to give a shout-out to their peeps? or are they just trying to figure out what the local diffusion rates are like? And again, I think that everyone agrees that what they do has both of those effects, at least in principle; but there's still a diagreement about the purpose of the behavior.
I suppose that "purpose" is a way of talking about evolutionary forces here, rather than a claim about any individual bacterium's state of mind. Though perhaps Dan Dennett would say that bacteria do have purposes as well as beliefs and intentions, I'm not sure.
[On a completely different topic -- When Rosie wrote that "Yeast transform dreary starches and sugars into intoxicants and fragrances", was "yeast" taking the game-animal zero plural? Historically, "yeast" was a mass noun, referring to the froth or sediment that forms during fermentation of certain fluids. At some point in the last couple of centuries, people realized that these substances were composed of single-celled fungi, who thus came to be called "yeasts" -- but the OED's earliest citation for the plural is from 1906:
1906 G. MASSEE Text-bk. Fungi III. 275 Symbiotic relationship between yeasts and bacteria is not uncommon.
Whatever the explanation, Rosie's usage ("yeast" with a plural verb) seems to be a common one:
Yeast ferment glucose and thus depend heavily on the glycolytic pathway.
Ale yeast ferment at warmer temperatures than will lager yeast.
Yeast grow in colonies that are generally isogenic, so survival of the genes of a single colony is guaranteed even if only a few organisms survive.
This system can compensate the absence of pyruvate dehydrogenase when yeast grow aerobically on glucose or lactate...
However, "yeast" with singular agreement seems to be roughly as common:
... confirmation of a theory originally proposed by Hopkins that yeast ferments the furanose form of fructose.
When yeast ferments glucose in the presence of potassium chloride K+ is taken up by the cells and an equivalent amount of H+ is excreted.
When yeast grows, it makes carbon dioxide and alcohol.
Yeast grows best in a warm, moist environment.
And examples with plural "yeasts" generally have the "types of X" interpretation typical of mass-noun plurals:
In contrast, tel1 mutant yeasts grow normally at 37°C.
...about 30% of all yeasts grow either on methanol (about 10%) or on hydrocarbons (about 20%)...
However, while many yeasts ferment hexoses, they are usually considered to be unable to ferment aldopentoses.
This is probably covered at length somewhere in CGEL, but I've got a meeting to go to. ]
October 04, 2006
Parts of a fish head: let me count the ways
Jan Freeman supplies a quote from an article in the Scottish Sunday Herald about TV quizmaster Magnus Magnusson, who is claimed to have a "genuine, 100% authentic, forgery-free Icelandic heritage", and to have grown up speaking Icelandic in Scotland:
He has a great love of the Icelandic language — there are, he says, 140 words for parts of a cod head in Icelandic, most of which are untranslatable.
How convenient that most of them are untranslatable so that there is no way we can confirm that they do indeed unambiguously denote parts of the head of the relevant fish species, or indeed, that they have meanings at all. How strange that a man should have a "great love" for a language simply on grounds of the size of its fish-head-part vocabulary. Does the head of a fish even have 140 parts, clearly recognizable without microichthyological analysis, that might need names? Maybe so. Who knows. But most of the public will probably find Magnusson's observation fascinating whether there are such fishy head parts or not. I hope they will also be fascinated to learn that I speak a language with at least 140 words — most of them unprintable — for gullible dimwits who propagate exotic but unchecked lexicographical traveller's tales.
[Update added October 5] But let me be serious about this topic for a moment or two. Gunnar Hrafn Hrafnbjargarson (he's an Icelandic researcher at the Institute for Linguistics at the University of Tromsö in Norway, and he admits that he found the above remarks "a bit annoying, to put it mildly"), has informed me that some Icelandic dictionaries do indeed have diagrams of the head of a cod, and list words denoting various parts. It is interesting, though, that these words all seem to be perfectly ordinary Icelandic words with meanings like "hen", "cow", "child", "bell", "comb", "shield", and so on. What is going on is that they are used metaphorically in this context to make a technical-term inventory of anatomical names for particular cod head parts: a certain muscle on the inside of the skull behind the ear is called the hen; the muscle that goes from above the eye towards the back of the head is called the child; there is a bone in the middle of the head below the eye that is called the shield; there is a small muscle by the eye that is called the bell; there is a muscle in the lower part of the upper jaw that is called the apron; and so on.
There do not seem to be as many as 140 of these words; but there may be as many as 100. More importantly, though, all the words are readily translatable into English. Almost certainly, what Magnusson meant by calling them "untranslatable" was that they did not have exactly synonymous single-lexeme counterparts in English. But that is really a very different matter.
What annoys me about lexicographical traveller's tales of the "many-words-for-X" and "no-word-for-Y" varieties (and there have been so many more, about the Eskimos, the Irish, and so on) is seeing fanciful (and often frankly incredible) claims of exoticism for some alien culture being supported through fraud and inaccuracy and presented to an audience that has no prospect of being able to check up on them. Natural languages are quite interesting enough. We don't need to make stuff up.
First Korean on the moon!

Phonetician/Phonologist Lisa Davidson, of NYU, sent me some comments on the Armstrong story. (For previous coverage on Peter Shann Ford's reported discovery of the missing "a" in "one small step for (a) man", see: One small step backwards; One 75-millisecond step before a "man"; Armstrong's abbreviated article: the smoking gun?; and Armstrong's abbreviated article: notes from the expert.) Lisa makes some sophisticated points. But she also observes, amusingly, that Shann Ford illustrated his explanation of how Armstrong would have produced the /r/ of "for" with an image (shown right) of a Korean alveolar. (Alveolar = consonant produced with constriction between tongue and roof of mouth just about where you see on the pic.) As you can see if you follow the link that Shann Ford himself provided on the picture, the image is adapted from a guide to the Korean alphabet. And look: the tongue is actually touching the roof of the mouth (specifically, the alveolar ridge). Now, /r/ is an approximant, meaning the tongue doesn't completely close off the air stream, so you can tell this isn't an /r/ at all, and, as Lisa points out, Korean doesn't even have an English-like alveolar approximant. (Which takes my mind back a couple weeks... what do Korean pirates say?) So what you see is two pictures of a Korean guy saying e.g. /d/, /t/ or /n/, and then one of the same guy saying e.g. /m/, /p/, or /b/. And here is what all this tells you about the first words on the moon: zip. Below is Lisa's message, which casts yet more doubt on Shann Ford's conclusions, and also includes an invitation for Neil Armstrong: let him know about it if you see him!
Lisa writes:
Although it's perhaps a minor part of this whole issue, I wanted to weigh in on Ford's articulatory description of how /r/ is produced. Since ultrasound and MRI are very well suited for looking at /r/, many of us have done a number of studies on the shapes corresponding to /r/. Extensive work has been done by Mark Tiede at MIT and Suzanne Boyce at the University of Cincinnati, but also Jeff Mielke, Adam Baker and Diana Archangeli at Arizona, Bryan Gick at UBC, and I'm working on a project on /r/ acquisition by children. While the retroflex shape shown on Ford's webpage is certainly one possible configuration for American English /r/ production, the fact is that there are at least 4 other tongue shapes ranging from a big bunch to a boring, undifferentiated lump in the mouth, that all correspond to /r/. I might also point out that the picture on Ford's website (http://www.controlbionics.com/Electronic%20Evidence%20and%20Physiological%20Reasoning.htm) is from a description of Korean alveolars, and Korean does not have the American English approximant /r/. In any case, given the variety possible, we have no idea what shape Armstrong produces (unless he's interested in coming in to one of our labs--I'd be happy to check it out for him!). It seemed from Ford's description that he considers the retroflex shape essential to the production of this supposed schwa, but in reality, we have no idea what Armstrong did. On the other hand, I'm not sure that his actual tongue shape is important for determining the presence or absence of schwa, so regardless of what Armstrong's canonical /r/ looks like, I think Ford's articulatory argument for the presence of schwa is incorrect. |
Speaking of missing words in American history

While David was posting about Armstrong night before last (see yesterday's follow-ups here, here, and here), my wife Karen and I were watching the rebroadcast of (the first episode of) Eyes on the Prize on our local PBS station. There's a segment about the horrible, horrifying, and heartbreaking story of the 1955 murder of Emmett Till in Mississippi, and the subsequent trial in which the all-white-male jury acquitted Till's killers, J.W. Milam and Roy Bryant. (A few months later, Milam and Bryant admitted their guilt to a reporter for $4000.)
Till's very courageous great-uncle, Mose Wright (pictured), was a witness on the stand. He was asked to identify the man who came to his door with a gun to take Till away on the night he disappeared. Wright stood up, pointed to Milam (or to both Milam and Bryant; reports are mixed), and said: "Dar he" -- helpfully translated as "there he is".
Now I'm no expert on African American Vernacular English (AAVE), but as I understood it -- that is, until I did just a little more research on the question yesterday -- the absence of a form of the copular verb be in AAVE (in sentences where a form of the copula would be expected in Standard English, SE) has the same distribution as contraction of the copula ('m, 's, 're) in SE. Contraction of the copula is ungrammatical phrase-finally in SE -- *There he's, where the '*' indicates ungrammaticality -- so (I reasoned) absence of the copula must be ungrammatical in AAVE -- *There (dar) he. (My understanding of this is based on Bill Labov's classic 1969 article in Language, "Contraction, Deletion, and Inherent Variability of the English Copula" -- and while you're at it, you may as well have a look at Ralph W. Fasold's article in the same issue, "Tense and the Form be in Black English".)
So I wondered, briefly: did Mose Wright say a very reduced or quiet "is" that the people present just didn't catch? There is lots of footage from the trial but apparently (and if so, unfortunately) no recording of Mose Wright saying these words, so we can't try the kind of audio analysis that David, Mark, or Peter did for the moon landing.
In this half-minute audio clip from Eyes on the Prize (starting at minute 11:43 of the relevant segment), the story of Mose Wright saying these words is told by James L. Hicks, a reporter for the Cleveland Call and Post who was at the trial (see his reports of the trial here). Consider what Hicks says:
[Mose Wright] stood up and there was a tension in the court room. And he says -- in his broken language -- "Dar he."
The "broken language" comment might indicate recognition that the missing be was unexpected even to Hicks, who either speaks or is familiar with prototypical AAVE speech. (Incidentally, the second voice in the clip is that of the documentary's narrator and chairman of the NAACP, Julian Bond.) This suggestive piece of evidence made me think that Mose Wright indeed did not pronounce the copula. This in turn made me doubt (my read of) Labov's article, however: maybe absence of the copula is grammatical in some places where contraction of the copula is not, at least for some AAVE speakers. I guess I just couldn't believe that someone could make a grammatical mistake like this one, no matter how poor or uneducated.
A little bit of research on the matter revealed that I may be right. Emily M. Bender completed her PhD thesis six years ago at Stanford (Dr. Bender is now at the University of Washington). The title of Bender's thesis is Syntactic variation and linguistic competence: the case of AAVE copula absence, in which Bender provides several types of counterexamples to Labov's earlier description of the relevant AAVE facts. One type of counterexample Bender found was the possibility of copular absence in AAVE in cases of what's called "complement extraction", where contraction is impossible in SE. The following examples are from p. 90 of Bender's thesis:
- How old you think his baby? (AAVE) / *How old do you think his baby's? (SE)
- I don't know how old his baby. (AAVE) / *I don't know how old his baby's. (SE)
(Consistent with the "broken English" remark is the fact that Bender found significant variation on the acceptability of examples like these; see her footnote 17 on p. 90.)
"Complement extraction" refers to the idea that sentences like those above involve some kind of relationship -- the exact kind depends on the theory -- between the position of a certain phrase (in these examples, the phrase "how old") and a position elsewhere in the sentence. For example, in the SE question How old do you think his baby is?, the position of the underlined phrase how old is thought to be related to an empty position right after is, based in part on the position of the underlined phrase in a prototypical answer to the question, such as I think his baby is two years old.
It's not just direct questions that involve complement extraction, as shown by the I don't know how old his baby (is) example above. Here's where we get to the point: a sentence like There he is also arguably involves complement extraction, in part given the alternative form He is there. It's not the case that all examples of complement extraction allow copula absence -- Labov provided examples where it's not allowed, and Bender discusses the technical differences between Labov's examples and her counterexamples -- but it's at least not completely unexpected in Dar he.
[ Update -- I wrote to Emily Bender to ask her about this example, and here's what she had to say:
I think you're right that "Dar he" would get a similar analysis to "How old your baby?", where "Dar" is a preposed complement of "he". This suggests it ought to be possible to [have] it long distance: "Dar they said he". [...]
[T]here's a comment on p.125 [of the thesis] leaving an account of which complements can and cannot be extracted [when the copula is absent] to future work. In the past 5 years, however, I've been working on very different things and have not come back to this problem. There's a footnote on that same page with some further perplexing data.
Thanks to Emily for this response, and for writing such an interesting thesis. (And I can certainly sympathize with not having had time to get back to problems left to future work in a thesis ...) -- end update ]
[ Comments? ]
Further annals of taboo avoidance
The New York Times continues to find ways to not print taboo words (for our most recent report on the phenomenon, look here). Now, in the Magazine of 10/1/06, Matt Bai struggles with Howard Dean's language ("Is Howard Dean willing to destroy the Democratic Party in order to save it?", p. 56):
"Bull," Dean snapped, using a slightly more elongated version of the term.
Well, THAT keeps that nasty word at arm's length, using the fancy "slightly more elongated" and the technical "term". Meanwhile, the stuff inside quotation marks isn't an actual quotation, but rather a stand-in for one, using an avoidance substitute. (" 'Fudge,' bellowed the coach, using a stronger version of the word.")
zwicky at-sign csli period stanford period edu
Terroir alert
 In the cheese business, the terroirists are winning. In Britain, they've gotten a phonetician to vouch for the local dialects of cows. Here in the U.S., they're focusing on local molds and bacteria. Well, they try not to mention the bacteria -- they use the term microflora, with an occasional tasteful presentation of the word "mold" as if it were a species of flower.
In the cheese business, the terroirists are winning. In Britain, they've gotten a phonetician to vouch for the local dialects of cows. Here in the U.S., they're focusing on local molds and bacteria. Well, they try not to mention the bacteria -- they use the term microflora, with an occasional tasteful presentation of the word "mold" as if it were a species of flower.
In today's NYT ("The Earth is the Finishing Touch"), the reporter, Marian Burros, lists all the types of wee beasties involved:
As cheesemaking and the appreciation of good cheese have matured in the United States in the past few years, American cheesemakers have begun to better understand the place of microflora — bacteria, yeast, molds — in the process of aging cheese. In these new caves and cellars, cheeses are exposed to an array of the tiny organisms local to the area.
But the word "bacteria" seems to be avoided in the quotes from cheese people:
By going underground, Mary and David Falk have stayed on top of most artisanal cheesemakers in this country.
For 10 years, at their Love Tree Farmstead in Grantsburg, Wis., they have been aging cheeses in caves dug into a hillside, their concrete walls painted with pictographs. The Falks say it’s the only way to produce deeply flavored, nuanced, natural-rind tommes and wheels like those of European cheesemakers.
“We believe in fresh-air aging, pollens, molds, humidity,” Ms. Falk said. “And we’ve positioned our cave so that it is surrounded by a wildlife refuge. It’s really a head trip to see semis pull up in the woods to get the cheese. It’s like from ‘The Twilight Zone.’ We wanted something that worked on the natural rhythm of the area. We took the microflora from what was there; we get humidity from the springs.”
Mary Falk waxes lyrical about the mold:
Ms. Falk describes the mold that forms on cheese as “a miniature flower garden, with the flowers sucking air into the cheese and pulling out the gas, and every little mold having its own little flavor profile.”
Jeff Roberts, author of the forthcoming Atlas of American Artisan Cheese, sticks with the formal and neutral "microflora", adding the all-purpose positive word "community" to make it clear that no disrespect is intended:
“Caves are not only great in terms of maintaining temperature and humidity but they also reflect the unique microflora communities,” Mr. Roberts said. “The microflora interacts with cheese; the cheese obtains a certain level of quality and so does the microflora. The cheese evolves over time and you can’t regulate it. It has a powerful connection to place.”
The complexity of the bacterial contribution to this process (whether in a warehouse or in a cave) is indicated by this abstract (M. Morea, F. Baruzzi and P.S. Cocconcelli, "Molecular and physiological characterization of dominant bacterial populations in traditional Mozzarella cheese processing", Journal of Applied Microbiology 87 574, 1999:
The development of the dominant bacterial populations during traditional Mozzarella cheese production was investigated using physiological analyses and molecular techniques for strain typing and taxonomic identification. Analysis of RAPD fingerprints revealed that the dominant bacterial community was composed of 25 different biotypes, and the sequence analysis of 16S rDNA demonstrated that the isolated strains belonged to Leuconostoc mesenteroides subsp. mesenteroides, Leuc. lactis, Streptococcus thermophilus, Strep. bovis, Strep. uberis, Lactococcus lactis subsp. lactis, L. garviae, Carnobacterium divergens, C. piscicola, Aerococcus viridans, Staphylococcus carnosus, Staph. epidermidis, Enterococcus faecalis, Ent. sulphureus and Enterococcus spp. The bacterial populations were characterized for their physiological properties. Two strains, belonging to Strep. thermophilus and L. lactis subsp. lactis, were the most acidifying; the L. lactis subsp. lactis strain was also proteolytic and eight strains were positive to citrate fermentation.
You can learn a lot more about this by asking Google Scholar about {cheese fermentation} or {cheese bacteria}.
Rhetorical exercise for the day: write a description of bacterial fermentation in cheese that's as appetizing as Mary Falk's prose poem about the molds ("a miniature flower garden, with the flowers sucking air into the cheese and pulling out the gas, and every little mold having its own little flavor profile").
Memo to the artisanal cheese industry: if you need expert linguistic advice, for example about the analysis of bacterial discourse, I'm available to consult. I try to set out an interesting sampling of artisanal cheeses at Tuesday night study breaks in the college house at Penn where I live, and I could use some help with the budget.
October 03, 2006
Armstrong's abbreviated article: notes from the expert
 In response to our flurry
of
postings,
Neil Armstrong's biographer, James Hansen, sent some comments that,
with his permission, I include below. That's him over there on the
right hand side. As you'll see from his messages, while he scolds me
lightly for historical carelessness, he's generally encouraging of the
linguist's enterprise. He also throws some light on the background both
of Armstrong's quote and Shann Ford's analysis, and even suggests some
rather natural lines of linguistic analysis.
In response to our flurry
of
postings,
Neil Armstrong's biographer, James Hansen, sent some comments that,
with his permission, I include below. That's him over there on the
right hand side. As you'll see from his messages, while he scolds me
lightly for historical carelessness, he's generally encouraging of the
linguist's enterprise. He also throws some light on the background both
of Armstrong's quote and Shann Ford's analysis, and even suggests some
rather natural lines of linguistic analysis.Here's the first message:
|
look at Peter's analysis. Actually, Peter told me and others he would welcome it. It will also be interesting to see what NASA's experts conclude. Of course, Peter is not arguing that a "canonical 'a'" was expressed. But he clearly regards it as a sound coming from Neil and exactly the place where Neil intended to put the vowel. Peter definitely believes it is not static, a question that we certainly asked him. His comparison of the "for [a] man" and "for mankind" is obviously very different from your own. It's amazing how many people have become fascinated with this. Do you see any plusses for your field? Jim |
Jim's next message followed my most recent post:
Very interesting, David. You make an interesting point about your community of practitioners at the end. I do have a couple of constructive criticisms, if I may. If you publish more on this, and I hope you do, try to make the historical context as accurate as possible. For example, you write, "He spent several hours rehearsing!" In fact, he didn't. Neil only composed the phrase in his head sometime after the landing and going through all the emergency liftoff procedures, etc. He had no more than two hours from the time he thought it up to the time he uttered it. Peter is actually very well versed in the Apollo 11 history, aside from reading my book. One of the reasons that Peter was so convincing to me, Neil, NASM, and NASA was that he knew the details of the Apollo 11 mission very well. They can be very important to the analysis. Also, you should take into consideration, even more so than Peter does, that Neil comes from northwestern Ohio. I come from northeastern Indiana, only 60 miles from where Neil grew up. There is a regional accent to consider. "For a" is often expressed is 'foruh," virtually as one syllable. Personally, that is my theory. At our meeting in National Air and Space, I suggested to Peter that someone should look for ALL of the expressions of the "a" word throughout the voice communication recordings. Surely if Neil "swallowed" the "a" in some way for his historic expression, he also did it many other times. Right? Anyway, I appreciate your generous comment about Peter's democratic approach to trying to resolve this mystery. He has spent the last 5-6 years looking at voice wave files as it relates to his Neuro-Server technology. So, though he does not have all the insights and techniques of your very important academic discipline, he does have some very interesting and useful background experience. Best, Jim |
The dialect issue is a natural one to consider, though my impression is that one syllable "for a," perhaps becoming "fruh," is more widespread than Jim suggests. Casually, this doesn't seem to be what Armstrong produced, though it merits further study. And Jim's suggestion that someone take a look at all the "a" words in the voice communication recordings, or at least a controlled subset of them, is spot on. Any linguists out there who are up for it?
Armstrong's abbreviated article: the smoking gun?
Following our comments earlier on the Small Step saga, I learned from historian Prof. James Hansen, author of the standard biography of Neil Armstrong, that Peter Shann Ford's paper is publicly available. Shann Ford has on the website of his company in html and pdf form. Wonderful! I wish everyone was so open and diligent!
 It turns out that Shann Ford's analysis is
based solely on the
waveform, not on spectrographic analysis. Neither has he performed any
special clean up of static or signal processing: he looked at the same
thing as Mark and I did, but minus the spectrograms. His main evidence
is the figure on the left which he say illustrates "a magnification of the sound wave
between the minimum point of decay
of "for" at 0.136 seconds and the point of onset of"man" at 0.171
seconds. This 0.035 second sound wave is the elusive "a" - thirty-five
thousandths of a second in duration."
It turns out that Shann Ford's analysis is
based solely on the
waveform, not on spectrographic analysis. Neither has he performed any
special clean up of static or signal processing: he looked at the same
thing as Mark and I did, but minus the spectrograms. His main evidence
is the figure on the left which he say illustrates "a magnification of the sound wave
between the minimum point of decay
of "for" at 0.136 seconds and the point of onset of"man" at 0.171
seconds. This 0.035 second sound wave is the elusive "a" - thirty-five
thousandths of a second in duration." Shann Ford goes on to say: "This 0.035 second sound wave is consistent with the sound made in the lingual (tongue) buccal (mouth) labial (lips) transition from the terminal consonant "r" in "for" to a vowel "a" to the introductory "m" in "man". It is not consistent with the sound made in the lingual-buccal-labial transition from the terminal "r" in "for" directly to the introductory "m" in "man", as in "for man"."
Further, we learn that "In the transition from "for" to "a" to "man" the tongue is curled into the terminal "r" of "for" and uncurls for the "a" before the lips close for "m" in "man" creating a pressure wave consistent with the 0.035 second sound wave [in the figure].
In the transition from "for" to "man" (as in the statement "for man") the lips close for the "m" of "man" while the tongue is still curled for the "r" of "for" precluding the creating of the pressure wave consistent with the sound wave of "a"."
None of this is unreasonable. But it's not terribly conclusive either. What Shann Ford claims to have seen is not a smoking gun, but a waft of air as Armstrong reached for the holster. Whether that is indeed what Shann Ford has observed, is not clear, and we have no evidence at all that Armstrong ever fired a bullet. At best, given the timing issues I alluded to in my last post, he probably fired a blank.
Now, as I have to switch to commuter mode, I'll limit myself to a few questions:
- Is .35 ms a reasonable length of time for a "sound wave" generated by uncurling of an [r]?
- On the spectrogram the first .35 ms of the interval in question does not appear interestingly distinct from what follows: not having the spectrogram available, he has probably chosen the onset point of "man" somewhat arbitrarily. Is there any reason to say that there is a special acoustic feature in the specific .35 ms region Shann Ford identifies?
- Even if there was some tongue gesture as Shann Ford describes, is that any reason to say that the "a" followed? Even if we were convinced that the unfolding of the tongue occurred in anticipation of an intended "a", it doesn't follow that there was an "a", only that Armstrong intended to produce one. But we already knew that. He spent several hours rehearsing!
- Even if the pulses of energy observed in the spectrograms in our earlier posts were interference (and Shann Ford apparently thinks one of them is a tongue movement, and the others are interference), that still doesn't explain why there is no trace of a vowel-like production in the gaps between the pulses. So if there was an "a", why was it so short (taking no extra time than a transition from "for" to "man" would anyway), and where did it go?
I say potable, you say portable
 Marginally related to Mark's recent posts about the new vs. old
wineskins (see
here, also
here), Kathleen Fasanella reports a more modern
example over the container issue, in this case what to call water
that is fit to drink. The link shows the lettering on
the back of a tank truck that was located
somewhere between El Paso and Las Cruces, which reads
, "NON PORTABLE WATER."
That couldn't be right though. Obviously it was portable, since it was
being transported in a tanker-type truck and apparently was being
either filled or emptied at an adjacent fire hydrant. So why would the
truck lettering say it wasn't portable?
Marginally related to Mark's recent posts about the new vs. old
wineskins (see
here, also
here), Kathleen Fasanella reports a more modern
example over the container issue, in this case what to call water
that is fit to drink. The link shows the lettering on
the back of a tank truck that was located
somewhere between El Paso and Las Cruces, which reads
, "NON PORTABLE WATER."
That couldn't be right though. Obviously it was portable, since it was
being transported in a tanker-type truck and apparently was being
either filled or emptied at an adjacent fire hydrant. So why would the
truck lettering say it wasn't portable?
I can't say for sure but I wonder if several factors were at work. Most likely, the company simply confused "portable" with "potable." Who uses "potable" anyway these days? Also, "potable" probably sounds a lot like "portable" to people who play free and loose with their "r" sounds (rhoticity is the uppity linguistic word for this). Some folks stick /r/ sounds into places that they don't belong and others drop them in certain positions of words. I grew up saying "framiliar," for example, but I faithfully preserved my /r/ in words like "car" or "teacher." There's a lot of that going around, keeping dialectologist busy.
So was this truck's sign an aberration of some kind? I checked "portable water" on Google, getting 596,000 hits for it, the vast majority of which aroused no suspicion whatsoever. They were associated mostly with portable water tanks, purifiers, filtration systems, bags, bowls (for potty training), sport cases, dog dishes, testing kits, heaters, hose adapters, and pumps. Then I checked "potable water" and got a million and a half hits, mostly associated with potable water tanks, treatment, reclamation, supplies, studies, installations, quality, contamination, applications, technologies, and chemistry.
Apparently the larger world of print hasn't fallen into the "portable/potable" sink hole, at least not yet. Well, except for the signage on the truck somewhere in the Southwestern US. But keep your eyes open, it may happen next door at any time. And when it does, we can all have a good chuckle.
Update: I spoke too soon. Mark advised me to try "water is not portable." I did and it gave me 251 items like: "tap water is not portable in China" and a sign near the Moscone Convention Center in San Francisco, "this water is not portable." Lots of water transportation going on I guess.
One 75-millisecond step before a "man"
I don't have any new insights to add to the Great Armstrong Determiner Hunt, but I can contribute some better-quality spectrograms.
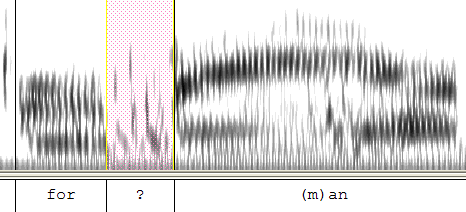
Here's the first phrase:
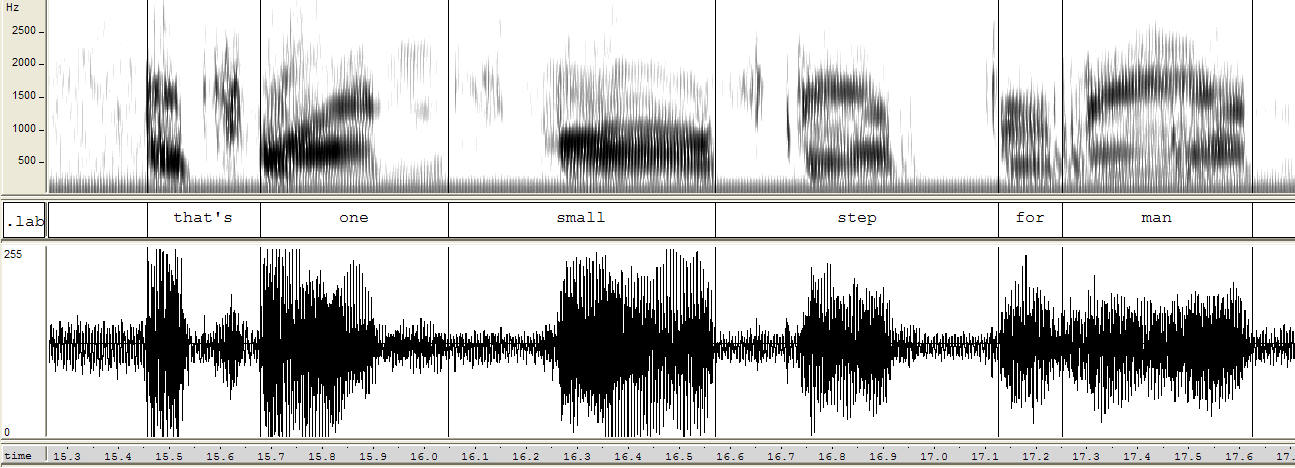
And here's the second one:
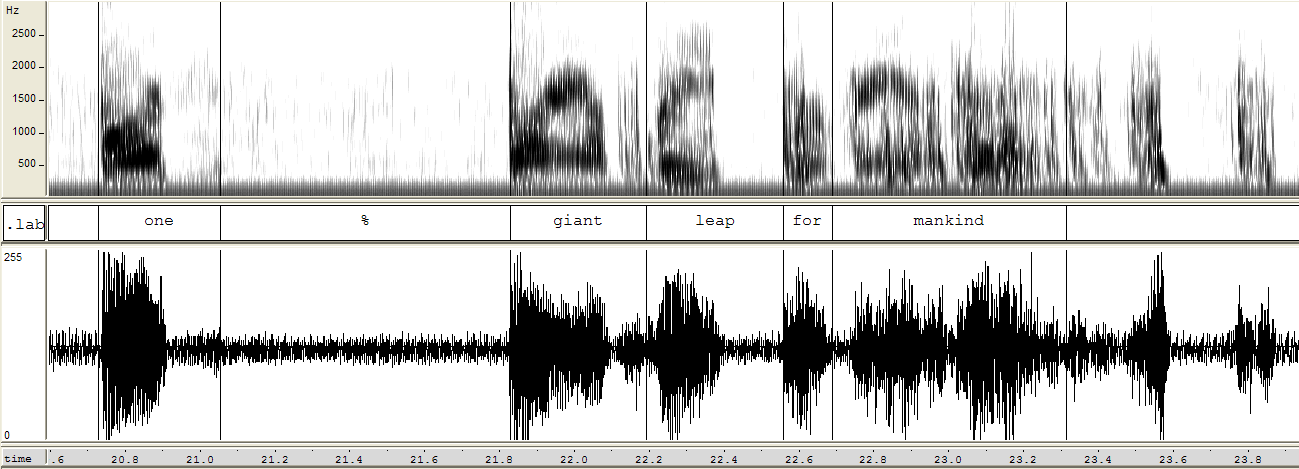
Well, here's an additional meta-comment. The Houston Chronicle story tells us that
According to Ford, Armstrong spoke, "One small step for a man ... " in a total of 35 milliseconds, 10 times too quickly to be heard."
If we take this assertion literally, the claim is that Armstrong produced six words in 35 milliseconds, which corresponds to the extraordinary speaking rate of 10,286 words per minute. Seems like BBC reporters are not the only ones who ought to get into the habit of invoking the calculator function on their cell phones from time to time.
It's apparent by inspection that "that's one small step for (x) man" actually took Armstrong about 2.18 seconds to say. This corresponds to a speaking rate of about 193 words per minute, which is a normal-to-slow sort of rate for formal speech when pauses are not counted. Thus in the first Bush-Kerry presidential debate, averaging over the first 3 1/2 minutes of each candidate's contributions, Bush clocked 220 words per minute while Kerry came in at 202 WPM. (W used longer pauses, so that if pauses are included, his rate went down to 155 WPM, while Kerry came in at 167 WPM).
I expect that what Ford meant was that there's a period of time that he associates with the missing 'a' that is .035 seconds long. It would have to be somewhere in the .075 seconds between the end of the vocalic part of "for" and the beginning of the vocalic part of "man", highlighted in the picture below:
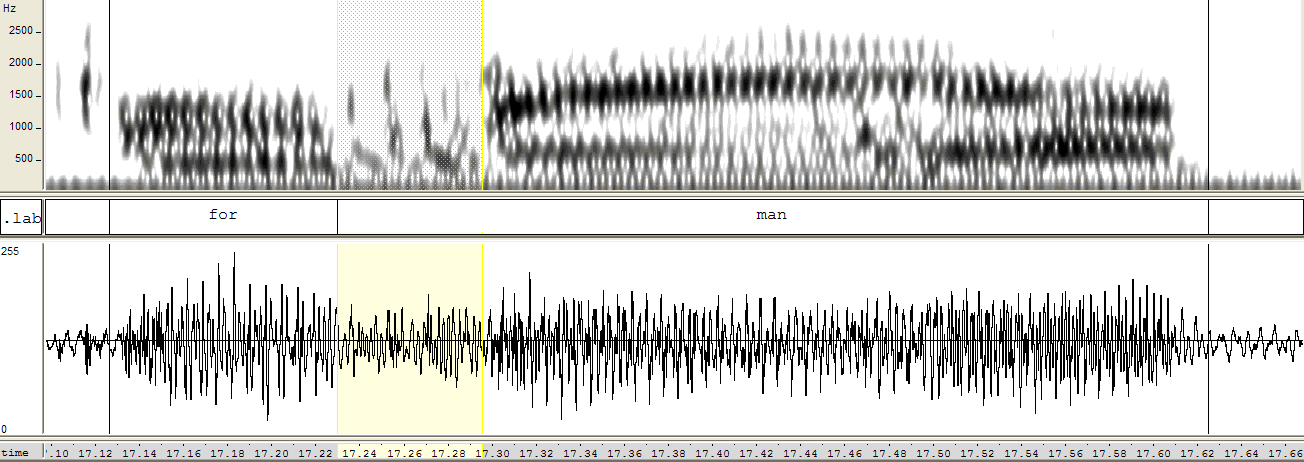
It would have to be sharing that space with the [m] of man. And as David Beaver has pointed out, the corresponding lower-amplitude region in the next phrase, between the end of the vowel of "for" and the start of the vowel of "mankind", is also about .075 seconds long (give or take 5 msec in either case, depending on your judgement about where to put the boundaries). And 75 msec is about right for a pre-stressed intervocalic word-initial [m].
[I guess I should say that I can't either hear or see whether or not Armstrong produced a half-swallowed schwa in between "for" and "man", and (in advance of seeing his discussion of the evidence) I'm skeptical of the arguments attributed to Ford in the news media. If anyone can point me to a version of his presentation that is not filtered through the media process, I'll look forward to reading it.]
More wineskin history
In response to Sunday's post about new (or old) wine in old (or new) bottles, two correspondents pointed out to me that the history is more complicated -- and more interesting -- than I thought. In the first place, there is an "old wine in new bottles" version of the proverb that is roughly as old as the "new wine in old bottles" version in the gospels. In the second place, the message of this alternate version is the basic "can't tell a book by its cover" idea which is behind most modern uses of the expression, as opposed to the message of the version in the gospels, which is something like "new ideas need new practices". In the third place -- well, let's get to the facts first.
Aaron "Dr. Whom" Dinkin writes:
I read the discussion of the interpretation of "new wine in old bottles" with interest; but it seems to me you've missed an early related example which seems to give the metaphor the reading that your original correspondent understood it to have (viz., "a new item or concept with little intrinsic value being packaged in a way that deceptively gave it the high values belonging to an older or well-established concept or item"). The Talmud (Avot 4:27) says:
Rabbi Meir said, "Look not at the flask, but at what it contains: there may be a new flask full of old wine, and an old flask that has not even new wine in it."
I gather that Meir lived in the late 1st century or early 2d.
And from Jacob Baskin comes a different translation, a hyperlink, and further insight:
Upon reading your Language Log post yesterday, I remembered having seen something like "new wine in old bottles" somewhere else. I found it in the Mishnah, in Pirke Avot (Chapters of the Fathers), a text containing Jewish proverbs dating between the 3rd century B.C. and the 3rd century A.D. In Chapter 4, Mishnah 20:
A Rabbi used to say: Do not look at the flask but at what is in it; there may be a new flask that is full of old wine and an old flask that does not even have new wine in it.
This saying is unattributed (attributed sometimes to Rabbi Meir, because all unattributed sayings are thus attributed traditionally), and could have been written before or after the books of the Gospel. The interesting thing is that it talks both about new flasks full of old wine and old flasks full (or empty) of new wine -- and uses the metaphor in a very different way. I found Pirke Avot in English and Hebrew here:
http://www.yarzheit.com/pirkeiavos.htm
The obvious (and I suppose unanswerable) question is whether there is some implicit two-thousand-year-old dialogue here. And if so, who was responding to whom. More food for the thought: I gather that the Pirke Avot was compiled in the 3rd century A.D. in Roman-occupied Palestine by Rabbi Yehudah ha Nasi, and the wineskin proverb is among the least spectacular of the stories attributed to Rabbi Meir.
A more accessible question is how the mishnaic wineskin proverb (or some older folkloric version) has contributed to the modern interpretation of the various new/old wine in old/new bottles expressions.
[Update -- Ian Slater offers an alternative (or perhaps additional) interpretation:
The passage from the Mishnah may be pertinent. However, the specific translation of "flagon" could be a problem. The on-line "Comprehensive Aramaic Lexicon" offers the definition "vessel" for the noun QNQN (http://cal1.cn.huc.edu/), which is at least compatible.
However, Marcus Jastrow's great "A Dictionary of the Targumim, The Talmud Babli and Yerushalmi, and the Midrashic Literature"* (1903) suggests a different image. It defines Qanqan (page 1394) first very specifically as "a cylindrical vessel let into the ground of the cellar," and then adding "in gen. wine- or oil-vessel." Avot is the first text cited; several others clarify the location in the cellar, and the considerable size, and relative value, of the object (e.g., giving someone not only the wine but the vessel is generous).
Jastrow indicates that, in its context, the Avot saying means that even a young man may be filled with a great quantity of good (old, established) learning, and even an old man may contain only what is new (and raw).
So the idea, and the vessels, may not be the same as those in the Gospel, although in modern usage some influence is likely.
*Available in pdf format from Tyndale House at http://www.tyndale.cam.ac.uk/jastrow/, and from ETANA, at http://www.case.edu/univlib/preserve/Etana/JAST.DICv1/JAST.DICv1.html and (for volume two) http://library.case.edu/ksl/ecoll/books/jasdic01/jasdic01.html
]
Posted by Mark Liberman at 08:00 AM
October 02, 2006
One small step backwards

Neil Armstrong, when he made that famous step, put his foot in it. He intended to say "That's one small step for a man, one giant leap for mankind." But stepping out after hours floating in a tin can, Armstrong famously fluffed his line, omitting the intended "a" and saying "That's one small step for man, one giant leap for mankind." Or at least this has until now been standard lore, accepted even by Armstrong. You can listen for yourself:
The Cupertino effect strikes again
On the American Dialect Society mailing list, Joel Berson recently noted this perplexing item from the police log of the Arlington (Mass.) Advocate (Sep. 28, 2006):
At 3:38 p.m., police responded to Wellington Street about youths shooting paintballs from a home. Police denitrified the youths and seized the paintball guns. Police are investigating.
Joel wondered if the "denitrifying" of the youths might be a chemical decontamination process, while other list members speculated that it could have something to do with a skin test to determine whose hands had fired the guns, or perhaps the forced removal of the paintballers' tanks of compressed gas (nitrogen or carbon dioxide, both slangily referred to as "nitro"). Despite these creative conjectures, this seems to be a pretty clear case of spellchecker interference (a possibility Joel had also considered), where identified was originally misspelled as dentified and then "corrected" by a spellcheck program to denitrified. In other words, it's the pernicious Cupertino effect again (so called by European Union writers who noticed that co-operation was turning up as Cupertino in EU documents).
When I entered dentified into MS Word 2000 and ran the spellcheck, I got three suggestions: identified, dandified, and denitrified. So the custom dictionary for Word 2000 ranks denitrified third, but I figured other custom dictionaries might rank it as the top alternative. And sure enough, when I tried the same test on a machine with MS Word 97, I got only one suggestion: denitrified.
So some time between the releases of Word 97 and Word 2000, the
Microsoft spellcheck gurus improved their algorithms and identified identified as the most likely word
mistyped as dentified. But
the denitrified suggestion,
either from old versions of MS Word or some other word processing
programs, lingers on in the text of various websites:
Not every song on Wippit is available at no extra cost to subscribers, but many are discounted to subscribers and can be denitrified by one of these little green S's. (Wippit FAQ)
This site provides information that Federal Preservation Officers denitrified as necessary for carrying out their legal responsibilities. (Native American Consulation, Federal Highway Administration)
Perfect new install of windows all devices detected except card which is denitrified as VGA compatible as usual giving usual quality screen in all resolutions despite no monitor showing in device manager or a "specific" card. (Motherboardpoint forum)
No one could have gone from among us who would be missed more than will George F. Bates who has been denitrified with all the interests of Allen for years. (Allen Cemetery, Lyon Co., Kansas, mistranscribed article from Northern Lyon County Journal, May 20, 1904)
And here's a case where identified was apparently misspelled as <i dentified> and then transformed into <in denitrified>:
Recognizing the mutual benefit of cooperation in promoting the development of the West Bank, the Gaza Strip and Israel, upon the entry into force of this Declaration of Principles, an Israeli-Palestinian Economic Cooperation Committee will be established in order to develop and implement in a cooperative manner the programs in denitrified in the protocols attached as Annex III and Annex Iv. (Palestinian Declaration of Principles on Interim Self-Government Authority, Sep. 13, 1993)
By the way, in my original post on the Cupertino effect, I wrote:
One EU writer claims that the Cupertino change can even happen to the word cooperation if the word processor's custom dictionary only has the hyphenated form co-operation. However, I find it difficult to believe that many custom dictionaries out there include Cupertino but not unhyphenated cooperation.
I shouldn't have been so incredulous. Even though none of the custom dictionaries I've tried produce the desired result, helpful reader "Huw" emailed a screenshot of an errant spellchecker in action, from an old version of Outlook Express (custom dictionary copyrighted as "Houghton Mifflin Company © 1996 Inso Corporation"):
[Update, 10/3/06: The Natural Language Team for Microsoft Office owns up to the denitrified slipup on the team's new blog.]
Pullum's peregrinations
Reprinted from WHASC:
Geoff Pullum will be at the Capitola Book Cafe (1475 41st Ave.) on Tuesday Evening, October 3rd at 7:30PM, to read from and discuss his new book (co-authored with Mark Liberman) Far From the Madding Gerund and Other Dispatches from Language Log.
Geoff has just returned from an extended trip to Europe, where he gave talks at the Philosophy of Linguistics Conference at the Interuniversity Center, Dubrovnik in Croatia, at a conference in honor of Professor Neil Smith at the Department of Phonetics and Linguistics, University College London in England, at l’Université de Paris 7 (Jussieu, Paris) in France, and a series of lectures to a research group at the University of Lille 3, also in France.
The imminent lexicographic singularity
In his 1940 essay "New Words", George Orwell wrote:
I have read somewhere that English gains about six and loses about four words a year.
In a review of Don Watson's 2003 jeremiad Death Sentence, The Decay of Public Language, James Button wrote:
The genius of English is the way it updates itself every day, with 20,000 new words a year, Watson read somewhere.
Now, a BBC News book review from 10/1/2006 ("New insults for English language"), writing about a book that documents cutesy new words like "tanorexic" and "celebutard", tells us that
The words have been taken from entries in the Collins Word Web, which monitors sources to pick up any new additions.
The Word Web lists genuine words and phrases that have entered the English language, and contains more than 2.5bn words, expanding at a rate of 30m words per month.
Holy singularity, Batman! Have we really come so far since 1940? Has the internet turned English into a real-world lexicographical Naian?
George Orwell would be intrigued by this prospect, I think, since he felt that
Everyone who thinks at all has noticed that our language is practically useless for describing anything that goes on inside the brain. [...] [I]t seems to me that from the point of view of exactitude and expressiveness our language has remained in the Stone Age.
And like many people (but not everyone), Orwell felt that the key to improving exactitude and expressiveness is to increase the stock of words. And 30 million new words a month would be a hefty rate of increase indeed, even if the voice of common sense whispers that you'd need to learn 12 words per second, 24/7, in order to keep up.
However, if Orwell has been reading the BBC news in some heavenly pub, I'm afraid that he's in for a disappointment. This particular BBC article is even more confused than your usual BBC piece is. A trivial web search turns up a 2004 press release, which makes it clear that the "Collins Word Web" does not "list genuine words and phrases that have entered the English language". Rather, it's a text corpus used by Collins (a Murdoch subsidiary) for lexicographical purposes -- that is, a collection of texts in digital form. By a sensible convention, the word count given for such a collection is the total number of character strings separated by white space, not the number of different space-separated strings, much less the number that are deemed to represent distinct "words" in any interesting sense. (You'll want to eliminate inflected forms of existing words, digit strings, typographical errors, and so on.)
The sheer size of the "Collins Word Web" corpus is not so impressive -- anyone can now use web search engines to search the text collection of the whole internet (minus various excluded bits), which amounts to many trillions of words. The Collins corpus is presumably selected in various ways to be more representative, to include less junk, etc. -- but the size alone shouldn't impress anyone.
A couple of items further along in the Google hits for "Collins Word Web", you can find a page on the Collins Word Exchange site, "How to make a dictionary", which explains the conceptual issues clearly, and explains that "[e]very month [the Colllins lexicographers] collect several hundred new [words] and then monitor them to see if they are becoming part of general language".
The writer(s) and editor(s) of the BBC piece apparently didn't know about any of this, and didn't have the time or inclination to learn. ("30 million, several hundred -- whatever.") That's not surprising, I guess, since they also neglected to mention the names of the authors of the book that they were reviewing -- for the record, the book title (which the review does give) is I Smirt, You Stooze, They Krump, and the authors (whom the review fails to mention) are Justin Crozier & Cormac McKeown.
All jokes aside, I wonder what is going on at the BBC these days. Do they give their writers impossible quotas to fulfill? Is this the insidious onset of nvCJD, seeded by the BBC cafeteria's roast beef? Does the organization's worldwide reach create a thriving internal market in unusually potent recreational drugs?
If you're curious about how many distinct new words are actually added to the English language every year, I can't give you an answer, but I can point you to a discussion of some of the additional questions that would have to be answered before you could get an answer that would mean anything.
And if you're a fan of jokey neologisms like "celebutard" and "tanorexic" (also known as "stunt words"), you should check out Mark Peters' blog Wordlustitude.
[Orwell link by email from Ian Cooper]
[Ben Zimmer points out that this confusion (between "corpus" and "lexicon") was also featured in recent headlines on the billion-word Oxford English corpus. But headline writers, especially at newswires like the AP, are notoriously careless. The novelty in the current story is that the confusion in embedded in the article itself. ]
October 01, 2006
Was Barbie Right??
Who could forget Barbie Doll's programmed utterance "Math is hard!" and the uproar it caused some years back? I was reminded of Barbie's opinion by the really interesting comment that Dick Margulis sent me a few weeks ago, triggered by my post Sex & Language Stereotypes through the Ages, which was about Otto Jespersen's chapter "The Woman". Dick describes a study done forty years ago on number-reading by women and men:
For some reason your post shook loose an item from my memory that you might find interesting.
In the mid-1960s, the Starch Organization did a study for the Peoria Journal Star newspaper in which they ascertained that, in news reports at least, men and women read numbers differently. (I would not begin to suggest that the result would be the same if the experiment were to be conducted today, nor that it would have applied in all geographic markets then; the study was of that time, place, and readership).
The paper ran a split edition on the test day. In half the papers, numeric quantities were expressed with numerals, in accordance with Associated Press style. In the other half, all numbers were spelled out.
Starch, if you are unfamiliar with their methods, interviews a random sample of the audience, in person, on the test date, and evaluates how much of each given article an individual has read and how much the individual has retained. What they found was that far more women than men stopped reading upon encountering numerals or, if they read past that point, were less able to recollect the amount, but that both amount read and amount retained were quite comparable for men and women if numbers were spelled out.
I suppose this isn't strictly a linguistic difference, and it pretty clearly has nothing to do with the way brains are wired--it's obviously culturally bound. I just thought you might find it of interest.
It may not be a strictly linguistic difference, but it sure looks like grist for our mill. Does anyone out there know if comparable studies have been done since the mid-1960s, and/or does anyone have any insight into the result of this study?
How Bank Robbers Talk in South Africa
This afternoon, while waiting to be interviewed about xenoglossy on the South African talk show Believe It or Not (Talk Radio 702), I was listening to a string of three or four commercials that they ran just before my interview. All but one of them, including a deodorant commercial, were read by men speaking what sounded to my dialect-deaf ears like a standard British English accent. The exception, advertising some terrific opportunity, was read by a man speaking straight midwestern American English, and it included the following line (the first two words may not be exactly what he said, but they're close): Everybody freeze! This is a hold-up! We're here to give you CASH BACK! He was obviously supposed to sound like a bank robber; the implication was that Americans are the quintessential bank robbers. So now we know: in the South African ad biz, at least, Americans are stereotypical ordinary or garden-variety criminals. This has to be a step up from a stereotype as, say, war-mongering international pariahs.
Ask Language Log
 Rosie Redfield writes:
Rosie Redfield writes:
I used to think that the phrase "new wine in old bottles" referred to a new item or concept with little intrinsic value being packaged in a way that deceptively gave it the high values belonging to an older or well-established concept or item.
But lately I've been noticing the reverse phrase "old wine in new bottles", where something old is said to gain apparent value by new packaging. This turns out to be the more common usage: Google finds 136,000 "old wine in new bottles" and 50,000 "new wine in old bottles"
Is this a new confusion? Which is the original?
Answering the second question first: despite the Google counts, the original expression is "new wine in old bottles". The source of this expression is a parable reported in the gospels of Matthew, Mark and Luke, given in the modern-spelling KJV below:
Then came to him the disciples of John, saying, Why do we and the Pharisees fast oft, but thy disciples fast not?
And Jesus said unto them, Can the children of the bridechamber mourn, as long as the bridegroom is with them? but the days will come, when the bridegroom shall be taken from them, and then shall they fast.
No man putteth a piece of new cloth unto an old garment, for that which is put in to fill it up taketh from the garment, and the rent is made worse.
Neither do men put new wine into old bottles: else the bottles break, and the wine runneth out, and the bottles perish: but they put new wine into new bottles, and both are preserved.And the disciples of John and of the Pharisees used to fast: and they come and say unto him, Why do the disciples of John and of the Pharisees fast, but thy disciples fast not?
And Jesus said unto them, Can the children of the bridechamber fast, while the bridegroom is with them? as long as they have the bridegroom with them, they cannot fast.
But the days will come, when the bridegroom shall be taken away from them, and then shall they fast in those days.
No man also seweth a piece of new cloth on an old garment: else the new piece that filled it up taketh away from the old, and the rent is made worse.
And no man putteth new wine into old bottles: else the new wine doth burst the bottles, and the wine is spilled, and the bottles will be marred: but new wine must be put into new bottles.And they said unto him, Why do the disciples of John fast often, and make prayers, and likewise the disciples of the Pharisees; but thine eat and drink?
And he said unto them, Can ye make the children of the bridechamber fast, while the bridegroom is with them?
But the days will come, when the bridegroom shall be taken away from them, and then shall they fast in those days
And he spake also a parable unto them; No man putteth a piece of a new garment upon an old; if otherwise, then both the new maketh a rent, and the piece that was taken out of the new agreeth not with the old.
And no man putteth new wine into old bottles; else the new wine will burst the bottles, and be spilled, and the bottles shall perish.
But new wine must be put into new bottles; and both are preserved.
No man also having drunk old wine straightway desireth new: for he saith, The old is better.
You might well be puzzled about why old bottles would be any more likely to burst than new ones. My assumption, based on no reliable information at all, has always been that the "bottles" in question would have been bags made from goatskin or the like, and old ones would have become dried out and prone to crack, especially given the stresses caused by fermentation of new wine.
As for the original meaning of the new/old wine/bottle parable, your guess is as good as mine, but my guess would be something in the general line of the UCC's interpretation of Gracie Allen's proverb "Never put a period where God has placed a comma". In a more familiar idiom, something like "different strokes for different folks".
However, the common application of the associated phrase has long since shifted in a completely different direction. Most uses in recent centuries seem to refer to certain sorts of deceptive practices, either passing something old off as new, or passing something new off as old. And people have become quite confused about whether it's old wine in new bottles, or new wine in old bottles. My theory is that this is because fementation of wine in goatskin wine bottles has never really been part of Anglophone culture, so the parable never made a lot of sense in the British Isles or in North America.
Addressing Professor Redfield's first question, "Is this a new confusion?":
You might be tempted to attribute the confusion to a modern decline in bible-study standards. However, while it's certainly true that the proportion of the population who can identify such biblical references is probably at an all-time low (cue the survey comparing knowledge of the bible and the Simpsons), the phrasal confusion is by no means modern in origin.
The earliest clear example of confusion that I was able to locate, in a couple of minutes of on-line searching, was from "The Retailer, No. VI", The Columbian Magazine, Dec 1788; 2, 12; p. 695:
Some unlucky satirical gentleman has found out our little rendezvous, and has lashed me severely by a letter, upon the subject of my numbers, and not content with leaving me to the secret pangs of self-mortification, he wishes me to give it a place in the present Retailer; as it will possibly afford some entertainment to the reader, and will furnish me with an opportunity to exculpate myself, I shall comply with his request.
"Master Retailer,
"I have for these four months kept a very sharp eye upon you, as I wanted to examine all your manoeuvres. I am pretty well acquainted with the liberties you take with yourself and others: -- for it is a well-known fact, that there is not a set of writers in the world, who are so given to fibbing, as your Spectators, Tattlers, Triflers, and your whole race of 'ers; but in good faith I think you beat them all. [...]
Now your third number really makes me laugh -- I'troth you must dream, because others before have dreamt, and then to set yourself up, you pull others down, pretending that all authors are Retailers. Thank Heaven! this was but a dream, and perfectly new, for I am sure no mortal ever dreamt of such a thing before; no, no, they were none of your second-handed fellows, that would present some stale stuff in a new fangled dress, or give you "old wine in new bottles," nor even new wine in old bottles, nor yet collect all the remains in the mugs of slobbering drunkards, nor like a certain brother Retailer of your's, who keeps nothing but Bohea tea, distributed in a number of little kegs, and yet can produce to his ignorant customers as good Hyson, Imperial, Congo, or Souchong, as ever came from Pekin, no -- they could each give you the genuine stuff, of their own preparing too."
[emphasis added]
Finally, I was very impressed by Professor Redfield's research blog. This is not my field at all, but that makes it all the more interesting to watch how someone thinks about research in progress, rather than trying to put the message back together from the way the results are ultimately presented in a formal journal article. It reminds me of the letters Michael Ventris wrote to Emmett Bennett, Alice Kober and others as he was working on the decipherment of Linear B.
[Update -- Ian Slater writes:
You seem to picked up your understanding to the "bottles" in the KJV from a reliable source.
Restricting the search to Matthew (on the assumption that translators would follow their own precedent what was long regarded as the "First Gospel," I found that The Revised Version of 1881, and the Revised Standard Version, have "wineskins," for the Greek askos (confirmed in UBS "Greek New Testament" and the Perseus on-line text), "leathern bag, wineskin" (after Liddell-Scott).
The standard explanation seems to be that skin bags, once having been stretched to their limits by fermenting wine, could not be expected to survive re-use.
Among the predecessors of the KJV, two rivals, the Calvinist Geneva Bible (1560) and the official Bishops' Bible (1568), both had the slightly ambiguous "vessels." I suspect was the reading of the earlier Tyndale-based versions as well, although I haven't found on-line texts to supplement my collection.
However, "bottle," in the general sense of "container for a liquid," as opposed to the modern assumption of "glass bottle," may have been the intended sense in 1611. It certainly hasn't been taken that way, however.
The eighteenth-century Challoner revision of Douay-Rheims has "bottles," but the influence of the KJV may be evident here, as elsewhere; the Douay New Testament of 1582 may have read differently. It was supposed to be following the Vulgate, which has "uter," defined by Lewis and Short as "a bag or bottle made of an animal's hide, a skin for wine, oil, water, etc." (again, checked against the Perseus on-line versions).
]
[And Kevin Smith agrees:
My two cents regarding the Biblical reference:
According to Thayer and Smith's Bible Dictionary, the Greek word used for bottles (transliterated Askos) refers to "a leathern bag or bottle, in which water or wine was kept." And many modern translations (the NIV and NAS come to mind) use the term "wineskins" instead of "bottles." The use of the term isn't to surprising, given Webster's definition of "bottle" in 1828:
"A hollow vessel of glass, wood, leather or other material, with a narrow mouth, for holding and carrying liquors. The oriental nations use skins or leather for the conveyance of liquors; and of this kind are the bottles mentioned in scripture. 'Put new wine into bottles.'"
]
[Josh Jensen clarifies the meaning of the parable:
A cursory glance over several commentaries reveals (surprisingly!) that in this case, there's general agreement over what Jesus meant about wine and wineskins. Jesus has been introducing a new paradigm, a new way of thinking about the kingdom of God. It just won't do to accept this new paradigm but hold onto the praxis that characterized the old paradigm.
A modern example: a university has a history faculty that thinks out from a European center. Over time, faculty members retire, die, or go to work at conservative think tanks. A new generation of professors comes to be the dominant force in the department. Eventually, an old alumnus visits campus and looks at a course listing. He asks where The History of Civilization and other core classes went to. The Chair tells him: "We don't teach the old classes because we don't believe what the course titles claimed about history. You can't put new wine in old wineskins: you'll ruin the skin and the wine. If you want the old wineskin, go somewhere that serves the old wine."
Since Josh describes himself elsewhere as "a very conservative evangelical", that history-department example has some interesting overtones. ]
[Update -- more here.]